Are you writing a e-book that includes Stata packages or output? We’re right here to assist! We all know you need your e-book to be fashionable and correct in all points, together with any parts that debate and exhibit Stata. That’s why we created the Creator Assist Program—a program that offers you direct entry to Stata specialists who will evaluate all of the Stata-related content material in your e-book to verify it’s correct, updated, and reflective of greatest practices.
StataCorp’s Creator Assist Program is a complimentary service that provides a spread of invaluable sources to boost your e-book’s Stata content material.
Knowledgeable code and output evaluate Our expert Stata professionals will meticulously evaluate your Stata code and output, making certain that they’re environment friendly and replicate fashionable utilization.
Problem-free formatting Our Stata manufacturing specialists will help you in formatting the Stata output and graphs that you simply embrace into your e-book.
Content material evaluate Our Stata specialists and statisticians will make sure the accuracy of all Stata-related content material.
Your Stata contact Upon enrollment, you’ll be paired with a devoted Stata skilled who will function your major level of contact. Your contact will leverage their deep understanding of Stata in addition to in depth sources and information of inner initiatives to supply assist that goes past expectations. From recommendation on fine-tuning Stata code to formatting output and graphs for the perfect presentation type, your contact will present recommendations on utilizing Stata in the simplest method and will probably be your trusted companion in your publication journey.
Ideas for a easy course of If you have already got a writer, step one is to let your editor know that you simply plan to make use of our Creator Assist Program.
Then, as you full chapters or sections of your e-book, you may ship the textual content, do-files, and datasets to your Stata contact. Sending content material a bit at a time tends to create the perfect workflow and permits us to provide you suggestions in essentially the most well timed method, however you probably have already accomplished the whole e-book, you may additionally ship it suddenly.
As you write, be at liberty to e mail your Stata contact with any questions you may have about using Stata in your e-book.
Make your e-book shine With our suggestions in hand, you may replace your e-book to indicate the very best Stata code, graphs, and output. You’re in command of your e-book, and our program is designed to empower, not impede, your publishing journey.
Be part of the Creator Assist Program at the moment We invite authors from all disciplines to affix the Creator Assist Program. Whether or not you’re a seasoned creator or new to the world of publishing, we’re right here to assist you alongside the way in which.
This put up is written with my PhD pupil and now visitor creator Patrik Reizinger and is an element 4 of a sequence of posts on causal inference:
A technique to consider causal inference is that causal fashions require a extra fine-grained fashions of the world in comparison with statistical fashions. Many causal fashions are equal to the identical statistical mannequin, but help completely different causal inferences. This put up elaborates on this level, and makes the connection between causal and statistical fashions extra exact.
Do you keep in mind these combinatorics issues from college the place the query was what number of methods exist to get from a begin place to a goal subject on a chessboard? And you’ll solely transfer one step proper or one step down. When you keep in mind, then I have to admit that we are going to not take into account issues like that. However its (one doable) takeaway truly might help us to grasp Markov factorizations.
You already know, it’s completely detached the way you traversed the chessboard, the consequence is identical. So we will say that – from the attitude of goal place and the method of getting there – it is a many-to-one mapping. The identical holds for random variables and causal generative fashions.
If in case you have a bunch of random variables – let’s name them $X_1, X_2, dots, X_n$ -, their joint distribution is $p left(X_1, X_2, dots, X_n proper) $. When you invoke the chain rule of likelihood, you should have a number of choices to precise this joint as a product of things:
the place $pi_i$ is a permutation of indices. Since you are able to do this for any permutation $pi$, the mapping between such factorizations and the joint distribution they categorical is many-to-one. As you’ll be able to see this within the picture under. The completely different factorizations induce a unique graph, however have the identical joint distribution.
Since you might be studying this put up, you could already bear in mind that in causal inference we frequently speak about a causal factorization, which appears to be like like
the place $mathrm{pa}(X_i)$ denotes the causal dad and mom of node $X_i$. That is one in every of many doable methods you’ll be able to factorize the joint distribution, however we take into account this one particular. Within the current work, Schölkopf et al. name it a disentangled mannequin. What are disentangled fashions? Disentangled components describe unbiased features of the mechanism that generated the info. And they aren’t unbiased since you factored them on this manner, however you had been searching for this factorization as a result of its components are unbiased.
In different phrases, for each joint distribution there are numerous doable factorizations, however we assume that just one, the causal or disentangled factorization, describes the true underlying course of that generated the info.
Let’s take into account an instance for disentangled fashions. We wish to mannequin the joint distribution of altitude $A$ and temperature $T$. On this case, the causal route is $A rightarrow T$ – if the altitude adjustments, the distribution of the temperature will change too. However you can not change the altitude by artificially heating a metropolis – in any other case all of us would get pleasure from views as in Miami; world warming is actual however luckily has no altitude-changing impact. Ultimately, we get the factorization of $p(A)p(T|A)$. The necessary insights listed below are the solutions to the query: What will we count on from these components? The previously-mentioned Schölkopf et al. paper calls the primary takeaway the Impartial Causal Mechanisms (ICM) Precept, i.e.
By conditioning on the dad and mom of any issue within the disentangled mannequin, the issue will neither have the ability to provide you with additional details about different components nor is ready to affect them.
Within the above instance, which means in case you take into account completely different nations with their altitude distributions, you’ll be able to nonetheless use the identical $p(T|A),$ i.e., the components generalize nicely. For no affect, the instance holds straight above the ICM Precept. Moreover, figuring out any of the components – e.g. $p(A)$ – will not inform something in regards to the different (no info). If you already know which nation you might be in, so can have no clue in regards to the local weather (in case you consulted the web site of the corresponding climate company, that is what I name dishonest). Within the different route, regardless of being the top-of-class pupil in local weather issues, you will not have the ability to inform the nation if any person says to you that right here the altitude is 350 meters and the temperature is 7°C!
Statistical vs causal inference
We mentioned Markov factorizations, as they assist us perceive the philosophical distinction between statistical and causal inference. The sweetness, and a supply of confusion, is that one can use Markov factorizations in each paradigms.
Nonetheless, whereas utilizing Markov factorizations is elective for statistical inference, it’s a should for causal inference.
So why would a statistical inference individual use Markov factorizations? As a result of they make life simpler within the sense that you do not want to fret about too excessive electricty prices. Particularly, factorized fashions of knowledge may be computationally rather more environment friendly. As an alternative of modeling a joint distribution straight, which has a whole lot of parameters – within the case of $n$ binary variables, that’s $2^n-1$ completely different values -, a factorized model may be fairly light-weight and parameter-efficient. If you’ll be able to factorize the joint in a manner that you’ve 8 components with $n/8$ variables every, then you’ll be able to describe your mannequin with $8times2^{n/8}-1$ parameters. If $n=16$, that’s $65,535$ vs $31$. Equally, representing your distibution in a factorized kind offers rise to environment friendly, general-purpose message-passing algorithms, akin to perception propagation or expectation propagation.
However, causal inference folks actually need this, in any other case, they’re misplaced. As a result of with out Markov factorizations, they can’t actually formulate causal claims.
A causal practicioner makes use of Markov factorizations, as a result of this fashion she is ready to motive about interventions.
When you don’t have the disentangled factorization, you can not mannequin the impact of interventions on the actual mechanisms that make the system tick.
Connection to area adaptation
In plain machine studying lingo, what you wish to do is area adaptation, that’s, you wish to draw conclusions a couple of distribution you didn’t observe (these are the interventional ones). The Markov factorization prescribes methods wherein you count on the distribution to alter – one issue at a time – and thus the set of distributions you need to have the ability to robustly generalise to or draw inferences about.
Do calculus
Do-caclculus, the subject of the first put up within the sequence, may be comparatively merely described utilizing Markov factorizations. As you keep in mind, $mathrm{do}(X=x)$ implies that we set the variable $X$ to the worth $x$, which means that the distribution of that variable $p(X)$ collapses to a degree mass. We are able to mannequin this intervention mathematically by changing the issue $p( x vert mathrm{pa}(X))$ by a Dirac-delta $delta_x$, ensuing within the deletion of all incoming edges of the intervened components within the graphical mannequin. We then marginalise over $x$ to calculate the joint distribution of the remaining variables. For instance, if we’ve got two variables $x$ and $y$ we will write:
SEMs, Markov factorization, and the reparamtrization trick
When you’ve learn the earlier components on this sequence, you will know that Markov factorizations aren’t the one software we use in causal inference. For counterfactuals, we used structural equation fashions (SEMs). On this half we are going to illustrate the connection between these with a tacky reference to the reparametrization trick utilized in VAEs amongst others.
However earlier than that, let’s recap SEMs. On this case, you outline the connection between the kid node and its dad and mom by way of a practical project. For node $X$ with dad and mom $mathrm{pa}(X)$ it has the type of
$$ X = f(mathrm{pa}(X), epsilon), $$
with some noise $epsilon.$ Right here, you must learn “=” within the sense of an assigment (like in Python), in arithmetic, this ought to be “:=”. The above equation expresses the conditional likelihood $ pleft(X| mathrm{pa}(X)proper)$ as a deterministic operate of $X$ and a few noise variable $epsilon$. Wait a second…, is not it the identical factor what the reparametrization trick does? Sure it’s.
So the SEM formulation (referred to as the implicit distribution) is expounded by way of the reparametrization trick to the conditional likelihood of $X$ given its dad and mom.
Lessons of causal fashions
Thus, we will say {that a} SEM is a conditional distribution, and vica versa. Okay, however how do the units of those constructs relate to one another? If in case you have a SEM, then you’ll be able to learn off the conditional, which is distinctive. However, yow will discover extra SEMs for a similar conditional. Simply as you’ll be able to categorical a conditional distribution in a number of other ways utilizing completely different reparametrizations, it’s doable to precise the identical Markov factorization by a number of SEMs. Think about for instance that in case your distribution is $mathcal{N}(mu,sigma),$ then multiplying it by -1 offers you a similar distribution. On this sense, SEMs are a richer class of fashions than Markov factorizations, thus they permit us to make inferences (counterfactual) which we weren’t capable of categorical within the extra coarse grained language of Markov Factorizations.
As we mentioned above, a single joint distribution has a number of legitimate Markov factorizations, and the identical Markov factorization may be expressed as completely different SEMs. We are able to consider joint distributions, Markov factorizations, and SEMs as more and more fine-grained mannequin lessons: joint distributions $subset$ Markov facorizations $subset$ SEMs. The extra features of the info producing course of you mannequin, the extra elaborate the set of inferences you can also make change into. Thus, Joint distributions will let you make predictions underneath no mechanism shift, Markov factorizations will let you mannequin interventions, SEMs will let you make counterfactual statements.
The worth you pay for extra expressive fashions is that additionally they get typically a lot tougher to estimate from knowledge. In truth, some features of causal fashions are unimaginable to deduce from i.i.d. observational knowledge. Furthermore, some counterfactual inferences are experimentally not verifiable.
We’re happy to announce the brand new “Getting ready to your group’s AI workloads” Microsoft Study Plan – targeted the IT/Ops viewers and now obtainable on Microsoft Study!
This set of content material was curated by our crew and is focused at serving to IT Professionals who need to discover ways to help their group’s AI functions and infrastructure. The Studying Plan consists of 4 milestones, which in its flip are composed of a complete of twenty-two modules:
This complete plan introduces foundational AI ideas, then guides you thru superior matters. Whether or not you are an IT administrator, safety specialist, or AI practitioner, this plan equips you with the abilities to construct trusted, safe, and compliant AI options at scale.
We hope you get pleasure from studying! Tell us what you consider this content material within the remark part beneath! If you would like to see extra of this kind of content material, or have any recommendations, tell us as properly!
Why Information Extraction Is the First Domino in Enterprise AI Automation
Enterprises as we speak face an information paradox: whereas info is plentiful, actionable, structured knowledge is scarce. This problem is a significant bottleneck for AI brokers and huge language fashions (LLMs). Automated knowledge extraction solves this by appearing because the enter layer for each AI-driven workflow. It programmatically converts uncooked knowledge—from paperwork, APIs, and net pages—right into a constant, machine-readable format, enabling AI to behave intelligently.
The truth, nonetheless, is that many organizations nonetheless rely on guide knowledge wrangling. Analysts retype vendor bill particulars into ERP programs, ops workers obtain and clear CSV exports, and compliance groups copy-paste content material from scanned PDFs into spreadsheets. Guide knowledge wrangling creates two critical dangers: sluggish decision-making and pricey errors that ripple via downstream automations or trigger mannequin hallucinations.
Automation solves these issues by delivering sooner, extra correct, and extra scalable extraction. Methods can normalize codecs, deal with various inputs, and flag anomalies way more constantly than human groups. Information extraction is now not an operational afterthought — it’s an enabler of analytics, compliance, and now, clever automation.
This information explores that enabler in depth. From totally different knowledge sources (structured APIs to messy scanned paperwork) to extraction methods (regex, ML fashions, LLMs), we’ll cowl the strategies and trade-offs that matter. We’ll additionally look at agentic workflows powered by extraction and find out how to design a scalable knowledge ingestion layer for enterprise AI.
What Is Automated Information Extraction?
If knowledge extraction is the primary domino in AI automation, then automated knowledge extraction is the mechanism that makes that domino fall constantly, at scale. At its core, it refers back to the programmatic seize and conversion of knowledge from any supply into structured, machine-usable codecs — with minimal human intervention.
Consider extraction because the workhorse behind ingestion pipelines: whereas ingestion brings knowledge into your programs, extraction is the method that parses, labels, and standardizes uncooked inputs—from PDFs or APIs—into structured codecs prepared for downstream use. With out clear outputs from extraction, ingestion turns into a bottleneck and compromises automation reliability.
In contrast to guide processes the place analysts reformat spreadsheets or copy values from paperwork, automated extraction programs are designed to ingest knowledge constantly and reliably throughout a number of codecs and programs.
🌐 The Supply Spectrum of Information Extraction
Not all knowledge seems the identical, and never all extraction strategies are equal. In observe, enterprises encounter 4 broad classes:
Structured sources — APIs, relational databases, CSVs, SQL-based finance ledgers or CRM contact lists the place info already follows a schema. Extraction right here typically means standardizing or syncing knowledge quite than deciphering it.
Semi-structured sources — XML or JSON feeds, ERP exports, or spreadsheets with inconsistent headers. These require parsing logic that may adapt as buildings evolve.
Unstructured sources — PDFs, free-text emails, log recordsdata, net pages, and even IoT sensor streams. These are essentially the most difficult, typically requiring a mixture of NLP, sample recognition, and ML fashions to make sense of irregular inputs.
Paperwork as a particular case — These mix format complexity and unstructured content material, requiring specialised strategies. Coated in depth later.
🎯 Strategic Targets of Automation
Automated knowledge extraction isn’t nearly comfort — it’s about enabling enterprises to function on the pace and scale demanded by AI-led automation. The targets are clear:
Scalability — deal with tens of millions of data or 1000’s of recordsdata with out linear will increase in headcount.
Velocity — allow real-time or near-real-time inputs for AI-driven workflows.
Accuracy — cut back human error and guarantee consistency throughout codecs and sources.
Lowered guide toil — release analysts, ops, and compliance workers from repetitive, low-value knowledge duties.
When these targets are achieved, AI brokers cease being proof-of-concept demos and begin changing into trusted programs of motion.
Information Varieties and Sources — What Are We Extracting From?
Defining automated knowledge extraction is one factor; implementing it throughout the messy actuality of enterprise programs is one other. The problem isn’t simply quantity — it’s selection.
Information hides in databases, flows via APIs, clogs electronic mail inboxes, will get trapped in PDFs, and is emitted in streams from IoT sensors. Every of those sources calls for a distinct method, which is why profitable extraction architectures are modular by design.
🗂️ Structured Methods
Structured knowledge sources are essentially the most easy to extract from as a result of they already observe outlined schemas. Relational databases, CRM programs, and APIs fall into this class.
Relational DBs: A monetary companies agency would possibly question a Postgres database to extract every day FX commerce knowledge. SQL queries and ETL instruments can deal with this at scale.
APIs: Fee suppliers like Stripe or PayPal expose clear JSON payloads for transactions, making extraction nearly trivial.
CSV exports: BI platforms typically generate CSV recordsdata for reporting; extraction is so simple as ingesting these into an information warehouse.
Right here, the extraction problem isn’t technical parsing however knowledge governance — guaranteeing schemas are constant throughout programs and time.
📑 Semi-Structured Feeds
Semi-structured sources sit between predictable and chaotic. They carry some group however lack inflexible schemas, making automation brittle if codecs change.
ERP exports: A NetSuite or SAP export would possibly include vendor cost schedules, however discipline labels differ by configuration.
XML/JSON feeds: E-commerce websites ship order knowledge in JSON, however new product classes or attributes seem unpredictably.
Spreadsheets: Gross sales groups typically keep Excel recordsdata the place some columns are constant, however others differ regionally.
Extraction right here typically depends on parsers (XML/JSON libraries) mixed with machine studying for schema drift detection. For instance, an ML mannequin would possibly flag that “supplier_id” and “vendor_number” confer with the identical discipline throughout two ERP situations.
🌐 Unstructured Sources
Unstructured knowledge is essentially the most plentiful — and essentially the most tough to automate.
Internet scraping: Pulling competitor pricing from retail websites requires HTML parsing, dealing with inconsistent layouts, and bypassing anti-bot programs.
Logs: Cloud purposes generate large logs in codecs like JSON or plaintext, however schemas evolve continuously. Safety logs as we speak might embrace fields that didn’t exist final month, complicating automated parsing.
Emails and chats: Buyer complaints or assist tickets hardly ever observe templates; NLP fashions are wanted to extract intents, entities, and priorities.
The most important problem is context extraction. In contrast to structured sources, the which means isn’t apparent, so NLP, classification, and embeddings typically complement conventional parsing.
📄 Paperwork as a Specialised Subset
Paperwork deserve particular consideration inside unstructured sources. Invoices, contracts, supply notes, and medical types are frequent enterprise inputs however mix textual content, tables, signatures, and checkboxes.
Invoices: Line objects might shift place relying on vendor template.
Contracts: Key phrases like “termination date” or “jurisdiction” conceal in free textual content.
Insurance coverage types: Accident claims might embrace each handwriting and printed checkboxes.
Extraction right here sometimes requires OCR + layout-aware fashions + enterprise guidelines validation. Platforms like Nanonets specialise in constructing these doc pipelines as a result of generic NLP or OCR alone typically falls quick.
🚦 Why Modularity Issues
No single method can deal with all of those sources. Structured APIs could be dealt with with ETL pipelines, whereas scanned paperwork require OCR, and logs demand schema-aware streaming parsers. Enterprises that attempt to force-fit one method shortly hit failure factors.
As an alternative, fashionable architectures deploy modular extractors — every tuned to its supply sort, however unified via frequent validation, monitoring, and integration layers. This ensures extraction isn’t simply correct in isolation but in addition cohesive throughout the enterprise.
Automated Information Extraction Methods — From Regex to LLMs
Figuring out the place knowledge resides is barely half the problem. The following step is knowing how to extract it. Extraction strategies have advanced dramatically over the past twenty years — from brittle, rule-based scripts to stylish AI-driven programs able to parsing multimodal sources. Right this moment, enterprises typically depend on a layered toolkit that mixes the most effective of conventional, machine studying, and LLM-based approaches.
🏗️ Conventional Strategies: Guidelines, Regex, and SQL
Within the early days of enterprise automation, extraction was dealt with primarily via rule-based parsing.
Regex (Common Expressions): A standard method for pulling patterns out of textual content. For instance, extracting electronic mail addresses or bill numbers from a physique of textual content. Regex is exact however brittle — small format modifications can break the principles.
Rule-based parsing: Many ETL (Extract, Rework, Load) programs rely on predefined mappings. For instance, a financial institution would possibly map “Acct_Num” fields in a single database to “AccountID” in one other.
SQL queries and ETL frameworks: In structured programs, extraction typically seems like working a SQL question to drag data from a database, or utilizing an ETL framework (Informatica, Talend, dbt) to maneuver and remodel knowledge at scale.
Internet scraping: For semi-structured HTML, libraries like BeautifulSoup or Scrapy permit enterprises to extract product costs, inventory ranges, or evaluations. However as anti-bot protections advance, scraping turns into fragile and resource-intensive.
These approaches are nonetheless related the place construction is steady — for instance, extracting fixed-format monetary reviews. However they lack flexibility in dynamic, real-world environments.
🤖 ML-Powered Extraction: Studying Patterns Past Guidelines
Machine studying introduced a step-change by permitting programs to study from examples as an alternative of relying solely on brittle guidelines.
NLP & NER fashions: Named Entity Recognition (NER) fashions can establish entities like names, dates, addresses, or quantities in unstructured textual content. As an illustration, parsing resumes to extract candidate abilities.
Structured classification: ML classifiers can label sections of paperwork (e.g., “bill header” vs. “line merchandise”). This permits programs to adapt to format variance.
Doc-specific pipelines: Clever Doc Processing (IDP) platforms mix OCR + format evaluation + NLP. A typical pipeline:
OCR extracts uncooked textual content from a scanned bill.
Structure fashions detect bounding bins for tables and fields.
Enterprise guidelines or ML fashions label and validate key-value pairs.
Clever Doc Processing (IDP) platforms illustrate how this method combines deterministic guidelines with ML-driven strategies to extract knowledge from extremely variable doc codecs.
The benefit of ML-powered strategies is adaptability. As an alternative of hand-coding patterns, you practice fashions on examples, they usually study to generalize. The trade-off is the necessity for coaching knowledge, suggestions loops, and monitoring.
🧠 LLM-Enhanced Extraction: Language Fashions as Orchestrators
With the rise of huge language fashions, a brand new paradigm has emerged: LLMs as extraction engines.
Immediate-based extraction: By fastidiously designing prompts, you may instruct an LLM to learn a block of textual content and return structured JSON (e.g., “Extract all product SKUs and costs from this electronic mail”). Instruments like LangChain formalize this into workflows.
Perform-calling and gear use: Some LLMs assist structured outputs (e.g., OpenAI’s function-calling), the place the mannequin fills outlined schema slots. This makes the extraction course of extra predictable.
Agentic orchestration: As an alternative of simply extracting, LLMs can act as controllers — deciding whether or not to parse straight, name a specialised parser, or flag low-confidence circumstances for human evaluate. This blends flexibility with guardrails.
LLMs shine when dealing with long-context paperwork, free-text emails, or heterogeneous knowledge sources. However they require cautious design to keep away from “black-box” unpredictability. Hallucinations stay a threat. With out grounding, LLMs would possibly fabricate values or misread codecs. That is particularly harmful in regulated domains like finance or healthcare.
🔀 Hybrid Architectures: Better of Each Worlds
The best fashionable programs as we speak hardly ever select one method. As an alternative, they undertake hybrid architectures:
LLMs + deterministic parsing: An LLM routes the enter — e.g., detecting whether or not a file is an bill, log, or API payload — after which palms off to the suitable specialised extractor (regex, parser, or IDP).
Validation loops: Extracted knowledge is validated in opposition to enterprise guidelines (e.g., “Bill totals should equal line-item sums”, or “e-commerce value fields should fall inside historic ranges”).
Human-in-the-loop: Low-confidence outputs are escalated to human reviewers, and their corrections feed again into mannequin retraining.
This hybrid method maximizes flexibility with out sacrificing reliability. It additionally ensures that when brokers devour extracted knowledge, they’re not relying blindly on a single, failure-prone methodology.
⚡ Why This Issues for Enterprise AI
For AI brokers to behave autonomously, their notion layer have to be strong.
Regex alone is simply too inflexible, ML alone might battle with edge circumstances, and LLMs alone can hallucinate. However collectively, they kind a resilient pipeline that balances precision, adaptability, and scalability.
Amongst all these sources, paperwork stay essentially the most error-prone and least predictable — demanding their very own extraction playbook.
Deep Dive — Doc Information Extraction
Of all the info sources enterprises face, paperwork are constantly the toughest to automate. In contrast to APIs or databases with predictable schemas, paperwork arrive in 1000’s of codecs, riddled with visible noise, format quirks, and inconsistent high quality. A scanned bill might look totally different from one vendor to a different, contracts might conceal essential clauses in dense paragraphs, and handwritten notes can throw off even essentially the most superior OCR programs.
⚠️ Why Paperwork Are So Laborious to Extract From
Structure variability: No two invoices, contracts, or types look the identical. Fields shift place, labels change wording, and new templates seem continuously.
Visible noise: Logos, watermarks, stamps, or handwritten notes complicate recognition.
Scanning high quality: Blurry, rotated, or skewed scans can degrade OCR accuracy.
Multimodal content material: Paperwork typically mix tables, paragraphs, signatures, checkboxes, and pictures in the identical file.
These elements make paperwork a worst-case situation for rule-based or template-based approaches, demanding extra adaptive pipelines.
🔄 The Typical Doc Extraction Pipeline
Trendy doc knowledge extraction follows a structured pipeline:
OCR (Optical Character Recognition): Converts scanned photographs into machine-readable textual content.
Structure evaluation: Detects visible buildings like tables, columns, or bounding bins.
Key-value detection: Identifies semantic pairs similar to “Bill Quantity → 12345” or “Due Date → 30 Sept 2025.”
Validation & human evaluate: Extracted values are checked in opposition to enterprise guidelines (e.g., totals should match line objects) and low-confidence circumstances are routed to people for verification.
This pipeline is powerful, but it surely nonetheless requires ongoing monitoring to maintain tempo with new doc templates and edge circumstances.
🤖 Superior Fashions for Context-Conscious Extraction
To maneuver past brittle guidelines, researchers have developed vision-language fashions that mix textual content and format understanding.
LayoutLM, DocLLM, and associated fashions deal with a doc as each textual content and picture, capturing positional context. This permits them to grasp {that a} quantity inside a desk labeled “Amount” means one thing totally different than the identical quantity in a “Complete” row.
Imaginative and prescient-language transformers can align visible options (shapes, bins, logos) with semantic which means, bettering extraction accuracy in noisy scans.
These fashions don’t simply “learn” paperwork — they interpret them in context, a significant leap ahead for enterprise automation.
🧠 Self-Enhancing Brokers for Doc Workflows
The frontier in doc knowledge extraction is self-improving agentic programs. Latest analysis explores combining LLMs + reinforcement studying (RL) to create brokers that:
Try extraction.
Consider confidence and errors.
Be taught from corrections over time.
In observe, this implies each extraction error turns into coaching knowledge. Over weeks or months, the system improves robotically, decreasing guide oversight.
This shift is essential for industries with excessive doc variability — insurance coverage claims, healthcare, and international logistics — the place no static mannequin can seize each attainable format.
🏢 Nanonets in Motion: Multi-Doc Claims Workflows
Doc-heavy industries like insurance coverage spotlight why specialised extraction is mission-critical. A claims workflow might embrace:
Accident report types (scanned and handwritten).
Car inspection images embedded in PDFs.
Restore store invoices with line-item variability.
Coverage paperwork in blended digital codecs.
Nanonets builds pipelines that mix OCR, ML-based format evaluation, and human-in-the-loop validation to deal with this complexity. Low-confidence extractions are flagged for evaluate, and human corrections movement again into the coaching loop. Over time, accuracy improves with out requiring rule rewrites for each new template.
This method permits insurers to course of claims sooner, with fewer errors, and at decrease value — all whereas sustaining compliance.
⚡ Why Paperwork Deserve Their Personal Playbook
In contrast to structured and even semi-structured knowledge, paperwork resist one-size-fits-all strategies. They require devoted pipelines, superior fashions, and steady suggestions loops. Enterprises that deal with paperwork as “simply one other supply” typically see initiatives stall; people who spend money on document-specific extraction methods unlock pace, accuracy, and downstream AI worth.
Actual-World AI Workflows That Rely on Automated Extraction
Beneath are real-world enterprise workflows the place AI brokers rely on a dependable, structured knowledge extraction layer:
Workflow
Inputs
Extraction Focus
AI Agent Output / Final result
Claims processing
Accident reviews, restore invoices, coverage docs
OCR + format evaluation for types, line-item parsing in invoices, clause detection in insurance policies
Automated actions when confidence is excessive; human-in-loop evaluate when low
RAG-enabled workflows
Extracted contract clauses, information base snippets
Structured snippet retrieval + grounding
LLM solutions grounded in extracted reality; decreased hallucination
Throughout these industries, a transparent workflow sample emerges: Extraction → Validation → Agentic Motion. The standard of this movement is essential. Excessive-confidence, structured knowledge empowers brokers to behave autonomously. When confidence is low, the system defers—pausing, escalating, or requesting clarification—guaranteeing human oversight solely the place it is actually wanted.
This modular method ensures that brokers don’t simply devour knowledge, however reliable knowledge — enabling pace, accuracy, and scale.
Constructing a Scalable Automated Information Extraction Layer
All of the workflows described above rely on one basis: a scalable knowledge extraction layer. With out it, enterprises are caught in pilot purgatory, the place automation works for one slim use case however collapses as quickly as new codecs or larger volumes are launched.
To keep away from that lure, enterprises should deal with automated knowledge extraction as infrastructure: modular, observable, and designed for steady evolution.
🔀 Construct vs Purchase: Choosing Your Battles
Not each extraction downside must be solved in-house. The hot button is distinguishing between core extraction — capabilities distinctive to your area — and contextual extraction, the place current options could be leveraged.
Core examples: A financial institution creating extraction for regulatory filings, which require domain-specific experience and compliance controls.
Contextual examples: Parsing invoices, buy orders, or IDs — issues solved repeatedly throughout industries the place platforms like Nanonets present pre-trained pipelines.
A sensible technique is to purchase for breadth, construct for depth. Use off-the-shelf options for commoditized sources, and make investments engineering time the place extraction high quality differentiates what you are promoting.
⚙️ Platform Design Rules
A scalable extraction layer isn’t just a set of scripts — it’s a platform. Key design parts embrace:
API-first structure: Each extractor (for paperwork, APIs, logs, net) ought to expose standardized APIs so downstream programs can devour outputs constantly.
Modular extractors: As an alternative of 1 monolithic parser, construct unbiased modules for paperwork, net scraping, logs, and many others., orchestrated by a central routing engine.
Schema versioning: Information codecs evolve. By versioning output schemas, you guarantee downstream shoppers don’t break when new fields are added.
Metadata tagging: Each extracted document ought to carry metadata (supply, timestamp, extractor model, confidence rating) to allow traceability and debugging.
🔄 Resilience: Adapting to Change
Your extraction layer’s biggest enemy is schema drift—when codecs evolve subtly over time.
A vendor modifications bill templates.
A SaaS supplier updates API payloads.
An internet web page shifts its HTML construction.
With out resilience, these small shifts cascade into damaged pipelines. Resilient architectures embrace:
Adaptive parsers that may deal with minor format modifications.
Fallback logic that escalates sudden inputs to people.
Suggestions loops the place human corrections are fed again into coaching datasets for steady enchancment.
This ensures the system doesn’t simply work as we speak — it will get smarter tomorrow.
📊 Observability: See What Your Extraction Layer Sees
Extraction shouldn’t be a black field. Treating it as such—with knowledge going out and in with no visibility—is a harmful oversight.
Observability ought to lengthen to per-field metrics — confidence scores, failure charges, correction frequency, and schema drift incidents. These granular insights drive selections round retraining, enhance alerting, and assist hint points when automation breaks. Dashboards visualizing this telemetry empower groups to constantly tune and show the reliability of their extraction layer.
Confidence scores: Each extracted discipline ought to embrace a confidence estimate (e.g., 95% sure that is the bill date).
Error logs: Mis-parsed or failed extractions have to be tracked and categorized.
Human corrections: When reviewers repair errors, these corrections ought to movement again into monitoring dashboards and retraining units.
With observability, groups can prioritize the place to enhance and show compliance — a necessity in regulated industries.
⚡ Why This Issues
Enterprises can’t scale AI by stitching collectively brittle scripts or advert hoc parsers. They want an extraction layer that’s architected like infrastructure: modular, observable, and constantly bettering.
Conclusion
AI brokers, LLM copilots, and autonomous workflows would possibly really feel like the longer term — however none of them work with out one essential layer: dependable, structured knowledge.
This information has explored the various sources enterprises extract knowledge from — APIs, logs, paperwork, spreadsheets, and sensor streams — and the number of methods used to extract, validate, and act on that knowledge. From claims to contracts, each AI-driven workflow begins with one functionality: dependable, scalable knowledge extraction.
Too typically, organizations make investments closely in orchestration and modeling — solely to search out their AI initiatives fail as a consequence of unstructured, incomplete, or poorly extracted inputs. The message is evident: your automation stack is barely as sturdy as your automated knowledge extraction layer.
That’s why extraction needs to be handled as strategic infrastructure — observable, adaptable, and constructed to evolve. It’s not a short lived preprocessing step. It’s a long-term enabler of AI success.
Begin by auditing the place your most crucial knowledge lives and the place human wrangling remains to be the norm. Then, spend money on a scalable, adaptable extraction layer. As a result of on the earth of AI, automation does not begin with motion—it begins with entry.
FAQs
What’s the distinction between knowledge ingestion and knowledge extraction in enterprise AI pipelines?
Information ingestion is the method of gathering and importing knowledge from varied sources into your programs — whether or not APIs, databases, recordsdata, or streams. Extraction, however, is what makes that ingested knowledge usable. It includes parsing, labeling, and structuring uncooked inputs (like PDFs or logs) into machine-readable codecs that downstream programs or AI brokers can work with. With out clear extraction, ingestion turns into a bottleneck, introducing noise and unreliability into the automation pipeline.
What are greatest practices for validating extracted knowledge in agent-driven workflows?
Validation needs to be tightly coupled with extraction — not handled as a separate post-processing step. Widespread practices embrace making use of enterprise guidelines (e.g., “bill totals should match line-item sums”), schema checks (e.g., anticipated fields or clause presence), and anomaly detection (e.g., flagging values that deviate from norms). Outputs with confidence scores beneath a threshold needs to be routed to human reviewers. These corrections then feed into coaching loops to enhance extraction accuracy over time.
How does the extraction layer affect agentic decision-making in manufacturing?
The extraction layer acts because the notion system for AI brokers. When it gives high-confidence, structured knowledge, brokers could make autonomous selections — similar to approving funds or routing claims. But when confidence is low or inconsistencies come up, brokers should escalate, defer, or request clarification. On this method, the standard of the extraction layer straight determines whether or not an AI agent can act independently or should search human enter.
What observability metrics ought to we observe in an enterprise-grade knowledge extraction platform?
Key observability metrics embrace:
Confidence scores per extracted discipline.
Success and failure charges throughout extraction runs.
Schema drift frequency (how typically codecs change).
Correction charges (how typically people override automated outputs).These metrics assist hint errors, information retraining, establish brittle integrations, and keep compliance — particularly in regulated domains.
Android Central’s Editor’s Desk is a weekly column discussing the most recent information, developments, and happenings within the Android and cellular tech house.
A runner I’m not. I spend a number of time on the health club, understanding and lifting weights a number of occasions every week, however cardio and working are the bane of my existence. I by no means fairly understood how and why anybody would take pleasure in working. Why topic your self to that?
Nevertheless, for the previous couple of months, I’ve been utilizing the Pixel Watch 3 and the Fitbit app to do exactly that. Regardless of my higher judgment, I made a decision it’s time to vary my routine, spending almost each morning working to see how I can enhance the period and distance of my runs.
To do that, I’ve been using the AI-powered day by day run suggestions within the Fitbit app. I’ve been curious to see whether or not these suggestions are actually useful or if it’s simply one other glorified AI function with no actual rhyme or motive to its strategies. Seems, this might really be a incredible software for newcomers like me, making the couch-to-5K journey rather less daunting.
Getting began
(Picture credit score: Andrew Myrick / Android Central)
It’s vital to notice that day by day AI run suggestions are solely obtainable to Fitbit Premium subscribers. Should you purchase a new Pixel Watch, it’s possible that you just acquired a free trial, so that you would possibly wish to examine on that in the event you’re not already a subscriber.
After that, AI-run suggestions ought to begin showing within the Coach tab. Nevertheless, you may all the time change your preferences by tapping the See all button subsequent to As we speak’s run, then tapping the three-dot menu within the high nook. Right here, you may disable day by day run exercises, alter your working degree or focus, and alter your distance days to give attention to longer runs.
Gradual and regular
(Picture credit score: Derrek Lee / Android Central)
I used to be initially nervous about beginning a working “plan.” My earlier expertise with a Garmin plan was a bit too intense for me, and I couldn’t sustain, so I went into this cautiously. It’s vital to notice that this isn’t a working “plan,” per se, so I couldn’t see forward to what my runs would appear to be. The Fitbit app would take my earlier exercise information in addition to my goal load to floor a brand new advice for me every day.
Whereas a viewable exercise plan of some type can be good, what I like about this function is that the exercises really feel like they’re completely tailor-made to me and my capabilities. Going into this, I may solely comfortably run a few mile earlier than I might tire and need to cease. Due to this fact, based mostly on what Fitbit is aware of about me and my targets, it was in a position to get me began with some very straightforward runs.
Get the most recent information from Android Central, your trusted companion on this planet of Android
(Picture credit score: Derrek Lee / Android Central)
These runs would differ every day, sometimes between a straightforward run and a tempo run, with the previous preserving me at a comparatively reasonable coronary heart price and the latter pushing me right into a extra vigorous coronary heart price zone. The period of the runs additionally varies, from shorter 18-minute runs to longer 40-minute runs.
That stated, even the shorter runs challenged me, as I might beforehand common about 10 minutes earlier than I known as it quits. Nevertheless, this was a really manageable problem, as I had a goal coronary heart price vary that I must keep. This helped me handle by respiration extra successfully, whereas additionally reminding me that I would not have to run as quick as I can on a regular basis; I can take my time at a gradual tempo to maintain me going for an extended time period.
Moreover, Fitbit would additionally combine issues up so the intervals have been all the time completely different from everyday. Generally it will have me do a single run for a sure time period, or it will break up my run, beginning me off slower and steadily pushing me to run sooner, or having me keep a sooner tempo however for brief intervals with even shorter relaxation intervals between them. This helped me get used to pacing myself whereas serving to me construct my endurance and mileage.
(Picture credit score: Derrek Lee / Android Central)
The very best half is that you just don’t need to comply with every run precisely because it seems. There’s a Customise run button on the backside of every advice, the place you may take away warm-ups and cool-downs, delete or transfer intervals round, add intervals, and even edit the depth of every interval. That stated, I not often discovered a necessity for this and simply adopted every advice because it was given to me.
As I famous earlier than, after I first began this simply a few months in the past, I may barely run for multiple mile with out tiring myself out. Now, I’m persistently and comfortably working two to a few miles per day, and my tempo has additionally improved to only underneath 12 minutes per mile.
Do I really like working now? Positively not. However I do not dislike it as a lot as I used to.
The place Google can enhance
(Picture credit score: Derrek Lee / Android Central)
Whereas every really useful run explains why it should profit you earlier than you begin it, I do want there was some form of built-in AI abstract for post-run evaluations. You possibly can view and examine charts in addition to kind evaluation to gauge how environment friendly your working is, however having one thing to summarize the info in an easy-to-consume approach would assist me work out the place and find out how to enhance.
You possibly can all the time share the post-run information with Gemini, however the expertise isn’t very seamless, and Gemini’s responses are a bit common.
(Picture credit score: Derrek Lee / Android Central)
I additionally want run strategies would seem on the Pixel Watch. Proper now, I can faucet the Begin run button within the Fitbit smartphone app, and it’ll ship it to the Pixel Watch 3, the place I can simply faucet the Begin button. Nevertheless, that is the extent of its presence on the watch, as AI run suggestions usually are not even viewable on the Fitbit Put on OS app.
This might be an ideal alternative to boost the Morning Transient function, which feels fairly ineffective in its present kind. Garmin watches just like the Venu 4 embody day by day exercise strategies within the Morning Report, whether or not or not you might have a plan in place, so it seems like a missed alternative on the Pixel Watch.
I am enthusiastic about what’s to come back
(Picture credit score: Google)
In fact, working is simply a part of my day by day routine now, as I additionally spend a number of time weightlifting. Nevertheless, Fitbit’s Coach tab merely surfaces numerous exercises I can do. Whereas they’re based mostly on my day by day readiness and exercise preferences, it is merely a set of video exercises I can comply with, and there doesn’t appear to be a lot rhyme or motive to their suggestions.
For this reason I’m excited for the upcoming Private Well being Coach, which can use AI to supply extra dynamic health suggestions. And never solely will you be capable to converse with the AI for strategies, nevertheless it seems that it’s going to take all of your information into consideration to supply really personalised health steering.
To obtain day by day run suggestions, you have to be subscribed to Fitbit Premium. The function is out there by way of the Coach tab within the Fitbit app.
Can customers customise the AI run suggestions?
Sure, in the event you do not just like the advised run, you may select from a brief listing of different advised runs or customise the day by day really useful run by tapping the Customise run button on the backside. You may also customise your preferences reminiscent of your working degree, private targets, and future days.
Is that this the identical because the Private Well being Coach?
No, Fitbit’s day by day run suggestions are already obtainable within the Fitbit app. The Private Well being Coach is an upcoming AI function that will likely be an integral a part of the revamped Fitbit app expertise, which can go into preview someday in October, 2025.
We’re beginning to unpick the genetics of fibromyalgia, a poorly understood situation that causes power ache all around the physique. The outcomes of two research – with thousands and thousands of individuals between them – help the concept that dysfunction within the central nervous system is a significant component in fibromyalgia. Nonetheless, earlier analysis suggests different mechanisms, equivalent to autoimmunity, are concerned, hinting on the situation’s multi-causal complexity.
To know the position of genetics, two units of researchers have carried out genome-wide affiliation research to establish genetic variants which might be extra frequent in folks with fibromyalgia. Each research centered solely on variations to single letters within the genome, somewhat than different variants, equivalent to large-scale deletions, which might have a extra dramatic impact.
The primary examine – led by Michael Wainberg at Mount Sinai Hospital in Toronto, Canada – pulled collectively cohorts from a number of nations, together with the US, the UK and Finland. The staff amassed a complete of 54,629 folks with fibromyalgia, most of whom have been of European ancestry, and a couple of,509,126 folks with out the situation. From this, the researchers recognized 26 variants within the genome related to the next fibromyalgia threat.
Joel Gelernter at Yale Faculty of Drugs led the second examine, which used datasets from the US and UK. Altogether, Gelernter and his colleagues checked out 85,139 folks with fibromyalgia and 1,642,433 folks with out it, who had a mixture of European, Latin American and African ancestries. They discovered 10 variants related to fibromyalgia within the European ancestry group, one within the African ancestry group and 12 that have been cross-ancestry.
Wainberg and Gelernter declined to be interviewed as a result of their research haven’t but been peer-reviewed.
“Each research, by way of pattern dimension, are actually nice,” says Cindy Boer at Erasmus Medical Middle in Rotterdam, the Netherlands.
In Wainberg and his staff’s examine, the strongest affiliation was with a variant in a gene referred to as huntingtin, which might trigger the neurodegenerative situation Huntington’s illness. Nonetheless, this situation is attributable to a repeated genetic sequence inside huntingtin, resulting in the manufacturing of a faulty protein. In distinction, the variant linked to fibromyalgia is a single-letter change in a special a part of the gene.
However this doesn’t imply that this mutation alone causes fibromyalgia, says Boer. “It must be mixed with different threat elements or different genetics.” There are most likely 1000’s of variants at work, plus exterior influences, equivalent to air air pollution publicity, she says. Figuring out all these variants would require even bigger research.
Regardless of these shortcomings, the variants implicated in Wainberg and his staff’s examine have been all in genes which have roles in neurons, suggesting that most of the key mechanisms of fibromyalgia happen within the mind. Likewise, Gelernter and his staff’s examine recognized variants which have beforehand been linked to ache and brain-related points, equivalent to post-traumatic stress dysfunction and melancholy.
These outcomes solidify an current speculation about fibromyalgia: “there’s one thing occurring in mind tissues”, says Boer. Comply with-up work on the implicated variants might establish key cell varieties, mind areas and biochemical pathways, which might finally be focused for therapies. These are most likely a few years away, Boer warns – until it seems {that a} recognized mechanism, focused by an current drug, is implicated. Present interventions deal with train, speaking therapies and antidepressants, with blended success.
Nonetheless, mechanisms outdoors of genetics may additionally be at work. David Andersson at King’s School London and his staff have beforehand discovered proof that fibromyalgia is an autoimmune situation. In 2021, they confirmed that when antibodies from folks with fibromyalgia have been injected into mice, they developed painful hypersensitivity and muscle weak point. In September this yr, the researchers confirmed that such mice had irregular responses to sensations, with nerves that usually reply to mild contact beginning to answer chilly as effectively. This mirrors how folks with fibromyalgia usually really feel ache in response to stimuli that different folks don’t discover painful, equivalent to barely chilly temperatures.
“I’m very assured within the conclusions from our personal work on fibromyalgia, and sure that our revealed work would be the inflection level marking when the sector modified focus from the central nervous system to autoantibodies [that target the body’s own tissues] and peripheral neuronal [neurons that lie outside of the brain and spinal cord] mechanisms,” says Andersson.
However Boer stresses that the most recent research don’t invalidate that. The researchers set a excessive bar for statistical significance, so whereas we might be assured in regards to the variants they recognized, and the bodily mechanisms they implicate, they may have missed many extra, she says. Additionally, Gelernter and his staff’s examine recognized some variants which have been related to autoimmune responses.
Research like these are “first steps”, says Boer, however they open the opportunity of understanding the roots of fibromyalgia. “What are the pathways?” she asks. “And is there one thing in there that we will goal?”
Historical past isn’t at all times clear-cut. It’s written by anybody with the desire to write down it down and the discussion board to distribute it. It’s helpful to grasp completely different views and the contexts that created them. The evolution of the time period Information Science is an efficient instance.
I realized statistics within the Seventies in a division of behavioral scientists and educators relatively than a division of arithmetic. At the moment, the picture of statistics was framed by tutorial mathematical-statisticians. They wrote the textbooks and managed the jargon. Utilized statisticians had been the silent majority, a large group overshadowed by the tutorial celebrities. For me, studying Tukey’s 1977 e-book Exploratory Information Evaluation was a revelation. He got here from a background of mathematical statistics but wrote about utilized statistics, a really completely different animal.
My applied-statistics cohorts and I had been a various group—instructional statisticians, biostatisticians, geostatisticians, psychometricians, social statisticians, and econometricians, nary a mathematician within the group. We referred to ourselves collectively as data-scientists, a time period we heard from our professor. We had been all information scientists, regardless of our completely different instructional backgrounds, as a result of all of us labored with information. However the time period by no means caught and light away for through the years.
Feline crunching on quantity keys.
Utilized statistics had been crucial throughout World Warfare II, most notably in code breaking but in addition in navy purposes and extra mundane logistics and demographic analyses. After the warfare, the dominance of deterministic engineering evaluation grew and drew a lot of the public’s consideration. There have been many new applied sciences in shopper items and transportation, particularly aviation and the house race, so statistics wasn’t on most individuals’s radar. Statistics was thought of to be a discipline of arithmetic. The general public’s notion of a statistician was a mathematician, sporting a white lab coat, employed in a college arithmetic division, who was engaged on who-knows-what.
One of many applied sciences that got here out of WWII was ENIAC, which led to the IBM/360 mainframes of the early Sixties. These computer systems had been nonetheless big and sophisticated, however in comparison with ENIAC, fairly manageable. They had been a technological leap ahead and cheap sufficient to grow to be a part of most college campuses. Mainframes grew to become the mainstays of training. Utilized statisticians and programmers led the way in which; laptop rooms throughout the nation had been filled with them.
In 1962, John Tukey wrote in “The Way forward for Information Evaluation”
“For a very long time, I’ve thought I used to be a statistician, eager about inferences from the actual to the overall. However as I’ve watched mathematical statistics evolve, I’ve had trigger to surprise and to doubt…I’ve come to really feel that my central curiosity is in information evaluation, which I take to incorporate, amongst different issues: procedures for analyzing information, strategies for deciphering the outcomes of such procedures, methods of planning the gathering of knowledge to make its evaluation simpler, extra exact or extra correct, and all of the equipment and outcomes of (mathematical) statistics which apply to analyzing information.”
I learn that paper as a part of my graduate research. Maybe utilized statisticians noticed this paper as a chance to develop their very own id, other than determinism and arithmetic, and even mathematical statistics. But it surely actually wasn’t an organized motion, it simply advanced.
One in all my cohorts and I discussing information science.
In order my cohorts and I understood it, the time period data-sciences was actually simply an try to coin a collective noun for all of the number-crunching, simply as social-sciences was a collective noun for sociology. anthropology, and associated fields. The information sciences included any discipline that analyzed information,whatever the area specialization,versus pure mathematical manipulations. Mathematical statistics was NOT a knowledge science as a result of it didn’t contain information. Biostatistics, chemometrics, psychometrics, social and academic statistics, epidemiology, agricultural statistics, econometrics, and different purposes had been a part of information science. Enterprise statistics, outdoors of actuarial science, was just about nonexistent. There have been surveys however enterprise leaders most popular to name their very own photographs. Information-driven enterprise didn’t grow to be standard till the 21st century. But when it had been a considerable discipline, it will have been a knowledge science.
Laptop programming may need concerned managing information however to statisticians it was not a knowledge science as a result of it didn’t contain any evaluation of knowledge. There was no science concerned. On the time, it was referred to as information processing. It concerned getting information right into a database and reporting them, however not analyzing them additional. Naur (1974) had a unique perspective. Naur was a pc scientist who thought of information science to embody coping with present information, and never how the info had been generated or had been to be analyzed. This was simply the other of the view of utilized statisticians. Totally different views.
Programming within the Fifties and Sixties was evolving from the times of flipping switches on a mainframe behemoth, however was nonetheless just about restricted to Fortran, COBOL, and a little bit of Algol. There have been points with utilized statisticians doing all their very own programming. They tended to be much less environment friendly than programmers and had been typically unreliable. To paraphrase Dr. McCoy, I’m an utilized statistician not a pc programmer.” This philosophy was strengthened by British statistician Michael Healy when he mentioned:
No single statistician could be anticipated to have an in depth data of all points of statistics and this has penalties for employers. Statisticians flourish finest in groups—a lone utilized statistician is more likely to discover himself frequently pressured in opposition to the sides of his competence.
So when the late Sixties introduced statistical-software-packages, most notably BMDP and later SPSS and SAS, utilized statisticians had been in Heaven. Nonetheless, the statistical packages had been costly packages that would solely run on mainframes, so solely the federal government, universities, and main companies may afford their annual licenses, the mainframes to run them, and the operators to take care of the mainframes. I used to be lucky. My college had all the most important statistical packages that had been out there on the time, a few of which now not exist. We realized all of them, and never simply the coding. It was an actual training to see how the identical statistical procedures had been carried out within the completely different packages.
Ready for the mainframe to print out my evaluation.
All through the Seventies, statistical analyses had been executed on these big-as-dinosaurs, IBM/360 mainframe computer systems. They needed to be sequestered in their very own climate-controlled quarters, waited on command and reboot by a priesthood of system operators. No meals and no smoking allowed! Customers by no means bought to see the mainframes besides, possibly, by means of a small window within the locked door. They used magnetic tapes. I noticed ‘em.
Conducting a statistical evaluation was an concerned course of. To investigate a knowledge set, you first needed to write your individual packages. Some folks used standalone programming languages, often Fortran. Others used the languages of SAS or SPSS. There have been no GUIs (Graphical Person Interfaces) or code writing purposes. The statistical packages had been simpler to make use of than the programming languages however they had been nonetheless sophisticated
When you had handwritten the data-analysis program, you needed to wait in line for an out there keypunch machine so you may switch your program code and all of your information onto 3¼-by-7⅜-inch laptop punch-cards. After that, you waited so you may feed the playing cards by means of the mechanical card-reader. On an excellent day, it didn’t jam … a lot. Lastly, you waited for the mainframe to run your program and the printer to output your outcomes. Then the priesthood would switch the printouts to bins for pickup. Once you picked up your output typically all you bought was a web page of error codes. You needed to decipher the codes, determine what to do subsequent, and begin the method once more. Life wasn’t slower again then, it simply required extra ready.
Within the Seventies, private computer systems, or what would finally evolve into what we now know as PCs, had been like mammals in the course of the Jurassic interval, hiding in protected niches whereas the mainframe dinosaurs dominated. Earlier than 1974, most PCs had been constructed by hobbyists from kits. The MITS Altair is mostly acknowledged as the primary private laptop, though there are quite a lot of different claimants. Client-friendly PCs had been a decade away. (My first PC was a Radio Shack TRS-80, AKA Trash 80, that I bought in 1980; it didn’t do any statistics however I did be taught BASIC and phrase processing.) Large companies had their mainframes however smaller companies didn’t have any considerable computing energy till the mid-Eighties. By that point, statistical software program for PCs started to spring out of academia. There was a prepared market of utilized statisticians who realized on a mainframe utilizing SAS and SPSS however didn’t have them of their workplaces.
Feline PC watching feline mainframe.
Statistical evaluation modified loads after the Seventies. Punch playing cards and their supporting equipment grew to become extinct. Mainframes had been changing into an endangered species, having been exiled to specialty niches by PCs that would sit on a desk. Safe, climate-controlled rooms weren’t wanted nor had been the operators. Now corporations had IT Departments. The technicians sat in their very own areas, the place they might eat and smoke, and went out to the customers who had a pc downside. It was as if all of the Medical doctors left their hospital practices to make home calls.
Cheap statistical packages that ran on PCs multiplied like rabbits. All of those packages had GUIs; all had been kludgy and even unusable by right now’s requirements. Even the venerable ancients, SAS and SPSS, advanced point-and-click faces (though you may nonetheless write code if you happen to needed). By the mid-Eighties, you may run even probably the most complicated statistical evaluation in much less time than it takes to drink a cup of espresso … as long as your laptop didn’t crash.
PC gross sales had reached virtually one million per 12 months by 1980. However then in 1981, IBM launched their 8088 PC. Over the following twenty years, the variety of IBM-compatible PCs that had been offered elevated yearly to virtually 200 million. From the early Nineteen Nineties, gross sales of PCs had been fueled by Pentium-speed, GUIs, the Web, and reasonably priced, user-friendly software program, together with spreadsheets with statistical capabilities. MITS and the Altair had been lengthy gone, now seen solely in museums, however Microsoft survived, advanced, and have become the apex predator.
The maturation of the Web additionally created many new alternatives. You now not needed to have entry to an enormous library of books to do a statistical evaluation. There have been dozens of internet sites with reference supplies for statistics. As an alternative of buying one costly e-book, you may seek the advice of a dozen completely different discussions on the identical matter, free. No useless timber want litter your workplace. Should you couldn’t discover web site with what you needed, there have been dialogue teams the place you may publish your questions. Maybe most significantly, although, information that might have been tough or not possible to acquire within the Seventies had been now just some mouse-clicks away, often from the federal authorities.
So, with laptop gross sales skyrocketing and the Web changing into as addictive as crack, it’s not shocking that using statistics may also be on the rise. Contemplate the developments proven on this determine. The purple squares characterize the variety of computer systems offered from 1981 to 2005. The blue diamonds, which observe a development much like laptop gross sales, characterize revenues for SPSS, Inc. So not less than a few of these computer systems had been getting used for statistical analyses.
One other main occasion within the Eighties was the introduction of Lotus 1-2-3. The spreadsheet software program offered customers with the flexibility to handle their information, carry out calculations, and create charts. It was HUGE. Everyone who analyzed information used it, if for nothing else, to clean their information and organize them in a matrix. Like a firecracker, the lifetime of Lotus 1-2-3 was explosive however temporary. A decade after its introduction, it misplaced its prominence to Microsoft Excel, and by the point information science bought horny within the 2010s, it was gone.
With the provision of extra computer systems and extra statistical software program, you would possibly count on that there could also be extra statistical analyses being executed. That’s a tricky development to quantify, however think about the will increase within the numbers of political polls and pollsters. Earlier than 1988, there have been on-average just one or two presidential approval polls performed every month. Inside a decade, that quantity had elevated to greater than a dozen. Within the determine, the inexperienced circles characterize the variety of polls performed on presidential approval. This development is sort of much like the developments for laptop gross sales and SPSS revenues. Correlation doesn’t indicate causation however typically it certain makes numerous sense.
Maybe much more revealing is the rise within the variety of pollsters. Earlier than 1990, the Gallup Group was just about the one group conducting presidential approval polls. Now, there are a number of dozen. These pollsters don’t simply ask about Presidential approval, both. There are a plethora of polls for each situation of actual significance and a lot of the problems with contrived significance. Many of those polls are repeated to search for adjustments in opinions over time, between areas, and for various demographics. And that’s simply political polls. There was an excellent quicker enhance in polling for advertising and marketing, product improvement, and different enterprise purposes. Even with out together with non-professional polls performed on the Web, the expansion of polling has been exponential.
Statistics was going by means of a section of explosive evolution. By the mid-Eighties, statistical evaluation was now not thought of the unique area of execs. With PCs and statistical software program proliferating and universities requiring a statistics course for a broad number of levels, it grew to become frequent for non-professionals to conduct their very own analyses. Sabermetrics, for instance, was popularized by baseball professionals who weren’t statisticians. Bosses who couldn’t program the clock on a microwave thought nothing of anticipating their subordinates to do all types of knowledge evaluation. They usually did. It’s no surprise that statistical analyses had been changing into commonplace wherever there have been numbers to crunch.
Large Information cat.
Towards that backdrop of utilized statistics got here the explosion of knowledge wrangling capabilities. Relational databases and Sequel (SQL) information retrieval grew to become the vogue. Expertise additionally exerted its affect. Not solely had been PCs changing into quicker however, maybe extra importantly, laborious disk drives had been getting greater and cheaper. This led to information warehousing, and finally, the emergence of Large Information. Large information introduced Information Mining and black-box modeling. BI (Enterprise Intelligence) emerged in 1989, primarily in main companies.
Then got here the Nineteen Nineties. Expertise went into overdrive. Bulletin Boards Techniques (BBSs) and Web Relay Chat (IRC) advanced into prompt messaging, social media, and running a blog. The quantity of knowledge generated by and out there from the Web skyrocketed. Google and different search engines like google proliferated. Information units had been no longer simply large, they had been BIG. Large Information required particular software program, like Hadoop, not simply due to its quantity but in addition as a result of a lot of it was unstructured.
At this level, utilized statisticians and programmers had symbiotic, although typically contentious, relationships. For instance, information wranglers at all times put information into relational databases that statisticians needed to reformat into matrices earlier than they might be analyzed. Then, 1995-2000 introduced the R programming language. This was notable for a number of causes. Faculties that couldn’t afford the licensing and operational prices of SAS and SPSS started educating R, which was free. This had the consequence of bringing programming again to the applied-statistics curriculum. It additionally freed graduates from worrying about having a method to do their statistical modeling at their new jobs wherever they could be.
Conducting a knowledge evaluation within the Nineteen Nineties was nowhere close to as onerous because it was twenty years earlier than. You would work at your desk in your PC as a substitute of tenting out within the laptop room. Many corporations had their very own information wranglers who constructed centralized information repositories for everybody to make use of. You didn’t need to enter your information manually fairly often, and if you happen to did, it was by keyboarding relatively than keypunching. Large corporations had their large information however most information units had been sufficiently small to deal with in Entry if not Excel. Low-cost, GUI-equipped statistical software program was available for any evaluation Excel couldn’t deal with. Analyses took minutes relatively than hours. It took longer to plan an evaluation than it did to conduct it. Anybody who took a statistics class in faculty started analyzing their very own information. The Nineteen Nineties produced numerous cringeworthy statistical analyses and deceptive chartsand graphs. Oh, these had been the times.
The 2000s introduced extra know-how. Most individuals had an electronic mail account. You would carry a library of ebooks wherever. Cell telephones advanced into smartphones. Flash drives made datasets moveable. Tablets augmented PCs and smartphones. Bluetooth facilitated information switch. Then one thing else essential occurred—funding.
Donoho captured the sentiment of statisticians in his handle on the 2015 Tukey Centennial workshop:
“Information Scientist means an expert who makes use of scientific strategies to liberate and create that means from uncooked information. … Statistics means the follow or science of amassing and analyzing numerical information in giant portions.
To a statistician, [the definition of data scientist] sounds an terrible lot like what utilized statisticians do: use methodology to make inferences from information. … [the] definition of statistics appears already to embody something that the definition of Information Scientist would possibly embody …
The statistics occupation is caught at a complicated second: the actions which preoccupied it over centuries are actually within the limelight, however these actions are claimed to be brilliant shiny new, and carried out by (though not really invented by) upstarts and strangers.
Feline statistician observing feline information scientist.
The remainder of the story of Information Science is extra clearly remembered as a result of it’s current. Most of right now’s information scientists hadn’t even graduated from faculty by the 2010s. They may bear in mind, although, the technological advances, the surge in social connectedness, and the cash pouring into information science packages in anticipation of the cash that might be generated from them. These components led to a revolution.
The common age of knowledge scientists in 2018 was 30.5, the median was decrease. The youthful half of knowledge scientists had been simply coming into faculty within the 2000s, simply when all that funding was hitting academia. (FWIW, I’m within the imperceptibly tiny bar on the higher left of the chart together with 193 others.) However KDnuggets concluded that:
“… relatively than attracting people from new demographics to computing and know-how, the expansion of knowledge science jobs has merely creating [sic] a brand new profession path for individuals who had been more likely to grow to be builders anyway.”
The occasion that propelled Information Science into the general public’s consciousness, although, was undoubtedly the 2012 Harvard Enterprise Evaluation article that declared information scientist to be the sexiest job of the 21st century. The article by Davenport and Patil described a knowledge scientist as “a high-ranking skilled with the coaching and curiosity to make discoveries on this planet of massive information.” Ignoring the thirty-year historical past of the time period, although not the idea which was new, the article notes that there have been already “1000’s of knowledge scientists … working at each start-ups and well-established corporations” in simply 5 years. I doubt they had been all high-ranking.
Davenport and Patil attributed the emergence of data-scientist as a job title to the varieties and volumes of unstructured Large Information in enterprise. However a constant definition of information scientist proved to be elusive. Six years later in 2018, KDnuggets described Information Science as an interdisciplinary discipline on the intersection of Statistics, Laptop Science, Machine Studying, and Enterprise, fairly a bit extra particular than the HBR article. There have been additionally fairly just a few different opinions about what information science really was. Everyone needed to be on the bandwagon that was horny, prestigious, and profitable.
…
The numbers of Google searches associated to subjects regarding information reveal the recognition, or not less than the curiosity, of the general public. Subjects associated to look time period statistics—most notably statistics, information mining, and information warehouse—all decreased in recognition from about 80 searches per 30 days in 2004 to 25 searches per 30 days in 2020. Six Sigma and SQL had been considerably extra standard than these subjects between 2004 and 2011. Laptop Programming rose in recognition barely from 2014 to 2016. Enterprise Intelligence adopted a sample much like SQL however had 10 to 30 extra searches per 30 days.
Subjects associated to the search time period information science—Information Science, Large Information, and Machine Studying—had fewer than 20 searches per 30 days from 2004 till 2012 once they started rising quickly. Large Information peaked in 2014 then decreased steadily. Information Science and Machine Studying elevated till about 2018 after which leveled off. The time period Python has elevated from about 35 searches per 30 days in 2013 to 90 searches per 30 days in 2020. The time period Synthetic Intelligence decreased from 70 searches per 30 days in 2004 to a minimal of 30 searches per 30 days from 2008 to 2014, then elevated to 80 searches per 30 days in 2019.
Whereas folks imagine Synthetic Intelligence is a relative current discipline of examine, largely an thought of science fiction, it really goes again to historical historical past. Autopilots in airplanes and ships date again to the early 20th century, now we’ve got driverless vehicles and vans. Computer systems, maybe the final word AI, had been first developed within the 1940. Voice recognition started within the Fifties, now we will discuss to Siri and Cortana. Amazon and Netflix inform us what we need to do. However maybe the e single occasion that caught the general public’s consideration was in 1997 when Deep Blue grew to become the primary laptop AI to beat a reigning, world chess champion, Garry Kasparov. This led to AI being utilized to different video games, like Go and Jeopardy, which elevated the general public’s consciousness of AI.
Aviation went from its first flight to touchdown on the moon in 65 years. Music went from vinyl to tape to disk to digital in 30 years. Information science overtook statistics in recognition in lower than a decade.
It’s fascinating to match the patterns of searches for the phrases: statistics; AI; large information; ML; and information science. Everyone is aware of what statistics is. They see statistics day-after-day on the native climate studies. AI entered the general public’s consciousness with the sport demonstrations and motion pictures, like Terminator and Star Wars. Large information isn’t all that mysterious, particularly for the reason that definition is rock strong even when new V-definitions seem often. However ML and information science are extra enigmatic. ML is conceptionally obscure as a result of, in contrast to AI, it’s removed from what the general public sees. The definition of information science, nevertheless, suffers from an excessive amount of variety of opinion. Within the Seventies, Tukey and Naur had diametrically-opposed definitions. Many others since then have added extra obfuscation than readability. Fayyad and Hamutcu conclude that “there is no such thing as a generally agreed on definition for information science,” and moreover, “there is no such thing as a consensus on what it’s.”
So, universities prepare college students to be information scientists, companies rent graduates to work as information scientists, and individuals who name themselves information scientists write articles about what they do. However as professions, we will’t agree on what information science is. As Humpty Dumpty mentioned:
“After I use a phrase,” Humpty Dumpty mentioned, in relatively a scornful tone, “it means simply what I select it to imply—neither extra nor much less.” “The query is,” mentioned Alice, “whether or not you can also make phrases imply so many alternative issues.” “The query is,” mentioned Humpty Dumpty, “which is to be grasp—that’s all.”
Lewis Carroll (Charles L. Dodgson), By means of the Wanting-Glass, chapter 6, p. 205 (1934). First revealed in 1872.
Feline on the lookout for definition of Information Science.
The time period information scientist has by no means had a constant that means. Tukey’s followers thought it utilized to all utilized statisticians and information analysts. Naur’s followers thought it referred to all programmers and information wranglers. These had been each collective nouns, however they had been unique. Tukey’s definition excluded information wranglers. Naur’s definition excluded information analysts. Nearly forty years later, Davenport and Patil used the time period for anybody with the abilities to unravel issues utilizing Large Information from enterprise. A few of right now’s definitions specify that particular person information scientists should be adept at wrangling, evaluation, modeling, and enterprise experience. In fact there are disagreements.
Expertise—Some definitions redefine what the abilities are. Statistics is the first instance. Some definitions restrict statistics to speculation testing regardless that modeling and prediction have been a part of the self-discipline for over a century. The implication is that something that isn’t speculation testing isn’t statistics.
Information—Some definitions specify that information science makes use of Large Information associated to enterprise. The implication is that smaller information units from non-business domains aren’t a part of information science.
Novelty—Some definitions give attention to new, particularly state-of-the-art applied sciences and strategies over conventional approaches. Information era is the first instance. Trendy applied sciences, like automated internet scraping with Python, are key strategies of some definitions of knowledge science. The implication is that conventional probabilistic sampling strategies aren’t a part of information science.
Specialization—Some definitions require information scientists to be multifaceted, generalist, jacks-of-all-trades. This technique of expertise has been deserted by just about all scientific professions. As Healy instructed, you may’t count on a pc programmer to be a statistician any greater than you may count on a statistician to be a programmer. Sure, there nonetheless are generalists, nexialists, interdisciplinarians; they make good mission managers and possibly even politicians. However, would you go to a GP (basic practitioner) for most cancers therapies?
These disagreements have led to some disrespectful opinions—you’re not an actual information scientist, you’re a programmer, statistician, information analyst, or another appellation. So, the elemental query is whether or not the time period information science refers to a large tent that holds all the abilities, and strategies, and kinds of information that may remedy an issue or it refers to a small tent that may solely maintain the particular expertise helpful for Large Information from enterprise.
What’s in a reputation? That which we name a rose by every other title would scent as candy.
William Shakespeare, Romeo and Juliet, Act II, Scene II
A gaggle of blind males heard {that a} unusual animal, referred to as an elephant, had been dropped at the city, however none of them had been conscious of its form and kind. Out of curiosity, they mentioned: “We should examine and comprehend it by contact, of which we’re succesful”. So, they sought it out, and once they discovered it they groped about it. The primary individual, whose hand landed on the trunk, mentioned, “This being is sort of a thick snake”. For one more one whose hand reached its ear, it appeared like a form of fan. As for one more individual, whose hand was upon its leg, mentioned, the elephant is a pillar like a tree-trunk. The blind man who positioned his hand upon its aspect mentioned the elephant, “is a wall”. One other who felt its tail, described it as a rope. The final felt its tusk, stating the elephant is that which is tough, easy and like a spear.
Information science is an elephant. The tougher we attempt to outline it the extra unrecognizable it turns into. Is it a collective noun or an exclusionary filter? There isn’t any consensus. However that’s the way in which the world works. Perhaps in fifty years, faculties can have packages to coach Knowledge Oracles to take the work of pedestrian information scientists and switch it into one thing actually helpful.
Something that’s on this planet once you’re born is regular and odd and is only a pure a part of the way in which the world works. Something that’s invented between once you’re fifteen and thirty-five is new and thrilling and revolutionary and you may in all probability get a profession in it. Something invented after you’re thirty-five is in opposition to the pure order of issues.
Douglas Adams
All images and graphs by writer besides as famous.
Cynomolgus monkey, a recognized reservoir of the Monkeypox virus
In current months, the mpox virus (previously monkeypox) has develop into a serious well being disaster globally. The outbreak began small however now exploded to over 15,600 instances and 537 deaths as of August 2024 within the Democratic Republic of the Congo (DRC). This fast improve is essentially attributable to a brand new lethal pressure, Clade 1b, which emerged final yr within the nation.
This pressure of the mpox virus is spreading quickly, primarily via sexual networks. It has now reached African nations like Burundi, Kenya, Rwanda, and Uganda for the primary time. The virus additionally unfold to Europe, with Sweden reporting its first case.
Responding to the disaster, the World Well being Group (WHO) declared the outbreak a Public Well being Emergency of Worldwide Concern (PHEIC) on August 14, 2024. This declaration highlights the intense nature of the unfold and the potential for much more unreported instances. It’s a name to the worldwide group to affix forces and assist comprise the virus, supporting affected nations in managing this escalating menace.
Whereas it’s essential to not panic, it’s useful to remain conscious of the signs, prognosis, therapy, and methods to stop the infectious illness.
What’s mpox (previously monkeypox)?
Mpox is an infectious illness attributable to the mpox virus. The virus belongs to the identical household because the smallpox virus. The illness was initially named monkeypox after it was first detected in lab monkeys in 1958. In 2022, WHO renamed the infectious illness to ‘mpox’, to align with trendy tips and remove “racist and stigmatizing language” related to the identify.
The primary human case of mpox was not found till 1970 within the Democratic Republic of Congo [2]. The virus belongs to the Orthopoxvirus genus of the Poxviridae household and is an enveloped double-stranded DNA virus. Different members of poxviridae embrace smallpox (variola), cowpox, buffalopox, and aracatuba [2].
This 1997 picture was created throughout an investigation into an outbreak within the Democratic Republic of the Congo (DRC) and depicts the palms of an mpox case-patient. It is very important be aware how comparable this maculopapular rash seems to be in comparison with the rash of smallpox, additionally an Orthopoxvirus. Picture courtesy of CDC/Dr. Brian W.J.Mahy
How do you get mpox? How does it unfold?
In response to WHO, the mpox virus can unfold from individual to individual via numerous methods, together with:
By speaking or respiration near an contaminated particular person
Pores and skin-to-skin contact
Mouth-to-mouth transmission (like kissing)
Oral intercourse or kissing pores and skin
Droplets within the air from shut contact for a chronic interval.
Notable outbreaks
2024
As of August 2024, the WHO has reported over 15,600 Mpox instances and 537 deaths within the DRC. This can be a vital improve in comparison with the whole numbers for all of 2023.
Simply hours after the WHO declared mpox as an emergency, the Swedish authorities confirmed their first case of the damaging mpox variant, clade 1b. The affected person was contaminated in Africa.
2023
Between January-December, 2023, there have been 92,783 lab-confirmed instances of mpox reported globally.
14, 626 instances and 654 deaths had been within the DRC alone.
Amongst these instances, 581 resulted in suspected mpox-related deaths, reflecting a case fatality ratio of 4.6%. In response to WHO, that is the best variety of instances ever recorded. Much more worrying is that a number of instances have been reported in areas that had not beforehand reported mpox instances.
2022
From January 1 to September 13, 2022, 4,494 instances of mpox (171 deadly) had been reported within the Democratic Republic of Congo.
Instances within the Democratic Republic of Congo, 1970 – 2019
Notable mpox outbreaks up to now
In the course of the single yr of 1967, nearly eleven thousand instances occurred in West and Central Africa.
Essentially the most uncommon illness outbreak of mpox occurred in 2003 when 81 people within the American Midwest had been contaminated via contact with contaminated prairie canines – themselves contaminated by rodents imported from Ghana. Fortuitously, all sufferers recovered and didn’t face longer-term results of the an infection.
From 2018 to 2019, 5 Nigerian vacationers had been discovered to have mpox – in Israel, Singapore, and London.
Who’s prone to getting contaminated?
Mpox is endemic to Central and West Africa, which places individuals in these areas at greater threat of getting mpox.
Different weak individuals embrace:
These with compromised or weak immune programs
Kids below one yr previous (Nonetheless, the 2024 mpox outbreaks exhibits the next proportion of infections in youngsters under 15 years)
Folks with a historical past of eczema
People who find themselves pregnant
Males who’ve intercourse with males (MSM).
Signs
In response to the US CDC, mpox signs often seem inside 3-17 days after an individual is first contaminated (incubation interval).
Mpox signs begin with:
Fever
Headache
Muscle ache and backache
Swollen lymph nodes
Chills
Excessive tiredness
Sore throat, cough, or different respiratory points.
A attribute rash develops after a couple of days (1-4). Be aware: Contaminated individuals can unfold the virus 1-4 days earlier than signs seem, making it much more essential to get examined early if you happen to suspect an an infection.
Prognosis
Mpox signs could be confused with that of chickenpox and smallpox, however a distinguishing characteristic of mpox is the presence of swelling within the lymph nodes.
Differential prognosis should embrace different rash-related sicknesses like scabies, pores and skin infections, and syphilis. The commonest diagnostic device is a bodily examination by skilled physicians and the PCR (polymerase chain response).
Nonetheless, for this take a look at to offer correct outcomes, samples from pores and skin lesions or fluid from the rash vesicles or pustules work greatest. PCR blood checks for mpox, and antigen and antibody checks are often inconclusive, in response to WHO.
Remedy
Mpox typically goes away by itself inside 2-4 weeks so therapy for mpox often focuses on assuaging signs and caring for the rash.
There aren’t any therapies particularly designed to deal with mpox however outbreaks could be managed with medicine (antivirals) and the mpox vaccine which could be given inside 4 days of contact with an contaminated particular person. If there aren’t any signs, the mpox vaccine could be given as much as 14 days. [7].
Prevention
An individual who’s contaminated with mpox might help stop the unfold of the illness by staying at dwelling and isolating from others, washing arms typically with cleaning soap, cowl the rashes when round others (however can in any other case depart them open to dry and heal), don’t share bedlinen, towels, or different objects till totally recovered, and take common over-the-counter ache medicine to assist ease signs.
There are two mpox vaccines presently accredited to be used by WHO. Nonetheless, the worldwide group is requesting vaccine producers to ramp up manufacturing of the mpox vaccine to assist throughout this public well being emergency.
[2] H. Adler et al., “Medical options and administration of human monkeypox: a retrospective observational examine within the UK,” Lancet Infect. Dis., 2022.
[5] Z. Jezek, M. Szczeniowski, Ok. M. Paluku, M. Mutombo, and B. Seize, “Human monkeypox: confusion with chickenpox,” Acta Trop., vol. 45, no. 4, pp. 297–307, 1988.
Sklenovská and M. Van Ranst, “Emergence of Monkeypox as an important Orthopoxvirus an infection in people,” Entrance. Public Well being, vol. 6, p. 241, 2018.
DejaDup is the default backup utility for Gnome. It’s a GUI for duplicity, focuses on simplicity, helps incremental encrypted backups and up till lately supported numerous cloud suppliers. Sadly as of model 42.0, all main cloud suppliers have been eliminated. Thus on condition that Ubuntu 20.10 ships with the particular model, any consumer who upgrades and has backups on Amazon S3 received’t be capable of entry them. On this weblog publish, we are going to present an answer that may can help you proceed taking backups on AWS S3 utilizing DejaDup.
The necessary rant (be happy to skip)
The removing of the cloud suppliers mustn’t come as a shock. I’m not precisely certain which model of DejaDup deprecated them but it surely was across the launch of Ubuntu 17.10 once they had been all hidden as an choice. So for 3 lengthy years, individuals who had backups on Amazon S3, Google Cloud Storage, Openstack Swift, Rackspace and so forth might nonetheless use the deprecated characteristic and put together for the inevitable removing.
So why complain you would possibly ask? Nicely, to start with, once you replace from an earlier model of Ubuntu to twenty.10, you don’t actually know that the all cloud suppliers are faraway from DejaDup. Therefore if one thing goes unsuitable through the replace, you received’t be capable of simply entry your backups and restore your system.
One other large downside is the dearth of storage choices on the final model of DejaDup. They determined to alter their coverage and assist solely “consumer-targeted cloud companies” however presently they solely assist Google Drive. So that they eradicated all the price environment friendly choices for mass storage and saved just one single very costly choice. I’m not likely certain how that is good for the customers of the applying. Linux was all the time about having a alternative (an excessive amount of of it in lots of instances), so why not preserve a number of storage choices to serve each the skilled and inexperienced customers? Fortunately as a result of we’re on Linux, we’ve got choice to repair this.
use Deja Dup v42+ with AWS S3
WARNING: I’ve not examined completely the next setup so use it at your personal threat. If the pc explodes in your face, you lose your knowledge, or your partner takes your youngsters and leaves you, don’t blame me.
Putting in s3fs fuse
With that out of the best way, let’s proceed to the repair. We’ll use s3fs fuse, a program that means that you can mount an S3 bucket by way of FUSE and successfully make it seem like a neighborhood disk. Fortunately you don’t must compile it from supply because it’s on Ubuntu’s repos. To put in it, sort the next in your terminal:
sudo apt set up s3fs
Establishing your AWS credentials file
Subsequent, we have to configure your credentials. The s3fs helps two strategies for authentication: an AWS credential file or a customized passwd file. On this tutorial we are going to use the primary methodology however if you’re for the latter be happy to view the s3fs documentation on Github. To setup your credentials ensure that the file ~/.aws/credentials comprises your AWS entry id and secret key. It ought to seem like this:
As soon as your have your credentials file you’re able to mount your backup bucket. In case you don’t keep in mind the bucket identify you will discover it by visiting your AWS account. To mount and unmount the bucket to/from a particular location sort:
# mount s3fs BUCKET_NAME /path/to/location
# unmount fusermount -u /path/to/location
Mounting the bucket like that is solely momentary and won’t persist throughout reboots. You’ll be able to add it on /and so forth/fstab however I consider this solely works with the passwd file. If you wish to use your AWS credentials file a simple workaround it to create a shortcut in your Startup Purposes Preferences.
Word that you may add a small 10 sec delay to make sure that the WiFi is linked earlier than you attempt to mount the bucket. Web entry is clearly mandatory for mounting it efficiently. If you’re behind VPNs or produce other advanced setups, you can too create a bash script that makes the required checks earlier than you execute the mount command.
Configuring DejaDup
With the bucket mounted as a neighborhood drive, we will now simply configure DejaDup to make use of it. Initially we have to change the backend to native. This may be executed both by utilizing a program like dconfig or the console with the next command:
gsettings set org.gnome.DejaDup backend 'native'
Lastly we open DejaDup, go to preferences and level the storage location to the listing that has your S3 backup recordsdata. Be sure to choose the subdirectory that comprises the backup recordsdata; that is sometimes a subdirectory in your mount level that has identify equal to your laptop’s hostname. Final however not least, ensure that the S3 mount listing is excluded from DejaDup! To do that, verify the ignored folders in Preferences.
That’s it! Now go to your restore tab and DejaDup will be capable of learn your earlier backups. You can even take new ones.
Gotchas
There are some things to remember on this setup:
Initially, you should be linked on the web once you mount the bucket. If you’re not the bucket received’t be mounted. So, I counsel you rather than simply calling the mount command, to jot down a bash script that does the required checks earlier than mounting (web connection is on, firewall permits exterior requests and so forth).
Taking backups like that appears slower than utilizing the outdated native S3 assist and it’s more likely to generate extra community site visitors (thoughts AWS site visitors prices!). That is anticipated as a result of DejaDup thinks it’s accessing the native file-system, so there is no such thing as a want for aggressive caching or minimization of operations that trigger community site visitors.
You need to anticipate stability points. As we stated earlier, DejaDup doesn’t understand it writes knowledge over the wire a lot of the functionalities that often exist in such setups (akin to retry-on-fail) are lacking. And clearly in the event you lose connection halfway of the backup you’ll have to delete it and begin a brand new one to keep away from corrupting your future backups.
Lastly take into account that this can be a very experimental setup and in the event you actually wish to have a dependable answer, you must do your personal analysis and choose one thing that meets your wants.
If in case you have a advice for an Open-Supply Backup answer that permits regionally encrypted incremental backups, helps S3 and has a simple to make use of UI please depart a remark as I’m very happy to offer it a strive.
Agentic AI is turning into tremendous standard and related throughout industries. But it surely additionally represents a elementary shift in how we construct clever techniques: agentic AI techniques that break down complicated objectives, resolve which instruments to make use of, execute multi-step plans, and adapt when issues go mistaken.
When constructing such agentic AI techniques, engineers are designing decision-making architectures, implementing security constraints that forestall failures with out killing flexibility, and constructing suggestions mechanisms that assist brokers get better from errors. The technical depth required is considerably completely different from conventional AI improvement.
Agentic AI remains to be new, so hands-on expertise is far more necessary. You should definitely search for candidates who’ve constructed sensible agentic AI techniques and may talk about trade-offs, clarify failure modes they’ve encountered, and justify their design selections with actual reasoning.
How you can use this text: This assortment focuses on questions that check whether or not candidates actually perceive agentic techniques or simply know the buzzwords. You may discover questions throughout device integration, planning methods, error dealing with, security design, and extra.
# Constructing Agentic AI Tasks That Matter
In relation to tasks, high quality beats amount each time. Do not construct ten half-baked chatbots. Deal with constructing one agentic AI system that really solves an actual downside.
So what makes a challenge “agentic”? Your challenge ought to exhibit that an AI can act with some autonomy. Assume: planning a number of steps, utilizing instruments, making choices, and recovering from failures. Attempt to construct tasks that showcase understanding:
Private analysis assistant — Takes a query, searches a number of sources, synthesizes findings, asks clarifying questions
Assembly prep agent — Gathers context about attendees, pulls related docs, creates agenda, suggests speaking factors
What to emphasise:
How your agent breaks down complicated duties
What instruments it makes use of and why
The way it handles errors and ambiguity
The place you gave it autonomy vs. constraints
Actual issues it solved (even when only for you)
One stable challenge with considerate design selections will train you extra — and impress extra — than a portfolio of tutorials you adopted.
# Core Agentic Ideas
// 1. What Defines an AI Agent and How Does It Differ From a Normal LLM Utility?
What to deal with: Understanding of autonomy, goal-oriented habits, and multi-step reasoning.
Reply alongside these traces: “An AI agent is an autonomous system that may understand and work together with its setting, makes choices, and takes actions to realize particular objectives. In contrast to customary LLM functions that reply to single prompts, brokers preserve state throughout interactions, plan multi-step workflows, and may modify their strategy based mostly on suggestions. Key parts embody objective specification, setting notion, decision-making, motion execution, and studying from outcomes.”
🚫 Keep away from: Complicated brokers with easy tool-calling, not understanding the autonomous facet, lacking the goal-oriented nature.
// 2. Describe the Foremost Architectural Patterns for Constructing AI Brokers
What to deal with: Information of ReAct, planning-based, and multi-agent architectures.
Reply alongside these traces: “ReAct (Reasoning + Appearing) alternates between reasoning steps and motion execution, making choices observable. Planning-based brokers create full motion sequences upfront, then execute—higher for complicated, predictable duties. Multi-agent techniques distribute duties throughout specialised brokers. Hybrid approaches mix patterns based mostly on activity complexity. Every sample trades off between flexibility, interpretability, and execution effectivity.”
🚫 Keep away from: Solely understanding one sample, not understanding when to make use of completely different approaches, lacking the trade-offs.
// 3. How Do You Deal with State Administration in Lengthy-Operating Agentic Workflows?
What to deal with: Understanding of persistence, context administration, and failure restoration.
Reply alongside these traces: “Implement specific state storage with versioning for workflow progress, intermediate outcomes, and resolution historical past. Use checkpointing at vital workflow steps to allow restoration. Preserve each short-term context (present activity) and long-term reminiscence (discovered patterns). Design state to be serializable and recoverable. Embody state validation to detect corruption. Take into account distributed state for multi-agent techniques with consistency ensures.”
🚫 Keep away from: Relying solely on dialog historical past, not contemplating failure restoration, lacking the necessity for specific state administration.
# Instrument Integration and Orchestration
// 4. Design a Sturdy Instrument Calling System for an AI Agent
What to deal with: Error dealing with, enter validation, and scalability concerns.
Reply alongside these traces: “Implement device schemas with strict enter validation and kind checking. Use async execution with timeouts to stop blocking. Embody retry logic with exponential backoff for transient failures. Log all device calls and responses for debugging. Implement charge limiting and circuit breakers for exterior APIs. Design device abstractions that enable straightforward testing and mocking. Embody device consequence validation to catch API adjustments or errors.”
🚫 Keep away from: Not contemplating error instances, lacking enter validation, no scalability planning.
// 5. How Would You Deal with Instrument Calling Failures and Partial Outcomes?
What to deal with: Swish degradation methods and error restoration mechanisms.
Reply alongside these traces: “Implement tiered fallback methods: retry with completely different parameters, use various instruments, or gracefully degrade performance. For partial outcomes, design continuation mechanisms that may resume from intermediate states. Embody human-in-the-loop escalation for vital failures. Log failure patterns to enhance reliability. Use circuit breakers to keep away from cascading failures. Design device interfaces to return structured error data that brokers can cause about.”
🚫 Keep away from: Easy retry-only methods, not planning for partial outcomes, lacking escalation paths.
Relying on the framework you’re utilizing to construct your utility, you’ll be able to seek advice from the particular docs. For instance, How you can deal with device calling errors covers dealing with such errors for the LangGraph framework.
// 6. Clarify How You’d Construct a Instrument Discovery and Choice System for Brokers
What to deal with: Dynamic device administration and clever choice methods.
Reply alongside these traces: “Create a device registry with semantic descriptions, capabilities metadata, and utilization examples. Implement device rating based mostly on activity necessities, previous success charges, and present availability. Use embedding similarity for device discovery based mostly on pure language descriptions. Embody value and latency concerns in choice. Design plugin architectures for dynamic device loading. Implement device versioning and backward compatibility.”
// 7. Evaluate Completely different Planning Approaches for AI Brokers
What to deal with: Understanding of hierarchical planning, reactive planning, and hybrid approaches.
Reply alongside these traces: “Hierarchical planning breaks complicated objectives into sub-goals, enabling higher group however requiring good decomposition methods. Reactive planning responds to speedy situations, providing flexibility however doubtlessly lacking optimum options. Monte Carlo Tree Search explores motion areas systematically however requires good analysis capabilities. Hybrid approaches use high-level planning with reactive execution. Selection is determined by activity predictability, time constraints, and setting complexity.”
🚫 Keep away from: Solely understanding one strategy, not contemplating activity traits, lacking trade-offs between planning depth and execution velocity.
// 8. How Do You Implement Efficient Objective Decomposition in Agent Methods?
What to deal with: Methods for breaking down complicated goals and dealing with dependencies.
Reply alongside these traces: “Use recursive objective decomposition with clear success standards for every sub-goal. Implement dependency monitoring to handle execution order. Embody objective prioritization and useful resource allocation. Design objectives to be particular, measurable, and time-bound. Use templates for frequent objective patterns. Embody battle decision for competing goals. Implement objective revision capabilities when circumstances change.”
🚫 Keep away from: Advert-hoc decomposition with out construction, not dealing with dependencies, lacking context.
# Multi-Agent Methods
// 9. Design a Multi-Agent System for Collaborative Drawback-Fixing
What to deal with: Communication protocols, coordination mechanisms, and battle decision.
Reply alongside these traces: “Outline specialised agent roles with clear capabilities and duties. Implement message passing protocols with structured communication codecs. Use coordination mechanisms like activity auctions or consensus algorithms. Embody battle decision processes for competing objectives or sources. Design monitoring techniques to trace collaboration effectiveness. Implement load balancing and failover mechanisms. Embody shared reminiscence or blackboard techniques for data sharing.”
🚫 Keep away from: Unclear position definitions, no coordination technique, lacking battle decision.
// 10. What Security Mechanisms Are Important for Manufacturing Agentic AI Methods?
What to deal with: Understanding of containment, monitoring, and human oversight necessities.
Reply alongside these traces: “Implement motion sandboxing to restrict agent capabilities to accredited operations. Use permission techniques requiring specific authorization for delicate actions. Embody monitoring for anomalous habits patterns. Design kill switches for speedy agent shutdown. Implement human-in-the-loop approvals for high-risk choices. Use motion logging for audit trails. Embody rollback mechanisms for reversible operations. Common security testing with adversarial situations.”
🚫 Keep away from: No containment technique, lacking human oversight, not contemplating adversarial situations.
Agentic AI engineering calls for a singular mixture of AI experience, techniques pondering, and security consciousness. These questions probe the sensible data wanted to construct autonomous techniques that work reliably in manufacturing.
The very best agentic AI engineers design techniques with applicable safeguards, clear observability, and sleek failure modes. They suppose past single interactions to full workflow orchestration and long-term system habits.
Would you want us to do a sequel with extra associated questions on agentic AI? Tell us within the feedback!
Bala Priya C is a developer and technical author from India. She likes working on the intersection of math, programming, information science, and content material creation. Her areas of curiosity and experience embody DevOps, information science, and pure language processing. She enjoys studying, writing, coding, and low! At the moment, she’s engaged on studying and sharing her data with the developer neighborhood by authoring tutorials, how-to guides, opinion items, and extra. Bala additionally creates partaking useful resource overviews and coding tutorials.






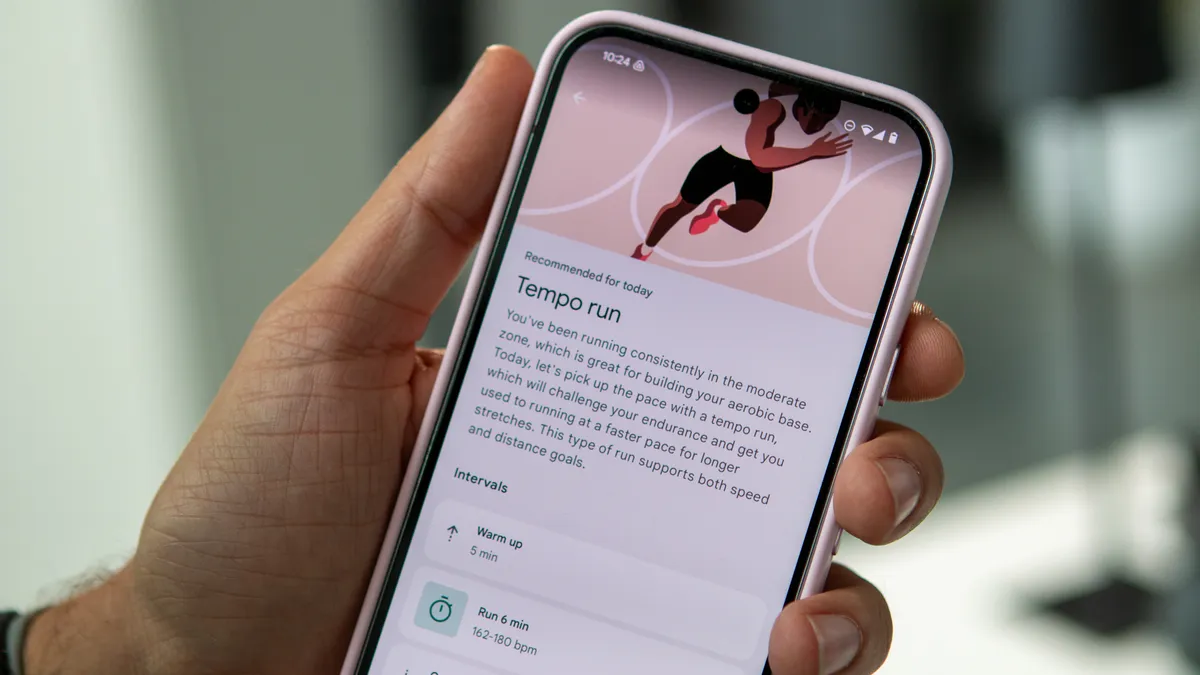



























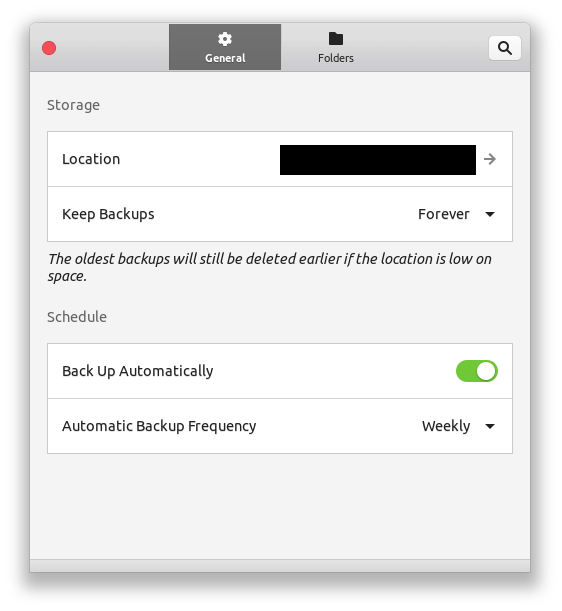

{kind=link}