

It’s most likely true that everyone has taken a survey in some unspecified time in the future or different. What’s additionally most likely true is that most individuals assume polling is simple. And why not? Google has a web site for creating polls. Social media websites and running a blog websites present capabilities for conducting polls. There are additionally fairly a number of free on-line survey instruments. Why wouldn’t folks consider that simply anyone might conduct a survey.
Maybe as a consequence of do-it-yourself polling, there isn’t a finish to really unhealthy, novice polls. However, there are additionally well-prepared polls meant to mislead, some overtly and a few underneath the guise of unbiased analysis. Some folks have accordingly come to consider that info derived from all polls is biased, deceptive or simply plain ineffective. Familiarity breeds contempt.
Like some other complicated apply like medication, statistical polling isn’t an actual science and may unexpectedly and unintentionally fail. However for probably the most half, it’s professional and dependable even when the general public doesn’t perceive it. Nevertheless, ignorance breeds contempt too.
Ignorance results in worry and worry results in hate.
Persons are comfy with polls that affirm their preconceived notions, affirmation bias, but they lambaste polls that don’t affirm their beliefs as a result of they don’t perceive the science and arithmetic behind statistical surveying. That is skilled equally by each side of the political spectrum. Nonetheless, surveys are relied on extensively all through authorities and enterprise to assist their work. And, after all, politicians dwell and die by ballot outcomes.
Ballot haters normally give attention to six sorts of criticisms:
- The outcomes have been determined earlier than the ballot was performed.
- The ballot solely included 1,000 folks out of 300,000,000 Individuals
- The outcomes ought to solely apply to the folks questioned
- The ballot didn’t embody me
- The ballot solely interviewed topics who had landlines
- The ballot didn’t ask truthful questions
I didn’t make these criticisms up. I compiled them from Twitter threads that concerned political polls. I clarify why these criticism is perhaps appropriate or not on the finish of the article.
If you wish to assess whether or not a political ballot actually is professional, there are 4 issues you need to take a look at. It helps if you understand some key survey ideas, together with inhabitants, body, pattern and pattern dimension, interview strategies, query varieties, scales, and demographics. In case you do, skip to the final part of this text for the hints. In any other case, learn on.
The phrases ballot and survey are sometimes used synonymously. Historically, polls have been easy, one-question, interviews typically performed in individual. Surveys have been extra elaborate, longer, knowledge gathering efforts performed with as a lot statistical rigor as attainable. Political “who-do-you-plan-to-vote-for” polls have developed into expansive devices to discover preferences for insurance policies and politicians. You may blame the evolution of computer systems, the web, and private communications for that.
Polls on social media are for leisure. Severe surveys of political preferences are fairly totally different. There’s a lot that goes into making a scientifically legitimate survey. Scores of textbooks have been written on the subject. Moreover, the state-of-the-art is continually enhancing as know-how advances and extra analysis on the psychology of survey response is performed.
Listed here are a number of essential issues in creating surveys.
As you may anticipate, the supply of a political survey is necessary. Earlier than 1988, there have been on common just one or two presidential approval polls performed monthly. Inside a decade, that quantity had elevated to greater than a dozen. By 2021, there have been 494 pollsters who performed 10,776 political surveys. Fivethirtyeight.com graded 93% of the pollsters with a B or higher; 2% failed. Of the pollsters, two-fifths lean Republican and three-fifths lean Democratic. Notable Republican-leaning pollsters embody: Rasmussen; Zogby; Mason-Dixon; and Harris. Notable Democratic-leaning pollsters embody: Public Coverage Polling; YouGov; College of New Hampshire; and Monmouth College.
The matters of a political survey are merely what you wish to find out about sure insurance policies, occasions, or people. Good surveys outline what they imply by the matters they’re investigating and don’t push biases and misinformation. They account for the relevance, changeability, and controversiality of the subject within the methods they manage the survey and ask the questions.
The inhabitants for a survey is the group to which you wish to extrapolate your findings. For political surveys within the U.S., the inhabitants of a survey is solely the inhabitants of the nation, or at the very least the voters. The Census Bureau gives all the knowledge on the demographics (e.g., gender, age, race/ethnicity, training, revenue, get together identification) of the nation that surveys want.
The body is an inventory of topics within the inhabitants that is perhaps surveyed. Frames are harder to assemble than inhabitants traits as a result of the knowledge sources are extra various and never centralized. Sources may embody phone directories, voters lists, tax data, membership lists of public organizations, and so forth.
The survey pattern is the people to be interviewed. Extra people are wanted than the variety of samples desired for the survey as a result of some people will decline to take part. The pattern is normally chosen from the body by some sort of chance sampling. Often, stratified-random sampling is used to make sure all of the related inhabitants demographics are adequately represented. This establishes survey accuracy.
Getting the inhabitants, body, and pattern proper is probably the most elementary side of a survey that may go unsuitable. Skilled statisticians agonize over it. When one thing goes unsuitable, it’s the primary place they give the impression of being as a result of all the pieces else is fairly easy. Generally figuring out issues in surveys is close to inconceivable.
Pattern dimension is solely the variety of people who reply to the survey. Pattern dimension (and some different survey traits) decide the precision of the outcomes. One of many first issues critics of political polls cite is how few topics are interviewed. A problem in survey design is to pick a big sufficient pattern dimension to offer satisfactory precision but not too many samples that will improve prices.
Most political polls use 500 to 1,500 people to realize margins-of-error between .5% and a pair of.6%. (In case you’ve taken Stats 101, the margin-of-error is the 95% confidence interval round a mean survey response.) Utilizing greater than 1,500 people is pricey and doesn’t improve precision a lot (as proven within the chart).
There are lots of strategies used to offer inquiries to people in a survey, together with: in-person, phone, recorded message, mail and electronic mail, and web sites. Every has its personal benefits and limitations. Some surveys use multiple methodology with the intention to take a look at the affect of the interview.
The questions which are included in a survey are sometimes a spotlight of critics. The building of survey questions is an arduous course of involving eliciting info on a subject so to not affect the ensuing reply. It sounds easy however to an expert survey designer, it seldom is. The construction of questions shouldn’t be obscure, main, or compound, nor ought to it make use of double negatives. The selection of particular person phrases can also be necessary to make sure they don’t introduce bias, aren’t offensive or emotion-laden, nor could also be deceptive, unfamiliar, or have a number of meanings. Jargon, slang, and abbreviations/acronyms are significantly taboo. Generally surveys must be offered in numerous languages in addition to English relying on the body. Questions additionally must be designed to facilitate the evaluation and presentation of outcomes.
Varieties of Questions
Asking a query in plain dialog doesn’t require the rigor that’s wanted for survey questions. In a dialog, you may rephrase and follow-up whenever you don’t get a solution that can be utilized in an evaluation. You don’t have that flexibility in a survey; you solely get as soon as likelihood. It’s important to assemble every query in order that respondents are pressured to categorize their responses into patterns that may be analyzed. There are fairly a number of methods to do that.
Open Ended Questions
Essentially the most versatile sort of query is the open-ended query, which has no predetermined classes of responses. This kind of query permits respondents to offer any info they need, even when the researcher had by no means thought of such a response. As a consequence, open-ended questions are notably troublesome to investigate. They’re virtually by no means utilized in professional political polls.
Closed ended Questions
Closed-ended questions all have a finite variety of decisions from which the respondent has to pick. There are lots of varieties of closed-ended questions, together with the next eight.
1. Dichotomous Questions — both/or questions, normally offered with the alternatives sure or no.

Dichotomous questions are simple for survey individuals to grasp. Responses are simple to investigate. Outcomes are simple to current. The disadvantage of dichotomous questions is that they don’t present any nuances to participant solutions.
2. Single-Selection Questions — a vertical or horizontal listing of unrelated responses, generally offered as a dropdown menu. The responses are sometimes offered in sequences which are randomized between respondents.

Single-choice questions are simple for survey individuals to grasp. Responses are simple to investigate. Outcomes are simple to current. The disadvantage of single-choice questions is that they will’t all the time present all the alternatives that is perhaps related. Within the pattern query, for instance, there are much more points {that a} participant may assume are extra necessary than the seven listed.
3. A number of-choice Questions — like a single selection query besides that the respondent can choose greater than one of many responses. This presents a problem for knowledge presentation as a result of percentages of responses gained’t sum to 100%

A number of-choice questions are considerably harder for survey individuals to grasp as a result of individuals can verify multiple response field. Survey software program helps to validate the responses. These responses are harder to investigate as a result of it’s virtually like having a dichotomous query for every response checkbox. Outcomes are harder to current clearly as a result of percentages will be deceptive. The benefit of multiple-choice questions is that they supply some comparative details about the alternatives in an environment friendly approach.
4. Rating Questions — questions by which respondents are supposed to put an order on an inventory unrelated objects.
Rating questions are comparatively simple for survey individuals to grasp however rank-ordering takes extra thought than simply choosing a single response. Responses are far more troublesome to investigate and current. The benefit of rating questions is that they supply extra comparative details about the alternatives than multiple-choice questions.
5. Score Questions — questions by which respondents are purported to assign a relative rating on unrelated objects. The rating is on some sort of steady scale. Responses is perhaps written in or indicated on a slider.

Score questions are comparatively simple for survey individuals to grasp, though something requiring survey individuals to work with numbers presents a threat of failure. Responses are simple to investigate and outcomes are simple to current, although. The disadvantage of ranking questions is that they take individuals longer to reply to than Likert-scale questions.
6. Likert-scale Questions— like a single-choice query by which the alternatives signify an ordered spectrum of decisions. An odd variety of decisions permits respondents to select a middle-of-the-road place, which some survey designers keep away from as a result of it masks true preferences.

Likert-scale questions are simple for survey individuals to grasp. Responses are simple to investigate and current. The disadvantage of Likert-scale questions is that they’re much less exact than ranking questions.
7. Semantic-differential Questions — like a Likert or ranking scale query by which the alternatives signify a spectrum of preferences, attitudes, or different traits, between two extremes (e.g., agree-disagree, conservative-progressive, important-unimportant). It’s considered simpler for respondents to grasp.

Semantic-differential questions are simple for survey individuals to grasp. Responses are simple to investigate as soon as the responses are coded. Outcomes are simple to current. The disadvantage of semantic-differential questions is that they aren’t supported by some survey software program.
8. Matrix Questions — Questions that enable two facets of a subject to be assessed on the identical time. Matrix questions are very environment friendly but additionally too complicated for some respondents.

Matrix questions are very environment friendly but additionally troublesome for some survey individuals to grasp. Responses are simple to investigate and current as a result of they’re like a number of Likert-scale questions.
Points with Questions
One widespread problem with questions in political surveys is constrained lists, by which just a few of many choices are offered. Then the outcomes are offered because the solely decisions chosen by respondents. This occurs with multiple-choice, rating, and matrix questions. For instance, a survey may ask “what’s a very powerful points going through the nation?” with the solely decisions being “abortion,” “immigration,” “marriage,” and “election fraud,” after which reporting that Individuals consider abortion is a significant nationwide problem. Constrained questioning just isn’t soundly-acquired, professional survey info.
There are lots of different points that query creators have to think about.
- It’s preferable to assemble questions equally to facilitate respondent understanding.
- The kinds and complexities of the questions and the variety of decisions will affect the kind of interview and the size of the survey.
- Lengthy surveys undergo from participant drop-out. This may occasionally trigger inquiries to have totally different precisions (due to totally different pattern sizes) and even totally different demographic profiles.
- When questions aren’t answered by respondents, the lacking knowledge that have to be thought of within the evaluation. Requiring solutions just isn’t a very good resolution as a result of it could trigger some respondents to go away the survey, worsening the drop-out charge.
- If the order of the questions or the order of the alternatives for every query could also be influential, they need to be randomized.
- Some questions may have an different possibility, which is troublesome to investigate.
- Demographic questions have to be included within the survey in order that comparability to the inhabitants is feasible.
- Interviewee anonymity have to be preserved whereas nonetheless together with demographic info.
- Focus teams, pilot research, and simultaneous use of other survey varieties are generally used for evaluating survey effectiveness.
Creating survey questions just isn’t so simple as critics assume it’s.
Individuals criticize political polls on a regular basis. Some criticisms are affordable and legitimate based mostly on flawed strategies, and others are only a reflection of the ballot outcomes being totally different from what the critic believes. Critics fall on all sides of the political spectrum.
Most individuals most likely wouldn’t criticize, or for that matter, even care about political polls in the event that they didn’t have preconceived notions about what the outcomes must be. In the event that they do see a ballot that doesn’t agree with their preconceived notions, they’re fast to seek out fault. A few of their criticisms might have benefit, however normally not. Listed here are six examples.
Too Few Members
Critics of political polls can’t appear to grasp {that a} pattern of just a few hundred people will be extrapolated to the entire inhabitants of the U.S., over 300 million, if the survey body and pattern are acceptable. What the variety of survey individuals does affect is the survey precision. So, this criticism could be true if the pattern dimension have been small, say lower than 100. This may make the margin of error about ±10%, which might be pretty massive for evaluating preferences for 2 candidates. Nevertheless, most professional political polls embody at the very least 500 individuals, making the margin of error about ±4.5%. Massive political polls may embody 1,500 individuals leading to a ±2.6% margin-of-error. This criticism is sort of all the time unjustified.
They Didn’t Ask Me
If the survey body and pattern are acceptable, the demographic of the critic is already represented. This criticism is all the time unjustified.
The first political ballot dates again to the Presidential election of 1824. Chance and statistical inference for different purposes is lots of of years older than that. The science behind extrapolating from a pattern consultant of a inhabitants to the inhabitants itself is effectively established.
This criticism is in regards to the frustration a critic has when the survey outcomes don’t match their expectations. It’s a type of affirmation bias. The outcomes simply imply that the opinion of the critic doesn’t match the inhabitants.
Solely Landline Customers Have been Interviewed
This criticism has to do with how know-how impacts the collection of a body and a pattern. The problem dates again to the 1930 and Nineteen Forties when phone numbers have been used to create frames. The issue was that solely rich households owned telephones so the body wasn’t consultant of the inhabitants. Truman defeated Dewey no matter what the polls predicted.
The problem repeated within the Nineteen Nineties and 2000s when cell telephones started changing landlines. For that interval, neither mode of telephony could possibly be relied on to be consultant of the U.S. inhabitants. By the 2010s, mobile phone customers have been sufficiently consultant of the inhabitants for use as a body.
Right this moment, utilizing phone lists solely to create frames is a recognized problem. Most massive political surveys use a number of totally different sources to create frames which are consultant of the inhabitants.
They Requested the Mistaken Questions
This criticism most likely isn’t about gathering details about the unsuitable matters. It’s most likely critics pondering that the questions have been biased or deceptive in some methods. It’s most likely true that this criticism is made with out the critic really studying the questions as a result of that info is seldom obtainable in information tales. It must be uncovered within the unique survey evaluation report.
This criticism could have benefit if the ballot didn’t clearly outline phrases, or used slang or jargon. Skilled statisticians normally ask easy and truthful survey questions however could once in a while use vocabulary that’s unfamiliar to individuals.
The Outcomes Have been Predetermined
This can be a daring criticism that isn’t all that troublesome to invalidate. First, no skilled pollster is more likely to commit fraud, whatever the reward, simply because their enterprise and profession could be in jeopardy. Take a look at the supply. Whether it is any nationally recognized pollster who has been round for some time, the criticism is unlikely.
If the supply is an unknown pollster, take a look at the report on the survey strategies. They could recommend poor strategies however that wouldn’t essentially assure a specific set of outcomes. If there was an apparent bias within the strategies, like surveying attendees at a gun present, it must be obvious.
If there isn’t a background report obtainable on the survey strategies, this criticism would benefit consideration. Particularly, if the survey outcomes have been ready by a non-professional for a particular political candidate or get together, skepticism could be acceptable.
The Outcomes Are Mistaken
There are lots of issues that may go unsuitable with a survey. Criticisms {that a} political ballot is unsuitable are normally suppositions based mostly on affirmation bias. Evaluate the ballot to different polls researching the identical matters throughout the identical timeframe. If the outcomes are shut, inside the margins-of-error, the polls are most likely professional.
Criticisms based mostly on suspect survey strategies are troublesome to show. The one technique to decide {that a} political ballot was really unsuitable is to attend till after the election and conduct a autopsy.
Even when an expert pollster designs a survey, sudden outcomes can happen. This was the case within the 1948 Presidential election. Extra not too long ago, polls performed earlier than the 2016 Presidential election didn’t appropriately predict the winner. New strategies have been put in place however the polls performed earlier than the 2020 election additionally had discrepancies. What polling organizations haven’t thought of but is that the polls have been appropriate however voter suppression measures affected the outcomes. In different phrases, the polls appropriately predicted the intent of the citizens however voters couldn’t specific their preferences on election day due to administrative limitations.
Don’t get fooled into believing outcomes you agree with or disbelieving outcomes you don’t, known as affirmation bias. Don’t get distracted by the variety of respondents. It’s important to dig deeper to evaluate the legitimacy of a ballot.
You gained’t have the ability to inform from a information story if a ballot is more likely to be legitimate. It’s important to discover a hyperlink to the documentation of the unique ballot. If there may be none, search the web for the polling group, subject, and date. If there isn’t a hyperlink to the ballot, or if the hyperlink is lifeless or results in a paywall, the legitimacy of the ballot is suspect.
If you discover the ballot documentation, search for 4 issues:
- Who performed the ballot? Are they unbiased, unbiased, and respected? Strive looking the web and visiting https://tasks.fivethirtyeight.com/pollster-ratings/. A ballot performed for a candidate or a political get together just isn’t more likely to be completely professional.
- What was the development from inhabitants to border to pattern? That is very troublesome for non-statisticians to evaluate; it’s even troublesome for statisticians to work out. It’s not only a matter of polling whoever solutions a cellphone or visits a web site. Members must be weighted for inhabitants demographics and cleared from any potential biases. Briefly, if the method is complicated and described intimately, it’s extra more likely to have been legitimate than not.
- Have been the questions easy and unbiased? Was the sentence construction of the questions comprehensible? Have been any complicated or emotion-laden phrases used? Did the questions instantly handle the matters of the survey? Have been the questions offered in close-ended varieties in order that the outcomes have been unambiguous? It’s important to really see the questions documented within the survey evaluation report to inform. Additionally, verify to see how the interviews have been performed, whether or not autonomously or in individual. It most likely gained’t matter. Refined surveys may use multiple interview methodology and examine the outcomes.
- Does it discover demographics? Any professional political survey will discover the background of the respondents, issues like intercourse, age, race, get together, revenue, and training. Researchers use this info to investigate patterns in subgroups of the pattern. If the ballot doesn’t ask about that info, it’s most likely not professional.
There’ll all the time be one thing which may adversely have an effect on the validity of a ballot. Even skilled statisticians make errors or overlook minor particulars. However, these glitches will most likely be inconceivable for many readers to identify. In case you as a mean client see one thing within the inhabitants, body, pattern, or questions that’s doubtful, you could have trigger to critique. In any other case, don’t expose your ignorance by complaining about not having sufficient individuals.
Discover ways to assume critically and make it your first response to any questionable ballot chances are you’ll encounter.















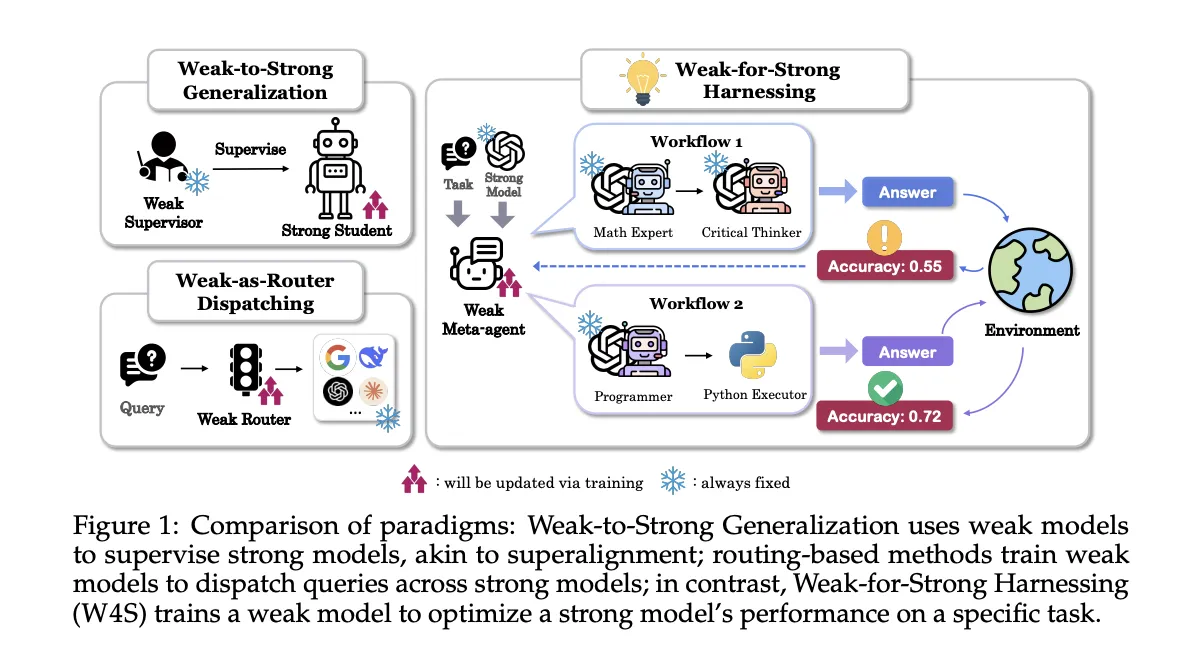
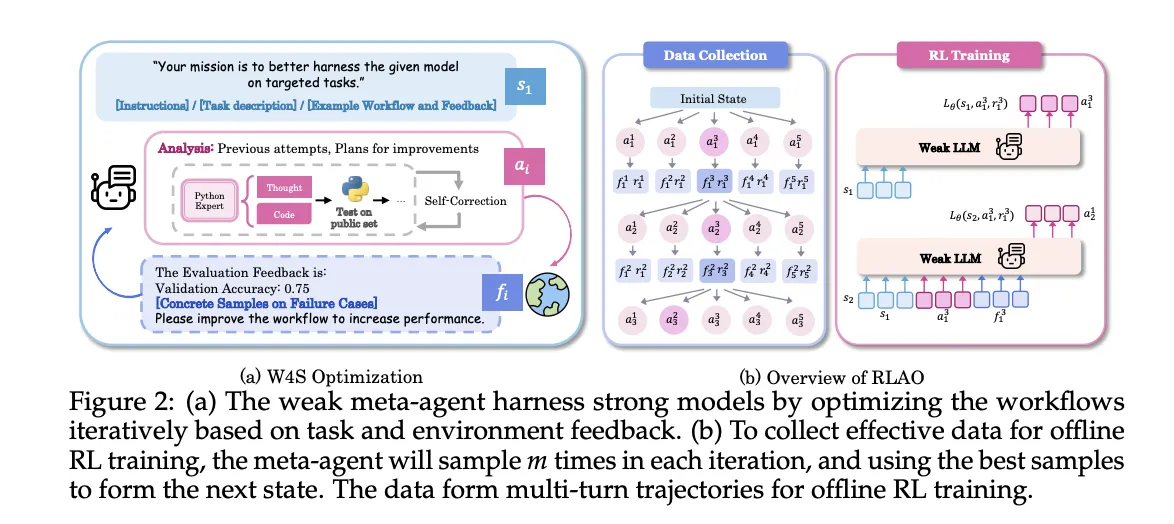
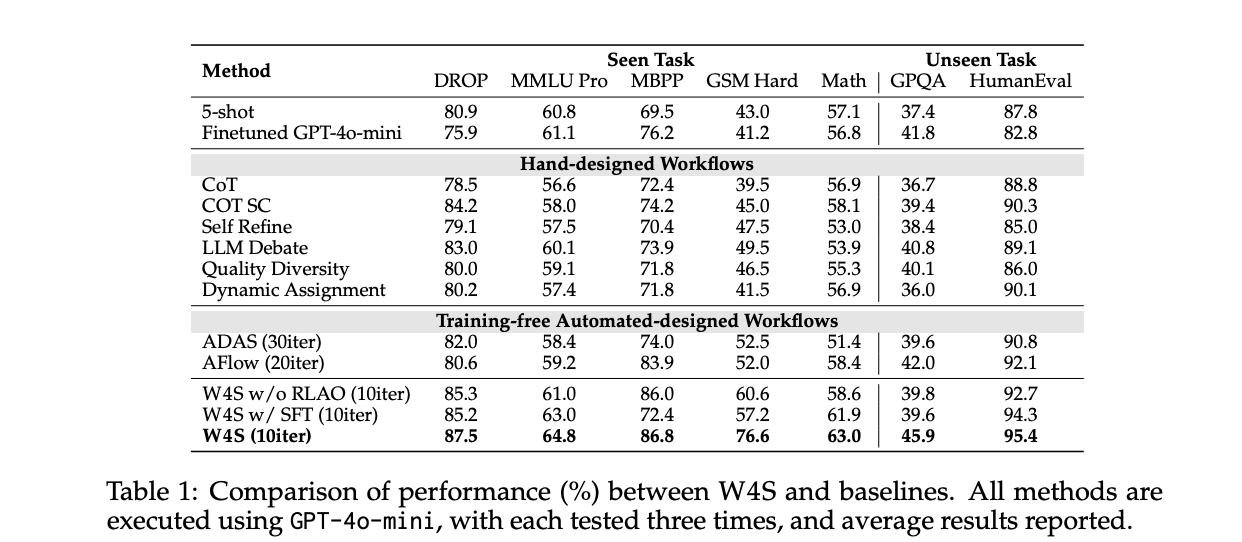
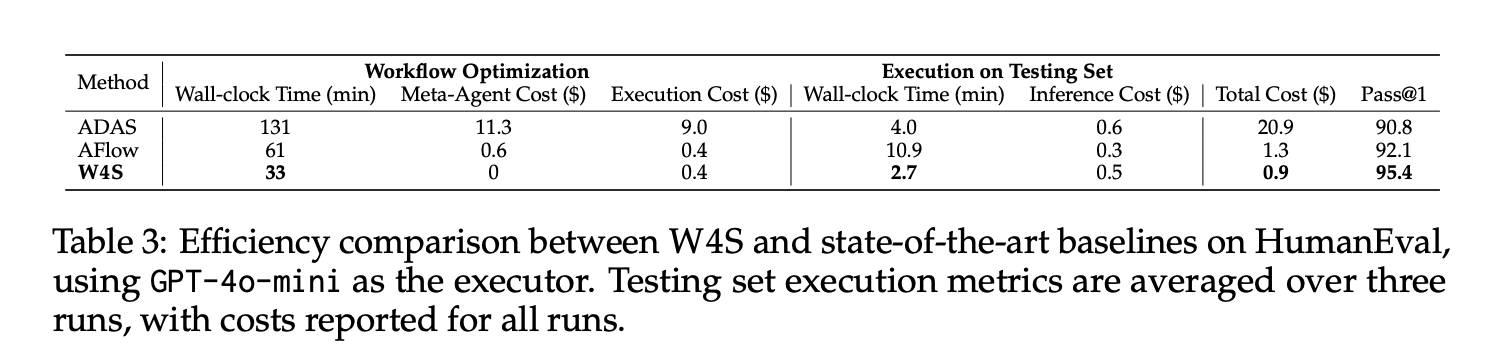
: A Novel Reinforcement Studying Algorithm that Trains a weak Meta Agent to Design Agentic Workflows with Stronger LLMs")


 is a curated listing of Psi Chi journals which can be good for Intro Stats.")
