My Gmail e-mail philosophy is easy: preserve all emails within the All Mail folder for the remainder of time. Nevertheless, Gmail contains a number of organizational instruments that will let you absolutely management your mailbox, from customized guidelines to labels, filters, and its new AI smarts. One administration motion that has stood the check of time is Archive.
This little instrument is only a horizontal swipe on an e-mail away, instantly eradicating it from the Inbox and stuffing it out of view. This, in a way, is a useful choice. It pushes customers in direction of that revered inbox zero, but it surely’s terribly ineffective when you take a look at it critically.
Though archiving is as previous as Gmail, it has been damaged for over a decade. Let me clarify.
Do you employ the archiving function in Gmail?
61 votes
An archivist’s nightmare
Andy Walker / Android Authority
First, to know the issue, I have to clarify how Gmail handles your array of emails.
Each e-mail saved in Gmail is positioned throughout the All Mail location. Every little thing else, together with your Inbox, will not be a folder or bodily location however a label. This digital submitting cupboard technique is an effective way to arrange mail. It’s very similar to a bodily ring binder that hosts each leaf of paper, however differentiated by sleeves and colourful dividers.
With every thing current in a single place, you possibly can successfully categorize, tag, and filter mail utilizing customized guidelines and search filters. In principle, this allows you to discover each e-mail you’ve ever obtained, however this system has issues, particularly relating to Gmail’s superficial archival technique.
Archiving emails doesn’t clear up your Gmail account; it merely makes emails harder to retrieve.
Once you archive an e-mail in Gmail, it doesn’t put it in a particular archival location inside Gmail. As a substitute, it strips the Inbox tag from the mail, eradicating it from the app’s most-trafficked mail label, and returns it to All Mail with no label. On the floor, it is a good factor. It removes that e-mail from instant view however retains it saved in your account. Nevertheless, when you don’t give this e-mail a customized tag earlier than archiving it, it’ll turn out to be difficult to search out that particular e-mail once more.
Importantly, not like unread mails, Gmail doesn’t particularly spotlight archived mails as archived. Due to this fact, remembering particular particulars about an e-mail or trying to find emails with out labels is the one dependable method to search these out. Certain, I’d be capable of retrieve the espresso shop-related e-mail I archived earlier immediately. Nevertheless, when you archive hundreds of unlabeled emails throughout a number of months, discovering that one you have been despatched a yr in the past all of a sudden turns into a near-impossible process.
Andy Walker / Android Authority
Gmail’s idea of archival goes towards the definition of the method. Basically, archiving entails gathering objects for long-term storage, however, and very importantly, cataloging is a core tenet of the method. Gmail doesn’t mechanically categorize and even label archived mail. So, in brief, archiving emails doesn’t clear up your Gmail account; it merely makes emails harder to retrieve.
Don’t need to miss one of the best from Android Authority?
So, why do I’ve an issue with Gmail’s archiving system once I don’t explicitly use the function? Properly, right here’s the place we stumbled into a bit downside attributable to the confluence of two Android options. Like many different Android customers, I swipe left from the best fringe of my display screen to return. By the way, swiping horizontally in both course on an e-mail in Gmail archives that e-mail. Naturally, this results in many, many by accident shadow-realmed emails.
Gmail does not give archived emails their very own label, making discovering them a chore and a problem.
Nevertheless, this downside extends to different Gmail app and internet interface areas, even for individuals who could actively use the function. There isn’t a simple method to discover archived emails. You should use the search string has:nouserlabels -in:inbox in Gmail’s search bar to deliver up unlabeled archived emails, however that is one thing I anticipate few to recollect, not to mention use usually.
A repair I’ve been ready a long time for
C. Scott Brown / Android Authority
This will likely appear to be an issue that may solely be resolved by Google revising the way it shops emails. Maybe establishing a bodily archive folder alongside All Mails would simplify this course of. Properly, sure, however there’s a far easier and extra instant resolution.
Archived emails must be mechanically labeled and accessible via an Archive shortcut on the Gmail app and the net interface’s sidebars. It truly is that easy. This could permit customers to shed emails from the Inbox label and supply a direct line to archived emails if the necessity ought to ever come up — all with out requiring search operators.
Archived emails must be mechanically labeled and accessible via an Archive shortcut on the Gmail app. It is that easy.
Moreover, I might admire better management over the swipe-to-archive motion. When you can change what the swipe actions do, the choices are fairly restricted. I’d fairly like the power to alter this gesture to star or apply a customized label to emails. I’m certain a number of energy customers would really like this, too.
I can’t fathom why Google has ignored Gmail’s archiving system for thus lengthy. Most of its rivals, together with Microsoft Outlook, Yahoo Mail, Proton Mail, and Apple Mail, provide much more approachable methods to entry archived emails. Finally, this downside is as previous as Gmail, so I’d a lot sooner belief pigs to fly than Google to treatment it.
Thanks for being a part of our neighborhood. Learn our Remark Coverage earlier than posting.
The 1937 disappearance of Amelia Earhart and Fred Noonan was briefly within the information within the final week or so. A marketing campaign, apparently primarily based within the Northern Marianas, to launch any papers held by the US authorities discovered a prepared ear within the present US administration.
I don’t assume any of these papers have but been launched, and there’s little or no probability they’ve any new data if/when they’re. However it did remind me I had lengthy meant to search for the precise key places concerned.
The expectation/hope of these concerned in pushing for a launch of papers is that they are going to present Earhart and Noonan ended up within the Japanese South Seas Mandate, in the end in Saipan (within the Northern Mariana Islands, now a US territory), and had been executed as some native oral traditions declare.
Why do I believe there can be no new data? Think about what could be wanted for the US to carry papers casting gentle on this:
Earhart and Noonan must gone far astray—both fully within the unsuitable course to finish up in Saipan immediately which appears to require an implausible diploma of incompetence, or nonetheless considerably (>1000km astray) to finish up within the Marshall Islands.
The Japanese would have needed to made secret captives of them, quite than both celebrating the rescue as a prestige-boost (bear in mind Japan and the USA had been in a tense, however removed from conflict, relationship at this level) or parading them as spies.
The Japanese must have saved this so secret on the time that no materials or archived proof has ever been discovered of it, aside from by US authorities.
The US must have discovered about this—both within the preliminary very in depth search in 1937, or after World Battle II whereas in occupation of Japan—and for some unfathomable cause saved it secret themselves.
This mix simply appears vanishingly unlikely to me so I bravely make the prediction that the approaching launch of information from the US will reveal nothing substantive new in regards to the matter. However nothing is for certain! I’ll humbly admit I’m unsuitable if needed.
There’s respectable Wikipedia articles on Amelia Earhart, and on the speculations about their disappearance. I received’t attempt to comprehensively summarise these as I’ve nothing actually so as to add, however the latter article offers a very good, easy abstract:
“Hypothesis on the disappearance of Amelia Earhart and Fred Noonan has continued since their disappearance in 1937. After the biggest search and rescue try in historical past as much as that point, the U.S. Navy concluded that Earhart and Noonan ditched at sea after their airplane ran out of gas; this “crash and sink idea” is essentially the most broadly accepted rationalization. Nevertheless, a number of different hypotheses have been thought of.”
Earhart and Noonan took off from Lae in Papua New Guinea and headed to Howland Island which is now an integrated territory of america.
A key truth is that the final obtained radio message from Earhart and Noonan was that they had been flying alongside a line of place operating north-to-south on 157–337 levels. This means they’d reached the place they thought Howland Island must be and had turned at a pointy angle—both simply east of south, or simply west of north—to attempt to discover it.
The non-insane key hypotheses for what occurred as soon as they acquired roughly within the neighborhood of Howland Island are (in descending order of plausibility):
They discovered no land, ran out of gas and crashed into the ocean
they travelled on a 157 diploma bearing (south of south-east), discovered Gardner Island (now Nikumaroro, a part of Kiribati), crashed there and ultimately died of thirst or starvation
they turned too early, travelled on a 337 diploma bearing (north of north-west) and ended up within the Marshall Islands, maybe Mili or Jaluit Atoll and had been picked up by the Japanese.
So I drew this chart, with key options together with:
the important thing locations named above
the trendy names of the areas that made up the Japanese-controlled South Seas Mandate
The 157-337 diploma line of place reported by Earhart and Noonan, if it had been centred on Howland Island (noting in fact that they in all probability weren’t really centered there, however a bit away from it, or they might have discovered it).
I’ve put it on a large enough scale to actually get a way of the huge distances and large our bodies of water concerned.
What I like about this map is that we will see these places in context unexpectedly—nothing in essentially the most accessible elements of the net coping with this situation does this for me, though I’m certain it’s been accomplished someplace. We are able to immediately see, for instance, how implausible it’s that Earhart and Noonan really flew to Saipan themselves. They might not have been flawless navigators (or I wouldn’t be scripting this in any respect), however they had been removed from clueless learners to set off at 90 levels to their supposed course.
I believe there have been a variety of issues that may have gone unsuitable for me right here. I needed to manually kind in a variety of latitudes and longitudes, I solely did a couple of hours studying and considering on the entire matter, I needed to do numerous advert hoc issues to work out what was meant by the road of place, draw a Pacific-centred map, and so on. In order ordinary, any suggestions may be very welcome and if what I’ve accomplished is dangerous sufficient I’ll repair it.
That’s it actually. Pesonally, I believe the commonly accepted reply that they acquired a bit of astray, ran out of gas and crashed within the ocean someplace near the place they had been heading (however not shut sufficient, sadly) may be very probably certainly.
Right here’s the code that pulls the map:
library(tidyverse)library(ggrepel)# Lae airfield, PNG https://en.wikipedia.org/wiki/Lae_Airfield# https://en.wikipedia.org/wiki/Howland_Island# different lat and lengthy equally taken from the opposite wikipedia articles# longitudes which might be west of 180 levels rely at first as damaging for this# approach of centering a map on Pacific:earhart<-tribble(~lat,~lengthy,~identify,~kind,-(6+43/60+59/3600),(146+59/60+45/3600),"Lae Airfield","Origin",0+48/60+25.84/3600,-(176+36/60+59.48/3600),"Howland Island","Deliberate",-(4+40/60+32/3600),-(174+31/60+4/3600),"Nikumaroro","Unlikely",15+11/60,(145+45/60),"Saipan","Unlikely",5+55/60+18/3600,(169+38/60+33/3600),"Jaluit Atoll","Unlikely",6+8/60,(171+55/60),"Mili Atoll","Unlikely")|># repair these damaging longitudes to work on a 0:360 scale:mutate(lengthy=ifelse(lengthy<0,lengthy+360,lengthy))# the 157/337 line of place, centred on Howland Island# 23 levels to the west of north, 23 levels to the east of south# tan(angle) = reverse / adjoining. so if we set north/south arbitrarily to be 8 for drawing our line,adjoining<-8reverse<-tan(-23*pi/180)*adjoininglop<-tibble(lat=earhart[2,]$lat+c(-1,1)*adjoining,lengthy=earhart[2,]$lengthy+c(-1,1)*reverse)# construct a background map out of two maps joined collectively.mp1<-fortify(maps::map(fill=TRUE,plot=FALSE))|>as_tibble()mp2<-mp1|>mutate(lengthy=lengthy+360,group=group+max(mp1$group)+1)mp<-rbind(mp1,mp2)|>filter(lengthy>90&lengthy<360&lat<50&lat>-60)|>mutate(japan=ifelse(area%in%c("Japan","Marshall Islands","Palau","Northern Mariana Islands","Micronesia","North Korea","South Korea"),"Japanese-controlled","Not Japanese-controlled"))# some factors for labels ofjapanese-controlled labelsjap<-mp|>filter(japan=="Japanese-controlled")|>group_by(area)|>summarise(lengthy=median(lengthy),lat=median(lat))|># tweaks for label positionsmutate(lat=case_when(area=="Northern Mariana Islands"~lat+2.0,area=="Marshall Islands"~lat+3.3,TRUE~lat))# the potential, unlikely color and linetypeplt<-2laptop<-"lightsalmon"# {the japanese} managed colorjc<-"pink"# the color for the deliberate line of journey:plcol<-"darkblue"# draw the precise plotggplot(mp,aes(x=lengthy,y=lat))+# add background mapgeom_polygon(aes(group=group),fill="grey60")+coord_map(xlim=c(100,206),ylim=c(-22,35))+# add labels of Japanese-controlled areas:geom_label(knowledge=jap,aes(label=area),color=jc)+# three traces from Lae outwards"geom_segment(xend=earhart[1,]$lengthy,yend=earhart[1,]$lat,knowledge=earhart[-1,],aes(color=kind,linetype=kind),linewidth=2)+# two traces from Howland Island:geom_segment(xend=earhart[2,]$lengthy,yend=earhart[2,]$lat,knowledge=earhart[-(1:2),],color=laptop,linetype=plt,linewidth=2)+# line of place reported by Earhart and Noonangeom_line(knowledge=lop)+# factors and labels of assorted placesgeom_point(knowledge=earhart,measurement=4,color="white",form=19)+geom_label_repel(knowledge=earhart[1:3,],aes(label=identify),color="grey20",alpha=0.9,seed=123)+geom_label_repel(knowledge=earhart[4:6,],aes(label=identify),color=jc,alpha=0.9,seed=123)+# annotations:annotate("textual content",x=182,y=6.2,hjust=0,measurement=3,label=str_wrap("Line of place reported by Earhart and Noonan whereas searching for Howland Island.",40))+annotate("textual content",x=189,y=-7,hjust=0,measurement=3,label=str_wrap("Nikumaroro, or Gardner Island, has been searched repeatedly and no agency proof discovered.",36))+annotate("textual content",x=140,y=21.5,hjust=0,measurement=3,label=str_wrap("Witnesses claimed to see the execution of Earhart and Noonan by Japanese troopers in Saipan however no information, different confirming proof or motivation have been discovered.",58))+annotate("textual content",x=152,y=10,label="Japan's South Seas Mandate",color=jc)+# scales, colors, themes, and so on:scale_linetype_manual(values=c(1,plt))+scale_colour_manual(values=c(plcol,laptop))+scale_x_continuous(breaks=c(120,150,180,210),labels=c("120E","150E","180","150W"))+labs(x="",y="",linetype="Routes",color="Routes",title="Key places referring to disappearance of Amelia Earhart and Fred Noonan in 1937",subtitle="Almost definitely rationalization was operating out of gas and crash in ocean close to Howland Island")+theme(panel.background=element_rect(fill="lightblue"),legend.place=c(0.963,0.064))
That’s all people. Take your navigation significantly!
A greater understanding of dementia threat can result in enhancements in care and in therapies, and a brand new research identifies a hyperlink between adjustments in mind form and declines in cognitive features – corresponding to reminiscence and reasoning.
The thought is that a number of the put on and tear that ultimately results in dementia also can alter the mind’s construction and form, and searching for these shifts may very well be a comparatively easy manner of unveiling dementia early.
These new findings are from researchers on the College of California, Irvine (UC Irvine) and the College of La Laguna in Spain, they usually construct on what we already learn about how the mind naturally shrinks as we grow old.
“Most research of mind getting old deal with how a lot tissue is misplaced in numerous areas,” says neuroscientist Niels Janssen, from the College of La Laguna.
“What we discovered is that the general form of the mind shifts in systematic methods, and people shifts are carefully tied as to whether somebody reveals cognitive impairment.”
The research charted mind construction adjustments throughout particular areas. (Escalante et al., Nat. Commun., 2025)
The workforce analyzed 2,603 MRI mind scans from individuals aged from 30 to 97, monitoring structural and form adjustments over time and mapping them in opposition to members’ cognitive take a look at scores.
Age-related expansions and contractions in mind form weren’t even throughout all of the mind areas, the researchers discovered, and in these individuals experiencing some stage of cognitive decline, the unevenness tended to be extra noticeable.
For instance, areas of the mind in the direction of the again of the pinnacle had been proven to shrink with age, and particularly for individuals who scored decrease on reasoning means assessments. Much more information goes to be required to determine these relationships extra exactly, however this research suggests they exist.
There are additional implications for neurodegenerative illnesses corresponding to Alzheimer’s, the place mind injury accumulates.
The researchers suggest {that a} essential reminiscence hub referred to as the entorhinal cortex could also be put beneath stress by age-related form shifts – and that is the identical area the place poisonous proteins linked to Alzheimer’s sometimes begin congregating.
“This might assist clarify why the entorhinal cortex is floor zero of Alzheimer’s pathology,” says neuroscientist Michael Yassa, from UC Irvine. “If the getting old mind is regularly shifting in a manner that squeezes this fragile area in opposition to a inflexible boundary, it might create the proper storm for injury to take root.”
“Understanding that course of provides us an entire new manner to consider the mechanisms of Alzheimer’s illness and the opportunity of early detection.”
Extra mind scans and extra exact measurements will assist progress this analysis additional. The workforce is eager to discover why some mind areas could broaden with age and the way this pertains to cognition.
The takeaway: it is proof that it isn’t simply the mind quantity that issues in well being and getting old, but in addition the 3D form of the mind – made up of many alternative areas all working collectively to maintain our minds sharp and energetic.
“We’re simply starting to unlock how mind geometry shapes illness,” says Yassa. “However this analysis reveals that the solutions could also be hiding in plain sight – within the form of the mind itself.”
Synthetic Intelligence (AI) is reworking industries and the epicentre of this revolution is the AI Product Supervisor. For the reason that enterprise world is scrambling to use machine studying, Pure Language Processing (NLP), pc imaginative and prescient and automation to its providers, the need to search out individuals who can fill the hole between what the enterprise needs to attain and what AI can do is rising exponentially.
On this information, you’ll study what an AI product supervisor is and what abilities it is advisable be an AIproduct supervisor, profession paths, most important tasks, and the right way to enter into this high-impact profession.
Who’s an AI Product Supervisor?
The position of an AI Product Supervisor (AI PM) is to determine enterprise alternatives the place AI may be utilized, collaborate with knowledge science and engineering groups to develop options, and be certain that merchandise created with the assistance of AI ship precise worth to customers.
In distinction to conventional PMs, AI PMs should work with unpredictable mannequin habits, knowledge constraints, and moral issues, and wish a mixture of technical experience, product-first first and accountable AI experience.
Key Duties
Collaborate with knowledge scientists, engineers, and stakeholders
Outline product imaginative and prescient and AI use circumstances
Handle mannequin lifecycle (from prototyping to deployment)
Consider AI efficiency and iterate based mostly on suggestions
Guarantee compliance with equity, accountability, and transparency requirements
Expertise Required for AI Product Supervisor Roles
To succeed as an AI product supervisor, you want a novel mixture of technical, enterprise, and tender abilities:
1. AI and Machine Studying Fundamentals
Understanding supervised and unsupervised studying, mannequin analysis metrics, knowledge pipelines, and the constraints of AI programs is crucial. You don’t must construct fashions, however you will need to perceive how they work.
2. Product Administration Experience
Defining product technique and roadmaps
Conducting market and person analysis
Prioritizing options utilizing frameworks like RICE or MoSCoW
Agile and Scrum methodologies
3. Information Literacy and Analytics
You should be snug working with knowledge, deciphering dashboards, collaborating on knowledge labeling duties, and asking the correct questions throughout error evaluation.
ML lifecycle instruments (e.g., MLflow, Weights & Biases) can considerably assist in working with technical groups.
Instructional Background and Studying Paths
There’s no single path, however a powerful basis in pc science, engineering, or knowledge science is typical. Many professionals additionally come from enterprise or UX backgrounds and later upskill in AI.
Beneficial Studying Paths:
AI and ML certifications from IITs, Stanford, or Nice Studying
PM bootcamps specializing in tech merchandise
On-line specializations in Accountable AI and mannequin governance
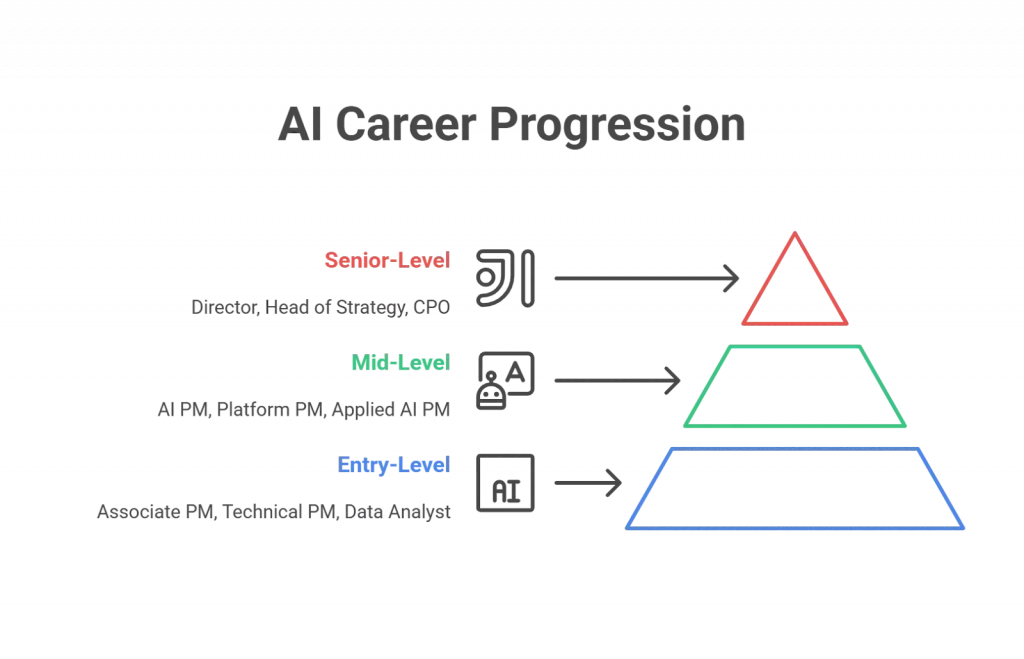
Profession Path & Development
Wage Expectations
Salaries fluctuate by area and firm dimension. Usually:
In India, entry-level AI PMs can count on ₹17–37 LPA at prime companies, with senior roles exceeding ₹50+ LPA.
Roadmap to Turning into an AI Product Supervisor
It is a step-by-step plan that will help you alongside the way in which:
Step 1: Study the rules of AI merchandise
Turn out to be aware of the methods the AI merchandise distinction with typical software program, taking note of iteration, the dependencies on knowledge, and the probabilistic outcomes.
Step 2: Purchase AI fundamentals
Study ML, NLP, deep studying, and mannequin evaluation. Sensible work will improve your confidence. Study now for free of charge with these AI and ML programs on the Nice Studying Academy.
Step 3: Develop a Product Pondering
Start creating product specs, person story writing and person journey evaluation. To get a really feel of working, use Miro and Notion.
Step 4: Open Supply or AI Undertaking Work
Staff up with knowledge scientists in GitHub or Kaggle. It will help you to study workflows and achieve credibility.
Step 5: Making use of to be a PM or APM in AI Groups
Deal with start-ups, analysis facilities, and AI-first enterprises. Show a capability to translate engineering data to product decisions.
Final Recommendation to Would-Be AI Product Managers
Sustain with AI tendencies (e.g., GenAI, LLMs, edge AI)
Learn Google, Meta, and OpenAI case research
Deal with person experiences, even on workflows that contain loads of knowledge
Take part in AI and PM meetups, webinars and hackathons
Assemble a portfolio of your product imaginative and prescient and data of how the mannequin works
The trail to changing into an AI product supervisor is a worthwhile one to those that are capable of mix data-driven pondering, empathy in the direction of customers, and technical fluency.
With the AI revolutionizing industries, AI PMs might be on the forefront of creating moral, scalable, and impactful merchandise.
Steadily Requested Questions(FAQs)
1. Does one should be a knowledge scientist to be an AI PM?
No. You must have a data of machine studying rules and processes, though you shouldn’t be anticipated to create fashions. Crucial factor you are able to do is to reconcile product technique and technical feasibility.
2. Do AI product managers should code?
Not essentially. Though familiarity with Python or knowledge querying is useful, AI PMs usually are not anticipated to spend their days writing code or engaged on the technical aspect of the merchandise they work on.
3. Which instruments are to be discovered?
Such instruments as Jupyter Notebooks, SQL, MLflow, Tableau, Jira, Figma, and Confluence may be helpful. It’s extra important to be tool-agnostic and data-aware slightly than to know one explicit device.
4. What’s the technique of changing into an AI PM when I’m a software program PM?
Start with the fundamentals of ML, and creating AI-adjacent options, and straight collaborate with knowledge science teams to get a really feel of the model-building lifecycle and its product implications.
5. Which industries want AI product managers in the present day?
The demand for AI PMs exists in lots of industries, together with healthcare, finance, e-commerce, SaaS, edtech, automotive, and generative AI startups. Each sector that makes use of knowledge and automation is recruiting.
mall makes use of Massive Language Fashions (LLM) to run
Pure Language Processing (NLP) operations towards your knowledge. This bundle
is accessible for each R, and Python. Model 0.2.0 has been launched to CRAN and PyPi respectively.
In R, you may set up the most recent model with:
In Python, with:
This launch expands the variety of LLM suppliers you should use with mall. Additionally,
in Python it introduces the choice to run the NLP operations over string vectors,
and in R, it permits assist for ‘parallelized’ requests.
It’s also very thrilling to announce a model new cheatsheet for this bundle. It
is accessible in print (PDF) and HTML format!
Extra LLM suppliers
The most important spotlight of this launch is the the flexibility to make use of exterior LLM
suppliers corresponding to OpenAI, Gemini
and Anthropic. As a substitute of writing integration for
every supplier one after the other, mall makes use of specialised integration packages to behave as
intermediates.
In R, mall makes use of the ellmer bundle
to combine with quite a lot of LLM suppliers.
To entry the brand new characteristic, first create a chat connection, after which move that
connection to llm_use(). Right here is an instance of connecting and utilizing OpenAI:
In Python, mall makes use of chatlas as
the combination level with the LLM. chatlas additionally integrates with a number of LLM suppliers.
To make use of, first instantiate a chatlas chat connection class, after which move that
to the Polars knowledge body by way of the .llm.use() perform:
Connecting mall to exterior LLM suppliers introduces a consideration of value.
Most suppliers cost for the usage of their API, so there’s a potential {that a}
massive desk, with lengthy texts, might be an costly operation.
Parallel requests (R solely)
A brand new characteristic launched in ellmer 0.3.0
permits the entry to submit a number of prompts in parallel, slightly than in sequence.
This makes it sooner, and probably cheaper, to course of a desk. If the supplier
helps this characteristic, ellmer is ready to leverage it by way of the parallel_chat()
perform. Gemini and OpenAI assist the characteristic.
Within the new launch of mall, the combination with ellmer has been specifically
written to benefit from parallel chat. The internals have been re-written to
submit the NLP-specific directions as a system message so as
cut back the scale of every immediate. Moreover, the cache system has additionally been
re-tooled to assist batched requests.
NLP operations and not using a desk
Since its preliminary model, mall has offered the flexibility for R customers to carry out
the NLP operations over a string vector, in different phrases, without having a desk.
Beginning with the brand new launch, mall additionally gives this similar performance
in its Python model.
mall can course of vectors contained in a record object. To make use of, initialize a
new LLMVec class object with both an Ollama mannequin, or a chatlasChat
object, after which entry the identical NLP features because the Polars extension.
# Initialize a Chat objectfrom chatlas import ChatOllamachat = ChatOllama(mannequin ="llama3.2")# Move it to a brand new LLMVecfrom mall import LLMVecllm = LLMVec(chat)
Entry the features by way of the brand new LLMVec object, and move the textual content to be processed.
llm.sentiment(["I am happy", "I am sad"])#> ['positive', 'negative']llm.translate(["Este es el mejor dia!"], "english")#> ['This is the best day!']
For extra data go to the reference web page: LLMVec
New cheatsheet
The model new official cheatsheet is now out there from Posit: Pure Language processing utilizing LLMs in R/Python.
Its imply characteristic is that one aspect of the web page is devoted to the R model,
and the opposite aspect of the web page to the Python model.
An net web page model can be availabe within the official cheatsheet website right here. It takes
benefit of the tab characteristic that lets you choose between R and Python
explanations and examples.
I wrote a weblog submit in 2023 titled A Stata command to run ChatGPT, and it stays in style. Sadly, OpenAI has modified the API code, and the chatgpt command in that submit now not runs. On this submit, I’ll present you methods to replace the API code and methods to write related Stata instructions that use Claude, Gemini, and Grok like this:
. chatgpt "Write a haiku about Stata."
Knowledge flows with ease,
Stata charts the silent truths,
Insights bloom in code.
. claude "Write a haiku about Stata."
Here's a haiku about Stata:
Stata, my previous buddy
Analyzing knowledge with ease
Insights ever discovered
. gemini "Write a haiku about Stata."
Instructions stream so quick,
Knowledge formed, fashions outlined,
Insights now seem.
. grok "Write a haiku about Stata."
Knowledge streams unfold,
Stata weaves the threads of fact,
Insights bloom in code.
The main focus of this submit, just like the earlier one, is to display how simple it’s to make the most of the PyStata options to hook up with ChatGPT and different AI instruments moderately than to provide recommendation on methods to use AI instruments to reply Stata-specific questions. Subsequently, the examples I present merely ask for a haiku about Stata. Nonetheless, you may cross any request that you’d discover useful in your Stata workflow.
Evaluate of Stata/Python integration
I’ll assume that you’re acquainted with Stata/Python integration and methods to write the unique chatgpt command. It would be best to learn the weblog posts under if these subjects are unfamiliar.
Updating the ChatGPT command
You will want an Open AI person account and your personal Open AI API key to make use of the code under. I used to be unable to make use of my previous API key from 2023, and I needed to create a brand new key.
Additionally, you will have to sort shell pip set up openai within the Stata Command window to set up the Python bundleopenai. It’s possible you’ll want to make use of a special technique to put in the openai bundle if you’re utilizing Python as a part of a platform reminiscent of Anaconda. I needed to sort shell pip uninstall openai to take away the previous model and sort shell pip set up openai to put in the newer model.
Subsequent we might want to exchange the previous Python code with newer code utilizing the trendy API syntax. I typed python operate to immediate chatgpt by way of api right into a search engine that led me to the Developer quickstart web page on the OpenAI web site. Some studying adopted by trial and error resulted within the Python code under. The Python operate query_openai() sends the immediate by way of the API, makes use of the “gpt-4.1-mini” mannequin, and receives the response. I didn’t embody any choices for different fashions, however you may change the mannequin should you like.
The remaining Python code does three issues with the response. First, it prints the response in Stata’s Outcomes window. Second, it writes the response to a file named chatgpt_output.txt. And third, it makes use of Stata’s SFI module to cross the response from Python to a neighborhood macro in Stata. The third step works effectively for easy responses, however it might result in errors for lengthy responses that embody nonstandard characters or many single or double quotations. You may place a # character at the start of the road “Macro.setLocal(…” to remark out that line and forestall the error.
It can save you the code under to a file named chatgpt.ado, place the file in your private ado-folder, and use it like another Stata command. You may sort adopath to find your private ado-folder.
seize program drop chatgpt program chatgpt, rclass model 19.5 // (or model 19 should you shouldn't have StataNow) args InputText show "" python: query_openai("`InputText'", "gpt-4.1-mini") return native OutputText = `"`OutputText'"' finish
python: import os from openai import OpenAI from sfi import Macro
def query_openai(immediate: str, mannequin: str = "gpt-4.1-mini") -> str: # Move the enter string from a Stata native macro to Python inputtext = Macro.getLocal('InputText')
# Ship the immediate by way of the API and obtain the response response = consumer.chat.completions.create( mannequin= mannequin, messages=[ {“role”: “user”, “content”: inputtext} ] )
# Print the response within the Outcomes window print(response.selections[0].message.content material)
# Write the response to a textual content file f = open(“chatgpt_output.txt”, “w”) f.write(response.selections[0].message.content material) f.shut()
# Move the response string from Python again to a Stata native macro Macro.setLocal(“OutputText”, response.selections[0].message.content material) finish
Now we will run our chatgpt command and look at the response within the Outcomes window.
. chatgpt "Write a haiku about Stata."
Knowledge flows with ease,
Stata charts the silent truths,
Insights bloom in code.
We will sort return checklist to view the response saved within the native macro r(OutputText).
. return checklist
macros:
r(OutputText) : "Knowledge flows with ease, Stata charts the silent truths, Insights bloom .."
And we will sort sort chatgpt_output.txt to view the response saved within the file chatgpt_output.txt.
. sort chatgpt_output.txt
Knowledge flows with ease,
Stata charts the silent truths,
Insights bloom in code.
It labored! Let’s see whether or not we will use an analogous technique to create a Stata command for one more AI mannequin.
A Stata command to make use of Claude
Claude is a well-liked AI mannequin developed by Anthropic. Claude contains an API interface, and you will have to arrange a person account and get an API key on its web site. After buying my API key, I typed python operate to question claude api, which led me to the Get began with Claude web site. Once more, some studying and trial and error led to the Python code under. You will want to sort shell pip set up anthropic in Stata’s Command window to put in the anthropic bundle.
Discover how related the Python code under is to the Python code in our chatgpt command. The one main distinction is the code that sends the immediate by way of the API and receives the response. Every little thing else is sort of similar.
It can save you the code under to a file named claude.ado, put the file in your private ado-folder, and use it similar to another Stata command.
seize program drop claude program claude, rclass model 19.5 // (or model 19 should you shouldn't have StataNow) args InputText show "" python: query_claude() return native OutputText = `"`OutputText'"' finish
python: import os from sfi import Macro from anthropic import Anthropic
def query_claude(): # Move the enter string from a Stata native macro to Python inputtext = Macro.getLocal('InputText')
# Ship the immediate by way of the API and obtain the response response = consumer.messages.create( mannequin=”claude-3-haiku-20240307″, max_tokens=1000, messages=[ {“role”: “user”, “content”: inputtext} ] )
# Print the response to the Outcomes window print(response.content material[0].textual content)
# Write the response to a textual content file f = open(“claude_output.txt”, “w”) f.write(response.content material[0].textual content) f.shut()
# Move the response string from Python again to a Stata native macro Macro.setLocal(“OutputText”, response.content material[0].textual content)
finish
Now we will run our claude command and look at the response.
. claude "Write a haiku about Stata."
Here's a haiku about Stata:
Stata, my previous buddy
Analyzing knowledge with ease
Insights ever discovered
We will sort return checklist to view the response saved within the native macro r(OutputText).
. return checklist
macros:
r(OutputText) : "Here's a haiku about Stata: Stata, my previous buddy Analyzing knowledge with ea.."
And we will sort sort claude_output.txt to view the response saved within the file claude_output.txt.
. sort claude_output.txt
Here's a haiku about Stata:
Stata, my previous buddy
Analyzing knowledge with ease
Insights ever discovered
It’s possible you’ll typically see an error just like the one under. This doesn’t point out an issue along with your code. It’s telling you that the API service or community has timed out or has been interrupted. Merely wait and check out once more.
File "C:UsersChuckStataAppDataLocalProgramsPythonPython313Libsite-packagesanthropic
> _base_client.py", line 1065, in request
elevate APITimeoutError(request=request) from err
anthropic.APITimeoutError: Request timed out or interrupted. This may very well be as a result of a community timeout,
> dropped connection, or request cancellation. See https://docs.anthropic.com/en/api/errors#long-requests
> for extra particulars.r(7102);
A Stata command to make use of Gemini
Gemini is a well-liked AI mannequin developed by Google. Gemini additionally contains an API interface and you will have to arrange a person account and get an API key on its web site. After buying my API key, I typed python operate to question gemini api, which led me to the Gemini API quickstart web site. Once more, some studying and trial and error led to the Python code under. You will want to sort shell pip set up -q -U google-genai in Stata’s Command window to put in the google-genai bundle.
Once more, it can save you the code under to a file named gemini.ado, put the file in your private ado-folder, and use it similar to another Stata command.
seize program drop gemini program gemini, rclass model 19.5 // (or model 19 should you shouldn't have StataNow) args InputText show "" python: query_gemini() return native OutputText = `"`OutputText'"' finish
python: import os from sfi import Macro from google import genai
def query_gemini(): # Move the enter string from a Stata native macro to Python inputtext = Macro.getLocal('InputText')
# Ship immediate by way of the claude API key and get response response = consumer.fashions.generate_content( mannequin=”gemini-2.5-flash”, contents=inputtext )
# Print the response to the Outcomes window print(response.textual content)
# Write the response to a textual content file f = open(“gemini_output.txt”, “w”) f.write(response.textual content) f.shut()
# Move the response string from Python again to a Stata native macro Macro.setLocal(“OutputText”, response.textual content) finish
Now we will run our gemini command and look at the response.
. gemini "Write a haiku about Stata."
Instructions stream so quick,
Knowledge formed, fashions outlined,
Insights now seem.
We will sort return checklist to view the response saved within the native macro r(OutputText).
. return checklist
macros:
r(OutputText) : "Instructions stream so quick, Knowledge formed, fashions outlined, Insights now appea.."
And we will sort sort gemini_output.txt to view the response saved within the file gemini_output.txt.
. sort gemini_output.txt
Instructions stream so quick,
Knowledge formed, fashions outlined,
Insights now seem.
A Stata command to make use of Grok
OK, another only for enjoyable. Grok is one other in style AI mannequin developed by xAI. You will want to arrange a person account and get an API key on its web site. After buying my API key, I typed python operate to question grok api, which led me to the Hitchhiker’s Information to Grok web site. Once more, some studying and trial and error led to the Python code under. You will want to sort shell pip set up xai_sdk in Stata’s Command window to put in the xai_sdk bundle.
As soon as once more, it can save you the code under to a file named grok.ado, put the file in your private ado-folder, and use it similar to another Stata command.
seize program drop grok program grok, rclass model 19.5 // (or model 19 should you shouldn't have StataNow) args InputText show "" python: query_grok("`InputText'", "grok-4") return native OutputText = `"`OutputText'"' finish
python: import os from sfi import Macro from xai_sdk import Consumer from xai_sdk.chat import person, system
def query_grok(immediate: str, mannequin: str = "grok-4") -> str: # Move the enter string from a Stata native macro to Python inputtext = Macro.getLocal('InputText')
# Ship immediate by way of the claude API key and get response chat = consumer.chat.create(mannequin=mannequin) chat.append(person(inputtext)) response = chat.pattern()
# Print the response to the Outcomes window print(response.content material)
# Write the response to a textual content file f = open(“grok_output.txt”, “w”) f.write(response.content material) f.shut()
# Move the response string from Python again to a Stata native macro Macro.setLocal(“OutputText”, response.content material) finish
Now we will run our grok command and look at the response within the Outcomes window.
. grok "Write a haiku about Stata."
Knowledge streams unfold,
Stata weaves the threads of fact,
Insights bloom in code.
We will sort return checklist to view the reply saved within the native macro r(OutputText).
. return checklist
macros:
r(OutputText) : "Knowledge streams unfold, Stata weaves the threads of fact, Insights b.."
And we will sort sort grok_output.txt to view the leads to the file grok_output.txt.
. sort grok_output.txt
Knowledge streams unfold,
Stata weaves the threads of fact,
Insights bloom in code.
Conclusion
I hope the examples above have satisfied you that it’s comparatively simple to write down and replace your personal Stata instructions to run AI fashions. My examples have been deliberately easy and just for instructional functions. However I’m certain you possibly can think about many choices that you may add to permit the usage of different fashions for different kinds of prompts, reminiscent of sound or photos. Maybe a few of you can be impressed to write down your personal instructions and submit them on the internet.
These of you who learn this submit sooner or later could discover it irritating that the API syntax has modified once more and the code above now not works. That is the character of utilizing APIs. They modify and you’ll have to do some homework to replace your code. However there are various sources accessible on the web that can assist you replace your code or write new instructions. Good luck and have enjoyable!
There are two varieties of individuals on this planet: those that take criticism critically, positively, and act on it to make themselves a greater particular person; and those that have an allergic response to any sort of criticism and instantly hearth again a disproportionate assault in return. My private Lex Luthor was once that method. Relaxation in peace, you jerk.
In fact, there are additionally two different kinds of individuals on this planet: those that give trustworthy suggestions, hoping to make the topic of the criticism a greater particular person; and those that nitpick little particulars in an try to interrupt down the topic of their contempt.
This all exists on a spectrum, by the way in which. There are very crucial folks, and individuals who barely complain when an apparent injustice or harm must be addressed. And there are individuals who will curse at you and spit in your face, whereas others are smooth spoken and meek.
Did I actually simply write that?
I was a loudmouth. Stunning for those who’ve met me within the final ten to fifteen years. Not stunning, for those who’ve recognized me since my teenage years. I used to be fairly the hothead in my time. However I at all times caught to 1 rule: I made damned certain the identical criticism couldn’t be thrown in my face. That’s, I checked for beams in my eye earlier than mentioning the motes within the eyes of others. Not solely is it good private coverage, nevertheless it simply helps keep away from pointless arguments to the tune of “I do know you might be, however what am I?”
Plus, Jesus stated it (the half concerning the mote), so it helps with the hyper-religious crowd.
I must really feel one thing
Over the previous few years, we’ve been dwelling in a world of “enragement equals engagement,” and engagement equals money. And, as a result of engagement equals money (simple money, at that), persons are fast to unfold concepts that promote anger. And nothing riles up an individual like feeling attacked for his or her views, or for one thing they don’t have any energy in altering.
It’s a variation on “if it bleeds, it leads,” proper? We take note of tragedies on the information (and even hunt down the movies of tragic occasions) as a result of it makes us really feel… one thing. We take a look at the automobile accidents on our commute, and we really feel fortunate to not be in that predicament. Or we hear a few youngster with most cancers, and we really feel blessed that our child is wholesome.
Again to criticisms
Generally you say or write one thing so spot on that it strikes on the core of who somebody is or what they do. Generally you name out an anti-vaccine activist on their logical fallacies, or level out to the creator of a paper that they did the maths all flawed. Or in my case, it’s not simply “some instances.”
Skilled and mature folks will say one thing like, “Hey, what? I tousled. Level taken.” They’ll even admit to their mistake and be clear about it. Ah, however the different kind, the emotionally immature. Whew! They get defensive. They get indignant. After which they take a look at you, discover the smallest of faults, and go nuclear.
I’ve been known as racial slurs, homophobic slurs (although I’m not homosexual, and I don’t take it as an offense to be named as such), or worse. In public well being discussions, folks typically level out my weight, as if being lean and swarthy would one way or the other validate my level. However I’m one way or the other flawed for liking tacos a bit an excessive amount of?
“Vaccines work,” I’ll say.
“You’re too fats, and I might by no means hearken to you about my well being,” they reply.
“Oh, okay… So let me go for a number of runs and eat some salad so vaccines will one way or the other work after that?”
Ridiculous.
All of it goes again to RFK Jr.
The rationale I’m writing it is because I’m having a tough time with a few of my colleagues being fast to level out that RFK Jr. has (had?) a substance use dysfunction through which he used heroin. He has been very open about this and about his street to sobriety. However a few of my colleagues are fast to level out that we shouldn’t be listening to him due to that dependancy.
It’s no totally different than disqualifying my skilled opinions due to my dependancy to tacos, and it hurts.
It’s more practical to level out the inaccuracies in his use of some proof however not others. Or to criticize his continued promotion of unproven strategies to stop, deal with, or treatment ailments and situations. Heck, I’ll take making enjoyable of his try at wooing a reporter earlier than mentioning his dependancy story. (I’ve by no means tried to woo a reporter, in order that’s why I feel it’s okay. Mote within the eye, keep in mind?)
Don’t hearken to me, although
In fact, you don’t need to hearken to me about any of this. The rationale I write that is to elucidate myself to anybody studying and to future generations on why I do the issues I do and say the issues I say. I actually need my daughter to know that, whereas I was a hothead, I did get higher with time.
And, in relation to debating or profitable arguments, it doesn’t assist to reply criticism with criticism. It’s greatest to be a grown-up and repair our errors.
When an IT staff begins to hunch, it may be a demoralizing, irritating expertise for CIOs and staff leaders. A as soon as vibrant workforce now seems to be caught in a rut as its efficiency dwindles, innovation slumps, and morale crashes.
What can a CIO do to reinvigorate a collapsing IT operation? Katherine Hosie, an government coach at Powerhouse Teaching, mentioned step one needs to be understanding the explanation for the hunch. “Is it burnout and fatigue, disappointment because of previous failures or pivots, or are present objectives too massive, unachievable?” she requested.
Root Causes
Distant work usually results in a slumping IT group, mentioned Surinder Kahai, an affiliate professor at Binghamton College’s College of Administration. “Whereas distant work affords flexibility and reduces unproductive commuting time, it additionally reduces alternatives for social interplay and reference to colleagues and the group,” he defined.
With distant work, there are fewer alternatives to collaborate on revolutionary tasks, which might carry pleasure and pleasure to a staff, Kahai mentioned. “Innovation usually occurs whenever you staff up with somebody fairly totally different from your self and get the chance to carry collectively various concepts and mix them creatively.”
Group flattening — eliminating center managers to chop prices, scale back pink tape, and/or simplify organizational charts — has accelerated lately, forcing managers to make do with much less, Kahai mentioned. The remaining managers now have extra folks of their span of management, difficult them to dedicate the identical period of time to every subordinate as earlier than. “This results in much less communication, recognition, and assist from leaders, which leads to decrease employee engagement.”
Waking up a slumping IT group requires management that invests in staff’ progress and makes them really feel extra valued, Kahai mentioned. “It suggests management that makes IT staff enthusiastic about their work — management with a imaginative and prescient that gives that means and function in what they do.”
As IT staff face uncertainty about their future, constructing a supportive setting the place others perceive their challenges and are keen to assist when wanted can be important. “No worker is immune from work-related uncertainty and stress,” Kahai mentioned. “Employees profit from position fashions who persist of their efforts and present resilience regardless of uncertainty and stress of their lives.”
Getting Again on Observe
As quickly as a hunch turns into evident, alert your staff leaders, Hosie advised. “Allow them to know you’ve got noticed a hunch of their staff and that your motive is to assist them,” she suggested. Sharing your motive will lower nervousness and confusion.
The following step needs to be conducting a radical tech audit, suggested Steve Grant, AI search strategist and founder at Figment. “You will must map the place your workflow is sagging and flag any inefficiencies within the system that gradual issues down,” he mentioned. “In case your fixes are focused and measurable, momentum will construct rapidly, as a result of your groups will see progress in areas which have doubtless lengthy pissed off them.”
The following logical step, Grant mentioned, is to incorporate the staff in setting objectives and selecting priorities. “These are the folks utilizing your system every single day, so involving them instantly builds a way of possession, turning obscure directions into widespread objectives,” he said. “This alteration will drive engagement and accountability and make workers extra invested in outcomes.”
Group leaders and members usually desire the options they develop themselves, Hosie mentioned. “Work along with your groups and assist them discover their very own solutions.” But this may increasingly take numerous restraint, she warned. “Encourage their concepts, even when they are not good after which confirm that their concepts are achievable.
Each resolution should have a single, self-selected, proprietor, Hosie mentioned. “Folks take motion once they know they’re the instantly accountable particular person,” she famous. Roll this idea into future staff conferences and one-on-ones. “It is now on you to make sure they observe by means of.”
An clever and supportive HR enterprise associate is usually a large useful resource, Hosie mentioned. “They’ve doubtless seen these challenges earlier than and might share concepts and even facilitate attainable options.” By no means waste a disaster, she suggested. “It is at all times a chance to develop and turn into stronger as a staff.”
Nonetheless, CIOs face a troublesome job — ensuring that the trains run on time whereas additionally offering course that is properly built-in with enterprise technique. “Each technical and enterprise acumen are important,” Kahai mentioned.
The really tough half, Kahai mentioned, is that CIOs are going through an uphill battle, persuading each senior executives and different decision-makers on hiring and workforce planning in a world the place AI is more and more seen as a panacea to slumping efficiency and productiveness.
the ultimate quarter of 2025, it’s time to step again and study the developments that can form knowledge and AI in 2026.
Whereas the headlines would possibly deal with the most recent mannequin releases and benchmark wars, they’re removed from probably the most transformative developments on the bottom. The true change is taking part in out within the trenches — the place knowledge scientists, knowledge + AI engineers, and AI/ML groups are activating these complicated programs and applied sciences for manufacturing. And unsurprisingly, the push towards manufacturing AI—and its subsequent headwinds in —are steering the ship.
Listed here are the ten developments defining this evolution, and what they imply heading into the ultimate quarter of 2025.
1. “Knowledge + AI leaders” are on the rise
Should you’ve been on LinkedIn in any respect lately, you may need seen a suspicious rise within the variety of knowledge + AI titles in your newsfeed—even amongst your individual staff members.
No, there wasn’t a restructuring you didn’t find out about.
Whereas that is largely a voluntary change amongst these historically categorized as knowledge or AI/ML professionals, this shift in titles displays a actuality on the bottom that Monte Carlo has been discussing for nearly a 12 months now—knowledge and AI are not two separate disciplines.
From the assets and abilities they require to the issues they clear up, knowledge and AI are two sides of a coin. And that actuality is having a demonstrable influence on the way in which each groups and applied sciences have been evolving in 2025 (as you’ll quickly see).
2. Conversational BI is scorching—however it wants a temperature verify
Knowledge democratization has been trending in a single kind or one other for almost a decade now, and Conversational BI is the most recent chapter in that story.
The distinction between conversational BI and each different BI device is the velocity and class with which it guarantees to ship on that utopian imaginative and prescient—even probably the most non-technical area customers.
The premise is easy: if you happen to can ask for it, you may entry it. It’s a win-win for house owners and customers alike…in idea. The problem (as with all democratization efforts) isn’t the device itself—it’s the reliability of the factor you’re democratizing.
The one factor worse than dangerous insights is dangerous insights delivered shortly. Join a chat interface to an ungoverned database, and also you received’t simply speed up entry—you’ll speed up the results.
3. Context engineering is turning into a core self-discipline
Enter prices for AI fashions are roughly 300-400x bigger than the outputs. In case your context knowledge is shackled with issues like incomplete metadata, unstripped HTML, or empty vector arrays, your staff goes to face huge value overruns whereas processing at scale. What’s extra, confused or incomplete context can be a significant AI reliability situation, with ambiguous product names and poor chunking complicated retrievers whereas small adjustments to prompts or fashions can result in dramatically completely different outputs.
Which makes it no shock that context engineering has develop into the buzziest buzz phrase for knowledge + AI groups in mid-year 2025. Context engineering is the systematic strategy of getting ready, optimizing, and sustaining context knowledge for AI fashions. Groups that grasp upstream context monitoring—guaranteeing a dependable corpus and embeddings earlier than they hit costly processing jobs—will see significantly better outcomes from their AI fashions. But it surely received’t work in a silo.
The fact is that visibility into the context knowledge alone can’t handle AI high quality—and neither can AI observability options like evaluations. Groups want a complete strategy that gives visibility into the whole system in manufacturing—from the context knowledge to the mannequin and its outputs. An socio-technical strategy that mixesknowledge + AIcollectively is the one path to dependable AI at scale.
4. The AI enthusiasm hole widens
The most recent MIT report stated all of it. AI has a worth downside. And the blame rests – no less than partially – with the chief staff.
“We nonetheless have a whole lot of people who consider that AI is Magic and can do no matter you need it to do with no thought.”
That’s an actual quote, and it echoes a typical story for knowledge + AI groups
An government who doesn’t perceive the expertise units the precedence
Mission fails to offer worth
Pilot is scrapped
Rinse and repeat
Corporations are spending billions on AI pilots with no clear understanding of the place or how AI will drive influence—and it’s having a demonstrable influence on not solely pilot efficiency, however AI enthusiasm as an entire.
Attending to worth must be the primary, second, and third priorities. Which means empowering the info + AI groups who perceive each the expertise and the info that’s going to energy it with the autonomy to handle actual enterprise issues—and the assets to make these use-cases dependable.
5. Cracking the code on brokers vs. agentic workflows
Whereas agentic aspirations have been fueling the hype machine over the past 18 months, the semantic debate between “agentic AI” an “brokers” was lastly held on the hallowed floor of LinkedIn’s feedback part this summer time.
On the coronary heart of the problem is a cloth distinction between the efficiency and value of those two seemingly an identical however surprisingly divergent ways.
Single-purpose brokers are workhorses for particular, well-defined duties the place the scope is evident and outcomes are predictable. Deploy them for centered, repetitive work.
Agentic workflows deal with messy, multi-step processes by breaking them into manageable parts. The trick is breaking large issues into discrete duties that smaller fashions can deal with, then utilizing bigger fashions to validate and mixture outcomes.
For instance, Monte Carlo’s Troubleshooting Agent makes use of an agentic workflow to orchestrate lots of of sub-agents to analyze the foundation causes of knowledge + AI high quality points.
6. Embedding high quality is within the highlight—and monitoring is true behind it
In contrast to the info merchandise of previous, AI in its numerous varieties isn’t deterministic by nature. What goes in isn’t at all times what comes out. So, demystifying what beauty like on this context means measuring not simply the outputs, but additionally the programs, code, and inputs that feed them.
Embeddings are one such system.
When embeddings fail to characterize the semantic that means of the supply knowledge, AI will obtain the unsuitable context no matter vector database or mannequin efficiency. Which is exactly why embedding high quality is turning into a mission-critical precedence in 2025.
Essentially the most frequent embedding breaks are fundamental knowledge points: empty arrays, unsuitable dimensionality, corrupted vector values, and many others. The issue is that almost all groups will solely uncover these issues when a response is clearly inaccurate.
One Monte Carlo buyer captured the issue completely: “We don’t have any perception into how embeddings are being generated, what the brand new knowledge is, and the way it impacts the coaching course of. We’re frightened of switching embedding fashions as a result of we don’t understand how retraining will have an effect on it. Do we’ve to retrain our fashions that use these things? Do we’ve to utterly begin over?”
As key dimensions of high quality and efficiency come into focus, groups are starting to outline new monitoring methods that may help embeddings in manufacturing; together with components like dimensionality, consistency, and vector completeness, amongst others.
7. Vector databases want a actuality verify
Vector databases aren’t new for 2025. What IS new is that knowledge + AI groups are starting to appreciate these vector databases they’ve been counting on may not be as dependable as they thought.
During the last 24 months, vector databases (which retailer knowledge as high-dimensional vectors that seize semantic that means) have develop into the de facto infrastructure for RAG purposes.And in current months, they’ve additionally develop into a supply of consternation for knowledge + AI groups.
Embeddings drift. Chunking methods shift. Embedding fashions get up to date. All this variation creates silent efficiency degradation that’s usually misdiagnosed as hallucinations — and sending groups down costly rabbit holes to resolve them.
The problem is that, in contrast to conventional databases with built-in monitoring, most groups lack the requisite visibility into vector search, embeddings, and agent conduct to catch vector issues earlier than influence. That is more likely to result in an increase in vector database monitoring implementation, in addition to different observability options to enhance response accuracy.
8. Main mannequin architectures prioritize simplicity over efficiency
The AI mannequin internet hosting panorama is consolidating round two clear winners: Databricks and AWS Bedrock. Each platforms are succeeding by embedding AI capabilities immediately into current knowledge infrastructure reasonably than requiring groups to be taught totally new programs.
Databricks wins with tight integration between mannequin coaching, deployment, and knowledge processing. Groups can fine-tune fashions on the identical platform the place their knowledge lives, eliminating the complexity of transferring knowledge between programs. In the meantime, AWS Bedrock succeeds via breadth and enterprise-grade safety, providing entry to a number of basis fashions from Anthropic, Meta, and others whereas sustaining strict knowledge governance and compliance requirements.
What’s inflicting others to fall behind? Fragmentation and complexity. Platforms that require intensive customized integration work or drive groups to undertake totally new toolchains are shedding to options that match into current workflows.
Groups are selecting AI platforms primarily based on operational simplicity and knowledge integration capabilities reasonably than uncooked mannequin efficiency. The winners perceive that the perfect mannequin is ineffective if it’s too difficult to deploy and preserve reliably.
9. Mannequin Context Protocol (MCP) is the MVP
Mannequin Context Protocol (MCP) has emerged because the game-changing “USB-C for AI”—a common commonplace that lets AI purposes hook up with any knowledge supply with out customized integrations.
As an alternative of constructing separate connectors for each database, CRM, or API, groups can use one protocol to offer LLMs entry to the whole lot on the similar time. And when fashions can pull from a number of knowledge sources seamlessly, they ship quicker, extra correct responses.
Early adopters are already reporting main reductions in integration complexity and upkeep work by specializing in a single MCP implementation that works throughout their whole knowledge ecosystem.
As a bonus, MCP additionally standardizes governance and logging — necessities that matter for enterprise deployment.
However don’t anticipate MCP to remain static. Many knowledge and AI leaders anticipate an Agent Context Protocol (ACP) to emerge inside the subsequent 12 months, dealing with much more complicated context-sharing situations. Groups adopting MCP now might be prepared for these advances as the usual evolves.
10. Unstructured knowledge is the brand new gold (however is it idiot’s gold?)
Most AI purposes depend on unstructured knowledge — like emails, paperwork, photographs, audio information, and help tickets — to offer the wealthy context that makes AI responses helpful.
However whereas groups can monitor structured knowledge with established instruments, unstructured knowledge has lengthy operated in a blind spot. Conventional knowledge high quality monitoring can’t deal with textual content information, photographs, or paperwork in the identical means it tracks database tables.
Options like Monte Carlo’s unstructured knowledge monitoring are addressing this hole for customers by bringing automated high quality checks to textual content and picture fields throughout Snowflake, Databricks, and BigQuery.
Trying forward, unstructured knowledge monitoring will develop into as commonplace as conventional knowledge high quality checks. Organizations will implement complete high quality frameworks that deal with all knowledge — structured and unstructured — as essential belongings requiring energetic monitoring and governance.
Picture: Monte Carlo
Trying ahead to 2026
If 2025 has taught us something up to now, it’s that the groups successful with AI aren’t those with the most important budgets or the flashiest demos. The groups successful the AI race are the groups who’ve found out the way to ship dependable, scalable, and reliable AI in manufacturing.
Winners aren’t made in a testing setting. They’re made within the palms of actual customers. Ship adoptable AI options, and also you’ll ship demonstrable AI worth. It’s that straightforward.
Net scraping sometimes refers to an automated technique of gathering knowledge from web sites. On a excessive stage, you are primarily making a bot that visits a web site, detects the info you are inquisitive about, after which shops it into some acceptable knowledge construction, so you’ll be able to simply analyze and entry it later.
Nonetheless, if you happen to’re involved about your anonymity on the Web, you must in all probability take a little bit extra care when scraping the online. Since your IP deal with is public, a web site proprietor may observe it down and, doubtlessly, block it.
So, if you wish to keep as nameless as attainable, and stop being blocked from visiting a sure web site, you must think about using proxies when scraping the online.
Proxies, additionally known as proxy servers, are specialised servers that allow you to not instantly entry the web sites you are scraping. Relatively, you will be routing your scraping requests by way of a proxy server.
That manner, your IP deal with will get “hidden” behind the IP deal with of the proxy server you are utilizing. This can assist you each keep as nameless as attainable, in addition to not being blocked, so you’ll be able to maintain scraping so long as you need.
On this complete information, you will get a grasp of the fundamentals of net scraping and proxies, you will see the precise, working instance of scraping a web site utilizing proxies in Node.js. Afterward, we’ll talk about why you would possibly think about using current scraping options (like ScraperAPI) over writing your personal net scraper. On the finish, we’ll provide you with some tips about how you can overcome among the commonest points you would possibly face when scraping the online.
Net Scraping
Net scraping is the method of extracting knowledge from web sites. It automates what would in any other case be a handbook technique of gathering info, making the method much less time-consuming and vulnerable to errors.
That manner you’ll be able to acquire a considerable amount of knowledge rapidly and effectively. Later, you’ll be able to analyze, retailer, and use it.
The first motive you would possibly scrape a web site is to acquire knowledge that’s both unavailable by an current API or too huge to gather manually.
It is significantly helpful when you must extract info from a number of pages or when the info is unfold throughout totally different web sites.
There are a lot of real-world purposes that make the most of the ability of net scraping of their enterprise mannequin. Nearly all of apps serving to you observe product costs and reductions, discover least expensive flights and inns, and even acquire job posting knowledge for job seekers, use the strategy of net scraping to assemble the info that gives you the worth.
Net Proxies
Think about you are sending a request to a web site. Often, your request is shipped out of your machine (together with your IP deal with) to the server that hosts a web site you are making an attempt to entry. That implies that the server “is aware of” your IP deal with and it might block you primarily based in your geo-location, the quantity of site visitors you are sending to the web site, and lots of extra elements.
However once you ship a request by a proxy, it routes the request by one other server, hiding your authentic IP deal with behind the IP deal with of the proxy server. This not solely helps in sustaining anonymity but additionally performs an important function in avoiding IP blocking, which is a typical challenge in net scraping.
By rotating by totally different IP addresses, proxies can help you distribute your requests, making them seem as in the event that they’re coming from numerous customers. This reduces the probability of getting blocked and will increase the possibilities of efficiently scraping the specified knowledge.
Varieties of Proxies
Usually, there are 4 major sorts of proxy servers – datacenter, residential, rotating, and cell.
Every of them has its execs and cons, and primarily based on that, you will use them for various functions and at totally different prices.
Datacenter proxies are the commonest and cost-effective proxies, offered by third-party knowledge facilities. They provide excessive velocity and reliability however are extra simply detectable and could be blocked by web sites extra steadily.
Residential proxies route your requests by actual residential IP addresses. Since they seem as atypical consumer connections, they’re much less prone to be blocked however are sometimes dearer.
Rotating proxies robotically change the IP deal with after every request or after a set interval. That is significantly helpful for large-scale scraping initiatives, because it considerably reduces the possibilities of being detected and blocked.
Cellular proxies use IP addresses related to cell gadgets. They’re extremely efficient for scraping mobile-optimized web sites or apps and are much less prone to be blocked, however they sometimes come at a premium price.
ISP proxies are a more moderen sort that mixes the reliability of datacenter proxies with the legitimacy of residential IPs. They use IP addresses from Web Service Suppliers however are hosted in knowledge facilities, providing a stability between efficiency and detection avoidance.
Instance Net Scraping Venture
Let’s stroll by a sensible instance of an internet scraping venture, and show how you can arrange a fundamental scraper, combine proxies, and use a scraping service like ScraperAPI.
Organising
Earlier than you dive into the precise scraping course of, it is important to arrange your improvement setting.
For this instance, we’ll be utilizing Node.js because it’s well-suited for net scraping attributable to its asynchronous capabilities. We’ll use Axios for making HTTP requests, and Cheerio to parse and manipulate HTML (that is contained within the response of the HTTP request).
First, guarantee you could have Node.js put in in your system. If you do not have it, obtain and set up it from nodejs.org.
Then, create a brand new listing to your venture and initialize it:
$ mkdir my-web-scraping-project
$ cd my-web-scraping-project
$ npm init -y
Lastly, set up Axios and Cheerio since they’re obligatory so that you can implement your net scraping logic:
$ npm set up axios cheerio
Easy Net Scraping Script
Now that your setting is ready up, let’s create a easy net scraping script. We’ll scrape a pattern web site to assemble well-known quotes and their authors.
So, create a JavaScript file named sample-scraper.js and write all of the code within it. Import the packages you will have to ship HTTP requests and manipulate the HTML:
Subsequent, create a wrapper perform that can include all of the logic you must scrape knowledge from an internet web page. It accepts the URL of a web site you need to scrape as an argument and returns all of the quotes discovered on the web page:
Word: All of the quotes are saved in a separate div ingredient with a category of quote. Every quote has its textual content and creator – textual content is saved below the span ingredient with the category of textual content, and the creator is throughout the small ingredient with the category of creator.
Lastly, specify the URL of the web site you need to scrape – on this case, https://quotes.toscrape.com, and name the scrapeWebsite() perform:
All that is left so that you can do is to run the script from the terminal:
$ node sample-scraper.js
Integrating Proxies
To make use of a proxy with axios, you specify the proxy settings within the request configuration. The axios.get() technique can embody the proxy configuration, permitting the request to route by the desired proxy server. The proxy object comprises the host, port, and non-obligatory authentication particulars for the proxy:
Word: You’ll want to exchange these placeholders together with your precise proxy particulars.
Apart from this transformation, the complete script stays the identical:
Take a look at our hands-on, sensible information to studying Git, with best-practices, industry-accepted requirements, and included cheat sheet. Cease Googling Git instructions and truly study it!
For web sites with advanced JavaScript interactions, you would possibly want to make use of a headless browser as a substitute of easy HTTP requests. Instruments like Puppeteer or Playwright can help you automate an actual browser, execute JavaScript, and work together with dynamic content material.
Headless browsers can be configured to make use of proxies, making them highly effective instruments for scraping advanced web sites whereas sustaining anonymity.
Integrating a Scraping Service
Utilizing a scraping service like ScraperAPI affords a number of benefits over handbook net scraping because it’s designed to deal with all the main issues you would possibly face when scraping web sites:
Mechanically handles frequent net scraping obstacles resembling CAPTCHAs, JavaScript rendering, and IP blocks.
Mechanically handles proxies – proxy configuration, rotation, and rather more.
As an alternative of constructing your personal scraping infrastructure, you’ll be able to leverage ScraperAPI’s pre-built options. This saves vital improvement time and sources that may be higher spent on analyzing the scraped knowledge.
ScraperAPI affords numerous customization choices resembling geo-location focusing on, customized headers, and asynchronous scraping. You’ll be able to personalize the service to fit your particular scraping wants.
Utilizing a scraping API like ScraperAPI is usually more cost effective than constructing and sustaining your personal scraping infrastructure. The pricing is predicated on utilization, permitting you to scale up or down as wanted.
ScraperAPI permits you to scale your scraping efforts by dealing with tens of millions of requests concurrently.
To implement the ScraperAPI proxy into the scraping script you have created to date, there are only a few tweaks you must make within the axios configuration.
To start with, guarantee you could have created a free ScraperAPI account. That manner, you will have entry to your API key, which might be obligatory within the following steps.
When you get the API key, use it as a password within the axios proxy configuration from the earlier part:
And, that is it, all your requests might be routed by the ScraperAPI proxy servers.
However to make use of the total potential of a scraping service you will must configure it utilizing the service’s dashboard – ScraperAPI is not any totally different right here.
It has a user-friendly dashboard the place you’ll be able to arrange the online scraping course of to greatest suit your wants. You’ll be able to allow proxy or async mode, JavaScript rendering, set a area from the place the requests might be despatched, set your personal HTTP headers, timeouts, and rather more.
And the very best factor is that ScraperAPI robotically generates a script containing all the scraper settings, so you’ll be able to simply combine the scraper into your codebase.
Greatest Practices for Utilizing Proxies in Net Scraping
Not each proxy supplier and its configuration are the identical. So, it is necessary to know what proxy service to decide on and how you can configure it correctly.
Let’s check out some suggestions and methods that will help you with that!
Rotate Proxies Usually
Implement a proxy rotation technique that modifications the IP deal with after a sure variety of requests or at common intervals. This strategy can mimic human shopping habits, making it much less probably for web sites to flag your actions as suspicious.
Deal with Price Limits
Many web sites implement price limits to stop extreme scraping. To keep away from hitting these limits, you’ll be able to:
Introduce Delays: Add random delays between requests to simulate human habits.
Monitor Response Codes: Monitor HTTP response codes to detect when you find yourself being rate-limited. Should you obtain a 429 (Too Many Requests) response, pause your scraping for some time earlier than making an attempt once more.
Implement Exponential Backoff: Relatively than utilizing mounted delays, implement exponential backoff that will increase wait time after every failed request, which is more practical at dealing with price limits.
Use High quality Proxies
Selecting high-quality proxies is essential for profitable net scraping. High quality proxies, particularly residential ones, are much less prone to be detected and banned by goal web sites. That is why it is essential to know how you can use residential proxies for your online business, enabling you to seek out useful leads whereas avoiding web site bans. Utilizing a mixture of high-quality proxies can considerably improve your possibilities of profitable scraping with out interruptions.
High quality proxy providers usually present a variety of IP addresses from totally different areas, enabling you to bypass geo-restrictions and entry localized content material. A proxy extension for Chrome additionally helps handle these IPs simply by your browser, providing a seamless method to swap places on the fly.
Dependable proxy providers can supply sooner response instances and better uptime, which is important when scraping massive quantities of information.
Nonetheless, keep away from utilizing a proxy that’s publicly accessible with out authentication, generally known as an open proxy. These are sometimes gradual, simply detected, banned, and will pose safety threats. They’ll originate from hacked gadgets or misconfigured servers, making them unreliable and doubtlessly harmful.
As your scraping wants develop, gaining access to a sturdy proxy service permits you to scale your operations with out the effort of managing your personal infrastructure.
Utilizing a good proxy service usually comes with buyer help and upkeep, which might prevent effort and time in troubleshooting points associated to proxies.
Dealing with CAPTCHAs and Different Challenges
CAPTCHAs and anti-bot mechanisms are among the commonest obstacles you will encounter whereas scraping an internet.
Web sites use CAPTCHAs to stop automated entry by making an attempt to distinguish actual people and automatic bots. They’re attaining that by prompting the customers to unravel numerous sorts of puzzles, establish distorted objects, and so forth. That may make it actually tough so that you can robotically scrape knowledge.
Though there are a lot of each handbook and automatic CAPTCHA solvers obtainable on-line, the very best technique for dealing with CAPTCHAs is to keep away from triggering them within the first place. Usually, they’re triggered when non-human habits is detected. For instance, a considerable amount of site visitors, despatched from a single IP deal with, utilizing the identical HTTP configuration is certainly a pink flag!
So, when scraping a web site, strive mimicking human habits as a lot as attainable:
Add delays between requests and unfold them out as a lot as you’ll be able to.
Usually rotate between a number of IP addresses utilizing a proxy service.
Randomize HTTP headers and consumer brokers.
Keep and use cookies appropriately, as many web sites observe consumer classes.
Contemplate implementing browser fingerprint randomization to keep away from monitoring.
Past CAPTCHAs, web sites usually use subtle anti-bot measures to detect and block scraping.
Some web sites use JavaScript to detect bots. Instruments like Puppeteer can simulate an actual browser setting, permitting your scraper to execute JavaScript and bypass these challenges.
Web sites generally add hidden type fields or hyperlinks that solely bots will work together with. So, strive avoiding clicking on hidden parts or filling out kinds with invisible fields.
Superior anti-bot methods go so far as monitoring consumer habits, resembling mouse actions or time spent on a web page. Mimicking these behaviors utilizing browser automation instruments can assist bypass these checks.
However the easiest and most effective method to deal with CAPTCHAs and anti-bot measures will certainly be to make use of a service like ScraperAPI.
Sending your scraping requests by ScraperAPI’s API will guarantee you could have the very best likelihood of not being blocked. When the API receives the request, it makes use of superior machine studying strategies to find out the very best request configuration to stop triggering CAPTCHAs and different anti-bot measures.
Conclusion
As web sites grew to become extra subtle of their anti-scraping measures, using proxies has change into more and more necessary in sustaining your scraping venture profitable.
Proxies show you how to preserve anonymity, stop IP blocking, and allow you to scale your scraping efforts with out getting obstructed by price limits or geo-restrictions.
On this information, we have explored the basics of net scraping and the essential function that proxies play on this course of. We have mentioned how proxies can assist preserve anonymity, keep away from IP blocks, and distribute requests to imitate pure consumer habits. We have additionally lined the various kinds of proxies obtainable, every with its personal strengths and excellent use instances.
We demonstrated how you can arrange a fundamental net scraper and combine proxies into your scraping script. We additionally explored the advantages of utilizing a devoted scraping service like ScraperAPI, which might simplify lots of the challenges related to net scraping at scale.
In the long run, we lined the significance of rigorously selecting the best sort of proxy, rotating them recurrently, dealing with price limits, and leveraging scraping providers when obligatory. That manner, you’ll be able to make sure that your net scraping initiatives might be environment friendly, dependable, and sustainable.
Do not forget that whereas net scraping could be a highly effective knowledge assortment method, it ought to at all times be accomplished responsibly and ethically, with respect for web site phrases of service and authorized concerns.