Music can elevate any outside journey, and the JBL Clip 5 Moveable Bluetooth Speaker is ideal for taking your tunes anyplace. This speaker simply dropped to $59.95, which is a 25% low cost relative to its regular value of $79.95.
Small however mighty, the Clip 5 presents spectacular sound high quality with its JBL Professional Sound expertise regardless of its compact design. It’s IP67-certified, which means it’s each waterproof and dustproof, so you’ll be able to confidently take it to the seaside, by the pool, or on a mountaineering path. With its built-in carabiner clip, you’ll be able to simply connect it to your backpack or carry it with one hand. On a single cost, you’ll be able to take pleasure in as much as 12 hours of playback, or 15 hours if you happen to allow Playtime Enhance. Plus, you’ll be able to handle the speaker via the JBL Moveable app, adjusting EQ settings and unlocking options.
In keeping with DealHunt, our companion website that tracks Amazon costs and charges offers utilizing AI evaluation, this product scores a formidable 87 out of 100. This rating displays the present value of $59.95, which is $12.10 under the 90-day common of $72.05, providing you with a 17% financial savings. Moreover, it’s at an all-time low, enhancing its worth. The worth dropped simply 19 hours in the past, guaranteeing that you’re getting a recent deal on this common speaker.
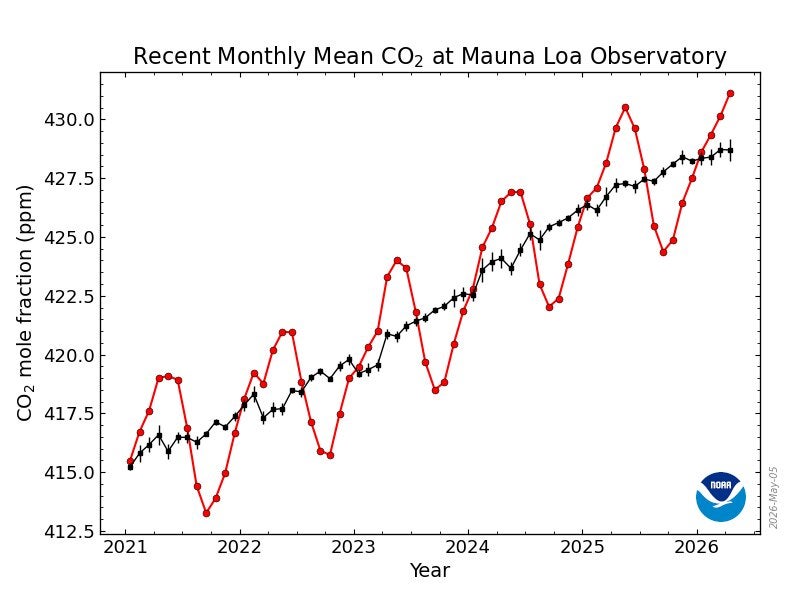
Carbon dioxide ranges within the environment simply hit a ‘miserable’ new file
These knowledge come from the Nationwide Oceanic and Atmospheric Administration’s Mauna Loa Observatory, which can quickly be shut down due to proposed authorities price range cuts
The quantity of carbon dioxide detected within the environment hit a file excessive in April. CO2 ranges averaged about 431 elements per million (ppm) over that month, in keeping with knowledge collected on the Nationwide Oceanic and Atmospheric Administration’s Mauna Loa Observatory in Hawaii.
Greenhouse gases, corresponding to carbon dioxide, are measured as a proportion of the whole environment. The numbers are offered because the variety of molecules of a selected gasoline out of one million complete molecules, or ppm.
Local weather scientist Zachary Labe of Local weather Central, a nonprofit that researches local weather change, says the brand new file is “miserable” however not surprising.
On supporting science journalism
If you happen to’re having fun with this text, contemplate supporting our award-winning journalism by subscribing. By buying a subscription you’re serving to to make sure the way forward for impactful tales concerning the discoveries and concepts shaping our world at this time.
“It’s simply one other signal that carbon dioxide continues to extend in our environment as our planet continues to heat,” he says. “For a lot of local weather scientists, that is simply ‘right here it’s once more, one other file within the unsuitable route.’”
Labe explains that the quantity of CO2 within the environment tends to peak in April every year as decaying vegetation launch greenhouse gases after winter. A few of that CO2 will get reabsorbed by vegetation as they develop through the hotter months. However NOAA’s knowledge present a worrying development, with the common month-to-month quantity of CO2 steadily growing.
The Mauna Loa Observatory has been instantly observing atmospheric CO2 and retaining file of its ranges for the longest out of some other U.S. facility. Mauna Loa first started retaining observe of the gasoline’s presence within the environment in 1958. That yr the April stage of CO2 was underneath 320 ppm.
The file comes because the observatory faces the danger of getting its funding reduce. A price range proposal on NOAA’s web site for the 2027 fiscal yr, which begins in October 2026, proposes reducing funding to quite a few local weather monitoring amenities, together with Mauna Loa.
Different strategies can hint carbon ranges within the environment additional again in historical past. For instance, climatologists can analyze small bubbles of gasoline trapped in ice cores to review the Earth’s environment tons of of hundreds of years in the past. On its web site, NOAA cites analyses that present that, in pre-industrial-revolution occasions, atmospheric CO2 was at 280 ppm or much less. Even throughout interglacial intervals, when Earth trended towards hotter temperatures and better CO2 ranges, the quantity of the gasoline within the environment appeared to have topped out at round 300 ppm.
Though the quantity of CO2 within the environment has continued to rise, there was a discount in U.S. emissions in 2023 and 2024. That development, nonetheless, was reversed in 2025, no less than partially due to the elevated electrical energy demand from synthetic intelligence knowledge facilities.
Nonetheless, Labe says there are causes for optimism as the usage of renewable vitality sources corresponding to photo voltaic and wind expands.
It’s Time to Stand Up for Science
If you happen to loved this text, I’d prefer to ask in your help. Scientific American has served as an advocate for science and business for 180 years, and proper now stands out as the most crucial second in that two-century historical past.
I’ve been a Scientific American subscriber since I used to be 12 years outdated, and it helped form the best way I have a look at the world. SciAm at all times educates and delights me, and evokes a way of awe for our huge, stunning universe. I hope it does that for you, too.
If you happen to subscribe to Scientific American, you assist make sure that our protection is centered on significant analysis and discovery; that we have now the assets to report on the selections that threaten labs throughout the U.S.; and that we help each budding and dealing scientists at a time when the worth of science itself too typically goes unrecognized.
Researchers analyzed newly revealed web sites from 2022 via mid-2025 to estimate what proportion used generated textual content and the way this may have an effect on future data on-line.
The proliferation of AI-generated and AI-assisted textual content on the web is feared to contribute to a degradation in semantic and stylistic variety, factual accuracy, and different damaging developments. We discover that by mid-2025, roughly 35% of newly revealed web sites had been categorised as AI-generated or AI-assisted, up from zero earlier than ChatGPT’s launch in late 2022. We additionally discover proof suggesting that will increase in AI-generated textual content on the web carry a couple of lower in semantic variety and a rise in optimistic sentiment. We don’t, nonetheless, discover statistically vital proof supporting the speculation that an elevated price of AI-generated textual content on the web decreases factual accuracy or stylistic variety. Notably, our findings diverge from public notion of AI’s affect on the web.
So it has grown to a couple of third of latest websites that use AI-generated or AI-assisted textual content. That looks like lots?
I’m extra stunned that there didn’t seem like a major change in pretend data or a convergence in fashion.
My concept is that most individuals placing up these generated websites are both experimenting or making an attempt to make a fast buck. Both method, they only take no matter data is given to them by way of a probabilisitic mannequin and neglect about it. They don’t care what the phrases say or how it’s stated, simply so long as it fills area. So the output defaults to largely right statements.
One of many pleasures of well-liked artwork is the glimpse it gives into the
attitudes of the occasions. Generally this pleasure comes from the naivete
of earlier occasions. Extra usually, although, the expertise is simply the
reverse — you uncover that the attitudes of earlier generations had been
advanced, surprisingly trendy and infrequently at odds with the standard
view of the period.
I not too long ago learn a few pulp novels from the Sixties that fell into the second class. One was The Thief Who Could not Sleep by Lawrence Block (mentioned right here). The opposite was The Ambushers, the sixth ebook within the Matt Helm sequence by Donald Hamilton.
Matt
Helm was a counter espionage agent specializing in moist work, nearer to a
John LeCarre hero than to James Bond. The books had been nicely reviewed
(Anthony Boucher, writing, I imagine, within the New York Instances, stated
“Donald Hamilton has dropped at the spy novel the genuine exhausting realism
of Dashiell Hammett; and his tales are as compelling, and doubtless as
near the sordid reality of espionage, as any now being advised.”), they
had been extraordinarily well-liked and so they had been sturdy sufficient to outlive a
god-awful sequence of in-name-only variations starring Dean Martin.
Should you picked up a replica of the Ambushers
in 1963 and turned to the primary web page, you’d discover the narrator slipping
right into a Latin American nation carrying a rifle with a excessive powered
scope. The insurgent chief he has been despatched to kill could have had it coming,
nevertheless it’s not apparent that concentrate on was any worse than the chief the U.S.
supported (later within the story, Helm is glad to listen to that the latter has
additionally been assassinated although his superiors most definitely aren’t).
The Russians in the Ambushers
are typically enemies and typically allies, relying on the
circumstances. The American brokers typically maintain the excessive ethical floor
nevertheless it’s a distinction that may be fairly skinny and the protagonist has
discovered to not dwell on it an excessive amount of. Everybody’s palms are soiled.
As
in lots of tales of the interval, the risk nuclear warfare right here comes not
from both of the superpowers however from a 3rd occasion. On this case, a
Nazi warfare legal who, not surprisingly, want to see Russia and
America destroy one another.
You’ll usually hear the attitudes
implicit on this story related to the late Sixties and early
Seventies, normally attributed to the escalation of the warfare and and the
rise of a politicized youth tradition, however this was 1963. It was early in
the warfare and even the oldest of the boomers had been nonetheless in highschool.
If
you surveyed the popular culture of the time you’ll discover different proof
{that a} radical shift in the way in which we appeared on the chilly warfare occurred in
the late Fifties and early Sixties. Nuclear warfare was not more likely to
be depicted as a Pearl Harbor-style assault however fairly as both a
horrible mistake (Failsafe — novel 1962, movie 1964) or the work of a
madman (Purple Alert — 1958/Strangelove* — 1963) or the terrorist scheme
of a 3rd occasion (too quite a few to say). Anti-communist brokers may
be as morally compromised because the enemy (The Spy Who Got here in from the
Chilly — 1963). A sympathetic Russian was so acceptable that by 1964, you
may have a loyal and brazenly communist Russian agent as a co-star in a
well-liked spy present (albeit a Russian performed by the Scottish David
McCallum).
I’ve puzzled if this shift was a response the Cuban
Missile Disaster. Speaking to those that had been round on the time, I get the
impression that for all of the paranoia and anxiousness and civil protection
drills, the idea of nuclear warfare was by no means actually actual to most individuals
till 1962.
Good researchers in sociology or political may
most likely present a rigorous reply to the query of what precisely drove
the shift. I would be eager about seeing what they got here up with and if
they want one other matter after that, I’ve an entire shelf Gold Medal
paperbacks for them to take a look at.
(You possibly can watch Dr. Strangelove on-line right here)
On this lesson, you’ll learn to harden a semantic cache for LLMs, one of the crucial essential LLMOps patterns for decreasing redundant inference prices, and transfer from a working semantic caching prototype to a system that may survive real-world utilization with TTL validation, confidence scoring, deduplication, and cache poisoning prevention.
This lesson is the final in a 2-part collection on Semantic Caching for LLMs:
In Lesson 1, we constructed a semantic cache that works end-to-end. It accurately avoids redundant LLM calls, reuses responses for an identical queries, and even handles paraphrased inputs by way of semantic similarity. For a lot of tutorials, that will be the top of the story.
In actual programs, nonetheless, working is simply the place to begin.
A semantic cache that works underneath ideally suited situations can nonetheless fail in delicate and harmful methods when uncovered to actual customers, long-running processes, and evolving data. These failures don’t often seem as crashes or specific errors. As a substitute, they present up as silent correctness points, degraded consumer belief, and unpredictable habits over time.
What Lesson 1 Solved — and What It Didn’t
Lesson 1 centered on the correctness of circulate:
Requests transfer by way of precise match → semantic match → LLM fallback (technology)
Cached responses are reused when acceptable
The system is observable and debuggable
Nothing is hidden behind abstractions
What it deliberately didn’t handle was long-term security.
We didn’t ask:
How outdated is that this cached response, and may we nonetheless belief it?
What occurs if the LLM returns an error or partial output?
What if the cache slowly fills with duplicates?
What if similarity is excessive however the reply is now not legitimate?
These questions solely matter as soon as the system runs for days or even weeks, not minutes.
Actual-World Failure Modes in Semantic Caching
Semantic caching introduces failure modes that not often exist in conventional exact-match caches.
For instance:
A cached reply with very excessive similarity should be stale
An error response could also be by accident cached and reused
Slight variations of the identical question might create duplicate entries
Outdated however related solutions might seem appropriate whereas being subtly improper
None of those points breaks the system outright. As a substitute, they quietly degrade correctness and consumer belief over time.
These are the toughest bugs to detect as a result of the system continues to reply rapidly and confidently.
Why “It Works” Does Not Imply “It’s Protected”
A semantic cache sits instantly within the resolution path of an LLM system. When it makes a mistake, that mistake is amplified by way of reuse.
If an unsafe response enters the cache:
It may be served repeatedly
It will probably outlive the situations that made it legitimate
It may be returned with excessive confidence
That is why semantic caching requires extra self-discipline, not much less, than direct LLM calls.
On this lesson, we’ll take the working system from Lesson 1 and start hardening it. We are going to introduce specific safeguards for staleness, confidence, duplication, and security — with out altering the core structure.
The aim is to not make the system good, however to make its failures managed, seen, and predictable.
That’s the distinction between a demo and a system you possibly can belief.
As soon as a semantic cache is deployed and begins reusing LLM responses, a brand new query instantly arises:
How lengthy ought to a cached response be trusted?
Not like conventional caches that retailer deterministic outputs, semantic caches retailer model-generated solutions. These solutions are solely legitimate inside a sure window of time and context. With out specific controls, a semantic cache can proceed serving responses which are technically legitimate however virtually improper.
This part explains why cached LLM responses grow to be stale, how TTLs assist, and what it means for a cache entry to be unsafe.
Why Cached LLM Responses Develop into Stale
LLM responses are usually not timeless.
They’re influenced by:
evolving APIs and libraries
altering enterprise logic or documentation
up to date prompts or system habits
newly launched edge circumstances
A cached reply that was appropriate an hour in the past might now not replicate the present state of the world.
Semantic caching amplifies this danger as a result of:
responses are reused aggressively
excessive similarity can masks outdated content material
cached solutions are returned with confidence
With out staleness controls, the cache slowly turns into a museum of outdated truths.
TTL as a Security Mechanism
A time-to-live (TTL) specifies how lengthy a cache entry stays legitimate.
As soon as the TTL expires:
the entry is handled as unsafe
it ought to now not be reused
a recent LLM response have to be generated
TTL doesn’t assure correctness, however it limits the blast radius of staleness.
In semantic caching, TTL just isn’t an optimization. It’s a correctness safeguard.
Software-Stage TTL vs Redis: EXPIRE
There are 2 frequent methods to implement TTLs when utilizing Redis:
Redis EXPIRE
Redis routinely deletes keys after a set period
Expired entries are eliminated totally
The appliance has no visibility into expired knowledge
Software-Stage TTL (Used Right here)
Entries stay saved in Redis
Expiration is checked at learn time by the appliance
The appliance decides whether or not an entry is secure to reuse
On this system, TTL is enforced on the utility layer relatively than utilizing Redis TTL by way of the native EXPIRE command, a deliberate selection that prioritizes observability over automation.
This selection permits us to:
examine expired entries throughout debugging
apply customized expiration logic
mix TTL with different security alerts (similar to confidence)
We commerce computerized deletion for management and observability.
When a Cache Entry Turns into Unsafe
On this system, a cache entry is taken into account unsafe when any of the next are true:
its TTL has expired
its content material is malformed or inaccurate
its confidence rating falls beneath an appropriate threshold
TTL is the primary and most elementary of those checks.
If an entry fails the TTL test, semantic similarity is irrelevant.
Reusing it could prioritize velocity over correctness.
Designing TTLs for LLM Workloads
There is no such thing as a common “appropriate” TTL for LLM responses.
As a substitute, TTLs needs to be chosen primarily based on:
how briskly the underlying data modifications
how expensive incorrect solutions are
how continuously related queries seem
Quick TTLs:
cut back staleness danger
improve LLM calls
Lengthy TTLs:
enhance cache hit price
improve danger of outdated responses
In Lesson 1, we used a conservative default TTL to maintain habits predictable. On this lesson, we’ll give attention to how TTLs are enforced relatively than on tuning them for a selected area.
TTL design is a coverage resolution. TTL enforcement is a correctness requirement.
Would you want fast entry to three,457 photographs curated and labeled with hand gestures to coach, discover, and experiment with … totally free? Head over to Roboflow and get a free account to seize these hand gesture photographs.
Want Assist Configuring Your Improvement Surroundings?
Having hassle configuring your improvement surroundings? Need entry to pre-configured Jupyter Notebooks working on Google Colab? You’ll want to be a part of PyImageSearch College — you’ll be up and working with this tutorial in a matter of minutes.
All that mentioned, are you:
Quick on time?
Studying in your employer’s administratively locked system?
Eager to skip the effort of preventing with the command line, package deal managers, and digital environments?
Able to run the code instantly in your Home windows, macOS, or Linux system?
Achieve entry to Jupyter Notebooks for this tutorial and different PyImageSearch guides pre-configured to run on Google Colab’s ecosystem proper in your internet browser! No set up required.
And better of all, these Jupyter Notebooks will run on Home windows, macOS, and Linux!
Earlier than diving into particular person parts, let’s take a second to know how the challenge is organized.
A transparent listing construction is particularly essential in LLM-backed programs, the place obligations span API orchestration, caching, embeddings, mannequin calls, and observability. On this challenge, every concern is remoted into its personal module so the request circulate stays simple to hint and cause about.
After downloading the supply code from the “Downloads” part, your listing construction ought to appear to be this:
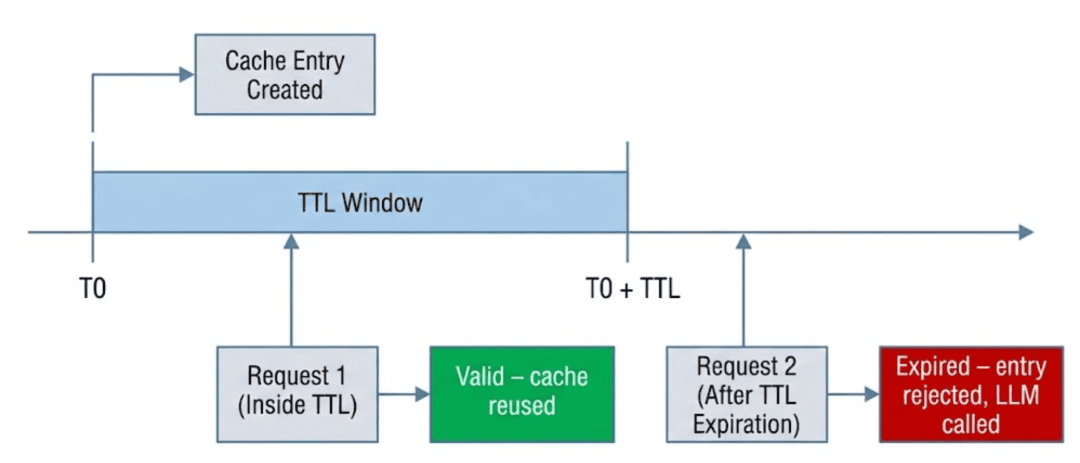
Within the earlier part, we mentioned why cached LLM responses grow to be stale and why TTLs are essential. On this part, we transfer from idea to code and have a look at how TTL validation is enforced in apply.
The important thing thought is straightforward however essential:
Cache entries are usually not deleted routinely. They’re validated at learn time.
This design selection retains cache habits specific, observable, and secure.
The Default TTL Configuration
TTL configuration is centralized in a single helper operate:
Reasonably than hardcoding a price, the TTL is loaded from configuration. This permits totally different environments to make use of totally different TTLs with out altering the code.
At this stage, the particular TTL worth just isn’t essential. What issues is that:
each cache entry receives a TTL at creation time
TTL is handled as metadata, not as a Redis function
Checking Whether or not an Entry Has Expired
TTL enforcement occurs by way of a devoted validation operate:
Is that this cache entry nonetheless secure to reuse?
If the present time exceeds created_at + ttl, the entry is taken into account expired and should not be reused.
Fail-Protected Expiration Conduct
Discover the exception dealing with on the finish of is_expired().
If the entry:
is lacking required fields
comprises malformed values
can’t be parsed safely
…it’s handled as expired by default.
This can be a deliberate fail-safe design.
When coping with cached LLM responses, silently trusting malformed knowledge is extra harmful than recomputing a response. If the system is uncertain, it expires the entry and falls again to the LLM.
Correctness all the time wins over reuse.
Determine 1: Software-level TTL validation for semantic cache entries. Cached responses are reused solely inside their TTL window and are rejected at learn time as soon as expired (supply: picture by the writer).
Finest-Effort Cleanup Throughout Cache Reads
TTL validation does greater than reject expired entries — it additionally performs opportunistic cleanup throughout cache searches.
Contained in the semantic cache search logic:
expired entries are detected
expired keys are faraway from Redis
the cache continues scanning remaining entries
This cleanup occurs:
with out background staff
with out scheduled jobs
with out blocking the request
This isn’t a full rubbish collector. It’s a best-effort hygiene mechanism that retains the cache from accumulating junk over time.
Why We Validate on Learn, Not Delete on Write
At this level, a pure query arises:
Why not simply use Redis EXPIRE and let Redis delete entries routinely?
There are 3 causes this technique validates TTLs on learn as an alternative:
Visibility: Expired entries stay inspectable throughout debugging.
Management: The appliance decides what “expired” means, not Redis.
Composability: TTL checks could be mixed with confidence scoring, poisoning detection, and different security alerts.
By validating at learn time, TTL turns into a part of the decision-making pipeline relatively than an invisible background mechanism.
Up thus far, semantic caching choices have relied closely on semantic similarity. If a cached response is analogous sufficient to a brand new question, it feels affordable to reuse it.
In apply, this assumption breaks down.
Excessive similarity solutions an essential query — “Is that this response about the identical factor?” — however it does not reply an equally essential one:
“Is that this response nonetheless secure to reuse proper now?”
Confidence scoring exists to bridge that hole.
Why Excessive Similarity Can Nonetheless Be Fallacious
Semantic similarity measures closeness in which means, not correctness over time.
Think about a cached response that:
has very excessive embedding similarity to the present question
was generated hours or days in the past
refers to data that has since modified
From a vector perspective, the response nonetheless seems “appropriate.”
From a system perspective, it could now not be reliable.
This downside is delicate as a result of:
similarity scores stay excessive
responses look fluent and assured
failures are silent relatively than catastrophic
With out an extra sign, the cache has no approach to distinguish related however stale from related and secure.
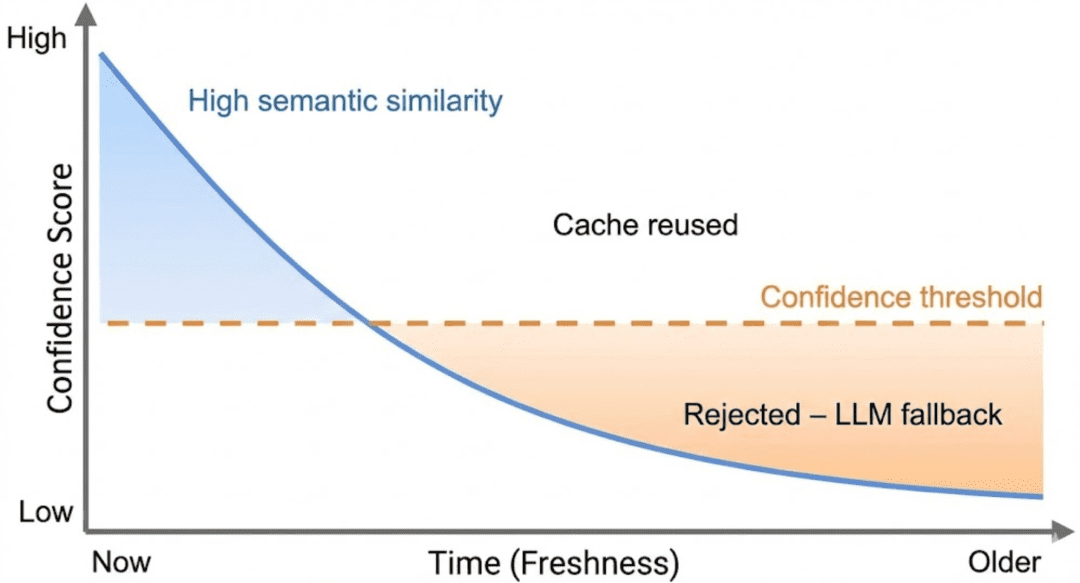
Combining Semantic Similarity with Freshness
Confidence scoring introduces a second dimension: freshness.
Reasonably than deciding reuse primarily based on similarity alone, the cache evaluates a mixed sign that displays:
how semantically shut the response is
how just lately the response was generated
At a excessive degree, confidence solutions the query:
“How snug are we reusing this response proper now?”
Contemporary responses with excessive similarity rating excessive confidence.
Outdated responses, even with excessive similarity, step by step lose confidence as they age.
This ensures that point acts as a pure decay mechanism.
Determine 2: Confidence scoring combines semantic similarity with freshness. Even extremely related cached responses lose confidence over time and are finally rejected (supply: picture by the writer).
Understanding the Confidence Rating (Excessive-Stage)
On this system, confidence is a weighted mixture of:
semantic similarity
freshness relative to TTL
You do not want to consider precise formulation at this stage. What issues is the habits:
Confidence begins excessive when an entry is created
Confidence decreases because the entry ages
Confidence is capped by semantic similarity
Expired entries all the time fail confidence checks
Confidence just isn’t a chance. It’s a reuse heuristic designed to favor correctness over velocity.
How Confidence Impacts Cache Reuse Selections
Confidence scoring acts as a gatekeeper within the cache pipeline.
Even when:
the entry just isn’t expired
the semantic similarity is above threshold
…the cache will reject reuse if confidence falls beneath an appropriate degree.
When this occurs:
the cache treats the entry as unsafe
the request falls again to the LLM
a recent response is generated and saved
This habits ensures that the cache degrades gracefully.
As uncertainty will increase, the system routinely shifts work again to the LLM relatively than returning questionable outcomes.
Why Confidence Belongs within the Cache (Not the LLM)
It’s tempting to push this logic downstream and let the LLM “repair” stale responses.
That method fails for 2 causes:
the LLM has no context about cache age
the LLM can not distinguish reused content material from recent inference
Confidence have to be enforced earlier than reuse, not after technology.
By embedding confidence checks instantly into the cache, we be certain that reuse choices are specific, explainable, and controllable.
Within the earlier part, we launched confidence scoring as a conceptual safeguard: a approach to stop semantically related however stale responses from being reused.
On this part, we make that concept concrete by implementing it.
We are going to stroll by way of the place confidence is computed, the place it’s enforced, and what occurs when a cached entry is rejected.
The place Confidence Is Computed
Confidence is computed contained in the semantic cache, alongside similarity scoring.
At this level, our semantic cache is secure towards stale and low-confidence responses. Nevertheless, there may be one other failure mode that seems as soon as the system runs for longer durations of time:
The cache slowly fills with duplicate entriescharacterizeing the identical question.
This downside doesn’t break correctness, however it might probably silently degrade cache high quality and effectivity.
Why Duplicate Cache Entries Are a Downside
In pure language programs, customers not often sort queries the identical manner twice.
Think about the next inputs:
What’s semantic caching?
What’s semantic caching
What is semantic caching?
From a human perspective, these queries are an identical.
From a naïve cache’s perspective, they’re fully totally different strings.
If we retailer every variation individually:
cache dimension grows unnecessarily
similarity scans grow to be slower
cache hit price decreases
an identical LLM work is repeated
This isn’t a semantic downside — it’s a normalization downside.
Normalizing Queries Earlier than Caching
To stop this, the cache normalizes queries earlier than storing them.
def _hash_query(question: str) -> str:
normalized = " ".be a part of(question.decrease().cut up())
return hashlib.sha256(normalized.encode()).hexdigest()
This operate performs 3 essential steps:
Lowercasing: Ensures case-insensitive matching
Whitespace normalization: Collapses further areas and removes main/trailing whitespace
Hashing: Produces a fixed-length identifier for quick comparability
The result’s a steady illustration of the question’s construction, not its formatting.
Deduplication at Retailer Time
Deduplication occurs when a brand new cache entry is about to be written.
query_hash = self._hash_query(question)
for key in self.r.smembers(f"{self.namespace}:keys"):
knowledge = self.r.hgetall(key)
if knowledge and knowledge.get("query_hash") == query_hash:
return
Earlier than storing a brand new entry, the cache checks whether or not an entry with the identical normalized hash already exists within the cache.
If it does:
the brand new entry is not saved
the cache avoids creating a replica
cupboard space and future scans are preserved
This method ensures that an identical queries map to a single cache entry, no matter how they had been formatted.
Why Deduplication Occurs within the Cache Layer
Deduplication is enforced contained in the cache relatively than within the API layer.
This design ensures:
all cache writes are normalized persistently
deduplication logic lives subsequent to storage logic
API code stays easy and declarative
The API doesn’t have to care how deduplication works — solely that the cache stays clear.
Why Hash-Primarily based Deduplication Works Effectively Right here
Utilizing a hash as an alternative of uncooked strings gives a number of benefits:
fixed-length comparisons
environment friendly storage
no dependency on question size
sensible collision resistance
For this technique, SHA-256 is greater than adequate. The aim is stability and ease, not cryptographic safety.
What Deduplication Does Not Resolve
It’s essential to know the bounds of this method.
Hash-based deduplication:
prevents precise duplicates after normalization
does not merge semantically related queries
does not exchange semantic caching
In different phrases:
deduplication retains the cache clear
semantic similarity retains the cache helpful
They resolve totally different issues and complement one another.
To this point, we’ve protected the semantic cache towards staleness, low confidence, and duplicate entries. There may be yet another failure mode that may silently undermine the complete system if left unchecked:
Cache poisoning — storing responses that ought to by no means be reused.
Cache poisoning doesn’t often crash the system. As a substitute, it causes the cache to confidently serve unhealthy solutions repeatedly, amplifying a single failure into many incorrect responses.
What Cache Poisoning Seems to be Like in LLM Programs
Within the context of LLM-backed programs, cache poisoning sometimes occurs when:
the LLM returns an error message
the response is empty or incomplete
the output is malformed resulting from a timeout or partial technology
If these responses are cached, each future “hit” returns the identical failure immediately — quick, however incorrect.
That is particularly harmful as a result of:
the cache seems to be working
responses are returned rapidly
the system seems wholesome from the skin
Poisoning Prevention Technique
Reasonably than making an attempt to detect each attainable unhealthy response, this technique makes use of a easy, conservative heuristic:
If a response seems unsafe, don’t cache it.
This retains the logic simple to cause about and avoids false positives.
Detecting Poisoned Entries
Poisoning detection is applied in a devoted helper operate.
def is_poisoned(entry):
resp = entry.get("response", "")
if not resp or resp.startswith("[LLM Error]"):
return True
return False
This operate flags an entry as poisoned if:
the response is empty, or
the response is an specific LLM error
These situations are deliberately strict. When doubtful, the entry is handled as unsafe.
The place Poisoning Is Enforced
Poisoning checks are utilized earlier than any cached response is reused in ask.py.
This demonstrates that semantic reuse is allowed when each relevance and freshness stay acceptable.
Demo Case 3: Failed LLM Responses Are By no means Cached
A secure semantic cache should be certain that failed LLM responses are by no means reused. This demo demonstrates write-time cache poisoning prevention.
This method enforces that rule at write time.
if not response.startswith("[LLM Error]"):
cache.retailer(...)
Solely legitimate responses are ever written to Redis.
How We Display This
We don’t shut down Ollama or the embedding service.
Community failures abort the request earlier than caching logic runs and are usually not appropriate demos.
As a substitute, we simulate an LLM failure.
Step 1: Briefly Simulate an LLM Error
In generate_llm_response():
if "simulate_error" in immediate.decrease():
return "[LLM Error] Simulated failure"
Step 2: Ship a Question
curl -X POST http://localhost:8000/ask
-H "Content material-Sort: utility/json"
-d '{"question": "Simulate error in semantic caching"}'
Anticipated Conduct
from_cache = false
Cache miss
Error response returned
Step 3: Ship the Identical Question Once more
Anticipated Outcome
Cache miss once more
LLM known as once more
No cached response reused
Why the Miss Cause Is no_match
Failed responses are by no means saved
No cache entry exists to reject or consider
Cache poisoning checks apply solely to present entries
That is intentional and proper.
Demo Case 4: Deduplication Underneath Question Variations
Ship a question with uncommon spacing:
curl -X POST http://localhost:8000/ask
-H "Content material-Sort: utility/json"
-d '{"question": " What is semantic caching? "}'
By this level, we’ve constructed a semantic cache that’s not solely useful, but additionally hardened towards frequent failure modes: staleness, low confidence, poisoning, duplication, and silent reuse.
Nevertheless, no system design is full with out clearly stating what it doesn’t try to unravel.
This part makes these boundaries specific.
Why This Cache Nonetheless Makes use of O(N) Scans
All semantic lookups on this implementation carry out a linear scan over cached entries.
Which means:
each semantic search compares the question embedding towards all saved embeddings
time complexity grows linearly with cache dimension
This isn’t an oversight.
It’s a deliberate design selection made for:
instructing readability
transparency
small-to-medium cache sizes
By avoiding ANN indexes or vector databases, each resolution stays seen and debuggable. You’ll be able to hint precisely why a match was chosen or rejected.
For instructional programs and low-volume providers, this trade-off is appropriate — and sometimes fascinating.
What We Deliberately Did Not Implement
To maintain the system centered and comprehensible, a number of manufacturing options had been deliberately disregarded:
Approximate nearest neighbor (ANN) indexing
Redis Vector Search or RediSearch
Background rubbish assortment staff
Distributed locks for thundering herd prevention
Request coalescing or single-flight patterns
Multi-process or persistent metrics
Cache warming methods
Every of those provides complexity that will obscure the core concepts being taught.
This cache is designed to clarify semantic caching, to not compete with specialised retrieval infrastructure.
When This Design Is “Good Sufficient”
This structure works effectively when:
cache dimension is modest (a whole bunch to low 1000’s of entries)
site visitors is low to reasonable
correctness and explainability matter greater than uncooked throughput
you might be experimenting with semantic reuse habits
you wish to perceive cache dynamics earlier than scaling
Typical examples embrace:
inside instruments
developer-facing APIs
analysis prototypes
instructional programs
early-stage LLM purposes
In these contexts, the simplicity of the design is a energy, not a weak point.
When You Want a Vector Database or ANN Index
As utilization grows, linear scans finally grow to be the bottleneck.
You need to think about a devoted vector search resolution when:
cache dimension grows into tens or a whole bunch of 1000’s of entries
latency necessities grow to be strict
a number of staff or providers share the identical cache
semantic search dominates request time
At that time, applied sciences similar to the next:
FAISS (Fb AI Similarity Search)
Milvus
Pinecone
Redis Vector Search
grow to be acceptable.
Importantly, the hardening ideas from this lesson nonetheless apply. TTLs, confidence scoring, poisoning prevention, and observability stay related even when the storage backend modifications.
The Core Commerce-Off, Revisited
This lesson intentionally favors:
readability over cleverness
specific choices over hidden automation
security over aggressive reuse
That makes it a great basis, not a ultimate vacation spot.
Course data:
86+ whole lessons • 115+ hours hours of on-demand code walkthrough movies • Final up to date: Could 2026 ★★★★★ 4.84 (128 Rankings) • 16,000+ College students Enrolled
I strongly imagine that in case you had the precise trainer you can grasp laptop imaginative and prescient and deep studying.
Do you assume studying laptop imaginative and prescient and deep studying must be time-consuming, overwhelming, and sophisticated? Or has to contain complicated arithmetic and equations? Or requires a level in laptop science?
That’s not the case.
All that you must grasp laptop imaginative and prescient and deep studying is for somebody to elucidate issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter training and the way complicated Synthetic Intelligence subjects are taught.
When you’re critical about studying laptop imaginative and prescient, your subsequent cease needs to be PyImageSearch College, essentially the most complete laptop imaginative and prescient, deep studying, and OpenCV course on-line immediately. Right here you’ll learn to efficiently and confidently apply laptop imaginative and prescient to your work, analysis, and initiatives. Be part of me in laptop imaginative and prescient mastery.
Inside PyImageSearch College you will discover:
&test; 86+ programs on important laptop imaginative and prescient, deep studying, and OpenCV subjects
&test; 86 Certificates of Completion
&test; 115+ hours hours of on-demand video
&test; Model new programs launched frequently, making certain you possibly can sustain with state-of-the-art strategies
&test; Pre-configured Jupyter Notebooks in Google Colab
&test; Run all code examples in your internet browser — works on Home windows, macOS, and Linux (no dev surroundings configuration required!)
&test; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
&test; Simple one-click downloads for code, datasets, pre-trained fashions, and so on.
&test; Entry on cellular, laptop computer, desktop, and so on.
On this lesson, we took a working semantic cache and made it secure, bounded, and explainable.
Reasonably than specializing in enhancing cache hit charges in any respect prices, we launched guardrails to make sure cached LLM responses are reused solely when they’re reliable.
We added application-level TTL validation to forestall stale responses from persisting indefinitely, mixed semantic similarity with freshness by way of confidence scoring, and enforced specific rejection paths for low-confidence and expired entries.
We additionally addressed delicate however harmful failure modes that seem in actual programs over time. Question normalization and deduplication stop silent cache bloat, and poisoning checks be certain that error responses are by no means reused.
Observability alerts make each cache resolution inspectable relatively than implicit. Collectively, these modifications rework the cache from a efficiency optimization right into a reliability element.
Lastly, we made the system’s limitations specific. This design favors readability, correctness, and debuggability over uncooked scalability. It intentionally avoids ANN indexes, vector databases, and distributed coordination, making it appropriate for small-to-medium programs and academic use circumstances.
As workloads develop, the identical hardening ideas apply even when the underlying storage or retrieval technique modifications.
With this lesson, semantic caching is now not simply quick. It’s defensive, explainable, and production-aware.
Quotation Data
Singh, V. “Semantic Caching for LLMs: TTLs, Confidence, and Cache Security,” PyImageSearch, S. Huot, A. Sharma, and P. Thakur, eds., 2026, https://pyimg.co/ahr3p
@incollection{Singh_2026_semantic-caching-llms-ttls-confidence-cache-safety,
writer = {Vikram Singh},
title = {{Semantic Caching for LLMs: TTLs, Confidence, and Cache Security}},
booktitle = {PyImageSearch},
editor = {Susan Huot and Aditya Sharma and Piyush Thakur},
12 months = {2026},
url = {https://pyimg.co/ahr3p},
}
To obtain the supply code to this put up (and be notified when future tutorials are revealed right here on PyImageSearch), merely enter your electronic mail handle within the kind beneath!
Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your electronic mail handle beneath to get a .zip of the code and a FREE 17-page Useful resource Information on Pc Imaginative and prescient, OpenCV, and Deep Studying. Inside you will discover my hand-picked tutorials, books, programs, and libraries that will help you grasp CV and DL!
The kerasformula bundle presents a high-level interface for the R interface to Keras. It’s fundamental interface is the kms operate, a regression-style interface to keras_model_sequential that makes use of formulation and sparse matrices.
The kerasformula bundle is accessible on CRAN, and may be put in with:
# set up the kerasformula bundleset up.packages("kerasformula")# or devtools::install_github("rdrr1990/kerasformula")library(kerasformula)# set up the core keras library (if you have not already performed so)# see ?install_keras() for choices e.g. install_keras(tensorflow = "gpu")install_keras()
The kms() operate
Many basic machine studying tutorials assume that knowledge are available in a comparatively homogenous kind (e.g., pixels for digit recognition or phrase counts or ranks) which might make coding considerably cumbersome when knowledge is contained in a heterogenous knowledge body. kms() takes benefit of the flexibleness of R formulation to easy this course of.
kms builds dense neural nets and, after becoming them, returns a single object with predictions, measures of match, and particulars concerning the operate name. kms accepts a variety of parameters together with the loss and activation capabilities present in keras. kms additionally accepts compiled keras_model_sequential objects permitting for even additional customization. This little demo reveals how kms can support is mannequin constructing and hyperparameter choice (e.g., batch dimension) beginning with uncooked knowledge gathered utilizing library(rtweet).
Let’s take a look at #rstats tweets (excluding retweets) for a six-day interval ending January 24, 2018 at 10:40. This occurs to present us a pleasant affordable variety of observations to work with when it comes to runtime (and the aim of this doc is to point out syntax, not construct notably predictive fashions).
rstats<-search_tweets("#rstats", n =10000, include_rts =FALSE)dim(rstats)
[1] 2840 42
Suppose our purpose is to foretell how in style tweets will likely be based mostly on how typically the tweet was retweeted and favorited (which correlate strongly).
Since few tweeets go viral, the information are fairly skewed in direction of zero.
Getting probably the most out of formulation
Let’s suppose we’re concerned about placing tweets into classes based mostly on recognition however we’re undecided how finely-grained we need to make distinctions. A number of the knowledge, like rstats$mentions_screen_name is available in an inventory of various lengths, so let’s write a helper operate to depend non-NA entries.
Let’s begin with a dense neural web, the default of kms. We are able to use base R capabilities to assist clear the information–on this case, reduce to discretize the result, grepl to search for key phrases, and weekdays and format to seize completely different features of the time the tweet was posted.
The mannequin solely classifies about 55% of the out-of-sample knowledge accurately and that predictive accuracy doesn’t enhance after the primary ten epochs. The confusion matrix means that mannequin does greatest with tweets which are retweeted a handful of occasions however overpredicts the 1-10 degree. The historical past plot additionally means that out-of-sample accuracy just isn’t very secure. We are able to simply change the breakpoints and variety of epochs.
Right here we use paste0 so as to add to the components by looping over person IDs including one thing like:
grepl("12233344455556", mentions_user_id)
mentions<-unlist(rstats$mentions_user_id)mentions<-distinctive(mentions[which(table(mentions)>5)])# take away rarementions<-mentions[!is.na(mentions)]# drop NAfor(iinmentions)pop_input<-paste0(pop_input, " + ", "grepl(", i, ", mentions_user_id)")recognition<-kms(pop_input, rstats)
That helped a contact however the predictive accuracy continues to be pretty unstable throughout epochs…
Customizing layers with kms()
We may add extra knowledge, maybe add particular person phrases from the textual content or another abstract stat (imply(textual content %in% LETTERS) to see if all caps explains recognition). However let’s alter the neural web.
The enter.components is used to create a sparse mannequin matrix. For instance, rstats$supply (Twitter or Twitter-client software sort) and rstats$screen_name are character vectors that will likely be dummied out. What number of columns does it have?
[1] 1277
Say we needed to reshape the layers to transition extra steadily from the enter form to the output.
kms builds a keras_sequential_model(), which is a stack of linear layers. The enter form is decided by the dimensionality of the mannequin matrix (recognition$P) however after that customers are free to find out the variety of layers and so forth. The kms argument layers expects an inventory, the primary entry of which is a vector items with which to name keras::layer_dense(). The primary ingredient the variety of items within the first layer, the second ingredient for the second layer, and so forth (NA as the ultimate ingredient connotes to auto-detect the ultimate variety of items based mostly on the noticed variety of outcomes). activation can be handed to layer_dense() and should take values similar to softmax, relu, elu, and linear. (kms additionally has a separate parameter to manage the optimizer; by default kms(... optimizer="rms_prop").) The dropout that follows every dense layer fee prevents overfitting (however after all isn’t relevant to the ultimate layer).
Selecting a Batch Measurement
By default, kms makes use of batches of 32. Suppose we had been pleased with our mannequin however didn’t have any explicit instinct about what the dimensions ought to be.
For the sake of curbing runtime, the variety of epochs was set arbitrarily brief however, from these outcomes, 64 is the most effective batch dimension.
Making predictions for brand new knowledge
Up to now, we’ve been utilizing the default settings for kms which first splits knowledge into 80% coaching and 20% testing. Of the 80% coaching, a sure portion is put aside for validation and that’s what produces the epoch-by-epoch graphs of loss and accuracy. The 20% is simply used on the finish to evaluate predictive accuracy.
However suppose you needed to make predictions on a brand new knowledge set…
As a result of the components creates a dummy variable for every display title and point out, any given set of tweets is all however assured to have completely different columns. predict.kms_fit is an S3 methodology that takes the brand new knowledge and constructs a (sparse) mannequin matrix that preserves the unique construction of the coaching matrix. predict then returns the predictions together with a confusion matrix and accuracy rating.
In case your newdata has the identical noticed ranges of y and columns of x_train (the mannequin matrix), you may also use keras::predict_classes on object$mannequin.
Utilizing a compiled Keras mannequin
This part reveals the way to enter a mannequin compiled within the style typical to library(keras), which is helpful for extra superior fashions. Right here is an instance for lstm analogous to the imbd with Keras instance.
ok<-keras_model_sequential()ok%>%layer_embedding(input_dim =recognition$P, output_dim =recognition$P)%>%layer_lstm(items =512, dropout =0.4, recurrent_dropout =0.2)%>%layer_dense(items =256, activation ="relu")%>%layer_dropout(0.3)%>%layer_dense(items =8, # variety of ranges noticed on y (end result) activation ='sigmoid')ok%>%compile( loss ='categorical_crossentropy', optimizer ='rmsprop', metrics =c('accuracy'))popularity_lstm<-kms(pop_input, rstats, ok)
Drop me a line by way of the undertaking’s Github repo. Particular because of @dfalbel and @jjallaire for useful options!!
Let’s face it: One other child increase isn’t coming anytime quickly.
The newest spherical of US start knowledge, launched earlier this month by the Facilities for Illness Management and Prevention, present the final fertility fee has dropped to a brand new document low of 53.1 per 1,000 females between 15 and 44 — a 23 p.c lower since the latest peak in 2007.
It’s the most recent knowledge level in an extended international development towards fewer youngsters, which suggests our already getting old populace will get even older over time, with fewer younger staff to deal with the financial system and care for the aged of their twilight years. About one in eight People have been over the age of 65 on the flip of the millennium; by 2040, it is going to be practically one in 5.
The actual fact is, nevertheless, that the development traces are unlikely to reverse no matter one’s most popular clarification.
It’s doable to arrange for a nation — and a world — with fewer youngsters that’s each useful and nice to stay in.
No low-birth nation on the planet, from essentially the most repressive misogynistic regimes to essentially the most progressive governments providing beneficiant go away and free childcare, has been capable of put their society on a path again to “alternative degree” fertility. Establishing the enabling circumstances so individuals can kind the households they need is a worthy aim deserving consideration, however the hour grows late and it’s time to begin speaking significantly about the way to adapt for an getting old, low-birth society.
We are able to’t get any youthful as a society however we will attempt to get wiser with age. With a bit foresight, it’s doable to arrange for a nation — and a world — with fewer youngsters that’s each useful and nice to stay in.
It gained’t occur by itself, although. America wants a national-level effort to futureproof the nation towards demographic adjustments, with all of the bodily, financial, political, and cultural shifts that may entail.
Such an effort doesn’t solely have to come back from the federal authorities (which is, at current, hardly a paragon of forward-thinking performance), however will must be led by authorities at each degree alongside the personal sector, non secular establishments, group teams, and people. And it begins with a troublesome acknowledgement: We’re not going to keep away from this coming disaster.
How a lot older are we going to get?
Demographics, importantly, are formed by extra than simply the start fee. Understanding the exact nation we’re heading towards will assist us higher perceive the options.
On the whole, a rustic’s inhabitants profile has three elements: births, deaths, and the way many individuals are in every age band. As America heads towards the 2030s and past, its outlook is marked by the mix of record-low births, a record-sized cohort of older residents, and people older individuals having record-long lifespans.
It’s excellent news, after all, that persons are residing longer, more healthy lives due to advances in medical science and improved life-style habits. Nevertheless it means the older individuals who do make up our inhabitants can be more and more out of the workforce and in want of extra acute care. By 2040, the variety of People 85 or older can have greater than tripledfrom 2000. Come 2055, People over 85 are projected to outnumber youngsters below the age of 5.
One choice is to easily add extra younger individuals by way of immigration to work and lift households right here, which has helped America dodge this demographic cliff for many years. However immigration has stagnated below the Trump administration, and it’s not clear these political constraints will go away anytime quickly. Even when immigration can function a short-term salve, it’s not a long-term answer in a world the place greater than three-quarters of nations are projected to have below-replacement-level fertility charges by 2050.
There are methods to age gracefully
To see what demographic adaptation can seem like, take into account colleges. Faculties face a confluence of challenges: Shrinking enrollments imply much less income whilst mounted prices like constructing upkeep keep the identical. On the similar time, shrinking tax bases (seniors in most states, for example, get property tax exemptions, and property taxes are a key supply of faculty funding) improve budgetary pressures.
When colleges shut with out a plan, they’ll develop into drains on municipal assets and hubs for crime, just like the deserted homes and buildings in post-industrial neighborhoods that shed inhabitants in prior generations. In Gary, Indiana, a 2025 investigation discovered that 28 deserted college services had drawn over 1,800 calls to 911 over a five-year interval. A number of have been the scenes of murders.
But the USA needn’t merely march right into a future with scores of empty, crime-ridden college buildings. College funding formulation might be revised so that they rely much less closely on per-pupil funding and take into account a broader set of operational wants. Youthful youngsters may very well be folded in, eliminating the cut up between “childcare” and “schooling.” And as college consolidation turns into a necessity, the closing services might be transformed for different makes use of, for example aiding America’s elder care wants by providing extra grownup day applications.
In Japan, the place 1000’s of faculties have closed in latest many years on account of demographic adjustments, the nation had, in 2018, efficiently repurposed 75 p.c of them for makes use of starting from artwork galleries to lodgings to group cafeterias.
The bottom line is that adaptation efforts want to begin now. Almost each state has some type of a “local weather motion plan” that guides their response to environmental adjustments; they might be sensible to develop “demographic motion plans” that do the identical for inhabitants adjustments. As an example, retrofitting old skool buildings will not be a straightforward nor swift feat. When a wing of Chilly Springs Elementary College in Missoula, Montana, was transformed to deal with group daycare applications with a $414,000 grant, venture backers needed to increase one other $200,000 to get the method began.
Faculties are just one instance of demographic adaptation. America’s housing inventory is ill-prepared for an getting old inhabitants who can have problem getting round within the many inaccessible houses available on the market. One might envision a nationwide service corps devoted to upgrading homes with accessibility gadgets like ramps and loo bars that allow extra seniors to age in place. Easing rules round accent dwelling items might empower extra households to embrace multigenerational residing, if that’s their desired course. This can be a area ripe for innovation.
Neighborhoods themselves might want to evolve as a far larger share of the inhabitants crosses 80 and even 90 years previous whereas dad and mom discover themselves more and more remoted, that means that care wants will typically be mismatched with present social and constructed environments.
An increasing number of international locations, for instance, are experimenting with “care blocks.” Pioneered in Colombia, these are stretches of neighborhoods that present centralized companies particularly designed to assist moms: academic applications, well being and health courses like yoga, baby care, authorized assist, laundromats, and so forth. The mannequin may very well be scaled and expanded to incorporate elder care. Equally, community-focused meals halls — like Berlin’s Markthalle Nuen — may very well be adopted to be able to centralize meals manufacturing and create a convening area for these unable to prepare dinner a lot for themselves.
We have to rethink how we look after one another
Cultural adaptation can be wanted alongside bodily adaptation. Presently, People rely closely on relations to assist with each childcare and eldercare. As kin networks shrink — the decline in births imply not solely fewer children and grandkids, however fewer aunts, uncles, and cousins — there can be fewer out there to assist. This can be particularly troublesome for these within the “sandwich technology,” who’re taking good care of youngsters and getting old dad and mom concurrently.
Fixing this implies going towards the grain of our more and more remoted and atomized society and reviving a way of group past our quick households. People would do effectively to rediscover “alloparenting,” the concept individuals aside from dad and mom might be actively concerned within the elevating of kids.
Nonetheless, alloparenting will not be going to emerge broadly with out cultural technique of normalizing it. As the author Anne Helen Petersen has explored, constructing bonds between these with and with out youngsters requires intentionality. We have to present seen examples of neighbors serving to neighbors to assist make this type of conduct a brand new norm or expectation. Establishing new rituals can be necessary: for example, “deliver a household good friend to high school day.” The advantages don’t circulate solely to oldsters and kids — a wider internet of care relationships has the potential to be an antidote to America’s rising epidemic of loneliness and depersonalization.
The times of huge households might not be coming again, however steps to adapt to a low-birth, high-age period not solely might have broadly constructive results, they could, satirically, assist stanch the start fee decline. A society that’s hospitable to oldsters and kids, helps people pursue meaning-filled lives, and emphasizes ties of interdependence and care for an getting old inhabitants might be one wherein extra individuals wish to develop their households.
Only one insightful psychedelic journey can have a profound affect on an individual, and a brand new examine goes some solution to explaining why.
The analysis suggests a single dose of psilocybin (the psychedelic compound in ‘magic mushrooms’) that sufficiently ‘shakes up’ the mind’s tried-and-true patterns may enhance an individual’s psychological well-being for as much as a month after their journey.
Many research on the results of psilocybin have checked out teams receiving the drug for therapeutic causes.
As an alternative, this new work investigated how 28 wholesome contributors who had by no means tried psilocybin earlier than reacted to a 25 milligram dose, which is sufficient to elicit a robust psychedelic journey.
The outcomes might assist to elucidate among the enhancements seen in individuals with despair, dependancy, and anxiousness.
“We already knew psilocybin might be useful for treating psychological sickness,” says UC San Francisco (UCSF) neurologist Robin Carhart-Harris. “However now we’ve a a lot better understanding of how.”
Psilocybin is finest often called the lively compound in ‘magic mushrooms’. (Yarphoto/Getty Photographs)
Carhart-Harris and staff assessed the novice trippers’ experiences by way of a collection of psychological checks to gauge elements like cognitive flexibility, sense of well-being, and psychological insights gleaned throughout the journey.
EEG readings had been taken earlier than the journey, after which one, two, and 4 and a half hours into it.
In the meantime, fMRI and DTI readings had been taken earlier than the psilocybin session, after which one month after.
Individuals undertook two periods. They had been knowledgeable that with every session they might obtain a dose of psilocybin, however they would not know the way a lot.
Within the first session, all contributors got 1 milligram of psilocybin, which is low sufficient to be thought of a placebo. This was the management.
A month later, contributors got 25 milligrams in a second session. The identical psychological and neurological checks had been carried out within the preliminary part as throughout the full-dose replication, to assemble baseline knowledge.
As you’ll be able to think about, it was apparent to many contributors which session had included the drug, which considerably limits the findings.
However, the info revealed a hyperlink between a short lived uptick in mind entropy – a measure of how broadly the mind’s neural exercise varies – and psychological perception reported the next day.
Individuals with larger mind entropy below the affect of psilocybin, together with next-day psychological perception, additionally reported larger enhancements in psychological well-being one month post-trip.
“Our knowledge exhibits that such experiences of psychological perception relate to an entropic high quality of mind exercise and the way each are concerned in inflicting subsequent enhancements in psychological well being,” explains Carhart-Harris.
“It means that the journey – and its correlates within the mind – is a key element of how psychedelic remedy works.”
The expertise of perception seems significantly essential to the long-term results on well-being. Maybe this might assist docs hone the usage of psilocybin in a medical setting by additional investigating what dose and settings promote these deeper revelations.
Some researchers, nevertheless, query whether or not heightened mind entropy is a dependable marker of the psychedelic state. In a current essential evaluate, as an example, a global staff of neuroscientists means that this view might oversimplify issues. Their evaluate requires a extra nuanced understanding of how entropy pertains to the psychedelic expertise.
Carhart-Harris and staff additionally acknowledge of their report, “we might not have but found a sufficiently delicate assay for detecting (true) purposeful mind modifications post-psilocybin,” writing that additional work will probably be wanted to fill this hole.
However the truth that a single dose of a drug can have lasting results on subjective well-being – significantly when the journey itself entails bodily mind modifications that seem associated to subjective psychedelic expertise and next-day insights – is, as neuroscientist Taylor Lyons from Imperial School London says, “particularly thrilling.”
“Psilocybin appears to loosen up stereotyped patterns of mind exercise and provides individuals the power to revise entrenched patterns of thought,” says Lyons.
This week’s episode of “The Odd Couple” is simply Caitlin and Hannah as I needed to go to Georgetown to speak about Claude Code at a school retreat. However earlier than we get going with an outline, Hannah talked about at the beginning in the course of the ice breaker in regards to the opening theme music to the podcast, and for those who do not acknowledge the lyrics, that is Mac Miller’s “Small Worlds” sung by my two nephews.
So what is that this episode about? One of many themes I’ve been emphasizing in my talks on AI Brokers and my substack is that AI Brokers have triggered a separation between the historic bundling of the manufacturing of analysis and the verification of the outcomes. Since AI Brokers are actually in a position to produce so many features of the analysis mission autonomously — that’s with out a lot path from the human researcher — one of many new duties of the researcher is to confirm them.
Should you bear in mind from just a few weeks in the past, Claude Code had almost immediately labored up the county-level marriage knowledge right into a county panel of marriage charges and marriage counts by yr. We introduced Hannah Sayre, a current school graduate and present financial marketing consultant, into the mission to assist us work by the latter process of “human verification”. Had Claude finished it appropriately? How will we confirm that it’s appropriate? And if it’s not appropriate, why was it not appropriate, and the way generalizable is that inaccuracy? Hannah was our eyes and ears, our boots on the bottom, as she independently investigated the identical query, the identical process we gave Claude, to on the again find yourself assist us decide whether or not Claude had certainly discovered the identical irregularities within the unique marriage dataset, and if that’s the case, what autonomous choices had he made. And so on this episode, Hannah walks us by it, and he or she and Caitlin talk about each these findings, in addition to start the work of conceptualizing the method of verification in a world of AI Brokers. Whereas not definitive, it is a likelihood for others to listen to extra particularly about this. I a minimum of anticipate that every one of us must wrestle with verification going ahead in methods we weren’t anticipating, and possibly even are usually not ready for, a minimum of not universally, and undoubtedly not essentially if the truth is AI Brokers shrink the scale of the mission crew members on account of automation, and the way greatest to reply to that smaller scale, and subsequently, fewer individuals accessible to do the precise verification itself.
Thanks once more for tuning in! We hope you might be having as a lot enjoyable with this as we’re!
Multi-tool-integrated reasoning allows LLM-empowered tool-use brokers to unravel complicated duties by interleaving natural-language reasoning with calls to exterior instruments. Nevertheless, coaching such brokers utilizing outcome-only rewards suffers from credit-assignment ambiguity, obscuring which intermediate steps (or tool-use selections) result in success or failure. On this paper, we suggest PORTool, an importance-aware policy-optimization algorithm that reinforces brokers’ tool-use competence from outcome-level supervision whereas assigning reward on the step degree. Particularly, PORTool generates a rewarded rollout tree by which trajectories share prefixes earlier than branching, enabling direct comparisons amongst various tool-use selections inside the similar context. It then estimates every step’s significance by a correctness-dominant sign, i.e., whether or not descendants of that step can finally produce an accurate last reply, plus an auxiliary time period indicating whether or not the step’s device calls execute efficiently. Utilizing these step-wise significance estimates, PORTool updates the coverage to generate environment friendly tool-call steps, guided by each native comparisons inside every branching determination and the general high quality of whole trajectories. Experiments present that PORTool improves final-answer accuracy whereas lowering tool-call steps in contrast with state-of-the-art baselines, and ablation research affirm the robustness of the proposed step-wise significance estimates.



















{kind=link}