Fairly than a gradual transition, your life staggers and lurches via the fast development of childhood and the plateau of early maturity, to an acceleration in growing older because the many years progress.
A examine recognized a turning level at which that acceleration sometimes happens: round age 50.
After this time, the trajectory at which your tissues and organs age is steeper than the many years previous, in response to a examine of proteins in human our bodies throughout a variety of grownup ages – and your veins are among the many quickest to say no.
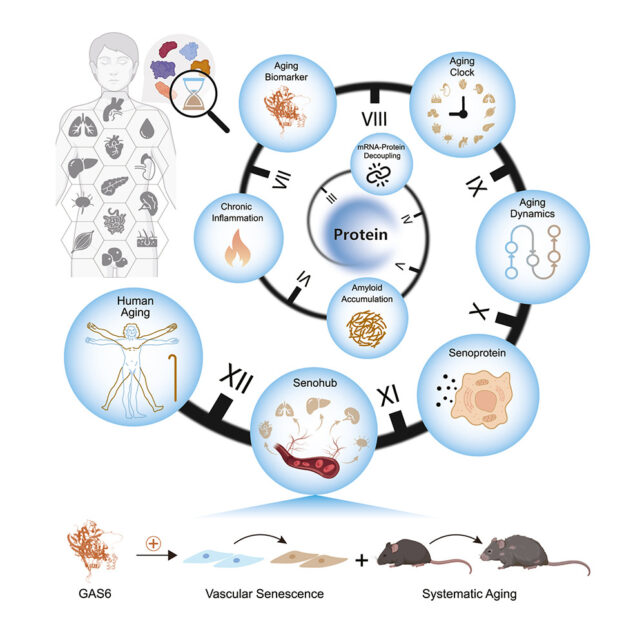
“Primarily based on aging-associated protein adjustments, we developed tissue-specific proteomic age clocks and characterised organ-level growing older trajectories,” writes a crew led by scientists from the Chinese language Academy of Sciences of their paper revealed in 2025.
“Temporal evaluation revealed an growing older inflection round age 50, with blood vessels being a tissue that ages early and is markedly inclined to growing older.”
“Our findings lay the groundwork for a systems-level understanding of human growing older via the lens of proteins,” the researchers write.
A graphic illustrating the function of proteins in human growing older. (Ding et al., Cell, 2025)
They collected tissue samples from a complete of 76 organ donors between the ages of 14 and 68 who had died of unintended traumatic mind damage. Additionally they obtained blood samples.
The 516 samples – from 13 completely different tissues – coated seven of the physique’s programs: cardiovascular (coronary heart and aorta), digestive (liver, pancreas, and gut), immune (spleen and lymph node), endocrine (adrenal gland and white adipose), respiratory (lung), integumentary (pores and skin), and musculoskeletal (muscle).
The crew constructed a list of the proteins present in these programs, taking cautious be aware of how their ranges modified because the ages of the donors elevated.
“We recognized tissue-enriched and tissue-enhanced proteins,” they write, “in addition to these widespread throughout tissues, that are very important for primary housekeeping features in biology.”
The researchers in contrast their findings to a database of ailments and their related genes, and located that expressions of 48 disease-related proteins elevated with age.
These included cardiovascular situations, tissue fibrosis, fatty liver illness, and liver-related tumors.
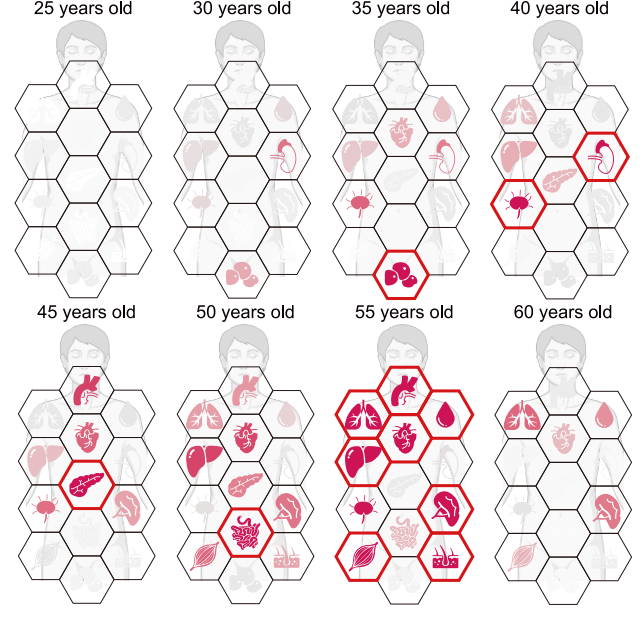
Essentially the most stark adjustments occurred between the ages of 45 and 55, the researchers discovered.
It is at this level that many tissues bear substantial proteomic reworking, with probably the most marked adjustments occurring within the aorta – demonstrating a robust susceptibility to growing older.
Your physique’s organs in response to once they’re most delicate to growing older. (Ding et al., Cell, 2025)
To check their findings, the researchers remoted a protein related to growing older within the aortas of mice, and injected it into younger mice to look at the outcomes.
Animals handled with the protein had diminished bodily efficiency, decreased grip power, decrease endurance, and decrease stability and coordination in comparison with non-treated mice. Additionally they had distinguished markers of vascular growing older.
Earlier work by a US crew confirmed one other two peaks in growing older, at round 44, and once more at round 60.
In that examine, the primary peak confirmed adjustments in molecules associated to the metabolism of lipids, caffeine, and alcohol, in addition to heart problems, and dysfunctions in pores and skin and muscle.
“Our examine is poised to assemble a complete multi-tissue proteomic atlas spanning 50 years of your complete human growing older course of, elucidating the mechanisms behind proteostasis imbalance in aged organs and revealing each common and tissue-specific growing older patterns,” the authors write.
Two-step estimation issues may be solved utilizing the gmm command.
When a two-step estimator produces constant level estimates however inconsistent commonplace errors, it is called the two-step-estimation downside. For example, inverse-probability weighted (IPW) estimators are a weighted common wherein the weights are estimated in step one. Two-step estimators use first-step estimates to estimate the parameters of curiosity in a second step. The 2-step-estimation downside arises as a result of the second step ignores the estimation error in step one.
One resolution is to transform the two-step estimator right into a one-step estimator. My favourite method to do that conversion is to stack the equations solved by every of the 2 estimators and clear up them collectively. This one-step strategy produces constant level estimates and constant commonplace errors. There isn’t any two-step downside as a result of all of the computations are carried out collectively. Newey (1984) derives and justifies this strategy.
I’m going as an example this strategy with the IPW instance, however it may be used with any two-step downside so long as every step is steady.
IPW estimators are steadily used to estimate the imply that may be noticed if everybody in a inhabitants acquired a specified remedy, a amount often known as a potential-outcome imply (POM). A distinction of POMs is named the common remedy impact (ATE). Other than all that, it’s the mechanics of the two-step IPW estimator that curiosity me right here. IPW estimators are weighted averages of the end result, and the weights are estimated in a primary step. The weights used within the second step are the inverse of the estimated chance of remedy.
Let’s think about we’re analyzing an extract of the birthweight knowledge utilized by Cattaneo (2010). On this dataset, bweight is the newborn’s weight at delivery, mbsmoke is 1 if the mom smoked whereas pregnant (and 0 in any other case), mmarried is 1 if the mom is married, and prenatal1 is 1 if the mom had a prenatal go to within the first trimester.
Let’s think about we wish to estimate the imply when all pregnant girls smoked, which is to say, the POM for smoking. If we have been doing substantive analysis, we’d additionally estimate the POM when no pregnant girls smoked. The distinction between these estimated POMs would then estimate the ATE of smoking.
Within the IPW estimator, we start by estimating the chance weights for smoking. We match a probit mannequin of mbsmoke as a operate of mmarried and prenatal1.
Massive language fashions (LLMs) can generate credible however inaccurate responses, so researchers have developed uncertainty quantification strategies to examine the reliability of predictions. One widespread methodology entails submitting the identical immediate a number of occasions to see if the mannequin generates the identical reply.
However this methodology measures self-confidence, and even probably the most spectacular LLM is likely to be confidently unsuitable. Overconfidence can mislead customers concerning the accuracy of a prediction, which could end in devastating penalties in high-stakes settings like well being care or finance.
To deal with this shortcoming, MIT researchers launched a brand new methodology for measuring a special kind of uncertainty that extra reliably identifies assured however incorrect LLM responses.
Their methodology entails evaluating a goal mannequin’s response to responses from a gaggle of comparable LLMs. They discovered that measuring cross-model disagreement extra precisely captures this kind of uncertainty than conventional approaches.
They mixed their strategy with a measure of LLM self-consistency to create a complete uncertainty metric, and evaluated it on 10 lifelike duties, reminiscent of question-answering and math reasoning. This whole uncertainty metric constantly outperformed different measures and was higher at figuring out unreliable predictions.
“Self-consistency is being utilized in numerous totally different approaches for uncertainty quantification, but when your estimate of uncertainty solely depends on a single mannequin’s consequence, it isn’t essentially trustable. We went again to the start to know the restrictions of present approaches and used these as a place to begin to design a complementary methodology that may empirically enhance the outcomes,” says Kimia Hamidieh, {an electrical} engineering and laptop science (EECS) graduate pupil at MIT and lead creator of a paper on this method.
She is joined on the paper by Veronika Thost, a analysis scientist on the MIT-IBM Watson AI Lab; Walter Gerych, a former MIT postdoc who’s now an assistant professor at Worcester Polytechnic Institute; Mikhail Yurochkin, a workers analysis scientist on the MIT-IBM Watson AI Lab; and senior creator Marzyeh Ghassemi, an affiliate professor in EECS and a member of the Institute of Medical Engineering Sciences and the Laboratory for Info and Choice Methods.
Understanding overconfidence
Many widespread strategies for uncertainty quantification contain asking a mannequin for a confidence rating or testing the consistency of its responses to the identical immediate. These strategies estimate aleatoric uncertainty, or how internally assured a mannequin is in its personal prediction.
Nonetheless, LLMs may be assured when they’re fully unsuitable. Analysis has proven that epistemic uncertainty, or uncertainty about whether or not one is utilizing the fitting mannequin, could be a higher technique to assess true uncertainty when a mannequin is overconfident.
The MIT researchers estimate epistemic uncertainty by measuring disagreement throughout the same group of LLMs.
“If I ask ChatGPT the identical query a number of occasions and it provides me the identical reply time and again, that doesn’t imply the reply is essentially appropriate. If I change to Claude or Gemini and ask them the identical query, and I get a special reply, that’s going to present me a way of the epistemic uncertainty,” Hamidieh explains.
Epistemic uncertainty makes an attempt to seize how far a goal mannequin diverges from the best mannequin for that process. However since it’s inconceivable to construct a really perfect mannequin, researchers use surrogates or approximations that usually depend on defective assumptions.
To enhance uncertainty quantification, the MIT researchers wanted a extra correct technique to estimate epistemic uncertainty.
An ensemble strategy
The strategy they developed entails measuring the divergence between the goal mannequin and a small ensemble of fashions with related measurement and structure. They discovered that evaluating semantic similarity, or how carefully the meanings of the responses match, might present a greater estimate of epistemic uncertainty.
To attain probably the most correct estimate, the researchers wanted a set of LLMs that coated various responses, weren’t too much like the goal mannequin, and have been weighted primarily based on credibility.
“We discovered that the simplest technique to fulfill all these properties is to take fashions which can be skilled by totally different firms. We tried many alternative approaches that have been extra advanced, however this quite simple strategy ended up working greatest,” Hamidieh says.
As soon as they’d developed this methodology for estimating epistemic uncertainty, they mixed it with an ordinary strategy that measures aleatoric uncertainty. This whole uncertainty metric (TU) provided probably the most correct reflection of whether or not a mannequin’s confidence degree is reliable.
“Uncertainty relies on the uncertainty of the given immediate in addition to how shut our mannequin is to the optimum mannequin. For this reason summing up these two uncertainty metrics goes to present us the most effective estimate,” Hamidieh says.
TU might extra successfully determine conditions the place an LLM is hallucinating, since epistemic uncertainty can flag confidently unsuitable outputs that aleatoric uncertainty would possibly miss. It might additionally allow researchers to bolster an LLM’s confidently appropriate solutions throughout coaching, which can enhance efficiency.
They examined TU utilizing a number of LLMs on 10 frequent duties, reminiscent of question-answering, summarization, translation, and math reasoning. Their methodology extra successfully recognized unreliable predictions than both measure by itself.
Measuring whole uncertainty typically required fewer queries than calculating aleatoric uncertainty, which might scale back computational prices and save power.
Their experiments additionally revealed that epistemic uncertainty is handiest on duties with a singular appropriate reply, like factual question-answering, however could underperform on extra open-ended duties.
Sooner or later, the researchers might adapt their method to enhance its efficiency on open-ended queries. They could additionally construct on this work by exploring different types of aleatoric uncertainty.
This work is funded, partly, by the MIT-IBM Watson AI Lab.
Furthermore, the notion of “set it and neglect it” within the cloud has confirmed dangerously outdated. The fixed drumbeat of threats, from ransomware to nation-state actors, mixed with the proliferation of APIs and providers, makes the cloud a shifting, ever-expanding assault floor. Enterprises are pressured not solely to upskill but in addition to undertake entire new mindsets round zero belief, observability, and resilience engineering.
The longer term: extra of the identical
The unique fantasy of cloud was that it will be a single pane of glass: one supplier (usually AWS), powering an enterprise’s each workload, built-in from edge to core to SaaS. In actuality, as we attain this 20-year milestone, we’re in a multicloud actuality whether or not by design, accident, or necessity. Enterprises are actually managing portfolios that span AWS, Microsoft Azure, Google Cloud, and typically dozens of SaaS or area of interest suppliers and their very own personal clouds.
This shift really magnifies all earlier challenges. Not solely do organizations should grasp the idiosyncrasies of every supplier’s architectures, prices, and safety fashions, however they need to additionally deal with interoperability, knowledge motion, compliance, and the expertise hole throughout each platform in use. The trendy IT property is a patchwork, not a seamless cloth.
Open‑weight fashions are quickly narrowing the hole with closed business methods. As of early 2026, Moonshot AI’s Kimi K2.5 is the flagship of this development: a one‑trillion parameter Combination‑of‑Specialists (MoE) mannequin that accepts photographs and movies, causes over lengthy contexts and may autonomously name exterior instruments. Not like closed alternate options, its weights are publicly downloadable underneath a modified MIT licence, enabling unprecedented flexibility.
This text explains how K2.5 works, evaluates its efficiency, and helps AI infrastructure groups determine whether or not and the right way to undertake it. All through we incorporate authentic frameworks just like the Kimi Functionality Spectrum and the AI Infra Maturity Mannequin to translate technical options into strategic choices. We additionally describe how Clarifai’s compute orchestration and native runners can simplify adoption.
Fast digest
Design: 1 trillion parameters organised into sparse Combination‑of‑Specialists layers, with solely ~32 billion lively parameters per token and a 256K‑token context window.
Modes: Immediate (quick), Considering (clear), Agent (device‑oriented) and Agent Swarm (parallel). They permit commerce‑offs between velocity, price and autonomy.
Highlights: High‑tier reasoning, imaginative and prescient and coding benchmarks; price effectivity resulting from sparse activation; however notable {hardware} calls for and power‑name failures.
Deployment: Requires a whole bunch of gigabytes of VRAM even after quantization; API entry prices round $0.60 per million enter tokens; Clarifai affords hybrid orchestration.
K2.5 is constructed to sort out complicated multimodal duties with minimal human intervention. It was pretrained on roughly 15 trillion mixed imaginative and prescient and textual content tokens. The spine consists of 61 layers—one dense and 60 MoE layers—housing 384 skilled networks. A router prompts the high eight consultants plus a shared skilled for every token. This sparse routing means solely a small fraction of the mannequin’s trillion parameters hearth on any given ahead go, holding compute manageable whereas preserving excessive capability.
A local MoonViT imaginative and prescient encoder sits contained in the structure, embedding photographs and movies instantly into the language transformer. Mixed with the 256K context made doable by Multi‑Head Latent Consideration (MLA)—a compression method that reduces key–worth cache dimension by round 10×—K2.5 can ingest total paperwork or codebases in a single immediate. The result’s a basic‑objective mannequin that sees, reads and plans.
The second hallmark of K2.5 is its agentic spectrum. Relying on the mode, it both spits out fast solutions, reveals its chain of thought, or orchestrates instruments and sub‑brokers. This spectrum is central to creating the mannequin sensible.
Modes of operation
Immediate mode: Prioritises velocity and price. It suppresses intermediate reasoning, returning solutions in a couple of seconds and consuming as much as 75 % fewer tokens than different modes. Use it for informal Q&A, customer support chats or brief code snippets.
Considering mode: Produces reasoning traces alongside the ultimate reply. It excels on maths and logic benchmarks (e.g., 96.1 % on AIME 2025, 95.4 % on HMMT 2025) however is slower and extra verbose. Appropriate for duties the place transparency is required, comparable to debugging or analysis planning.
Agent mode: Provides the power to name search engines like google, code interpreters and different instruments sequentially. K2.5 can execute 200–300 device calls with out shedding observe. This mode automates workflows like information extraction and report era. Word that about 12 % of device calls can fail, so monitoring and retries are important.
Agent Swarm: Breaks a big job into subtasks and executes them in parallel. It spawns as much as 100 sub‑brokers and delivers ≈4.5× speedups on search duties, enhancing BrowseComp scores from 60.6 % to 78.4 %. Preferrred for extensive literature searches or information‑assortment initiatives; not applicable for latency‑important situations resulting from orchestration overhead.
These modes kind the Kimi Functionality Spectrum—our framework for aligning duties to modes. Map your workload’s want for velocity, transparency and autonomy onto the spectrum: Fast Lookups → Immediate; Analytical Reasoning → Considering; Automated Workflows → Agent; Mass Parallel Analysis → Agent Swarm.
Making use of the Kimi Functionality Spectrum
To floor this framework, think about a product crew constructing a multimodal assist bot. For easy FAQs (“How do I reset my password?”), Immediate mode suffices as a result of latency and price trump reasoning. When the bot must hint via logs or clarify a troubleshooting course of, Considering mode affords transparency: the chain‑of‑thought helps engineers audit why a sure repair was prompt. For extra complicated duties, comparable to producing a compliance report from a number of spreadsheets and information‑base articles, Agent mode orchestrates a code interpreter to parse CSV recordsdata, a search device to tug the most recent coverage and a summariser to compose the report. Lastly, if the bot should scan a whole bunch of authorized paperwork throughout jurisdictions and evaluate them, Agent Swarm shines: sub‑brokers every sort out a subset of paperwork and the orchestrator merges findings. This gradual escalation illustrates why a single mannequin wants distinct modes and the way the aptitude spectrum guides mode choice.
Importantly, the spectrum encourages you to keep away from defaulting to essentially the most complicated mode. Agent Swarm is highly effective, however orchestrating dozens of brokers introduces coordination overhead and price. If a job could be solved sequentially, Agent mode could also be extra environment friendly. Likewise, Considering mode is invaluable for debugging or audits however wastes tokens in a excessive‑quantity chatbot. By explicitly mapping duties to quadrants, groups can maximise worth whereas controlling prices.
How K2.5 achieves scale – structure defined
Sparse MoE layers
Conventional transformers execute the identical dense feed‑ahead layer for each token. K2.5 replaces most of these layers with sparse MoE layers. Every MoE layer comprises 384 consultants, and a gating community routes every token to the highest eight consultants plus a shared skilled. In impact, solely ~3.2 % of the trillion parameters take part in computing any given token. Specialists develop area of interest specialisations—math, code, inventive writing—and the router learns which to choose. Whereas this reduces compute price, it requires storing all consultants in reminiscence for dynamic routing.
Multi‑Head Latent Consideration & context home windows
To attain a 256K‑token context, K2.5 introduces Multi‑Head Latent Consideration (MLA). Reasonably than storing full key–worth pairs for each head, it compresses them right into a shared latent illustration. This reduces KV cache dimension by about tenfold, permitting the mannequin to keep up lengthy contexts. Regardless of this effectivity, lengthy prompts nonetheless enhance latency and reminiscence utilization; many purposes function comfortably inside 8K–32K tokens.
Imaginative and prescient integration
As an alternative of bolting on a separate imaginative and prescient module, K2.5 consists of MoonViT, a 400 million‑parameter imaginative and prescient encoder. MoonViT converts photographs and video frames into embeddings that movement via the identical layers as textual content. The unified coaching improves efficiency on multimodal benchmarks comparable to MMMU‑Professional, MathVision and VideoMMMU. It means you may go screenshots, diagrams or brief clips instantly into K2.5 and obtain reasoning grounded in visible context.
Limitations of the design
Full parameter storage: Despite the fact that solely a fraction of the parameters are lively at any time, the whole weight set should reside in reminiscence. INT4 quantization shrinks this to ≈630 GB, but consideration layers stay in BF16, so reminiscence financial savings are restricted.
Randomness in routing: Slight variations in enter or weight rounding can activate completely different consultants, often producing inconsistent outputs.
Partial quantization: Aggressive quantization right down to 1.58 bits reduces reminiscence however slashes throughput to 1–2 tokens per second.
Key takeaway: K2.5’s structure cleverly balances capability and effectivity via sparse routing and cache compression, however calls for large reminiscence and cautious configuration.
Benchmarks & what they imply
K2.5 performs impressively throughout a spectrum of assessments. These scores present directional steerage moderately than ensures.
Reasoning & information: Achieves 96.1 % on AIME 2025, 95.4 % on HMMT 2025 and 87.1 % on MMLU‑Professional.
Imaginative and prescient & multimodal: Scores 78.5 % on MMMU‑Professional, 84.2 % on MathVision and 86.6 % on VideoMMMU.
Coding: Attains 76.8 % on SWE‑Bench Verified and 85 % on LiveCodeBench v6; anecdotal stories present it may possibly generate full video games and cross‑language code.
Agentic & search duties: With Agent Swarm, BrowseComp accuracy rises from 60.6 % to 78.4 %; Extensive Search climbs from 72.7 % to 79 %.
Value effectivity: Sparse activation and quantization imply the API analysis suite prices roughly $0.27 versus $0.48–$1.14 for proprietary alternate options. Nonetheless, chain‑of‑thought outputs and power calls devour many tokens. Modify temperature and top_p values to handle price.
Decoding scores: Excessive numbers point out potential, not a assure of actual‑world success. Latency will increase with context size and reasoning depth; device‑name failures (~12 %) and verbose outputs can dilute the advantages. All the time take a look at by yourself workloads.
One other nuance usually missed is cache hits. Many API suppliers provide decrease costs when repeated requests hit a cache. When utilizing K2.5 via Clarifai or a 3rd‑occasion API, design your system to reuse prompts or sub‑prompts the place doable. For instance, if a number of brokers want the identical doc abstract, name the summariser as soon as and retailer the output, moderately than invoking the mannequin repeatedly. This not solely saves tokens but additionally reduces latency.
Deployment & infrastructure
Quantization & {hardware}
Deploying K2.5 domestically or on‑prem requires severe assets. The FP16 variant wants practically 2 TB of storage. INT4 quantization reduces weights to ≈630 GB and nonetheless requires eight A100/H100/H200 GPUs. Extra aggressive 2‑bit and 1.58‑bit quantization shrink storage to 375 GB and 240 GB respectively, however throughput drops dramatically. As a result of consideration layers stay in BF16, even the INT4 model requires about 549 GB of VRAM.
API entry
For many groups, the official API affords a extra sensible entry level. Pricing is roughly $0.60 per million enter tokens and $3.00 per million output tokens. This avoids the necessity for GPU clusters, CUDA troubleshooting and quantization configuration. The commerce‑off is much less management over fantastic‑tuning and potential information‑sovereignty issues.
Clarifai’s orchestration & native runners
To strike a stability between comfort and management, Clarifai’s compute orchestration permits K2.5 deployments throughout SaaS, devoted cloud, self‑managed VPCs or on‑prem environments. Clarifai handles containerisation, autoscaling and useful resource administration, decreasing operational overhead.
Clarifai additionally affords native runners: run clarifai mannequin serve domestically and expose your mannequin by way of a safe endpoint. This allows offline experimentation and integration with Clarifai’s pipelines with out committing to cloud infrastructure. You may take a look at quantisation variants on a workstation after which transition to a managed cluster.
Deployment guidelines:
{Hardware} readiness: Do you could have sufficient GPUs and reminiscence? If not, keep away from self‑internet hosting.
Compliance & safety: K2.5 lacks SOC 2/ISO certifications. Use managed platforms if certifications are required.
Price range & latency: Evaluate API prices to {hardware} prices; for sporadic utilization, the API is cheaper.
Workforce experience: With out distributed methods and CUDA experience, managed orchestration or API entry is safer.
Backside line: Begin with the API or native runners for pilots. Contemplate self‑internet hosting solely when workloads justify the funding and you’ll deal with the complexity.
For these considering self‑internet hosting, think about the actual‑world deployment story of a blogger who tried to deploy K2.5’s INT4 variant on 4 H200 GPUs (every with 141 GB HBM). Regardless of cautious sharding, the mannequin ran out of reminiscence as a result of the KV cache—wanted for the 256K context—crammed the remaining house. Offloading to CPU reminiscence allowed inference to proceed, however throughput dropped to 1–2 tokens per second. Such experiences underscore the problem of trillion‑parameter fashions: quantisation reduces the load dimension however doesn’t eradicate the necessity for room to retailer activations and caches. Enterprises ought to price range for headroom past the uncooked weight dimension, and if that isn’t doable, lean on cloud APIs or managed platforms.
Limitations & commerce‑offs
Each mannequin has shortcomings; K2.5 isn’t any exception:
Excessive reminiscence calls for: Even quantised, it wants a whole bunch of gigabytes of VRAM.
Partial quantization: Solely MoE weights are quantised; consideration layers stay in BF16.
Verbosity & latency: Considering and agent modes produce prolonged outputs, elevating prices and delay. Deep analysis duties can take 20 minutes.
Instrument‑name failures & drift: Round 12 % of device calls fail; lengthy periods could drift from the unique aim.
Inconsistency & self‑misidentification: Gating randomness often yields inconsistent solutions or faulty code fixes.
Compliance gaps: Coaching information is undisclosed; no SOC 2/ISO certifications; business deployments should present attribution.
Mitigation methods:
Price range for GPU headroom or select API entry.
Restrict reasoning depth; set most token limits.
Break duties into smaller segments; monitor device calls and embody fallback fashions.
Use human oversight for important outputs and combine area‑particular security filters.
For regulated industries, deploy via platforms that present isolation and audit trails.
These bullet factors are simple to skim, however in addition they suggest deeper operational practices:
{Hardware} planning & scaling: All the time provision extra VRAM than the nominal mannequin dimension to accommodate KV caches and activations. When utilizing quantised variants, take a look at with lifelike prompts to make sure caches match. If utilizing Clarifai’s orchestration, specify useful resource constraints up entrance to forestall oversubscription.
Output administration: Verbose chains of thought inflate prices. Implement truncation methods—for example, discard reasoning content material after extracting the ultimate reply or summarise intermediate steps earlier than storage. In price‑delicate environments, disable pondering mode except an error happens.
Workflow checkpoints: In lengthy agentic periods, create checkpoints. After every main step, consider if the output aligns with the aim. If not, intervene or restart utilizing a smaller mannequin. A easy if–then logic applies: If the agent drift exceeds a threshold, Then swap again to Immediate or Considering mode to re‑orient the duty.
Compliance & auditing: Preserve logs of prompts, device calls and responses. For delicate information, anonymise inputs earlier than sending them to the mannequin. Use Clarifai’s native runners for information that can’t depart your community; the runner exposes a safe endpoint whereas holding weights and activations on‑prem.
Continuous analysis: Fashions evolve. Re‑benchmark after updates or fantastic‑tuning. Over time, routing choices can drift, altering efficiency. Automate periodic analysis of latency, price and accuracy to catch regressions early.
Strategic outlook & AI infra maturity
K2.5 indicators a brand new period the place open fashions rival proprietary ones on complicated duties. This shift empowers organisations to construct bespoke AI stacks however calls for new infrastructure capabilities and governance.
To information adoption, we suggest the AI Infra Maturity Mannequin:
Exploratory Pilot: Check by way of API or Clarifai’s hosted endpoints; collect metrics and crew suggestions.
Hybrid Deployment: Mix API utilization with native runners for delicate information; start integrating with inside workflows.
Full Autonomy: Deploy on devoted clusters by way of Clarifai or in‑home; fantastic‑tune on area information; implement monitoring.
Agentic Ecosystem: Construct a fleet of specialized brokers orchestrated by a central controller; combine retrieval, vector search and customized security mechanisms. Put money into excessive‑availability infrastructure and compliance.
Groups can stay on the stage that finest meets their wants; not each organisation should progress to full autonomy. Consider return on funding, regulatory constraints, and organisational readiness at every step.
Wanting ahead, anticipate bigger, extra multimodal and extra agentic open fashions. Future iterations will probably broaden context home windows, enhance routing effectivity and incorporate native retrieval; regulators will push for better transparency and bias auditing. Platforms like Clarifai will additional democratise deployment via improved orchestration throughout cloud and edge.
These strategic shifts have sensible implications. As an example, as context home windows develop, AI methods will be capable of ingest total supply code repositories or full‑size novels in a single go. That functionality can remodel software program upkeep and literary evaluation, however provided that infrastructure can feed 256K‑plus tokens at acceptable latency. On the agentic entrance, the following era of fashions will probably embody constructed‑in retrieval and reasoning over structured information, decreasing the necessity for exterior search instruments. Groups constructing retrieval‑augmented methods right now ought to architect them with modularity in order that elements could be swapped as fashions mature.
Regulatory adjustments are one other driver. Governments are more and more scrutinising coaching information provenance and bias. Open fashions may have to incorporate datasheets that disclose composition, just like diet labels. Organisations adopting K2.5 ought to put together to reply questions on content material filtering, information privateness and bias mitigation. Utilizing Clarifai’s compliance choices or different regulated platforms will help meet these obligations.
Is K2.5 totally open supply? – It’s open‑weight moderately than open supply; you may obtain and modify weights, however coaching information and code stay proprietary.
What {hardware} do I would like? – INT4 variations require round 630 GB of storage and a number of GPUs; excessive compression lowers this however slows throughput.
How do I entry it? – Chat by way of Kimi.com, name the API, obtain weights from Hugging Face, or deploy via Clarifai’s orchestration.
How a lot does it price? – About $0.60/M enter tokens and $3/M output tokens by way of the API. Self‑internet hosting prices scale with {hardware}.
Does it assist retrieval? – No; combine your individual vector retailer or search engine.
Is it protected and unbiased? – Coaching information is undisclosed, so biases are unknown. Implement publish‑processing filters and human oversight.
Can I fantastic‑tune it? – Sure. The modified MIT licence permits modifications and redistribution. Use parameter‑environment friendly strategies like LoRA or QLoRA to adapt K2.5 to your area with out retraining the whole mannequin. Wonderful‑tuning calls for cautious hyperparameter tuning to protect sparse routing stability.
What’s the true‑world throughput? – Hobbyists report reaching ≈15 tokens per second on twin M3 Extremely machines when utilizing excessive quantisation. Bigger clusters will enhance throughput however nonetheless lag behind dense fashions resulting from routing overhead. Plan batch sizes and asynchronous duties accordingly.
Why select Clarifai over self‑internet hosting? – Clarifai combines the comfort of SaaS with the flexibleness of self‑hosted fashions. You can begin with public nodes, migrate to a devoted occasion or join your individual VPC, all via the identical API. Native runners allow you to prototype offline and nonetheless entry Clarifai’s workflow tooling.
Determination framework
Want multimodal reasoning and lengthy context? → Contemplate K2.5; deploy by way of API or managed orchestration.
Want low latency and easy language duties? → Smaller dense fashions suffice.
Require compliance certifications or secure SLAs? → Select proprietary fashions or regulated platforms.
Have GPU clusters and deep ML experience? → Self‑host K2.5 or orchestrate by way of Clarifai for max management.
Conclusion
Kimi K2.5 is a milestone in open AI. Its trillion‑parameter MoE structure, lengthy context window, imaginative and prescient integration and agentic modes give it capabilities beforehand reserved for closed frontier fashions. For AI infrastructure groups, K2.5 opens new alternatives to construct autonomous pipelines and multimodal purposes whereas controlling prices. But its energy comes with caveats: huge reminiscence wants, partial quantization, verbose outputs, device‑name instability and compliance gaps.
To determine whether or not and the right way to undertake K2.5, use the Kimi Functionality Spectrum to match duties to modes, comply with the AI Infra Maturity Mannequin to stage your adoption, and seek the advice of the deployment guidelines and resolution framework outlined above. Begin small—use the API or native runners for pilots—then scale as you construct experience and infrastructure. Monitor upcoming variations like K2.6 and evolving regulatory landscapes. By balancing innovation with prudence, you may harness K2.5’s strengths whereas mitigating its weaknesses.
Macworld reviews on DarkSword malware focusing on iPhones operating iOS variations 18.4 via 18.7, exploiting six safety vulnerabilities to steal knowledge and observe customers.
Google’s Menace Intelligence Group found this malware toolkit creates three households referred to as Ghostblade, Ghostknife, and Ghostsaber, spreading via malicious web sites.
All vulnerabilities have been patched in iOS 26.3 and earlier variations, making rapid iPhone updates essential for defense.
The Google Menace Intelligence Group has posted a report about malware that makes use of six completely different safety vulnerabilities to assault an iPhone. In accordance with the report, a toolkit referred to as DarkSword has been used to create three malware households referred to as Ghostblade, Ghostknife, and Ghostsaber, and iPhones operating iOS 18.4 to 18.7 are weak.
The entire safety holes utilized by the DarkSword malware have been mounted as of iOS 26.3 (the present model is iOS 26.3.1); most of them have been mounted earlier than 26.3. The most recent model of iOS is eighteen.7.6, launched on March 4. GTIG notes that the menace actors utilizing DarkSword focused customers in Malaysia, Saudi Arabia, Turkey, and Ukraine.
DarkSword creates malware that makes use of JavaScript, and the attacker doesn’t want entry to your system. Moderately, a menace agent embeds the code inside an internet site. When the consumer visits the web site, the JavaScript executes and installs malware on the iPhone that may collect the consumer’s private knowledge, report audio, or examine GS knowledge for the present location. The data is then uploaded to a distant server.
The exploits utilized by DarkSword have been recorded within the Widespread Vulnerabilities and Exposures database as the next:
A probiotic cream may make visits to extraordinarily chilly environments slightly bit safer
Aurora Images, USA
Polar explorers and deep-water divers may someday apply a probiotic cream to their pores and skin to push back frostbite or hypothermia. This optimism comes after scientists genetically engineered micro organism that naturally stay on our pores and skin to detect temperature, and produce extra warmth when wanted, for the primary time.
“It’s very inventive work. You possibly can think about this cream being the distinction between getting frostbite or not,” says Harris Wang at Columbia College in New York, who wasn’t concerned within the analysis. “I can consider many purposes – from conserving heat in winter, stopping frostbite throughout expeditions, to deep-water diving – the place producing warmth is necessary.”
Guillermo Nevot Sánchez at Pompeu Fabra College in Barcelona and his colleagues genetically engineered a pressure of the bacterium Cutibacterium acnes, one of the vital considerable microbes on wholesome pores and skin, to provide twice as a lot warmth as regular. They did this through the use of CRISPR, a genetic software, to alter ranges of a protein referred to as arcC that’s concerned in producing vitality.
The crew additionally used CRISPR to alter the expression of heat-sensitive genes in a separate batch of C. acnes. This meant the microbes may detect temperatures above 32°C (90°F), which they flagged through a fluorescent sign.
Collectively, the findings present the primary proof of idea that pores and skin micro organism might be engineered to provide extra warmth in response to a temperature change, says Nevot Sánchez. The crew now wants to mix these two skills in the identical micro organism, and exhibit that they will detect a harmful drop in temperature, not simply when it’s excessive.
Nevot Sánchez says the crew has carried out experiments, which haven’t but been printed, that present C. acnes strains can survive when blended right into a cream.
“We may develop a probiotic cream that you simply put over a lot of the physique – earlier than climbing into chilly locations, for example – to stop hypothermia,” says Nevot Sánchez, who offered the analysis on the Artificial Biology for Well being and Sustainability convention in Hinxton, UK, on 12 March. It may even assist individuals who stay in harsh climates and don’t have heating, he says.
However additional analysis is required to check the extent to which such a cream truly heats up human pores and skin samples within the lab and on mice earlier than testing it on individuals, says Wang. Engineering methods to kill off the micro organism when desired – by making use of a second cream, for example – may even be essential to restrict potential unintended effects, resembling overheating, says Nevot Sánchez.
Editor’s observe: Mat Marquis and Andy Bell have launched JavaScript for Everybody, an internet course supplied completely at Piccalilli. This put up is an excerpt from the course taken particularly from a chapter all about JavaScript destructuring. We’re publishing it right here as a result of we imagine on this materials and need to encourage of us like your self to join the course. So, please get pleasure from this break from our common broadcasting to get a small style of what you may count on from enrolling within the full JavaScript for Everybody course.
I’ve been writing about JavaScript for lengthy sufficient that I wouldn’t rule out a hubris-related curse of some form. I wrote JavaScript for Net Designers greater than a decade in the past now, again within the period when packs of feral var nonetheless roamed the Earth. The basics are sound, however the recommendation is a bit dated now, for certain. Nonetheless, regardless of being an online growth vintage, one a part of the e-book has aged significantly nicely, to my fixed frustration.
A complete programming language appeared like an excessive amount of to ever absolutely perceive, and I used to be sure that I wasn’t tuned for it. I used to be a developer, certain, however I wasn’t a developer-developer. I didn’t have the requisite robotic mind; I simply put borders on issues for a dwelling.
JavaScript for Net Designers
I nonetheless hear this sentiment from extremely proficient designers and extremely technical CSS specialists that one way or the other can’t fathom calling themselves “JavaScript builders,” as if they had been tragically born with out no matter gland produces the chemical compounds that make an individual innately perceive the idea of variable hoisting and will by no means probably qualify — this even though lots of them write JavaScript as a part of their day-to-day work. Whereas I’ll not stand by means of alert() in a few of my examples (once more, very long time in the past), the spirit of JavaScript for Net Designers holds each bit as true at this time because it did again then: kind a semicolon and also you’re writing JavaScript. Write JavaScript and also you’re a JavaScript developer, full cease.
Now, ultimately, you do run into the catch: no person is born considering like JavaScript, however to get actually good at JavaScript, you will want to study how. In an effort to know why JavaScript works the way in which it does, why generally issues that really feel like they need to work don’t, and why issues that really feel like they shouldn’t work generally do, it’s essential go one step past the code you’re writing and even the results of operating it — it’s essential get inside JavaScript’s head. It is advisable to study to work together with the language by itself phrases.
That deep-magic data is the objective of JavaScript for Everybody, a course designed that will help you get from junior- to senior developer. In JavaScript for Everybody, my purpose is that will help you make sense of the extra arcane guidelines of JavaScript as-it-is-played — not simply train you the how however the why, utilizing the syntaxes you’re most probably to come across in your day-to-day work. In case you’re model new to the language, you’ll stroll away from this course with a foundational understanding of JavaScript value a whole lot of hours of trial-and-error; if you happen to’re a junior developer, you’ll end this course with a depth of data to rival any senior.
Because of our mates right here at CSS-Tips, I’m in a position to share your entire lesson on destructuring task. These are a few of my favourite JavaScript syntaxes, which I’m certain we will all agree are regular and in reality very cool issues to have —syntaxes are as highly effective as they’re terse, all of them doing quite a lot of work with just a few characters. The draw back of that terseness is that it makes these syntaxes a bit extra opaque than most, particularly if you’re armed solely with a browser tab open to MDN and a gleam in your eye. We bought this, although — by the point you’ve reached the tip of this lesson, you’ll be unpacking advanced nested information buildings with the perfect of them.
Once you’re working with a knowledge construction like an array or object literal, you’ll regularly end up in a state of affairs the place you need to seize some or all the values that construction comprises and use them to initialize discrete variables. That makes these values simpler to work with, however traditionally talking, it may possibly result in fairly wordy code:
That is high quality! I imply, it works; it has for thirty years now. However as of 2015’s ES6, we’ve had a way more elegant choice: destructuring.
Destructuring lets you extract particular person values from an array or object and assign them to a set of identifiers while not having to entry the keys and/or values one by one. In its simplest kind — known as binding sample destructuring — every worth is unpacked from the array or object literal and assigned to a corresponding identifier, all of that are declared with a single let or const (or var, technically, sure, high quality). Brace your self, as a result of this can be a unusual one:
That’s the good things, even when it’s a little bizarre to see brackets on that facet of an task operator. That one binding covers all the identical territory because the way more verbose snippet above it.
When working with an array, the person identifiers are wrapped in a pair of array-style brackets, and every comma separated identifier you specify inside these brackets will likely be initialized with the worth within the corresponding ingredient within the supply Array. You’ll generally see destructuring known as unpacking a knowledge construction, however regardless of how that and “destructuring” each sound, the unique array or object isn’t modified by the method.
Components will be ignored by omitting an identifier between commas, the way in which you’d pass over a worth when making a sparse array:
There are a few variations in the way you destructure an object utilizing binding sample destructuring. The identifiers are wrapped in a pair of curly braces fairly than brackets; smart sufficient, contemplating we’re coping with objects. Within the easiest model of this syntax, the identifiers you employ need to correspond to the property keys:
An array is an listed assortment, and listed collections are supposed for use in methods the place the particular iteration order issues — for instance, with destructuring right here, the place we will assume that the identifiers we specify will correspond to the weather within the array, in sequential order.
That’s not the case with an object, which is a keyed assortment — in strict technical phrases, only a huge ol’ pile of properties which are supposed to be outlined and accessed in no matter order, based mostly on their keys. No huge deal in apply, although; odds are, you’d need to use the property keys’ identifier names (or one thing very comparable) as your identifiers anyway. Easy and efficient, however the downside is that it assumes a given… nicely, construction to the article being destructured.
This brings us to the alternate syntax, which appears to be like completely wild, no less than to me. The syntax is object literal formed, however very, very completely different — so earlier than you take a look at this, briefly overlook all the things you understand about object literals:
You’re nonetheless not desirous about object literal notation, proper? As a result of if you happen to had been, wow would that syntax look unusual. I imply, a reference to the property to be destructured the place a key could be and identifiers the place the values could be?
Luckily, we’re not desirous about object literal notation even a bit bit proper now, so I don’t have to put in writing that earlier paragraph within the first place. As an alternative, we will body it like this: throughout the parentheses-wrapped curly braces, zero or extra comma-separated cases of the property key with the worth we would like, adopted by a colon, adopted by the identifier we would like that property’s worth assigned to. After the curly braces, an task operator (=) and the article to be destructured. That’s all quite a bit in print, I do know, however you’ll get a really feel for it after utilizing it a couple of instances.
The second strategy to destructuring is task sample destructuring. With task patterns, the worth of every destructured property is assigned to a selected goal — like a variable we declared with let (or, technically, var), a property of one other object, or a component in an array.
When working with arrays and variables declared with let, task sample destructuring actually simply provides a step the place you declare the variables that can find yourself containing the destructured values:
Now, if you happen to wished to make use of these destructured values to populate one other array or the properties of an object, you’ll hit a predictable double-declaration wall when utilizing binding sample destructuring:
// Error
const theArray = [ true, false ];
let theResultArray = [];
let [ theResultArray[1], theResultArray[0] ] = theArray;
// Uncaught SyntaxError: redeclaration of let theResultArray
We are able to’t make let/const/var do something however create variables; that’s their complete deal. Within the instance above, the primary a part of the road is interpreted as let theResultArray, and we get an error: theResultArray was already declared.
No such concern after we’re utilizing task sample destructuring:
You’ll discover a pair of disambiguating parentheses across the line the place we’re doing the destructuring. You’ve seen this earlier than: with out the grouping operator, a pair of curly braces in a context the place a press release is anticipated is assumed to be a block assertion, and also you get a syntax error:
To date this isn’t doing something that binding sample destructuring couldn’t. We’re utilizing identifiers that match the property keys, however any identifier will do, if we use the alternate object destructuring syntax:
As soon as once more, nothing binding sample destructuring couldn’t do. However not like binding sample destructuring, any sort of task goal will work with task sample destructuring:
With both syntax, you may set “default” values that will likely be used if a component or property isn’t current in any respect, or it comprises an express undefined worth:
const theArray = [ true, undefined ];
const [ firstElement, secondElement = "A string.", thirdElement = 100 ] = theArray;
console.log( firstElement );
// End result: true
console.log( secondElement );
// End result: A string.
console.log( thirdElement );
// End result: 100
const theObject = {
"theProperty" : true,
"theOtherProperty" : undefined
};
const { theProperty, theOtherProperty = "A string.", aThirdProperty = 100 } = theObject;
console.log( theProperty );
// End result: true
console.log( theOtherProperty );
// End result: A string.
console.log( aThirdProperty );
// End result: 100
Snazzy stuff for certain, however the place this syntax actually shines is if you’re unpacking nested arrays and objects. Naturally, there’s nothing stopping you from unpacking an object that comprises an object as a property worth, then unpacking that interior object individually:
However we will make this far more concise. We don’t need to unpack the nested object individually — we will unpack it as a part of the identical binding:
From an object inside an object to a few easy-to-use constants in a single line of code.
We are able to unpack combined information buildings simply as succinctly:
const theObject = [{
"aProperty" : true,
},{
"anotherProperty" : "A string."
}];
const [{ aProperty }, { anotherProperty }] = theObject;
console.log( anotherProperty );
// End result: A string.
A dense syntax, there’s no query of that — bordering on “opaque,” even. It’d take a bit experimentation to get the dangle of this one, however as soon as it clicks, destructuring task provides you an extremely fast and handy approach to break down advanced information buildings with out spinning up a bunch of intermediate information buildings and values.
Relaxation Properties
In all of the examples above we’ve been working with identified portions: “flip these X properties or components into Y variables.” That doesn’t match the fact of breaking down an enormous, tangled object, jam-packed array, or each.
Within the context of a destructuring task, an ellipsis (that’s ..., not …, for my fellow Unicode fanatics) adopted by an identifier (to the tune of ...theIdentifier) represents a relaxation property — an identifier that can signify the remaining of the array or object being unpacked. This relaxation property will comprise all of the remaining components or properties past those we’ve explicitly unpacked to their very own identifiers, all bundled up in the identical sort of information construction because the one we’re unpacking:
Typically I attempt to keep away from utilizing examples that veer too near real-world use on goal the place they’ll get a bit convoluted and I don’t need to distract from the core concepts — however on this case, “convoluted” is strictly what we’re seeking to work round. So let’s use an object close to and pricey to my coronary heart: (a part of) the info representing the very first e-newsletter I despatched out again once I began penning this course.
const firstPost = {
"id": "mat-update-1.md",
"slug": "mat-update-1",
"physique": "Hey, nice to fulfill you, all people. I am Mat — "Wilto" is nice too — and I am right here to show you JavaScript. Not simply what JavaScript is or what JavaScript does, however the *how* and the *why* of JavaScript. The bizarre stuff. The *deep magic_.nnWell, okay, I am not *presently* right here to show you JavaScript, however I will likely be quickly. Proper now I am simply getting issues to ensure that the course — planning, outlining, sprucing the flamboyant semicolons that I solely take out once I'm having firm over, writing like 5,000 phrases about `this` as a warm-up that fully bought away from me, that sort of factor.",
"assortment": "emails",
"information": {
"title": "Meet your Teacher",
"pubDate": "2025-05-08T09:55:00.630Z",
"headingSize": "massive",
"showUnsubscribeLink": true,
"stream": "javascript-for-everyone"
}
};
Fairly a bit occurring in there. For functions of this train, assume that is coming in from an exterior API the way in which it’s over on my web site — this isn’t an object we management. Certain, we will work with that object instantly, however that’s a bit unwieldy when all we want is, for instance, the e-newsletter title and physique:
const firstPost = {
"id": "mat-update-1.md",
"slug": "mat-update-1",
"physique": "Hey, nice to fulfill you, all people. I am Mat — "Wilto" is nice too — and I am right here to show you JavaScript. Not simply what JavaScript is or what JavaScript does, however the *how* and the *why* of JavaScript. The bizarre stuff. The *deep magic_.nnWell, okay, I am not *presently* right here to show you JavaScript, however I will likely be quickly. Proper now I am simply getting issues to ensure that the course — planning, outlining, sprucing the flamboyant semicolons that I solely take out once I'm having firm over, writing like 5,000 phrases about `this` as a warm-up that fully bought away from me, that sort of factor.",
"information": {
"title": "Meet your Teacher",
"pubDate": "2025-05-08T09:55:00.630Z",
"headingSize": "massive",
"showUnsubscribeLink": true,
"stream": "javascript-for-everyone"
}
};
const { information : { title }, physique } = firstPost;
console.log( title );
// End result: Meet your Teacher
console.log( physique );
/* End result:
Hey, nice to fulfill you, all people. I am Mat — "Wilto" is nice too — and I am right here to show you JavaScript. Not simply what JavaScript is or what JavaScript does, however the *how* and the *why* of JavaScript. The bizarre stuff. The *deep magic_.
Effectively, okay, I am not *presently* right here to show you JavaScript, however I will likely be quickly. Proper now I am simply getting issues to ensure that the course — planning, outlining, sprucing the flamboyant semicolons that I solely take out once I'm having firm over, writing like 5,000 phrases about `this` as a warm-up that fully bought away from me, that sort of factor.
*/
That’s tidy; a pair dozen characters and we’ve got precisely what we want from that tangle. I do know I’m not going to want these id or slug properties to publish it alone web site, so I omit these altogether — however that interior information object has a conspicuous ring to it, like perhaps one might count on it to comprise different properties related to future posts. I don’t know what these properties will likely be, however I do know I’ll need all of them packaged up in a manner the place I can simply make use of them. I would like the firstPost.information.title property in isolation, however I additionally need an object containing all of the relaxation of the firstPost.information properties, no matter they find yourself being:
const firstPost = {
"id": "mat-update-1.md",
"slug": "mat-update-1",
"physique": "Hey, nice to fulfill you, all people. I am Mat — "Wilto" is nice too — and I am right here to show you JavaScript. Not simply what JavaScript is or what JavaScript does, however the *how* and the *why* of JavaScript. The bizarre stuff. The *deep magic_.nnWell, okay, I am not *presently* right here to show you JavaScript, however I will likely be quickly. Proper now I am simply getting issues to ensure that the course — planning, outlining, sprucing the flamboyant semicolons that I solely take out once I'm having firm over, writing like 5,000 phrases about `this` as a warm-up that fully bought away from me, that sort of factor.",
"information": {
"title": "Meet your Teacher",
"pubDate": "2025-05-08T09:55:00.630Z",
"headingSize": "massive",
"showUnsubscribeLink": true,
"stream": "javascript-for-everyone"
}
};
const { information : { title, ...metaData }, physique } = firstPost;
console.log( title );
// End result: Meet your Teacher
console.log( metaData );
// End result: Object { pubDate: "2025-05-08T09:55:00.630Z", headingSize: "massive", showUnsubscribeLink: true, stream: "javascript-for-everyone" }
Now we’re speaking. Now we’ve got a metaData object containing something and all the things else within the information property of the article we’ve been handed.
Hear. In case you’re something like me, even if you happen to haven’t fairly gotten your head across the syntax itself, you’ll discover that there’s one thing viscerally satisfying concerning the binding within the snippet above. All that work achieved in a single line of code. It’s terse, it’s elegant — it takes the advanced and makes it easy. That’s the good things.
And but: perhaps you may hear it too, ever-so-faintly? A quiet voice, manner down at the back of your thoughts, that asks “I ponder if there’s a good higher manner.” For what we’re doing right here, in isolation, this answer is about pretty much as good because it will get — however so far as the huge world of JavaScript goes: there’s all the time a greater manner. In case you can’t hear it simply but, I guess you’ll by the tip of the course.
Anybody who writes JavaScript is a JavaScript developer; there aren’t any two methods about that. However the satisfaction of making order from chaos in only a few keystrokes, and the drive to search out even higher methods to do it? These are the makings of a JavaScript developer to be reckoned with.
You are able to do extra than simply “get by” with JavaScript; I do know you may. You’ll be able to perceive JavaScript, all the way in which right down to the mechanisms that energy the language — the gears and comes that transfer your entire “interactive” layer of the online. To actually perceive JavaScript is to grasp the boundaries of how customers work together with the issues we’re constructing, and broadening our understanding of the medium we work with every single day sharpens all of our expertise, from structure to accessibility to front-end efficiency to typography. Understanding JavaScript means much less “I ponder if it’s potential to…” and “I assume we’ve got to…” in your day-to-day choice making, even if you happen to’re not the one tasked with writing it. Increasing our skillsets will all the time make us higher — and extra valued, professionally — irrespective of our roles.
JavaScript is a difficult factor to study; I do know that each one too nicely — that’s why I wrote JavaScript for Everybody. You are able to do this, and I’m right here to assist.
Claude Expertise (or Agent Expertise) can flip a easy AI assistant into one thing way more highly effective. However most individuals hit the identical wall: they don’t know the place to search out them?
Constructing expertise from scratch is gradual. The smarter transfer is to make use of production-ready Claude Code expertise that builders are already sharing on GitHub. This checklist covers one of the best repositories the place you could find 1000+ free Claude-compatible expertise, from automation workflows to agent techniques.
That is the official GitHub repository of Claude Code expertise. Maintained by Anthropic, this repository exhibits how Claude Expertise are literally designed and used internally. The repository additionally lists the official expertise (supplied by Anthropic) that can be utilized in our workflows.
What makes this repository particular?
17 official Claude expertise
Doc creation workflows
Safe and updates expertise
Clear, well-documented examples
Finest for: Understanding the muse of Claude Expertise earlier than exploring bigger repositories.
This repo stands out as a result of it goes past Claude. The assist for this repository extends to OpenAI Codex, Gemini CLI, OpenClaw, Cursor and lots of extra AI instruments. It contains over 200 expertise that additionally work throughout a number of AI instruments.
What makes this repository particular?
200+ production-ready expertise
Compatibility with Codex, Gemini CLI, Cursor, and extra
Developer-focused workflows
Open-source license
Finest for: Builders working throughout a number of AI ecosystems.
A curated checklist of 200+ agent expertise from builders and groups. This may not be the one-stop for procuring Claude expertise, however what’s affords is high quality. This repo focuses on high quality over amount, making it simpler to search out usable expertise with out digging.
What makes this repository particular?
Multi-step agent workflows
Actual-world automation use circumstances
Recurrently up to date neighborhood contributions
Curated checklist of most used expertise
Finest for: Builders on the lookout for sensible, ready-to-use expertise.
The most important repository on this checklist. With 1200+ expertise, it covers virtually each use case you’ll be able to consider. That is a type of repositories which can be value bookmarking for additional reference (24k+ Github stars proves the purpose).
What makes this repository particular?
1,200+ agentic expertise
Works with Claude, Copilot, Cursor, Gemini CLI
Big selection of automation and dev workflows
Extremely trusted by a lot of customers
Finest for: Customers who desire a large library of expertise in a single place.
That is the place Claude turns into an agent that really does issues. The abilities offered on this repository are constructed for workflow automation. And one of the best half is: All the talents are coding assistant agnostic. That means the talents aren’t restricted to Claude ecosystem.
What makes this repository particular?
Excessive compatibility of expertise throughout AI coding assistants
Elaborate checklist of Automation Expertise
Fixed including retains the checklist up to date
Expertise can join with 1000+ apps
Finest for: Customers who need automation and real-world integrations, not simply textual content output.
If you wish to be taught extra about expertise in Claude code, consult with What are Expertise?
Last Ideas
Claude Expertise are probably the most highly effective methods to degree up your workflow. It’s a level-up choice for brokers, and might be put in on a coding assistant in below a minute. This plug-and-play property of Claude Expertise make them a goto alternative for AI workflows.
However the true benefit comes from utilizing the proper expertise, not the most expertise.
Begin with Anthropic’s official repo for readability
Transfer to VoltAgent for curated workflows
Use ComposioHQ for actual automation
Discover antigravity while you want scale
Choose based mostly in your use case, not hype. Spend the additional time discovering the talent appropriate on your utility would make the time worthwhile later down the road.
Q1. What are Claude Expertise and the way do they work?
A. Claude Expertise are reusable workflows that assist Claude carry out duties like automation, coding, and structured outputs utilizing predefined directions and instruments.
Q2. The place can I discover free Claude Code Expertise?
A. You could find free Claude Expertise on GitHub repositories like anthropics/expertise, VoltAgent, and antigravity, providing 1000+ ready-to-use workflows.
Q3. Can Claude Expertise be used with different AI fashions?
A. Sure, many Claude Expertise might be tailored for different LLMs like ChatGPT or Gemini, although some require modifications for compatibility.
I concentrate on reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, knowledge evaluation, and knowledge retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and luxuriate in expert-curated content material.
Like all transformative applied sciences, akin to e mail within the office and even calculators in school rooms, turning into mainstream takes time. We are able to take into consideration the rise of AI brokers within the workforce and the adoption of Anthropic’s Mannequin Context Protocol (MCP) — a brand new customary for linking AI assistants on to the programs the place information lives — as the newest traits on this cycle.
The time period AI agent has gained recognition solely prior to now 12 months, highlighting simply how new brokers are. Many enterprises are experimenting with AI brokers, however few have absolutely built-in them into on a regular basis workflows. That is partly as a result of, like most new applied sciences, brokers require enhancements to turn out to be actually helpful for customers.
A serious impediment to AI adoption is connecting AI programs to the appropriate enterprise instruments and information in a safe, constant method. Because of this, AI brokers are promising, however not fairly relevant throughout each workflow.
That is shortly altering. It looks as if each week brings a brand new mannequin replace or improved interoperability between brokers and the context they should carry out precisely. New developments are pushing the capabilities of AI brokers to the subsequent degree, largely because of MCP.
Enterprises adopting MCP are making a extra dependable method for AI programs to entry the information they want. You possibly can consider MCP like a well-designed freeway for AI and information. As a substitute of every firm constructing its personal disconnected roads, MCP gives a standardized route for information to maneuver shortly and securely to the brokers. As extra corporations use MCP servers to attach with brokers from different platforms, brokers will turn out to be extra useful in real-world purposes.
You possibly can consider MCP like a well-designed freeway for AI and information.
Three causes for adopting MCP
Entry to context throughout platforms: AI brokers are solely as helpful because the context they’ll entry. By standardizing how AI programs hook up with information, MCP permits brokers to work collectively throughout platforms, enabling context-aware purposes. Think about a gross sales rep prepping for a buyer name. As a substitute of logging into a number of programs, an AI agent powered by MCP can immediately pull the newest CRM updates, fetch supporting paperwork, and even coordinate workflows throughout apps like ServiceNow or Snowflake. With a safe API name by way of MCP, the agent will get precisely the context it must ship related insights.
Compounding AI ecosystem worth: MCP is rising as the brand new rulebook for enterprise AI, and its impression grows exponentially as every firm adopts it. The extra corporations that undertake the protocol, the extra interoperable AI brokers turn out to be, making a virtuous cycle.
Enterprise-grade safety: With MCP, AI fashions do not want direct entry to each system or database, they simply must know which MCP servers can be found. Every server enforces strict entry controls, guaranteeing that AI brokers can work together with solely the information and actions they’re licensed to make use of. This reduces the danger of unauthorized entry or information leaks whereas sustaining its context-aware performance.
As MCP adoption spreads, AI brokers will progress. Every new implementation strengthens the ecosystem and gives an enormous value-add for purchasers who can use AI brokers throughout platforms for his or her private workflows with out worrying about safety leaks. The extra corporations embrace MCP, the nearer we get to a future the place AI brokers are absolutely built-in companions in on a regular basis work.










")