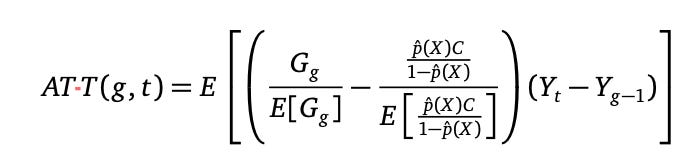Monitoring competitor costs is important for ecommerce groups to keep up a market edge. Nevertheless, many groups stay trapped in guide monitoring, losing hours every day checking particular person web sites. This inefficient strategy delays decision-making, raises operational prices, and dangers human errors that end in missed income and misplaced alternatives.
Amazon Nova Act is an open-source browser automation SDK used to construct clever brokers that may navigate web sites and extract information utilizing pure language directions. This publish demonstrates easy methods to construct an automatic aggressive worth intelligence system that streamlines guide workflows, supporting groups to make data-driven pricing choices with real-time market insights.
The hidden price of guide aggressive worth intelligence
Ecommerce groups want well timed and correct market information to remain aggressive. Conventional workflows are guide and error-prone, involving looking a number of competitor web sites for sure merchandise, recording pricing and promotional information, and consolidating this information into spreadsheets for evaluation. This course of presents a number of essential challenges:
Time and useful resource consumption: Handbook worth monitoring consumes hours of workers time each day, representing a big operational price that scales poorly as product catalogs develop.
Information high quality points: Handbook information entry introduces inconsistency and human error, doubtlessly resulting in incorrect pricing choices based mostly on flawed data.
Scalability limitations: As product catalogs increase, guide processes turn out to be more and more unsustainable, creating bottlenecks in aggressive evaluation.
Delayed insights: Essentially the most essential subject is timing. Competitor pricing can change quickly all through the day, which means choices made on stale information can lead to misplaced income or missed alternatives.
These challenges lengthen far past ecommerce. Insurance coverage suppliers routinely overview competitor insurance policies, inclusions, exclusions, and premium constructions to keep up market competitiveness. Monetary providers establishments analyze mortgage charges, bank card provides, and price constructions by time-consuming guide checks. Journey and hospitality companies monitor fluctuating costs for flights, lodging, and packages to regulate their choices dynamically. Whatever the trade, the identical struggles exist. Handbook analysis is gradual, labor-intensive, and susceptible to human error. In markets the place costs change by the hour, these delays make it nearly unattainable to remain aggressive.
Automating with Amazon Nova Act
Amazon Nova Act is an AWS service, with an accompanying SDK, designed to assist builders construct brokers that may act inside internet browsers. Builders construction their automations by composing smaller, focused instructions in Python, combining pure language directions for browser interactions with programmatic logic resembling checks, breakpoints, assertions, or thread-pooling for parallelization. By way of its software calling functionality, builders may allow API calls alongside browser actions. This provides groups full management over how their automations run and scale. Nova Act helps agentic commerce situations the place automated brokers deal with duties resembling aggressive monitoring, content material validation, catalogue updates, and multi-step searching workflows. Aggressive worth intelligence is a robust match as a result of the SDK is designed to deal with real-world web site conduct, together with format modifications and dynamic content material.
Ecommerce websites ceaselessly change layouts, run short-lived promotions, or rotate banners and elements. These shifts typically break conventional rules-based scripts that depend on mounted ingredient selectors or inflexible navigation paths. Nova Act’s versatile, pure language command-driven strategy helps brokers proceed working whilst pages evolve, offering the resilience wanted for manufacturing aggressive intelligence techniques.
Widespread constructing blocks
Nova Act features a set of constructing blocks that simplify browser automation. This can be utilized by ecommerce firms to gather and file product costs from web sites with out human intervention. The constructing blocks that allow this embody:
Extracting data from a webpage
With the extraction capabilities in Nova Act, brokers can collect structured information immediately from a rendered webpage. You’ll be able to outline a Pydantic mannequin that represents the schema that they need returned, then ask an act_get() name to reply a query in regards to the present browser web page utilizing that schema. This retains the extracted information strongly typed, validated, and prepared for downstream use.
Nova.act_get("Seek for 'iPad Professional 13-inch (M4 chip), 256GB Wi-Fi'.", schema=ProductData.model_json_schema())
Navigate to a webpage
This step redirects the agent to a particular webpage as a place to begin. A brand new browser session opens at a desired place to begin, enabling the agent to take actions or extract information.
nova.go_to_url(website_url)
Working a number of periods in parallel
Value intelligence workloads typically require checking dozens of competitor pages in a brief interval. A single Nova Act occasion can invoke just one browser at a time, however a number of cases can run concurrently. Every occasion is light-weight, making it sensible to spin up a number of in parallel and distribute work throughout them. This allows a map‑scale back fashion strategy to browser automation the place totally different Nova Act cases deal with separate duties on the similar time. By parallelizing searches or extraction work throughout many cases, organizations can scale back whole execution time and monitor massive product catalogs with minimal latency.
from concurrent.futures import ThreadPoolExecutor, as_completed
from nova_act import ActError, NovaAct
# Accumulate the whole record right here.
all_prices = []
# Set max staff to the max variety of lively browser periods.
with ThreadPoolExecutor(max_workers=10) as executor:
# Get all costs in parallel.
future_to_source = {
executor.submit(
check_source_price, product_name, source_name, source_url, headless
): source_name
for source_name, source_url in sources
}
# Gather the leads to all_books.
for future in as_completed(future_to_source.keys()):
strive:
supply = future_to_source[future]
source_price = future.end result()
if source_price is just not None:
all_prices.lengthen(source_price.supply)
besides ActError as exc:
print(f"Skipping supply worth attributable to error: {exc}")
print(f"Discovered {len(all_prices)} supply costs:n{all_books}")
Captchas
Some web sites current captchas throughout automated searching. For moral causes, we suggest involving a human to resolve captchas relatively than making an attempt automated options. Nova Act doesn’t resolve captchas on the person’s behalf.
When working Nova Act regionally, your workflow can use an act_get() name to detect whether or not a captcha is current. If one is detected, the workflow can pause and immediate the person to finish it manually, for instance, by calling enter() in a terminal-launched course of. To allow this, run your workflow in headed mode (set headless=False, which is the default) so the person can work together with the browser window immediately.
When deploying Nova Act workflows with AgentCore Browser Device (ACBT), you should utilize its built-in human-in-the-loop (HITL) capabilities. ACBT offers serverless browser infrastructure with stay streaming from the AgentCore AWS Console. When a captcha is encountered, a human operator can take over the browser session in real-time by the UI takeover function, resolve the problem, and return management to the Nova Act workflow.
end result = nova.act("Is there a captcha on the display?", schema=BOOL_SCHEMA) if end result.matches_schema and end result.parsed_response:
enter("Please resolve the captcha and hit return when executed")
...
Dealing with errors
As soon as the Nova Act shopper is began, it might encounter errors throughout an act() name. These points can come up from dynamic layouts, lacking parts, or surprising web page modifications. Nova Act surfaces these conditions as ActErrors in order that builders can catch them, retry operations, apply fallback logic, or log particulars for additional evaluation. This helps worth intelligence brokers keep away from silent failures and proceed working even when web sites behave unpredictably.
Constructing and Monitoring Nova Act workflows
Constructing with AI-powered IDEs
Builders constructing Nova Act automation workflows can speed up experimentation and prototyping through the use of AI-powered improvement environments with Nova Act IDE extensions. The extension is accessible for widespread IDEs together with Kiro, Visible Studio Code, and Cursor, bringing clever code era and context-aware help immediately into your most well-liked improvement surroundings. The IDE extension for Amazon Nova Act hurries up improvement by turning pure language prompts into production-ready code. As a substitute of digging by documentation or writing repetitive boilerplate, you may merely describe your automation targets. That is useful for advanced duties like aggressive worth intelligence, the place the extension will help you shortly construction ThreadPoolExecutor logic, design Pydantic schemas, and construct sturdy error dealing with.
Observing workflows within the Nova Act console
The Nova Act AWS console offers visibility into your workflow execution with detailed traces and artifacts out of your AWS surroundings through the AWS Administration Console. It offers a central place to handle and monitor automation workflows in real-time. You’ll be able to navigate from a high-level view of the workflow runs into the particular particulars of particular person periods, acts, and steps. This visibility lets you debug and analyze efficiency by exhibiting you precisely how the agent makes choices and executes loops. With direct entry to screenshots, logs, and information saved in Amazon S3, you may troubleshoot points shortly with out switching between totally different instruments. This streamlines the troubleshooting course of and accelerates the iteration cycle from experimentation to manufacturing deployment.
Working the answer
That can assist you get began with automated market analysis, we’ve launched a Python-based pattern challenge that handles the heavy lifting of worth monitoring. This resolution makes use of Amazon Nova Act to launch a number of browser periods directly, looking for merchandise throughout numerous competitor websites concurrently. As a substitute of going by tabs your self, the script navigates the online to seek out costs and promotions. It then gathers all the things right into a clear, structured format so you should utilize it in your individual pricing fashions. The next sections will describe how one can get began constructing the aggressive worth intelligence agent. After exploring, you may deploy to AWS and monitor your workflows within the AWS Administration Console.
The aggressive worth intelligence agent is accessible as an AWS Samples resolution within the Amazon Nova Samples GitHub repository as a part of the Value Comparability use case.
1. Stipulations
Your improvement surroundings should embody: Python: 3.10 or later and the Nova Act SDK.
2. Get Nova Act API key:
Navigate to https://nova.amazon.com/act and generate an API key. When utilizing the Nova Act Playground or selecting Nova Act developer instruments with API key authentication, entry and use are topic to the nova.amazon.com Phrases of Use.
3. Clone the repo, set the API key, and set up the dependencies:
To get began, clone the repository, set your API key so the applying can authenticate, and set up the required Python dependencies. This prepares your surroundings so you may run the challenge regionally with out points. An API Key may be generated on Nova Act.
# Clone the repo
https://github.com/aws-samples/amazon-nova-samples.git
cd nova-act/usecases/price_comparison
# Create and activate a digital surroundings (non-compulsory however really helpful)
python3 -m venv .venv
supply .venv/bin/activate
# Home windows:
.venvScriptsactivate
# Set up Python dependencies
pip set up -r necessities.txt
# Set the Nova Act API Key export NOVA_ACT_API_KEY="your_api_key"
4. Working the script
As soon as your surroundings is about up, you may run the agent to carry out aggressive worth intelligence. The script takes a product identify (non-compulsory) and an inventory of competitor web sites (non-compulsory), launches concurrent Nova Act browser periods, searches every website, extracts worth and promotional particulars, and returns a structured, aggregated end result.
The earlier instance makes use of the script’s default competitor record, which incorporates main retailers resembling Amazon, Goal, Greatest Purchase, and Costco. You’ll be able to override these defaults by supplying your individual record of competitor URLs when working the script.
The agent launches a number of Nova Act browser periods in parallel, one per competitor website. Every session masses the retailer’s web site, checks whether or not a captcha is current, and pauses for person enter if one must be solved. As soon as clear, the agent searches for the product, opinions the returned outcomes, clicks probably the most related itemizing, and extracts the worth and promotional data. Working these flows concurrently permits the agent to finish a multi-site comparability effectively.
For instance, when concentrating on Amazon, the agent opens a recent browser session, navigates to amazon.com, and performs a site-specific seek for the product. It inspects the returned outcomes, identifies the product itemizing that the majority carefully matches the question, and extracts key particulars resembling worth, promotions, availability, and related metadata. This course of is mirrored within the following terminal output that displays every reasoning step (costs on this instance are illustrative and never consultant of actual market costs):
583c> act("Is there a captcha on the display?, format output with jsonschema: {"kind": "boolean"}")
583c> ...
583c> suppose("I'm on the Amazon homepage. My activity is to return whether or not there's a captcha on the display. I can look across the web page to try to discover a captcha. I do not see something that appears like a captcha. I additionally do not see something that looks as if it will require a captcha to be displayed. I ought to return false to point that there isn't any captcha on the web page.");
...
583c> act("Seek for 'iPad Professional 13-inch (M4 chip), 256GB Wi-Fi'.")
583c> ...
583c> suppose("I'm on the amazon homepage. My activity is to seek for 'iPad Professional 13-inch (M4 chip), 256GB Wi-Fi'. I see an empty search discipline. I have to kind 'iPad Professional 13-inch (M4 chip), 256GB Wi-Fi' into the search discipline.");
583c> ...
583c> suppose("I see that the search discipline is populated with 'iPad Professional 13-inch (M4 chip), 256GB Wi-Fi', however the search has not been initiated. Due to this fact, my final motion was not appropriate. I see a search button to the precise of the search discipline which can be utilized to finish the search. I'll click on on the search button to finish the search.");
...
583c> suppose("I'm now on the search outcomes web page for 'iPad Professional 13-inch (M4 chip), 256GB Wi-Fi'. My activity is full, and I have to return.");
...
583c> suppose("I'm on the Amazon search outcomes web page for "iPad Professional 13-inch (M4 chip), 256GB Wi-Fi". My activity is to overview all the outcomes and discover probably the most related one, then extract the worth and any promotion particulars. I have to return the data within the specified JSON format. I see an inventory of merchandise, however the first few are sponsored. I ought to scroll down the web page to seek out probably the most related, non-sponsored product.");
583c> ...
583c> suppose("The web page has scrolled down and I see extra merchandise. My prior motion of scrolling down was profitable. I see the primary non-sponsored product, which is the "Apple iPad Professional 13-Inch (M4): Constructed for Apple Intelligence, Extremely Retina XDR Show, 256GB, 12MP Entrance/Again Digital camera, LiDAR Scanner, Wi-Fi 6E, Face ID, All-Day Battery Life — Area Black". I ought to click on on the product to navigate to its web page and discover the worth and promotion particulars.");
583c> ...
583c> suppose("I'm now on the product web page for the "Apple iPad Professional (M4) 13-inch (M4 chip), 256GB Wi-Fi". My prior motion of clicking on the product was profitable. I see the worth of the product is $1,039.99 and there's a promotion for 19% off. I ought to return the worth and promotion particulars within the specified JSON format.");
4. Reviewing the output
After the agent finishes looking all competitor websites, it returns a consolidated desk that lists every retailer, the matched product, the extracted worth, the promotion particulars, and extra metadata. From this desk, you may evaluate outcomes throughout a number of sources in a single view. For instance, the output may look as follows (costs on this instance are illustrative and never consultant of actual market costs):
| Supply | Product Identify | Product SKU | Value | Promotion Particulars |
|--------|--------------|-------|-------|-------------------|
| Amazon | Apple iPad Professional (M4) 13-inch (M4 chip), 256GB Wi-Fi | MVX23LL/A | $1,039.99 | 19% off |
| Greatest Purchase | Apple - 13-inch iPad Professional M4 chip Constructed for Apple Intelligence Wi-Fi 256GB with OLED - Silver | MVX23LL/A | $1239.00 | Save $50 |
| Costco | iPad Professional 13-inch (M4 chip), 256GB Wi-Fi | MVX23LL/A | $1039.99 | $200 OFF; financial savings is legitimate 11/12/25 by 11/22/25. Whereas provides final. Restrict 2 per member. |
| Goal | Apple iPad Professional (M4) WiFi with Customary glass | MVX23LL/A | $999.00 | Sale ends Wednesday |
The agent writes the extracted outcomes to a CSV file to later combine with pricing instruments, dashboards, or inside APIs.
Conclusion
Amazon Nova Act transforms browser automation from a posh technical activity right into a easy pure language interface, so retailers can automate guide workflows, scale back operational prices, and acquire real-time market insights. By considerably decreasing the time spent on guide information assortment, groups can shift their focus to strategic pricing choices. The answer scales effectively as monitoring wants develop, with out requiring proportional will increase in sources. Nova Act allows builders to construct versatile, sturdy brokers that ship well timed insights, decrease operational effort, and assist data-driven pricing choices throughout industries.
We welcome suggestions and would love to listen to how you employ Nova Act in your individual automation workflows. Share your ideas within the feedback part or open a dialogue within the GitHub repository. Go to the Nova Act to study extra or discover extra examples on the Amazon Nova Samples GitHub Repository.
What’s helpful about embeddings? Relying on who you ask, solutions could range. For a lot of, probably the most fast affiliation could also be phrase vectors and their use in pure language processing (translation, summarization, query answering and so on.) There, they’re well-known for modeling semantic and syntactic relationships, as exemplified by this diagram present in some of the influential papers on phrase vectors(Mikolov et al. 2013):
Others will in all probability convey up entity embeddings, the magic instrument that helped win the Rossmann competitors(Guo and Berkhahn 2016) and was tremendously popularized by quick.ai’s deep studying course. Right here, the thought is to make use of information that isn’t usually useful in prediction, like high-dimensional categorical variables.
One other (associated) concept, additionally broadly unfold by quick.ai and defined in this weblog, is to use embeddings to collaborative filtering. This principally builds up entity embeddings of customers and objects primarily based on the criterion how effectively these “match” (as indicated by current scores).
So what are embeddings good for? The way in which we see it, embeddings are what you make of them. The objective on this put up is to supply examples of use embeddings to uncover relationships and enhance prediction. The examples are simply that – examples, chosen to exhibit a way. Essentially the most fascinating factor actually shall be what you make of those strategies in your space of labor or curiosity.
Embeddings for enjoyable (picturing relationships)
Our first instance will stress the “enjoyable” half, but additionally present technically take care of categorical variables in a dataset.
We’ll take this yr’s StackOverflow developer survey as a foundation and decide just a few categorical variables that appear fascinating – stuff like “what do folks worth in a job” and naturally, what languages and OSes do folks use. Don’t take this too severely, it’s meant to be enjoyable and exhibit a way, that’s all.
Getting ready the info
Outfitted with the libraries we’ll want:
We load the info and zoom in on just a few categorical variables. Two of them we intend to make use of as targets: EthicsChoice and JobSatisfaction. EthicsChoice is one among 4 ethics-related questions and goes
“Think about that you simply had been requested to write down code for a function or product that you simply think about extraordinarily unethical. Do you write the code anyway?”
With questions like this, it’s by no means clear what portion of a response needs to be attributed to social desirability – this query appeared just like the least liable to that, which is why we selected it.
The variables we’re interested by present a bent to have been left unanswered by fairly just a few respondents, so the best technique to deal with lacking information right here is to exclude the respective individuals utterly.
That leaves us with ~48,000 accomplished (so far as we’re involved) questionnaires.
Wanting on the variables’ contents, we see we’ll should do one thing with them earlier than we will begin coaching.
Distribution of solutions to: “Think about that you simply had been requested to write down code for a function or product that you simply think about extraordinarily unethical. Do you write the code anyway?”
You would possibly agree that with a query containing the phrase a function or product that you simply think about extraordinarily unethical, the reply “will depend on what it’s” feels nearer to “sure” than to “no.” If that looks like too skeptical a thought, it’s nonetheless the one binarization that achieves a wise break up.
Taking a look at our second goal variable, JobSatisfaction:
Distribution of solutions to: ““How happy are you together with your present job? In the event you work a couple of job, please reply relating to the one you spend probably the most hours on.”
We expect that given the mode at “reasonably happy,” a wise technique to binarize is a break up into “reasonably happy” and “extraordinarily happy” on one aspect, all remaining choices on the opposite:
Predictors
Among the many predictors, FormalEducation, UndergradMajor and OperatingSystem look fairly innocent – we already turned them into components so it needs to be simple to one-hot-encode them. For curiosity’s sake, let’s take a look at how they’re distributed:
FormalEducation depend
1 Bachelor’s diploma (BA, BS, B.Eng., and so on.) 25558
2 Grasp’s diploma (MA, MS, M.Eng., MBA, and so on.) 12865
3 Some school/college examine with out incomes a level 6474
4 Affiliate diploma 1595
5 Different doctoral diploma (Ph.D, Ed.D., and so on.) 1395
6 Skilled diploma (JD, MD, and so on.) 723
UndergradMajor depend
1 Pc science, laptop engineering, or software program engineering 30931
2 One other engineering self-discipline (ex. civil, electrical, mechani… 4179
3 Data methods, data expertise, or system adminis… 3953
4 A pure science (ex. biology, chemistry, physics) 2046
5 Arithmetic or statistics 1853
6 Internet growth or net design 1171
7 A enterprise self-discipline (ex. accounting, finance, advertising) 1166
8 A humanities self-discipline (ex. literature, historical past, philosophy) 1104
9 A social science (ex. anthropology, psychology, political scie… 888
10 Tremendous arts or performing arts (ex. graphic design, music, studi… 791
11 I by no means declared a significant 398
12 A well being science (ex. nursing, pharmacy, radiology) 130
OperatingSystem depend
1 Home windows 23470
2 MacOS 14216
3 Linux-based 10837
4 BSD/Unix 87
LanguageWorkedWith, alternatively, accommodates sequences of programming languages, concatenated by semicolon.
One technique to unpack these is utilizing Keras’ text_tokenizer.
language_tokenizer<-text_tokenizer(break up =";", filters ="")language_tokenizer%>%fit_text_tokenizer(information$LanguageWorkedWith)
Now we have 38 languages general. Precise utilization counts aren’t too shocking:
We are able to merely append these columns to the dataframe (and perform a little cleanup):
We nonetheless have the AssessJob[n] columns to take care of. Right here, StackOverflow had folks rank what’s necessary to them a few job. These are the options that had been to be ranked:
The trade that I’d be working in
The monetary efficiency or funding standing of the corporate or group
The precise division or workforce I’d be engaged on
The languages, frameworks, and different applied sciences I’d be working with
The compensation and advantages provided
The workplace setting or firm tradition
The chance to do business from home/remotely
Alternatives for skilled growth
The variety of the corporate or group
How broadly used or impactful the services or products I’d be engaged on is
Columns AssessJob1 to AssessJob10 comprise the respective ranks, that’s, values between 1 and 10.
Based mostly on introspection concerning the cognitive effort to really set up an order amongst 10 objects, we determined to tug out the three top-ranked options per particular person and deal with them as equal. Technically, a primary step extracts and concatenate these, yielding an middleman results of e.g.
Now that column appears precisely like LanguageWorkedWith seemed earlier than, so we will use the identical technique as above to supply a one-hot-encoded model.
values_tokenizer<-text_tokenizer(break up =";", filters ="")values_tokenizer%>%fit_text_tokenizer(information$job_vals)
From right here on, completely different actions will ensue relying on whether or not we select the street of working with a one-hot mannequin or an embeddings mannequin of the predictors.
There may be one different factor although to be achieved earlier than: We need to work with the identical train-test break up in each instances.
One-hot mannequin
Given this can be a put up about embeddings, why present a one-hot mannequin? First, for tutorial causes – you don’t see lots of examples of deep studying on categorical information within the wild. Second, … however we’ll flip to that after having proven each fashions.
For the one-hot mannequin, all that is still to be achieved is utilizing Keras’ to_categorical on the three remaining variables that aren’t but in one-hot type.
We divide up our dataset into practice and validation components
…leads to an accuracy on the validation set of 0.64 – not a powerful quantity per se, however fascinating given the small quantity of predictors and the selection of goal variable.
Embeddings mannequin
Within the embeddings mannequin, we don’t want to make use of to_categorical on the remaining components, as embedding layers can work with integer enter information. We thus simply convert the components to integers:
Now for the mannequin. Successfully we now have 5 teams of entities right here: formal training, undergrad main, working system, languages labored with, and highest-counting values with respect to jobs. Every of those teams get embedded individually, so we have to use the Keras practical API and declare 5 completely different inputs.
input_fe<-layer_input(form =1)# formal training, encoded as integerinput_um<-layer_input(form =1)# undergrad main, encoded as integerinput_os<-layer_input(form =1)# working system, encoded as integerinput_langs<-layer_input(form =38)# languages labored with, multi-hot-encodedinput_vals<-layer_input(form =10)# values, multi-hot-encoded
Having embedded them individually, we concatenate the outputs for additional frequent processing.
concat<-layer_concatenate(listing(input_fe%>%layer_embedding( input_dim =size(ranges(information$FormalEducation)), output_dim =64, title ="fe")%>%layer_flatten(),input_um%>%layer_embedding( input_dim =size(ranges(information$UndergradMajor)), output_dim =64, title ="um")%>%layer_flatten(),input_os%>%layer_embedding( input_dim =size(ranges(information$OperatingSystem)), output_dim =64, title ="os")%>%layer_flatten(),input_langs%>%layer_embedding(input_dim =38, output_dim =256, title ="langs")%>%layer_flatten(),input_vals%>%layer_embedding(input_dim =10, output_dim =128, title ="vals")%>%layer_flatten()))output<-concat%>%layer_dense( models =128, activation ="relu")%>%layer_dropout(0.5)%>%layer_dense( models =128, activation ="relu")%>%layer_dropout(0.5)%>%layer_dense( models =128, activation ="relu")%>%layer_dense( models =128, activation ="relu")%>%layer_dropout(0.5)%>%layer_dense(models =1, activation ="sigmoid")
Now to cross the info to the mannequin, we have to chop it up into ranges of columns matching the inputs.
y_train<-information$EthicsChoice[train_indices]%>%as.matrix()y_valid<-information$EthicsChoice[-train_indices]%>%as.matrix()x_train<-listing(X_embed[train_indices, 1, drop =FALSE]%>%as.matrix() ,X_embed[train_indices , 2, drop =FALSE]%>%as.matrix(),X_embed[train_indices , 3, drop =FALSE]%>%as.matrix(),X_embed[train_indices , 4:41, drop =FALSE]%>%as.matrix(),X_embed[train_indices , 42:51, drop =FALSE]%>%as.matrix())x_valid<-listing(X_embed[-train_indices, 1, drop =FALSE]%>%as.matrix() ,X_embed[-train_indices , 2, drop =FALSE]%>%as.matrix(),X_embed[-train_indices , 3, drop =FALSE]%>%as.matrix(),X_embed[-train_indices , 4:41, drop =FALSE]%>%as.matrix(),X_embed[-train_indices , 42:51, drop =FALSE]%>%as.matrix())
Utilizing the identical train-test break up as earlier than, this leads to an accuracy of … ~0.64 (simply as earlier than). Now we stated from the beginning that utilizing embeddings might serve completely different functions, and that on this first use case, we needed to exhibit their use for extracting latent relationships. And in any case you may argue that the duty is simply too onerous – in all probability there simply will not be a lot of a relationship between the predictors we selected and the goal.
However this additionally warrants a extra normal remark. With all present enthusiasm about utilizing embeddings on tabular information, we aren’t conscious of any systematic comparisons with one-hot-encoded information as regards the precise impact on efficiency, nor do we all know of systematic analyses beneath what circumstances embeddings will in all probability be of assist. Our working speculation is that within the setup we selected, the dimensionality of the unique information is so low that the data can merely be encoded “as is” by the community – so long as we create it with ample capability. Our second use case will subsequently use information the place – hopefully – this gained’t be the case.
However earlier than, let’s get to the primary function of this use case: How can we extract these latent relationships from the community?
We’ll present the code right here for the job values embeddings, – it’s straight transferable to the opposite ones. The embeddings, that’s simply the burden matrix of the respective layer, of dimension variety of completely different values occasions embedding measurement.
pca%>%as.information.body()%>%mutate(class =attr(values_tokenizer$word_index, "names"))%>%ggplot(aes(x =PC1, y =PC2))+geom_point()+geom_label_repel(aes(label =class))
That is what we get (displaying 4 of the 5 variables we used embeddings on):
Two first principal parts of the embeddings for undergrad main (prime left), working system (prime proper), programming language used (backside left), and first values with respect to jobs (backside proper)
Now we’ll undoubtedly chorus from taking this too severely, given the modest accuracy on the prediction activity that result in these embedding matrices.
Definitely when assessing the obtained factorization, efficiency on the primary activity must be taken under consideration.
However we’d prefer to level out one thing else too: In distinction to unsupervised and semi-supervised methods like PCA or autoencoders, we made use of an extraneous variable (the moral conduct to be predicted). So any discovered relationships are by no means “absolute,” however all the time to be seen in relation to the way in which they had been discovered. For this reason we selected an extra goal variable, JobSatisfaction, so we might evaluate the embeddings discovered on two completely different duties. We gained’t refer the concrete outcomes right here as accuracy turned out to be even decrease than with EthicsChoice. We do, nonetheless, need to stress this inherent distinction to representations discovered by, e.g., autoencoders.
Now let’s tackle the second use case.
Embedding for revenue (bettering accuracy)
Our second activity right here is about fraud detection. The dataset is contained within the DMwR2 package deal and is known as gross sales:
Every row signifies a transaction reported by a salesman, – ID being the salesperson ID, Prod a product ID, Quant the amount bought, Val the amount of cash it was bought for, and Insp indicating one among three prospects: (1) the transaction was examined and located fraudulent, (2) it was examined and located okay, and (3) it has not been examined (the overwhelming majority of instances).
Whereas this dataset “cries” for semi-supervised methods (to utilize the overwhelming quantity of unlabeled information), we need to see if utilizing embeddings may also help us enhance accuracy on a supervised activity.
We thus recklessly throw away incomplete information in addition to all unlabeled entries
which leaves us with 15546 transactions.
One-hot mannequin
Now we put together the info for the one-hot mannequin we need to evaluate towards:
With 2821 ranges, salesperson ID is much too high-dimensional to work effectively with one-hot encoding, so we utterly drop that column.
Product id (Prod) has “simply” 797 ranges, however with one-hot-encoding, that also leads to important reminiscence demand. We thus zoom in on the five hundred top-sellers.
The continual variables Quant and Val are normalized to values between 0 and 1 so that they match with the one-hot-encoded Prod.
We then carry out the same old train-test break up.
This mannequin achieved optimum validation accuracy at a dropout charge of 0.2. At that charge, coaching accuracy was 0.9761, and validation accuracy was 0.9507. In any respect dropout charges decrease than 0.7, validation accuracy did certainly surpass the bulk vote baseline.
Can we additional enhance efficiency by embedding the product id?
Embeddings mannequin
For higher comparability, we once more discard salesperson data and cap the variety of completely different merchandise at 500.
In any other case, information preparation goes as anticipated for this mannequin:
The mannequin we outline is as comparable as potential to the one-hot different:
This time, accuracies are in actual fact larger: On the optimum dropout charge (0.3 on this case), coaching resp. validation accuracy are at 0.9913 and 0.9666, respectively. Fairly a distinction!
So why did we select this dataset? In distinction to our earlier dataset, right here the explicit variable is high-dimensional, so effectively fitted to compression and densification. It’s fascinating that we will make such good use of an ID with out understanding what it stands for!
Conclusion
On this put up, we’ve proven two use instances of embeddings in “easy” tabular information. As said within the introduction, to us, embeddings are what you make of them. In that vein, should you’ve used embeddings to perform issues that mattered to your activity at hand, please remark and inform us about it!
Guo, Cheng, and Felix Berkhahn. 2016. “Entity Embeddings of Categorical Variables.”CoRR abs/1604.06737. http://arxiv.org/abs/1604.06737.
Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. “Distributed Representations of Phrases and Phrases and Their Compositionality.”CoRR abs/1310.4546. http://arxiv.org/abs/1310.4546.
The Iran warfare of 2026 will proceed, however it seems to be getting into its remaining section. Or at the very least, that’s what President Donald Trump hopes.
Claiming that the “exhausting half is completed,” Trump made the case in a televised handle on Wednesday evening that America has “overwhelmed and utterly decimated Iran” and urged that the battle was “very shut” to completion and would wrap up over the subsequent two to 3 weeks.
“By no means within the historical past of warfare has an enemy suffered such clear and devastating, large-scale losses in a matter of weeks,” Trump mentioned, noting the injury inflicted to Iran’s Revolutionary Guard Corps, Navy, and missile program.
Trump mentioned he would favor to make a cope with Iran, and would launch assaults on Iran’s civilian infrastructure and vitality services if it didn’t agree to 1. However he appeared to counsel that the US would wrap up operations quickly both approach. Trump gave the impression to be asking Individuals for persistence, noting that the warfare was far shorter than earlier conflicts like World Warfare II and Vietnam.
There are a selection of the way the scenario might nonetheless change dramatically within the subsequent few weeks, but when Trump is, the truth is, beginning the method of winding down the warfare, there are a couple of classes we are able to already take from it.
The warfare might probably not be ending
One navy cliché has been getting a exercise over the previous month: In any warfare plan, the enemy will get a vote. That’s simply as true in any withdrawal plan. Iran might not cease combating simply because the US stops bombing. Provided that its air defenses proved utterly incapable of stopping the US and Israeli bombardment, Iran might look to boost the prices to the US and its allies to the purpose the place they are going to be deterred from merely coming again and bombing Iran once more in six months.
Particularly, Iran will not be in a rush to reopen the Strait of Hormuz — the very important world vitality chokepoint it has successfully shut down. Hormuz has emerged as Iran’s predominant level of leverage on this battle, and leaders in Tehran will likely be reluctant to present it up. Over the weekend, Iran’s parliament handed a measure authorizing the gathering of tolls from ships transiting the Strait, although it’s not clear how that might work in apply.
Trump urged in his speech that he was unbothered by this, saying that the Strait would “simply open up naturally” as soon as the warfare ended, but in addition calling on international locations that depend on it to point out some “lengthy delayed braveness” and reopen it themselves.
It’s additionally price noting that US forces are nonetheless heading to the area. A second Marine Expeditionary Unit, consisting of about 2,200 Marines and three warships, is because of arrive in a couple of weeks to hitch one other MEU in addition to components of the 82nd Airborne Division, who have been deployed to the area final week. These forces, designed for fast deployments to grab and maintain territory, may very well be a type of negotiating leverage for the US because it winds down the battle, or might give the president further navy choices if he alters his thoughts.
Then there’s the “axis of resistance”: Iran’s regional proxies, badly weakened by Israel’s publish–Oct. 7 offensive, appeared like a non-factor within the warfare’s early days. However currently they’ve made their presence felt. Yemen’s Houthis, who sat out a lot of the warfare’s first month, have begun firing missiles at Israel. Iraqi militias have been stepping up their assault on US pursuits, and seem to have kidnapped an American journalist. Hezbollah, combating Israeli forces in Southern Lebanon, has proven it might probably nonetheless hearth barrages of lots of of rockets into Israel. These teams aren’t as highly effective as they was once, however they’re not eradicated, they usually might not halt their assaults when the warfare ends.
Whether it is ending, no one gained
It’s necessary to keep in mind that whereas Trump’s rapid justifications for this warfare have shifted over time, the one constant case he has made is that, as he put it on Wednesday, I “would by no means permit Iran to have a nuclear weapon.” It’s notable that in his speech, Trump didn’t discuss with Iran’s stockpile of 450 kilograms of enriched uranium. So long as that stockpile stays, the US can not credibly declare to have eradicated Iran’s nuclear risk, although Trump did vow to launch new airstrikes if any new nuclear exercise is detected.
If the warfare winds down within the coming weeks, Iran will likely declare victory on the grounds that it’s nonetheless in energy, regardless of the onslaught, and was in a position to combat again extra successfully than many anticipated through its missile and drone assaults all through the area and its closure of the Strait. However we shouldn’t overstate that case both.
Along with dozens of senior leaders, together with its most distinguished figures like Ayatollah Ali Khamenei and safety chief Ali Larijani, Iran’s typical armed forces, navy, and missile forces have sustained heavy injury. Its strikes throughout the Gulf have enraged the Gulf Arab nations with which it had reached a tentative detente in recent times. It’s unlikely to search out many companions anxious to put money into its rebuilding effort.
Israeli airstrikes have additionally focused the Basij militia, which led the efforts to crush anti-regime protests in Iran earlier this 12 months. It’s exhausting to know but what impact the warfare — which is estimated to have killed greater than 1,500 civilians — has had on public opinion in Iran. Nevertheless it appears possible that the regime’s opponents, whether or not on the streets of main cities or in ethnic minority areas, would possibly quickly need to check simply how a lot it’s been weakened.
Trump continues to be allergic to huge floor wars
The relative success of “Operation Midnight Hammer” final June — Israel and America’s so-called 12-day warfare on Iran that focused its nuclear services — and, much more so, the US operation to grab Venezuelan President Nicolás Maduro in January seem to have elevated the navy confidence of a president who, till just lately, was campaigning for a Nobel Peace Prize. If Trump have been working for workplace once more, it might be exhausting for him to once more marketing campaign because the “pro-peace” candidate, however there do nonetheless look like some strains he’s reluctant to cross.
In current weeks, there was widespread reporting that the administration was contemplating dangerous operations to seize islands in and across the Strait of Hormuz to interrupt Iran’s blockade or to deploy particular forces to grab Iran’s uranium stockpile. Extracting 450 kilograms of radioactive materials buried deep underneath rubble whereas taking heavy enemy hearth all the time appeared like a tall order. The Hormuz operations might have been doable however would additionally increase the danger of American casualties — 13 American servicemembers have been killed within the warfare, already — and lengthen an already unpopular battle. The escalations that Trump mentioned in his speech concerned bombing Iran “again to the stone age” — not sending in troops.
This can be the closest Trump has come to the kind of Mideast navy quagmire that has bedeviled the US for the previous 25 years, however regardless of his claims that the “doesn’t have the yips” with regards to boots on the bottom, he nonetheless appears intent on avoiding large-scale floor operations that might see a lot of Individuals coming house in coffins.
Colin Powell’s well-known “pottery barn rule” is not in impact: The US is okay simply breaking issues and transferring on.
One of many predominant questions prone to perplex future historians of this warfare is why its planners didn’t anticipate and put together for Iran blocking the Strait of Hormuz — a state of affairs that has dominated US strategic fascinated with the area for many years. (A Marine Corps veteran I spoke with just lately recalled war-gaming an amphibious operation on Iran’s Qeshm Island within the Nineteen Eighties.) Making certain the free stream of vitality from the Gulf is likely one of the predominant justifications for having a big navy presence on this area within the first place.
It’s true that Iran was in a position to successfully shut the Strait extra simply than many anticipated, with only a handful of demonstrative strikes on tankers quite than a big deployment of mines. However that might have been anticipated when the Houthis did the very same factor within the Purple Sea in 2024.
For years, the US leveraged its management of chokepoints within the world economic system — the usage of the greenback in worldwide monetary transactions; the worldwide tech business’s reliance on semiconductors made by US allies — to punish its rivals. Over the previous 12 months, we’ve seen these rivals be taught to play the identical sport.
Closing the Strait has resulted in world shortages in meals, fertilizer, and different commodities — the reverberations of which may very well be felt for months after the combating stops — and people worst-affected by it will likely be these dwelling within the world’s poorest international locations, who had nothing to do with this warfare.
However we’ve seen the boundaries as nicely. In current days, it’s been changing into clear that the Iranian strikes on US bases have been extra damaging than initially reported and that they’ve been having extra success penetrating Israel’s air defenses as nicely. Whether or not that’s as a result of Iran was studying how one can evade these defenses (maybe with Russian help) or as a result of it has been saving its extra subtle {hardware} for later within the warfare stays unclear.
The US and Gulf Nations have been by no means actually in peril of working out of important interceptors, however their heavy use on this battle, together with different subtle methods like Tomahawk missiles, has compelled robust selections about how one can allocate them, and the diminished stockpile could also be felt in future conflicts, notably within the Asia-Pacific area.
The destiny of the USS Gerald Ford, which in current months has had its deployment twice prolonged because it was diverted from the Center East for operations in Venezuela, then despatched again for the warfare in Iran, then lastly docked in Croatia after its laundry room caught on hearth and its bathrooms started malfunctioning, might function a cautionary story.
We’ve realized as soon as once more that even probably the most highly effective and best-funded navy on this planet faces navy constraints when the president is launching new main navy operations each few months.
As for Gaza itself, Israel seems to be fortifying its navy presence inside the enclave, support has been severely restricted from getting into the Strip, and speak of transferring to a brand new section of reconstruction seems like a distant reminiscence.
Even because the Iran warfare was by no means fashionable in the US, it was overwhelmingly so in Israel, regardless of a lot of the inhabitants spending the previous month out and in of air raid shelters. Even when Trump forces the warfare to an in depth wanting Prime Minister Benjamin Netanyahu’s final objective of regime change in Tehran, the Israeli expectation has all the time been that they’d merely proceed to degrade Iran’s capabilities as a lot as attainable for so long as the US would permit. As for what stays, there’s all the time the subsequent time — a regional enlargement of the “mowing the grass” technique that Israel has lengthy employed in Gaza. “If we see them make a transfer, even a transfer ahead, will hit them with missiles very exhausting once more,” Trump mentioned on Wednesday, suggesting that the US might once more participate int he mowing.
The warfare might have accomplished critical injury to Israel’s standing within the US — and never solely amongst Democrats, who have been already a misplaced trigger from Netanyahu’s perspective, however amongst Republicans searching for somebody aside from Trump in charge for this warfare. However that’s a priority for an additional day: For now, Israel sees its regional enemies on the again foot and can look to proceed to press its benefit.
If there was a transparent winner from this warfare, it’s Russian President Vladimir Putin, who has benefited from each an financial shot within the arm from excessive oil costs and from the additional pressure that the battle has placed on the transatlantic alliance. (The Monetary Instances experiences that Trump had threatened to halt support to Ukraine if European international locations didn’t participate in an effort to reopen the Strait.) Trump is as soon as once more speaking about pulling the US out of NATO, in mild of the alliance’s reluctance to permit their bases for use for navy operations or to hitch a combat to reopen Hormuz. Given the skepticism Trump is voicing concerning the alliance’s all-important mutual protection obligation, it’s truthful to ask if the alliance is successfully lifeless already. That’s a trigger for concern in a world the place interstate wars are beginning to develop into extra widespread once more.
Not each nation has entry to one thing just like the Strait of Hormuz, however different international locations are prone to attempt to be taught from Iran’s instance of weaponizing chokepoints within the world economic system to combat a extra highly effective adversary. Iran’s concentrating on of Amazon knowledge facilities can also portend a world wherein tech corporations are thought-about respectable navy targets.
Khamenei’s killing broke a precedent: There are only a few fashionable examples of heads of state being intentionally killed in warfare. Provided that new advances in precision concentrating on and drones have made “decapitation strikes” simpler to hold out, this might make future wars much more harmful for the leaders waging them.
Iran clearly has extra incentive than ever to really construct a nuclear weapon — although whether or not it might really be capable of do that with a lot of its weapons program in shambles and its authorities penetrated by spies is one other query. What’s extra clear, although, is that the assault on Iran, the second launched by the US and Israel prior to now 12 months within the midst of ongoing nuclear negotiations, will persuade many international locations that it’s price having a nuclear weapon and never trusting future efforts at nuclear diplomacy.
Iran itself could also be weaker than it was a month in the past — however its tolerance for danger and desperation are additionally greater. The injury inflicted on the regime on this warfare might have happy leaders in Washington and Jerusalem, however the world itself has possible gotten extra harmful.
A tobacco plant has been modified to provide 5 psychedelic medicine
Aharoni lab, Weizmann Institute if Science
Scientists have engineered tobacco vegetation to provide 5 highly effective psychedelic compounds usually present in different vegetation, fungi and animals in a single crop. They argue that utilizing vegetation to fabricate the medicine can be less complicated and extra sustainable than present processes, making analysis into therapeutic makes use of and manufacturing of future medicines simpler.
Asaph Aharoni on the Weizmann Institute of Science in Israel and his colleagues modified Nicotiana benthamiana vegetation utilizing a method referred to as agroinfiltration, which entails utilizing a bacterium to introduce genes from different organisms right into a plant. The modified plant then makes the proteins encoded by these genes, however the DNA isn’t integrated into the plant’s genome, so the impact is short-lived.
With the addition of 9 genes, the vegetation have been capable of produce psilocin and psilocybin, normally present in mushrooms; DMT from varied vegetation; and bufotenin and 5-methoxy-DMT, compounds secreted by the Colorado river toad (Incilius alvarius).
Vegetation might simply be altered completely with adjustments that develop into inheritable, however doing so could possibly be problematic, on condition that the compounds produced are generally used as leisure medicine, says Aharoni. “It’s a bit bit tough if we now have it inherited, after which individuals will ask for seeds,” he says. “We are able to do it additionally in tomato, potato, corn.”
The medical makes use of of psychedelic compounds are rising in popularity and higher understood, says Aharoni, however harvesting them from pure sources dangers populations threatened by habitat loss and overexploitation. The medicine are chemically synthesised to be used in analysis, however producing them in tobacco vegetation, that are simply cultivated in greenhouses, can be a lot less complicated.
The thought of rising medicine by means of pharmaceutical farming, or “pharming”, definitely isn’t new. Plant-produced protein medicine have been authorized within the US since 2012, and way back to 2002, maize has been modified to provide a pharmaceutical protein. One other analysis staff used tobacco vegetation in 2022 to synthesise cocaine, discovering that it might produce about 400 nanograms of cocaine per milligram of dried leaf – a few twenty fifth of the extent in a coca plant.
Rupert Fray on the College of Nottingham, UK, says round 25 per cent of pharmaceuticals are derived wholly or partially from vegetation, and there are large alternatives to create “inexperienced factories” that may develop new compounds in greenhouses.
“If you wish to perceive one thing, you’ve acquired to have the ability to construct one thing, so displaying that you could make it in tobacco vegetation is helpful,” says Fray. “As a technical accomplishment, to point out that you just perceive the pathways and might do it, I believe it has worth.”
There’s a set of ideas crossing my thoughts that I’d wish to share right now. Hopefully that is helpful for everybody. Per my ordinary, since this isn’t a direct Claude Code publish, I flip cash as as to if to right away paywall it. And it’s once more two heads vs one tails, and subsequently it’s paywalled, about 30-40% of the best way down.
So thanks once more in your help of me and this substack. It’s enormously appreciated.
Probably the most poplar new diff-in-diff estimators is Callaway and Sant’anna. It has over 11,000 cites and within the APE knowledge from the Social Catalyst Lab, it’s the commonest estimator selected by AI Brokers. It’s used when there are a number of therapy intervals or “staggered adoption”.
It’s a simple estimator in some ways. In contrast to two-way fastened results, the place the entire knowledge is processed as soon as utilizing matrix calculations to resolve for a single coefficient, CS as its typically known as estimates smaller constructing block coefficients, one after the other, after which takes weighted averages of them when you’ve accomplished doing them. These coefficients are known as 2x2s and when assumptions maintain they map onto one thing known as the group-time ATT, or ATT(g,t). The ATT(g,t) is a inhabitants estimand, as they are saying, which in a sampling framework means for those who had all the info, you’d calculate it like this:
The capital G is a dummy variable indicating whether or not you might be in a gaggle, g. The “p-hat” is the propensity rating (on this case estimated with logit), the C is a dummy indicating you might be not handled. And Y is the result.
Chances are high, you have already got the sensation that the brand new, agent-first synthetic intelligence period is right here, with builders resorting to new instruments that, as an alternative of simply producing code reactively, genuinely perceive the distinctive processes behind code era.
Google Antigravity has loads to say on this matter. This software holds the important thing to constructing extremely customizable brokers. This text unveils a part of its potential by demystifying three cornerstone ideas: guidelines, abilities, and workflows.
On this article, you may discover ways to hyperlink these key ideas collectively to construct extra strong brokers and highly effective automated pipelines. Particularly, we’ll carry out a step-by-step course of to arrange a code high quality assurance (QA) agent workflow, primarily based on specified guidelines and abilities. Off we go!
# Understanding the Three Core Ideas
Earlier than getting our palms soiled, it’s handy to interrupt down the next three components belonging to the Google Antigravity ecosystem:
Rule: These are the baseline constraints that dictate the agent’s habits, in addition to tips on how to adapt it to our stack and match our model. They’re saved as markdown information.
Ability: Take into account abilities as a reusable bundle containing data that instructs the agent on tips on how to deal with a concrete job. They’re allotted in a devoted folder that comprises a file named SKILL.md.
Workflow: These are the orchestrators that put all of it collectively. Workflows are invoked through the use of command-like directions preceded by a ahead slash, e.g. /deploy. Merely put, workflows information the agent via an motion plan or trajectory that’s well-structured and consists of a number of steps. That is the important thing to automating repetitive duties with out lack of precision.
# Taking Motion
Let’s transfer on to our sensible instance. We are going to see tips on how to configure Antigravity to evaluation Python code, apply right formatting, and generate assessments — all with out the necessity for extra third-party instruments.
Earlier than taking these steps, be sure to have downloaded and put in Google Antigravity in your pc first.
As soon as put in, open the desktop utility and open your Python undertaking folder — in case you are new to the software, you may be requested to outline a folder in your pc file system to behave because the undertaking folder. Regardless, the best way so as to add a manually created folder into Antigravity is thru the “File >> Add Folder to Workspace…” possibility within the higher menu toolbar.
Say you may have a brand new, empty workspace folder. Within the root of the undertaking listing (left-hand facet), create a brand new folder and provides it the identify .brokers. Inside this folder, we’ll create two subfolders: one referred to as guidelines and one named abilities. You could guess that these two are the place we’ll outline the 2 pillars for our agent’s habits: guidelines and abilities.
The undertaking folder hierarchy | Picture by Writer
Let’s outline a rule first, containing our baseline constraints that may make sure the agent’s adherence to Python formatting requirements. We do not want verbose syntax to do that: in Antigravity, we outline it utilizing clear directions in pure language. Contained in the guidelines subfolder, you may create a file named python-style.md and paste the next content material:
# Python Type Rule
All the time use PEP 8 requirements. When offering or refactoring code, assume we're utilizing `black` for formatting. Preserve dependencies strictly to free, open-source libraries to make sure our undertaking stays free-friendly.
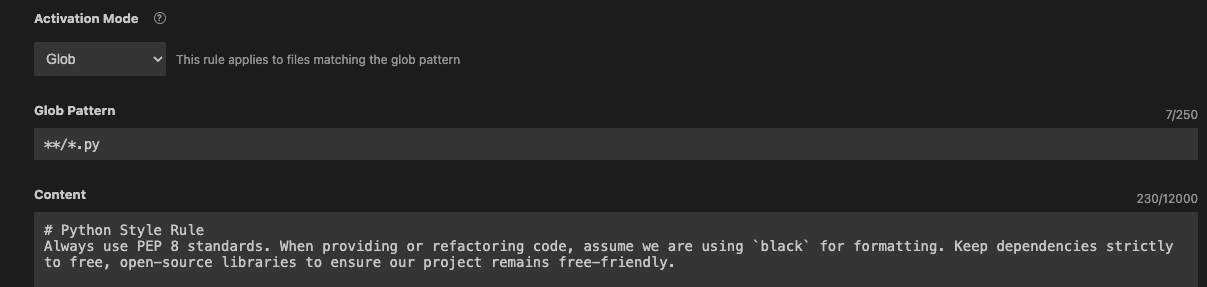
If you wish to nail it, go to the agent customizations panel that prompts on the right-hand facet of the editor, open it, and discover and choose the rule we simply outlined:
Customizing the activation of agent guidelines | Picture by Writer
Customization choices will seem above the file we simply edited. Set the activation mannequin to “glob” and specify this glob sample: **/*.py, as proven under:
Setting the glob activation mode | Picture by Writer
With this, you simply ensured the agent that will likely be launched later at all times applies the rule outlined after we are particularly engaged on Python scripts.
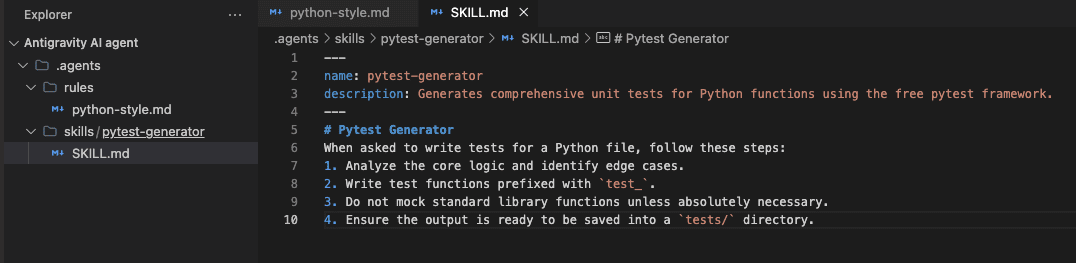
Subsequent, it is time to outline (or “educate”) the agent some abilities. That would be the ability of performing strong assessments on Python code — one thing extraordinarily helpful in right now’s demanding software program growth panorama. Contained in the abilities subfolder, we’ll create one other folder with the identify pytest-generator. Create a SKILL.md file inside it, with the next content material:
Defining agent abilities inside the workspace | Picture by Writer
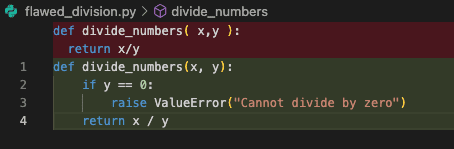
Now it is time to put all of it collectively and launch our agent, however not with out having inside our undertaking workspace an instance Python file containing “poor-quality” code first to strive all of it on. If you haven’t any, strive creating a brand new .py file, calling it one thing like flawed_division.py within the root listing, and add this code:
def divide_numbers( x,y ):
return x/y
You could have seen this Python code is deliberately messy and flawed. Let’s examine what our agent can do about it. Go to the customization panel on the right-hand facet, and this time concentrate on the “Workflows” navigation pane. Click on “+Workspace” to create a brand new workflow we’ll name qa-check, with this content material:
# Title: Python QA Test
# Description: Automates code evaluation and take a look at era for Python information.
Step 1: Overview the at present open Python file for bugs and magnificence points, adhering to our Python Type Rule.
Step 2: Refactor any inefficient code.
Step 3: Name the `pytest-generator` ability to write down complete unit assessments for the refactored code.
Step 4: Output the ultimate take a look at code and counsel working `pytest` within the terminal.
All these items, when glued collectively by the agent, will rework the event loop as a complete. With the messy Python file nonetheless open within the workspace, we’ll put our agent to work by clicking the agent icon within the right-hand facet panel, typing the qa-check command, and hitting enter to run the agent:
Invoking the QA workflow through the agent console | Picture by Writer
After execution, the agent could have revised the code and robotically advised a brand new model within the Python file, as proven under:
The refactored code advised by the agent | Picture by Writer
However that is not all: the agent additionally comes with the great high quality test we had been searching for by producing quite a lot of code excerpts you need to use to run various kinds of assessments utilizing pytest. For the sake of illustration, that is what a few of these assessments may appear to be:
All this sequential course of carried out by the agent has consisted of first analyzing the code below the constraints we outlined via guidelines, then autonomously calling the newly outlined ability to provide a complete testing technique tailor-made to our codebase.
# Wrapping Up
Trying again, on this article, we now have proven tips on how to mix three key components of Google Antigravity — guidelines, abilities, and workflows — to show generic brokers into specialised, strong, and environment friendly workmates. We illustrated tips on how to make an agent specialised in accurately formatting messy code and defining QA assessments.
Iván Palomares Carrascosa is a frontrunner, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the actual world.
The WASI SDK is a modified model of the Clang compiler, which makes use of a library referred to as wasi-libc. This provides applications written in C (and C API-compatible languages) entry to WASI’s APIs for the host (storage, networking, timers, and so forth).
In idea, we should always simply be capable of compile a given CPython launch with the newest WASI SDK on the time. However issues aren’t that easy. For one, the SDK’s largest element, wasi-libc, doesn’t assure it’ll be forward- or backward-compatible. Additionally, some variations of the SDK could trigger buggy conduct with some variations of CPython. As builders, we need to know that this model of CPython works with this model of the SDK—or no less than be capable of doc which bugs seem with any given mixture of the 2.
How future releases of CPython will use WASI
CPython has been out there on Wasm since model 3.11, with Tier 2 and Tier 3 help. The extra official wasip1 is the better-supported goal, whereas the older emscripten commonplace is the less-supported model. However Tier 2 help has been confined to the WASI “Preview 1” set of system calls. And for the explanations already acknowledged, the WASI SDK CPython makes use of just isn’t essentially the newest model, both: it’s SDK model 21 for Python 3.11 and three.12, and SDK model 24 for 3.13 and three.14.
On this tutorial, we construct and run a Colab workflow for Gemma 3 1B Instruct utilizing Hugging Face Transformers and HF Token, in a sensible, reproducible, and easy-to-follow step-by-step method. We start by putting in the required libraries, securely authenticating with our Hugging Face token, and loading the tokenizer and mannequin onto the out there system with the proper precision settings. From there, we create reusable era utilities, format prompts in a chat-style construction, and take a look at the mannequin throughout a number of sensible duties corresponding to fundamental era, structured JSON-style responses, immediate chaining, benchmarking, and deterministic summarization, so we don’t simply load Gemma however really work with it in a significant method.
import os
import sys
import time
import json
import getpass
import subprocess
import warnings
warnings.filterwarnings("ignore")
def pip_install(*pkgs):
subprocess.check_call([sys.executable, "-m", "pip", "install", "-q", *pkgs])
pip_install(
"transformers>=4.51.0",
"speed up",
"sentencepiece",
"safetensors",
"pandas",
)
import torch
import pandas as pd
from huggingface_hub import login
from transformers import AutoTokenizer, AutoModelForCausalLM
print("=" * 100)
print("STEP 1 — Hugging Face authentication")
print("=" * 100)
hf_token = None
attempt:
from google.colab import userdata
attempt:
hf_token = userdata.get("HF_TOKEN")
besides Exception:
hf_token = None
besides Exception:
go
if not hf_token:
hf_token = getpass.getpass("Enter your Hugging Face token: ").strip()
login(token=hf_token)
os.environ["HF_TOKEN"] = hf_token
print("HF login profitable.")
We arrange the setting wanted to run the tutorial easily in Google Colab. We set up the required libraries, import all of the core dependencies, and securely authenticate with Hugging Face utilizing our token. By the tip of this half, we are going to put together the pocket book to entry the Gemma mannequin and proceed the workflow with out guide setup points.
We configure the runtime by detecting whether or not we’re utilizing a GPU or a CPU and deciding on the suitable precision to load the mannequin effectively. We then outline the Gemma 3 1 B Instruct mannequin path and cargo each the tokenizer and the mannequin from Hugging Face. At this stage, we full the core mannequin initialization, making the pocket book able to generate textual content.
def build_chat_prompt(user_prompt: str):
messages = [
{"role": "user", "content": user_prompt}
]
attempt:
textual content = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
besides Exception:
textual content = f"usern{user_prompt}nmodeln"
return textual content
def generate_text(immediate, max_new_tokens=256, temperature=0.7, do_sample=True):
chat_text = build_chat_prompt(immediate)
inputs = tokenizer(chat_text, return_tensors="pt").to(mannequin.system)
with torch.no_grad():
outputs = mannequin.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=do_sample,
temperature=temperature if do_sample else None,
top_p=0.95 if do_sample else None,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.eos_token_id,
)
generated = outputs[0][inputs["input_ids"].form[-1]:]
return tokenizer.decode(generated, skip_special_tokens=True).strip()
print("=" * 100)
print("STEP 4 — Fundamental era")
print("=" * 100)
prompt1 = """Clarify Gemma 3 in plain English.
Then give:
1. one sensible use case
2. one limitation
3. one Colab tip
Preserve it concise."""
resp1 = generate_text(prompt1, max_new_tokens=220, temperature=0.7, do_sample=True)
print(resp1)
We construct the reusable capabilities that format prompts into the anticipated chat construction and deal with textual content era from the mannequin. We make the inference pipeline modular so we will reuse the identical operate throughout completely different duties within the pocket book. After that, we run a primary sensible era instance to substantiate that the mannequin is working appropriately and producing significant output.
print("=" * 100)
print("STEP 5 — Structured output")
print("=" * 100)
prompt2 = """
Examine native open-weight mannequin utilization vs API-hosted mannequin utilization.
Return JSON with this schema:
{
"native": {
"professionals": ["", "", ""],
"cons": ["", "", ""]
},
"api": {
"professionals": ["", "", ""],
"cons": ["", "", ""]
},
"best_for": {
"native": "",
"api": ""
}
}
Solely output JSON.
"""
resp2 = generate_text(prompt2, max_new_tokens=300, temperature=0.2, do_sample=True)
print(resp2)
print("=" * 100)
print("STEP 6 — Immediate chaining")
print("=" * 100)
job = "Draft a 5-step guidelines for evaluating whether or not Gemma suits an inside enterprise prototype."
resp3 = generate_text(job, max_new_tokens=250, temperature=0.6, do_sample=True)
print(resp3)
followup = f"""
Right here is an preliminary guidelines:
{resp3}
Now rewrite it for a product supervisor viewers.
"""
resp4 = generate_text(followup, max_new_tokens=250, temperature=0.6, do_sample=True)
print(resp4)
We push the mannequin past easy prompting by testing structured output era and immediate chaining. We ask Gemma to return a response in an outlined JSON-like format after which use a follow-up instruction to remodel an earlier response for a unique viewers. This helps us see how the mannequin handles formatting constraints and multi-step refinement in a practical workflow.
print("=" * 100)
print("STEP 7 — Mini benchmark")
print("=" * 100)
prompts = [
"Explain tokenization in two lines.",
"Give three use cases for local LLMs.",
"What is one downside of small local models?",
"Explain instruction tuning in one paragraph."
]
rows = []
for p in prompts:
t0 = time.time()
out = generate_text(p, max_new_tokens=140, temperature=0.3, do_sample=True)
dt = time.time() - t0
rows.append({
"immediate": p,
"latency_sec": spherical(dt, 2),
"chars": len(out),
"preview": out[:160].exchange("n", " ")
})
df = pd.DataFrame(rows)
print(df)
print("=" * 100)
print("STEP 8 — Deterministic summarization")
print("=" * 100)
long_text = """
In sensible utilization, groups typically consider
trade-offs amongst native deployment price, latency, privateness, controllability, and uncooked functionality.
Smaller fashions might be simpler to deploy, however they might wrestle extra on complicated reasoning or domain-specific duties.
"""
summary_prompt = f"""
Summarize the next in precisely 4 bullet factors:
{long_text}
"""
abstract = generate_text(summary_prompt, max_new_tokens=180, do_sample=False)
print(abstract)
print("=" * 100)
print("STEP 9 — Save outputs")
print("=" * 100)
report = {
"model_id": model_id,
"system": str(mannequin.system),
"basic_generation": resp1,
"structured_output": resp2,
"chain_step_1": resp3,
"chain_step_2": resp4,
"abstract": abstract,
"benchmark": rows,
}
with open("gemma3_1b_text_tutorial_report.json", "w", encoding="utf-8") as f:
json.dump(report, f, indent=2, ensure_ascii=False)
print("Saved gemma3_1b_text_tutorial_report.json")
print("Tutorial full.")
We consider the mannequin throughout a small benchmark of prompts to watch response habits, latency, and output size in a compact experiment. We then carry out a deterministic summarization job to see how the mannequin behaves when randomness is diminished. Lastly, we save all the most important outputs to a report file, turning the pocket book right into a reusable experimental setup moderately than only a non permanent demo.
In conclusion, we now have a whole text-generation pipeline that reveals how Gemma 3 1B can be utilized in Colab for sensible experimentation and light-weight prototyping. We generated direct responses, in contrast outputs throughout completely different prompting types, measured easy latency habits, and saved the outcomes right into a report file for later inspection. In doing so, we turned the pocket book into greater than a one-off demo: we made it a reusable basis for testing prompts, evaluating outputs, and integrating Gemma into bigger workflows with confidence.
In South Korea, a playful inexperienced cartoon dinosaur named Dooly, identified for the 2 small tufts of hair on his head, has been a favourite for generations. So when scientists uncovered a brand new species of younger dinosaur on Aphae Island, the identify got here naturally: Doolysaurus.
“Dooly is likely one of the very well-known, iconic dinosaur characters in Korea. Each era in Korea is aware of this character,” mentioned Jongyun Jung, a visiting postdoctoral researcher at UT’s Jackson Faculty of Geosciences who led the analysis. “And our specimen can be a juvenile or ‘child’, so it is excellent for our dinosaur species identify to honor Dooly.”
First New Dinosaur Species in Korea in 15 Years
This discovery marks the primary new dinosaur species recognized in South Korea in 15 years. It’s also the primary fossil from the nation to incorporate components of a dinosaur cranium.
Initially, researchers solely noticed a number of bones, together with components of the legs and backbone. Nevertheless, a micro-CT scan performed on the College of Texas Excessive-Decision X-ray Computed Tomography (UTCT) facility revealed far more hidden contained in the rock, together with cranium fragments.
“After we first discovered the specimen, we noticed some leg bones preserved and a few vertebrae,” Jung mentioned. “We did not anticipate cranium components and so many extra bones. There was a good quantity of pleasure once we noticed what was hidden contained in the block.”
Meet Doolysaurus huhmini
The species has been formally named Doolysaurus huhmini. The second a part of the identify honors Korean paleontologist Min Huh for his a long time of contributions to dinosaur analysis in Korea, in addition to his position in founding the Korean Dinosaur Analysis Middle and serving to protect fossil websites by way of UNESCO.
The findings have been printed within the journal Fossil Document on March 19. The fossil itself was found in 2023 by co-author Hyemin Jo.
What the Child Dinosaur Seemed Like
The younger dinosaur was about two years outdated when it died and was nonetheless rising. It measured roughly the dimensions of a turkey, although adults of the species might have been twice as giant. Scientists additionally assume it could have been lined in tender, fuzzy filaments.
“I believe it will have been fairly cute,” mentioned research co-author Julia Clarke, a professor on the Jackson Faculty. “It might need appeared a bit like somewhat lamb.”
CT Scanning Reveals Hidden Fossil Particulars
A lot of the fossil stays encased in laborious rock, and manually eradicating it may take years. As a substitute, researchers relied on micro-CT scanning, which allowed them to visualise the complete skeleton in only a few months.
Jung and Clarke, together with their collaborators, then spent greater than a 12 months finding out the anatomy intimately. Clarke famous that CT scanning has grow to be a vital methodology for finding out delicate fossils, particularly small dinosaurs and early birds trapped in strong rock.
Life within the Mid-Cretaceous Interval
Doolysaurus lived between about 113 and 94 million years in the past through the mid-Cretaceous interval. Based mostly on its options, scientists labeled it as a thescelosaurid, a gaggle of two-legged dinosaurs present in East Asia and North America which will have had fuzzy coverings.
Researchers confirmed that the fossil belonged to a juvenile by analyzing progress patterns in a skinny part of its femur bone.
Food plan Clues From Abdomen Stones
Contained in the fossil, scientists additionally discovered dozens of gastroliths, small stones that the dinosaur swallowed to assist digest meals. These stones counsel the animal had an omnivorous food regimen that included crops, bugs, and small animals.
The presence of those stones additionally inspired researchers to research additional. As a result of gastroliths are small and lightweight, their intact association indicated that a lot of the skeleton would possibly nonetheless be preserved throughout the rock.
“Somewhat cluster of abdomen stones, with two leg bones protruding signifies that the animal was not absolutely pulled aside earlier than it has hit the fossil report,” Clarke mentioned. “So, I inspired [Jung and co-authors Minguk Kim and Hyemin Jo] to go to Texas and the UTCT, to strive scanning the fossil.”
Extra Discoveries Might Be Hidden in Rock
Kim and Jo at the moment are making use of the CT scanning strategies they discovered to different fossils in Korea. Jung additionally plans to return to Aphae Island to seek for extra specimens.
South Korea is well-known for fossilized dinosaur tracks, nests, and eggs, however precise dinosaur bones are comparatively uncommon. Researchers consider that many fossils should still be hidden inside rock, identical to Doolysaurus.
Jung is optimistic that continued use of micro-CT expertise will uncover extra discoveries.
“We’re anticipating some new dinosaur or different egg fossils to return from Aphae and different small islands,” he mentioned.
Quite a bit has occurred in CSS in the previous couple of years, however there’s nothing we wanted lower than the upcoming Olfactive API. Now, I do know what you’re going to say, increasing the net in a extra immersive manner is an efficient factor, and basically I’d agree, however there’s no generalized {hardware} assist for this but and, for my part, it’s an excessive amount of, too early.
First let’s take a look at the {hardware}. Disney World and different theme parks have completed some area of interest so-called 4D films (which is nonsense since there isn’t a fourth dimensional side, and should you contemplate time the fourth dimension then each film is fourth dimensional). And some startups have tried to carry olfactory senses into the trendy day, however as of this writing, the {hardware} isn’t consumer-ready but. That stated, it’s in energetic improvement and one startup assured me the expertise can be out there inside the yr. (And startups by no means, ever lie about when their merchandise will launch, proper?)
Even when it does come out inside the yr, would we even need this? I imply Scent-O-Imaginative and prescient completely caught on, proper? It’s positively not thought of one of many worst innovations of all time… However, alas, nobody cares in regards to the ravings of a mad man, at the very least, not this mad man, so the API rolls on.
Alright, I’m going to step off my cleaning soap field now and attempt to concentrate on the expertise and the way it works.
Scent Tech
One of many fights at present occurring within the CSS Working Group is whether or not we must always restrict smells to these thought of pleasing by the fragrance business or whether or not to open web sites to a a lot wider selection. For example, whereas everybody’s olfactory sense is totally different, the fragrance business has centered on a choice of fragrances that can be pleasing to a large swath of individuals.
That stated, there are a lot of pleasing fragrances that will not be included on this, akin to food-based smells: recent baked bread and so forth. Fragrances that the Massive Meals Foyer is itching to incorporate of their ads. As of now the CSS Olfactive API solely contains the twelve common classes utilized by the fragrance business, however identical to there are methods to increase the colour gamut, the system is constructed to permit for expanded smells sooner or later ought to the variety of out there perfume fragments enhance.
Smelly Households
You don’t must look far on-line to seek out one thing known as the Scent Wheel (alternately known as the Perfume Wheel or the Wheel of Scent-Tune, however that final one is simply utilized by me). There are 4 bigger households of scent:
Floral
Amber (beforehand known as Oriental)
Woody
Contemporary
These 4 are every subdivided into extra classes although there are overlaps between the place one of many bigger households begins/ends and the sub households start/finish
Floral:
Floral (fl)
Mushy Floral (sf)
Floral Amber (fa)
Amber:
Mushy Amber (sa)
Amber (am)
Woody Amber (wa)
Woody:
Woods (wo)
Mossy Woods (mw)
Dry Woods (dw)
Contemporary (fr)
Fragrant (ar)
Citrus (ct)
Water (ho)
Inexperienced (gr)
Fruity (fu)
It’s from these fifteen perfume classes {that a} scent will be made by mixing totally different quantities utilizing the 2 letter identifiers. (We’ll speak about this once we focus on the scent() operate afterward. Word that “Contemporary” is the one giant household with its personal identifier (fr) as the opposite bigger households are duplicated within the sub-families)
Implementation
Initially, its carried out (correctly) in HTML in a lot the identical manner video and audio are with the addition of the component, and was once more used to provide the browser totally different choices for wafting the scent towards your sniffer. Three competing file codecs are being developed .smll, .arma, and, I child you not, .smly. One by Google, one by Mozilla, and one, once more, not kidding, by Frank’s Fantastic Fragrances who intends to leap on this “fourth dimension of the net.”
For accessibility, ensure that you set the autosmell attribute to none. In concept, this isn’t required, however a number of the present {hardware} has a bug that activates the wafter even when a scent hasn’t been activated.
Nevertheless, just like how you need to use a picture or video within the background of a component, you too can connect a scent profile to a component utilizing the brand new scent-profile property.
scent-profile can take considered one of three issues.
The key phrase none (default):
scent-profile: none;
A url() operate and the trail to a file e.g.:
scent-profile: url(mossywoods.smll);
Or a set of fragrant identifiers utilizing the scent() operate:
scent-profile: scent(wo, ho, fu);
This produces a scent that has notes of woody, water, and fruity which was described to me as “an orchard within the rain” however to me smelled extra like “a picket bowl of watered-down applesauce.” Please take that with a grain of salt, although, as I’ve been informed I’ve “the nasal palette of a useless fish.”
You may add as much as 5 scent sub-families without delay. That is an arbitrary restrict, however greater than that will possible muddle the scent. Equal quantities of every can be used, however you need to use the brand new whf unit to regulate how a lot of every is used. 100whf is probably the most potent an aroma will be. In contrast to most items, your implementation, should add as much as 100whf or much less. In case your numbers add as much as greater than 100, the browser will take the primary 100whfs it will get and ignore all the pieces afterward.
scent-profile: scent(wo 20whf, ho 13whf, fu 67whf);
…or you can scale back the general scent by selecting whfs lower than 100:
scent-profile: scent(wo 5whf, ho 2whf, fu 14whf);
Sooner or later, ought to different fragrances be allowed, they’d merely want so as to add some new perfume fragments from which to assemble the fragrant air.
Sniffing Out Limitations
One giant concern for the working group was that some developer would go loopy inserting scent-profiles on each single component, each overwhelming the person and muddling every scent used.
As such it was determined that the browser will solely permit one scent-profile to be set per the guardian component’s sub tree. This mainly signifies that when you set a scent-profile on a selected component you can not add a scent profile to any of its descendants, nor are you able to add a scent profile to any of its siblings. On this manner, a scent profile set on a hungry selector (e.g. * or div) will create a fraction of the scent profiles than what may in any other case be created. Whereas there are clearly straightforward methods to maliciously get round this limitation, it was thought that this could at the very least stop a developer from unintentionally overwhelming the person.
Fragrant Accessibility
Since aromas will be overpowering they’ve additionally added a media-query:
Surprisingly, regardless of Chrome Canary actually being named after a fowl who would scent fuel within the mine, Chrome has not but begun experimenting with it. The one browser you may take a look at issues out on, as of this writing, is the KaiOS Browser.
Conclusion
There you’ve gotten it. I nonetheless don’t suppose we want this, however with the persevering with march of expertise it’s most likely not one thing we are able to cease. So let’s make an settlement between you studying this and me right here penning this that you simply’ll at all times use your new-found olfactory powers for good… and that you simply received’t ever say this text stinks.