LumberChunker lets an LLM determine the place a protracted story needs to be break up, creating extra pure chunks that assist Retrieval Augmented Era (RAG) methods retrieve the fitting info.
Introduction
Lengthy-form narrative paperwork often have an specific construction, akin to chapters or sections, however these items are sometimes too broad for retrieval duties. At a decrease degree, essential semantic shifts occur inside these bigger segments with none seen structural break. After we break up textual content solely by formatting cues, like paragraphs or mounted token home windows, passages that belong to the identical narrative unit could also be separated, whereas unrelated content material may be grouped collectively. This misalignment between construction and that means produces chunks that include incomplete or combined context, which reduces retrieval high quality and impacts downstream RAG efficiency. Because of this, segmentation ought to purpose to create chunks which can be semantically unbiased, slightly than relying solely on doc construction.
So how can we protect the story’s circulate and nonetheless maintain chunking sensible?
In lots of instances, a reader can simply acknowledge the place the narrative begins to shift—for instance, when the textual content strikes to a distinct scene, introduces a brand new entity, or modifications its goal. The issue is that the majority automated chunking strategies don’t take into account this semantic sign and as an alternative rely solely on floor construction. Because of this, they might produce segmentations that look cheap from a formatting perspective however break the underlying narrative coherence.
To make this concrete, take into account the brief passage beneath and determine the optimum chunking boundary!
LumberChunker: Phase 2 (Quiz)
1 Learn the passage
The LumberChunker Methodology
Within the instance above, Possibility C supplies probably the most coherent segmentation. The boundary aligns with the purpose the place the narrative turns into semantically unbiased from the previous context.
Our purpose is to make such a segmentation resolution sensible at scale. The problem is that human-quality boundary detection requires understanding narrative context, which is pricey to use throughout hundreds of paragraphs in long-form paperwork.
LumberChunker approaches this by treating segmentation as a boundary-finding downside: given a brief sequence of consecutive paragraphs, we ask a language mannequin to establish the earliest level the place the content material clearly shifts. This formulation permits segments to fluctuate in size whereas remaining aligned with the underlying narrative construction. In follow, LumberChunker consists of those steps:
1) Doc Paragraph Extraction
Cleanly break up the e-book into paragraphs and assign secure IDs (ID:1, ID:2, …). This preserves the doc’s pure discourse items and provides us protected candidate boundaries.
Instance: From a novel, we extract:
ID:1 “The morning solar filtered by the dusty home windows…” ID:2 “She walked slowly to the door, hesitating…” ID:3 “In the meantime, throughout city, Detective Morrison reviewed the case information…” ID:4 “The earlier evening’s occasions had left him puzzled…”
Every paragraph will get a singular ID for monitoring boundaries.
2) IDs Grouping for LLM
Construct a gaggle G_i by appending paragraphs till the group’s size reaches a token price range θ. This supplies sufficient context for the mannequin to evaluate when a subject/scene really shifts.
Instance: With θ = 550 tokens, we construct, per instance:
G_1 = [ID:1, ID:2, ID:3, ID:4, ID:5, ID:6]
This window, by spanning a number of paragraphs, will increase the prospect that a minimum of one significant narrative shift is current throughout the context.
3) LLM Question
Immediate the mannequin with the paragraphs in G_i and ask it to return the first paragraph the place content material clearly modifications relative to what got here earlier than. Use that returned ID because the chunk boundary; begin the following group at that paragraph and repeat to the tip of the e-book.
Instance: Given G_1 = [p1, p2, p3, p4, p5, p6], the LLM responds: p3
Reply Extraction: We extract p3 because the boundary. This creates:
Chunk 1: [p1, p2]
Subsequent group (G_2) begins atp3
GutenQA: A Benchmark for Lengthy-Type Narrative Retrieval
To guage our chunking method, we introduce GutenQA, a benchmark of 100 rigorously cleaned public-domain books paired with 3,000 needle-in-a-haystack sort of questions. This enables us to measure retrieval high quality immediately after which observe how higher retrieval results in extra correct solutions in a RAG system.
Key Findings
Retrieval: LumberChunker leads ⭐
LumberChunker leads throughout each DCG@okay and Recall@okay. By okay=20, it reaches DCG ≈ 62.1% and Recall ≈ 77.9%, displaying that higher segmentation improves not solely which passages seem first, but in addition how reliably the fitting context is retrieved.
LumberChunker: Phase 4 (Tables)
Retrieval Efficiency Comparability
1
2
5
10
20
Semantic Chunking
29.50
35.31
40.67
43.14
44.74
Paragraph-Stage
36.54
42.11
45.87
47.72
49.00
Recursive Chunking
39.04
45.37
50.66
53.25
54.72
HyDE†
33.47
39.74
45.06
48.14
49.92
Proposition-Stage
36.91
42.42
44.88
45.65
46.19
LumberChunker
48.28
54.86
59.37
60.99
62.09
1
2
5
10
20
Semantic Chunking
29.50
38.70
50.60
58.21
64.51
Paragraph-Stage
36.54
45.37
53.67
59.34
64.34
Recursive Chunking
39.04
49.07
60.64
68.62
74.35
HyDE†
33.47
43.41
55.11
64.61
71.61
Proposition-Stage
36.91
45.64
51.04
53.41
55.54
LumberChunker
48.28
58.71
68.58
73.58
77.92
Downstream QA: Focused Retrieval Outperforms Massive Context Home windows
We discover that even with very massive context home windows, a non-retrieval setup nonetheless performs worse than RAG, displaying that deciding on centered, related passages is simpler than merely growing the quantity of uncooked context. Underneath this setting, when built-in into a typical RAG pipeline on a GutenQA subset, our RAG-LumberChunker is second solely to RAG-Guide, which makes use of hand-segmented ground-truth chunks.
LumberChunker: Phase 4 (Bar Chart)
Downstream QA Accuracy (%)
A Candy Spot Round θ ≈ 550 Tokens
We sweep θ ∈ [450, 1000] tokens and discover that θ ≈ 550 constantly maximizes retrieval high quality: massive sufficient for context, sufficiently small to maintain the mannequin centered on the present flip within the story.
LumberChunker: Phase 5 (Theta Slider + Line Chart)
DCG@okay vs Token Price range (θ)
This doesn’t imply the ensuing chunks are massive. In follow, because the desk exhibits, the common chunk dimension is about 334 tokens, which means that LumberChunker usually detects earlier semantic shifts throughout the window.
LumberChunker: Phase 5 (Token Rely Desk)
Common variety of tokens per chunk and the whole variety of
chunks after segmenting GutenQA
Methodology
Avg. #Tokens / Chunk
Whole #Chunks
Semantic Chunking
185 tokens
191059
Paragraph Stage
79 tokens
248307
Recursive Chunking
399 tokens
31787
Proposition-Stage
12 tokens
914493
LumberChunker
334 tokens
36917
Conclusion
LumberChunker reframes doc chunking as a semantic boundary detection downside. As an alternative of counting on mounted token limits or floor construction, it makes use of a rolling context window to establish the earliest level the place the that means of the textual content turns into unbiased from what got here earlier than, producing segments that higher align with the underlying narrative construction.
On the GutenQA benchmark, LumberChunker constantly improves retrieval and downstream QA over conventional fixed-size and recursive strategies, approaching the standard of guide, human-curated segmentations.
These outcomes recommend that segmentation is not only a preprocessing step, however a core design selection for retrieval methods. By creating semantically unbiased chunks, LumberChunker supplies a sensible manner to enhance how long-form paperwork are retrieved and utilized in RAG pipelines.
Quotation
For those who discover LumberChunker helpful in your analysis, please take into account citing:
@inproceedings{duarte-etal-2024-lumberchunker,
title = "{L}umber{C}hunker: Lengthy-Type Narrative Doc Segmentation",
creator = "Duarte, Andr{'e} V. and Marques, Jo{~a}o DS and Gra{c{c}}a, Miguel and Freire, Miguel and Li, Lei and Oliveira, Arlindo L.",
editor = "Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung",
booktitle = "Findings of the Affiliation for Computational Linguistics: EMNLP 2024",
month = nov,
12 months = "2024",
deal with = "Miami, Florida, USA",
writer = "Affiliation for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-emnlp.377/",
doi = "10.18653/v1/2024.findings-emnlp.377",
pages = "6473--6486",
summary = "LumberChunker reframes doc chunking as a semantic boundary detection downside..."
}
DataRobot and Nebius have partnered to introduce AI Manufacturing unit for Enterprises, a joint resolution designed to speed up the event, operation, and governance of AI brokers. This platform permits brokers to succeed in manufacturing in days, moderately than months.
AI Manufacturing unit for Enterprises supplies a scalable, cost-effective, ruled, and managed enterprise-grade platform for brokers. It achieves this by combining DataRobot’s Agent Workforce Platform: essentially the most complete, versatile, safe, and enterprise-ready agent lifecycle administration platform, with Nebius’ purpose-built cloud infrastructure for AI.
Our partnership
Nebius: The aim-built cloud for AI
The problem right this moment is that general-purpose cloud platforms typically introduce unpredictable efficiency, latency, and a “virtualization tax” that cripples steady, production-scale AI.
To resolve this, DataRobot is leveraging Nebius AI Cloud, a GPU cloud platform engineered from the {hardware} layer up particularly to ship the bare-metal efficiency, low latency, and predictable throughput important for sustained AI coaching and inference. This eliminates the “noisy-neighbor” downside and ensures your most demanding agent workloads run reliably, delivering predictable outcomes and clear prices.
Nebius’ Token Manufacturing unit augments the providing by offering a pay-per-token mannequin entry layer for key open-source fashions, which prospects can use throughout agent constructing and experimentation, after which deploy the identical fashions with DataRobot when working the brokers in manufacturing.
DataRobot: Seamlessly construct, function, and govern brokers at scale
DataRobot’s Agent Workforce Platform is essentially the most complete Agent Lifecycle Administration platform that permits prospects to construct, function, and govern their brokers seamlessly.
The platform affords two main parts:
An enterprise-grade, scalable, dependable, and cost-effective runtime for fashions and brokers, that includes out-of-the-box governance and monitoring.
A simple-to-use agent builder setting that permits prospects to seamlessly construct production-ready brokers in hours, moderately than days or months.
Complete enterprise-grade runtime capabilities
Scalable, cost-effective runtime: Options single-click deployment of fifty+ NIMs and Hugging Face fashions with autoscaling or deploy any containerized artifacts through Workload API (each with inbuilt monitoring/governance), optimized utilization by endpoint degree multi-tenancy (token quota), and high-availability inferencing. You possibly can deploy containerized brokers, functions or different composite methods constructed utilizing a mixture of say LLMs, area particular libraries like PhysicsNemo, cuOpt and so forth., or your individual proprietary fashions, with a single command utilizing Workload API.
Governance and monitoring: Offers the {industry}’s most complete out-of-the-box metrics (behavioral and operational), tracing capabilities for agent execution paths, full lineage/versioning with audit logging, and industry-leading governance in opposition to Safety, Operational, and Compliance Dangers with real-time intervention and automatic reporting.
Safety and id: Consists of Unified Identification and Entry Administration with OAuth 2.0, granular RBAC for least-privilege entry throughout sources, and safe secret administration with an encrypted vault.
Builder instruments: Assist for well-liked frameworks (Langchain, Crew AI, Llamaindex, Nvidia NeMo Agent Toolkit) and out-of-the-box help for MCP, authentication, managed RAG, and knowledge connectors. Nebius token manufacturing unit integration allows on-demand mannequin use through the construct.
Analysis & tracing: Trade-leading analysis with LLM as a Decide, Human-in-the-Loop, Playground/API, and agent tracing. Presents complete behavioral (e.g., activity adherence) and operational (latency, value) metrics, plus customized metric help.
Out-of-the field manufacturing readiness: Enterprise hooks summary away infrastructure, safety, authentication, and knowledge complexity. Brokers deploy with a single command; DataRobot handles element deployment with embedded monitoring and governance at each the total agent and particular person element/software ranges.
Construct and deploy utilizing the AI Manufacturing unit for Enterprises
Wish to take brokers you might have constructed elsewhere, and even open supply {industry} particular fashions and deploy them in a scalable, safe and ruled method utilizing the AI Manufacturing unit? Or would you wish to construct brokers with out worrying concerning the heavy lifting of creating them manufacturing prepared? This part will present you the way to do each.
1. DataRobot STS on Nebius
DataRobot Single-Tenant SaaS (STS) is deployed on Nebius Managed Kubernetes and will be backed by GPU-enabled node teams, high-performance networking, and storage choices applicable for AI workloads.For DataRobot deployments, Nebius is a high-performance low value setting for agent workloads. Devoted NVIDIA clusters (H100, H200, B200, B300, GB200 NVL72, GB300 NVL72) allow environment friendly tensor parallelism and KV-cache-heavy serving patterns, whereas InfiniBand RDMA helps high-throughput cross-node scaling. The DataRobot/Nebius partnership supplies a sturdy AI infrastructure:
Managed kubernetes with GPU-aware scheduling simplifies STS set up and upgrades, pre-configured with NVIDIA operators.
Devoted GPU employee swimming pools (H100, B200, and so forth.) isolate demanding STS providers (LLM inference, vector databases) from generic CPU-only workloads.
Excessive-throughput networking and storage help massive mannequin artifacts, embeddings, and telemetry for steady analysis and logging.
Safety and tenancy is maintained: STS makes use of devoted tenant boundaries, whereas Nebius IAM and community insurance policies meet enterprise necessities.
Constructed-in node well being monitoring proactively identifies and addresses GPU/community points for secure clusters and smarter upkeep.
The problem with GenAI isn’t getting a mannequin working; it’s getting it working with the identical monitoring, governance, and safety your group expects. DataRobot’s NVIDIA NIM integration deploys NIM containers from NGC onto Nebius GPUs in 4 clicks:
In Registry > Fashions, click on Import from NVIDIA NGC and browse the NIM gallery.
Choose the mannequin, assessment the NGC mannequin card, and select a efficiency profile.
Overview the GPU useful resource bundle robotically really useful based mostly on the NIM’s necessities.
Click on Deploy, choose the Serverless setting, and deploy the mannequin.
Out-of-the-box observability and governance for deployed fashions
Automated monitoring & threat evaluation: Leverage the NeMo Evaluator integration for mannequin faithfulness, groundness, and relevance scoring. Robotically scan for Bias, PII, and Immediate Injection dangers.
Actual-time moderation & deep observability: DataRobot affords a platform for NIM moderation and monitoring. Deploy out-of-the-box guards for dangers like PII, Immediate Injection, Toxicity, and Content material Security. OTel-compliant monitoring supplies visibility into NIM operational well being, high quality, security, and useful resource use.
Enterprise governance & compliance: DataRobot supplies the executive layer for secure, organization-wide scaling. It robotically compiles monitoring and analysis knowledge into compliance documentation, mapping efficiency to regulatory requirements for audits and reporting.
3. Agent deployment utilizing the Workload API
An MCP software server, a LangGraph agent, a FastAPI backend, composite methods constructed utilizing mixture of say LLMs and area particular libraries like cuOpt, PhysicsNemo and so forth; these are containers, not fashions, they usually want their very own path to manufacturing. The Workload API provides you a ruled endpoint with autoscaling, monitoring, and RBAC in a single API name.
The agent is instantly accessible at /endpoints/workloads/{id}/ with monitoring, RBAC, audit trails, and autoscaling.
Out-of-the-box observability and governance for deployed agentic workloads
DataRobot drives the AI Manufacturing unit by offering strong governance and observability for agentic workloads:
Observability (OTel Normal): DataRobot standardizes on OpenTelemetry (OTel): logs, metrics, and traces—to make sure constant, high-fidelity telemetry for all deployed entities. This telemetry seamlessly integrates with present enterprise observability stacks, permitting customers to watch crucial dimensions, together with:
Agent-specific metrics: Akin to Agent Job Adherence and Agent Job Accuracy.
Operational well being and useful resource utilization.
Tracing and Logging: OTel-compliant tracing interweaves container-level logs with execution spans to simplify root trigger evaluation inside advanced logic loops.
Governance and Entry Management: DataRobot enforces enterprise-wide authentication and authorization protocols throughout deployed brokers utilizing OAuth-based entry management mixed with Position-Based mostly Entry Management (RBAC).
Superior requirements: Expertise, MCP (Mannequin Context Protocol) for knowledge/software interplay, and strong Immediate Administration for versioning/optimization.
The Nebius benefit: DataRobot’s Agent Workforce Platform integrates with the Nebius Token Manufacturing unit, permitting builders to eat fashions like Nemotron 3 (and any open supply mannequin) on a pay-per-token foundation through the experimental part. This permits fast, low-cost iteration with out heavy infrastructure provisioning. As soon as perfected, brokers can seamlessly transition from the Token Manufacturing unit to a devoted deployment (e.g., NVIDIA NIM) for enterprise scale and low latency.
Getting Began: Constructing is straightforward utilizing our Node Structure Tooling (NAT). You outline agent nodes as structured, testable steps in YAML.
First, join your deployed LLM within the Nebius token elements to DataRobot
features:
planner:
_type: chat_completion
llm_name: datarobot_llm
system_prompt: |
You're a content material planner. You create temporary, structured outlines for weblog articles.
You determine crucial factors and cite related sources. Hold it easy and to the purpose -
that is simply a top level view for the author.
Create a easy define with:
1. 10-15 key factors or details (bullet factors solely, no paragraphs)
2. 2-3 related sources or references
3. A short recommended construction (intro, 2-3 sections, conclusion)
Do NOT write paragraphs or detailed explanations. Simply present a centered checklist.
author:
_type: chat_completion
llm_name: datarobot_llm
system_prompt: |
You're a content material author working with a planner colleague.
You write opinion items based mostly on the planner's define and context. You present goal and
neutral insights backed by the planner's data. You acknowledge when your statements are
opinions versus goal details.
1. Use the content material plan to craft a compelling weblog put up.
2. Construction with a fascinating introduction, insightful physique, and summarizing conclusion.
3. Sections/Subtitles are correctly named in a fascinating method.
4. CRITICAL: Hold the whole output underneath 500 phrases. Every part ought to have 1-2 temporary paragraphs.
Write in markdown format, prepared for publication.
content_writer_pipeline:
_type: sequential_executor
tool_list: [planner, writer]
description: A software that plans and writes content material on the requested subject.
function_groups:
mcp_tools:
_type: datarobot_mcp_client
authentication:
datarobot_mcp_auth:
_type: datarobot_mcp_auth
llms:
datarobot_llm:
_type: datarobot-llm-component
workflow:
_type: tool_calling_agent
llm_name: datarobot_llm
tool_names:
- content_writer_pipeline
- mcp_tools
return_direct:
- content_writer_pipeline
system_prompt:
Select and name a software to reply the question.
Analysis capabilities: The “how-to”
Constructing is simply half the battle; figuring out if it really works is the opposite. Our analysis framework strikes past easy “thumbs up/down” and into data-driven validation.
To judge your agent, you may:
Outline a check suite: Add a “golden dataset” of anticipated queries and ground-truth solutions.
Automated metrics: Run your agent in opposition to built-in evaluators for faithfulness, relevance, and toxicity.
LLM-as-a-Decide: Use a “critic” mannequin to attain agent responses based mostly on customized rubrics (e.g., “Did the agent comply with the model’s tone of voice?”).
Facet-by-side comparability: Run two variations of your agent (e.g., one utilizing NAT and one utilizing LangChain) in opposition to the identical dataset to match value, latency, and accuracy in a single dashboard.
Enterprise hooks: Deployment-ready from day one
We automate the “enterprise tax” (safety, logging, auth) that separates notebooks from manufacturing providers by embedding construct “hooks”:
Observability: Automated OTel-compliant tracing captures each step with out boilerplate.
Identification & auth: Constructed-in OAuth 2.0 and Service Accounts guarantee brokers use the person’s precise permissions when calling inside APIs (CRM, ERP), sustaining strict safety.
Manufacturing hand-off: Deployment packages the setting, parts, and auth hooks right into a safe, ruled container, making certain a constant agent from dev to manufacturing. Advanced brokers are autoparsed into orchestrated containers for granular monitoring whereas deployed as a single pipeline entity.
Ruled, scalable inference
The DataRobot and Nebius partnership delivers a validated, enterprise-ready deployment stack for agentic AI constructed on NVIDIA accelerated computing. For groups shifting past experimentation, it supplies a ruled and scalable path to sustained manufacturing inference.
Nebius and DataRobot might be showcasing this resolution at NVIDIA GTC 2026, happening March 16-19 in San Jose, California.
Sony PlayStation 4 emulator ShadPS4 has reached v0.15.0, and the developer suggests customers persist with it, as the following launch will introduce breaking modifications.
The variety of playable video games on shadPS4 has jumped from 33 to 109 in only a yr, with Home windows and Linux seeing essentially the most progress.
Model 0.15.0 delivers rendering and stability fixes that enhance the efficiency on video games like Bloodborne, Driveclub, and The Final Guardian.
shadPS4 is presently some of the vital PlayStation 4 emulators available on the market, primarily as a result of it has achieved main technical breakthroughs that had been beforehand deemed tough and a few years away. We’ve been monitoring shadPS4’s progress over the months, and it’s been spectacular how a lot the emulator has grown. The newest shadPS4 v0.15.0 replace has simply been launched and contains numerous fixes that affect video games like The Final Guardian, Driveclub, and others.
Don’t need to miss the very best from Android Authority?
shadPS4’s v0.15.0 launch could be thought-about a milestone, because the developer suggests customers keep it up for some time since v0.15.1 will introduce breaking modifications. The discharge notes are fairly technical, however notable modifications embrace lacking hotkeys now being mechanically added to the worldwide enter config, and sign emulation has been improved.
shadPS4’s compatibility web page now lists a very good 109 video games as playable (by means of numerous releases over the months), an enormous soar from the 33 we noticed final yr. One other 181 land into the sport, up from the 81 final yr. The state of affairs has additionally massively improved on Linux, with 119 video games playable, whereas macOS remains to be pretty behind with 11. The standing of an Android port is presently unknown.
As for video games, Bloodborne is taken into account the gold normal for this emulator, as it’s stated to be extremely playable at 60 fps on higher-end {hardware} like an RTX 4060 with mods.
v0.15.0 improves readback dealing with, which fixes a number of visible bugs on this sport, and in addition improves sport mechanics in The Final Guardian. This launch additionally improves coloration grading and rendering stability for Driveclub. Lara Croft and the Temple of Osiris has additionally reached playable standing on Home windows with this replace.
Do word that enabling “Exact” in “Readback Mode” will repair graphical bugs at the price of efficiency, whereas “Relaxed” would provide you with higher efficiency however could trigger flickering or lacking textures. Additional, emulating the PS4’s GPU is CPU-intensive, so that you’ll need high-end laptop {hardware} for a playable expertise, and it is best to nonetheless count on bugs and glitches. Nonetheless, the progress right here stays commendable.
Thanks for being a part of our neighborhood. Learn our Remark Coverage earlier than posting.
A “probably hazardous” asteroid accommodates all the “letters” that make up DNA, suggesting that these key components for all times could also be frequent within the photo voltaic system.
Researchers made the invention after analyzing samples collected from asteroid Ryugu, a 3,000-foot-wide (900 meters) area rock formed like a spinning high.
The scientists detected a whole set of canonical nucleobases, that are the constructing blocks for DNA — the genetic basis for all life on Earth — and its lesser-known cousin RNA, in keeping with a brand new examine revealed Monday (March 16) within the journal Nature Astronomy.
Article continues under
This “doesn’t imply that life existed on Ryugu,” examine lead creator Toshiki Koga, a biogeochemist on the Japan Company for Marine-Earth Science and Expertise, advised AFP, per Phys.org. “As an alternative, their presence signifies that primitive asteroids might produce and protect molecules which are essential for the chemistry associated to the origin of life.”
This is not the primary time an asteroid has been discovered to be carrying all 5 nucleobases. NASA recovered the identical set of nucleobases from asteroid Bennu in 2023, courtesy of the OSIRIS-REx spacecraft. Researchers have additionally detected the nucleobases on meteorites. Taken collectively, these findings recommend that nucleobases may very well be widespread within the photo voltaic system.
Cosmic origins of life?
Scientists aren’t certain how life received began on Earth. Some theories posit that it originated right here, comparable to in deep-sea vents. Nevertheless, there’s additionally a chance that life — or the constructing blocks of life — did not kind on Earth in any respect however have been carried right here on comets or asteroids.
César Menor Salván, an astrobiologist on the College of Alcalá in Spain who was not concerned within the examine, emphasised in an interview with AFP that the brand new outcomes “don’t recommend that the origin of life came about in area.”
Get the world’s most fascinating discoveries delivered straight to your inbox.
Nevertheless, “with this and the outcomes from Bennu, now we have a really clear thought of which natural supplies can kind below prebiotic situations wherever within the universe,” Salván added.
The Japan Aerospace Exploration Company (JAXA) collected the Ryugu samples as a part of its Hayabusa2 mission, which launched in 2014. The uncrewed Hayabusa2 spacecraft landed on the asteroid in 2019, earlier than accumulating two mud samples from the asteroid’s floor and returning them to Earth in 2020.
The samples weigh simply 5.4 grams (0.19 ounces) every, lower than the burden of 1 / 4, however have excited scientists for years. Preliminary evaluation of a tiny fraction of the sampled materials in 2023 revealed that the asteroid contained most of the constructing blocks for all times, together with one nucleobase (uracil) and quite a few different natural supplies, together with 15 amino acids, that are the inspiration of proteins. These are prebiotic molecules, and though they are not life, they’re present in all life.
One examine additionally revealed microorganisms crawling throughout one asteroid Ryugu pattern. However these microorganisms carefully matched Earth’s micro organism, and their presence was virtually definitely the results of contamination after the pattern returned to Earth. (Even NASA has had bother maintaining Earth micro organism off its interplanetary spacecraft in ostensibly sterile rooms).
The Japan Aerospace Exploration Company (JAXA) collected samples from Ryugu by touchdown a spacecraft on the asteroid. (Picture credit score: (left) JAXA, College of Tokyo, Kochi College, Rikkyo College, Nagoya College, Chiba Institute of Expertise, Meiji College, College of Aizu, AIST. (proper) MASCOT/DLR/JAXA)
The closest look but
For the brand new examine, researchers did a way more complete evaluation of nucleobases than was executed throughout the preliminary analysis, utilizing extra pattern materials and optimized analytical methods.
This time, the researchers discovered all the nucleobases — adenine, guanine, cytosine, thymine and uracil. These pure compounds combine with ribose and phosphate to kind DNA and RNA. The researchers additionally regarded on the ratio of nucleobases and in contrast them to these found on Bennu and on two meteorites (Murchison and Orgueil) that had fallen to Earth.
Nucleobases are cut up into two teams primarily based on their chemical construction. Adenine and guanine are purines, that are identified for his or her double-ring construction, whereas cytosine, thymine and uracil belong to the single-ring-structured pyrimidines.
The researchers discovered that Ryugu had equal quantities of purines and pyrimidines, whereas Bennu and Orgueil have been extra enriched in pyrimidines and Murchison was extra enriched in purines. Notably, the researchers additionally recognized a powerful correlation between the purine-pyrimidine ratio and the concentrations of ammonia in Ryugu, Bennu and Orgueil, suggesting that ammonia, one other life-friendly molecule, might have been a key issue driving comparable nucleobase formation pathways within the rocks’ distinct environments, in keeping with the examine.
“As a result of no identified formation mechanism predicts such a relationship, this discovering might level to a beforehand unrecognized pathway for nucleobase formation in early photo voltaic system supplies,” Koga stated.
Ryugu and Bennu are a standard sort of asteroid often known as carbonaceous asteroids, which make up 75% of all asteroids in our photo voltaic system. James Webb Area Telescope (JWST) observations recommend that each asteroids might originate from the identical father or mother asteroid that broke aside billions of years in the past. The Orgueil meteorite additionally derived from a carbonaceous asteroid.
These historic rocks are left over from when the photo voltaic system was nonetheless forming round 4.5 billion years in the past, when the Earth was additionally forming. The detection of nucleobases, due to this fact, means that carbonaceous asteroids might have helped Earth get its life-forming chemical substances.
“The detection of numerous nucleobases in asteroid and meteorite supplies demonstrates their widespread presence all through the Photo voltaic System and reinforces the speculation that carbonaceous asteroids contributed to the prebiotic chemical stock of early Earth,” the researchers wrote within the examine.
With a big selection of Nova customization choices, the journey to customization and transitioning between platforms has historically been intricate, necessitating technical experience, infrastructure setup, and appreciable time funding. This disconnect between potential and sensible functions is exactly what we aimed to handle. Nova Forge SDK makes massive language mannequin (LLM) customization accessible, empowering groups to harness the complete potential of language fashions with out the challenges of dependency administration, picture choice, and recipe configuration. We view customization as a continuum throughout the scaling ladder, subsequently, the Nova Forge SDK helps all customization choices, starting from variations based mostly on Amazon SageMaker AI to deep customization utilizing Amazon Nova Forge capabilities.
Within the final publish, we launched the Nova Forge SDK and how you can get began with it together with the conditions and setup directions. On this publish, we stroll you thru the method of utilizing the Nova Forge SDK to coach an Amazon Nova mannequin utilizing Amazon SageMaker AI Coaching Jobs. We consider our mannequin’s baseline efficiency on a StackOverFlow dataset, use Supervised High quality-Tuning (SFT) to refine its efficiency, after which apply Reinforcement High quality Tuning (RFT) on the custom-made mannequin to additional enhance response high quality. After every sort of fine-tuning, we consider the mannequin to point out its enchancment throughout the customization course of. Lastly, we deploy the custom-made mannequin to an Amazon SageMaker AI Inference endpoint.
Subsequent, let’s perceive the advantages of Nova Forge SDK by going by means of a real-world state of affairs of computerized classification of Stack Overflow questions into three well-defined classes (HQ, LQ EDIT, LQ CLOSE).
Case research: classify the given query into the right class
Stack Overflow has 1000’s of questions, various enormously in high quality. Routinely classifying query high quality helps moderators prioritize their efforts and information customers to enhance their posts. This resolution demonstrates how you can use the Amazon Nova Forge SDK to construct an automatic high quality classifier that may distinguish between high-quality posts, low-quality posts requiring edits, and posts that ought to be closed. We use the Stack Overflow Query High quality dataset containing 60,000 questions from 2016-2020, categorized into three classes:
HQ (Excessive High quality): Effectively-written posts with out edits
LQ_EDIT (Low High quality – Edited): Posts with destructive scores and a number of group edits, however stay open
LQ_CLOSE (Low High quality – Closed): Posts closed by the group with out edits
For our experiments, we randomly sampled 4700 questions and cut up them as follows:
Break up
Samples
Share
Objective
Coaching (SFT)
3,500
~75%
Supervised fine-tuning
Analysis
500
~10%
Baseline and post-training analysis
RFT
700 + (3,500 from SFT)
~15%
Reinforcement fine-tuning
For RFT, we augmented the 700 RFT-specific samples with all 3,500 SFT samples (whole: 4,200 samples) to stop catastrophic forgetting of supervised capabilities whereas studying from reinforcement indicators.
The experiment consists of 4 most important phases: baseline analysis to measure out-of-the-box efficiency, supervised fine-tuning (SFT) to show domain-specific patterns, and reinforcement fine-tuning (RFT) on SFT checkpoint to optimize for particular high quality metrics and eventually deployment to Amazon SageMaker AI. For fine-tuning, every stage builds upon the earlier one, with measurable enhancements at each step.
We used a standard system immediate for all of the datasets:
This can be a stack overflow query from 2016-2020 and it may be categorized into three classes:
* HQ: Excessive-quality posts with no single edit.
* LQ_EDIT: Low-quality posts with a destructive rating, and a number of group edits. Nevertheless, they continue to be open after these modifications.
* LQ_CLOSE: Low-quality posts that had been closed by the group with no single edit.
You're a technical assistant who will classify the query from customers into any of above three classes. Reply with solely the class identify: HQ, LQ_EDIT, or LQ_CLOSE.
**Don't add any clarification, simply give the class as output**.
Stage 1: Set up baseline efficiency
Earlier than fine-tuning, we set up a baseline by evaluating the pre-trained Nova 2.0 mannequin on our analysis set. This offers us a concrete baseline for measuring future enhancements. Baseline analysis is vital as a result of it helps you perceive the mannequin’s out-of-the-box capabilities, determine efficiency gaps, set measurable enchancment targets, and validate that fine-tuning is critical.
Set up the SDK
You’ll be able to set up the SDK with a easy pip command:
The Amazon Nova Forge SDK gives highly effective knowledge loading utilities that deal with validation and transformation routinely. We start by loading our analysis dataset and remodeling it to the format anticipated by Nova fashions:
The CSVDatasetLoader class handles the heavy lifting of information validation and format conversion. The question parameter maps to your enter textual content (the Stack Overflow query), response maps to the bottom reality label, and system accommodates the classification directions that information the mannequin’s habits.
# Normal Configuration
MODEL = Mannequin.NOVA_LITE_2
INSTANCE_TYPE = 'ml.p5.48xlarge'
EXECUTION_ROLE = ''
TRAIN_INSTANCE_COUNT = 4
EVAL_INSTANCE_COUNT = 1
S3_BUCKET = ''
S3_PREFIX = 'stack-overflow'
EVAL_DATA = './eval.csv'
# Load knowledge# Word: 'question' maps to the query, 'response' to the classification label
loader = CSVDatasetLoader(
question='Physique', # Query textual content column
response="Y", # Classification label column (HQ, LQ_EDIT, LQ_CLOSE)
system='system' # System immediate column
)
loader.load(EVAL_DATA)
Subsequent, we use the CSVDatasetLoader to rework your uncooked knowledge into the anticipated format for Nova mannequin analysis:
# Rework to Nova format
loader.rework(methodology=TrainingMethod.EVALUATION, mannequin=MODEL)
loader.present(n=3)
The remodeled knowledge could have the next format:
Earlier than importing to Amazon Easy Storage Service (Amazon S3), validate the remodeled knowledge by operating the loader.validate() methodology. This lets you catch any formatting points early, relatively than ready till they interrupt the precise analysis.
# Validate knowledge format
loader.validate(methodology=TrainingMethod.EVALUATION, mannequin=MODEL)
Lastly, we are able to save the dataset to Amazon S3 utilizing the loader.save_data() methodology, in order that it may be utilized by the analysis job.
# Save to S3
eval_s3_uri = loader.save_data(
f"s3://{S3_BUCKET}/{S3_PREFIX}/knowledge/eval.jsonl"
)
Run baseline analysis
With our knowledge ready, we initialize our SMTJRuntimeManager to configure the runtime infrastructure. We then initialize a NovaModelCustomizer object and name baseline_customizer.consider() to launch the baseline analysis job:
# Configure runtime infrastructure
runtime_manager = SMTJRuntimeManager(
instance_type=INSTANCE_TYPE,
instance_count=EVAL_INSTANCE_COUNT,
execution_role=EXECUTION_ROLE
)
# Create baseline evaluator
baseline_customizer = NovaModelCustomizer(
mannequin=MODEL,
methodology=TrainingMethod.EVALUATION,
infra=runtime_manager,
data_s3_path=eval_s3_uri,
output_s3_path=f"s3://{S3_BUCKET}/{S3_PREFIX}/baseline-eval"
)
# Run analysis# GEN_QA process gives metrics like ROUGE, BLEU, F1, and Precise Match
baseline_result = baseline_customizer.consider(
job_name="blogpost-baseline",
eval_task=EvaluationTask.GEN_QA # Use GEN_QA for classification
)
For classification duties, we use the GEN_QA analysis process, which treats classification as a generative process the place the mannequin generates a category label. The exact_match metric from GEN_QA immediately corresponds to classification accuracy, the share of predictions that precisely match the bottom reality label. The complete listing of benchmark duties may be retrieved from the EvaluationTask enum, or seen within the Amazon Nova Person Information.
Understanding the baseline outcomes
After the job completes, outcomes are saved to Amazon S3 on the specified output path. The archive accommodates per-sample predictions with log possibilities, aggregated metrics throughout the complete analysis set, and uncooked mannequin predictions for detailed evaluation.
Within the following desk, we see the aggregated metrics for all of the analysis samples from the output of the analysis job (word that BLEU is on a scale of 0-100):
Metric
Rating
ROUGE-1
0.1580 (±0.0148)
ROUGE-2
0.0269 (±0.0066)
ROUGE-L
0.1580 (±0.0148)
Precise Match (EM)
0.1300 (±0.0151)
Quasi-EM (QEM)
0.1300 (±0.0151)
F1 Rating
0.1380 (±0.0149)
F1 Rating (Quasi)
0.1455 (±0.0148)
BLEU
0.4504 (±0.0209)
The bottom mannequin achieves solely 13.0% exact-match accuracy on this 3-class classification process, whereas random guessing would yield 33.3%. This clearly demonstrates the necessity for fine-tuning and establishes a quantitative baseline for measuring enchancment.
As we see within the subsequent part, that is largely as a result of mannequin ignoring the formatting necessities of the issue, the place a verbose response together with explanations and analyses is taken into account invalid. We will derive the format-independent classification accuracy by parsing our three labels from the mannequin’s output textual content, utilizing the next classification_accuracy utility perform.
def classification_accuracy(samples):
"""Extract predicted class by way of substring match and compute accuracy."""
right, whole, no_pred = 0, 0, 0
for s in samples:
gold = s["gold"].strip().higher()
pred_raw = s["inference"][0] if isinstance(s["inference"], listing) else s["inference"]
pred_cat = extract_category(pred_raw)
if pred_cat is None:
no_pred += 1
proceed
whole += 1
if pred_cat == gold:
right += 1
acc = right / whole if whole else 0
print(f"Classification Accuracy: {right}/{whole} ({acc*100:.1f}%)")
print(f" No legitimate prediction: {no_pred}/{whole + no_pred}")
return acc
print("???? Baseline Classification Accuracy (extracted class labels):")
baseline_accuracy = classification_accuracy(baseline_samples)
Nevertheless, even with a permissive metric, which ignores verbosity, we get solely a 52.2% classification accuracy. This clearly signifies the necessity for fine-tuning to enhance the efficiency of the bottom mannequin.
Conduct baseline failure evaluation
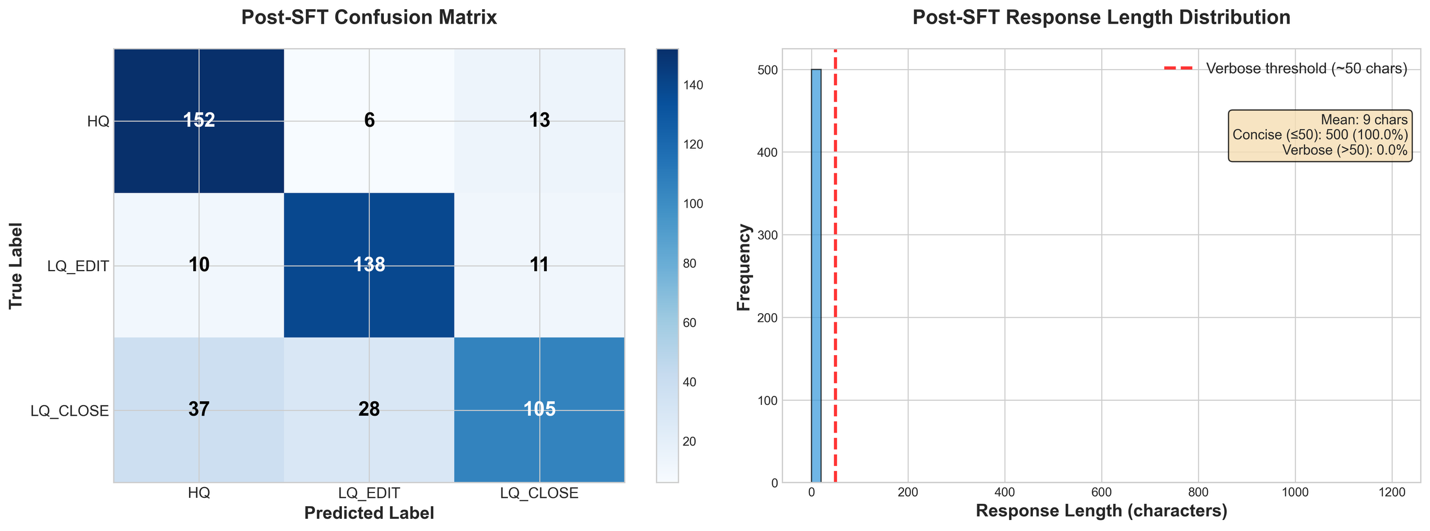
The next picture exhibits a failure evaluation on the baseline. From the response size distribution, we observe that each one responses included verbose explanations and reasoning regardless of the system immediate requesting solely the class identify. As well as, the baseline confusion matrix compares the true label (y axis) with the generated label (x axis); the LLM has a transparent bias in direction of classifying messages as Excessive High quality no matter their precise classification.
Given these baseline outcomes of each instruction-following failures and classification bias towards HQ, we now apply Supervised High quality-Tuning (SFT) to assist the mannequin perceive the duty construction and output format, adopted by Reinforcement Studying (RL) with a reward perform that penalizes the undesirable behaviors.
Stage 2: Supervised fine-tuning
Now that we’ve got accomplished our baseline and performed the failure area evaluation, we are able to use Supervised High quality Tuning to enhance our efficiency. For this instance, we use a Parameter Environment friendly High quality-Tuning method, as a result of it’s a way that offers us preliminary indicators on fashions studying functionality.
Knowledge preparation for supervised fine-tuning
With the Nova Forge SDK, we are able to convey our datasets and use the SDKs knowledge preparation helper features to curate the SFT datasets with in-build knowledge validations.
As earlier than, we use the SDK’s CSVDatasetLoader to load our coaching CSV knowledge and rework it into the required format:
Now that we’ve got our knowledge well-formed and within the right format, we are able to cut up it into coaching, validation, and take a look at knowledge, and add all three to Amazon S3 for our coaching jobs to reference.
# Save to S3
train_path = loader.save_data(f"s3://{S3_BUCKET}/{S3_PREFIX}/knowledge/prepare.jsonl")
Begin a supervised fine-tuning job
With our knowledge ready and uploaded to Amazon S3, we provoke the Supervised High quality-tuning (SFT) job.
The Nova Forge SDK streamlines the method by serving to us to specify the infrastructure for coaching, whether or not it’s Amazon SageMaker Coaching Jobs or Amazon SageMaker Hyperpod. It additionally provisions the required situations and facilitates the launch of coaching jobs, eradicating the necessity to fear about recipe configurations or API codecs.
For our SFT coaching, we proceed to make use of Amazon SageMaker Coaching Jobs, with 4 ml.p5.48xlarge situations. The SDK validates your surroundings and occasion configuration towards supported values for the chosen mannequin when making an attempt to begin a coaching job, stopping errors from occurring after the job is submitted.
Subsequent, we arrange the configuration for the coaching itself and run the job. You should use the overrides parameter to switch coaching configurations from their default values for higher efficiency. Right here, we set the max_steps to a comparatively small quantity to maintain the length of this take a look at low.
You should use the Nova Forge SDK to run coaching jobs in dry_run mode. This mode runs all of the validations that the SDK would execute, whereas really operating a job, however doesn’t begin the execution if all validations fail. This lets you know prematurely whether or not a coaching setup is legitimate earlier than making an attempt to make use of it, for example when producing configs routinely or exploring potential settings:
To save lots of the info for a job that you just created, you’ll be able to serialize your outcome object to a JSON file, after which retrieve it later to proceed the place you left off:
# Save to a file
outcome.dump(file_path=".", file_name="training_result.json")
# Load from a file
outcome = TrainingResult.load("training_result.json")
Monitoring the Logs publish SFT launch
After we’ve got launched the SFT job, we are able to now monitor the logs it publishes to Amazon CloudWatch. The logs present per-step metrics together with loss, studying price, and throughput, letting you observe convergence in actual time.
The Nova Forge SDK has built-in utilities for simply extracting and displaying the logs from every platform sort immediately in your pocket book surroundings.
You can too immediately ask a customizer object for the logs, and it’ll intelligently retrieve them for the newest job it created:
customizer.get_logs(restrict=20)
As well as, you’ll be able to observe the job standing in actual time, which is helpful for monitoring when a job succeeds or fails:
outcome.get_job_status() # Returns (JobStatus.IN_PROGRESS, ...) or (JobStatus.COMPLETED, ...)
Evaluating the SFT mannequin
With coaching full, we are able to consider the fine-tuned mannequin on the identical dataset that we used for baseline analysis, to know how a lot we improved in comparison with the baseline. The Nova Forge SDK helps operating evaluations on the fashions generated by a coaching job. The next instance demonstrates this:
Within the following desk, we see the aggregated metrics for a similar analysis dataset after making use of SFT coaching:
Metric
Rating
Delta
ROUGE-1
0.8290 (±0.0157)
0.671
ROUGE-2
0.4860 (±0.0224)
0.4591
ROUGE-L
0.8290 (±0.0157)
0.671
Precise Match (EM)
0.7720 (±0.0188)
0.642
Quasi-EM (QEM)
0.7900 (±0.0182)
0.66
F1 Rating
0.7720 (±0.0188)
0.634
F1 Rating (Quasi)
0.7900 (±0.0182)
0.6445
BLEU
0.0000 (±0.1031)
-0.4504
Even with a brief coaching run, we see enhancements in all of our metrics save BLEU (which provides low scores for terribly quick responses), going as much as 77.2% accuracy for actual match metrics.
print("Submit-SFT Classification Accuracy (extracted class labels):")
sft_accuracy = classification_accuracy(sft_samples)
Checking our personal classification accuracy metric, we are able to see 79.0% of analysis datapoints getting the right classification. The small distinction between classification accuracy and actual match scores exhibits us that the mannequin has correctly discovered the required format.
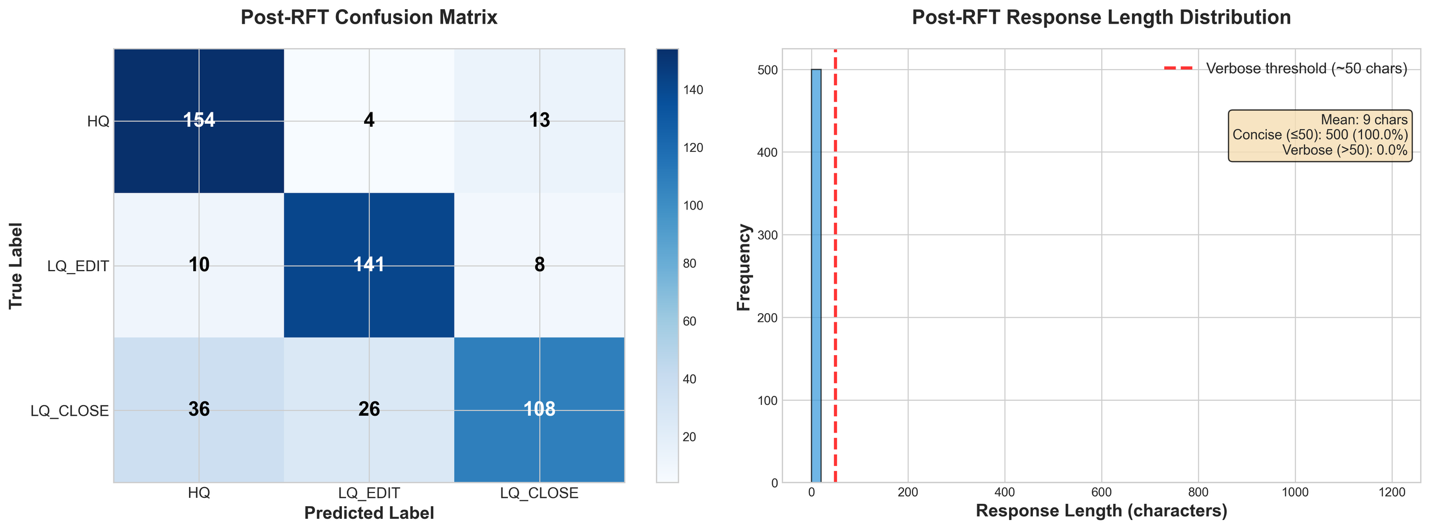
From our detailed efficiency metrics, we are able to see that the response size distribution has been pulled absolutely to non-verbose responses. Within the Confusion Matrix, we additionally see a drastic enhance in classification accuracy for the LQ_EDIT and LQ_CLOSE courses, decreasing the mannequin’s bias in direction of classifying rows as HQ.
Step 3: Reinforcement High quality Tuning
Based mostly on the earlier knowledge, SFT does properly at coaching the mannequin to suit the required format, however there may be nonetheless extra to enhance within the accuracy of the generated labels. Subsequent, we try and iteratively add Reinforcement High quality Tuning on high of our skilled SFT checkpoint. That is usually useful when making an attempt to enhance mannequin accuracy, particularly on advanced use circumstances the place the issue entails extra than simply becoming a required format and the duties may be framed when it comes to a quantifiable reward.
Constructing reward features
For classification, we create an AWS Lambda perform that rewards right predictions with a optimistic rating (+1) and a destructive rating (-1) for unsuitable predictions:
1.0: Appropriate prediction
-1.0: Incorrect prediction
The perform handles three high quality classes (HQ, LQ_EDIT, LQ_CLOSE) and makes use of versatile textual content extraction to deal with minor formatting variations in mannequin outputs (for instance, “HQ”, “HQ.”, “The reply is HQ”). This sturdy extraction makes positive that the mannequin receives correct reward indicators even when producing barely verbose responses. The binary reward construction creates robust, unambiguous gradients that assist the mannequin be taught to tell apart between high-quality and low-quality content material classes.
"""Binary reward perform for classification: +1 right, -1 unsuitable.
Easy and clear sign:
- Appropriate prediction: +1.0
- Incorrect prediction: -1.0
"""
def calculate_reward(prediction: str, ground_truth: str) -> float:
""" Calculates binary reward """
extracted = extract_category(prediction) # Extracts class from prediction and normalize it
truth_norm = normalize_text(ground_truth) # Normalize the groundtruth
# Appropriate prediction
if extracted and extracted == truth_norm: return 1.0
# Incorrect prediction
return -1.0
def lambda_handler(occasion, context):
""" Lambda handler with binary rewards. """
scores: Checklist[RewardOutput] = []
for pattern in occasion:
idx = pattern.get("id", "no_id")
ground_truth = pattern.get("reference_answer", "")
prediction = last_message.get("content material", "")
# Calculate binary reward
reward = calculate_reward(prediction, ground_truth)
scores.append(RewardOutput(id=idx, aggregate_reward_score=reward))
return [asdict(score) for score in scores]
Deploy this Lambda perform to AWS and word the ARN to be used within the RFT coaching configuration.
Subsequent we deploy the lambda perform to AWS account, and get the deployed lambda ARN, so it may be used whereas launching the RFT coaching.
Be sure that so as to add Lambda Invoke Insurance policies to your customization IAM function, in order that Amazon SageMaker AI can invoke the Lambda insurance policies after coaching begins.
Knowledge preparation in direction of RFT
Equally because the SFT experiment setup, we are able to use the Nova Forge SDK to curate the dataset and carry out validations for RFT schema. This helps in bringing the dataset and remodeling them into the OpenAI schema that works for RFT. The next snippet exhibits how you can rework a dataset into RFT dataset.
RFT_DATA = './rft.csv'
rft_loader = CSVDatasetLoader(
question='Physique',
response="Y",
system='system'
)
rft_loader.load(RFT_DATA)
# Rework for RFT
rft_loader.rework(methodology=TrainingMethod.RFT_LORA, mannequin=MODEL)
rft_loader.validate(methodology=TrainingMethod.RFT_LORA, mannequin=MODEL)
# Save to S3
rft_s3_uri = rft_loader.save_data(
f"s3://{S3_BUCKET}/{S3_PREFIX}/knowledge/rft.jsonl"
)
After this transformation you’re going to get knowledge in following OpenAI format:
Launching RFT on SFT checkpoint and Monitoring Logs
Subsequent, we are going to initialize the RFT job itself on high of our SFT checkpoint. For this step, Nova Forge SDK helps you launch your RFT job by bringing the formatted dataset together with the reward perform for use. The next snippet exhibits an instance of how you can run RFT on high of SFT checkpoint, with RFT knowledge and reward perform.
We use the next hyperparameters for the RFT coaching run. To discover the hyperparameters, we purpose for under 40 steps for this RFT job to maintain the coaching time low.
rft_overrides = {
"lr": 0.00001, # Studying price
"number_generation": 4, # N samples per immediate to estimate benefits (variance vs price).
"reasoning_effort": "null", # Permits reasoning mode Excessive / Low / or null for non-reasoning
"max_new_tokens": 50, # This cuts off verbose outputs
"kl_loss_coef": 0.02, # Weight on the KL penalty between the actor (trainable coverage) and a frozen reference mannequin
"temperature": 1, # Softmax temperature
"ent_coeff": 0.01, # A bonus added to the coverage loss that rewards higher-output entropy
"max_steps": 40, # Steps to coach for. One Step = global_batch_size
"save_steps": 30, # Steps after which a checkpoint will probably be saved
"top_k": 5, # Pattern solely from top-Okay logits
"global_batch_size": 64, # Whole samples per optimizer step throughout all replicas (16/32/64/128/256)
}
# Begin RFT coaching
rft_result = rft_customizer.prepare(
job_name="stack-overflow-rft",
rft_lambda_arn=REWARD_LAMBDA_ARN,
overrides = rft_overrides
)
We will monitor the RFT coaching logs utilizing the show_logs() methodology:
Reward statistics exhibiting the typical high quality scores assigned by your Lambda perform to generated responses.
Critic scores indicating how properly the worth mannequin predicts future rewards.
Coverage gradient metrics like loss and KL divergence that measure coaching stability and the way a lot the mannequin is altering from its preliminary state.
Response size statistics to trace output verbosity.
Efficiency metrics together with throughput (tokens/second), reminiscence utilization, and time per coaching step.
Monitoring these logs helps us determine points like reward collapse (declining common rewards), coverage instability (excessive KL divergence), or era issues (response lengths bumping towards the max_token depend). After we determine the problems, we alter our hyperparameters or reward features as wanted.
RFT reward distribution
For the earlier RFT coaching, we used a reward perform of +1.0 for proper responses (responses containing the right label inside them) and -1.0 for incorrect responses.
It’s because our SFT coaching already taught the mannequin the required format. If we don’t over-train and disrupt the patterns from SFT tuning, responses will have already got the right verbosity and the mannequin will attempt to give the correct reply (relatively than giving up or gaming the format).
We assist the prevailing SFT coaching by including kl_loss_coef to decelerate the mannequin’s divergence from the SFT-induced patterns. We additionally restrict the max_tokens, which considerably encourages shorter responses over longer ones (as their classification tokens are assured to be throughout the window). Given the quick coaching length, that is enough to find out that the RFT tuning represents an enchancment within the mannequin’s efficiency.
Evaluating publish SFT+RFT experiment
We use the identical analysis setup as our baseline and post-SFT evaluations to conduct assess our publish SFT+RFT custom-made mannequin. This offers us an understanding of what number of enhancements we are able to understand with iterative coaching. As earlier than, utilizing Nova Forge SDK, we are able to shortly run one other spherical of analysis to search out the mannequin efficiency carry.
Outcomes
Metric
Rating
Delta
ROUGE-1
0.8400 (±0.0153)
0.011
ROUGE-2
0.4980 (±0.0224)
0.012
ROUGE-L
0.8400 (±0.0153)
0.011
Precise Match (EM)
0.7880 (±0.0183)
0.016
Quasi-EM (QEM)
0.8060 (±0.0177)
0.016
F1 Rating
0.7880 (±0.0183)
0.016
F1 Rating (Quasi)
0.8060 (±0.0177)
0.016
BLEU
0.0000 (±0.0984)
0
Upon incorporating Reinforcement High quality-Tuning (RFT) into our present mannequin, we see improved efficiency in comparison with the baseline and the standalone Supervised High quality-Tuning (SFT) mannequin. All our metrics persistently improved by round 1 %.
Evaluating the metrics, we see that the order of improvement-deltas is completely different from that of the SFT fine-tuning, indicating that RFT is calibrating completely different patterns within the mannequin relatively than reinforcing the teachings from the SFT run.
The detailed efficiency metrics present that our mannequin continues to comply with to the requested output format, remembering the teachings of the SFT run. As well as, the classifications themselves are extra focused on the right diagonal, with every of the wrong squares of the confusion matrix exhibiting a lower in inhabitants.
These preliminary indications present that iterative coaching can assist push efficiency additional than only a single coaching session. With tuned hyperparameters on longer coaching runs, we may convey these enhancements even additional.
Ultimate outcome evaluation
Metric
Baseline
Submit-SFT
Submit-RFT
Delta (RFT-Base)
ROUGE-1
0.158
0.829
0.84
0.682
ROUGE-2
0.0269
0.486
0.498
0.4711
ROUGE-L
0.158
0.829
0.84
0.682
Precise Match (EM)
0.13
0.772
0.788
0.658
Quasi-EM (QEM)
0.13
0.79
0.806
0.676
F1 Rating
0.138
0.772
0.788
0.65
F1 Rating (Quasi)
0.1455
0.79
0.806
0.6605
BLEU
0.4504
0
0
-0.4504
Throughout all analysis metrics, we see:
General Enchancment: The 2-stage customization method (SFT + RFT) achieved constant enhancements throughout all metrics, with ROUGE-1 enhancing by +0.682, EM by +0.658, and F1 by +0.650 over baseline.
SFT vs RFT Roles: SFT gives the muse for area adaptation with the most important efficiency good points, whereas RFT fine-tunes decision-making by means of reward-based studying.
BLEU scores should not significant for this classification process, as BLEU measures n-gram overlap for era duties. Since our mannequin outputs single-token classifications (HQ, LQ_EDIT, LQ_CLOSE), BLEU can’t seize the standard of those categorical predictions and ought to be disregarded in favor of actual match (EM) and F1 metrics.
Step 4: Deployment to an Amazon SageMaker AI Inference
Now that we’ve got our closing mannequin prepared, we are able to deploy it the place it might serve actual predictions. The Nova Forge SDK makes deployments easy, whether or not you select Amazon Bedrock for absolutely managed inference or Amazon SageMaker AI for extra management over your infrastructure.
The SDK helps two deployment targets, every with distinct benefits:
Amazon Bedrock gives a totally managed expertise with two choices:
On-Demand: Serverless inference with computerized scaling and pay-per-use pricing which is ideal for variable workloads and growth
Provisioned Throughput: Devoted capability with predictable efficiency for manufacturing workloads with constant site visitors
Amazon SageMaker AI Inference gives flexibility if you want customized occasion varieties or particular surroundings configurations. You’ll be able to specify the occasion sort, preliminary occasion depend, and configure mannequin habits by means of surroundings variables whereas the SDK handles the deployment complexity.
We deploy to Amazon SageMaker AI Inference for this demonstration.
This may create the execution function blogpost-sagemaker if it doesn’t exist and use it throughout deployment. If you have already got a job that you just wish to use, you’ll be able to move the identify of that function immediately.
Invoke endpoint
After the endpoint is deployed, we are able to invoke it utilizing the SDK. The invoke_inference methodology gives streaming output for SageMaker endpoints and non-streaming for Amazon Bedrock endpoints. We will use the next code to invoke it:
streaming_chat_request = {
"messages": [{"role": "user", "content": "Tell me a short story"}],
"max_tokens": 200,
"stream": True,}
ENDPOINT_NAME = f"arn:aws:sagemaker:REGION:ACCOUNT_ID:endpoint/{ENDPOINT_NAME}"
inference_result = rft_customizer.invoke_inference(
request_body=streaming_chat_request,
endpoint_arn=ENDPOINT_NAME
)
inference_result.present()
Step 5: Cleanup
After you’ve completed testing your deployment, clear up these assets to keep away from ongoing AWS costs.
import boto3
iam_client = boto3.consumer('iam')
role_name="your-role-name"
# Detach managed insurance policies
attached_policies = iam_client.list_attached_role_policies(RoleName=role_name)
for coverage in attached_policies['AttachedPolicies']:
iam_client.detach_role_policy(
RoleName=role_name,
PolicyArn=coverage['PolicyArn']
)
# Delete inline insurance policies
inline_policies = iam_client.list_role_policies(RoleName=role_name)
for policy_name in inline_policies['PolicyNames']:
iam_client.delete_role_policy(
RoleName=role_name,
PolicyName=policy_name
)
# Take away from occasion profiles
instance_profiles = iam_client.list_instance_profiles_for_role(RoleName=role_name)
for profile in instance_profiles['InstanceProfiles']:
iam_client.remove_role_from_instance_profile(
InstanceProfileName=profile['InstanceProfileName'],
RoleName=role_name
)
# Delete the function
iam_client.delete_role(RoleName=role_name)
Conclusion
The Nova Forge SDK transforms mannequin customization from a posh, infrastructure-heavy course of into an accessible, developer-friendly workflow. By our Stack Overflow classification case research, we demonstrated how groups can use the SDK to realize measurable enhancements by means of iterative coaching, shifting from 13% baseline accuracy to 79% after SFT, and reaching 80.6% with extra RFT.
By eradicating the normal limitations to LLM customization, technical experience necessities, and time funding, the Nova Forge SDK empowers organizations to construct fashions that perceive their distinctive context with out sacrificing the final capabilities that make basis fashions useful. The SDK handles configuring compute assets, orchestrating the complete customization pipeline, monitoring coaching jobs, and deploying endpoints. The result’s enterprise AI that’s each specialised and clever, domain-expert and broadly succesful.
Able to customise your individual Nova fashions? Get began with the Nova Forge SDK on GitHub and discover the full documentation to start constructing fashions tailor-made to your enterprise wants.
Within the lead-up to the USA and Israel’s assault on Iran, prediction markets noticed a frenzy of exercise tied to the battle. Customers of prediction markets had been placing down cash on when the primary bombs would drop, in addition to the place the bombs may hit. However probably the most energetic markets had folks betting on whether or not Iranian Supreme Chief Ayatollah Ali Khamenei would depart workplace earlier than March 1. He was killed on February 28.
“So on Polymarket, there’s a ton of various bets you can also make,” Kate Knibbs, a senior author for Wired, instructed At present, Defined co-host Sean Rameswaram. “I feel they really simply took down a number of the markets for missile strikes due to all of the backlash that has been occurring in response to the truth that you possibly can guess on warfare as a result of it’s so dystopian.”
This type of factor has occurred in sports activities and sports activities betting for years. And it appears more likely to occur rather more typically in response to information occasions because of prediction markets too. As a result of as Knibbs spelled out to Rameswaram, these markets have gotten more and more widespread. They’ve the Trump administration on their aspect. And folk throughout the globe appear absorbed with the thought of betting on warfare.
Under is an excerpt of their dialog, edited for size and readability. There’s rather more within the full podcast, so hearken to At present, Defined wherever you get podcasts, together with Apple Podcasts, Pandora, and Spotify.
What sort of bets are folks making on the warfare in Iran?
Particularly on Polymarket, there’s a ton of various bets you can also make. You can guess on when the Strait of Hormuz is gonna open, or whether or not it’s gonna open. You can guess on missile strikes. There was famously this market about whether or not the supreme chief would stay in energy or not. There have been markets on who his successor was going to be.
It’s nearly like something you assume is perhaps a market, most likely is a market, no less than on Polymarket, as a result of Kalshi has some stricter guidelines and its choices are usually not fairly as morbid. You’ll be able to’t guess on assassinations, for example, there. However Polymarket largely exists exterior of the USA, so it’s much less beholden to US legislation, or no less than that’s the way it’s performing.
How a lot cash are folks making on these sorts of bets proper now? Do we all know?
“Donald Trump Jr. is an adviser to each Kalshi and Polymarket. The Trump household is planning on launching their very own prediction market referred to as Reality Predict.”
With Polymarket, you possibly can see the wallets of the merchants. You’re in a position to see just about exactly how a lot some persons are profiting. And you already know, like in all playing, most people who find themselves collaborating in these markets are literally shedding cash.
So the winners are this tiny little share. And the winners who’re successful huge are an excellent smaller slice of that small slice. So we now have a really choose group of people who find themselves making, in some instances tens of millions and tens of millions of {dollars} on warfare.
And a few of these folks making tens of millions and tens of millions of {dollars} type of appeared suspicious, proper? As a result of, I don’t know, they made a giant guess the night time earlier than the warfare began that we’d be going to warfare in a number of hours after which they made lots of of 1000’s of {dollars}.
Yeah. Particularly as a result of in a number of these instances, it wasn’t as if they’d this lengthy historical past of simply being tremendous sensible and savvy at geopolitical contracts.
In a number of these instances, the wallets had been simply created inside days of creating these extremely suspect trades. And so a number of totally different organizations that may hint crypto wallets have been trying on the patterns which might be rising round these warfare markets and principally saying, “Look, we don’t know precisely who’s doing this, nevertheless it’s most likely insider buying and selling as a result of there’s simply no method that these persons are popping up out of nowhere to drop a bunch of cash and make these extremely exact bets and revenue after which disappear into the ether.”
Is that allowed? Is that throughout the parameters of what’s allowed on these betting markets?
It looks as if it shouldn’t be, proper? It appears morally repugnant. It appears clearly ethically flawed. However in terms of what’s the definition of insider buying and selling, we sometimes consider it when it comes to somebody having nonpublic materials details about an organization that can change how their shares carry out. It has a really particular definition if you’re speaking about SEC inventory market stuff.
Prediction markets are regulated in another way and there’s type of a fuzziness round what constitutes personal materials info. If there’s a Google Insider who’s insider buying and selling, it’s type of apparent, “Oh, they realized these particular details about how the corporate is gonna carry out.” With regards to prediction markets, there’s markets on the whole lot. So who’s an insider?
There’s a category motion lawsuit in opposition to Kalshi proper now. What’s occurring there?
A few of them have been ongoing for some time and are arguing that plaintiffs have been preyed upon by Kalshi as a result of it’s secretly an unlawful playing group. And people are extra like normal curiosity or class actions.
I feel what you’re pondering of is the one which simply got here out that’s particularly tied to the Khomeini market, the place a bunch of persons are actually, actually pissed as a result of when the Ayatollah died, they thought that they had been gonna revenue as a result of they’d guess “sure” on this market that stated that he would now not be in energy by “X” date. After which Kalshi got here out and stated, “Uh, no, we really don’t permit betting on demise. And that’s been within the wonderful print of our guidelines this whole time.” So as an alternative of profiting, folks bought their a refund, however they didn’t get the cash that they thought that they deserved for appropriately collaborating out there. And they also’re now suing.
Do you assume what’s occurred prior to now couple weeks and what folks have seen with these type of brand-new accounts, making tons of cash off of a warfare that’s simply beginning and wildly controversial goes to be the driving power behind some regulation?
Effectively, proper now the Trump administration could be very pleasant in direction of prediction markets. Donald Trump Jr. is an adviser to each Kalshi and Polymarket. The Trump household is planning on launching their very own prediction market referred to as Reality Predict like a spin-off of Reality Social. And the White Home hasn’t been commenting straight on the prediction market stuff, however the CFTC, the Commodity Futures Buying and selling Fee, which is the federal government company that regulates these on a federal stage, the chairman Michael Selig has like come out swinging saying, “That is our turf. All of those efforts on the state stage to make all of those corporations abide by state playing rules and to place guardrails up, these efforts are one thing we don’t stand by. We really strongly disagree with them.”
I feel there’s over 50 totally different lawsuits flying round about this proper now. A few of them, the states stand an opportunity at successful. And so if the states win, it’ll set a precedent and these prediction markets will now not have the ability to function as they at present are. And that would actually change issues. However apart from that, I don’t see, I don’t see these being curbed in any possible way quickly.
Scientists have adopted the position of “cosmic archaeologists” to find a uncommon, iron-deficient second-generation star — basically a fossil document of our universe’s chemical evolution. Simply as uncovering artifacts right here on Earth teaches us about misplaced generations of people, this statement gives laborious proof of how the primary technology of stars died to chemically enrich their successors.
The second technology, or POP II, star was found within the dwarf galaxy Pictor II, positioned round 150,000 light-years from Earth within the constellation Pictor, utilizing the Darkish Power Digital camera (DECam) mounted atop Víctor M. Blanco 4-meter Telescope. Designated PicII-503, the star has just one/40,000th of the iron contained inside the solar, which is a third-generation, or (considerably confusingly) POP I, star. The truth that PicII-503 has the bottom focus of iron ever seen past the Milky Manner makes it some of the primordial stars ever found.
That deficit is not essentially the most extraordinary about PicII-503, nonetheless. The staff additionally discovered that this POP II star has an enormous overabundance of carbon, with its ratio of carbon-to-iron over 1,500 occasions better than the identical ratio within the solar. This overabundance mirrors the distinctive carbon signature of low-iron stars discovered within the nebulous outer halo of the Milky Manner.
Article continues under
“Discoveries like this are cosmic archaeology, uncovering uncommon stellar fossils that protect the fingerprints of the universe’s first stars,” Chris Davis, Nationwide Science Basis Program Director for NOIRLab mentioned in a press release.
A form of magic
The primary stars within the universe, or POP III stars, had been born when the chemical abundance of the cosmos did not lengthen past hydrogen, helium, and a smattering of heavier components, which astronomers collectively name “metals. “This meant that these POP III stars had been additionally dominated by hydrogen with just a bit helium and little or no when it comes to metals. These stars solid the primary carbon and iron of their cores, materials that was distributed into the interstellar medium when these stars went supernova and exploded on the finish of their lives.
Interstellar clouds of gasoline and dirt enriched with these metals ultimately cooled and collapsed to beginning the second technology of stars, stars that had been extra metal-rich due to the donation of heavy components from their predecessors. That makes POP II akin to time capsules, recording an necessary stage within the chemical enrichment of the universe.
“Discovering a star that unambiguously preserves the heavy metals from the primary stars was on the fringe of what we thought doable, given the acute rarity of those objects,” staff chief Anirudh Chiti of Stanford College mentioned within the assertion. “With the bottom iron abundance ever derived in any ultra-faint dwarf galaxy, PicII-503 gives a window into preliminary component manufacturing inside a primordial system that’s unprecedented.”
Breaking area information, the newest updates on rocket launches, skywatching occasions and extra!
The primary confirmed instance of a POP II star present in a faint dwarf galaxy, PicII-503 was highlighted as an especially metal-poor star in information collected by DECam’s MAGIC (Mapping the Historic Galaxy in CaHK) survey. This 54-night observing endeavor was developed with the express function of figuring out the oldest and most chemically primitive stars within the Milky Manner and its dwarf galaxy companions.
“With out information from MAGIC, it might have been unattainable to isolate this star among the many a whole bunch of different stars within the neighborhood of the Pictor II ultra-faint dwarf galaxy,” Chiti mentioned.
Chiti and colleagues mixed MAGIC information with observations from the Very Massive Telescope (VLT) within the Atacama Desert area of northern Chile and the Baade Magellan Telescope to find low iron and calcium abundances of PicII-503, the bottom seen past our dwelling galaxy. In flip, this revealed that PicII-503 was the primary document of chemical enrichment present in a dwarf galaxy.
The Darkish Power Digital camera is mounted within the Victor Blanco telescope, pictured right here with different telescopes on the Cerro Tololo Inter-American Observatory in Chile. (Picture credit score: Fermilab)
One doable rationalization for the shockingly low iron-to-carbon ratio of PicII-503 is that when POP III stars went supernova, these explosions had been comparatively low in vitality. That will have meant that whereas lighter components like carbon had been blasted into the interstellar medium, heavy components like iron fell again into the wreckage of the supernova.
The truth that PicII-503 is present in one of many smallest dwarf galaxies ever seen, with a correspondingly low gravitational affect, helps the thought of POP III stars dying in low-energy supernovas.
“What excites me essentially the most is that we’ve got noticed an final result of the very preliminary component manufacturing in a primordial galaxy, which is a elementary statement!” Chiti mentioned. “It additionally cleanly connects to the signature that we’ve got seen within the lowest-metallicity Milky Manner halo stars, tying collectively their origins and the first-star-enriched nature of those objects.”
The staff’s analysis was revealed on Monday (March 16) within the journal Nature Astronomy.
We’ve simply introduced the discharge of Stata 14. Stata 14 ships and downloads beginning now.
Stata 14 is now out there. You heard it right here first.
There’s a protracted custom that Statalisters hear about Stata’s new releases first. The brand new discussion board is celebrating its first birthday, however it’s a continuation of the outdated Statalist, so the custom continues, however up to date for the fashionable world, the place every thing occurs extra rapidly. You’re listening to about Stata 14 roughly a microsecond earlier than the remainder of the world. Traditions are essential.
Right here’s yet one more instance of every thing taking place sooner within the trendy world. Relatively than the announcement previous delivery by a couple of weeks as in earlier releases, Stata 14 ships and downloads beginning now. Or fairly, a microsecond from now.
Some issues from the previous are price preserving, nevertheless, and one is that I get to jot down concerning the new launch in my very own idiosyncratic approach. So let me get the advertising and marketing stuff out of the way in which after which I can inform you about a couple of issues that particularly curiosity me and would possibly curiosity you.
MARKETING BEGINS.
Right here’s a partial record of what’s new, a.ok.a. the highlights:
Unicode
Greater than 2 billion observations (Stata/MP)
Bayesian evaluation
IRT (Merchandise Response Principle)
Panel-data survival fashions
Remedy results
Remedy results for survival fashions
Endogenous therapies
Likelihood weights
Stability evaluation
Multilevel mixed-effects survival fashions
Small-sample inference for multilevel fashions
SEM (structural equation modeling)
Survival fashions
Satorra-Bentler scaled chi-squared take a look at
Survey information
Multilevel weights
Energy and pattern dimension
Survival fashions
Contingency (epidemiological) tables
Markov-switching regression fashions
Assessments for structural breaks in time-series
Fractional consequence regression fashions
Hurdle fashions
Censored Poisson regression
Survey help & multilevel weights for multilevel fashions
New random-number mills
Estimated marginal means and marginal results
Tables for a number of outcomes and ranges
Integration over unobserved and latent variables
ICD-10
Stata in Spanish and in Japanese
The above record will not be full; it lists about 30% of what’s new.
For all the main points about Stata 14, together with buy and replace info, and hyperlinks to distributors exterior of the US, go to stata.com/stata14.
In case you are exterior of the US, you may order out of your licensed Stata distributor. They’ll provide codes as a way to entry and obtain from stata.com.
MARKETING ENDS.
I need to write about three of the brand new options ‒ Unicode, greater than 2-billion observations, and Bayesian evaluation.
Unicode is the fashionable approach that computer systems encode characters such because the letters in what you are actually studying. Unicode encodes all of the world’s characters, that means I can write Hiya, Здравствуйте, こんにちは, and much extra apart from. Effectively, the discussion board software program is trendy and I at all times might write these phrases right here. Now I can write them in Stata, too.
For many who care, Stata makes use of Unicode’s UTF-8 encoding.
Anyway, you should utilize Unicode characters in your information, in fact; in your variable labels, in fact; and in your worth labels, in fact. What you won’t count on is that you should utilize Unicode in your variable names, macro names, and in every single place else Stata needs a reputation or identifier.
Right here’s the auto information in Japanese:
Your use of Unicode will not be as excessive because the above. It may be sufficient simply to make tables and graphs labeled in languages apart from English. If that’s the case, simply set the variable labels and worth labels. It doesn’t matter whether or not the variables are named übersetzung and kofferraum or gear_ratio and trunkspace or 変速比 and トランク.
I need to remind English audio system that Unicode contains mathematical symbols. You should use them in titles, axis labels, and the like.
Few good issues come with out price. When you’ve got been utilizing Prolonged ASCII to avoid Stata’s plain ASCII limitations, these information must be translated to Unicode if the strings in them are to show accurately in Stata 14. This contains .dta information, do-files, ado-files, assist information, and the like. It’s simpler to do than you would possibly count on. A brand new unicode analyze command will inform you whether or not you may have information that want fixing and, in that case, the brand new unicode translate command will repair them for you. It’s virtually as simple as typing
. unicode translate *
This command interprets your information and that has received to concern you. What if it mistranslates them? What if the ability fails? Calm down. unicode translate makes backups of the originals, and it retains the backups till you delete them, which it’s a must to do by typing
. unicode erasebackups, badidea
Sure, the choice actually is known as badidea and it isn’t optionally available. One other unicode command can restore the backups.
The troublesome a part of translating your current information will not be performing the interpretation, it’s figuring out which Prolonged ASCII encoding your information used in order that the interpretation will be carried out. We have now recommendation on that within the assist information however, even so, a few of you’ll solely be capable of slim down the encoding to some decisions. The excellent news is that it’s simple to strive every one. You simply kind
. unicode retranslate *
It received’t take lengthy to determine which encoding works finest.
Stata/MP now lets you course of datasets containing greater than 2.1-billion observations. This sounds thrilling, however I believe it is going to curiosity only some of you. How many people have datasets with greater than 2.1-billion observations? And even in the event you do, you will want a pc with numerous reminiscence. This function is beneficial in case you have entry to a 512-gigabyte, 1-terabyte, or 1.5-terabyte pc. With smaller computer systems, you might be unlikely to have room for two.1 billion observations. It’s thrilling that such computer systems can be found.
We elevated the restrict on solely Stata/MP as a result of, to use the upper restrict, you want a number of processors. It’s simple to misjudge how a lot bigger a 2-billion remark dataset is than a 2-million remark one. On my on a regular basis 16 gigabyte pc ‒ which is nothing particular ‒ I simply match a linear regression with six RHS variables on 2-million observations. It ran in 1.2 seconds. I used Stata/SE, and the 1.2 seconds felt quick. So, if my pc had extra reminiscence, how lengthy wouldn’t it take to suit a mannequin on 2-billion observations? 1,200 seconds, which is to say, 20 minutes! You want Stata/MP. Stata/MP4 will cut back that to five minutes. Stata/MP32 will cut back that to 37.5 seconds.
By the way in which, in the event you intend to make use of greater than 2-billion observations, make sure you click on on assist obs_advice that seems within the start-up notes after Stata launches. You’re going to get higher efficiency in the event you set min_memory and segmentsize to bigger values. We inform you what values to set.
After that, it’s statistics, statistics, statistics.
Which new statistics will curiosity you clearly relies on your area. We’ve gone deeper into numerous fields. Remedy results for survival fashions is only one instance. Multilevel survival fashions is one other. Markov-switching fashions is yet one more. Effectively, you may learn the record above.
Two of the brand new statistical options are price mentioning, nevertheless, as a result of they merely weren’t there beforehand. They’re Bayesian evaluation and IRT fashions, that are admittedly two very various things.
IRT is a spotlight of the discharge and for a few of it you’ll be the spotlight, so I point out it, and I’ll simply inform you to see stata.com/stata14/irt for extra info.
Bayesian evaluation is the opposite spotlight so far as I’m involved, and it’ll curiosity plenty of you as a result of it cuts throughout fields. Lots of you might be already educated about this and I can simply hear you asking, “Does Stata embrace …?” So right here’s the high-speed abstract:
Stata suits continuous-, binary-, ordinal-, and count-outcome fashions. And linear and nonlinear fashions. And generalized nonlinear fashions. Univariate, multivariate, and multiple-equation. It supplies 10 chance fashions and 18 prior distributions. It additionally permits for user-defined likelihoods mixed with built-in priors, built-in likelihoods mixed with user-defined priors, and a roll-your-own programming method to calculate the posterior density instantly. MCMC strategies are offered, together with Adaptive Metropolis-Hastings (MH), Adaptive MH with Gibbs updates, and full Gibbs sampling for sure likelihoods and priors.
It’s additionally simple to make use of and that’s saying one thing.
There’s an awesome instance of the brand new Bayes options in The Stata Information. I point out this as a result of together with the instance there may be almost a proof of ease of use. The instance seems on the variety of disasters within the British coal mining trade. There was a reasonably abrupt lower within the charge someday between 1887 and 1895, which you see in the event you eyeballed a graph. Within the instance, we mannequin the variety of disasters earlier than the change level as one Poisson course of; the quantity after, as one other Poisson course of; after which we match a mannequin of the 2 Poisson parameters and the date of change. For the change level it makes use of a uniform prior on [1851, 1962] ‒ the vary of the info ‒ and obtains a posterior imply estimate of 1890.4 and a 95% credible interval of [1886, 1896], which agrees with our visible evaluation.
I hope one thing I’ve written above pursuits you. Go to stata.com/stata14 for extra info.
Assessments in fashionable LMS platforms transcend multiple-choice questions. Product groups are constructing quiz builders, rubric creators, peer evaluation workflows, and inline suggestions instruments that every one rely on one shared part: the wealthy textual content editor.
The editor’s capabilities instantly decide what sorts of assessments your platform can supply. This text covers 4 patterns the place EdTech firms are utilizing WYSIWYG editors to construct differentiated evaluation experiences, with implementation particulars for product leaders evaluating these alternatives.
Key Takeaways
Wealthy evaluation enhancing is a real differentiator.
A number of editor situations per web page demand light-weight initialization.
The editor’s API depth determines your evaluation ceiling.
Sample 1: Wealthy Quiz and Examination Builders
The best evaluation editors deal with plain textual content questions with radio button solutions. That’s desk stakes. The platforms profitable institutional offers supply wealthy media questions that embody formatted textual content with code snippets, photographs, diagrams, and embedded video explanations.
A STEM teacher constructing a physics examination wants to incorporate diagrams, mathematical notation, and formatted resolution explanations throughout the query and reply choices. A language teacher wants wealthy textual content with audio embeds for listening comprehension. A enterprise teacher wants formatted tables and charts inside case research questions.
The editor powering this quiz builder must help inline picture insertion, desk creation, math equation rendering through MathType, code block formatting, and media embedding. Every query area and every reply possibility requires an unbiased editor occasion, which implies the editor’s initialization efficiency and reminiscence footprint instantly have an effect on web page load time when rendering a 30-question examination builder.
Light-weight editors that initialize in milliseconds per occasion make this structure possible. Editors that take 500ms+ per occasion make a 30-question web page really feel sluggish. Throughout your analysis, check with the precise variety of editor situations your quiz builder will render per web page. The Chrome DevTools Efficiency panel can assist you measure initialization time per occasion.
A rubric builder in an LMS usually presents as a grid: standards rows and efficiency stage columns. Every cell accommodates an outline of what efficiency at that stage appears to be like like for that criterion. These descriptions want wealthy formatting, together with daring textual content for emphasis, bulleted lists for a number of indicators, and generally hyperlinks to supporting sources.
The implementation requires an editor occasion in every rubric cell, much like the quiz builder sample. The important thing distinction is that rubric content material tends to be shorter however extra densely formatted. Your editor must deal with frequent switching between cells with out dropping state, and the generated HTML must be compact since rubric content material will get saved and rendered repeatedly throughout scholar grade views.
Past the enhancing expertise, the HTML output issues for downstream use. Rubrics typically get exported to PDF for offline grading, included in grade stories, and displayed in student-facing grade breakdowns. Clear, semantic HTML output from the editor simplifies all of those rendering contexts.
Sample 3: Peer Overview Workflows with Inline Suggestions
Peer evaluation is a rising evaluation mannequin in EdTech, particularly in writing-intensive programs. The Writing Throughout the Curriculum (WAC) Clearinghouse gives frameworks that many universities comply with, and structured peer suggestions is central to the strategy.
The implementation sample works like this: a scholar submits written work via the LMS. Reviewers (different college students or instructing assistants) open the submission and supply inline feedback on particular passages, plus a abstract analysis.
The editor serves two roles on this workflow. First, it renders the unique submission as read-only formatted content material. Second, it powers the suggestions interface the place reviewers compose their feedback.
The extra refined implementations use the editor’s choice API to seize the precise textual content vary the reviewer is commenting on, then show the remark anchored to that vary. This requires the editor to reveal dependable entry to DOM choice ranges, help read-only mode for the supply content material, enable programmatic insertion of annotation markers, and keep the connection between feedback and their anchored textual content ranges even when the supply content material is modified.
Sample 4: Teacher Suggestions with Tracked Adjustments
When instructors grade essay assignments, they typically need to present college students not simply what’s incorrect however how you can repair it. Tracked adjustments, the identical sample utilized in Microsoft Phrase’s evaluation mode, provides instructors this functionality instantly within the LMS.
The teacher opens a scholar’s submission within the editor, makes edits (including textual content, deleting textual content, reformatting), and people adjustments are recorded as tracked modifications. The scholar sees the unique content material with the teacher’s adjustments overlaid: inexperienced textual content for additions, pink strikethrough for deletions, and highlighted sections for formatting adjustments.
This sample requires the editor to help a observe adjustments mode that information insertions, deletions, and formatting adjustments with writer attribution. It additionally requires a rendering mode that visually differentiates authentic content material from tracked adjustments.
In response to suggestions analysis from the American Psychological Affiliation, particular, actionable suggestions improves scholar studying outcomes extra successfully than grades alone. Tracked adjustments present precisely this: particular, contextual recommendations that college students can evaluation and be taught from.
The implementation complexity lies in sustaining two parallel representations of the content material: the unique and the modified model with change monitoring metadata, and rendering them coherently. Industrial editors that embody observe adjustments as a built-in characteristic deal with this dual-state administration on the product stage, saving your engineering crew months of growth.
Selecting an Editor That Helps These Patterns
Not each editor can deal with these 4 patterns. The frequent necessities throughout all of them embody quick initialization since a number of situations per web page are the norm, small reminiscence footprint per occasion, clear semantic HTML output for downstream rendering, complete API entry for choice, content material manipulation, and occasion dealing with, and plugin extensibility for customized assessment-specific options.
When evaluating editors for evaluation use instances, transcend the usual demo. Construct a prototype of your most advanced evaluation kind, the one with essentially the most editor situations and the richest content material necessities. Check initialization efficiency, reminiscence utilization, and HTML output high quality below sensible circumstances.
The Differentiation Alternative
Most LMS platforms nonetheless supply primary textual content enter for evaluation creation. Wealthy evaluation enhancing is a real differentiator in institutional gross sales conversations, particularly for platforms focusing on writing-intensive applications, STEM departments, and graduate faculties the place evaluation complexity issues.
Product leaders evaluating this chance ought to map every sample to their goal market. In case your prospects are primarily STEM establishments, prioritize the quiz builder and rubric patterns with math help. Should you serve writing applications, put money into peer evaluation and tracked adjustments. Should you serve a broad institutional market, construct towards all 4.
The editor you select determines the ceiling of what your evaluation instruments can do. Select one which helps the place your product must go, not simply the place it’s as we speak.
Hallucinations will not be only a mannequin downside. In manufacturing, they’re a system design downside. Essentially the most dependable groups cut back hallucinations by grounding the mannequin in trusted information, forcing traceability, and gating outputs with automated checks and steady analysis.
On this article, we’ll cowl seven confirmed and field-tested methods builders and AI groups are utilizing immediately to scale back hallucinations in massive language mannequin (LLM) purposes.
# 1. Grounding Responses Utilizing Retrieval-Augmented Era
In case your utility have to be right about inside insurance policies, product specs, or buyer information, don’t let the mannequin reply from reminiscence. Use retrieval-augmented era (RAG) to retrieve related sources (e.g. docs, tickets, data base articles, or database information) and generate responses from that particular context.
For instance:
Consumer asks: “What’s our refund coverage for annual plans?”
Your system retrieves the present coverage web page and injects it into the immediate
The assistant solutions and cites the precise clause used
# 2. Requiring Citations for Key Claims
A easy operational rule utilized in many manufacturing assistants is: no sources, no reply.
Anthropic’s guardrail steering explicitly recommends making outputs auditable by requiring citations and having the mannequin confirm every declare by discovering a supporting quote, retracting any claims it can not assist. This straightforward method reduces hallucinations dramatically.
For instance:
For each factual bullet, the mannequin should connect a quote from the retrieved context
If it can not discover a quote, it should reply with “I should not have sufficient info within the supplied sources”
# 3. Utilizing Software Calling As a substitute of Free-Type Solutions
For transactional or factual queries, the most secure sample is: LLM — Software/API — Verified System of Report — Response.
As a substitute of letting the mannequin “recall” details, it fetches them. The LLM turns into a router and formatter, not the supply of reality. This single design resolution eliminates a big class of hallucinations.
# 4. Including a Put up-Era Verification Step
Many manufacturing methods now embrace a “decide” or “grader” mannequin. The workflow sometimes follows these steps:
Generate reply
Ship reply and supply paperwork to a verifier mannequin
Rating for groundedness or factual assist
If beneath threshold — regenerate or refuse
Some groups additionally run light-weight lexical checks (e.g. key phrase overlap or BM25 scoring) to confirm that claimed details seem within the supply textual content. A extensively cited analysis strategy is Chain-of-Verification (CoVe): draft a solution, generate verification questions, reply them independently, then produce a ultimate verified response. This multi-step validation pipeline considerably reduces unsupported claims.
# 5. Biasing Towards Quoting As a substitute of Paraphrasing
Paraphrasing will increase the prospect of delicate factual drift. A sensible guardrail is to:
Require direct quotes for factual claims
Enable summarization solely when quotes are current
Reject outputs that introduce unsupported numbers or names
This works notably properly in authorized, healthcare, and compliance use instances the place accuracy is crucial.
# 6. Calibrating Uncertainty and Failing Gracefully
You can not get rid of hallucinations fully. As a substitute, manufacturing methods design for secure failure. Widespread strategies embrace:
Confidence scoring
Help chance thresholds
“Not sufficient info accessible” fallback responses
Human-in-the-loop escalation for low-confidence solutions
Returning uncertainty is safer than returning assured fiction. In enterprise settings, this design philosophy is usually extra necessary than squeezing out marginal accuracy features.
# 7. Evaluating and Monitoring Constantly
Hallucination discount just isn’t a one-time repair. Even for those who enhance hallucination charges immediately, they’ll drift tomorrow attributable to mannequin updates, doc adjustments, and new person queries. Manufacturing groups run steady analysis pipelines to:
Consider each Nth request (or all high-risk requests)
Monitor hallucination fee, quotation protection, and refusal correctness
Alert when metrics degrade and roll again immediate or retrieval adjustments
Consumer suggestions loops are additionally crucial. Many groups log each hallucination report and feed it again into retrieval tuning or immediate changes. That is the distinction between a demo that appears correct and a system that stays correct.
# Wrapping Up
Lowering hallucinations in manufacturing LLMs just isn’t about discovering an ideal immediate. If you deal with it as an architectural downside, reliability improves. To take care of accuracy:
Floor solutions in actual information
Want instruments over reminiscence
Add verification layers
Design for secure failure
Monitor constantly
Kanwal Mehreen is a machine studying engineer and a technical author with a profound ardour for information science and the intersection of AI with drugs. She co-authored the e-book “Maximizing Productiveness with ChatGPT”. As a Google Era Scholar 2022 for APAC, she champions range and educational excellence. She’s additionally acknowledged as a Teradata Range in Tech Scholar, Mitacs Globalink Analysis Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having based FEMCodes to empower ladies in STEM fields.