A current research of Enceladus, considered one of Saturn’s moons, has detected a number of natural compounds that had by no means been recorded there earlier than. The findings, revealed this month in Nature Astronomy, present new clues in regards to the inside chemical composition of this icy world, in addition to new hope that it might harbor life.
The researchers analyzed knowledge from the Cassini probe, which launched in 1997 and studied Saturn and its moons for years till its destruction in 2017. For Enceladus, Cassini gathered knowledge from ice fragments forcefully ejected from the moon’s subsurface ocean up into area.
Enceladus is considered one of 274 our bodies to date found in Saturn’s gravitational pull. It measures about 500 kilometers in diameter, making it the planet’s sixth-largest satellite tv for pc. Whereas this moon doesn’t stand out for its measurement, it’s notable for its cryovolcanoes—geysers at Enceladus’s south pole that spew out water vapor and ice fragments. Plumes of ejected materials can prolong to just about 10,000 kilometers in size, which is greater than the space from Mexico to Patagonia, and a few of this materials rises into area. The outermost of Saturn’s essential rings—its E ring—is primarily made up of ice ejected into area by Enceladus.
This materials is believed to come back from a saline water chamber beneath the moon’s icy crust that’s related to its rocky core. It’s attainable that chemical reactions are going down down there, below excessive stress and warmth.
Till now, most chemical analyses of ice from Enceladus have been of particles deposited in Saturn’s E ring. However throughout a high-speed flyby of the moon in 2008, Cassini was lucky sufficient to instantly pattern freshly ejected fragments from a cryovolcano. The brand new analysis paper reanalyzed this knowledge, confirming the presence of beforehand detected natural molecules, in addition to revealing compounds that had beforehand been undetected.
“Such compounds are believed to be intermediates within the synthesis of extra complicated molecules, which might be doubtlessly biologically related. You will need to observe, nonetheless, that these molecules will be fashioned abiotically as effectively,” Nozair Khawaja, a planetary scientist at Freie Universität Berlin and lead writer of the research, informed Reuters. The invention considerably expands the vary of confirmed natural molecules on Enceladus.
The hot button is that the compounds appeared in freshly ejected particles, suggesting that they have been fashioned throughout the moon’s hidden ocean or in touch with its inside interfaces, not throughout their journey via the E ring or through publicity to the situations of area. This reinforces the speculation that hydrothermal processes beneath Enceladus’s floor might be producing wealthy natural chemistry. Combining this new analysis with earlier research, scientists have now discovered 5 of the six parts important for all times—carbon, hydrogen, nitrogen, oxygen, phosphorus, and sulfur—within the satellite tv for pc’s ejected materials.
This itself shouldn’t be a discovery of life, nor of biosignatures—the indicators of life. Nonetheless, the analysis confirms that Enceladus has the three primary situations for all times to type: liquid water, an vitality supply, and important parts and organics. “Enceladus is, and needs to be ranked, because the prime goal to discover habitability and search whether or not there may be life or not,” Khawaja mentioned.
This story initially appeared onWIRED en Españoland has been translated from Spanish.
This text from Tyler Cowen has been catching lots of on-line flak.
Below just about any circumstances, complaining—even jokingly—that not one of the actresses you see on display screen are virgins is in questionable style. However if you have a look at the small print on this case, it will get a lot, a lot worse.
We’re speaking about an animated and depiction of a lady who seems to be someplace in her mid- to late teenagers. This isn’t made higher if you be taught that Tyler Cowen is 63 years previous.
At this level, we’re edging into the territory of fanboys insisting on-line that Sailor Moon must be “horny however not slutty.” This isn’t nook of the web.
Clearly, Cowen was going for mildly edgy snark. Whereas which may lower him some slack (or won’t—that’s a debate for one more day), the remark appears to be like significantly worse when taken within the context of what Cowen and others in his motion have been saying for years.
The fixation on virginity has been one thing of a recurring matter.
Discussions of virginity and purity are intently tied to the even creepier obsession with cuckolding. Probably the most infamous instance is the hat-tipped Robin Hanson’s argument that it may be extra ethical for a person to “gently” rape an unconscious lady than it could be for her to commit adultery.
Any dialogue of the libertarian motion’s angle towards ladies has obtained to deal with what Peter Thiel stated in a broadly disseminated Cato Institute essay
from 2009. (Ever since then, Thiel and his apologists have been dancing
round what he stated about ladies’s suffrage. It is best to disregard the
distractions and deal with his precise phrases.)
The Peter Thiel connection leads us to seasteading and different plans for libertarian utopias, which in flip deliver us to a different disturbing side of this story. Whereas I don’t wish to paint with too broad a brush right here, if you learn the proposals from individuals pushing these sovereign states of limitless freedom, one frequent chorus is that there needs to be no age of consent. There is no such thing as a context during which this isn’t troubling, however as half of a bigger sample, it’s significantly damning.
Although they’re two distinct teams, there’s a substantial amount of interconnection between the George Mason libertarians and the Silicon Valley alt-right. They share many frequent roots and have a symbiotic relationship and one thing of a mutual admiration society. Tyler Cowen, specifically, has executed greater than his share to construct up the reputations of individuals like Elon Musk.
This is some related context on tech bro tradition.
On the top of the dotcom mania within the Nineties, many critics warned
of a creeping reactionary fervor. “Neglect digital utopia,” wrote the
longtime know-how journalist Michael Malone, “we may very well be headed for
techno-fascism.” Elsewhere, the author Paulina Borsook known as the
valley’s worship of male energy “a little bit harking back to the early
celebrants of Eurofascism from the Nineteen Thirties”.
Their voices had been
largely drowned out by the techno-enthusiasts of the time, however Malone
and Borsook had been pointing to a imaginative and prescient of Silicon Valley constructed round a
reverence for limitless male energy – and a serious pushback when that
energy was challenged. On the root of this reactionary pondering was a
author and public mental named George Gilder. Gilder was one in every of
Silicon Valley’s most vocal evangelists, in addition to a well-liked “futurist”
who forecasted coming technological traits. In 1996, he began an
funding e-newsletter that grew to become so well-liked that it generated rushes on
shares from his readers, in a course of that grew to become often called the “Gilder
impact”.
Gilder was additionally a longtime social conservative who introduced his politics
to Silicon Valley. He had first made his identify within the Seventies as an
anti-feminist provocateur and a mentee of the conservative stalwart
William F Buckley. At a time when ladies had been getting into the workforce in
unprecedented numbers, he wrote books that argued that conventional
gender roles wanted to be restored, and he blamed social points reminiscent of
poverty on the breakdown of the nuclear household. (He additionally blamed federal
welfare applications, particularly people who funded single moms, claiming
they turned males into “cuckolds of the state”). In 1974, the Nationwide
Group for Girls named him “Male Chauvinist Pig of the 12 months”;
Gilder wore it as a badge of delight.
So far as I can inform, there’s nothing innate to libertarian philosophy that leads one to have an issue with ladies, and I definitely don’t wish to generalize about its followers. However there’s undoubtedly one thing occurring with the George Mason/Silicon Valley chapters of the motion, and it’s getting troublesome to disregard.
Can AI do utilized econometrics and causal inference? Can LLMs choose up on the nuances and social norms that dictate so lots of the choices made in utilized work and replicate them in response to a immediate? LLMs carry to the desk unimaginable capabilities and efficiencies and alternatives to create worth. However there are dangers when these instruments are used like Dunning-Kruger-as-a-Service (DKaaS), the place the crucial considering and precise studying begins and ends with immediate engineering and a response. We’ve got to be very cautious to acknowledge as Philip Tetlock describes in his e book “Superforecasters” that there’s a distinction between mimicking and reflecting which means vs. originating which means. To acknowledge that it’s not simply what you know that issues, however how you recognize what you recognize. The second-handed tendency to imagine that we are able to or ought to be outsourcing, nay, sacrificing our considering to AI in alternate for deceptive if not false guarantees about worth, is philosophically and epistemically disturbing.
“whereas LLMs are good at studying and extracting info from a corpus, they’re blind to one thing that people do very well – which is to measure the affect of 1’s choices.”
In a current discuss Cassie Kozrykov places it effectively: “AI doesn’t automate considering!”
Channelling Judea Pearl, understanding what makes a distinction (causality)requires greater than information, it additionally requires one thing not within the information to start with. A lot of the hype round AI is predicated on a instruments and know-how mindset. As Captain Jack Sparrow says about ships in Pirates of the Caribbean, a ship is greater than sails and rudders, these are issues a ship wants. What a ship actually is, is freedom. Causal inference is greater than strategies and theorems, these are issues causal inference wants, however what it truly is, is a mind-set. And in enterprise, what’s required is an alignment of considering. As an example, in his article The Significance of Being Causal, Ivor Bojinov describes the Causal Knowledge Evaluation Assessment Committee at LinkedIn. It’s a widespread finest follow in studying organizations that leverage experimentation and causal inference.
In case you attended very a lot of these evaluations you start to understand the quantity of cautious considering required to grasp the enterprise downside, body the speculation, and translate it to an analytical answer….then interpret the outcomes and make a advice about what motion to take subsequent. Equally a typical machine studying workflow requires up entrance considering and downside framing. However not like coaching an ML mannequin, as Scott Lundberg describes (see my LI Submit: Past SHAP Values and Crystal Balls), understanding what makes a distinction isn’t just a matter of letting an algo determine the perfect predictors and calling it a day, there may be a whole backyard of forking paths to navigate and every flip requires extra considering and an enormous distinction in opinions amongst ‘consultants’ about which course to go.
“even when all I’m after is a single estimate of a given regression coefficient, a number of testing and researcher levels of freedom may very well grow to be fairly a related concern…and this reveals the fragility in a number of empirical work that prudence would require us to view with a crucial eye”
Certain you may most likely pair a LLM with statistical software program and an information base connection and ask it to run a regression, however getting again to Jack Sparrow’s ship analogy, a regression is extra than simply becoming a line to information and testing for heteroskedasticity and multicollinearity (lets hope if LLMs practice on econometrics textbooks they do not weight the worth of data by the quantity of fabric devoted to multicollinearity!!!) and the laundry record of textbook assumptions. AI may most likely even describe in phrases a mechanical interpretation of the outcomes. All of that’s actually cool, and one thing like that would save a number of time and increase our workflows (which is efficacious) however we additionally need to watch out about that instruments mindset creeping again on us. All these issues that AI could possibly do are solely the issues regression wants, however to get the place we have to go, to grasp why, we’d like far more than what AI can at the moment present. We’d like considering. So even for a primary regression, relying on our targets, the considering required is at the moment and should all the time be past the capabilities of AI.
After we take into consideration these forking paths encountered in utilized work, every path can finish with a special measure of affect that comes with numerous caveats and tradeoffs to consider. There are seldom commonplace issues with commonplace options. The plan of action taken requires aware choices and the assembly of minds amongst completely different professional judgements (if not explicitly then implicitly) that considers all of the tradeoffs concerned in shifting from what could also be theoretically right and what’s virtually possible.
In his e book, “A Information to Econometrics” Peter Kennedy states that “Utilized econometricians are regularly confronted with awkward compromises” and gives an excellent story about what it is love to do utilized work:
“Econometric principle is like an exquisitely balanced French recipe, spelling out exactly with what number of turns to combine the sauce, what number of carats of spice so as to add, and for what number of milliseconds to bake the combination at precisely 474 levels of temperature. However when the statistical prepare dinner turns to uncooked supplies, he finds that hearts of cactus fruit are unavailable, so he substitutes chunks of cantaloupe; the place the recipe requires vermicelli he used shredded wheat; and he substitutes inexperienced garment die for curry, ping-pong balls for turtles eggs, and for Chalifougnac classic 1883, a can of turpentine.”
What selection would AI pushed causal inference make when it has to make the awkward compromise between Chalifougnac classic 1883 and turpentine and the way would it not clarify the selection it made and the considering that went into it? How would that selection stack up in opposition to the opinions of 4 different utilized econometricians who would have chosen in another way?
As Richard McElreath discusses in his nice e book Statistical Rethinking:
“Statisticians don’t usually precisely agree on tips on how to analyze something however the easiest of issues. The truth that statistical inference makes use of arithmetic doesn’t indicate that there’s just one affordable or helpful option to conduct an evaluation. Engineers use math as effectively, however there are lots of methods to construct a bridge.”
Because of this in utilized economics a lot of what we might contemplate as ‘finest practices’ are as a lot the results of social norms and practices as they’re textbook principle. These norms are sometimes established and evolve informally over time and typically tailored to the particulars of circumstances and place distinctive to a enterprise or choice making setting, or analysis self-discipline (this explains the language limitations for example between economists and epidemiologists and why completely different language can be utilized to explain the identical factor and the identical language can imply various things to completely different practitioners). A sort of results of human motion however not human design, many finest practices might seldom be formally codified or revealed in a method accessible to coach a chatbot to learn and perceive. Would an algorithm have the ability to perceive and relay again this nuance? I gave this a attempt by asking chatGPT about linear chance fashions (LPMs), and whereas I used to be impressed with a few of the element, I am not totally satisfied at this level primarily based on the solutions I obtained. Whereas it did an excellent job articulating the professionals and cons of LPMs vs logistic regression or different fashions, I believe it could go away the informal reader with the impression that they need to be cautious of counting on LPMs to estimate therapy results in most conditions. So that they miss out on the sensible advantages (the ‘execs’ that come from utilizing LPMs) whereas avoiding the ‘cons’ that as Angrist and Pischke may say, are principally innocent. I’d be involved about tougher econometric issues with extra nuance and extra enchantment to social norms and practices and considering that an LLM will not be aware of.
ChatGPT as a Analysis Assistant
Exterior of really doing utilized econometrics and causal inference, I’ve further issues with LLMs and AI in relation to utilizing them as a software for analysis and studying. At first it might sound actually nice if as an alternative of studying 5 journal articles you may simply have a software like chatGPT do the onerous give you the results you want and summarize them in a fraction of the time! And I agree this sort of abstract information is helpful, however most likely not in the best way many customers may assume.
I’ve been considering lots about how a lot you get out of placing your fingers on a paper or e book and going by means of it and wrestling with the concepts, the paths main from from hypotheses to the conclusions, and the way the cited references allow you to retrace the steps of the authors to grasp why, both slowly nudging your priors in new instructions or reinforcing your current perspective, and synthesizing these concepts with your individual. Then summarizing and making use of and speaking this synthesis with others.
ChatGPT may give the impression that’s what it’s doing in a fraction of the time you may do it (actually seconds vs. hours or days). Nonetheless, even when it gave the identical abstract you may write verbatim the distinction could not be as far aside as night time and day when it comes to the worth created. There’s a massive distinction between the educational that takes place while you undergo this strategy of integrative advanced considering vs. simply studying a abstract delivered on a silver platter from chatGPT. I’m skeptical what I’m describing might be outsourced to AI with out dropping one thing vital. I additionally assume there are actual dangers and prices concerned when these instruments are used like Dunning-Kruger-as-a-Service (DKaaS), the place the crucial considering and precise studying begins and ends with immediate engineering and a response.
In the case of the sensible utility of this data and considering and fixing new issues it’s not simply what you recognize that issues, however how you recognize what you recognize. If all you may have is a abstract, will you understand how to navigate the tradeoffs between what’s theoretically right and what’s virtually possible to make the perfect choice when it comes to what forking path to absorb an evaluation? Figuring out concerning the significance of social norms and practices in doing utilized work, and if the dialogue above about LPMs is any indication, I am unsure. And with simply the abstract, will you have the ability to shortly assimilate new developments within the subject….or will you need to return to chatGPT. How a lot information and vital nuance is misplaced with each replace? What’s missed? Considering!
As Cassie says in her discuss, considering is about:
“understanding what’s price saying…understanding what’s price doing, we’re considering once we are developing with concepts, once we are fixing issues, once we are being inventive”
AI shouldn’t be able to doing this stuff, and believing and even trying or pretending that we are able to get this stuff on a second-handed foundation from an AI software will in the end erode the true human abilities and capabilities important to actual productiveness and development over the long term. If we fail to just accept this we are going to hear a large sucking sound that’s the ROI we thought we had been going to get from AI within the brief run by trying to automate what cannot be automated. That’s the false promise of a instruments and know-how mindset.
It worries me that this identical instruments and know-how primarily based information science alchemy mindset has moved many managers who had been as soon as had been offered the snake oil that information scientists may merely spin information into gold with deep studying, will now purchase into the snake oil that LLMs will have the ability to spin information into gold and do it even cheaper and ship the thinkers packing!
Equally Cassie says: “that could be the most important downside, that administration has not discovered tips on how to handle considering…vs. what you’ll be able to measure simply….considering is one thing you’ll be able to’t power, you’ll be able to solely get in the best way of it.”
She elaborates a bit extra about this in her LinkedIn submit:“A misguided view of productiveness may imply misplaced jobs for staff with out whom organizations will not have the ability to thrive in the long term – what a painful mistake for everybody.”
Thunking vs. Considering
I did say that this sort of abstract data might be helpful. And I agree that the sorts of issues that AI and LLMs will probably be helpful for are what Cassie refers to in her discuss as ‘thunking.’ The issues that eat our time and sources however do not require considering. Having performed your homework, the sort of abstract info you get from an LLM will help reinforce your considering and learnings and save time when it comes to manually googling or wanting up a number of belongings you as soon as knew however have forgotten. If there may be an space you have not thought of shortly it may be an effective way to assist get again on top of things. And when attempting to study new issues, it may be leveraged to hurry up some features of your discovery course of or make it extra environment friendly, and even assist problem or vet your considering (nearly bouncing concepts backwards and forwards). However to be helpful, this nonetheless requires some background information and will by no means be an alternative choice to placing your fingers on a paper and doing the required cautious and significant considering.
One space of utilized econometrics I’ve not talked about is the customarily much less glamorous work it takes to implement an answer. Along with all of the considering concerned in translating the answer and navigating the forking paths, there may be a number of time spent accessing and reworking the information and implementing the estimation that entails coding (notice even within the midst of all that thunking work there may be nonetheless considering concerned – typically we study essentially the most about our enterprise and our downside whereas trying to wrangle the information – so that is additionally a spot the place we have to be cautious about what we automate). A number of information science people are additionally utilizing these instruments to hurry up a few of their programming duties. I am a ordinary consumer of stack-exchange and git hub and always recycle my very own code or others’ code. However I burn a number of time somedays in the hunt for what I want. That is the sort of thunking that it makes since to enlist new AI instruments for!
Conclusion: Considering is Our Accountability
I’ve noticed two extremes in relation to opinions about instruments like ChatGPT. One is that LLMs have the information and knowledge of Yoda and can remedy all of our issues. The opposite excessive is that as a result of LLMs haven’t got the information and knowledge of Yoda they’re largely irrelevant. Clearly there may be center floor and I’m looking for it on this submit. And I believe Cassie has discovered it:
“AI doesn’t automate considering. It would not! There’s a number of unusual rumblings about this that sound very odd to me who has been on this area for two many years“
I’ve sensed those self same rumblings and it ought to make us all really feel a bit uneasy. She goes on to say:
“when you find yourself not the one making the choice and it appears just like the machine is doing it, there may be somebody who is definitely making that call for you…and I believe that we’ve been complacent and we’ve allowed our know-how to be faceless….how will we maintain them accountable….for knowledge…considering is our accountability”
Considering is an ethical accountability. Outsourcing our considering and fooling ourselves into considering we are able to get information and knowledge and judgment second-handed from a abstract written by an AI software, and to imagine that’s the identical factor and gives the identical worth as what we may produce as considering people is a harmful phantasm when in the end, considering is the means by which the human race and civil society in the end thrives and survives. In 2020 former President Barak Obama emphasised the significance of considering in a democracy:
“if we would not have the capability to differentiate what’s true from what’s false, then by definition {the marketplace} of concepts would not work. And by definition our democracy would not work. We’re getting into into an epistemological disaster.”
The flawed sort of instruments and know-how mindset, and obsequiousness towards the know-how, and a second-handed tendency to imagine that we are able to or ought to be outsourcing, nay, sacrificing our considering to AI in alternate for deceptive if not false guarantees about worth, is philosophically and epistemically disturbing.
LLMs carry to the desk unimaginable capabilities and efficiencies and alternatives to create worth. However we’ve to be very cautious to acknowledge as Philip Tetlock describes in his e book Superforecasters, that there’s a distinction between mimicking and reflecting which means vs. originating which means. To acknowledge that it’s not simply what you recognize that issues, however how you recognize what you recognize. To repurpose the closing statements from the e book Principally Innocent Econometrics: If utilized econometrics had been simple, LLMs may do it.
Word on updates: An authentic model of this submit was written on July 29 along side the submit On LLMs and LPMs: Does the LL in LLM Stand for Linear Literalism? Shortly after posting I ran throughout Cassie’s discuss and up to date to include lots of the factors she made, with the perfect of intentions. Any misrepresentation/misappropriation of her views is unintentional.
Sometimes talking, creating software program is an extended collection of phases that begins with necessities gathering to growth to testing, to ultimate launch. Every stage requires the respective members to contribute to the ultimate growth of the product in their very own capability. The enterprise analyst’s job is to gather necessities from the shopper and validate their feasibility with a technical architect. The technical architect research the entire surroundings and performs the influence evaluation of putting a brand new resolution in it. Based mostly on feasibility, they could advocate modifications within the necessities.
After lengthy discussions and backward and forward of necessities, the event of the product begins. Then the event staff faces its personal challenges. They encounter unexpected occasions whereas constructing the software program that will require both updating the design or a change within the necessities themselves. Then the subsequent stage of testing arrives when the product is examined towards completely different standards. Even this stage might push again the software program to any of the earlier phases primarily based on the character of the defects discovered.
So, what we perceive from all that is that software program growth isn’t a linear course of. It goes backwards and forwards between many phases which are required to present it a ultimate form. And therefore, the query arises, when ought to the testing ideally start? That is what we’ll discover intimately within the additional sections.
Why the Timing of Testing Issues?
Testing is definitely wanted to develop a product that’s dependable and secure. There’s little doubt about it. However what issues most is the timing when the defect is discovered. This timing has a direct influence on each the seller and the purchasers. If the defect is present in manufacturing, it instantly breaks buyer belief. Your model popularity falters immediately within the buyer’s eyes.
However, research have proven that the later a defect is found, the dearer it’s to repair it. It’s as a result of a software program resolution is constructed on a big set of algorithms and logic. Every has an influence on others by way of knowledge change, dependent logic, and the sequence of its circulation. A defect discovered at one spot can go away all different dependent applications and subroutines to fail as nicely. It might disrupt the entire circulation of the code. A incorrect logic in producing a worth that’s used at a number of locations can have cascading results. Therefore, it turns into exponentially expensive and laborious to repair the defect later than sooner.
So, the conclusion is, the earlier you uncover a bug, the higher it’s in all phrases. And that leads us to the query: what’s the perfect timing when the testing ought to start? In fact, it is not sensible to start out testing till there’s not sufficient substance generated. However, it’s equally dangerous to postpone it to be found later, when it is going to create the next influence on the general resolution.
The Function of Testing in Every Stage of Improvement
To grasp the position of testing in every stage, let’s categorize the phases into three phases of growth: necessities gathering and design, code growth, and integration and deployment.
Requirement Gathering and Design
On this stage, the testing is relevant to not catch the bugs as a result of there’s no code developed but. It’s largely about testing the assumptions. Necessities raised by the shopper have to be validated towards technical feasibility and alignment with enterprise targets. This type of testing is on the purposeful degree, the place the necessities are examined for his or her influence on different associated processes, each on the enterprise and technical ranges.
For instance, a change within the workflow of the method that follows after a buyer locations an order might influence the downstream occasions, like updating the database, buyer notification course of, and product supply. A enterprise analyst validates the workflow on the purposeful degree whereas a technical architect checks for the feasibility of creating such an answer. The sooner the assumptions are uncovered, the much less influence it has on the method that follows.
Code Improvement and Unit Testing
That is the stage when testing turns into extra tangible. On this stage, a unit of performance is developed, like a stand-alone program, and it may be examined towards its anticipated outputs. The dependent applications’ knowledge and purposeful change needn’t be developed but, because the transaction with them might be simulated by way of hard-coded values. Unit testing intends to verify how a single unit of performance works independently, and if it generates the anticipated consequence in each perfect and unfavorable eventualities. For efficient unit testing, utilizing an automation framework is wiser. testRigor, as a software program testing software, is one such product that may carry out this process by way of simulated eventualities.
The perfect testing follow on this stage is to create take a look at circumstances even earlier than this system has been coded. Its duty falls on the developer himself, who is anticipated to not simply write the code but in addition validate its outcomes truthfully.
Integration and Deployment
After unit testing, which validates the performance of every element, the combination course of comes into play. On this stage, all of the completely different parts that have been developed and examined individually are introduced collectively, and their efficiency is examined in relation to one another. Whereas unit testing was about testing a element individually, integration testing assessments their relationship. It validates whether or not the entire is larger than the sum of its elements or not.
As soon as the combination works flawlessly, its usability is checked towards buyer expectations. This half contains testing the software program from a human perspective. All of the technical elements are helpful solely so long as they will lastly meet customers’ expectations. This testing might be executed on a Person Acceptance surroundings, which is nearly a duplicate of manufacturing.
Closing Assertion: When Ought to Testing Start?
Having understood the varied phases of testing, it’s justifiable to ask when the perfect time to start out testing is. The straightforward reply to that’s as quickly as attainable. Earlier than you begin testing your product, you need to domesticate a mindset of high quality inside your staff in any respect ranges. Testing isn’t just about discovering defects, however primarily about creating a vital outlook in the direction of each stage of growth. How fool-proof this requirement is, how sturdy the code is, will it stand towards hostile eventualities? These are the questions that don’t require a set stage to start with. These standards ought to be validated proper from the beginning until the deployment section.
So, the ultimate reply is, testing begins proper in the intervening time we begin imagining a product. Each requirement have to be met with a “What if?” query. Each assumption ought to be unearthed, and each performance ought to be examined towards tangible outcomes. When you domesticate a vital mindset in your staff, all of your testing endeavours will likely be its manifestation that can have a deeper influence on the standard of the product.
This put up was written with Dominic Catalano from Anyscale.
Organizations constructing and deploying large-scale AI fashions typically face important infrastructure challenges that may instantly affect their backside line: unstable coaching clusters that fail mid-job, inefficient useful resource utilization driving up prices, and sophisticated distributed computing frameworks requiring specialised experience. These components can result in unused GPU hours, delayed initiatives, and pissed off information science groups. This put up demonstrates how one can handle these challenges by offering a resilient, environment friendly infrastructure for distributed AI workloads.
Amazon SageMaker HyperPod is a purpose-built persistent generative AI infrastructure optimized for machine studying (ML) workloads. It offers strong infrastructure for large-scale ML workloads with high-performance {hardware}, so organizations can construct heterogeneous clusters utilizing tens to 1000’s of GPU accelerators. With nodes optimally co-located on a single backbone, SageMaker HyperPod reduces networking overhead for distributed coaching. It maintains operational stability by steady monitoring of node well being, routinely swapping defective nodes with wholesome ones and resuming coaching from essentially the most not too long ago saved checkpoint, all of which will help save as much as 40% of coaching time. For superior ML customers, SageMaker HyperPod permits SSH entry to the nodes within the cluster, enabling deep infrastructure management, and permits entry to SageMaker tooling, together with Amazon SageMaker Studio, MLflow, and SageMaker distributed coaching libraries, together with help for varied open-source coaching libraries and frameworks. SageMaker Versatile Coaching Plans complement this by enabling GPU capability reservation as much as 8 weeks prematurely for durations as much as 6 months.
The Anyscale platform integrates seamlessly with SageMaker HyperPod when utilizing Amazon Elastic Kubernetes Service (Amazon EKS) because the cluster orchestrator. Ray is the main AI compute engine, providing Python-based distributed computing capabilities to deal with AI workloads starting from multimodal AI, information processing, mannequin coaching, and mannequin serving. Anyscale unlocks the ability of Ray with complete tooling for developer agility, important fault tolerance, and an optimized model referred to as RayTurbo, designed to ship main cost-efficiency. By means of a unified management airplane, organizations profit from simplified administration of complicated distributed AI use circumstances with fine-grained management throughout {hardware}.
This put up demonstrates the way to combine the Anyscale platform with SageMaker HyperPod. This mixture can ship tangible enterprise outcomes: lowered time-to-market for AI initiatives, decrease complete price of possession by optimized useful resource utilization, and elevated information science productiveness by minimizing infrastructure administration overhead. It’s supreme for Amazon EKS and Kubernetes-focused organizations, groups with large-scale distributed coaching wants, and people invested within the Ray ecosystem or SageMaker.
Resolution overview
The next structure diagram illustrates SageMaker HyperPod with Amazon EKS orchestration and Anyscale.
The sequence of occasions on this structure is as follows:
A consumer submits a job to the Anyscale Management Airplane, which is the primary user-facing endpoint.
The Anyscale Management Airplane communicates this job to the Anyscale Operator throughout the SageMaker HyperPod cluster within the SageMaker HyperPod digital non-public cloud (VPC).
The Anyscale Operator, upon receiving the job, initiates the method of making the mandatory pods by reaching out to the EKS management airplane.
The EKS management airplane orchestrates creation of a Ray head pod and employee pods. These pods symbolize a Ray cluster, operating on SageMaker HyperPod with Amazon EKS.
The Anyscale Operator submits the job by the pinnacle pod, which serves as the first coordinator for the distributed workload.
The pinnacle pod distributes the workload throughout a number of employee pods, as proven within the hierarchical construction within the SageMaker HyperPod EKS cluster.
All through the job execution, metrics and logs are printed to Amazon CloudWatch and Amazon Managed Service for Prometheus or Amazon Managed Grafana for observability.
When the Ray job is full, the job artifacts (closing mannequin weights, inference outcomes, and so forth) are saved to the designated storage service.
Job outcomes (standing, metrics, logs) are despatched by the Anyscale Operator again to the Anyscale Management Airplane.
This circulation reveals distribution and execution of user-submitted jobs throughout the out there computing assets, whereas sustaining monitoring and information accessibility all through the method.
Conditions
Earlier than you start, you should have the next assets:
Arrange Anyscale Operator
Full the next steps to arrange the Anyscale Operator:
In your workspace, obtain the aws-do-ray repository:
git clone https://github.com/aws-samples/aws-do-ray.git
cd aws-do-ray/Container-Root/ray/anyscale
This repository has the instructions wanted to deploy the Anyscale Operator on a SageMaker HyperPod cluster. The aws-do-ray undertaking goals to simplify the deployment and scaling of distributed Python software utilizing Ray on Amazon EKS or SageMaker HyperPod. The aws-do-ray container shell is supplied with intuitive motion scripts and comes preconfigured with handy shortcuts, which save in depth typing and enhance productiveness. You may optionally use these options by constructing and opening a bash shell within the container with the directions within the aws-do-ray README, or you’ll be able to proceed with the next steps.
In case you proceed with these steps, ensure your setting is correctly arrange:
Confirm your connection to the HyperPod cluster:
Acquire the title of the EKS cluster on the SageMaker HyperPod console. In your cluster particulars, you will note your EKS cluster orchestrator.
Replace kubeconfig to hook up with the EKS cluster:
If the output signifies InProgress as a substitute of Handed, look ahead to the deep well being checks to complete.
Evaluate the env_vars file. Replace the variable AWS_EKS_HYPERPOD_CLUSTER. You may depart the values as default or make desired adjustments.
Deploy your necessities:
Execute:
./1.deploy-requirements.sh
This creates the anyscale namespace, installs Anyscale dependencies, configures login to your Anyscale account (this step will immediate you for extra verification as proven within the following screenshot), provides the anyscale helm chart, installs the ingress-nginx controller, and eventually labels and taints SageMaker HyperPod nodes for the Anyscale employee pods.
Create an EFS file system:
Execute:
./2.create-efs.sh
Amazon EFS serves because the shared cluster storage for the Anyscale pods. On the time of writing, Amazon EFS and S3FS are the supported file system choices when utilizing Anyscale and SageMaker HyperPod setups with Ray on AWS. Though FSx for Lustre will not be supported with this setup, you should use it with KubeRay on SageMaker HyperPod EKS.
Register an Anyscale Cloud:
Execute:
./3.register-cloud.sh
This registers a self-hosted Anyscale Cloud into your SageMaker HyperPod cluster. By default, it makes use of the worth of ANYSCALE_CLOUD_NAME within the env_vars file. You may modify this discipline as wanted. At this level, it is possible for you to to see your registered cloud on the Anyscale console.
Deploy the Kubernetes Anyscale Operator:
Execute:
./4.deploy-anyscale.sh
This command installs the Anyscale Operator within the anyscale namespace. The Operator will begin posting well being checks to the Anyscale Management Airplane.
To see the Anyscale Operator pod, run the next command:kubectl get pods -n anyscale
Submit coaching job
This part walks by a easy coaching job submission. The instance implements distributed coaching of a neural community for Trend MNIST classification utilizing the Ray Prepare framework on SageMaker HyperPod with Amazon EKS orchestration, demonstrating the way to use the AWS managed ML infrastructure mixed with Ray’s distributed computing capabilities for scalable mannequin coaching.Full the next steps:
Navigate to the jobs listing. This comprises folders for out there instance jobs you’ll be able to run. For this walkthrough, go to the dt-pytorch listing containing the coaching job.
Submit the coaching job: ./2.submit-dt-pytorch.shThis makes use of the job configuration laid out in job_config.yaml. For extra data on the job config, confer with JobConfig.
Monitor the deployment. You will notice the newly created head and employee pods within the anyscale namespace. kubectl get pods -n anyscale
View the job standing and logs on the Anyscale console to watch your submitted job’s progress and output.
Clear up
To wash up your Anyscale cloud, run the next command:
cd ../..
./5.remove-anyscale.sh
To delete your SageMaker HyperPod cluster and related assets, delete the CloudFormation stack if that is the way you created the cluster and its assets.
Conclusion
This put up demonstrated the way to arrange and deploy the Anyscale Operator on SageMaker HyperPod utilizing Amazon EKS for orchestration.SageMaker HyperPod and Anyscale RayTurbo present a extremely environment friendly, resilient answer for large-scale distributed AI workloads: SageMaker HyperPod delivers strong, automated infrastructure administration and fault restoration for GPU clusters, and RayTurbo accelerates distributed computing and optimizes useful resource utilization with no code adjustments required. By combining the high-throughput, fault-tolerant setting of SageMaker HyperPod with RayTurbo’s sooner information processing and smarter scheduling, organizations can practice and serve fashions at scale with improved reliability and important price financial savings, making this stack supreme for demanding duties like massive language mannequin pre-training and batch inference.
Sindhura Palakodetyis a Senior Options Architect at AWS and Single-Threaded Chief (STL) for ISV Generative AI, the place she is devoted to empowering prospects in growing enterprise-scale, Properly-Architected options. She focuses on generative AI and information analytics domains, serving to organizations use modern applied sciences for transformative enterprise outcomes.
Mark Vinciguerrais an Affiliate Specialist Options Architect at AWS based mostly in New York. He focuses on generative AI coaching and inference, with the aim of serving to prospects architect, optimize, and scale their workloads throughout varied AWS companies. Previous to AWS, he went to Boston College and graduated with a level in Pc Engineering.
Florian Gauteris a Worldwide Specialist Options Architect at AWS, based mostly in Hamburg, Germany. He focuses on AI/ML and generative AI options, serving to prospects optimize and scale their AI/ML workloads on AWS. With a background as a Information Scientist, Florian brings deep technical experience to assist organizations design and implement refined ML options. He works intently with prospects worldwide to remodel their AI initiatives and maximize the worth of their ML investments on AWS.
Alex Iankoulskiis a Principal Options Architect within the Worldwide Specialist Group at AWS. He focuses on orchestration of AI/ML workloads utilizing containers. Alex is the writer of the do-framework and a Docker captain who loves making use of container applied sciences to speed up the tempo of innovation whereas fixing the world’s greatest challenges. Over the previous 10 years, Alex has labored on serving to prospects do extra on AWS, democratizing AI and ML, combating local weather change, and making journey safer, healthcare higher, and vitality smarter.
Anoop Sahais a Senior GTM Specialist at AWS specializing in generative AI mannequin coaching and inference. He’s partnering with prime basis mannequin builders, strategic prospects, and AWS service groups to allow distributed coaching and inference at scale on AWS and lead joint GTM motions. Earlier than AWS, Anoop has held a number of management roles at startups and huge firms, primarily specializing in silicon and system structure of AI infrastructure.
Dominic Catalanois a Group Product Supervisor at Anyscale, the place he leads product growth throughout AI/ML infrastructure, developer productiveness, and enterprise safety. His work focuses on distributed programs, Kubernetes, and serving to groups run AI workloads at scale.
Generate the request utilizing the Certificates snap-in in Microsoft Administration Console (MMC).
Step 1: Open the Certificates Snap-In
Press Home windows + R, sort mmc, and press Enter.
Go to File > Add/Take away Snap-in.
Choose Certificates and click on Add.
Select Pc account, then click on Subsequent.
Choose Native laptop and click on End.
Click on OK to shut the Add/Take away window.
Step 2: Begin the CSR Wizard
Within the left pane, increase Certificates (Native Pc).
Proper-click Private and choose:
All Duties → Superior Operations → Create Customized Request
Step 3: Configure the Request
On the Certificates Enrollment web page, click on Subsequent.
Choose Proceed with out enrollment coverage and click on Subsequent.
On the “Certificates Info” web page, increase Particulars and click on Properties.
On the Basic tab:
Enter a pleasant identify, e.g., WS25-IIS Certificates.
On the Topic tab:
Below Topic identify, select Frequent Title.
Enter the totally certified area identify (FQDN), e.g. ws25-iis.windowserver.information.
Click on Add.
Below Different identify, select DNS.
Enter the identical FQDN and click on Add.
On the Extensions tab:
Below Key Utilization, guarantee Digital Signature and Key Encipherment are chosen.
Below Prolonged Key Utilization, add Server Authentication.
On the Personal Key tab:
Below Cryptographic Supplier, choose RSA, Microsoft Software program Key Storage Supplier.
Set Key measurement to 2048 bits.
Examine Make non-public key exportable and Enable non-public key to be archived.
Click on Apply, then OK, after which Subsequent.
Step 4: Save the Request
Select a location to avoid wasting the request file (e.g. C:Temp).
Make sure the format is ready to Base 64.
Present a filename corresponding to SSLRequest.req.
Click on End.
You possibly can open the file in Notepad to confirm the Base64-encoded request textual content.
Submit the CSR to a Certification Authority
You need to use an inside Home windows CA or a public CA. The instance beneath assumes an online enrollment interface.
Step 1: Open the CA Net Enrollment Web page
Navigate to your CA’s enrollment website. If the server doesn’t belief the CA, you could obtain a warning. You may must or set up the CA certificates as wanted.
Step 2: Submit an Superior Certificates Request
Choose Request a certificates.
Select superior certificates request.
Open the CSR in Notepad, copy the Base64 textual content, and paste it into the request kind.
Click on Submit.
Step 3: Approve the Request (if required)
In case your CA requires approval, check in to the CA server and approve the pending request.
Step 4: Obtain the Issued Certificates
Return to the CA net enrollment web page.
View the standing of pending requests.
Find your request and choose it.
Select the Base 64 encoded certificates format.
Obtain the certificates.
Put it aside to a recognized location and rename it meaningfully (e.g. WS25-IIS-Cert.cer).
Set up the SSL Certificates
Double-click the .cer file to open it.
Click on Set up Certificates.
Select Native Machine as the shop location.
When prompted for the shop, choose:
Place all certificates within the following retailer
Select Private
Click on Subsequent, then End.
Verify the success message by clicking OK.
The certificates is now imported and obtainable to be used by IIS.
Bind the Certificates in IIS
Step 1: Open IIS Supervisor
Open Server Supervisor or seek for IIS Supervisor.
Within the left pane, increase the server and choose your web site (e.g., Default Net Website).
Step 2: Add an HTTPS Binding
Within the Actions pane, click on Bindings.
Within the Website Bindings window, click on Add.
Choose:
Sort: https
Hostname: the FQDN used within the certificates (e.g., ws25-iis.windowserver.information)
SSL Certificates: select the certificates you put in (e.g. WS25-IIS Certificates)
Click on OK, then Shut.
Take a look at the HTTPS Connection
Open Microsoft Edge (or your most well-liked browser).
Browse to the location utilizing https:// and the FQDN.
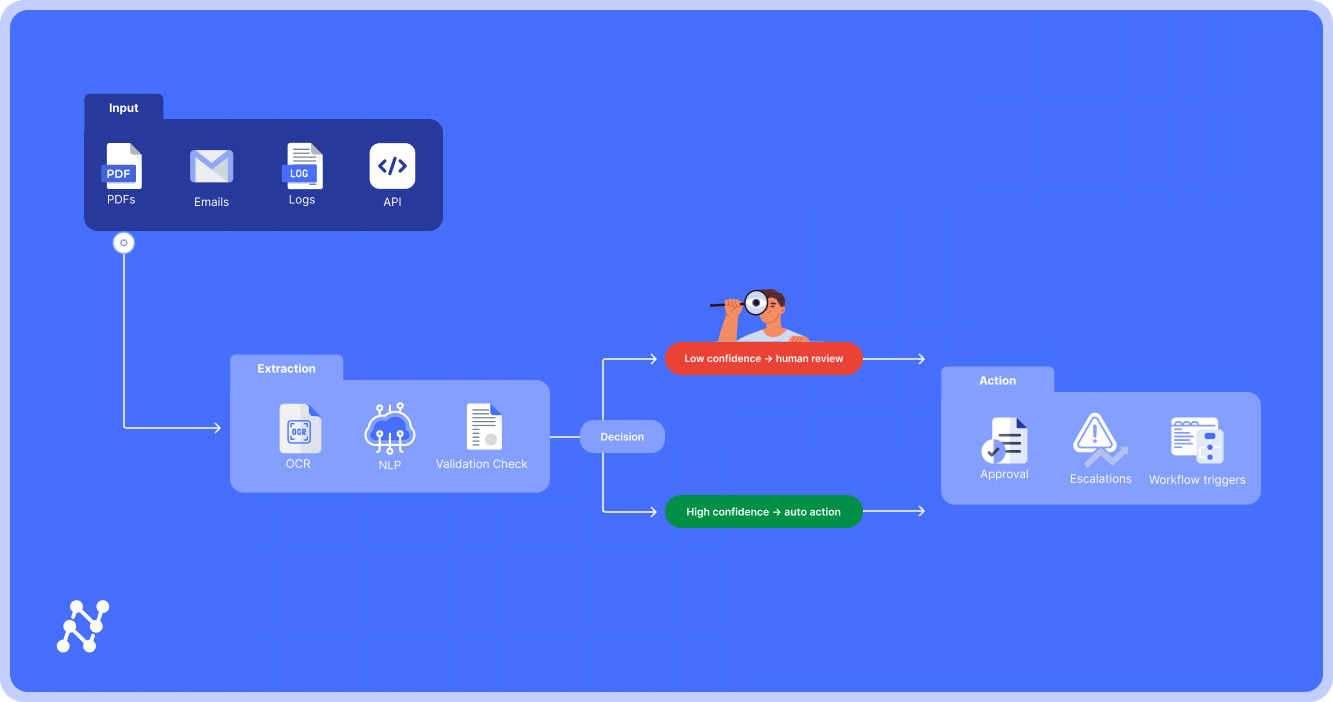
80–90% of enterprise information lives in unstructured paperwork — contracts, claims, medical information, and emails. But most organizations nonetheless depend on brittle templates or guide keying to make sense of it. Information sits on a spectrum — from clear, tabular codecs to messy, free-form content material. Paperwork symbolize probably the most advanced and high-value finish of this continuum.
Now image this: a 60-page provider contract lands in procurement’s inbox. Historically, analysts would possibly spend two days combing by means of indemnity clauses, renewal phrases, and non-standard provisions earlier than routing obligations right into a contract lifecycle administration (CLM) system. With an Clever Doc Processing (IDP) pipeline in place, the contract is parsed, key clauses are extracted, deviations are flagged, and obligations are pushed into the CLM system in beneath an hour. What was as soon as guide, error-prone, and sluggish turns into close to real-time, structured, and auditable.
IDP applies AI/ML—NLP, pc imaginative and prescient, and supervised/unsupervised studying—to enterprise paperwork. Not like Automated Doc Processing (ADP), which depends on guidelines and templates, IDP adapts to unseen layouts, interprets semantic context, and improves repeatedly by means of suggestions loops. To grasp IDP’s function, consider it because the AI mind of doc automation, working in live performance with different instruments: OCR offers the eyes, RPA the palms, and ADP the deterministic guidelines spine.
This text takes you beneath the hood of how this mind works, the applied sciences it builds on, and why enterprises can now not ignore it.
IDP isn’t a one-size-fits-all silver bullet. The precise strategy relies on your doc DNA. Whereas ADP could also be enough for high-volume, structured codecs, IDP is the smarter long-term play for variable or unstructured paperwork. Earlier than investing, consider your doc panorama on three axes—sort, variability, and velocity. This evaluation will information whether or not deterministic guidelines, adaptive intelligence, or a hybrid mannequin is one of the best match.
What Is Clever Doc Processing?
At its core, Clever Doc Processing (IDP) is the AI-driven transformation of paperwork into structured, validated, system-ready information. The lifecycle is constant throughout industries:
Not like earlier generations of automation, IDP doesn’t cease at information seize. It layers in machine studying fashions, NLP, and human-in-the-loop suggestions so every cycle improves accuracy.
One option to perceive IDP is to position it within the automation stack alongside associated instruments:
OCR = the eyes. Optical Character Recognition converts pixels into machine-readable textual content.
RPA = the palms. Robotic Course of Automation mimics keystrokes and clicks.
ADP = the foundations engine. Automated Doc Processing depends on templates and deterministic guidelines.
IDP = the mind. Machine studying fashions interpret construction, semantics, and context.
This framing issues as a result of many enterprises conflate these instruments. In follow, they’re complementary, with IDP sitting on the intelligence layer that makes automation scalable past inflexible templates.
Why Clever Doc Processing Issues for IT, Answer Architects, and Information Scientists
For IT leaders: IDP reduces the break/repair cycles that plague template-driven techniques. No extra firefighting each time a vendor tweaks an bill format.
For resolution architects: IDP offers a versatile, API-first layer that scales throughout heterogeneous doc varieties — with out ballooning upkeep prices.
For information scientists: IDP formalizes a studying loop. Confidence scores, energetic studying, and reviewer suggestions are baked into manufacturing pipelines, turning noisy human corrections into structured coaching alerts.
Key Phrases to Know
Confidence scores: Every extracted subject carries a chance used for routing (auto-post vs assessment). Actual thresholds will probably be coated in a later part.
Lively studying: A technique the place human corrections are recycled into mannequin coaching, lowering guide effort over time.
Format-aware transformers (e.g., LayoutLM): Deep studying fashions that mix textual content, place, and visible cues to parse advanced layouts like invoices or types. (LayoutLM paper →)
OCR-free fashions (e.g., Donut): Newer approaches that bypass OCR altogether, instantly parsing digital PDFs or photographs into structured outputs. (Donut paper →)
Briefly: IDP isn’t “smarter OCR” or “higher RPA.” It’s the AI/ML mind that interprets paperwork, enforces context, and scales automation into domains the place templates collapse.
Subsequent, we’ll look beneath the hood on the core applied sciences — from machine studying fashions to NLP, pc imaginative and prescient, and human-in-the-loop studying techniques — that make IDP doable at enterprise scale.
Core Applied sciences Beneath the Hood
IDP isn’t a single mannequin or API name. It is a layered structure combining machine studying, NLP, pc imaginative and prescient, human suggestions, and, more and more, giant language fashions (LLMs). Each bit performs a definite function, and their orchestration is what permits IDP to scale throughout messy, high-volume enterprise doc units. As an example how these applied sciences work collectively, let’s hint a single doc—a fancy customs declaration kind with each typed and handwritten information, a nested desk of products, and a signature.
Machine Studying Fashions: The Basis
Machine studying (ML) is the spine of IDP. Not like deterministic ADP techniques, IDP depends on fashions that study from information, adapt to new codecs, and enhance repeatedly.
Supervised Studying: The commonest strategy. Fashions are educated on labeled samples—for our customs kind, this could be a dataset with bounding packing containers round “Port of Entry,” “Worth,” and “Consignee.” This allows a supervised mannequin to acknowledge these fields with excessive accuracy on future, comparable types.
Unsupervised/Self-Supervised Studying: Helpful when labeled information is scarce. Fashions can cluster unlabeled paperwork by structure or content material similarity, grouping all customs types collectively earlier than a human even has to label them.
Format-Conscious Transformers: Fashions like LayoutLM are designed particularly for paperwork. They mix the extracted textual content with its spatial coordinates and visible cues. On our customs kind, this mannequin understands not simply the phrases “Whole Worth,” but in addition that they’re situated subsequent to a particular field and above a line of numbers, guaranteeing appropriate information extraction even when the shape structure varies barely.
Mannequin Alternative by Doc Sort
Doc Sort
Really helpful Tech
Rationale
Fastened-format invoices
Supervised ML + light-weight OCR
Excessive throughput, low price
Receipts / cellular captures
Format-aware transformers
Strong to variable fonts, noise
Contracts
NLP-heavy + structure transformers
Captures clauses throughout pages
Pure Language Processing (NLP): Understanding the Textual content
Whereas ML handles construction, NLP provides IDP semantic understanding. This issues most when the content material isn’t simply numbers and packing containers, however text-heavy narratives.
Named Entity Recognition (NER): After the ML mannequin identifies the products desk on the customs kind, NER extracts particular entities like “Amount” and “Description” from every line merchandise.
Semantic Similarity: If the shape has a “Particular Directions” part with free-form textual content, NLP fashions can learn it to detect clauses associated to dealing with or transport dangers, guaranteeing a human flag is raised if the language is advanced.
Multilingual Capabilities: For worldwide types, fashionable transformer fashions can course of languages from Spanish to Arabic, guaranteeing a single IDP system can deal with world paperwork with out guide language switching.
Laptop Imaginative and prescient (CV): Seeing the Particulars
Paperwork aren’t at all times pristine PDFs. Scanned faxes, cellular uploads, and stamped types introduce noise. CV layers in preprocessing and construction detection to stabilize downstream fashions.
Pre-processing: If our customs kind is a blurry fax, CV strategies like de-skewing and binarization clear up the picture, making the textual content clearer for extraction.
Construction Detection: CV fashions can exactly section the shape, figuring out separate zones for the typed desk, the handwritten signature, and any stamps, permitting specialised fashions to course of every space appropriately. This ensures the handwritten signature is not misinterpreted as a part of the typed information.
Even one of the best fashions aren’t 100% correct. HITL closes the hole by routing unsure fields to human reviewers—after which utilizing these corrections to enhance the mannequin. On our customs kind, a really low confidence rating on the handwritten signature may set off an automated escalation to a reviewer for verification. That correction then feeds again into the energetic studying system, serving to the mannequin get higher at studying comparable handwriting over time.
LLM Augmentation (Rising Layer): The Last Semantic Layer
LLMs are the latest frontier, including a layer of semantic depth. As soon as the customs kind is processed, an LLM can present a fast abstract of the products, spotlight any uncommon objects, and even draft an e mail to the logistics workforce based mostly on the extracted information. This isn’t a substitute for IDP, however an augmentation that gives deeper, extra human-like interpretation.
How an IDP Workflow Really Runs
In follow, IDP isn’t a single “black field” AI—it’s a fastidiously orchestrated pipeline the place machine studying, enterprise guidelines, and human oversight interlock to ship dependable outcomes.
Enterprises care much less about mannequin structure and extra about whether or not paperwork stream end-to-end with out fixed firefighting. That requires not solely extraction accuracy but in addition governance, validations, and workflows that stand as much as real-world quantity, range, and compliance.
Beneath, we break down an IDP workflow step-by-step—with technical particulars for IT and information science, and operational advantages for finance, claims, and provide chain leaders.
Step 1. Ingestion Mesh — Getting Paperwork In Cleanly
Channels supported: e mail attachments, SFTP batch drops, API/webhooks, buyer/provider portals, cellular seize apps.
Governance hooks: idempotency keys (keep away from duplicates), retries with exponential backoff, DLQs (dead-letter queues) for failed paperwork.
Personas impacted:
IT → safety, authentication (SSO, MFA).
Ops → throughput, SLA monitoring.
Architects → resilience beneath peak load.
💡
Why it issues: With out sturdy consumption, you find yourself with fragmented workflows—one set of invoices in e mail, one other on a portal, nonetheless one other coming by way of API. An ingestion mesh ensures each doc—whether or not 1 or 100,000—flows into the identical ruled pipeline.
Step 2. Classification — Realizing What You’re Wanting At
Confidence thresholds: high-confidence classifications route straight to extraction; low-confidence circumstances set off HITL assessment.
Restoration actions:
Mis-routed doc → auto-reclassification engine.
Unknown doc sort → tagged by reviewers, feeding energetic studying.
💡
Instance: A customs declaration mis-sent as a “invoice of lading” is mechanically corrected by the classifier after just a few coaching examples. Over time, the system’s taxonomy expands organically.
Step 3. Information Extraction — Pulling Fields and Buildings
Scope: key-value pairs (bill quantity, declare ID), tabular information (line objects, shipments), signatures, and stamps.
Enterprise guidelines: normalization of dates, tax percentages, forex codecs; per-line merchandise checks for totals.
HITL UI: per-field confidence scores, color-coded, with keyboard-first navigation to reduce correction time.
💡
Why it issues: Extraction is the place most legacy OCR-based techniques break down. IDP’s edge lies in parsing variable layouts (multi-vendor invoices, multilingual contracts) whereas surfacing solely unsure fields for assessment.
IT → integration stability by way of API-first design.
Step 5. Routing & Orchestration — Getting Clear Information to the Proper Place
Workflows supported:
Finance → auto-post bill to ERP.
Insurance coverage → open a declare in TPA system.
Logistics → set off customs clearance workflow.
Integrations: API/webhooks most popular; RPA as fallback solely when APIs are absent.
Governance options: SLA timers on exception queues, escalation chains to approvers, Slack/Groups notifications for human motion.
💡
Key precept: Orchestration turns “extracted information” into enterprise impression. With out routing, even 99% correct extraction is simply numbers sitting in a JSON file.
Step 6. Suggestions Loop — Making the System Smarter Over Time
Confidence funnel: ≥0.95 → auto-post; 0.80–0.94 → HITL assessment; <0.80 → escalate or reject. Granular thresholds may also be utilized per subject (e.g., stricter for bill totals than for vendor addresses).
Studying cycle: reviewer corrections are logged as coaching alerts, feeding energetic studying pipelines.
Ops guardrails: A/B testing new fashions earlier than manufacturing rollout; regression monitoring to forestall accuracy drops.
💡
Enterprise worth: That is the place IDP outpaces ADP. As a substitute of static templates that degrade over time, IDP learns from each exception—pushing first-pass yield increased month after month.
An IDP workflow isn’t just AI—it’s a ruled pipeline. It ingests paperwork from each channel, classifies them appropriately, extracts fields with ML, validates in opposition to insurance policies, routes to core techniques, and repeatedly improves by means of suggestions. This mixture of machine studying, controls, and human assessment is what makes IDP scalable in messy, high-stakes enterprise environments.
IDP vs Different Approaches — Drawing the Proper Boundaries
Clever Doc Processing (IDP) isn’t a substitute for OCR, RPA, or Automated Doc Processing (ADP). As a substitute, it acts because the orchestrator that makes them clever, complementing them by doing what they can not: studying, generalizing, and deciphering paperwork past templates. The chance in lots of enterprise packages is assuming these instruments are interchangeable—a class mistake that results in brittle, costly automation.
On this part, we’ll make clear their distinct roles and illustrate what occurs when these boundaries blur.
IDP vs. OCR
Whereas OCR offers the foundational “eyes” by changing pixels to textual content, it stays blind to which means or context. IDP builds on this textual content layer by including construction and semantics. It makes use of machine studying and pc imaginative and prescient to grasp that “12345” isn’t just textual content, however a particular bill quantity linked to a vendor and due date. With out IDP, OCR-only techniques collapse in variable environments like multi-vendor invoices.
IDP vs. RPA
RPA serves because the “palms,” automating keystrokes and clicks to bridge legacy techniques with out APIs. It’s quick to deploy however fragile when UIs change and essentially lacks an understanding of the information it is dealing with. Utilizing RPA for doc interpretation is a class mistake; IDP’s function is to extract and validate the information, guaranteeing the RPA bot solely pushes clear, enriched inputs into downstream techniques.
IDP vs. Generic Automation (BPM)
Enterprise Course of Administration (BPM) engines are the “site visitors lights” of a workflow, orchestrating which duties are routed the place and when. They depend on fastened, static guidelines. IDP offers the adaptive “intelligence” inside these workflows by making sense of contracts, claims, or multilingual invoices earlier than the BPM engine routes them. With out IDP, BPM routes unverified, “blind” information.
IDP with ADP
ADP (Automated Doc Processing) offers the deterministic spine, finest fitted to high-volume, low-variance paperwork like standardized types. It ensures auditability and throughput stability. IDP handles the variability that may break ADP’s templates, adapting to new bill layouts and unstructured contracts. Each are required at enterprise scale: ADP for determinism and stability, IDP for managing ambiguity and adaptation.
Errors to Keep away from in Doc Automation
The commonest mistake is assuming these instruments are interchangeable. The flawed alternative results in pricey, fragile options.
Overinvesting in IDP for secure codecs: In case your invoices are from a single vendor, deterministic ADP guidelines will ship sooner ROI than ML-heavy IDP.
Utilizing RPA for interpretation: Let IDP deal with which means; RPA ought to solely bridge techniques with out APIs.
Treating OCR as a full resolution: OCR captures textual content however doesn’t perceive it, permitting errors to leak into core enterprise techniques.
✅ Rule of thumb: Map your doc DNA first (quantity, variability, velocity). Then determine what mixture of OCR, RPA, ADP, BPM, and IDP suits finest.
IDP in Apply: Actual-World Use Instances & Enterprise Outcomes
Clever Doc Processing (IDP) proves its price within the messy actuality of contracts, invoices, claims, and affected person information. What makes it enterprise-ready is not simply its extraction accuracy, however the best way it enforces validations, triggers approvals, and integrates into downstream workflows to ship measurable enhancements in accuracy, scalability, compliance, and value effectivity.
Not like conventional OCR or ADP, IDP does not simply digitize—it learns, validates, and scales throughout unstructured inputs, lowering exception overhead whereas strengthening governance. Against this, template-based techniques usually plateau at round 70–80% field-level accuracy. IDP packages, nevertheless, persistently obtain 90–95%+ accuracy throughout various doc units as soon as human-in-the-loop (HITL) suggestions is embedded, with some benchmarks reporting as much as ~99% accuracy in narrowly outlined contexts. This accuracy isn’t static; IDP pipelines compound accuracy over time as corrections feed again into fashions.
The transformation is finest seen in a side-by-side comparability of key operational metrics.
Advantages (Expertise Outcomes)
IDP Impression Snapshot — Earlier than vs After
Metric
Earlier than (ADP / Handbook)
After (IDP-enabled)
Subject-level accuracy
70–80% (template-driven, brittle)
90–95%+ (compounding by way of HITL suggestions)
First-pass yield (FPY)
50–60% paperwork stream by means of untouched
80–90% paperwork auto-processed
Bill processing price
$11–$13 per bill (guide/AP averages)
$2–$3 per bill (IDP-enabled)
Cycle time
Days (guide routing & approvals)
Minutes → Hours (with validation + SLA timers)
Compliance
Audit trails fragmented; dangerous exception dealing with
Let’s discover how this performs out throughout 5 key doc households.
Contracts: Clause Extraction and Obligation Administration
Contract processing is the place static automation usually breaks. A 60-page provider settlement might comprise indemnity clauses, renewal phrases, or legal responsibility caps buried throughout sections and in inconsistent codecs. With IDP, contracts are ingested from PDFs or scans, labeled and parsed with layout-aware NLP, and validated for required clauses. Counterparties are checked in opposition to vendor masters, deviations past thresholds (e.g., indemnity >$1M) set off escalations, and obligations stream seamlessly into the CLM. Non-standard language does not sit unnoticed—it triggers an alert to Authorized Ops, whereas LLM summarization offers digestible clause critiques grounded in supply textual content.
End result: Obligations are tracked on time, non-standard clauses are flagged immediately, and authorized threat publicity is considerably lowered.
Monetary Paperwork: Invoices, Financial institution Statements, and KYC
Finance is usually the primary area the place brittle automation hurts. Bill codecs fluctuate, IBANs get miskeyed, and KYC packs comprise a number of IDs. Right here, IDP extracts totals and line objects, however extra importantly, it enforces finance coverage: cross-checks invoices in opposition to POs and items receipts, validates vendor information in opposition to grasp information, and screens KYC paperwork in opposition to sanctions lists. Excessive-value invoices set off twin approvals, whereas segregation-of-duties guidelines block conflicts. Clear invoices auto-post into ERP; mismatches stream into dispute queues. Business analysis places guide bill dealing with round $11–$13 per bill, whereas automation reduces this to ~$2–$3, yielding financial savings at scale. A Harvard Enterprise Faculty/BCG research discovered that AI instruments boosted productiveness by 12.2% and reduce job time by 25.1% in information work, mirroring what IDP delivers in document-heavy workflows.
End result: Cheaper invoices, sooner closes, and stronger compliance—all backed by measurable ROI.
Insurance coverage: FNOL Packets and Coverage Paperwork
A single insurance coverage declare would possibly bundle a kind, a coverage doc, and a medical report—every with distinctive codecs. The place ADP thrives in finance/AP, IDP scales horizontally throughout domains like insurance coverage, the place doc range is the rule, not the exception. IDP parses and classifies every doc, validating protection, checking ICD/CPT codes, and recognizing pink flags corresponding to duplicate VINs. Low-value claims stream straight by means of, whereas high-value or suspicious ones path to adjusters or SIU. Structured information feeds actuaries for fraud analytics, whereas LLM summaries give adjusters fast narratives backed by IDP outputs.
End result: Sooner claims triage, diminished leakage from fraud, and an improved policyholder expertise.
Healthcare: Affected person Information and Referrals
Healthcare paperwork mix messy inputs with strict compliance. Affected person IDs and NPIs should match, consent types have to be current, and codes should align with payer insurance policies. IDP parses scans and notes, flags lacking consent types, validates therapy codes, and routes prior-auth requests into payer techniques. Each motion is logged for HIPAA compliance. Handwriting fashions seize doctor notes, whereas PHI redaction ensures protected downstream LLM use.
End result: Sooner prior-auth approvals, decrease clerical load, and regulatory compliance by design.
Logistics: Payments of Lading and Customs Paperwork
International provide chains are document-heavy, and a single error in a invoice of lading or customs declaration can cascade into detention and demurrage charges. These prices aren’t theoretical: a container held at a port for lacking or inconsistent paperwork can run a whole bunch of {dollars} per day in penalties. With IDP, logistics groups can automate classification and validation throughout multilingual transport manifests, payments of lading, and customs types. Information is cross-checked in opposition to tariff codes, provider databases, and cargo information. Incomplete or mismatched paperwork are flagged earlier than they attain customs clearance, lowering pricey delays. Approvals are triggered for high-risk shipments (e.g., hazardous items, dual-use exports) whereas compliant paperwork stream straight by means of.
End result: Sooner clearance, fewer fines, improved visibility, and diminished working capital tied up in delayed shipments.
Why IDP Issues for IT, Answer Architects & Information Scientists
Clever Doc Processing (IDP) isn’t simply an operations win—it reshapes how IT leaders, resolution architects, and information scientists design, run, and enhance enterprise doc workflows.
Every function faces totally different pressures: stability and safety for IT, flexibility and time-to-change for architects, and mannequin lifecycle rigor for information scientists. IDP issues as a result of it unifies these priorities right into a system that’s each adaptable and ruled.
Focuses labeling effort by way of energetic studying, improves repeatedly, ensures protected deployments with rollback paths
Fashions degrade as codecs drift, excessive labeling prices, ungoverned ML lifecycles
For IT Leaders — Stability, Safety, and Scale
IT leaders are tasked with constructing platforms that don’t simply work as we speak however scale reliably for tomorrow. In document-heavy enterprises, the query isn’t whether or not to automate—it’s methods to do it with out compromising safety, compliance, and resilience.
API-first integration: Trendy IDP stacks expose clear APIs that plug instantly into ERP, CRM, and content material administration techniques, lowering reliance on brittle RPA scripts. When APIs are absent, RPA can nonetheless be used—however as a fallback, not the spine.
Safety and governance: Function-based entry management (RBAC) ensures delicate information (like PII or PHI) is simply seen to approved customers. Immutable audit logs monitor each extraction, correction, and approval, which is important for compliance frameworks corresponding to SOX, HIPAA, and GDPR.
Infrastructure readiness: IDP brings workloads which are GPU-heavy in coaching however CPU-efficient at inference. IT should measurement infrastructure for peak throughput, provision excessive availability (HA), and catastrophe restoration (DR), and implement observability layers (metrics, traces, logs) to detect bottlenecks.
Backside line for IT: IDP reduces fragility by minimizing RPA dependence, strengthens compliance by means of auditable pipelines, and scales predictably with the appropriate infra sizing and observability in place.
For Answer Architects — Designing for Variability
Answer architects stay within the area between enterprise necessities and technical realities. Their mandate: design automation that adapts as doc varieties evolve.
Sample libraries: IDP permits architects to outline reusable ingestion, classification, validation, and routing patterns. As a substitute of one-off templates, they create modular constructing blocks that deal with households of paperwork.
Time-to-change: In rule-based techniques, including a brand new doc sort may take weeks of template design. With IDP, supervised fashions fine-tuned on annotated samples scale back onboarding to days. Lively studying additional accelerates this by letting fashions enhance repeatedly with human suggestions.
Orchestration flexibility: Architects can embed enterprise guidelines the place determinism issues (e.g., approvals, segregation of duties) and let IDP deal with variability the place templates fail (e.g., new bill layouts, contract clauses).
Backside line for architects: IDP extends their toolkit from inflexible guidelines to adaptive intelligence. This steadiness means fewer brittle workflows and sooner responses to altering doc ecosystems.
For Information Scientists — A Residing ML System
Not like static analytics tasks, IDP techniques are stay ML ecosystems that should study, enhance, and be ruled in manufacturing. Information scientists in IDP packages face a really totally different actuality than in conventional mannequin deployments.
Annotation technique: Excessive-quality coaching information is the one most essential issue for IDP accuracy. DS groups should steadiness annotation throughput with high quality, usually utilizing weak supervision or energetic studying to maximise effectivity.
Lively studying queues: As a substitute of labeling paperwork at random, IDP techniques prioritize “arduous” circumstances (low-confidence, unseen layouts) for human assessment. This ensures mannequin enhancements the place they matter most.
MLOps lifecycle: IDP requires sturdy launch and rollback methods. Fashions have to be evaluated offline on validation units, then on-line with A/B testing to make sure accuracy doesn’t regress.
Drift detection: Doc codecs evolve continuously—new distributors, new clause language, new healthcare types. Steady monitoring for distributional drift is obligatory to maintain fashions performant over time.
Backside line for DS groups: IDP isn’t a one-time deployment—it’s an evolving ML program. Success relies on robust annotation pipelines, energetic studying methods, and mature MLOps practices.
The Balancing Act: IDP and ADP Collectively
Enterprises usually fall into the lure of asking: “Ought to we use ADP or IDP?” The truth is that each are required at scale.
ADP (Automated Doc Processing) offers the deterministic spine—guidelines, validations, and routing. It ensures compliance and repeatability.
IDP (Clever Doc Processing) offers the adaptive mind—machine studying that handles unstructured and variable codecs.
“With out ADP’s determinism, IDP can not scale. With out IDP’s intelligence, ADP collapses beneath variability.”
Every persona sees IDP in a different way: IT leaders concentrate on safety and stability, architects on adaptability, and information scientists on steady studying. However the convergence is evident: IDP is the ML mind that, mixed with ADP’s guidelines spine, makes enterprise automation each resilient and scalable.
Construct vs Purchase — A Technical Choice Lens
When you’ve audited your doc DNA and decided that IDP is the appropriate match, the following query is evident: do you construct in-house fashions, purchase a vendor platform, or pursue a hybrid strategy? The precise alternative relies on the way you steadiness management, time-to-value, and compliance in opposition to the realities of knowledge labeling, mannequin upkeep, and safety posture.
When to Construct — Management and Customized IP
Constructing your personal IDP stack appeals to groups that worth management and differentiation. By coaching customized fashions, you personal the mental property, tune efficiency for domain-specific edge circumstances, and retain full visibility into the ML lifecycle.
However management comes at a price:
Information/labeling burden: Excessive-quality labeled datasets are the bedrock of IDP efficiency. Constructing requires sustained funding in annotation pipelines, tooling, and workforce administration.
MLOps lifecycle: You inherit duty for versioning, rollback methods, monitoring for drift, and refreshing fashions at an everyday cadence (usually quarterly or sooner in dynamic domains).
Compliance overhead: In regulated industries (finance, healthcare, insurance coverage), self-built options should obtain certifications (SOC 2, HIPAA, ISO) and stand up to audits—burdens normally absorbed by distributors.
Construct is smart for organizations with robust ML groups, distinctive doc varieties (e.g., specialised underwriting packs), and strategic curiosity in proudly owning IP.
When to Purchase — Accelerators and Assurance
Shopping for from an IDP vendor offers pace and assurance. Trendy platforms ship with pre-trained accelerators for widespread doc households: invoices, POs, IDs, KYC paperwork, contracts. They sometimes arrive with:
Connectors and APIs: Prepared-made integrations for ERP (SAP, Oracle), CRM (Salesforce), and storage techniques (SharePoint, S3).
Help for HITL workflows: Configurable reviewer consoles, audit logs, and approval chains.
The trade-off is opacity and suppleness. Some platforms act as black packing containers—you may’t see mannequin internals or adapt coaching past predefined accelerators. For enterprises needing explainability, this will restrict adoption.
Purchase is smart if you want speedy time-to-value, trade certifications, and protection for widespread doc varieties.
When to Go Hybrid — Better of Each Worlds
In follow, many enterprises find yourself with a hybrid mannequin:
Use vendor platforms for the 80% of paperwork that match widespread accelerators.
Construct customized fashions for area of interest, high-value doc households (e.g., mortgage origination packs, insurance coverage bordereaux, affected person referral bundles).
This strategy reduces time-to-market whereas nonetheless letting inside information science groups apply domain-specific elevate. Distributors more and more assist this mannequin with bring-your-own-model (BYOM) choices—the place customized ML fashions can plug into their ingestion and workflow engines.
Hybrid is smart when enterprises need vendor reliability with out giving up management over specialised circumstances.
Choice Matrix — Construct vs Purchase vs Hybrid
Construct vs Purchase vs Hybrid — Engineering Choice Matrix
Standards
Construct
Purchase
Hybrid
Time-to-value
Gradual (months for information & infra)
Quick (weeks with pre-trained accelerators)
Reasonable (weeks for core, months for customized)
Mannequin possession
Full management & IP
Vendor-owned, black-box threat
Cut up (vendor core + customized fashions)
Labeling overhead
Excessive (guide + energetic studying required)
Low (pre-trained units included)
Medium (low for traditional docs, excessive for area of interest)
Change velocity
Quick for customized fashions, however useful resource heavy
Restricted flexibility; vendor launch cycles
Balanced—vendor updates core, groups adapt area of interest
Safety posture
Customized certifications required; heavy burden
Certifications pre-included (SOC 2, ISO, HIPAA)
Blended—vendor covers core; groups certify area of interest
Sensible Steering
Most enterprises overestimate their capability to maintain a pure-build strategy. Information labeling, compliance, and MLOps burdens develop sooner than anticipated. Essentially the most pragmatic path is normally:
Begin buy-first → leverage vendor accelerators for widespread paperwork.
Show worth in 4–6 weeks with invoices, POs, or KYC packs.
Prolong with in-house fashions solely the place domain-specific elevate issues
The Street Forward for IDP — Future Instructions & Sensible Subsequent Steps
Clever Doc Processing (IDP) has matured into the AI/ML mind of enterprise doc workflows. It enhances ADP’s guidelines spine and RPA’s execution bridge, however its subsequent evolution goes additional: including semantic understanding, autonomous brokers, and enterprise-grade governance.
The chance is large—and organizations don’t want to attend to start out benefiting.
From Capturing Fields to Understanding That means
For many of the final decade, IDP success was measured when it comes to accuracy and throughput: how effectively may techniques classify a doc and extract key fields? That downside isn’t going away, however the bar is transferring increased.
The brand new wave of IDP is about semantics, not simply syntax. Giant Language Fashions (LLMs) can now sit on high of structured IDP outputs to:
Summarize lengthy contracts into digestible threat experiences.
Flag uncommon indemnity clauses or lacking obligations.
Flip unstructured affected person notes into structured scientific codes plus a story abstract.
Crucially, these insights will be grounded with RAG (retrieval-augmented technology) so that each AI-generated abstract factors again to unique textual content. That’s not simply helpful—it’s important for audits, authorized assessment, and compliance-heavy industries.
From Inflexible Workflows to Autonomous Brokers
Immediately’s IDP techniques route structured information into ERPs, CRMs, claims platforms, or TMS portals. Tomorrow, that’s only the start.
We’re getting into the period of multi-agent orchestration, the place AI brokers devour IDP information and carry processes additional on their very own:
Retriever brokers fetch the appropriate paperwork from repositories.
Validator brokers test in opposition to insurance policies or threat thresholds.
Executor brokers carry out actions in techniques of document—posting entries, triggering funds, or updating claims.
Consider claims triage, accounts payable reconciliation, or customs clearance working agentically, with people stepping in just for oversight or exception dealing with.
The Governance Crucial
However better autonomy brings better threat. As LLMs and brokers enter doc workflows, enterprises face questions on reliability, security, and accountability.
Mitigating that threat requires new disciplines:
Analysis harnesses to stress-test workflows earlier than launch.
Pink-team prompting to uncover weaknesses in mannequin conduct.
Fee limiters and value screens to maintain operations secure and predictable.
Immutable audit trails to fulfill regulators and guarantee inside stakeholders.
The profitable IDP packages will probably be those who mix innovation with governance—pushing towards new capabilities with out sacrificing management.
What Enterprises Ought to Do Now
The long run is thrilling, however the actual query for many leaders is: what ought to we do as we speak?
The playbook is simple:
Audit your doc DNA. What varieties dominate your enterprise? How variable are they? What’s the rate? This tells you whether or not ADP, IDP, or each are wanted.
Choose one household for a pilot. Invoices, contracts, claims—select one thing high-volume and pain-heavy.
Run a 4–6 week pilot. Observe 4 metrics: accuracy (F1 rating), first-pass yield, exception fee, and cycle time.
Scale with intent. Increase to adjoining doc varieties. Layer ADP for compliance, IDP for variability, and use RPA solely the place APIs aren’t obtainable.
Construct future hooks. Even when you don’t deploy LLMs or brokers as we speak, design workflows that might accommodate them later. That manner, you’re not re-architecting in two years.
The purpose isn’t to leap straight into futuristic agent-driven workflows—it’s to start out measuring and capturing worth now whereas making ready for what’s subsequent.
FAQs
1. What do analyst companies say in regards to the IDP market?
Analyst companies typically place Clever Doc Processing (IDP) throughout the broader “clever automation” or “hyperautomation” stack alongside RPA, BPM/workflow, and analytics. Whereas terminology varies (e.g., “doc AI,” “content material intelligence,” “clever automation platforms”), the consensus is that IDP offers the studying and interpretation layer that makes automation resilient when doc codecs fluctuate.
They consider distributors on ingestion, classification, extraction, HITL assessment, workflow depth, platform qualities, and time-to-value. Enterprises ought to map their doc DNA (quantity, variability, velocity) in opposition to vendor strengths and validate by way of time-boxed pilots measuring F1, FPY, exception charges, and cycle instances.
2. What’s RAG (retrieval-augmented technology) in IDP, and the way is it wired into the pipeline?
Retrieval-augmented technology (RAG) grounds LLM outputs in retrieved supply paperwork, lowering hallucinations and guaranteeing traceability. In IDP pipelines, RAG sits after extraction to allow summaries and explanations that cite unique textual content.
Typical stream:
IDP extracts structured fields/tables with confidence scores.
Textual content chunks + metadata (web page, part, doc sort) are embedded right into a vector index.
A retriever selects related chunks, that are appended to the LLM immediate.
The LLM generates grounded outputs (summaries, threat flags, obligation lists) with citations.
Outputs, retrieval units, and mannequin variations are logged for audit.
3. What dangers include LLMs in doc workflows, and the way can we mitigate them?
Key dangers embrace hallucinations, information leakage, immediate injection, compliance gaps, price/latency spikes, and explainability calls for.
Mitigation methods:
Hallucinations: Use RAG grounding, “answer-from-context” prompting, factuality testing.
Information leakage: Redact PII, implement personal deployments, encrypt retention.
Run a 4–6 week pilot to baseline these metrics, then monitor month-to-month. Success = increased F1/FPY, decrease exceptions and value/doc, and secure auditability.
5. Can IDP deal with handwriting reliably? What ought to we count on?
Sure—fashionable IDP platforms can deal with handwriting, however reliability relies on scan high quality, script, and language. Count on robust outcomes on quick structured fields (names, dates, quantities) if scans are clear (≥300 DPI).
Challenges come up with cursive scripts, noisy cellular captures, and non-Latin handwriting with out domain-specific coaching.
Finest practices embrace:
Pre-process scans (de-skew, distinction enhance).
Zone handwriting individually from typed sections.
Implement subject constraints (e.g., date codecs).
Like clockwork, Apple launched a brand new set of iPhones this September. However the spotlight of the “Awe Dropping” keynote for me wasn’t the brand new iPhone 17 lineup and even the Apple Watch Sequence 11. It was the brand new AirPods Professional 3.
As an Android person for the previous few years, I’ve all the time been a bit envious of how seamlessly the AirPods work throughout the Apple ecosystem. You may effortlessly change between gadgets, take pleasure in that glossy connection animation each time you open the case, and expertise among the finest energetic noise cancellation on any earbuds.
Certain, Android has loads of sturdy contenders, too. The Google Pixel Buds Professional 2 and Samsung Galaxy Buds 3 Professional are each wonderful wi-fi earbuds, and there are equally spectacular choices from manufacturers like Bose and Sony, together with the brand new QuietComfort Extremely Earbuds Gen 2 and Sony WF-1000XM5.
However the AirPods Professional 3 had been the turning level for me. After avoiding them for years, I lastly purchased them — and there is not any doubt they’re spectacular. The energetic noise cancellation is actually top-tier.
I took two flights carrying them, and there was just about no cabin noise in any respect. My Pixel Buds Professional 2 have been nice at slicing down ambient sounds throughout journey, however this was on one other stage.
However that is not the characteristic I would like different manufacturers to repeat. Earbuds will maintain getting higher at noise cancellation with every new technology, however the characteristic that genuinely blew me away on the AirPods Professional 3 is the built-in coronary heart price monitoring.
AirPods Professional 3 can now monitor your exercises too
One of many new options Apple has added to the AirPods Professional 3 is an optical coronary heart price sensor. This implies now you can use the AirPods Professional 3 to trace your exercises. Just like different health trackers, the guts price sensor flashes mild to measure blood circulate by the ear canal and shares that knowledge with the iPhone’s Health app.
Get the most recent information from Android Central, your trusted companion on this planet of Android
The app then makes use of on-device AI to calculate exercise metrics similar to energy burned, steps taken, and distance lined. Apple even claims that the AirPods Professional 3 can monitor over fifty exercises, together with operating, yoga, and power coaching.
And whereas it might sound unusual to trace exercises utilizing earbuds as a substitute of conventional health trackers or smartwatches, it is truly a fairly good thought. The ear is definitely a fairly steady location for coronary heart price monitoring, because the sensors are near main arteries and fewer affected by motion throughout intense exercise.
Apple additionally says that when each the AirPods Professional 3 and an Apple Watch are linked to your iPhone, the system mechanically makes use of knowledge from whichever gadget offers essentially the most correct readings at any given second. This ensures the very best protection and accuracy all through your exercise.
That stated, I made a decision to make use of the AirPods Professional 3 as my solely health-tracking gadget for over every week, evaluating it instantly with a devoted health tracker. And this is how the AirPods carried out and whether or not they can actually be thought of dependable health trackers.
How dependable is the AirPods Professional 3’s coronary heart price monitoring?
Since I already put on the AirPods Professional 3 all through my exercise classes, having the ability to monitor exercises means I can skip health wearables on my wrist, which seems like a win-win for me.
To actually assess whether or not the AirPods Professional 3 is a dependable health tracker, I examined them towards one other health tracker, the Huawei Watch Match 4 Professional, which I paired with a unique smartphone to forestall my iPhone from mixing the information. My objective was to see if the 2 gadgets recorded related outcomes, and the result was surprisingly shut.
For context, my exercises often embrace a mixture of power coaching, cardio, and stretching. Even on different health gadgets, I usually choose the “Different” exercise mode so I haven’t got to change between a number of modes throughout my hour-long classes.
I adopted the identical setup for this check. I began my exercise on each gadgets on the similar time and in contrast their coronary heart price and calorie readings all through.
To my shock, the guts price numbers from each the AirPods Professional 3 and the Huawei Watch Match 4 Professional had been virtually similar each time I checked. The calorie estimates had been barely completely different, which is sensible since every gadget makes use of its personal algorithm to estimate energy burned. What impressed me was how effectively the AirPods tracked exercise depth and rhythm by the ear.
The guts price is a direct physiological metric, whereas calorie burn relies upon extra on how every gadget interprets your physique knowledge. The truth that the AirPods Professional 3 matched a devoted health tracker in real-time coronary heart price accuracy was genuinely spectacular.
For most individuals, particularly informal gym-goers or those that don’t love carrying a smartwatch, this stage of precision is greater than sufficient, for my part. You may merely pop in your AirPods, begin your exercise, and nonetheless get significant insights with none additional gear.
After all, for those who’re in search of superior health monitoring, one thing like a Whoop or Garmin watch will nonetheless be the higher selection. However for on a regular basis customers or those that often overlook their tracker at house, the AirPods Professional 3 does a surprisingly good job.
Health in your ears
The AirPods Professional 3 ship an improved energetic noise cancelation together with spatial audio with dynamic head monitoring. Apple’s newest earbuds additionally add IP57-rated sweat and water resistance, Dwell Translation assist, and a built-in coronary heart price sensor that displays your pulse throughout exercises, bringing health monitoring on to your ears.
The Bayesian evaluation reporting tips (BARG) are actually listed on The EQUATOR Community.
“The EQUATOR (Enhancing the QUAlity and Transparency Of well being Analysis) Community is a global initiative that seeks to enhance the reliability and worth of revealed well being analysis literature by selling clear and correct reporting and wider use of strong reporting tips. It’s the first coordinated try to deal with the issues of insufficient reporting systematically and on a worldwide scale; it advances the work completed by particular person teams during the last 15 years.” (Quoted from this web page.)
“The [EQUATOR] Library for well being analysis reporting gives an up-to-date assortment of tips and coverage paperwork associated to well being analysis reporting. These are aimed primarily at authors of analysis articles, journal editors, peer reviewers and reporting guideline builders.” (Quoted from this web page.)
The Bayesian evaluation reporting tips (BARG) are described in an open-access article at Nature Human Behaviour. The BARG present an intensive set of factors to contemplate when reporting Bayesian knowledge analyses. The factors are completely defined, and a abstract desk is supplied.
The BARG are listed at The EQUATOR Community right here.
Earth has entered a grim new local weather actuality.
The planet has formally handed its first local weather tipping level. Relentlessly rising warmth within the oceans has now pushed corals world wide previous their restrict, inflicting an unprecedented die-off of worldwide reefs and threatening the livelihoods of practically a billion individuals, scientists say in a brand new report printed October 13.
Even underneath essentially the most optimistic future warming state of affairs — one wherein international warming doesn’t exceed 1.5 levels Celsius above pre-industrial occasions — all warm-water coral reefs are just about sure to cross some extent of no return. That makes this “one of the crucial urgent ecological losses humanity confronts,” the researchers say in World Tipping Factors Report 2025.
And the lack of corals is simply the tip of the iceberg, so to talk.
“Since 2023, we’ve witnessed over a yr of temperatures of greater than 1.5 levels Celsius above the preindustrial common,” stated Steve Smith, a geographer on the College of Exeter who researches tipping factors and sustainable options, at a press occasion October 7 forward of publication. “Overshooting the 1.5 diploma C restrict now appears fairly inevitable and will occur round 2030. This places the world in a hazard zone of escalating dangers, of extra tipping factors being crossed.”
These tipping factors are factors of no return, nudging the world over a proverbial peak into a brand new local weather paradigm that, in flip, triggers a cascade of results. Relying on the diploma of warming over the subsequent a long time, the world may witness widespread dieback of the Amazon rainforest, the collapse of the Greenland and West Antarctic ice sheets and — most worrisome of all — the collapse of a robust ocean present system often known as the Atlantic Meridional Overturning Circulation, or AMOC.
Falling dominos
World warming has already pushed coral reefs previous their resilience restrict, researchers say. Below present local weather insurance policies, warming is prone to attain about 3 levels Celsius inside a long time, triggering a tipping level for collapse of the West Antarctic Ice Sheet, retreat of mountain glaciers and the collapse of an ocean present off Greenland referred to as the subpolar gyre. The destiny of the Amazon rainforest is tied each to warming and to charges of deforestation, whereas the destiny of Atlantic ocean circulation stays unsure underneath present warming trajectories. This graphic reveals warming thresholds for various points of the local weather system; previous these thresholds, every system will shift dramatically into a brand new local weather paradigm.
World Tipping Factors Abstract Report 2025
It’s now 10 years after the historic Paris Settlement, wherein practically all the world’s nations agreed to curb greenhouse fuel emissions sufficient to restrict international warming to properly beneath 2 levels Celsius by the yr 2100 — ideally limiting warming to not more than 1.5 levels Celsius, with the intention to forestall most of the worst impacts of local weather change.
However “we’re seeing the backsliding of local weather and environmental commitments from governments, and certainly from companies as properly,” in terms of lowering emissions, stated Tanya Steele, CEO of the UK workplace of the World Wildlife Fund, which hosted the press occasion.
The report is the second tipping level evaluation launched by a world consortium of over 200 researchers from greater than 25 establishments. The discharge of the brand new report is deliberately timed: On October 13, ministers from nations world wide will arrive in Belém, Brazil, to start negotiations forward of COP30, the annual United Nations Local weather Change Convention.
In 2024, there have been about 150 unprecedented excessive climate occasions, together with the worst-ever drought within the Amazon. That the convention is being held close to the guts of the rainforest is a chance to lift consciousness about that looming tipping level, Smith stated. Current analyses recommend the rainforest “is at better threat of widespread dieback than beforehand thought.”
That’s as a result of it’s not simply warming that threatens the forest: It’s the mix of deforestation and local weather change. Simply 22 % deforestation within the Amazon is sufficient to decrease the tipping level threshold temperature to 1.5 levels warming, the report states. Proper now, Amazon deforestation stands at about 17 %.
There’s a glimmer of fine information, Smith stated. “On the plus facet, we’ve additionally handed a minimum of one main constructive tipping level within the power system.” Optimistic tipping factors, he stated, are paradigm shifts that set off a cascade of constructive adjustments. “Since 2023, we’ve witnessed speedy progress within the uptake of unpolluted applied sciences worldwide,” notably electrical automobiles and photo voltaic photovoltaic, or photo voltaic cell, expertise. In the meantime, battery costs for these applied sciences are additionally dropping, and these results “are beginning to reinforce one another,” Smith stated.
Nonetheless, at this level, the problem is just not about simply lowering emissions and even pulling carbon out of the environment, says report coauthor Manjana Milkoreit, a political scientist on the College of Oslo who researches Earth system governance.
What’s wanted is a wholescale paradigm shift in how governments method local weather change and mitigations, Milkoreit and others write. The issue is that present programs of governance, nationwide insurance policies, guidelines and multinational agreements — together with the Paris Settlement — have been merely not designed with tipping factors in thoughts. These programs have been designed to embody gradual, linear adjustments, not abrupt, quickly cascading fallout on a number of fronts without delay.
“What we’re arguing within the report is that these tipping processes actually current a brand new sort of risk,” one that’s so large it’s tough to understand its scale, Milkoreit says.
The report outlines a number of steps that decision-makers might want to take, and shortly, to keep away from passing extra tipping factors. Chopping emissions of short-lived pollutions reminiscent of methane and black carbon are the primary line of motion, to purchase time. The world additionally must swiftly amp up efforts for large-scale elimination of carbon from the environment. At each the governmental and the private stage, efforts ought to ramp up making international provide chains sustainable, reminiscent of by lowering demand for and consumption of merchandise linked to deforestation.
And governments will rapidly have to develop mitigation methods to cope with a number of local weather impacts without delay. This isn’t a menu of selections, the report emphasizes: It’s a listing of the actions which are wanted.
Making these leaps quantities to an enormous activity, Milkoreit acknowledges. “We’re bringing this large new message, saying, ‘What you’ve gotten is just not ok.’ We’re properly conscious that that is coming inside the context of 40 years of efforts and struggles, and there are many political dimensions, and that the local weather work itself is just not getting simpler. The researchers wrestle with this, journalists wrestle with promoting the horrible information and decision-makers equally have resistance to this.”
It’s essential to not look away. She and her coauthors hope this report will immediate individuals to have interaction with the problem, to think about at the same time as people what actions we will take now to help these efforts, whether or not it’s making totally different shopper selections or amplifying the message that the time to behave is now, she says. “Even for a reader to have the braveness to stick with the difficulty is figure, and I wish to acknowledge that work.”








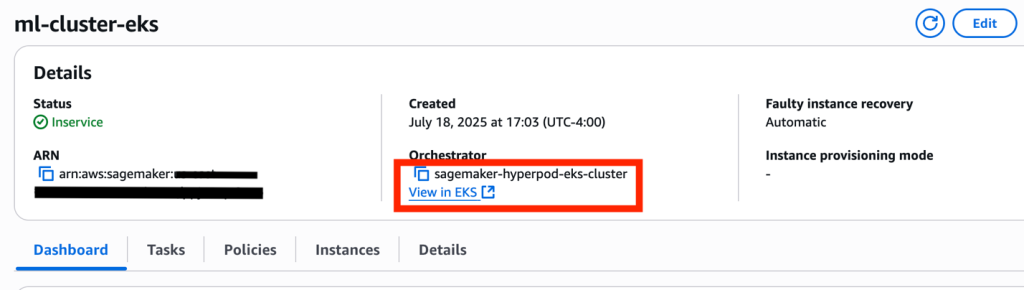









")