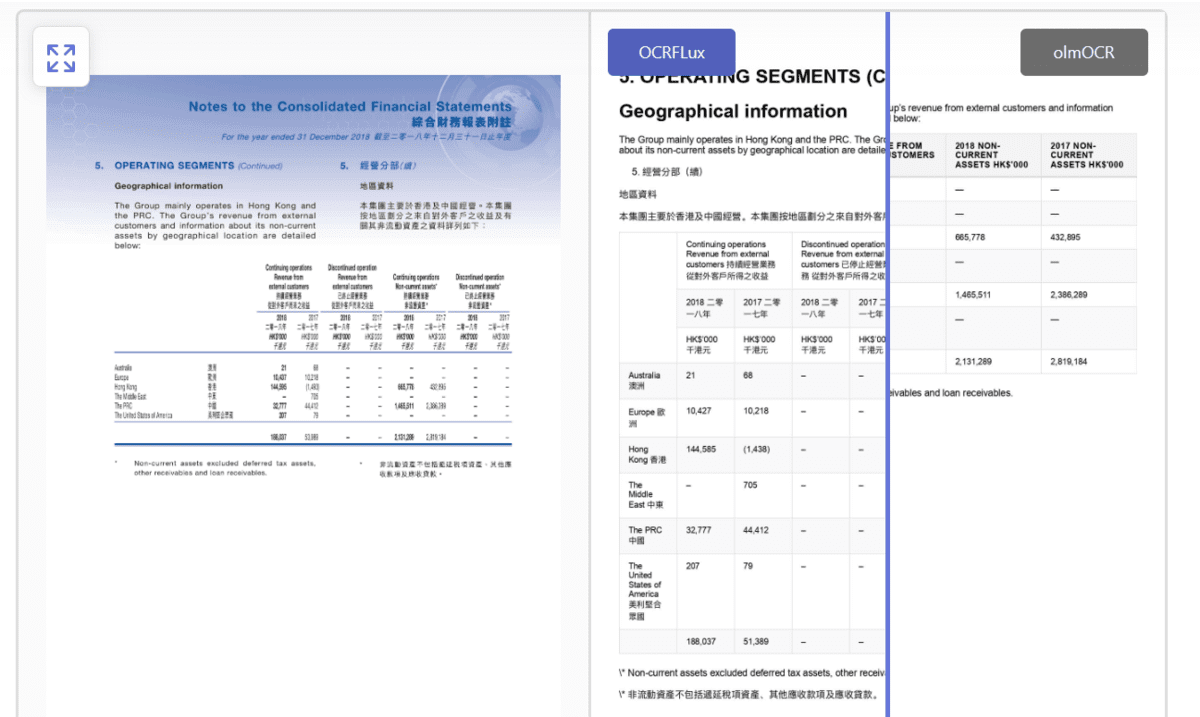
A examine reveals that restoring the mind’s vitality stability might not simply sluggish Alzheimer’s — however really reverse it.
- For greater than a century, Alzheimer’s illness has been broadly seen as everlasting and untreatable as soon as it begins. Consequently, most analysis has targeted on stopping the illness or slowing its development somewhat than making an attempt to reverse it.
- By learning a number of mouse fashions of Alzheimer’s alongside human Alzheimer’s mind tissue, researchers recognized a important organic drawback on the heart of the illness. They discovered that the mind’s incapacity to keep up wholesome ranges of a significant mobile vitality molecule referred to as NAD+ performs a significant position in driving Alzheimer’s.
- In animal fashions, sustaining regular mind NAD+ ranges prevented Alzheimer’s from growing. Much more putting, restoring NAD+ stability after the illness was already superior allowed the mind to restore injury and absolutely restore cognitive perform.
- These outcomes counsel that remedies geared toward restoring the mind’s vitality stability may doubtlessly transfer Alzheimer’s remedy past slowing decline and towards significant restoration.
- The findings additionally open the door to additional analysis, together with the exploration of complementary methods and thoroughly designed medical trials to find out whether or not these outcomes can translate to sufferers.
A Longstanding View of Alzheimer’s Is Being Questioned
For greater than 100 years, Alzheimer’s illness (AD) has been broadly seen as a situation that can not be undone. Due to this perception, most scientific efforts have targeted on stopping the illness or slowing its development, somewhat than making an attempt to revive misplaced mind perform. Even after a long time of analysis and billions of {dollars} in funding, no drug trial for Alzheimer’s has ever been designed with the aim of reversing the illness and recovering cognitive skills.
That long-held assumption is now being challenged by researchers from College Hospitals, Case Western Reserve College, and the Louis Stokes Cleveland VA Medical Middle. Their work got down to reply a daring query: can brains already broken by superior Alzheimer’s recuperate?
New Examine Targets Mind Power Failure
The analysis was led by Kalyani Chaubey, PhD, of the Pieper Laboratory and revealed on December 22 in Cell Reviews Medication. By analyzing each human Alzheimer’s mind tissue and a number of preclinical mouse fashions, the workforce recognized a key organic failure on the heart of the illness. They discovered that the mind’s incapacity to keep up regular ranges of a important mobile vitality molecule referred to as NAD+ performs a significant position in driving Alzheimer’s. Importantly, sustaining correct NAD+ stability was proven to not solely forestall the illness but additionally reverse it in experimental fashions.
NAD+ ranges naturally decline all through the physique, together with the mind, as individuals age. When NAD+ drops too low, cells lose the power to hold out important processes wanted for regular perform and survival. The researchers found that this decline is much extra extreme within the brains of individuals with Alzheimer’s. The identical sample was seen in mouse fashions of the illness.
How Alzheimer’s Was Modeled within the Lab
Though Alzheimer’s happens solely in people, scientists examine it utilizing specifically engineered mice that carry genetic mutations recognized to trigger the illness in individuals. On this examine, researchers used two such fashions. One group of mice carried a number of human mutations affecting amyloid processing, whereas the opposite carried a human mutation within the tau protein.
Amyloid and tau abnormalities are among the many earliest and most important options of Alzheimer’s. In each mouse fashions, these mutations led to widespread mind injury that intently mirrors the human illness. This included breakdown of the blood-brain barrier, injury to nerve fibers, persistent irritation, decreased formation of recent neurons within the hippocampus, weakened communication between mind cells, and in depth oxidative injury. The mice additionally developed extreme reminiscence and cognitive issues just like these seen in individuals with Alzheimer’s.
Testing Whether or not Alzheimer’s Injury May Be Reversed
After confirming that NAD+ ranges dropped sharply in each human and mouse Alzheimer’s brains, the workforce explored two prospects. They examined whether or not sustaining NAD+ stability earlier than signs appeared may forestall Alzheimer’s, and whether or not restoring that stability after the illness had already progressed may reverse it.
This strategy constructed on the group’s earlier work revealed in Continuing of the Nationwide Academy of Sciences USA, which confirmed that restoring NAD+ stability led to each structural and practical restoration after extreme, long-lasting traumatic mind harm. Within the present examine, the researchers used a well-characterized pharmacologic compound referred to as P7C3-A20, developed within the Pieper laboratory, to revive NAD+ stability.
Full Cognitive Restoration Noticed in Superior Illness
The outcomes had been putting. Preserving NAD+ stability protected mice from growing Alzheimer’s, however much more shocking was what occurred when remedy started after the illness was already superior. In these instances, restoring NAD+ stability allowed the mind to restore the most important pathological injury brought on by the genetic mutations.
Each mouse fashions confirmed full restoration of cognitive perform. This restoration was additionally mirrored in blood checks, which confirmed normalized ranges of phosphorylated tau 217, a not too long ago permitted medical biomarker used to diagnose Alzheimer’s in individuals. These findings supplied robust proof of illness reversal and highlighted a possible biomarker for future human trials.
Researchers Categorical Cautious Optimism
“We had been very excited and inspired by our outcomes,” mentioned Andrew A. Pieper, MD, PhD, senior creator of the examine and Director of the Mind Well being Medicines Middle, Harrington Discovery Institute at UH. “Restoring the mind’s vitality stability achieved pathological and practical restoration in each strains of mice with superior Alzheimer’s. Seeing this impact in two very completely different animal fashions, every pushed by completely different genetic causes, strengthens the concept restoring the mind’s NAD+ stability may assist sufferers recuperate from Alzheimer’s.”
Dr. Pieper additionally holds the Morley-Mather Chair in Neuropsychiatry at UH and the CWRU Rebecca E. Barchas, MD, DLFAPA, College Professorship in Translational Psychiatry. He serves as Psychiatrist and Investigator within the Louis Stokes VA Geriatric Analysis Schooling and Scientific Middle (GRECC).
A Shift in How Alzheimer’s Is Considered
The findings counsel a basic change in how Alzheimer’s might be approached sooner or later. “The important thing takeaway is a message of hope — the results of Alzheimer’s illness might not be inevitably everlasting,” mentioned Dr. Pieper. “The broken mind can, beneath some circumstances, restore itself and regain perform.”
Dr. Chaubey added, “By our examine, we demonstrated one drug-based strategy to accomplish this in animal fashions, and likewise recognized candidate proteins within the human AD mind that will relate to the power to reverse AD.”
Why This Method Differs From Dietary supplements
Dr. Pieper cautioned towards complicated this technique with over-the-counter NAD+-precursors. He famous that such dietary supplements have been proven in animal research to lift NAD+ to dangerously excessive ranges that promote most cancers The strategy used on this analysis depends as a substitute on P7C3-A20, a pharmacologic agent that helps cells keep wholesome NAD+ stability throughout excessive stress, with out pushing ranges past their regular vary.
“That is vital when contemplating affected person care, and clinicians ought to take into account the likelihood that therapeutic methods geared toward restoring mind vitality stability may provide a path to illness restoration,” mentioned Dr. Pieper.
Subsequent Steps Towards Human Trials
The analysis additionally opens the door to further research and eventual testing in individuals. The expertise is presently being commercialized by Glengary Mind Well being, a Cleveland-based firm co-founded by Dr. Pieper.
“This new therapeutic strategy to restoration must be moved into rigorously designed human medical trials to find out whether or not the efficacy seen in animal fashions interprets to human sufferers,” Dr. Pieper defined. “Further subsequent steps for the laboratory analysis embrace pinpointing which elements of mind vitality stability are most vital for restoration, figuring out and evaluating complementary approaches to Alzheimer’s reversal, and investigating whether or not this restoration strategy can be efficient in different types of persistent, age-related neurodegenerative illness.”