Proper to restore efforts are gaining headway within the US. Numerous that motion has been led by state laws in Colorado.
Since 2022, Colorado has handed payments giving customers the instruments, directions, and authorized capabilities to repair or improve their very own wheelchairs, agricultural farming gear, and shopper electronics. Related efforts have rippled out via the nation, the place restore payments have been launched in each US state and handed in eight of them.
“Colorado has the broadest restore rights within the nation,” says Danny Katz, govt director of CoPIRG Basis, the Colorado department of the buyer advocate group Pirg. “We needs to be pleased with main the best way.”
Producers are typically much less supportive of right-to-repair efforts, as companies stand to make more cash charging for instruments, alternative components, and restore companies than in the event that they had been to simply let folks make things better on their very own. Some corporations have begrudgingly agreed to make their merchandise extra repairable. Some have began actively pushing again in opposition to new legal guidelines meant to allow that.
At this time at a listening to of the Colorado Senate Enterprise, Labor, and Know-how committee, lawmakers voted unanimously to maneuver Colorado state invoice SB26-090—titled Exempt Essential Infrastructure from Proper to Restore—out of committee and into the state senate and home for a vote.
The invoice modifies Colorado’s Client Proper to Restore Digital Digital Tools act, which was handed in 2024 and went into impact in January 2026. Whereas the protections secured by that act are huge, the brand new SB26-090 invoice goals to, “exempt data expertise gear that’s meant to be used in important infrastructure from Colorado’s shopper proper to restore legal guidelines.”
The invoice is supported by tech producers like Cisco and IBM, in accordance with lobbying disclosures. These are corporations which have vested pursuits in manufacturing issues like routers, server gear, and computer systems, and stand to revenue if they will management who fixes their merchandise and the instruments, elements, and software program used to make these upgrades and repairs. In addition they cite cybersecurity issues, saying that giving folks entry to the instruments and techniques they would wish to restore a tool may additionally allow unhealthy actors to make use of these strategies for nefarious means. (It is a frequent argument producers make when opposing proper to restore legal guidelines.)
“IBM helps right-to-repair insurance policies that empower customers whereas defending cybersecurity, mental property, and demanding infrastructure,” wrote an IBM spokesperson in an e mail to WIRED. “Given the important and infrequently delicate nature of enterprise-level merchandise, any laws needs to be clearly scoped to shopper units.”
Cisco didn’t reply to WIRED’s request for remark, however within the listening to a Cisco consultant mentioned, “Cisco helps SB-90. Whereas it appreciates the arguments provided in favor of the appropriate to restore, not all digital expertise units are equal.”
Throughout the listening to, greater than a dozen restore advocates spoke from organizations like Pirg, the Restore Affiliation, and iFixit opposing the invoice. YouTuber and restore advocate Louis Rossmann was there. The primary drawback, restore advocates say, is that the invoice intentionally makes use of obscure language to make the case for controlling who can repair their merchandise.
“The ‘data expertise’ and ‘important infrastructure’ factor is as cynical as you possibly can probably be about it,” says Nathan Proctor, the chief of Pirg’s US proper to restore marketing campaign. “It sounds scary to lawmakers, but it surely simply means the web.”
Although not clearly outlined within the invoice, “data expertise” normally means tech like servers and routers. “Essential infrastructure” is language taken from a 2001 federal laws that defines the time period as, “techniques and belongings, whether or not bodily or digital, so very important to the US that the incapacity or destruction of such techniques and belongings would have a debilitating affect on safety, nationwide financial safety, nationwide public well being or security, or any mixture of these issues.”
I feel any press one who watched President Trump’s Iran cheer-up session speech on fact serum must concede that this was a speech he shouldn’t have given. He meandered. He seemed unhealthy and worn out. He had the requisite moments when his degenerate internal monologue creeps into the open: he stated that free passage by way of the Strait of Hormuz is one thing for importer nations in Asia to take care of, that they need to “seize and cherish” the Strait, as if it had been some underage magnificence pageant contestant Trump was hungering to assault. [He also announced the US was “hottest country anywhere in the world by far, with no inflation.’’ which was both off topic and not exactly reality based — MP] “What’s vital is that in political and public opinion phrases, there was nothing new or newsworthy on this speech. They didn’t even handle to perform this within the slim and cynical sense of claiming something new that could possibly be a recent level of public dialogue. It was a rambling set of unconvincing excuses nobody with any actual concern or nervousness about this warfare (the one actual viewers) would discover convincing. Why are you complaining, he asks? This warfare hasn’t gone on almost so long as World Warfare II! LOL.
There’s no announcement coming. There isn’t any plan.
The “taco commerce” was at all times primarily based on a number of fallacies: the belief that Trump would cease doing this silly/loopy factor earlier than it did any harm; the belief that he wouldn’t revert to the disastrous coverage; and the belief that the backing out couldn’t go within the incorrect course.
We have now seen no less than one case of a “double taco,” the place Trump was frightened away from a place that was costing him politically, solely to be frightened again into it by worry of MAGA backlash. I understand occasions appear compressed on this administration—it’s tough to imagine it’s been just a bit over one yr—however it wasn’t that way back that Trump, underneath strain from the agricultural sectors in his base, publicly reversed his place on mass deportation of farm employees, solely to flip-flop once more nearly instantly when Stephen Miller received to him.
There are quite a few causes to imagine that we’ve simply seen one other double taco, this time with the administration coming very near a humiliating however most likely best-deal-he-was-going-to-get give up, beginning with the speech itself (Why request community time to perform nothing however spooking the markets?). There have been indications that the Iranians had been getting ready for a ceasefire up till some level throughout Trump’s speech. Even the Israelis appeared to be getting ready for an American withdrawal.
It was, as talked about earlier than, an unpleasant alternative, however it might have alleviated most of Trump’s fast issues—and, provided that the markets had skyrocketed on the mere chance, they unquestionably would have rewarded something that ended the warfare.
Nonetheless, as finest we are able to inform, shortly earlier than the time got here to tug off the Band-Assist, Trump once more chickened out, most likely spooked by the inevitable backlash to capitulation. Probably—given what we all know concerning the man—nonetheless enraged by that day’s Supreme Courtroom proceedings.
Regardless, one other month of warfare will deliver critical ache factors by way of oil/LNG, helium, fertilizer, and vital stagflationary strain on the financial system—to not point out great human struggling.
I stay desirous about attempting to grasp how the way by which you extract the inputs wanted to calculate t-statistics from printed work can provide false positives when checking for p-hacking. This substack is about me strolling you thru this once more, however utilizing a stroll by video, a shiny app, in addition to a transcript of my change with Claude Code the place I figured this out myself. Right here is the transcript for individuals who need to see how I have a tendency to make use of Claude Code, much less as an automator and extra as a “considering companion”.
Thanks once more for studying! I hope you take pleasure in this submit. This can be a reader supported substack and as earlier than, all Claude Code posts will probably be out there free to everybody till they mechanically go behind a paywall (all posts ultimately go behind a paywall, however solely the non-Claude Code ones are randomly paywalled instantly).
Right here is the earlier submit from March twenty ninth the place I posted that I’d found out the extraction technique I had used to recreate t-statistics from the APE venture’s AI generated papers was giving false positives for p-hacking.
Let me simply overview a number of issues, although, in order that this submit stands sufficient alone that it may be learn.
Once we run a regression, we get a coefficient and we get a typical error. These are the 2 inputs used for our speculation assessments apart from a vital worth and a call rule. The choice rule will probably be a model of “if the t-statistic exceeds some vital worth, then reject at alpha equal to some fraction I’ve picked”. We use the vital worth of 1.96 due to the central restrict theorem. Underneath the legislation of enormous numbers, the imply of the calculations from the implied counterfactual samples related to an estimator’s sampling distribution is at all times centered on the true inhabitants estimand. And underneath the central restrict theorem, that sampling distribution is regular as n goes to infinity. The massive of enormous numbers tells us in regards to the imply, and the central restrict theorem tells in regards to the form, and we use the form, primarily, for calculating p-values. And we decide 1.96 as a result of for the traditional distribution, 95% of all chance is mass is inside 1.96 commonplace deviations from the imply (in both route).
So in case you run a regression, your package deal used will provide you with a number of the outcomes of speculation assessments. For one you’ll get a t-statistic, which is the “true ratio of the true coefficient and the true commonplace error”. You’ll get a p-value related to that t-statistic (what share of the remaining elements of the tail have t-statistics bigger than your t-statistic?). And also you’ll most likely get a 95% confidence interval. They comprise a lot of the identical info, with slight twists, and all of them are simply misunderstood by folks with no depth of statistical literacy.
However my level is that you’ll be making all of these speculation testing calculations off the “actual coefficients” and “actual commonplace errors” and never the rounded ones.
None of that is truly an issue, although. You around the coefficients and commonplace errors as a result of they the rounded numbers are solely executed for the aim of speaking outcomes. The rounded numbers will not be themselves used for any subsequent speculation testing calculations. The one purpose it issues on this case is that in case you are extracting the inputs from tables to assemble your individual t-statistics for a take a look at of p-hacking, then you’ll have measurement error that’s instantly pointing to a t-statistic of two, paradoxically. Put one other means, rounded coefficients and rounded commonplace errors at all times create heaping. It’s not simply that you just introduce measurement error — it’s that if you find yourself rounding these final two digits, you might be principally collapsing the ratio (for ratios that had been in both route) into a selected set of discrete numbers. The t-statistic will not be steady any extra.
So if rounding is at all times creating comparatively extra heaps after rounding than earlier than, the one factor that can make such issues visibly stand out is that if there are a variety of such situations proper round there within the first place.
There are literally a variety of methods to take a ratio of two single digit integers and get precisely 2. It’s truly the second commonest ratio you will get, the opposite being to get a ratio of 1. Let me present you all of the methods you get take two single digit integers and get a ratio of precisely 2:1.
2 / 1 = 2
4 / 2 = 2
6 / 3 = 2
8 / 2 = 2
What a couple of ratio of precisely 3:1 although? That one is more durable. There’s solely to was to take single digit integers, take a ratio, and get 3. They’re:
3 / 1 = 3
9 / 3 = 3
The one one that’s bigger than 2 is a ratio equalling 1. And there are 9 methods to take a ratio of single digit integers to get a price of 1. They’re:
1 / 1 = 1
2 / 2 = 1
3 / 3 = 1
And so forth.
So the difficulty is that when you’ve gotten numbers with main zeroes earlier than and after the decimal level (e.g., beta hat = 0.00313 vs beta hat = 3.313), the rounding you do is definitely creating de facto “single digit integers” for the aim of this instance. Have a look at the instance beneath that Claude Code gave me in our dialog to see what I imply. Now these will not be simply the only digit examples; you’ve received included issues like 18/9 and 12/6. However that’s simply one other means of explaining all of the spikes within the rounded to the thousandth case.
There are a number of shifting elements to this synthetic proof for p-hacking related to easy counting of t-statistic values. The opposite that isn’t as apparent I feel is the standard relationship between a regression coefficient’s personal worth and the dimensions of the end result itself.
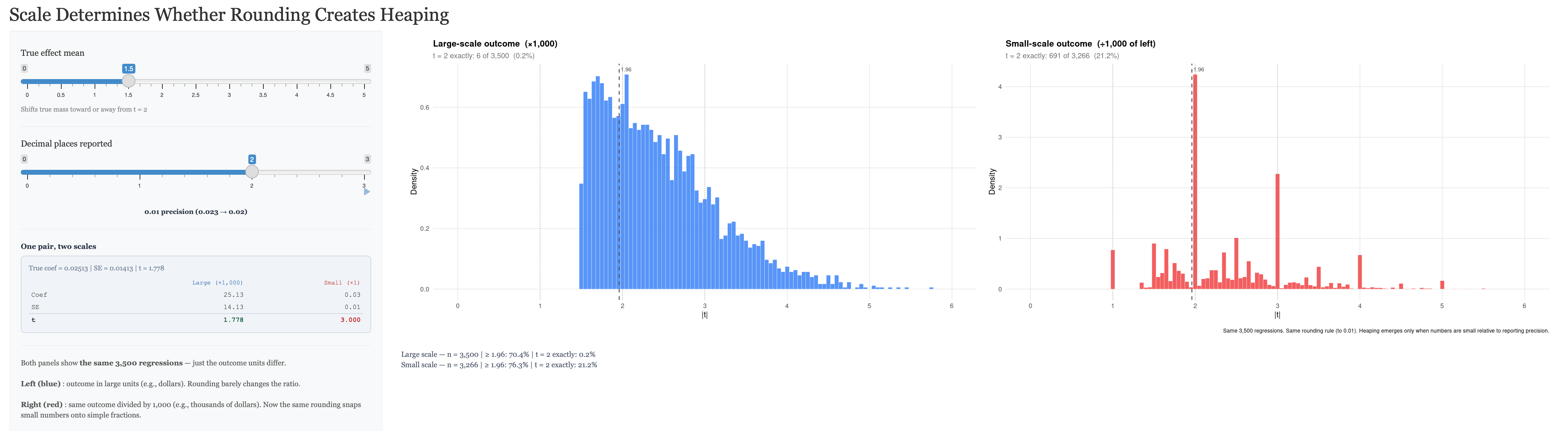
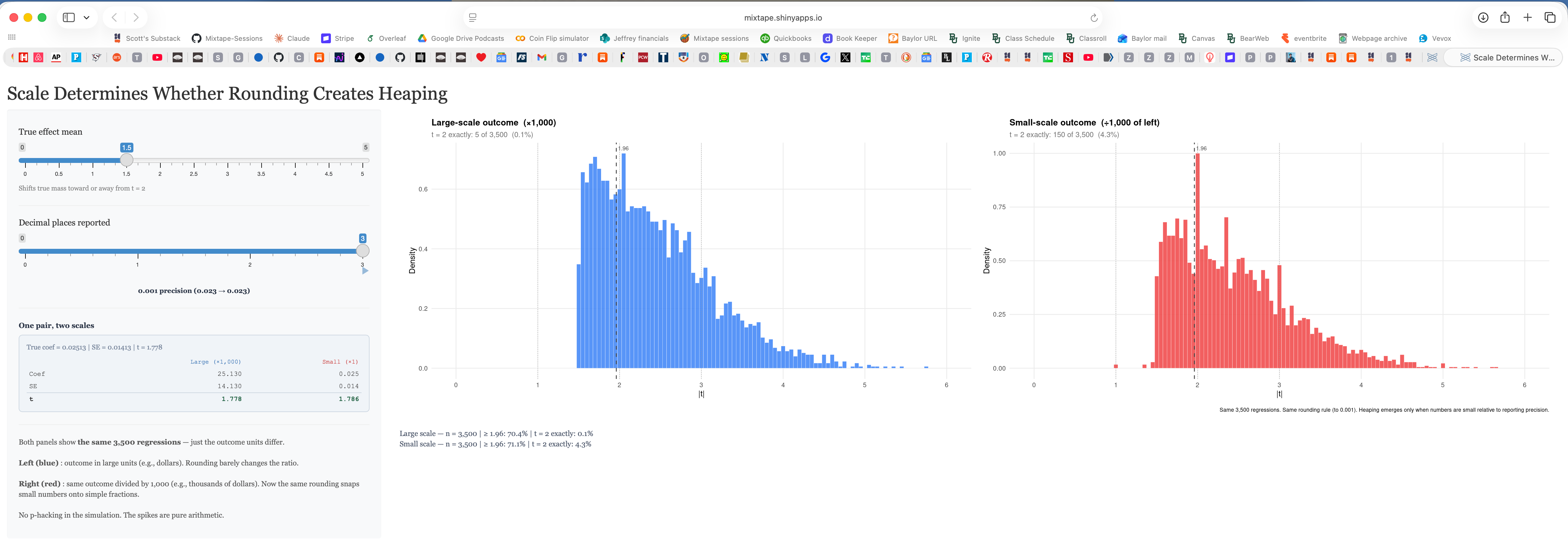
Right here is an instance from the shiny app. The one on the left is when the dimensions is ‘giant’, and the one on the fitting is when the dimensions is ‘small’. And also you get the heaping on integers (and notably at 2) on the fitting however not the left. The correct being the small scaled end result and the left being its authentic scale. Why is that this occurring?
While you regress a quantity like annual earnings onto a dummy variable for faculty, the coefficient on faculty can have many numbers forward of the 0. So as an example, it is likely to be beta = $25,123.45 with a typical error of $5,456.78 giving a t-statistic of 4.6040796954. In the event you rounded these numbers, perhaps you’d spherical to the entire quantity: beta = $25,123 and a typical error of $5,457 and a t-statistic of 4.6038116181.
However when in case you had at all times for no matter purpose divided your earnings information by 10,000 first after which ran the regression. Nicely, in case you did that, your beta coefficient can also be scaled by 10,000 and your commonplace error too, however not your t-statistic. Your t-statistic is “scale invariant”. No matter you probably did to the information does rescale the coefficients and commonplace errors, nevertheless it does so proportionally, and thus the t-statistic being a ratio stays precisely the identical.
So in case you spherical coefficients and commonplace errors for tables, executed purely for rhetorical functions not scientific ones, you truly received’t change the t-statistic on your speculation assessments as a result of the t-statistic executed on your speculation assessments relies on non-rounded ones. However, in case you are a 3rd social gathering extracting the coefficients and commonplace errors from tables, which had been rounded for rhetorical functions, to assemble t-statistics, they are going to at all times be heaped regardless that the precise p-values within the papers themselves can have been executed off the true t-statistic, and never the one the third social gathering simply pulled.
The one means subsequently that you just’d falsely reject the null was if two issues had been true. First, the distribution of t-statistics should have giant mass round 2 within the first place. You’ve gotten easy features with focus round 2 and nonetheless not have the sort of bunching that density assessments are designed to choose up, thoughts you. In order that’s the very first thing — you’d must have a variety of true t-statistics in that neighborhood of two to ensure that there to be heaps at 2 after you collapse. And you’ll frankly want the dimensions of the end result to most likely be small.
The second shouldn’t be actually a principled assertion, however I’m saying in follow, with causal research, the place so typically the therapy variable is binary, then you definately’re going to be extra prone to decide up “small coefficients and small commonplace errors” (which means numbers with a number of zeroes after the decimal level first) when the end result was already small in scale. I feel it’s intuitive when you concentrate on it too.
Return to that instance the place you might be regressing whole annual earnings onto a dummy. Your coefficient on the dummy is prone to be giant too. You received’t get a t-statistic of precisely 2, moreover, even in case you spherical as a result of in such situations “rounding” is at all times about placement close to the decimal level. So you probably have a quantity like 1,527.345, rounding means to indicate 1,527. It doesn’t imply exhibiting 15, and it for positive doesn’t imply exhibiting 2. Rounding is in different phrases about coping with fractions for show functions. And so because of this, many of the ratio worth will probably be unchanged by rounding as a result of 1527 and 1527.345 within the numerator are kind of going to be the identical factor.
But when the dimensions had been small to start with, then perhaps your coefficient and commonplace error would’ve been extra like 0.01527 and 0.00456. So then the rounding does find yourself pushing you in direction of these explicit pairs I mentioned as you chop off increasingly more of the final digits.
I wished to now share a shiny app I made with Claude Code’s assist for example this. I even have a video stroll by. Let me share them each now. The video stroll by takes you thru the shiny app, as I’m nonetheless undecided I absolutely made a really intuitive shiny app within the first place. So I wished to simply assist you see easy methods to interpret this stuff as there are a number of shifting elements. Bear in mind the shifting elements are:
Rounding coefficients and commonplace errors for desk functions
Extracting rounded coefficients and rounded commonplace errors by a 3rd social gathering for the needs of reconstructing a t-statistic
The arithmetic implied by why rounded numbers can attain the quantity 2 so simply than 1.5 or 3 or most different numbers
The precise circumstances underneath which rounding coefficients and commonplace errors will give inflated t-stats at t=2 and result in false positives that there’s p-hacking when there isn’t
The position that the dimensions of the left-hand-side variable performs in all of this.
And the video simply walks you thru it. The precise shiny app is right here although. And sure that’s round 10,000 open tabs. Tune in Saturday morning when I’ll submit all of them.
Watch the video, have Claude Code learn this substack, learn it your self, however I feel between all of it you possibly can most likely work out the purpose I’m making.
So what I’m going to do subsequent is I’m going to do an explainer on the historical past of the Brodeur p-hacking papers, however much less so on the findings, and moreso in relation to those rounding issues. And the reason being as a result of Brodeur, et al., like me, had extracted their t-statistics from 50,000 regressions utilizing tables, which had been rounded, and apparently sufficient, the consequence of rounding was correlated with which analysis design the researchers used.
What I didn’t know is that within the evolution of these papers, the “repair” for this rounding problem that Brodeur et al had executed initially didn’t actually repair it. A staff wrote a remark within the AER pointing it out. Brodeur, et al. responded graciously, acknowledging the issue, and when an accurate repair was employed to beat it, the proof for p-hacking in difference-in-differences went away. The p-hacking for diff-in-diff was actually an artifact of the extraction technique. Instrumental variables nonetheless confirmed indicators of p-hacking, however diff-in-diff didn’t. Not on the 1.96 vital worth anyway (they are saying there’s nonetheless one thing on the 10% stage once they do the repair).
For the reason that AI generated papers on the Social Catalyst’s Lab APE Venture are overwhelmingly utilizing DiD, this extraction technique I used was notably delicate to it. And I simply thought I ought to actually attempt to make this stuff as clear as I can. I additionally really feel like this substack can attempt to educate others in regards to the mindset to be having for when David and them launch their very own evaluation of the AI papers. The problem they’ll have is that they must get the “true t-statistic” from the uncooked regression information, however because the AI brokers weren’t producing t-statistics, however slightly normally simply reporting asterisks (I discovered that additionally which I can present one other time) for tiers of p-values (e.g., ** if p<0.05), then the “true t-statistic” shouldn’t be within the papers, neither is it actually even being saved anyplace. In order that they’d must go subsequently write a brand new script to return and recollect all of it. However in contrast to any third social gathering doing meta-analysis on different folks’s work, that is truly doable. Often, it’s not.
AI adoption is accelerating, and it comes with a surge in bandwidth demand, low-latency necessities, and operational complexity. For broadband service suppliers, the strain is rising as video analytics, generative AI (GenAI) brokers, immersive purposes, and enterprise automation reshape community site visitors patterns.
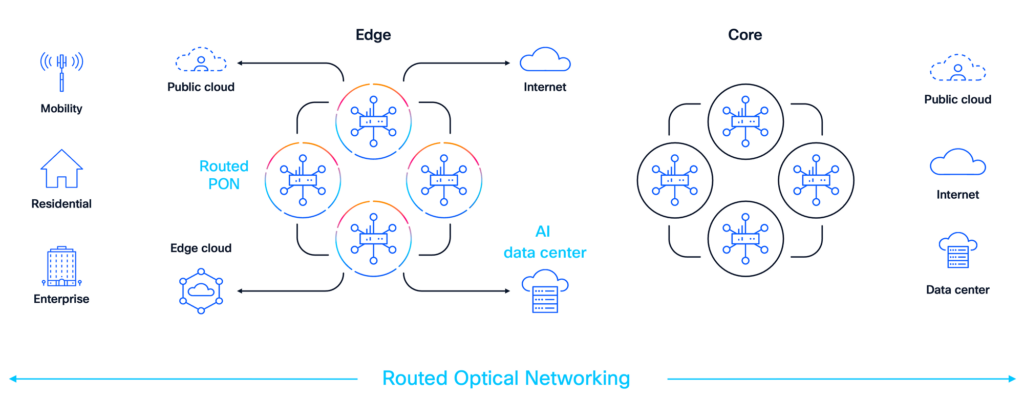
TheCisco Agile Companies Networking and Cisco Unified Edge platforms have been constructed to assist suppliers meet these challenges. They create scalable, service-centric, AI-ready foundations that assist cut back community pressure, allow differentiated companies, and help sustainable income progress.
Determine 1: A pattern community structure with Cisco Routed PON used within the entry community—one of many many Agile Companies Networking options that groups can implement to ship high quality buyer experiences whereas controlling prices
Lowering backhaul demand with native AI processing
Many AI workloads, particularly inferencing, originate on the community edge: cameras, sensors, Wi-Fi gadgets, enterprise purposes, and buyer gear. Historically, uncooked knowledge is transported again to the core or cloud for processing, putting heavy load on transport and backhaul networks.
Cisco Unified Edge modifications this mannequin by putting compute, storage, and inferencing capabilities immediately on the edge, together with metro factors of presence (POPs), aggregation websites, and enterprise areas.
Advantages embody:
Much less uncooked knowledge flowing via the spine
Decreased peak bandwidth utilization
Decrease congestion within the core community
By performing inferences the place knowledge is generated, suppliers can considerably lower backhaul necessities and enhance effectivity.
Enabling ultra-low-latency AI experiences
Actual-time AI purposes require extraordinarily low latency. These embody video analytics, interactive brokers, AR/VR, sensible retail automation, and industrial controls.
Unified Edge processes inference near the top consumer, enabling constant, low-latency efficiency with out counting on distant cloud areas. This makes broadband networks succesful platforms for high-performance, latency-sensitive AI companies.
Powering clever site visitors prioritization and service assurance
As AI site visitors grows, it competes with all different broadband companies. Agile Companies Networking addresses this problem via a service-centric structure designed for policy-based site visitors management.
Agile Companies Networking allows:
Prioritization and classification of AI and non-AI site visitors
Predictable latency, jitter, and efficiency via QoS and slicing
Multidomain service assurance throughout entry, metro, and core
Assist for differentiated service tiers and enterprise fashions
This helps guarantee AI workloads get the efficiency they want with out overrunning the community.
Delivering automation at scale for distributed edge websites
As extra edge areas come on-line, managing them manually turns into impractical. Cisco supplies automation and centralized operations throughout each Agile Companies Networking and Unified Edge, together with:
Zero-touch provisioning
Constant coverage automation
Unified lifecycle administration
Streamlined deployment of AI workloads and updates
This allows operators to scale edge compute and AI companies with out proportional will increase in operational price.
Offering real-time observability and AI-driven community optimization
AI-driven purposes produce dynamic site visitors patterns. Agile Companies Networking contains deep observability and helps closed-loop automation to adapt the community in actual time.
Community operators can:
Detect congestion and anomalies
Modify site visitors courses or slices immediately
Shift workloads to accessible edge websites
Increase or contract service capability routinely
This establishes the inspiration for autonomous broadband operations.
Unlocking new AI-driven income alternatives
As a substitute of treating AI as a price driver, Agile Companies Networking and Unified Edge permit suppliers to show it right into a enterprise alternative.
Doable choices embody:
Premium low-latency paths for AI site visitors
Hosted inference companies on the edge
Managed edge compute for enterprises
Video analytics and automation companies
Assured connectivity tiers for AI-intensive prospects
This creates sustainable service fashions that align with rising enterprise AI demand.
Securing distributed, data-sensitive AI workloads
Unified Edge allows delicate or regulated knowledge to be processed domestically, decreasing publicity and assembly compliance necessities. Agile Companies Networking extends this by offering safe, policy-driven transport and isolation throughout your complete community. This mix provides end-to-end safety for distributed AI purposes.
Empowering broadband suppliers to thrive at the moment—and tomorrow
AI transforms purposes, workflows, and buyer expectations. Visitors is rising, latency necessities are tightening, and enterprises are looking for real-time experiences delivered at scale.
Cisco Agile Companies Networking supplies the automated, service-aware, assured transport basis wanted to fulfill these new calls for.
CiscoUnified Edge delivers AI compute and inference capabilities near subscribers.
Collectively, they assist broadband suppliers cut back community pressure, ship superior AI-powered companies, and unlock new income fashions whereas getting ready for the subsequent decade of AI-driven progress.
Groups additionally have to plan for novelty sporting off. Early on, folks give the system a move when it stumbles. That wears off quick. Round week two or three, the comparability shifts. Individuals cease considering ‘that’s fairly good for AI’ and begin considering ‘my admin assistant would have gotten that proper’. At work, everybody already is aware of what competent assist seems like: The assistant who juggles calendars, the IT one that fixes issues with out being requested twice, the colleague who by no means forgets to ship the agenda. That’s the bar, and the one option to see whether or not the system goes to clear it over time is longitudinal analysis.
Design issues, not engineering ones
The issues with enterprise voice AI aren’t technical mysteries. The fashions work. What’s been lacking is treating voice AI as a UX downside from the beginning, making use of analysis apply to the particular challenges that voice and agentic AI create in enterprise collaboration. Social threat, autonomous belief selections, the hole between what the system can do and what folks will really depend on: These are design issues, not engineering ones.
As voice AI brokers develop extra autonomous, the query researchers and builders ought to be asking collectively isn’t ‘does this work?’ It’s ‘do folks belief it sufficient to let it act on their behalf, in entrance of different folks, with out checking its work first?’ That’s the actual adoption threshold. The strategies and ideas to get there are nicely understood. What issues now could be whether or not groups put UX researchers within the room early sufficient to make use of them.
On March 25, 2026, Google Analysis revealed a weblog put up a few compression algorithm known as TurboQuant.
Inside 48 hours, SK Hynix had misplaced 7.3% of its market worth. Micron dropped 3%. Western Digital fell 4.7%. SanDisk gave up 5.7%. Kioxia, the Japanese flash reminiscence firm, dropped almost 6%. The selloff unfold throughout two continents, wiping out tens of billions in market cap.
Cloudflare’s CEO Matthew Prince known as it “Google’s DeepSeek second.” Half the web in contrast it to Pied Piper, the fictional startup from HBO’s Silicon Valley. The memes moved quicker than the precise analysis.
So what truly occurred? And does this algorithm change something in regards to the reminiscence scenario the AI trade has been panicking about for the previous 18 months?
Let’s decode.
Why Fashionable AI Is So Hungry for Reminiscence
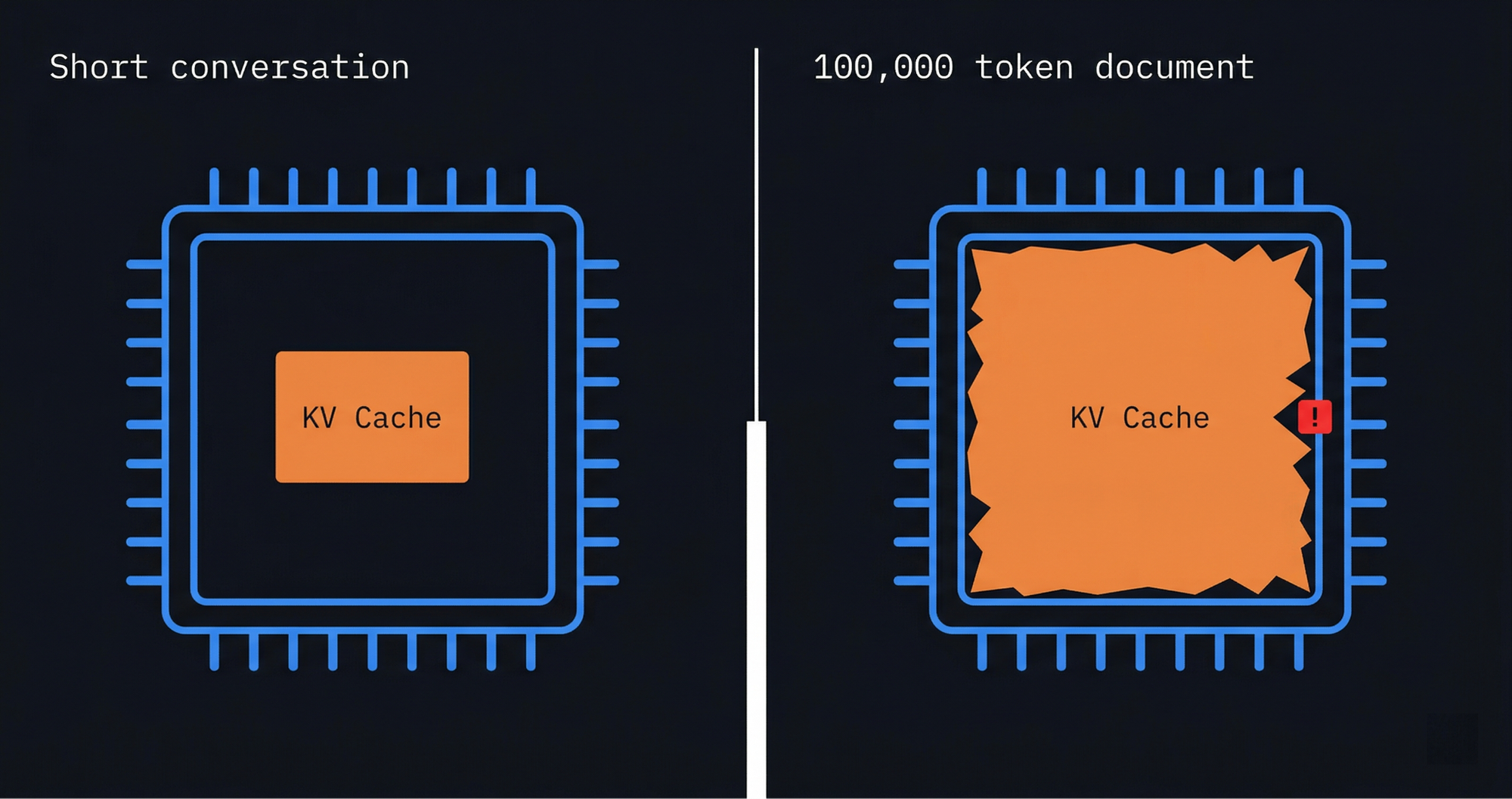
When an LLM generates textual content, it would not recompute every little thing from the start with each new phrase. As an alternative, it shops all its prior calculations in a fast-access buffer known as the key-value cache, or KV cache. Each token the mannequin has seen in a dialog will get saved there, so when the mannequin processes the following token, it could look again at what got here earlier than with out redoing all the mathematics.
The issue is the cache grows constantly. A mannequin working by means of a 100,000-token doc is holding an enormous quantity of energetic information in GPU reminiscence simply to take care of context. And this received considerably worse when reasoning fashions turned mainstream. Reasoning means lengthy context, lengthy context means a big KV cache, massive KV cache means you want numerous reminiscence. By 2024, anybody taking note of the trajectory of AI fashions might see the place this was heading and the market largely did not catch up till costs began reflecting it.
How the KV Cache Fills a GPU: Quick Dialog vs 100,000 Token Doc
And the trade has been combating this downside for years, with real ingenuity, and TurboQuant is the most recent step in that arc.
What TurboQuant Is and How It Works
TurboQuant compresses that KV cache down to three bits per worth, from the usual 16. The claimed discount is 6x in reminiscence footprint, with an 8x speedup in consideration computation on Nvidia H100 GPUs, and no measurable accuracy loss in benchmarks.
The mathematics works in two levels.
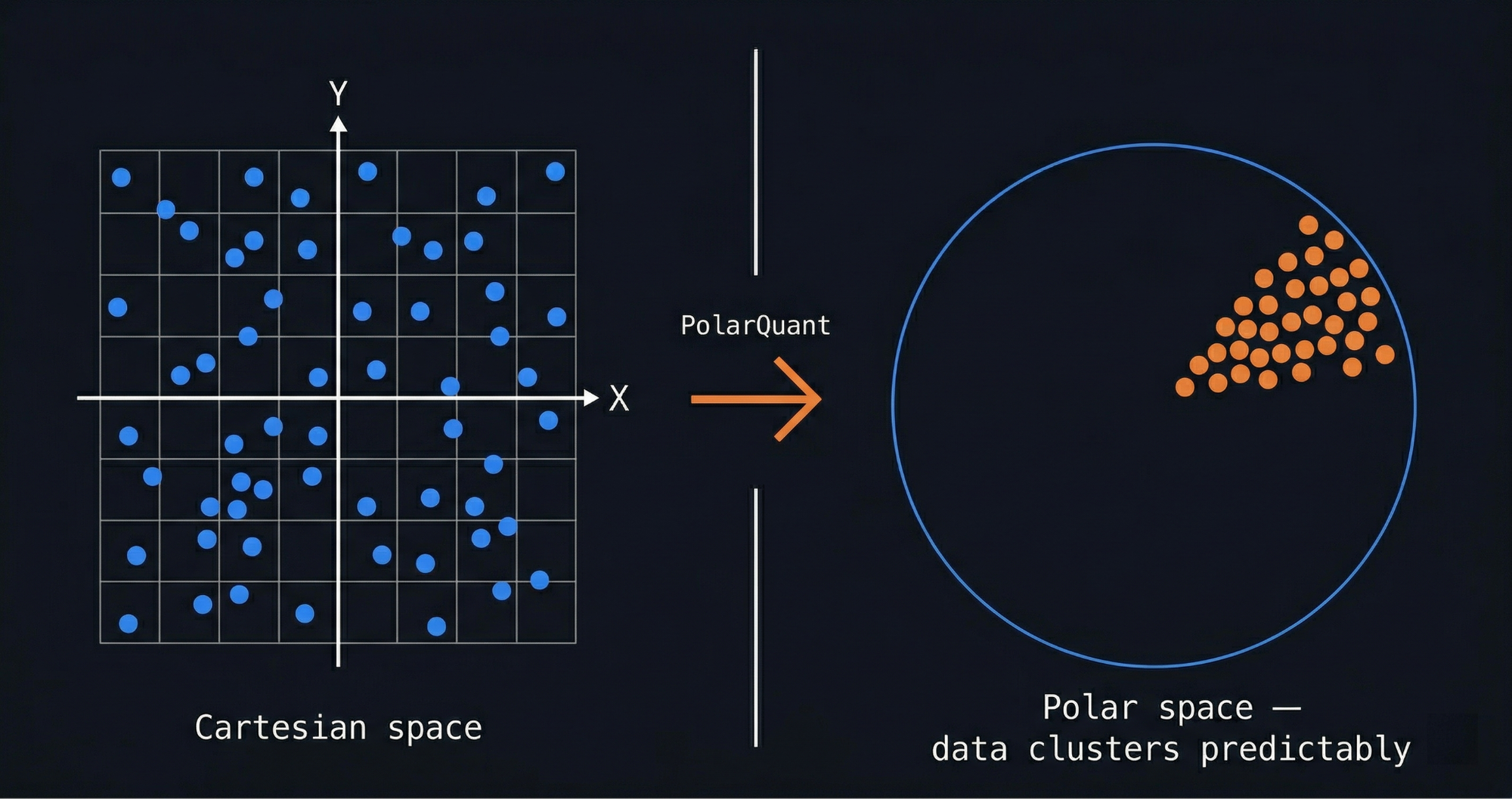
The primary stage, PolarQuant, converts information vectors from Cartesian coordinates into polar coordinates. In Cartesian kind, a degree is described by how far it sits alongside the X axis and Y axis: a grid of (x, y). In polar kind, the identical level is described by its distance from the origin (r) and the angle it makes from a reference route (θ). The conversion is: r = √(x² + y²) and θ = arctan(y/x). Going again: x = r·cos(θ) and y = r·sin(θ). In larger dimensions, the identical precept extends.
Why this issues for compression is as a result of in polar house, the angular distribution of AI consideration information clusters in predictable, concentrated patterns. Conventional quantization strategies need to retailer further normalization constants alongside compressed information so the system can decompress precisely later. These constants add one or two bits per worth proper again in, partially undoing the financial savings. PolarQuant eliminates that overhead as a result of the construction of the info in polar house makes these constants pointless.
How Cartesian Information Clusters in Polar House to Allow KV Cache Compression
The second stage handles the residual error left over from stage one. Every leftover error quantity will get diminished to a single signal bit, optimistic or unfavorable. That signal bit acts as a statistical zero-bias corrector, that means the compressed cache stays equal to the full-precision unique when the mannequin computes consideration scores. The mannequin would not discover the distinction.
Google examined TurboQuant on 5 customary benchmarks for long-context fashions, together with LongBench and Needle in a Haystack, utilizing Gemma, Mistral, and Llama. At 3 bits, it matched or beat KIVI, the usual baseline for KV cache quantization. On needle-in-a-haystack duties the place the mannequin has to find a selected truth buried in a protracted doc, it hit excellent scores at 6x compression.
Curious to be taught extra?
See how our brokers can automate doc workflows at scale.
The explanation a compression paper might transfer the reminiscence chip market by 6% in two days is that the reminiscence scenario going into 2026 was already excessive. To grasp it, you must return to 2023.
In 2023, reminiscence producers have been dropping cash. DRAM costs had collapsed after the pandemic oversupply, and Samsung, SK Hynix, and Micron all pulled again on capital expenditure. They weren’t constructing new fabs as a result of there was no margin to justify it. But it surely coincided exactly with the start of the reasoning mannequin period, which was about to create a requirement curve nobody had seen earlier than on this trade.
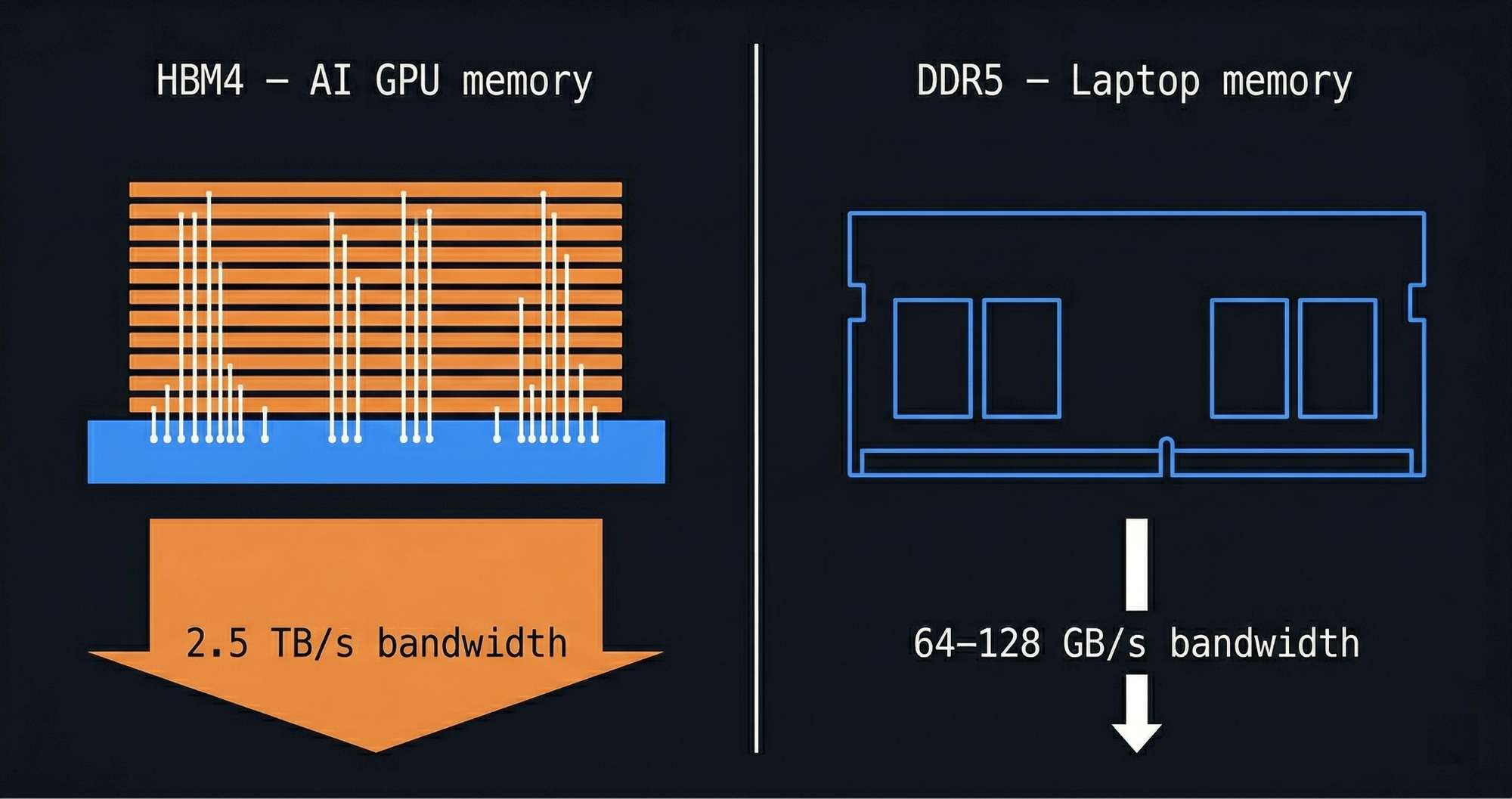
Let’s perceive why AI is so exhausting on reminiscence. A GPU wants information to maneuver at excessive speeds to maintain its processors fed. An HBM4 stack, the kind of reminiscence utilized in Nvidia’s newest chips, transfers reminiscence at roughly 2.5 terabytes per second. A comparable space of normal DDR5, the reminiscence in your laptop computer, does someplace round 64 to 128 gigabytes per second. Shopper reminiscence is constructed for a totally completely different job.
HBM4 vs DDR5 Reminiscence Bandwidth: Why AI GPUs Want 2.5 TB/s and Laptops Get 128 GB/s
HBM is constructed in another way, stacked in a number of layers, related with 1000’s of micro-connections known as through-silicon vias, and it is terribly costly to supply. Producing one gigabyte of HBM consumes 4 instances the wafer capability of normal DRAM. To place that in GPU phrases: a single Nvidia H100 presently prices between $25,000 and $30,000 per chip, and reminiscence accounts for roughly 30% of the price of deploying AI at scale. When Meta constructed its preliminary H100 coaching cluster with 24,000 of these chips, the GPU {hardware} invoice alone crossed $800 million, earlier than a single energy cable was run or a server rack assembled. That is one cluster, hyperscalers are constructing dozens. Of the $600 billion in mixed Large Tech capital spending this 12 months, roughly $180 billion goes to reminiscence alone.
Individuals normally make the “simply make extra reminiscence” argument. International silicon wafer manufacturing capability is rising, however solely at round 6 to 7% per 12 months. AI infrastructure spending is rising at charges many instances that. The fabs that may ultimately shut the hole began development after the demand sign hit, which suggests the significant new capacities do not come on-line till 2027-2028 and the crunch can doubtlessly final till 2030.
The Compression Arms Race That Was Already Taking place
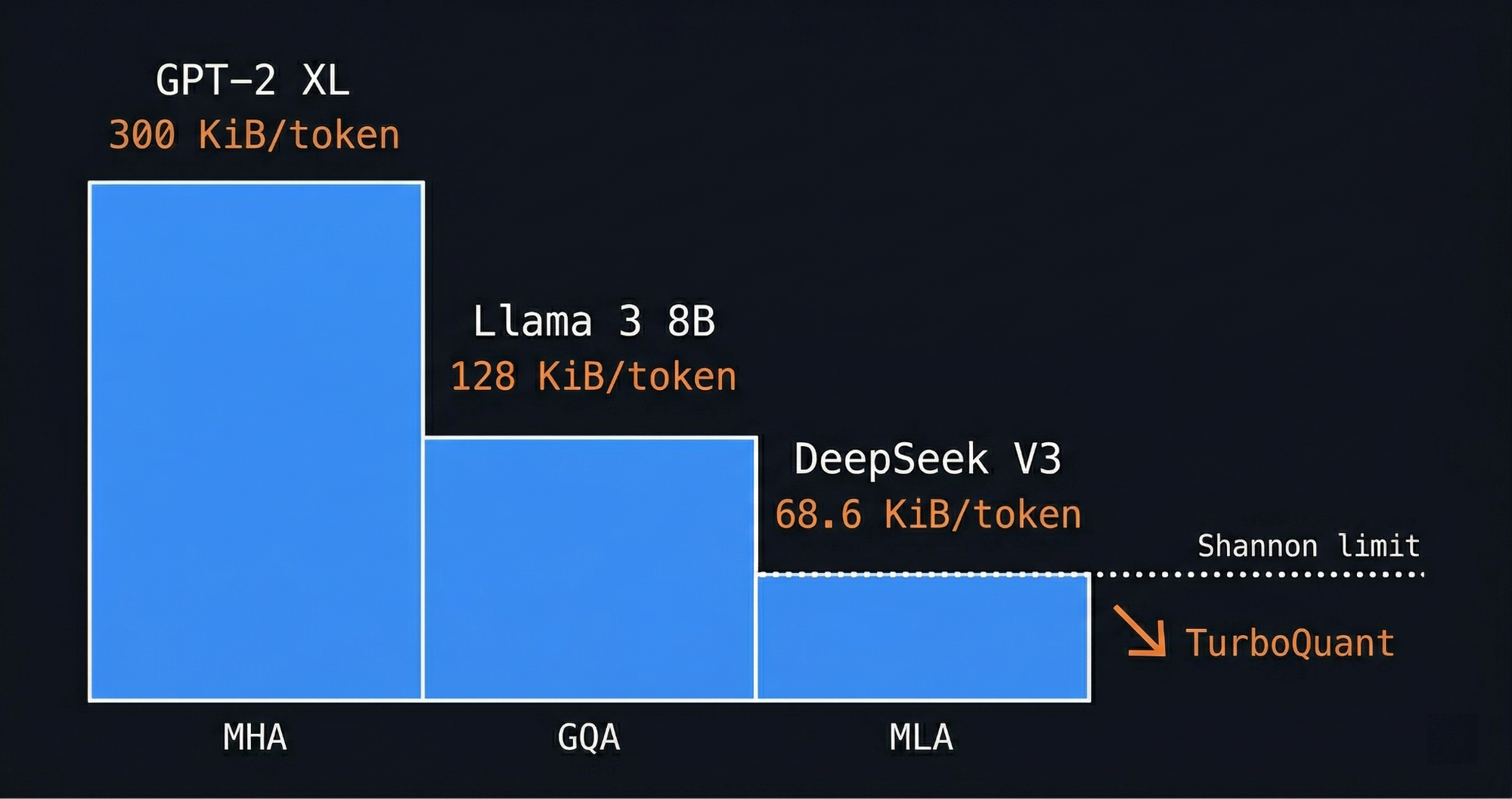
The trade has been chipping away on the KV cache reminiscence downside for years.GPT-2 XL, the most important 2019 variant, used the best potential design: each consideration head saved its personal unbiased set of keys and values. Price: round 300 kilobytes per token. By 2024, Llama 3 8B launched grouped-query consideration, the place a number of heads share the identical saved representations as a substitute of sustaining separate copies. Price dropped to 128 kilobytes per token, lower than half, with nearly no high quality loss on benchmarks. Then DeepSeek V3 went additional with multi-head latent consideration, compressing the key-value pairs right into a lower-dimensional kind earlier than storing them and decompressing at inference time. Price: 68.6 kilobytes per token, on a mannequin with 671 billion whole parameters, although solely 37 billion are energetic at any second.
KV Cache Per Token: GPT-2 XL to Llama 3 to DeepSeek V3 and the Shannon Restrict TurboQuant Is Approaching
That development, 300 to 128 to 68 kilobytes per token, is the compression arc that existed earlier than TurboQuant confirmed up. Every step traded one thing, normally some architectural complexity or slight recall degradation, for significant reminiscence financial savings. Every step additionally captured the simpler positive aspects first. What remained received more durable.
So by the point TurboQuant arrived, the low-hanging fruit was gone. TurboQuant issues much less as a result of it saves further reminiscence and extra as a result of it marks the place KV cache compression is approaching the information-theoretic restrict. You are near the Shannon ceiling. Each further bit squeezed out from right here prices extra engineering effort and dangers extra high quality degradation than the final.
There’s additionally an issue no compression algorithm touches. When the KV cache grows too massive for out there GPU reminiscence, fashions typically summarize their very own context right into a shorter kind and proceed from the abstract. The compression is lossy in methods the mannequin cannot detect. A selected funds determine turns into “roughly that quantity.” A nuanced instruction turns into “one thing about pointers.” The mannequin retains going, assured in info that not totally exists. Compression makes the cache smaller. It would not clear up the issue of deciding what’s truly value protecting.
So Why the Market Response Was Flawed
The shares fell for a similar cause markets typically overreact to technical bulletins: most traders learn the headline, not the paper.
TurboQuant solely addresses inference reminiscence, particularly the KV cache throughout inference. Coaching a mannequin, the months-long, multi-billion-dollar means of instructing the mannequin within the first place, requires basically completely different reminiscence, pushed by activations, gradients, and optimizer states. TurboQuant has zero impact on any of that. The huge HBM buildout that hyperscalers are funding exists primarily to coach and retrain ever-larger fashions. That demand curve is untouched by a KV cache compression algorithm.
Past coaching, TurboQuant is a analysis outcome with no manufacturing deployment. The paper was initially revealed in 2025 and received re-featured on the weblog forward of ICLR. Google itself hasn’t deployed it broadly within the 12 months for the reason that math was first documented.
The 6x headline additionally deserves scrutiny. It is benchmarked in opposition to 16-bit full-precision. Industrial inference already runs at 4 or 8 bits as customary follow. So the actual marginal achieve over deployed programs is smaller than the quantity suggests.
Jevons Paradox is one other factor to speak about. When DeepSeek launched dramatically extra environment friendly inference in early 2025, the identical concern unfold: HBM demand would drastically fall nevertheless it did not. As a result of cheaper inference expanded the set of organizations that would economically deploy AI, which drove extra whole demand for infrastructure. When inference prices fall, extra functions develop into viable, extra fashions keep energetic, and reminiscence corporations find yourself because the long-run beneficiary.
Jevons Paradox in AI Reminiscence: How DeepSeek and TurboQuant Each Drove Greater HBM Demand Regardless of Effectivity Features
The market has now seen this precise film twice, however panicked each instances. Bizarre proper?
Curious to be taught extra?
See how our brokers can automate doc workflows at scale.
The algorithm does have actual implications. They’re simply completely different from what the market priced in.
Essentially the most quick is inference economics. TurboQuant compresses the KV cache, which determines what number of concurrent customers a single GPU can serve and the way lengthy a context window is sensible at scale. If it will get deployed throughout manufacturing inference stacks, the throughput per GPU will increase. That issues for AI merchandise working thousands and thousands of queries per day, the place inference value is the recurring expense that determines profitability. Something that adjustments the memory-to-compute ratio per question shifts the associated fee construction of working AI merchandise.
The longer-term implication is on-device AI. Proper now, working a succesful language mannequin regionally on a telephone or laptop computer requires both compromising on high quality or shopping for costly {hardware}. If TurboQuant’s method will get carried out in native inference runtimes at scale, the {hardware} ground for working a significant AI mannequin drops. Fashions that presently require cloud infrastructure might run regionally. But it surely performs out over years, not quarters, and it has extra to do with software program ecosystem adoption than with whether or not reminiscence chip shares are accurately priced immediately.
It’s positively actual math that compresses one particular kind of reminiscence utilization throughout one section of AI operation. But it surely would not construct fabs and it would not change coaching economics. Reminiscence will get inbuilt clear rooms in South Korea and Idaho, by individuals working instruments that value a whole lot of thousands and thousands of {dollars} every. That a part of the provision chain strikes on a totally completely different clock than an algorithm (or only a analysis paper.)
So the crunch solely ends when the fabs are achieved.
Macworld studies the iPhone 18 Professional and Professional Max are anticipated to launch in September 2026 with Apple’s new C2 5G modem and 2nm A20 Professional chip.
Key upgrades embody a considerably smaller Dynamic Island by means of under-display Face ID, variable aperture cameras, and 24MP selfie cameras for enhanced pictures.
The units will retain 6.3 and 6.9-inch display sizes with new deep pink and low coloration choices, whereas customary iPhone 18 fashions face potential delays till spring 2027.
The iPhone 18 Professional and Professional Max are anticipated to launch in September 2026 that includes a number of cutting-edge {hardware} developments, together with the debut of Apple’s C2 modem, and a shift to a 2nm manufacturing course of for the A20 Professional chip.
Different key rumored upgrades embody a smaller Dynamic Island with under-display Face ID parts and digicam enhancements which will embody variable aperture on the Professional Max and enhanced sensors.
Alongside the iPhone 18 Professional and Professional Max Apple is claimed to be planning to launch the ultra-premium folding iPhone. Nevertheless, in a change to the same old schedule, the corporate is anticipated to shift the launch of the iPhone 18 spring 2027 to maintain the highlight on the Professional collection throughout its conventional September debut.
Right here’s a fast abstract of what all of the rumors and leaks say to count on from the iPhone 18 Professional and Professional Max in 2026.
Replace April 2, 2026: Weibo leaker On the spot Digital claims the iPhone 18 Professional and Professional Max won’t be accessible in Black, simply because the iPhone 17 Professional and Professional Max will not be.
What are the most important upgrades for iPhone 18 Professional & Professional Max
Professional fashions launching first in September 2026, base fashions delayed to spring 2027
Smaller Dynamic Island doubtless, with some Face ID parts underneath the show
Potential variable aperture digicam (Professional Max solely)
New A20 chip (2nm) for efficiency and effectivity good points
Apple’s personal C2 modem anticipated throughout the lineup
Potential satellite tv for pc web help, not simply emergency use
How is iPhone 18 Professional/Max completely different from iPhone 17 Professional/Max?
Cut up launch schedule (Professional first, base later)
Smaller or modified Dynamic Island
Potential under-display Face ID parts
New modem (shift away from Qualcomm)
Digicam experimentation (variable aperture on Professional Max)
iPhone 18 Professional/Max vs iPhone 17 Professional/Max
Function
iPhone 18 Professional/Max
iPhone 17 Professional/Max
Launch date
September 2026
September 2025
Dynamic Island
Smaller design
No change since 2022 iPhone 14 Professional
Face ID
Beneath-display
No change since 2022 iPhone 14 Professional
Modem
C2 modem
Qualcomm modem
Digicam
Improved aperture know-how for rear. 24MP selfie cameras
All three rear cameras are 48MP, optical-quality 8x zoom. 18MP entrance digicam.
Evaluating iPhone 18 Professional rumors to present iPhone 17 Professional
When will the iPhone 18 Professional/Max launch?
There have been constant studies for a while that there shall be a significant shift from Apple’s normal iPhone launch schedule in 2026. In September 2026, Apple will reportedly solely launch the high-end fashions: iPhone 18 Professional and Professional Max, the brand new folding iPhone, and maybe an up to date iPhone Air.
Which means the bottom mannequin iPhone 18 will wait till spring 2027, when it can reportedly arrive alongside the iPhone 18e. This can be a large departure for Apple, and it signifies that the brand new iPhones in September 2026 will all have value tags of $999 or extra.
This staggered method may permit Apple to focus extra consideration on its premium Professional and foldable handsets in the course of the vacation season.
iPhone 18 Professional/Max
September 2026
iPhone Fold
September 2026
iPhone Air (2nd gen)
Spring 2027
iPhone 18
Spring 2027
iPhone 18e
Spring 2027
The anticipated launch dates for the 2026-2027 iPhones
What’s going to the iPhone 18 Professional/Max seem like?
The design of the iPhone 18 Professional and Professional Max is claimed to resemble the iPhone 17 Professional and Professional Max, however some modifications are predicted.
One attainable change, shared by a Weibo leaker in September 2025, is a “barely clear” ceramic defend part on the again of Professional fashions, although particulars are unclear.
New colorways, together with a deep shade of pink (probably burgundy or purple-toned) and a espresso shade, are rumored (through Digital Chat Station). As with the iPhone 17 Professional, there shall be no black possibility, in line with On the spot Digital.
Display screen sizes are anticipated to stay at 6.3 and 6.9 inches. The Professional fashions can even retain the broader three-camera raised plateau.
Almost definitely: Design modifications shall be minimal, with the most important seen variations restricted to colours and delicate refinements.
What’s new with the iPhone 18 Professional/Max digicam?
Eugen Wegmann
Apple might introduce variable aperture know-how to the 48MP important digicam on the iPhone 18 Professional and Professional Max (probably solely the Professional Max), permitting mechanical management over mild consumption and depth of area. This has lengthy been a perk restricted to high-end skilled cameras.
If the rumor (from Digital Chat Station on Weibo) is true, iPhone customers will be capable to mechanically management how a lot mild reaches the sensor for the primary time, permitting extra management over depth of area and sharpness. This might elevate portrait photographs by enhancing the utilized depth of area impact, in addition to minimizing overexposure.
Improved telephoto apertures on the Professional fashions also needs to lead to higher low-light efficiency.
For a while (since January 2025) Samsung has been stated to be engaged on a brand new three-layer stacked digicam sensor known as ‘PD-TR-Logic,’ and this might seem within the iPhone 18 collection. This picture sensor is anticipated to reinforce the digicam’s responsiveness, whereas additionally providing benefits resembling diminished photograph noise, improved dynamic vary.
The front-facing digicam can also get an improve past the rumored modifications to the housing (as mentioned elsewhere the selfie digicam could also be housed in a smaller hole-punch reduce out, lowering the scale of the Dynamic Island). The iPhone 17 technology options 18MP sensors for the selfie digicam, however this will likely improve to 24MP within the subsequent technology, in line with leaker WhyLab on Weibo.
Extra megapixels would result in improved video calls and higher low-light efficiency.
Almost definitely: Incremental enhancements, with a brand new variable aperture characteristic on the Professional Max.
Will the iPhone 18 Professional/Max Dynamic Island or entrance digicam change?
Britta O’Boyle
Apple hasn’t modified the Dynamic Island for the reason that iPhone 14 Professional, however the iPhone 18 Professional might introduce some changes.
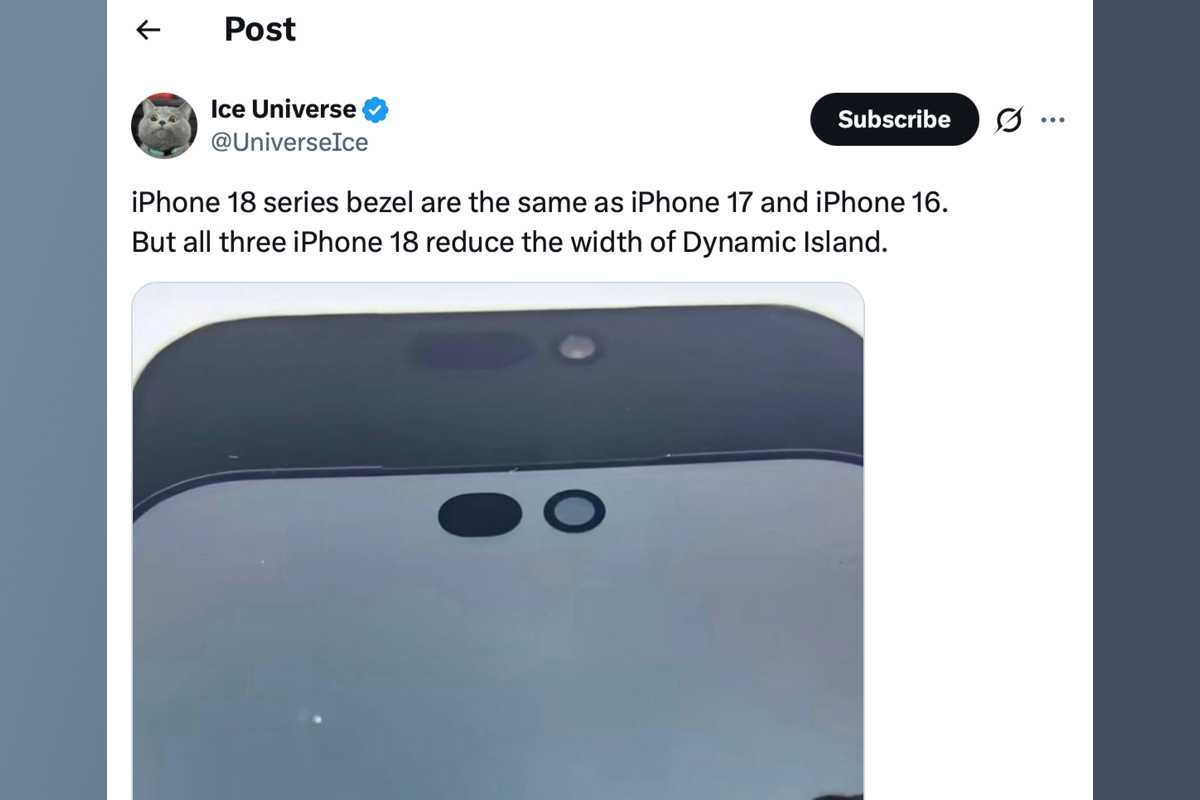
Some studies counsel Face ID parts may transfer underneath the show, shrinking the Dynamic Island.
A report in December 2025 from Weibo account “Good Pikachu” claimed that Apple is testing an under-display “micro-transparent glass panel” for some Face ID sensors. This could allow a smaller Dynamic Island for iPhone 18 Professional.
The ever-reliable Mark Gurman at Bloomberg additionally reported that Apple will “shrink” the Dynamic Island on the iPhone 18 fashions, so there’s sturdy proof that a number of the a number of sensors and emitters required for Face ID shall be underneath the show or mixed.
There have been conflicting claims that the place of the front-facing digicam can also change:
In December 2025 The Info claimed Apple will put the Face ID sensors underneath the show, and transfer the entrance digicam to the higher left nook in a punch-hole design. This might make the iPhone 18 Professional/ Max the primary iPhones with a entrance digicam within the nook.
Almost definitely: A smaller Dynamic Island with some parts of Face ID underneath the glass. Smaller capsule reduce out for digicam, remaining in central place.
Will the iPhone 18 Professional/Max show change?
Stephan Wiesend
Display screen sizes needs to be according to the 6.3 and 6.9-inch shows on the present fashions, however studies counsel a large leap in brightness from the present 1600 nits HDR and three,000 nits peak. https://www.macworld.com/article/3039085/the-iphone-18-is-expected-to-get-a-much-brighter-screen.html
In response to Weibo leaker, On the spot Digital, Chinese language provider BOE has revealed that Apple is focusing on unprecedentedly excessive brightness necessities for the show. The Elec corroborated this, claiming BOE is combating iPhone OLED manufacturing so panel orders have been shifted to Samsung Show.
Almost definitely: A rise in brightness is anticipated, however there aren’t any particulars but on the extent of the development.
How highly effective will the A20 chip within the iPhone 18 Professional/Max be?
The iPhone 18 collection is anticipated to make use of a new A20 chip, constructed on TSMC’s N2 (2nm) course of. This can symbolize a significant architectural shift for Apple’s smartphone silicon, primarily because of the transition to a extra superior manufacturing course of.
This transfer to a smaller course of permits for extra transistors in the identical area, which is projected to ship as much as 15% sooner efficiency and 30% higher energy effectivity in comparison with the A19 chip.
The iPhone 18 Professional and Professional Max fashions will make the most of an A20 Professional variant to additional differentiate their capabilities. This elevated energy is anticipated to help superior options.
The A20 is rumored to use a brand new course of known as Wafer-Degree Multi-Chip Module (WMCM) packaging to include the RAM into the SoC’s bundle. It’s not clear what the profit shall be, however extra tightly built-in RAM can imply extra reminiscence bandwidth and decrease RAM latency, or higher energy effectivity.
Almost definitely: A typical Apple leap in effectivity and pace, with behind-the-scenes good points fairly than dramatic user-visible modifications.
Will connectivity enhance (5G, Wi-Fi, satellite tv for pc) with iPhone 18 Professional/Max?
iPhone 18 Professional fashions will doubtless characteristic the second technology of Apple’s in-house 5G modem, the C2 chip.
The C2 modem is anticipated to interchange Qualcomm throughout the lineup. This could enhance:
Effectivity
Efficiency
mmWave help
There are additionally studies of full satellite tv for pc web help, increasing past emergency use. The Info says that Apple is gearing as much as help 5G networks which are served from satellites, specifically Starlink satellites. Whereas the iPhone has provided satellite tv for pc connectivity for emergency conditions for years, this is able to permit the iPhone 18 fashions to have full web entry through satellite tv for pc, not simply emergency companies.
The Wi-Fi/Bluetooth chip (N1) will doubtless stay unchanged. Apple debuted its native networking chip within the iPhone 17 line – the N1 helps Wi-Fi 7, Bluetooth 6, and Thread networking. We haven’t heard something about an N2, and truthfully, one most likely isn’t wanted so quickly. Might Apple have an “N1X” shock in retailer the best way it did with the C1X? It’s attainable, however thus far the rumor mill expects Apple to construct the iPhone 18 line with the identical N1 chip as discovered within the iPhone 17.
Almost definitely: A significant improve in connectivity, particularly if satellite tv for pc web expands.
How a lot will the iPhone 18 Professional/Max price?
Pricing might stay the identical as the present technology as no main pricing modifications are at the moment rumored for the brand new iPhone 18 collection.
Nevertheless, the introduction of a folding iPhone may dramatically change the pricing construction, as it can reportedly have a beginning value of $1,999 or extra.
When periodical cicadas floor after years underground, they don’t grope blindly for bushes. They head for the shadows, researchers report March 20 within the American Naturalist.
An in depth evaluation of Brood XIII cicadas — which spend 17 years growing in subterranean tunnels earlier than rising suddenly — discovered that newly arrived, wingless nymphs use darkness cues to maneuver with hanging precision towards tree trunks.
Throughout dozens of recorded trajectories, the bugs deviated solely barely from probably the most direct route. “They simply zoomed in, marching towards the bushes,” says Martha Weiss, an evolutionary ecologist at Georgetown College in Washington, D.C.
This near-direct motion, Weiss and her colleagues discovered, hinges on the cicadas’ potential to detect darkish shapes towards paler backgrounds within the dim night mild. That cue guides the nymphs to the vertical surfaces they have to climb to grow to be winged adults.
Guided by darkness, a cicada nymph climbs a tree and molts right into a winged grownup — an instance of skototaxis in motion.Martha Weiss
Whereas engaged on the leafy grounds of Lake Forest School in northern Illinois in 2024, Weiss’s crew quickly painted over the compound eyes and less complicated light-sensing organs of newly emerged nymphs. With out the distinction between mild and darkness to information them, many of the immature cicadas wandered aimlessly and by no means reached a trunk. In distinction, management nymphs with unobscured imaginative and prescient moved shortly and instantly towards the close by bushes.
The researchers then put the nymphs by a visual-preference check, presenting them with a easy alternative between lighter and darker targets. Very like an individual instinctively heading for the darkish define of a doorway in a dim room, 28 of 32 bugs crawled towards the darker floor. Solely 4 moved towards the lighter possibility.
The consequence confirmed that it was certainly darkness guiding the bugs, a habits referred to as skototaxis.
In hindsight, cicada knowledgeable Gene Kritsky, an entomologist at Mount St. Joseph College in Cincinnati, says he has witnessed this darkness-seeking intuition as nicely. However the opportunity of formally investigating it “didn’t daybreak on me,” Kritsky says. The brand new examine “fills in a clean with experimental proof a couple of habits that’s so frequent that it normally goes unnoticed.”
Skototaxis exists throughout the insect world: Cicadas be part of crickets, beetles, ants, flat bugs and even swimming bees.
Earlier this yr, entomologist Zach Huang from Michigan State College in East Lansing and colleagues reported that honeybees and mason bees stranded on water swim towards darker areas, utilizing brightness variations to direct themselves towards dry land.
Like Weiss, Huang says he didn’t learn about skototaxis till he studied the habits. “I didn’t even know that the phrase existed.” However after studying the brand new analysis, Huang suspects skototaxis could also be way more widespread than researchers have appreciated.
Many vegetation and animals, it appears, have discovered the identical easy lesson: When survival is on the road, following the shadows is usually a vibrant thought.
Synthetic intelligence is more and more getting used to assist optimize decision-making in high-stakes settings. As an illustration, an autonomous system can establish an influence distribution technique that minimizes prices whereas protecting voltages secure.
However whereas these AI-driven outputs could also be technically optimum, are they truthful? What if a low-cost energy distribution technique leaves deprived neighborhoods extra weak to outages than higher-income areas?
To assist stakeholders shortly pinpoint potential moral dilemmas earlier than deployment, MIT researchers developed an automatic analysis methodology that balances the interaction between measurable outcomes, like value or reliability, and qualitative or subjective values, equivalent to equity.
The system separates goal evaluations from user-defined human values, utilizing a big language mannequin (LLM) as a proxy for people to seize and incorporate stakeholder preferences.
The adaptive framework selects the perfect situations for additional analysis, streamlining a course of that usually requires expensive and time-consuming handbook effort. These check circumstances can present conditions the place autonomous methods align nicely with human values, in addition to situations that unexpectedly fall in need of moral standards.
“We will insert numerous guidelines and guardrails into AI methods, however these safeguards can solely forestall the issues we will think about taking place. It isn’t sufficient to say, ‘Let’s simply use AI as a result of it has been skilled on this info.’ We wished to develop a extra systematic option to uncover the unknown unknowns and have a option to predict them earlier than something dangerous occurs,” says senior creator Chuchu Fan, an affiliate professor within the MIT Division of Aeronautics and Astronautics (AeroAstro) and a principal investigator within the MIT Laboratory for Info and Resolution Programs (LIDS).
Fan is joined on the paper by lead creator Anjali Parashar, a mechanical engineering graduate scholar; Yingke Li, an AeroAstro postdoc; and others at MIT and Saab. The analysis might be offered on the Worldwide Convention on Studying Representations.
Evaluating ethics
In a big system like an influence grid, evaluating the moral alignment of an AI mannequin’s suggestions in a means that considers all aims is particularly troublesome.
Most testing frameworks depend on pre-collected information, however labeled information on subjective moral standards are sometimes exhausting to return by. As well as, as a result of moral values and AI methods are each continuously evolving, static analysis strategies primarily based on written codes or regulatory paperwork require frequent updates.
Fan and her staff approached this drawback from a unique perspective. Drawing on their prior work evaluating robotic methods, they developed an experimental design framework to establish essentially the most informative situations, which human stakeholders would then consider extra carefully.
Their two-part system, referred to as Scalable Experimental Design for System-level Moral Testing (SEED-SET), incorporates quantitative metrics and moral standards. It could possibly establish situations that successfully meet measurable necessities and align nicely with human values, and vice versa.
“We don’t wish to spend all our sources on random evaluations. So, it is extremely necessary to information the framework towards the check circumstances we care essentially the most about,” Li says.
Importantly, SEED-SET doesn’t want pre-existing analysis information, and it adapts to a number of aims.
As an illustration, an influence grid might have a number of consumer teams, together with a big rural group and an information heart. Whereas each teams might want low-cost and dependable energy, every group’s precedence from an moral perspective might range extensively.
These moral standards might not be well-specified, to allow them to’t be measured analytically.
The ability grid operator desires to search out essentially the most cost-effective technique that finest meets the subjective moral preferences of all stakeholders.
SEED-SET tackles this problem by splitting the issue into two, following a hierarchical construction. An goal mannequin considers how the system performs on tangible metrics like value. Then a subjective mannequin that considers stakeholder judgements, like perceived equity, builds on the target analysis.
“The target a part of our method is tied to the AI system, whereas the subjective half is tied to the customers who’re evaluating it. By decomposing the preferences in a hierarchical style, we will generate the specified situations with fewer evaluations,” Parashar says.
Encoding subjectivity
To carry out the subjective evaluation, the system makes use of an LLM as a proxy for human evaluators. The researchers encode the preferences of every consumer group right into a pure language immediate for the mannequin.
The LLM makes use of these directions to match two situations, choosing the popular design primarily based on the moral standards.
“After seeing lots of or hundreds of situations, a human evaluator can endure from fatigue and turn into inconsistent of their evaluations, so we use an LLM-based technique as a substitute,” Parashar explains.
SEED-SET makes use of the chosen situation to simulate the general system (on this case, an influence distribution technique). These simulation outcomes information its seek for the following finest candidate situation to check.
In the long run, SEED-SET intelligently selects essentially the most consultant situations that both meet or will not be aligned with goal metrics and moral standards. On this means, customers can analyze the efficiency of the AI system and alter its technique.
As an illustration, SEED-SET can pinpoint circumstances of energy distribution that prioritize higher-income areas during times of peak demand, leaving underprivileged neighborhoods extra vulnerable to outages.
To check SEED-SET, the researchers evaluated lifelike autonomous methods, like an AI-driven energy grid and an city site visitors routing system. They measured how nicely the generated situations aligned with moral standards.
The system generated greater than twice as many optimum check circumstances because the baseline methods in the identical period of time, whereas uncovering many situations different approaches ignored.
“As we shifted the consumer preferences, the set of situations SEED-SET generated modified drastically. This tells us the analysis technique responds nicely to the preferences of the consumer,” Parashar says.
To measure how helpful SEED-SET could be in follow, the researchers might want to conduct a consumer examine to see if the situations it generates assist with actual decision-making.
Along with operating such a examine, the researchers plan to discover the usage of extra environment friendly fashions that may scale as much as bigger issues with extra standards, equivalent to evaluating LLM decision-making.
This analysis was funded, partly, by the U.S. Protection Superior Analysis Tasks Company.
Early explorers typically traveled with maps that had been fantastically illustrated, but deeply deceptive. Coastlines drifted, rivers wandered and full areas existed in solely the cartographer’s creativeness.
Because of this, the crews that survived weren’t those who adopted the map most faithfully. They had been led by navigators who understood the terrain and adjusted course as circumstances modified.
That distinction issues once more, now in shaping trendy IT programs.
The build-versus-buy framework nonetheless seems on whiteboards, as if nothing basic has shifted. In observe, the programs that leaders are answerable for now not behave like fastened coastlines.
Information strikes continually. Workflows evolve as quickly as they attain manufacturing. AI introduces new layers of reasoning, dependency and failure that had been by no means a part of the unique mannequin. A framework designed for stability is now being utilized to programs in movement.
Construct and purchase as soon as represented two clear paths. Every got here with tradeoffs that had been effectively understood, and both may ship a sturdy end result as a result of the atmosphere positioned restricted pressure on the structure. Workflows had been predictable, and alter occurred in measured cycles. Software program was anticipated to execute, to not interpret.
That world now not exists. Fashionable operational programs are anticipated to soak up change constantly whereas remaining dependable. AI has accelerated that by embedding decision-making instantly into workflows. Programs now motive and adapt in actual time. The unique framework was drawn for placid circumstances. Leaders at this time function in altering climate.
As such, resilient programs rely on architectures constructed to deal with change and stress, and a important share of enterprise purposes will quickly embody task-specific AI brokers. This strikes us towards intelligence woven instantly into operations reasonably than layered on prime.
Velocity comes with hidden constraints
SaaS earned its position by providing velocity and predictability. For standardized workflows, it nonetheless delivers worth. The constraints floor when operational complexity enters the image.
In environments formed by subject circumstances, regulatory nuance or variable demand, SaaS begins to impose its personal assumptions. Organizations adapt their processes to suit the software program, reasonably than the opposite approach round. Over time, they undertake a vendor’s view of how work ought to run.
The associated fee isn’t theoretical. In a single field-service group, annual spend on a single platform reached roughly $170,000, whereas solely a small fraction of its capabilities had been used. When the seller launched revenue-based pricing, development successfully grew to become a tax. Software program supposed to help operations was a drag on margins.
This sample is frequent. SaaS distributors are incentivized to serve the broadest doable market, which leaves many organizations renting programs indefinitely whereas absorbing constraints that compound over time.
Precision carries its personal weight
Customized engineering sits on the reverse finish of the spectrum, providing a degree of precision and management that turns into important when workflows are genuinely distinctive. That precision, nevertheless, comes with weight. As programs turn out to be extra tailor-made, integration surfaces multiply, upkeep calls for enhance and supply timelines prolong, typically in methods which are troublesome to reverse as soon as the structure is in place.
Traditionally, economics made this method unrealistic for a lot of organizations. Constructing a bespoke operational system required important time and capital. Even leaders annoyed by SaaS constraints typically accepted them as a result of the choice felt heavier.
AI has shifted that calculus. When an in depth necessities doc might be translated right into a working, navigable prototype in days reasonably than months, the fee curve modifications. Programs that when required lots of of engineering hours can now be formed iteratively with far much less friction. Possession turns into viable once more, offered it is utilized selectively.
Hybrid engineering has emerged to fulfill these circumstances. It begins with a robust operational core composed of intelligence-ready elements designed to soundly take in variability. These foundations stabilize the components of a system most susceptible to failure, whereas making a base that may help reasoning, validation and alter over time.
Engineering effort then focuses on the a part of the system the place differentiation really lives. That is the place operational nuance is expressed and aggressive benefit takes form. The result’s a system designed to evolve as a result of it was constructed for motion from the beginning.
The terrain now not matches the map. Leaders can preserve following maps drawn for a calmer period, or they’ll undertake a mannequin that displays how trendy programs behave. Hybrid engineering would not substitute judgment, but it surely does restore it.


: The Double Taco")













{kind=link}