In his 1993 e-book “Managing with Twin Methods,” Derek Abell made a daring argument for his time: operating the enterprise and altering the enterprise will not be sequential actions — they should occur in parallel. He wrote that altering the enterprise requires a transparent imaginative and prescient of the long run and a method for the way the group should evolve to satisfy it.
That is troublesome within the age of AI, the place there are not any cookie-cutter roadmaps ahead. And it is particularly exhausting for CIOs who — now anticipated to run and alter the enterprise on the identical time — nonetheless lack in lots of circumstances the deep enterprise partnerships wanted to do each properly.
The hole typically begins with HR. In a latest interview, Jonathan Feldman, CIO for Wake County, N.C., mentioned, “IT is basically a folks enterprise — and that and not using a robust partnership with HR, CIOs danger falling quick.”
Within the AI period, this partnership is essential, not non-compulsory. As companions, CIOs and HR leaders can outline and form the way forward for work for his or her corporations, in shut alignment with their CEOs. The danger of inaction is important.
Organizations that fail to adapt will face increased prices than rivals, wrestle to construct the workforce they want, and lack the velocity required to compete in an more and more AI-driven world.
This text focuses on three areas CIOs should handle in parallel to compete:
How work is altering throughout roles and capabilities.
How techniques should evolve to help AI-augmented work.
What expertise employees might want to stay related.
Job disruption and workforce shifts
Final November, a 2025 Stanford College examine led by Dr. Erik Brynjolfsson utilizing information from hundreds of thousands of ADP payroll data discovered that AI is already driving labor market shifts. Early-career employees in AI-exposed occupations are experiencing a 16% decline in employment, whereas employment for knowledgeable employees stays secure up to now. To be clear, employment adjustments are concentrated in occupations the place AI automates fairly than augments labor.
With out query, AI will have an effect on duties, occupations and industries in numerous methods, changing work in some, augmenting others, and reworking nonetheless others. Professions already affected on the hiring stage embody software program builders and customer support representatives. Extra skilled employees haven’t been disrupted on the identical charge, regardless of being much less prone to embrace AI to enhance their work. Generative AI instruments like Claude and Open AI fashions are already demonstrating positive factors in private productiveness.
The query CIOs and their HR companions must reply is: which enterprise processes and duties inside the enterprise might be automated, augmented, or modified, and — over time — what work will seem like if brokers deal with execution. Within the longer-term agentic world, people might be chargeable for architecting work, placing collectively governance constructions (tips, guardrails, and requirements), and managing how brokers do their execution. On this part, Ian Beacraft mentioned in his South by Southwest speak just a few weeks in the past, we transfer to agentic organizations.
To navigate the workforce shift, CIOs ought to process their enterprise architects to take their maps of enterprise capabilities and enterprise processes and decide which might be automated, augmented, or modified. In apply, this makes enterprise structure the mechanism for redesigning work. In lots of circumstances, this must be completed utilizing future-state maps that mirror how AI can remodel working fashions and create new worth propositions.
With these in hand, CIOs, together with their HR companions and AI-skilled architects, ought to consider job expertise, decide which could be automated or augmented with AI, and align them to job descriptions.
Position of enterprise architects
Enterprise architects might help by relating maps of enterprise capabilities, expertise, and job descriptions. To be clear, EAs are in an help function; they need to not personal the workforce or job redesign immediately.
As an alternative, EAs ought to join the dots throughout enterprise capabilities, processes, techniques, information, the working mannequin and governance, serving to to tell function and expertise adjustments alongside HR and the enterprise.
This collective effort ought to end in two issues: first, figuring out extremely automated jobs; second, defining new job classifications that may mix job duties from partially automated jobs or for roles that may handle agent-driven work and efficiency. This can be crucial job that enterprise architects ever carry out — a rebuilding of the complete enterprise.
Programs should help AI-augmented work
With this accomplished, the following logical query to think about is how techniques must be designed to raised help augmented jobs.
For these positions, the query that CIOs, CHROs, EAs and CEOs want to think about is what techniques should be capable of do to help augmented work — and the place they fall quick at this time.
These are large questions that have to be answered collaboratively. As soon as once more, enterprise architects must take heart stage.
12 expertise CIOs say employees want to remain related
Lastly, I requested CIOs concerning the expertise that employees ought to develop to be related in an AI-driven future. Their solutions had been synthesized into 12 talent suggestions.
AI fluency. Perceive how AI fashions work — how they ingest, course of and validate information — and the place their limitations lie.
Human judgment. Apply essential pondering to evaluate AI outputs, particularly when one thing feels off or incomplete.
Downside-solving. Skill to border the best questions and use AI to speed up higher, extra knowledgeable selections.
Moral duty and AI security consciousness. Perceive how AI is used responsibly, with consideration to bias, danger, accountability and governance.
Adaptability. Skill to repeatedly modify to quickly evolving instruments, workflows and enterprise expectations.
Steady studying mindset. Dedication to ongoing talent improvement as AI reshapes roles and required capabilities.
Enterprise acumen. Perceive core enterprise targets, processes and worth drivers to make sure AI delivers significant outcomes.
Course of and techniques pondering. Skill to reimagine workflows end-to-end — transferring from remoted duties to built-in, AI-enabled outcomes.
Creativity and innovation. Establish new information units, use circumstances and methods AI can unlock worth — not simply optimize current work.
Communication and translation expertise. Bridge technical and enterprise worlds by explaining AI ideas in clear, actionable phrases.
Cross-functional collaboration. Work successfully throughout IT, HR and enterprise items as AI turns into embedded in each perform.
End result orientation. Concentrate on constructing techniques that ship predictive insights and measurable enterprise impression.
This can be a robust listing. Clearly, the diploma of fluency and course of and techniques pondering might be completely different for IT and enterprise employees. However all employees should be AI savvy to a level.
What CIOs cannot afford to get flawed
This text argues that this can be a second for CIOs to step up and associate deeply throughout the group. It additionally highlights a essential alternative for enterprise architects to assist outline the trail ahead. Delivering on this chance would require self-discipline and powerful collaboration. Success will rely on constructing the correct mix of expertise. The winners within the AI period will not be outlined by technical depth alone, however by their capacity to mix human capabilities — judgment, creativity, ethics — with AI as a associate to drive enterprise outcomes.
Writing a analysis paper is brutal. Even after the experiments are finished, a researcher nonetheless faces weeks of translating messy lab notes, scattered outcomes tables, and half-formed concepts into a sophisticated, logically coherent manuscript formatted exactly to a convention’s specs. For a lot of recent researchers, that translation work is the place papers go to die.
A workforce at Google Cloud AI Analysis suggest ‘PaperOrchestra‘, a multi-agent system that autonomously converts unstructured pre-writing supplies — a tough thought abstract and uncooked experimental logs — right into a submission-ready LaTeX manuscript, full with a literature overview, generated figures, and API-verified citations.
https://arxiv.org/pdf/2604.05018
The Core Downside It’s Fixing
Earlier automated writing programs, like PaperRobot, may generate incremental textual content sequences however couldn’t deal with the complete complexity of a data-driven scientific narrative. Newer end-to-end autonomous analysis frameworks like AI Scientist-v1 (which launched automated experimentation and drafting through code templates) and its successor AI Scientist-v2 (which will increase autonomy utilizing agentic tree-search) automate the whole analysis loop — however their writing modules are tightly coupled to their very own inside experimental pipelines. You may’t simply hand them your information and anticipate a paper. They’re not standalone writers.
In the meantime, programs specialised in literature critiques, akin to AutoSurvey2 and LiRA, produce complete surveys however lack the contextual consciousness to jot down a focused Associated Work part that clearly positions a particular new methodology towards prior artwork. CycleResearcher requires a pre-existing structured BibTeX reference listing as enter — an artifact hardly ever obtainable in the beginning of writing — and fails fully on unstructured inputs.
The result’s a spot: no present device may take unconstrained human-provided supplies — the type of factor an actual researcher would possibly even have after ending experiments — and produce an entire, rigorous manuscript by itself. PaperOrchestra is constructed particularly to fill that hole.
https://arxiv.org/pdf/2604.05018
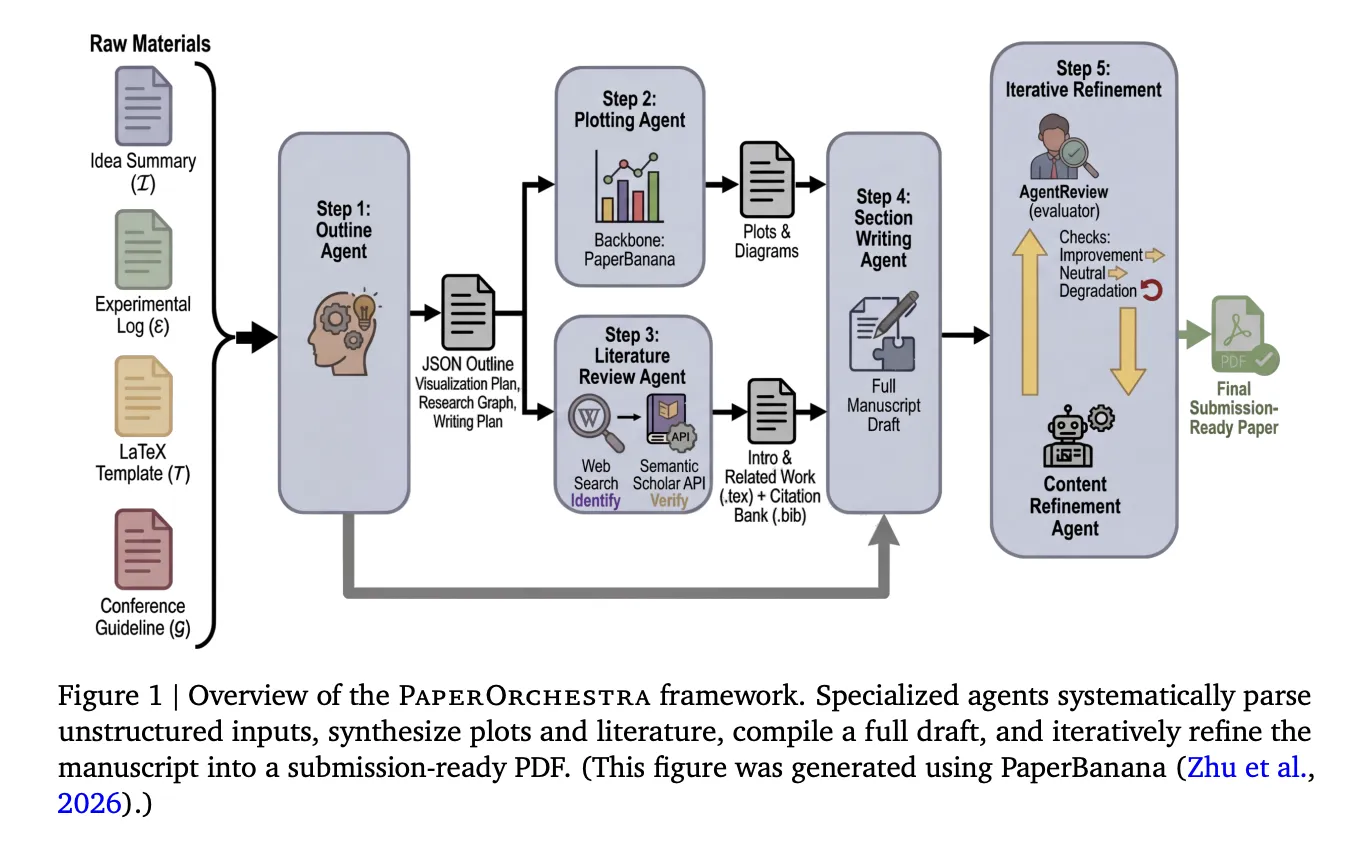
How the Pipeline Works
PaperOrchestra orchestrates 5 specialised brokers that work in sequence, with two working in parallel:
Step 1 — Define Agent: This agent reads the thought abstract, experimental log, LaTeX convention template, and convention tips, then produces a structured JSON define. This define features a visualization plan (specifying what plots and diagrams to generate), a focused literature search technique separating macro-level context for the Introduction from micro-level methodology clusters for the Associated Work, and a section-level writing plan with quotation hints for each dataset, optimizer, metric, and baseline methodology talked about within the supplies.
Steps 2 & 3 — Plotting Agent and Literature Assessment Agent (parallel): The Plotting Agent executes the visualization plan utilizing PaperBanana, an instructional illustration device that makes use of a Imaginative and prescient-Language Mannequin (VLM) critic to guage generated pictures towards design targets and iteratively revise them. Concurrently, the Literature Assessment Agent conducts a two-phase quotation pipeline: it makes use of an LLM outfitted with net search to determine candidate papers, then verifies every one by means of the Semantic Scholar API, checking for a sound fuzzy title match utilizing Levenshtein distance, retrieving the summary and metadata, and implementing a temporal cutoff tied to the convention’s submission deadline. Hallucinated or unverifiable references are discarded. The verified citations are compiled right into a BibTeX file, and the agent makes use of them to draft the Introduction and Associated Work sections — with a tough constraint that at the very least 90% of the gathered literature pool should be actively cited.
Step 4 — Part Writing Agent: This agent takes the whole lot generated up to now — the define, the verified citations, the generated figures — and authors the remaining sections: summary, methodology, experiments, and conclusion. It extracts numeric values immediately from the experimental log to assemble tables and integrates the generated figures into the LaTeX supply.
Step 5 — Content material Refinement Agent: Utilizing AgentReview, a simulated peer-review system, this agent iteratively optimizes the manuscript. After every revision, the manuscript is accepted provided that the general AgentReview rating will increase, or ties with web non-negative sub-axis features. Any general rating lower triggers an instantaneous revert and halt. Ablation outcomes present this step is vital: refined manuscripts dominate unrefined drafts with 79%–81% win charges in automated side-by-side comparisons, and ship absolute acceptance charge features of +19% on CVPR and +22% on ICLR in AgentReview simulations.
The complete pipeline makes roughly 60–70 LLM API calls and completes in a imply of 39.6 minutes per paper — solely about 4.5 minutes greater than AI Scientist-v2’s 35.1 minutes, regardless of working considerably extra LLM calls (40–45 for AI Scientist-v2 vs. 60–70 for PaperOrchestra).
The Benchmark: PaperWritingBench
The analysis workforce additionally introduce PaperWritingBench, described as the primary standardized benchmark particularly for AI analysis paper writing. It accommodates 200 accepted papers from CVPR 2025 and ICLR 2025 (100 from every venue), chosen to check adaptation to totally different convention codecs — double-column for CVPR versus single-column for ICLR.
For every paper, an LLM was used to reverse-engineer two inputs from the printed PDF: a Sparse Concept Abstract (high-level conceptual description, no math or LaTeX) and a Dense Concept Abstract (retaining formal definitions, loss capabilities, and LaTeX equations), alongside an Experimental Log derived by extracting all numeric information and changing determine insights into standalone factual observations. All supplies have been absolutely anonymized, stripping creator names, titles, citations, and determine references.
This design isolates the writing activity from any particular experimental pipeline, utilizing actual accepted papers as floor fact — and it reveals one thing vital. For Total Paper High quality, the Dense thought setting considerably outperforms Sparse (43%–56% win charges vs. 18%–24%), since extra exact methodology descriptions allow extra rigorous part writing. However for Literature Assessment High quality, the 2 settings are almost equal (Sparse: 32%–40%, Dense: 28%–39%), that means the Literature Assessment Agent can autonomously determine analysis gaps and related citations with out counting on detail-heavy human inputs.
The Outcomes
In automated side-by-side (SxS) evaluations utilizing each Gemini-3.1-Professional and GPT-5 as decide fashions, PaperOrchestra dominated on literature overview high quality, reaching absolute win margins of 88%–99% over AI baselines. For general paper high quality, it outperformed AI Scientist-v2 by 39%–86% and the Single Agent by 52%–88% throughout all settings.
Human analysis — carried out with 11 AI researchers throughout 180 paired manuscript comparisons — confirmed the automated outcomes. PaperOrchestra achieved absolute win charge margins of 50%–68% over AI baselines in literature overview high quality, and 14%–38% in general manuscript high quality. It additionally achieved a 43% tie/win charge towards the human-written floor fact in literature synthesis — a notable end result for a completely automated system.
The quotation protection numbers inform a very clear story. AI baselines averaged solely 9.75–14.18 citations per paper, inflating their F1 scores on the must-cite (P0) reference class whereas leaving “good-to-cite” (P1) recall close to zero. PaperOrchestra generated a median of 45.73–47.98 citations, intently mirroring the ~59 citations present in human-written papers, and improved P1 Recall by 12.59%–13.75% over the strongest baselines.
Beneath the ScholarPeer analysis framework, PaperOrchestra achieved simulated acceptance charges of 84% on CVPR and 81% on ICLR, in comparison with human-authored floor fact charges of 86% and 94% respectively. It outperformed the strongest autonomous baseline by absolute acceptance features of 13% on CVPR and 9% on ICLR.
Notably, even when PaperOrchestra generates its personal figures autonomously from scratch (PlotOn mode) somewhat than utilizing human-authored figures (PlotOff mode), it achieves ties or wins in 51%–66% of side-by-side matchups — regardless of PlotOff having an inherent data benefit since human-authored figures usually embed supplementary outcomes not current within the uncooked experimental logs.
Key Takeaways
It’s a standalone author, not a analysis bot. PaperOrchestra is particularly designed to work with your supplies — a tough thought abstract and uncooked experimental logs — without having to run experiments itself. This can be a direct repair to the most important limitation of present programs like AI Scientist-v2, which solely write papers as a part of their very own inside analysis loops.
Quotation high quality, not simply quotation depend, is the true differentiator. Competing programs averaged 9–14 citations per paper, which sounds acceptable till you understand they have been nearly fully “must-cite” apparent references. PaperOrchestra averaged 45–48 citations per paper, matching human-written papers (~59), and dramatically improved protection of the broader tutorial panorama — the “good-to-cite” references that sign real scholarly depth.
Multi-agent specialization persistently beats single-agent prompting. The Single Agent baseline — one monolithic LLM name given all the identical uncooked supplies — was outperformed by PaperOrchestra by 52%–88% in general paper high quality. The framework’s 5 specialised brokers, parallel execution, and iterative refinement loop are doing work that no single immediate, no matter high quality, can replicate.
The Content material Refinement Agent just isn’t elective. Ablations present that eradicating the iterative peer-review loop causes a dramatic high quality drop. Refined manuscripts beat unrefined drafts 79%–81% of the time in side-by-side comparisons, with simulated acceptance charges leaping +19% on CVPR and +22% on ICLR. This step alone is liable for elevating a practical draft into one thing submission-ready.
Human researchers are nonetheless within the loop — and should be. The system explicitly can’t fabricate new experimental outcomes, and its refinement agent is instructed to disregard reviewer requests for information that doesn’t exist within the experimental log. The authors place PaperOrchestra as a complicated assistive device, with human researchers retaining full accountability for accuracy, originality, and validity of the ultimate manuscript.
A large marketing campaign impacting practically 100 on-line shops utilizing the Magento e-commerce platform hides credit score card-stealing code in a pixel-sized Scalable Vector Graphics (SVG) picture.
When clicking the checkout button, the sufferer is proven a convincing overlay that may validate card particulars and billing knowledge.
The marketing campaign was found by eCommerce safety firm Sansec, whose researchers imagine that the attacker possible gained entry by exploiting the PolyShell vulnerability disclosed in mid-March.
PolyShell impacts all Magento Open Supply and Adobe Commerce steady model 2 installations, permitting unauthenticated code execution and account takeover.
Sansec warned that greater than half of all weak shops have been focused in PolyShell assaults, which in some instances deployed cost card skimmers utilizing WebRTC for stealthy knowledge exfiltration.
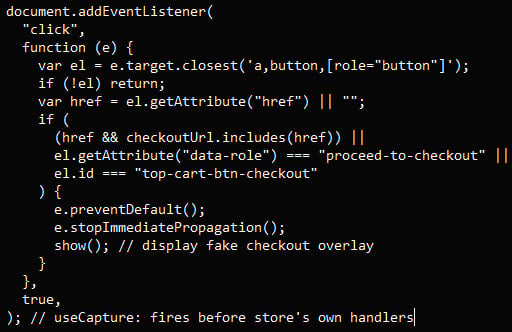
Within the newest marketing campaign, the researchers discovered that the malware is injected as a 1×1-pixel SVG factor with an ‘onload’ handler into the goal web site’s HTML.
“The onload handler incorporates all the skimmer payload, base64-encoded inside an atob() name and executed through setTimeout,” Sansec explains.
“This method avoids creating exterior script references that safety scanners sometimes flag. The complete malware lives inline, encoded as a single string attribute.”
When unsuspecting consumers click on checkout on compromised shops, a malicious script intercepts the press and shows a faux “Safe Checkout” overlay that features card particulars fields and a billing type.
Cost knowledge submitted on this web page is validated in actual time utilizing the Luhn verification and exfiltrated to the attacker in an XOR-encrypted, base64-obfuscated JSON format.
Decoded payload Supply: Sansec
Sansec recognized six exfiltration domains, all hosted at IncogNet LLC (AS40663) within the Netherlands, and every getting knowledge from 10 to fifteen confirmed victims.
To guard towards this marketing campaign, Sansec recommends the next:
Search for hidden SVG tags with an onload attribute utilizing atob() and take away them out of your website recordsdata
Examine if the _mgx_cv key exists in browser localStorage, as this means cost knowledge might have been stolen
Monitor and block requests to /fb_metrics.php or any unfamiliar analytics-like domains
Block all site visitors to the IP tackle 23.137.249.67 and related domains
As of writing, Adobe has nonetheless not launched a safety replace to deal with the PolyShell flaw in manufacturing variations of Magento. The seller has solely made a repair out there within the pre-release model 2.4.9-alpha3+.
Additionally, Adobe has not responded to our repeated requests for a touch upon the subject.
Web site homeowners/admins are suggested to use all out there mitigations and, if attainable, improve Magento to the most recent beta launch.
Automated pentesting proves the trail exists. BAS proves whether or not your controls cease it. Most groups run one with out the opposite.
This whitepaper maps six validation surfaces, exhibits the place protection ends, and gives practitioners with three diagnostic questions for any software analysis.
Scientists have unveiled an in depth “atlas” of the placenta and uterus, displaying how these distinctive tissues develop and evolve all through being pregnant to accommodate a creating fetus.
In charting this new map, the scientists revealed a subtype of cell that had by no means been described earlier than and seems to be distinctive to being pregnant.
These cells should not current within the uterus outdoors being pregnant, and so they all of the sudden rise in quantity at first of gestation because the uterine lining morphs to cradle and help the embryo, defined examine first writer Cheng Wang, a specialist in regeneration drugs specialist on the College of California, San Francisco (UCSF).
“That was an thrilling second through the examine,” examine senior writer Jingjing Li, an affiliate professor of neurology at UCSF who research human genomics, stated of the cells’ discovery. “We requested round — nobody is aware of what they’re.”
These newly described cells appear to be concerned in linking the placenta to the maternal blood provide, and so they carry receptors that reply to cannabinoids. Cannabinoids embrace body-made chemical substances, in addition to the hashish compounds THC and CBD. Due to this fact, the researchers suspect these cells could assist to clarify why hashish use in being pregnant is tied to well being penalties comparable to decreased blood movement to the placenta; poor oxygen supply to the fetus; and a heightened danger of preterm delivery, low delivery weight and NICU admission.
It is unlikely that these cells’ sensitivity to cannabinoids absolutely explains the dangers posed by hashish use in being pregnant, Li informed Stay Science; different potential culprits have been described within the medical literature. Nonetheless, these newfound cells are an element that warrant additional examine, he stated.
An important “velocity bump”
Previous to the brand new examine, printed April 8 within the journal Nature, different analysis teams had mapped the placenta and uterus utilizing comparable strategies. Nevertheless, these earlierresearch coated solely choose chapters of being pregnant.
Get the world’s most fascinating discoveries delivered straight to your inbox.
“The most important distinction is we’re trying on the complete time course” from early being pregnant to delivery, Li stated. The brand new atlas incorporates knowledge from tissues that have been collected between weeks 5 and 39 of being pregnant after which saved in tissue banks at UCSF and Stanford College.
Li’s lab analyzes tissues in nice element, on the decision of single cells, with placental growth being one of many crew’s main analysis focuses. Their new atlas incorporates snapshots of which genes have been lively and which proteins have been current within the analyzed cells at a given stage of being pregnant. It additionally appears at “chromatin accessibility,” which displays how DNA molecules are packaged inside the cell and which genes could be activated at a given second.
In whole, the crew analyzed about 1.2 million placental and uterine cells, together with 200,000 remoted cells and 1 million cells embedded of their unique areas inside the tissue.
The work revealed fascinating hyperlinks between a given cell’s gene exercise and its habits.
For example, early in being pregnant, sure fetal cells invade the uterus and its main arteries, serving to to determine blood movement to the placenta. Utilizing machine studying, the researchers predicted how deeply a given cell would invade the uterus based mostly on its gene exercise. When this invasion goes awry — for instance, if cells don’t penetrate deeply sufficient or they penetrate too deeply — it could actually contribute to problems like preeclampsia or placenta accreta.
This picture labels the newfound cell subtype, generally known as decidual stromal cell 4 (DSC4), with yellow arrows. (Picture credit score: Courtesy of Jingjing Li and Cheng Wang, UCSF)
It seems that the brand new cell kind recognized by the researchers helps to manage the invasion. By sending out particular alerts, the cell kind acts as a “velocity bump” to stop the method from continuing too rapidly, Li stated.
“It is on the frontline of the maternal-fetal interface,” Weng informed Stay Science. Numerous proteins carried by these cells help this concept that they are regulating the habits of different cells at this important interface, he stated.
With their accomplished map in hand, the researchers married their findings with knowledge from big genetics research of preeclampsia, preterm delivery and being pregnant loss. Theseprintedresearch had uncovered hyperlinks between particular gene variants and the danger of those problems. The crew might then pinpoint the particular cells within the placenta and uterus that actively use these genes and are due to this fact most susceptible to the situations.
“The query is, ‘During which cell kind will these high-risk variants take impact?'” Li stated. “This may assist us to know which cells are underlying these problems” and probably develop therapies that focus on these cells sooner or later.
Whereas the examine brings collectively a trove of information, Li emphasised that there is extra work to be carried out. The examine centered on wholesome pregnancies, so there’s nonetheless a query of how pregnancies impacted by numerous situations differ from this baseline. The crew is now working with scientific companions to start out making these comparisons. General, they goal to extend the entire variety of cells analyzed to verify they’re capturing the complete range of cells within the pregnant uterus.
“If we embrace extra cells, extra samples, numerous new, thrilling discoveries could possibly be made,” Li stated. “So that is actually a place to begin.”
This text is for informational functions solely and isn’t meant to supply medical recommendation.
When you’ve got a bug in your evaluator program, nl will produce, likely, the next error:
your program returned 198
confirm that your program is a operate evaluator program
r(198);
The error signifies that your program can’t be evaluated.
The easiest way to identify any points in your evaluator program is to run it interactively. You simply must outline your pattern (often observations the place not one of the variables are lacking), and a matrix with values on your parameters. Let me present you an instance with nlces2. That is the code to suit the CES manufacturing operate, from the documentation for the nl command:
cscript
program nlces2
model 12
syntax varlist(min=3 max=3) if, at(identify)
native logout : phrase 1 of `varlist'
native capital : phrase 2 of `varlist'
native labor : phrase 3 of `varlist'
// Retrieve parameters out of at matrix
tempname b0 rho delta
scalar `b0' = `at'[1, 1]
scalar `rho' = `at'[1, 2]
scalar `delta' = `at'[1, 3]
tempvar kterm lterm
generate double `kterm' = `delta'*`capital'^(-1*`rho') `if'
generate double `lterm' = (1-`delta')*`labor'^(-1*`rho') `if'
// Fill in dependent variable
substitute `logout' = `b0' - 1/`rho'*ln(`kterm' + `lterm') `if'
finish
webuse manufacturing, clear
nl ces2 @ lnoutput capital labor, parameters(b0 rho delta) ///
preliminary(b0 0 rho 1 delta 0.5)
Now, let me present you the best way to run it interactively:
webuse manufacturing, clear
*generate a variable to limit my pattern to observations
*with non-missing values in my variables
egen u = rowmiss(lnoutput capital labor)
*generate a matrix with parameters the place I'll consider my operate
mat M = (0,1,.5)
gen nloutput_new = 1
nlces2 nloutput_new capital labor if u==0, at(M)
This may consider this system solely as soon as, utilizing the parameters in matrix M. Discover that I generated a brand new variable to make use of as my dependent variable. It’s because this system nlces2, when run by itself, will modify the dependent variable. If you run this program by itself, you’ll get hold of a extra particular error message. You may add debugging code to this program, and you can even use the hint setting to see how every step is executed. Sort assist hint to study this setting.
One other potential supply of error (which can generate error r(480) when run from nl) is when an evaluator operate produces lacking values for observations within the pattern. If so, you will note these lacking values within the variable nloutput_new, i.e., within the variable you entered as dependent when operating your evaluator by itself. You may then add debugging code, for instance, utilizing codebook or summarize to look at the completely different components that contribute to the substitution carried out within the dependent variable.
For instance, after the road that generates `kterm’, I may write
summarize `kterm' if u == 0
to see if this variable accommodates any lacking values in my pattern.
This technique may also be used to debug your operate evaluator packages for nlsur. In an effort to protect your dataset, it is advisable use copies for all of the dependent variables in your mannequin.
At present, we’re sharing how Amazon Bedrock makes it easy to customise Amazon Nova fashions on your particular enterprise wants. As prospects scale their AI deployments, they want fashions that replicate proprietary information and workflows — whether or not which means sustaining a constant model voice in buyer communications, dealing with complicated industry-specific workflows or precisely classifying intents in a high-volume airline reservation system. Strategies like immediate engineering and Retrieval-Augmented Technology (RAG) present the mannequin with further context to enhance activity efficiency, however these strategies don’t instill native understanding into the mannequin.
Amazon Bedrock helps three customization approaches for Nova fashions: supervised fine-tuning (SFT), which trains the mannequin on labeled input-output examples; reinforcement fine-tuning (RFT), which makes use of a reward perform to information studying towards goal behaviors; and mannequin distillation, which transfers information from a bigger trainer mannequin right into a smaller, sooner scholar mannequin. Every approach embeds new information immediately into the mannequin weights, moderately than supplying it at inference time by means of prompts or retrieved context. With these approaches, you get sooner inference, decrease token prices, and better accuracy on the duties that matter most to your enterprise. Amazon Bedrock manages the coaching course of routinely, requiring solely that you simply add your knowledge to Amazon Easy Storage Service (Amazon S3) and provoke the job by means of the AWS Administration Console, CLI, or API. Deep machine studying experience is just not required. Nova fashions assist on-demand invocation of custom-made fashions in Amazon Bedrock. This implies you pay solely per-call at the usual price for the mannequin, as an alternative of needing to buy costlier allotted capability (Provisioned Throughput).
On this submit, we’ll stroll you thru an entire implementation of mannequin fine-tuning in Amazon Bedrock utilizing Amazon Nova fashions, demonstrating every step by means of an intent classifier instance that achieves superior efficiency on a website particular activity. All through this information, you’ll be taught to organize high-quality coaching knowledge that drives significant mannequin enhancements, configure hyperparameters to optimize studying with out overfitting, and deploy your fine-tuned mannequin for improved accuracy and decreased latency. We’ll present you learn how to consider your outcomes utilizing coaching metrics and loss curves.
Understanding fine-tuning and when to make use of it
Context-engineering strategies equivalent to immediate engineering or Retrieval-Augmented Technology (RAG) place info into the mannequin’s immediate. These approaches provide important benefits: they take impact instantly with no coaching required, permit for dynamic info updates, and work with a number of basis fashions with out modification. Nevertheless, these strategies eat context window tokens on each invocation, which might improve cumulative prices and latency over time. Extra importantly, they don’t generalize nicely. The mannequin is just studying directions every time moderately than having internalized the information, so it could possibly battle with novel phrasings, edge instances, or duties that require reasoning past what was explicitly offered within the immediate. Customization strategies, by comparability, incorporate the brand new information immediately into the mannequin by including an adapter matrix of further weights and customizing these (“parameter-efficient fine-tuning”, aka “PEFT”). The ensuing custom-made mannequin has acquired new domain-specific abilities. Customization permits sooner and extra environment friendly small fashions to achieve efficiency akin to bigger fashions within the particular coaching area.
When to fine-tune: Think about fine-tuning when you may have a high-volume, well-defined activity the place you possibly can assemble high quality labeled examples or a reward perform. Use instances embody coaching a mannequin to accurately render your organization’s emblem, embedding model tone and firm insurance policies into the mannequin, or changing a standard ML classifier with a small LLM. For instance, Amazon Buyer Service custom-made Nova Micro for specialised buyer assist to enhance accuracy and scale back latency, bettering accuracy by 5.4% on domain-specific points and seven.3% on normal points.
Wonderful-tuned small LLMs like Nova Micro are more and more changing conventional ML classifiers for duties equivalent to intent detection. They ship the pliability and world information of an LLM on the velocity and value of a light-weight mannequin. In contrast to classifiers, LLMs deal with pure variation in phrasing, slang, and context with out retraining, and fine-tuning sharpens their accuracy additional for the particular activity. We display this with an intent classifier instance later on this weblog.
When NOT to fine-tune: Wonderful-tuning requires assembling high quality labeled knowledge or a reward perform and executing a coaching job, which entails upfront time and value. Nevertheless, this preliminary funding can scale back per-request inference prices and latency for high-volume functions.
Customization approaches
Amazon Bedrock provides three customization approaches for Nova fashions:
Supervised fine-tuning (SFT) customizes the mannequin to be taught patterns from labeled knowledge that you simply provide. This submit demonstrates this method in motion.
Reinforcement fine-tuning (RFT) takes a special method, utilizing coaching knowledge mixed with a reward perform, both customized code or an LLM appearing as a choose, to information the educational course of.
Mannequin distillation, for situations requiring information switch, enables you to compress insights from massive trainer fashions into smaller, extra environment friendly scholar fashions appropriate for resource-constrained units.
Amazon Bedrock routinely makes use of parameter environment friendly fine-tuning (PEFT) strategies acceptable to the mannequin for customizing Nova fashions. This reduces reminiscence necessities and accelerates coaching in comparison with full fine-tuning, whereas sustaining mannequin high quality. Having established when and why to make use of fine-tuning, let’s discover how Amazon Bedrock simplifies the implementation course of, and which Nova fashions assist this customization method.
Understanding Amazon Nova fashions on Amazon Bedrock
Amazon Bedrock totally automates infrastructure provisioning, compute administration, and coaching orchestration. You add knowledge to S3 and begin coaching with a single API name, with out managing clusters and GPUs or configuring distributed coaching pipelines. It supplies clear documentation for knowledge preparation (together with format specs and schema necessities), smart hyperparameter defaults (equivalent to epochCount, learningRateMultiplier), and coaching visibility by means of loss curves that aid you monitor convergence in real-time.
Nova Fashions: A number of of the Nova fashions permit fine-tuning (see documentation). After coaching is accomplished, you may have the choice to host the custom-made Nova fashions on Amazon Bedrock utilizing cost-effective On Demand inference, on the identical low inference worth because the non-customized mannequin.
Nova 2 Lite, for instance, is a quick, cost-effective reasoning mannequin. As a multimodal basis mannequin, it processes textual content, pictures, and video inside a 1-million token context window. This context window helps evaluation of paperwork longer than 400 pages or 90-minute movies in a single immediate. It excels at doc processing, video understanding, code era, and agentic workflows. Nova 2 Lite helps each SFT and RFT.
The smallest Nova mannequin, Nova Micro, can be significantly helpful as a result of it provides quick, low-cost inference with LLM intelligence. Nova Micro is good for pipeline processing duties executed as half of a bigger system, equivalent to fixing addresses or extracting knowledge fields from textual content. On this submit, we present an instance of customizing Nova Micro for a segmentation activity as an alternative of constructing a customized knowledge science mannequin.This desk exhibits each Nova 1 and Nova 2 reasoning fashions and their present availability as of publication time, with which fashions at present permit RFT or SFT. These capabilities are topic to vary; see the on-line documentation for essentially the most present mannequin availability and customization, and the Nova Customers Information for extra element on the fashions.
Mannequin
Capabilities
Enter
Output
Standing
Bedrock fine-tuning
Nova Premier
Most succesful mannequin for complicated duties and trainer for mannequin distillation
Textual content, pictures, video (excluding audio)
Textual content
Usually accessible
Can be utilized as a trainer for mannequin distillation
Nova Professional
Multimodal mannequin with finest mixture of accuracy, velocity, and value for a variety of duties
Textual content, pictures, video
Textual content
Usually accessible
SFT
Nova 2 Lite
Low value multimodal mannequin with quick processing
Textual content, pictures, video
Textual content
Usually accessible
RFT, SFT
Nova Lite
Low value multimodal mannequin with quick processing
Textual content, pictures, video
Textual content
Usually accessible
SFT
Nova Micro
Lowest latency responses at low value.
Textual content
Textual content
Usually accessible
SFT
Now that you simply perceive how Nova fashions assist fine-tuning by means of the Amazon Bedrock managed infrastructure, let’s look at a real-world state of affairs that demonstrates these capabilities in motion.
Use case instance – intent detection (changing conventional ML fashions)
Intent detection determines the class of the person’s meant interplay from the enter case. For instance, within the case of an airline journey help system, the person may be trying to get details about a beforehand booked flight or asking a query about airline companies, equivalent to learn how to transport a pet. Typically methods will need to route the inquiry to particular brokers based mostly on intent. Intent detection methods should function rapidly and economically at excessive quantity.
The standard answer for such a system has been to coach a machine-learning mannequin. Whereas that is efficient, builders are extra usually turning to small LLMs for these duties. LLMs provide extra flexibility, can rapidly be modified by means of immediate adjustments, and include in depth world information in-built. Their understanding of shorthand, texting slang, equal phrases, and context can present a greater person expertise, and the LLM improvement expertise is acquainted for AI engineers.
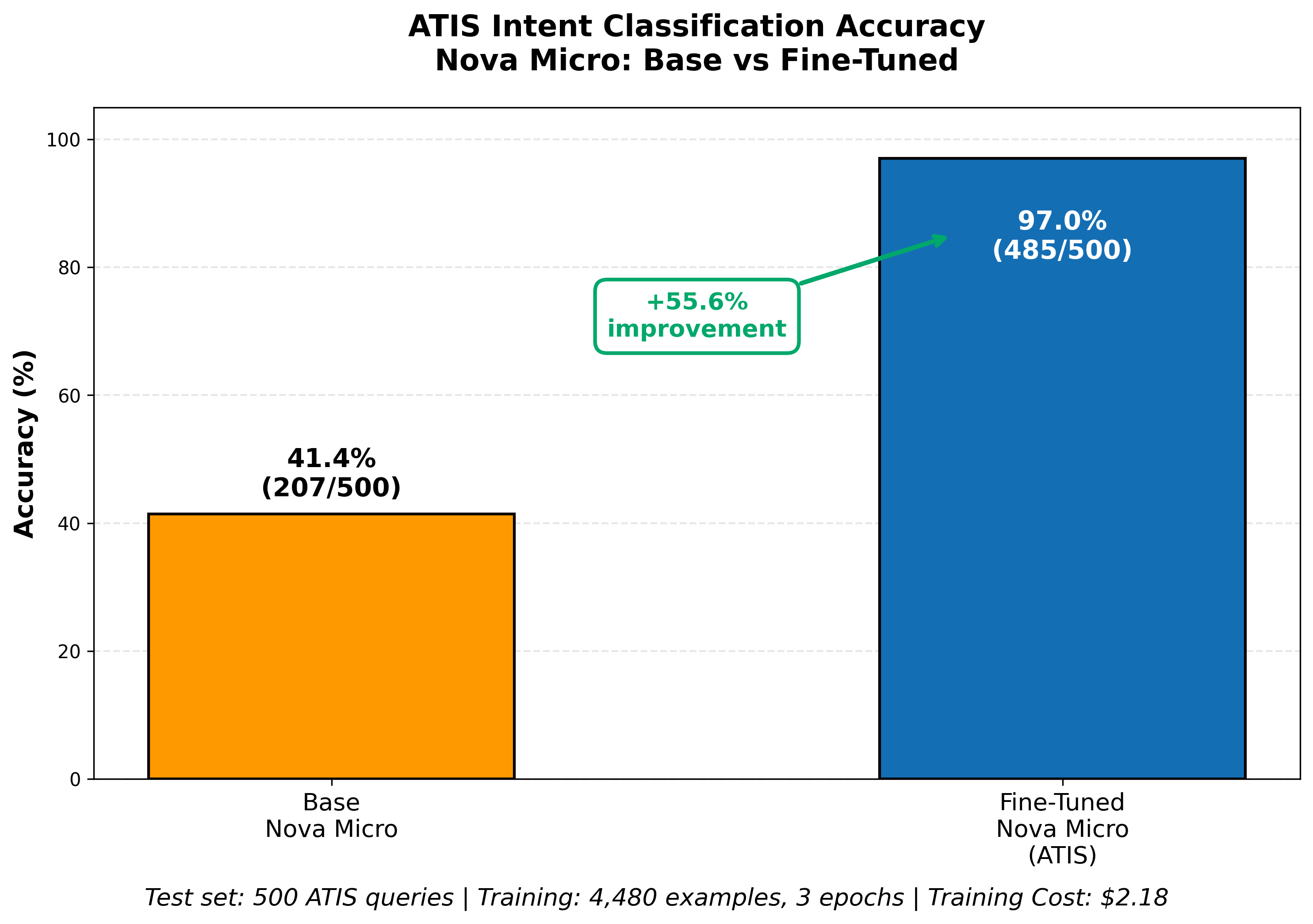
For our instance, we are going to customise Nova Micro mannequin on the open-source Airline Journey Info System (ATIS) knowledge set, an {industry} customary benchmark for intent-based methods. Nova Micro achieves 41.4% on ATIS with no customization, however we will customise it for the particular activity, bettering its accuracy to 97% with a easy coaching job.
Technical implementation: Wonderful-tuning course of
The 2 crucial elements that drive mannequin fine-tuning success are knowledge high quality and hyperparameter choice. Getting these proper determines whether or not your mannequin converges effectively or requires expensive retraining. Let’s stroll by means of every part of the implementation course of, beginning with learn how to put together your coaching knowledge.
Information preparation
Amazon Bedrock requires JSONL (JavaScript Object Notation Strains) format as a result of it helps environment friendly streaming of huge datasets throughout coaching, in an effort to course of your knowledge incrementally with out reminiscence constraints. This format additionally simplifies validation. Every line will be checked independently for errors. Confirm that every row within the JSONL file is legitimate JSON. If the file format is invalid, the Amazon Bedrock mannequin creation job will fail with an error. For extra element, see the documentation on Nova mannequin fine-tuning. We used a script to format the ATIS dataset as JSONL. Nova Micro accepts a separate validation set so we then off cut up 10% of the information right into a validation set (Nova 2 fashions do that routinely in customization). We additionally reserved a check set of data, which the mannequin was not skilled on, to facilitate clear testing outcomes.
For our intent classifier instance, our enter knowledge is textual content solely. Nevertheless, when fine-tuning multimedia fashions, additionally be sure to are utilizing solely supported picture codecs (PNG, JPEG, and GIF). Be sure your coaching examples span the vital instances. Validate your dataset together with your workforce and take away ambiguous or contradictory solutions earlier than fine-tuning.
{"schemaVersion": "bedrock-conversation-2024", "system": [{"text": "Classify the intent of airline queries. Choose one intent from this list: abbreviation, aircraft, aircraft+flight+flight_no, airfare, airfare+flight_time, airline, airline+flight_no, airport, capacity, cheapest, city, distance, flight, flight+airfare, flight_no, flight_time, ground_fare, ground_service, ground_service+ground_fare, meal, quantity, restrictionnnRespond with only the intent name, nothing else."}], "messages": [{"role": "user", "content": [{"text": "show me the morning flights from boston to philadelphia"}]}, {"function": "assistant", "content material": [{"text": "flight"}]}]}
Ready row in a coaching knowledge pattern (observe that though it seems wrapped, JSONL format is known as a single row per instance)
Essential: Be aware that the system immediate seems within the coaching knowledge. It is crucial that the system immediate used for coaching match the system immediate used for inference, as a result of the mannequin learns the system immediate as context that triggers its fine-tuned habits.
Information privateness concerns:
When fine-tuning with delicate knowledge:
Anonymize or masks PII (names, electronic mail addresses, cellphone numbers, fee particulars) earlier than importing to Amazon S3.
Think about knowledge residency necessities for regulatory compliance.
Amazon Bedrock doesn’t use your coaching knowledge to enhance base fashions.
For enhanced safety, think about using Amazon Digital Non-public Cloud (VPC) endpoints for personal connectivity between S3 and Amazon Bedrock, eliminating publicity to the general public web.
Key hyperparameters
Hyperparameters management the coaching job. Amazon Bedrock units affordable defaults, and you’ll usually use them with no adjustment, however you would possibly want to regulate them on your fine-tuning job to realize your goal accuracy. Listed below are the hyperparameters for the Nova understanding fashions – seek the advice of the documentation for different fashions:
Three hyperparameters management your coaching job’s habits, and whereas Amazon Bedrock units affordable defaults, understanding them helps you optimize outcomes. Getting these settings proper can prevent hours of coaching time and reduce compute prices.
The primary hyperparameter, epochCount, specifies what number of full passes the mannequin makes by means of your dataset. Consider it like studying a e-book a number of instances to enhance comprehension. After the primary learn you would possibly retain 60% of the fabric; a second cross raises comprehension to 80%. Nevertheless, after you perceive 100% of the fabric, further readings waste coaching time with out producing positive factors. Amazon Nova fashions assist 1 to five epochs with a default of two. Bigger datasets sometimes converge with fewer epochs, whereas smaller datasets profit from extra iterations. For our ATIS intent classifier instance with ~5000 mixed samples, we set epochCount to three.
The learningRateMultiplier controls how aggressively the mannequin learns from errors. It’s primarily the step measurement for corrections. If the educational price is simply too excessive, you would possibly miss particulars and soar to fallacious conclusions. If the speed is simply too low, you kind conclusions slowly. We use 1e-5 (0.00001) for the ATIS instance, which supplies steady, gradual studying. The learningRateWarmupSteps parameter steadily will increase the educational price to the desired worth over a set variety of iterations, assuaging unstable coaching at first. We use the default worth of 10 for our instance.
Why this issues to you: Setting the appropriate epoch rely avoids wasted coaching time and prices. Every epoch represents one other cross by means of the entire coaching knowledge, which is able to improve the variety of tokens processed (the principle value in mannequin coaching—see “Price and coaching time” later on this submit). Too few epochs imply your mannequin won’t be taught the coaching knowledge successfully sufficient. Discovering this steadiness early saves each time and price range. The educational price immediately impacts your mannequin’s accuracy and coaching effectivity, probably which means the distinction between a mannequin that converges in hours versus one which by no means reaches acceptable efficiency.
Beginning a fine-tuning job
The prerequisite of fine-tuning is creating an S3 bucket with coaching knowledge.
S3 bucket setup
Create an S3 bucket in the identical area as your Amazon Bedrock job with the next safety configurations:
Allow server-side encryption (SSE-S3 or SSE-KMS) to guard coaching knowledge at relaxation.
Block public entry on the bucket to stop unauthorized publicity.
Allow S3 versioning to guard coaching knowledge from unintended overwrites and monitor adjustments throughout coaching iteration.
Apply the identical encryption and entry controls to your output S3 bucket. Add your JSONL file within the new S3 bucket after which set up it with the /training-data prefix. S3 versioning helps defend your coaching knowledge from unintended overwrites and permits you to monitor adjustments throughout coaching iterations. That is important whenever you’re experimenting with totally different dataset variations to optimize outcomes.
Select Check, Chat/Textual content playground and ensure that Nova Micro seems within the mannequin selector drop-down record.
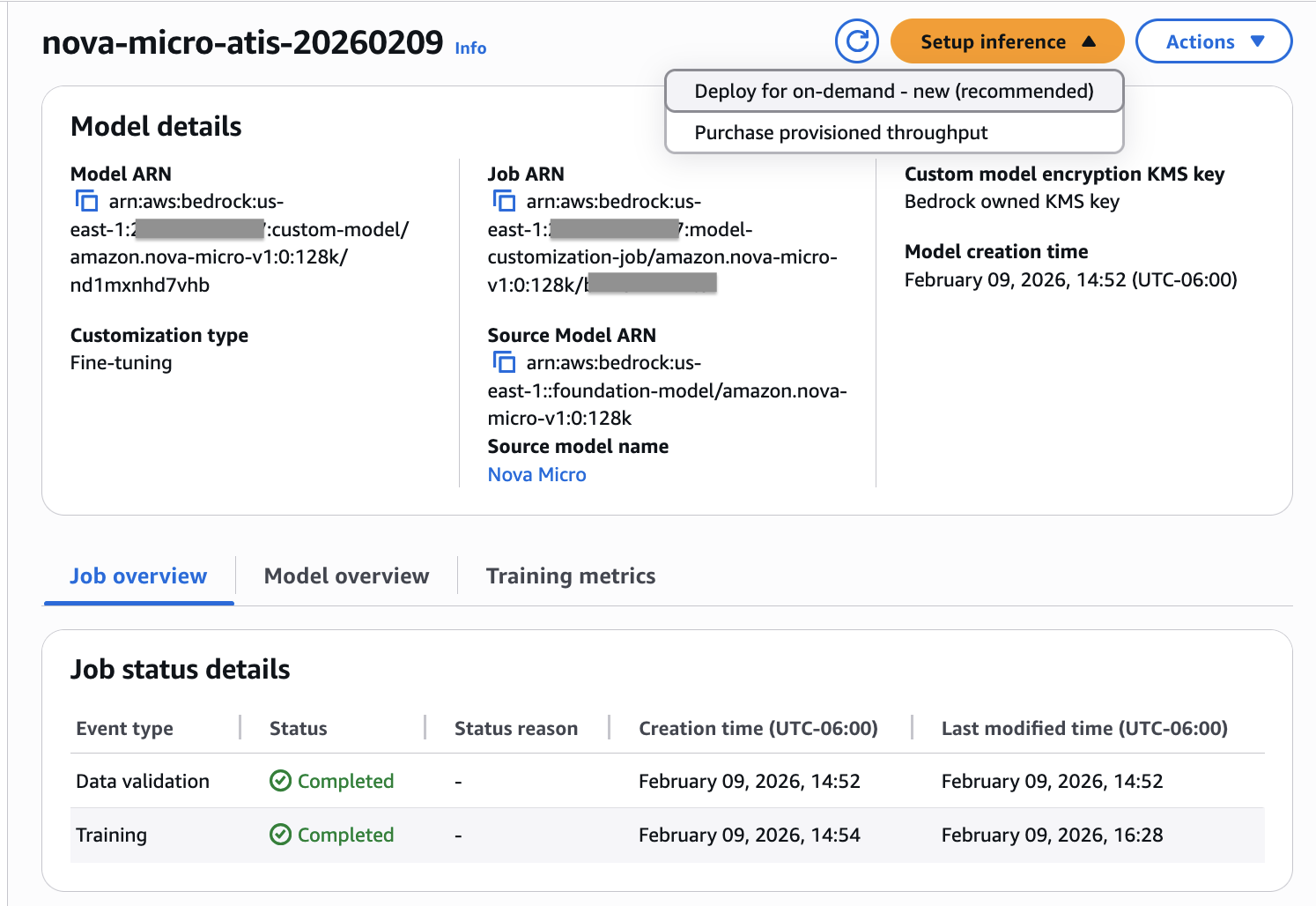
Beneath Customized mannequin, select Create, after which choose Supervised fine-tuning job.
Determine 1: Creating supervised fine-tuning job
Specify “Nova Micro” mannequin because the supply mannequin.
Within the Coaching knowledge part, enter the S3 URI path to your JSONL coaching file (for instance, s3://amzn-s3-demo-bucket/training-data/focused-training-data-v2.jsonl).
Within the Output knowledge part, specify the S3 URI path the place coaching outputs will probably be saved (for instance, s3://amzn-s3-demo-bucket/output-data/).
Broaden the Hyperparameters part and configure the next values: epochCount: 3, learningRateMultiplier: 1e-5, learningRateWarmupSteps: 10
Choose the IAM function with least-privilege S3 entry permissions or you possibly can create one. The function ought to have:
Scoped permissions restricted to particular actions (s3:GetObject and s3:PutObject) on particular bucket paths (for instance, arn:aws:s3:::your-bucket-name/training-data/* and arn:aws:s3:::your-bucket-name/output-data/*)
Keep away from over-provisioning and embody IAM situation keys.
To observe the coaching job’s standing and convergence:
Monitor the job standing within the Customized fashions dashboard.
Look ahead to the Information validation section to finish, adopted by the Coaching section (completion time ranges from minutes to hours relying on dataset measurement and modality).
After coaching completes, select your job title to view the Coaching metrics tab and confirm the loss curve exhibits correct convergence.
After coaching is accomplished, if the job is profitable, a customized mannequin is created and prepared for inference. You’ll be able to deploy the custom-made Nova mannequin for on-demand inference.
Determine 2: Verifying job standing
Evaluating coaching success
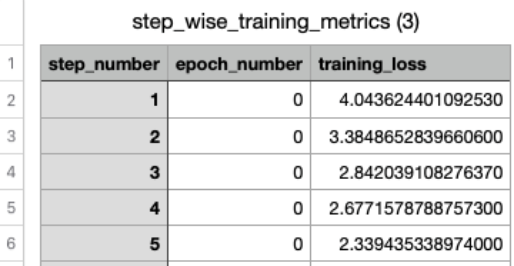
With Amazon Bedrock, you possibly can consider your fine-tuning job’s effectiveness by means of coaching metrics and loss curves. By analyzing the coaching loss development throughout steps and epochs, you possibly can assess whether or not your mannequin is studying successfully and decide if hyperparameter changes are wanted for optimum efficiency. Amazon Bedrock customization routinely shops coaching artifacts, together with validation outcomes, metrics, logs, and coaching knowledge in your designated S3 bucket, supplying you with full visibility into the coaching course of. Coaching metrics knowledge enables you to monitor how your mannequin performs with particular hyperparameters and make knowledgeable tuning selections.
Determine 3: Instance coaching metrics in CSV format
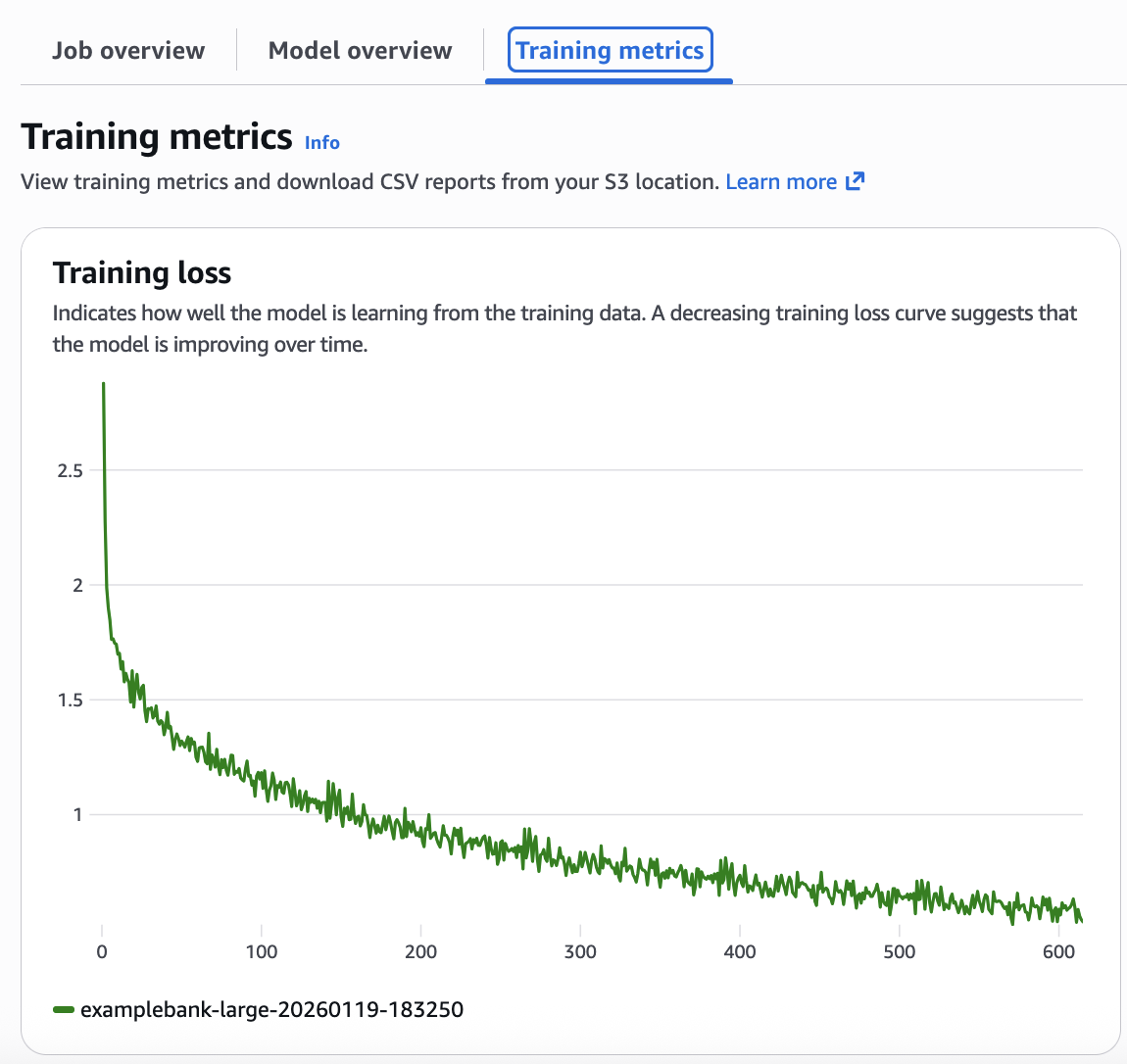
You’ll be able to visualize your mannequin’s coaching progress immediately from the Amazon Bedrock Customized Fashions console. Choose your custom-made mannequin to entry detailed metrics, together with an interactive coaching loss curve that exhibits how successfully your mannequin discovered from the coaching knowledge over time. The loss curve provides perception into how coaching progressed, and whether or not hyperparameters want modification for efficient coaching. From the Amazon Bedrock Customized Fashions tab, choose the custom-made mannequin to see its particulars, together with the coaching loss curve. (Determine 4).
Determine 4: Analyzing the loss curve from the coaching metrics
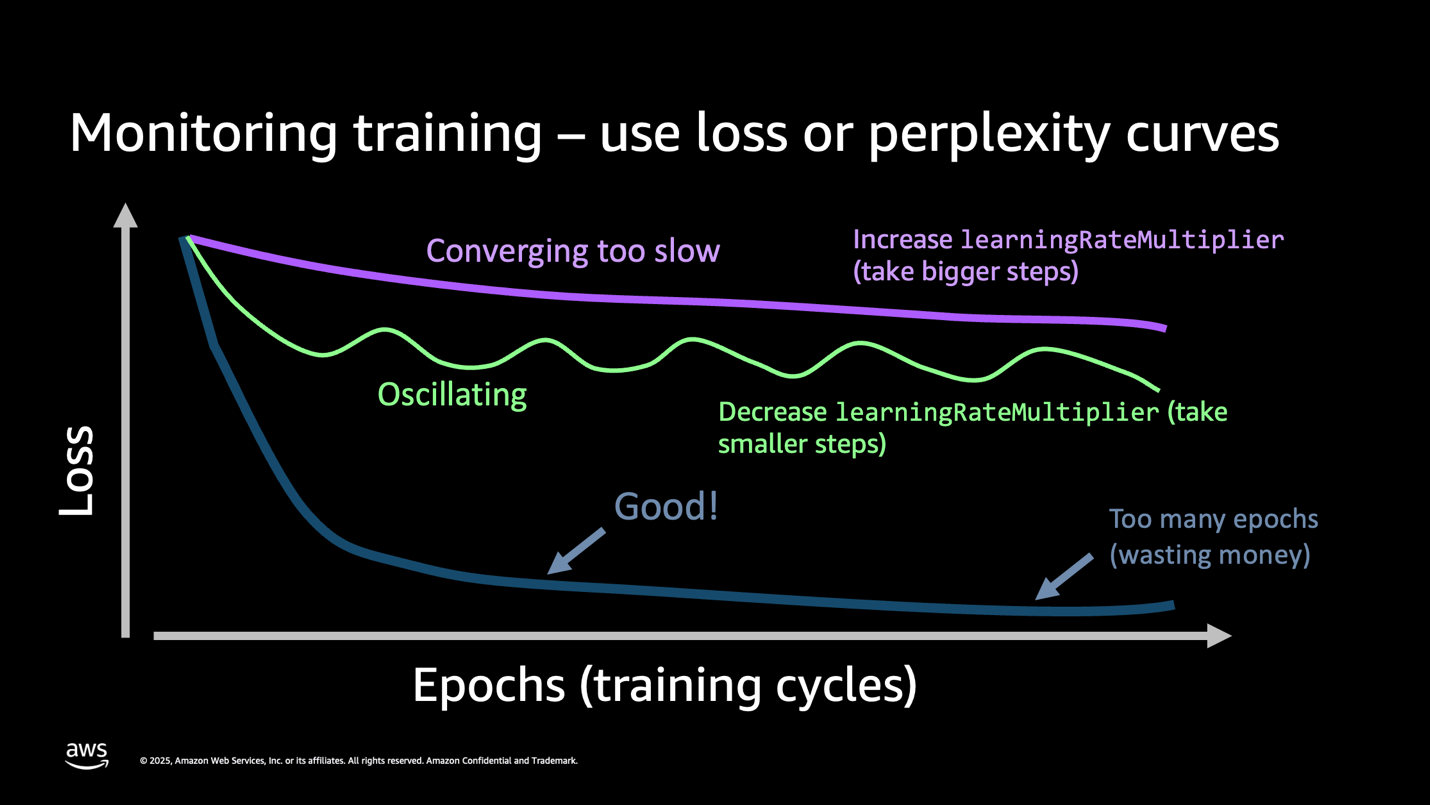
This loss curve exhibits that the mannequin is performing nicely. The reducing loss curve proven in your metrics confirms the mannequin efficiently discovered out of your coaching knowledge. Ideally whereas the mannequin is studying, the coaching loss and validation loss curves ought to monitor equally .A well-configured mannequin exhibits regular convergence—the loss decreases easily with out dramatic fluctuations. If you happen to see oscillating patterns in your loss curve (wild swings up and down), scale back your learningRateMultiplier by 50% and restart coaching. In case your loss decreases too slowly (flat or barely declining curve), improve your learningRateMultiplier by 2x. In case your loss plateaus early (flattens earlier than reaching good accuracy), improve your epochCount by 1-2 epochs.
Determine 5:Understanding the loss curve
Key takeaway: Your loss curve tells the entire story. A clean downward pattern means success. Wild oscillations imply that your studying price is simply too excessive. Flat strains imply you want extra epochs or higher knowledge. Monitor this one metric to keep away from expensive retraining.
Customization finest practices
Maximizing your fine-tuning success begins with knowledge high quality. Small, high-quality datasets persistently outperform massive, noisy ones. Concentrate on curating labeled examples that precisely symbolize your goal area moderately than amassing huge volumes of mediocre knowledge. Every coaching pattern ought to be correctly formatted and validated earlier than use, as clear knowledge immediately interprets to raised mannequin efficiency. Keep in mind to specify an acceptable system immediate.
Frequent pitfalls to keep away from embody over-training (operating too many epochs after convergence), suboptimal knowledge formatting (inconsistent JSON/JSONL buildings), and hyperparameter settings that want adjustment. We suggest validating your coaching knowledge format earlier than beginning and monitoring loss curves actively throughout coaching. Look ahead to indicators that your mannequin has converged. Persevering with coaching past this level wastes assets with out bettering outcomes.
Price and coaching time
Coaching the custom-made Nova Micro mannequin for our ATIS instance with 4,978 mixed examples and three coaching epochs (~1.75M whole tokens) accomplished in about 1.5 hours and value solely $2.18, plus a $1.75 month-to-month recurring storage payment for the mannequin. On-Demand inference utilizing custom-made Amazon Nova fashions is charged on the identical price because the non-customized fashions. See the Bedrock pricing web page for reference. The managed fine-tuning offered by Amazon Bedrock and the Amazon Nova fashions deliver fine-tuning nicely inside value thresholds for many organizations. The benefit of use and value effectiveness opens new potentialities for customizing fashions to supply higher and sooner outcomes with out sustaining lengthy prompts or information bases of data particular to your group.
Deploying and testing the fine-tuned mannequin
Think about on-demand inference for unpredictable or low-volume workloads. Use the costlier provisioned throughput when wanted for constant, high-volume manufacturing workloads requiring assured efficiency and decrease per-token prices.
Mannequin safety concerns:
Prohibit mannequin invocation utilizing IAM useful resource insurance policies to regulate which customers and functions can invoke your customized mannequin.
Implement authentication/authorization for API callers accessing the on-demand inference endpoint by means of IAM roles and insurance policies.
Community safety:
Configure VPC endpoints for Amazon Bedrock to maintain site visitors inside your AWS community.
Prohibit community entry to coaching and inference pipelines utilizing safety teams and community ACLs.
Think about deploying assets inside a VPC for extra network-level controls.
The deployment title ought to be distinctive, and the outline ought to clarify intimately what the customized mannequin is used for.
To deploy the mannequin, enter deployment title, description and select Create (Determine 6).
Determine 6: Deploying a customized mannequin with on-demand inference
After the standing adjustments to “Energetic” the mannequin is able to use by your software and will be examined through the Amazon Bedrock playground. Select Check in playground (Determine 7).
Determine 7: Testing the mannequin from the deployed inference endpoint
Logging and monitoring:
Allow the next for safety auditing and incident response:
AWS CloudTrail for Amazon Bedrock API name logging
Amazon CloudWatch for mannequin invocation metrics and efficiency monitoring
S3 entry logs for monitoring knowledge entry patterns.
Testing the mannequin within the playground:
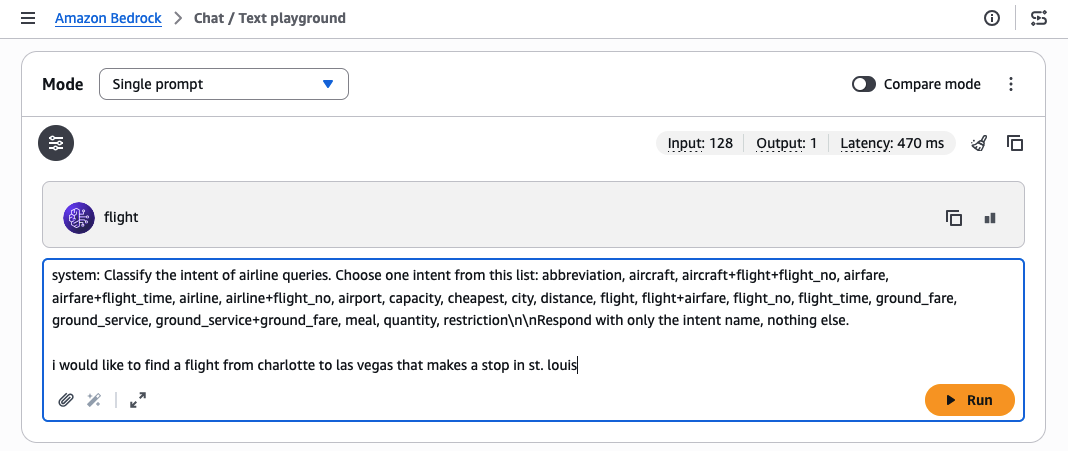
To check inference with the customized mannequin, we use the Amazon Bedrock playground, giving the next instance immediate:system:
Classify the intent of airline queries. Select one intent from this record: abbreviation, plane, plane+flight+flight_no, airfare, airfare+flight_time, airline, airline+flight_no, airport, capability, most cost-effective, metropolis, distance, flight, flight+airfare, flight_no, flight_time, ground_fare, ground_service, ground_service+ground_fare, meal, amount, restrictionnnRespond with solely the intent title, nothing else. I wish to discover a flight from charlotte to las vegas that makes a cease in st. louisIf referred to as on the bottom mannequin, the identical immediate will return a much less correct reply.
Essential: Be aware that the system immediate supplied with the coaching knowledge for fine-tuning have to be included together with your immediate throughout invocation for finest outcomes. As a result of the playground doesn’t present a separate place to place the system immediate for our customized mannequin, we embody it within the previous immediate string.
Determine 8: Manually evaluating a custom-made mannequin within the check playground
Evaluating your custom-made mannequin
After you may have skilled your mannequin, you need to consider its real-world efficiency. A typical analysis is “LLM as a choose,” the place a bigger, extra clever mannequin with entry to a full RAG database scores the skilled mannequin’s responses in opposition to the anticipated responses. Amazon Bedrock supplies the Amazon Bedrock Evaluations service for this goal (or you need to use your individual framework). For steering, seek advice from the weblog submit LLM-as-a-judge on Amazon Bedrock Mannequin Analysis.
Your analysis ought to use a check set of questions and solutions, ready utilizing the identical methodology as your coaching knowledge, however saved separate so the mannequin has not seen the precise questions. Determine 9 exhibits the fine-tuned mannequin achieves accuracy of 97% on the check knowledge set, a 55% enchancment vs. the bottom Nova Micro mannequin.
Determine 9: Analysis of fine-tuning outcomes vs. base mannequin
Past Amazon Bedrock customization
Amazon Bedrock’s simplified customization expertise will meet many buyer wants. Do you have to want extra in depth management over customization, Amazon SageMaker AI supplies a broader vary of customization varieties and extra detailed management over hyperparameters – see the weblog Saying Amazon Nova customization in Amazon SageMaker AI for extra element.
For instances the place much more in depth customization is required, Amazon Nova Forge supplies a strategic various to constructing basis fashions from scratch. Whereas fine-tuning teaches particular activity behaviors by means of labeled examples, Nova Forge makes use of continued pre-training to construct complete area information by immersing the mannequin in tens of millions to billions of tokens of unlabeled, proprietary knowledge. This method is good for organizations with huge proprietary datasets, extremely specialised domains requiring deep experience, or these constructing long-term strategic foundational fashions that may function organizational property.
Nova Forge goes past customary fine-tuning by providing superior capabilities together with knowledge mixing to mitigate catastrophic forgetting throughout full-rank supervised fine-tuning, checkpoint choice for optimum mannequin efficiency, and bring-your-own-optimizer (BYOO) for multi-turn reinforcement fine-tuning. Whereas requiring higher funding by means of an annual subscription and longer coaching cycles, Forge can ship a considerably cheaper path than coaching basis fashions from scratch. This method is good for constructing strategic AI property that function long-term aggressive benefits. For Nova Forge customization examples, see the Amazon Nova Customization Hub on GitHub.
Conclusion
As now we have demonstrated by means of our intent classifier instance, the Amazon Bedrock managed fine-tuning capabilities, along with the Nova and Nova 2 fashions, make AI customization accessible at low value and with low effort. This simplified method requires minimal knowledge preparation and hyperparameter administration, minimizing the necessity for devoted knowledge science abilities. You’ll be able to customise fashions to enhance latency and scale back inference value by lowering the tokens of contextual info that the mannequin should course of. Wonderful-tuning Nova fashions on Amazon Bedrock transforms generic basis fashions into highly effective, domain-specific instruments that ship larger accuracy and decreased latency, at low coaching value. The power of Amazon Bedrock to host the Nova fashions utilizing On-Demand inference permits you to run the mannequin on the identical per-token pricing as the bottom Nova mannequin. See the Bedrock pricing web page for present charges.
Once you wish to run frontier fashions domestically, you hit the identical constraints repeatedly.
Cloud APIs lock you into particular suppliers and pricing buildings. Each inference request leaves your surroundings. Delicate information, proprietary workflows, inner data bases – all of it goes by means of another person’s infrastructure. You pay per token whether or not you want the total mannequin capabilities or not.
Self-hosting offers you management, however integration turns into the bottleneck. Your native mannequin works completely in isolation, however connecting it to manufacturing methods means constructing your personal API layer, dealing with authentication, managing routing, and sustaining uptime. A mannequin that runs fantastically in your workstation turns into a deployment nightmare when it is advisable expose it to your utility stack.
{Hardware} utilization suffers in each situations. Cloud suppliers cost for idle capability. Self-hosted fashions sit unused between bursts of site visitors. You are both paying for compute you do not use or scrambling to scale when demand spikes.
Google’s Gemma 4 modifications one a part of this equation. Launched April 2, 2026 underneath Apache 2.0, it delivers 4 mannequin sizes (E2B, E4B, 26B MoE, 31B dense) constructed from Gemini 3 analysis that run in your {hardware} with out sacrificing functionality.
Clarifai Native Runners resolve the opposite half: exposing native fashions by means of production-grade APIs with out giving up management. Your mannequin stays in your machine. Inference runs in your GPUs. Knowledge by no means leaves your surroundings. However from the skin, it behaves like several cloud-hosted endpoint – authenticated, routable, monitored, and prepared for integration.
This information reveals you tips on how to run Gemma 4 domestically and make it accessible wherever.
Why Gemma 4 + Native Runners Matter
Constructed from Gemini 3 Analysis, Optimized for Edge
Gemma 4 is not a scaled-down model of a cloud mannequin. It is purpose-built for native execution. The structure contains:
Hybrid consideration: Alternating native sliding-window (512-1024 tokens) and world full-context consideration balances effectivity with long-range understanding
Twin RoPE: Customary rotary embeddings for native layers, proportional RoPE for world layers – allows 256K context on bigger fashions with out high quality degradation at lengthy distances
Shared KV cache: Final N layers reuse key/worth tensors, decreasing reminiscence and compute throughout inference
Per-Layer Embeddings (E2B/E4B): Secondary embedding alerts feed into each decoder layer, enhancing parameter effectivity at small scales
The E2B and E4B fashions run offline on smartphones, Raspberry Pi, and Jetson Nano with near-zero latency. The 26B MoE and 31B dense fashions match on single H100 GPUs or shopper {hardware} by means of quantization. You are not sacrificing functionality for native deployment – you are getting fashions designed for it.
What Clarifai Native Runners Add
Native Runners bridge native execution and cloud accessibility. Your mannequin runs totally in your {hardware}, however Clarifai offers the safe tunnel, routing, authentication, and API infrastructure.
This is what truly occurs:
You run a mannequin in your machine (laptop computer, server, on-prem cluster)
Native Runner establishes a safe connection to Clarifai’s management aircraft
API requests hit Clarifai’s public endpoint with customary authentication
Requests path to your machine, execute domestically, return outcomes to the consumer
All computation stays in your {hardware}. No information uploads. No mannequin transfers.
This is not simply comfort. It is architectural flexibility. You may:
Prototype in your laptop computer with full debugging and breakpoints
Maintain information personal – fashions entry your file system, inner databases, or OS assets with out exposing your surroundings
Skip infrastructure setup – No must construct and host your personal API. Clarifai offers the endpoint, routing, and authentication
Take a look at in actual pipelines with out deployment delays. Examine requests and outputs dwell
Use your personal {hardware} – laptops, workstations, or on-prem servers with full entry to native GPUs and system instruments
Gemma 4 Fashions and Efficiency
Mannequin Sizes and {Hardware} Necessities
Gemma 4 ships in 4 sizes, every accessible as base and instruction-tuned variants:
Mannequin
Complete Params
Lively Params
Context
Greatest For
{Hardware}
E2B
~2B (efficient)
Per-Layer Embeddings
256K
Edge units, cell, IoT
Raspberry Pi, smartphones, 4GB+ RAM
E4B
~4B (efficient)
Per-Layer Embeddings
256K
Laptops, tablets, on-device
8GB+ RAM, shopper GPUs
26B A4B
26B
4B (MoE)
256K
Excessive-performance native inference
Single H100 80GB, RTX 5090 24GB (quantized)
31B
31B
Dense
256K
Most functionality, native deployment
Single H100 80GB, shopper GPUs (quantized)
The “E” prefix stands for efficient parameters. E2B and E4B use Per-Layer Embeddings (PLE) – a secondary embedding sign feeds into each decoder layer, enhancing intelligence-per-parameter at small scales.
Benchmark Efficiency
On Area AI’s textual content leaderboard (April 2026):
31B: #3 globally amongst open fashions (ELO ~1452)
26B A4B: #6 globally
Tutorial benchmarks:
BigBench Additional Laborious: 74.4% (31B) vs 19.3% for Gemma 3
MMLU-Professional: 87.8%
HumanEval coding: 85.2%
Multimodal capabilities (native, no adapter required):
Picture understanding with variable side ratio and backbone
Video comprehension as much as 60 seconds at 1 fps (26B and 31B)
Audio enter for speech recognition and translation (E2B and E4B)
Agentic options (out of the field):
Native operate calling with structured JSON output
Multi-step planning and prolonged reasoning mode (configurable)
System immediate assist for structured conversations
Setting Up Gemma 4 with Clarifai Native Runners
Stipulations
Ollama put in and operating in your native machine
Python 3.10+ and pip
Clarifai account (free tier works for testing)
8GB+ RAM for E4B, 24GB+ for quantized 26B/31B fashions
Step 1: Set up Clarifai CLI and Login
Log in to hyperlink your native surroundings to your Clarifai account:
Enter your Consumer ID and Private Entry Token when prompted. Discover these in your Clarifai dashboard underneath Settings → Safety.
(Observe: Use the precise listing title created by the init command, e.g., ./gemma-4-e4b or ./gemma-4-31b)
As soon as operating, you obtain a public Clarifai URL. Requests to this URL path to your machine, execute in your native Ollama occasion, and return outcomes.
Working Inference
Set your Clarifai PAT:
Use the usual OpenAI consumer:
That is it. Your native Gemma 4 mannequin is now accessible by means of a safe public API.
From Native Growth to Manufacturing Scale
Native Runners are constructed for improvement, debugging, and managed workloads operating in your {hardware}. Once you’re able to deploy Gemma 4 at manufacturing scale with variable site visitors and wish autoscaling, that is the place Compute Orchestration is available in.
Compute Orchestration handles autoscaling, load balancing, and multi-environment deployment throughout cloud, on-prem, or hybrid infrastructure. The identical mannequin configuration you examined domestically with clarifai mannequin serve deploys to manufacturing with clarifai mannequin deploy.
Past operational scaling, Compute Orchestration offers you entry to the Clarifai Reasoning Engine – a efficiency optimization layer that delivers considerably quicker inference by means of customized CUDA kernels, speculative decoding, and adaptive optimization that learns out of your workload patterns.
When to make use of Native Runners:
Your utility processes proprietary information that can’t depart your on-prem servers (regulated industries, inner instruments)
You’ve got native GPUs sitting idle and wish to use them for inference as an alternative of paying cloud prices
You are constructing a prototype and wish to iterate shortly with out deployment delays
Your fashions must entry native recordsdata, inner databases, or personal APIs you can’t expose externally
Transfer to Compute Orchestration when:
Site visitors patterns spike unpredictably and also you want autoscaling
You are serving manufacturing site visitors that requires assured uptime and cargo balancing throughout a number of cases
You need traffic-based autoscale to zero when idle
You want the efficiency benefits of Reasoning Engine (customized CUDA kernels, adaptive optimization, greater throughput)
Your workload requires GPU fractioning, batching, or enterprise-grade useful resource optimization
You want deployment throughout a number of environments (cloud, on-prem, hybrid) with centralized monitoring and price management
Conclusion
Gemma 4 ships underneath Apache 2.0 with 4 mannequin sizes designed to run on actual {hardware}. E2B and E4B work offline on edge units. 26B and 31B match on single shopper GPUs by means of quantization. All 4 sizes assist multimodal enter, native operate calling, and prolonged reasoning.
Clarifai Native Runners bridge native execution and manufacturing APIs. Your mannequin runs in your machine, processes information in your surroundings, however behaves like a cloud endpoint with authentication, routing, and monitoring dealt with for you.
Take a look at Gemma 4 together with your precise workloads. The one benchmark that issues is the way it performs in your information, together with your prompts, in your surroundings.
Macworld reviews Apple launched iOS 26.4.1 and iPadOS 26.4.1 to deal with a important iCloud syncing bug affecting information change notifications.
The bug prevented units from receiving iCloud updates, impacting all CloudKit apps together with Apple’s Passwords app and third-party functions.
Customers ought to replace instantly to revive correct iCloud performance, although these on iOS 26.5 beta stay unaffected by this difficulty.
Apple has simply launched iOS 26.4.1 and iPadOS 26.4.1. Apple says this solely included bug fixes and no safety updates, with easy patch notes: “This replace supplies bug fixes in your iPhone.”
In response to customers on Apple’s developer boards, it really fixes a reasonably important iCloud sync bug launched in iOS 26.4. In response to this thread on the Apple Developer Boards, the bug prevented units operating iOS/iPadOS 26.4 from receiving notifications that iCloud information had modified, in order that they weren’t getting information that was up to date from different units.
This impacted all first and third-party apps that use CloudKit, together with even Apple’s personal Passwords app. This bug seems to be resolved within the 26.4.1 updates. When you’re operating the iOS 26.5 beta, you ought to be high quality, because the bug doesn’t seem there.
To replace your gadget, open Settings and faucet Basic, then Software program Updates and observe the on-screen directions.
The world’s strongest particle accelerator, the Giant Hadron Collider, has given scientists their greatest look but at quark-gluon plasma, the primordial matter that stuffed the universe moments after the Massive Bang.
Throughout the first fractions of a second of the universe’s existence, the cosmos was stuffed with a scorching and dense primordial soup known as quark-gluon plasma. On the almost 17-mile-long round particle accelerator, the Giant Hadron Collider (LHC) that sits deep beneath the French Alps, CERN scientists recreated the quark-gluon plasma by smashing collectively atomic nuclei of iron at near-light pace. The mission is named ALICE (A Giant Ion Collider Experiment).
The ALICE staff obtained new details about the quark-gluon plasma (and thus the situations within the early universe) after they noticed a sample frequent to collisions between protons — the particles discovered on the coronary heart of atoms — collisions between protons and lead nuclei, and collisions between lead nuclei themselves. This sample might reveal how the quark-gluon plasma shaped proper after the Massive Bang, indicating it could possibly be cast by smaller particle collisions than beforehand thought.
When scientists first began smashing protons collectively on the LHC, it was theorized that collisions between protons in addition to between protons and lead can be too small to generate quark-gluon plasma. Nevertheless, tantalizing indicators of this primordial matter have just lately been seen in these small collisions in addition to within the collisions between lead nuclei.
One of many signatures of quark-gluon plasma and its formation is the truth that particles aren’t emitted evenly, however in a most well-liked course, which scientists name anisotropic circulate. At intermediate speeds, the anisotropic circulate of particles will depend on the variety of quarks that compose them. Baryons, particles composed of three quarks, exhibit a stronger circulate than mesons, that are particles composed of two quarks.
Scientists theorize that that is linked to the method that brings quarks collectively to type bigger particles. Baryons have extra quarks and thus acquire larger circulate.
(Proper) A proton–proton collision on the LHC wherein many particles have been created and tracked by the ALICE detector. (Left) Illustration of the anisotropic circulate of mesons and baryons that ALICE has studied utilizing information from such collisions, with the big arrows representing the popular instructions. (Picture credit score: CERN/ALICE Collaboration)
In new analysis the ALICE Collaboration defined how they measured the anisotropic circulate for various mesons and baryons created by proton-proton and proton-lead collisions. By isolating particles flowing collectively, the staff confirmed that, simply as is seen in heavy collisions, these lighter collisions give rise to baryons with stronger circulate and mesons with weaker circulate at intermediate speeds.
Breaking area information, the most recent updates on rocket launches, skywatching occasions and extra!
“That is the primary time we have now noticed, for a big interval in momentum and for a number of species, this circulate sample in a subset of proton collisions wherein an unusually massive variety of particles are produced,” David Dobrigkeit Chinellato, Physics Coordinator of the ALICE experiment, stated in a press release. “Our outcomes assist the speculation that an increasing system of quarks is current even when the scale of the collision system is small.”
The ALICE staff in contrast the circulate observations they made to fashions of quark-gluon plasma formation, discovering the circulate sample carefully match fashions that account for the formation of baryons and mesons. Fashions that do not issue on this quark coalescence, nevertheless, failed to copy the noticed circulate sample.
The researchers additionally discovered that even the best-fit fashions could not fully account for the noticed circulate. There are nonetheless some lingering discrepancies, wrinkles that the staff thinks different collisions between particles with sizes between protons and iron might assist to iron out.
“We count on that, with the oxygen collisions that have been recorded in 2025, which bridge the hole between proton collisions and lead collisions, we’ll acquire new insights into the character and evolution of the quark-gluon plasma throughout totally different collision techniques,” ALICE Spokesperson Kai Schweda stated within the assertion.
Then, scientists will edge even nearer to understanding the situations discovered on the very daybreak of the universe.
A paper about this analysis was revealed on March 20 within the journal Nature Communications,
Working a top-performing AI mannequin domestically not requires a high-end workstation or costly cloud setup. With light-weight instruments and smaller open-source fashions, now you can flip even an older laptop computer right into a sensible native AI atmosphere for coding, experimentation, and agent-style workflows.
On this tutorial, you’ll learn to run Qwen3.5 domestically utilizing Ollama and join it to OpenCode to create a easy native agentic setup. The purpose is to maintain every little thing easy, accessible, and beginner-friendly, so you will get a working native AI assistant with out coping with a sophisticated stack.
# Putting in Ollama
Step one is to put in Ollama, which makes it simple to run massive language fashions domestically in your machine.
If you’re utilizing Home windows, you’ll be able to both obtain Ollama instantly from the official Obtain Ollama on Home windows web page and set up it like every other software, or run the next command in PowerShell:
irm https://ollama.com/set up.ps1 | iex
The Ollama obtain web page additionally consists of set up directions for Linux and macOS, so you’ll be able to observe the steps there if you’re utilizing a unique working system.
As soon as the set up is full, you can be prepared to start out Ollama and pull your first native mannequin.
# Beginning Ollama
Typically, Ollama begins mechanically after set up, particularly once you launch it for the primary time. Meaning you could not have to do anything earlier than operating a mannequin domestically.
If the Ollama server will not be already operating, you can begin it manually with the next command:
# Working Qwen3.5 Regionally
As soon as Ollama is operating, the following step is to obtain and launch Qwen3.5 in your machine.
For those who go to the Qwen3.5 mannequin web page in Ollama, you will notice a number of mannequin sizes, starting from bigger variants to smaller, extra light-weight choices.
For this tutorial, we’ll use the 4B model as a result of it gives a very good stability between efficiency and {hardware} necessities. It’s a sensible selection for older laptops and sometimes requires round 3.5 GB of random entry reminiscence (RAM).
To obtain and run the mannequin out of your terminal, use the next command:
The primary time you run this command, Ollama will obtain the mannequin recordsdata to your machine. Relying in your web pace, this may occasionally take a couple of minutes.
After the obtain finishes, Ollama could take a second to load the mannequin and put together every little thing wanted to run it domestically. As soon as prepared, you will notice an interactive terminal chat interface the place you’ll be able to start prompting the mannequin instantly.
At this level, you’ll be able to already use Qwen3.5 within the terminal for easy native conversations, fast exams, and light-weight coding assist earlier than connecting it to OpenCode for a extra agentic workflow.
# Putting in OpenCode
After establishing Ollama and Qwen3.5, the following step is to put in OpenCode, a neighborhood coding agent that may work with fashions operating by yourself machine.
You’ll be able to go to the OpenCode web site to discover the obtainable set up choices and study extra about the way it works. For this tutorial, we’ll use the fast set up methodology as a result of it’s the easiest technique to get began.
Run the next command in your terminal:
curl -fsSL https://opencode.ai/set up | bash
This installer handles the setup course of for you and installs the required dependencies, together with Node.js when wanted, so that you shouldn’t have to configure every little thing manually.
# Launching OpenCode with Qwen3.5
Now that each Ollama and OpenCode are put in, you’ll be able to join OpenCode to your native Qwen3.5 mannequin and begin utilizing it as a light-weight coding agent.
For those who take a look at the Qwen3.5 web page in Ollama, you’ll discover that Ollama now helps easy integrations with exterior AI instruments and coding brokers. This makes it a lot simpler to make use of native fashions in a extra sensible workflow as a substitute of solely chatting with them within the terminal.
To launch OpenCode with the Qwen3.5 4B mannequin, run the next command:
ollama launch opencode --model qwen3.5:4b
This command tells Ollama to start out OpenCode utilizing your domestically obtainable Qwen3.5 mannequin. After it runs, you can be taken into the OpenCode interface with Qwen3.5 4B already linked and able to use.
# Constructing a Easy Python Challenge with Qwen3.5
As soon as OpenCode is operating with Qwen3.5, you can begin giving it easy prompts to construct software program instantly out of your terminal.
For this tutorial, we requested it to create a small Python recreation undertaking from scratch utilizing the next immediate:
Create a brand new Python undertaking and construct a contemporary Guess the Phrase recreation with clear code, easy gameplay, rating monitoring, and an easy-to-use terminal interface.
After a couple of minutes, OpenCode generated the undertaking construction, wrote the code, and dealt with the setup wanted to get the sport operating.
We additionally requested it to put in any required dependencies and check the undertaking, which made the workflow really feel a lot nearer to working with a light-weight native coding agent than a easy chatbot.
The ultimate consequence was a totally working Python recreation that ran easily within the terminal. The gameplay was easy, the code construction was clear, and the rating monitoring labored as anticipated.
For instance, once you enter an accurate character, the sport instantly reveals the matching letter within the hidden phrase, exhibiting that the logic works correctly proper out of the field.
# Closing Ideas
I used to be genuinely impressed by how simple it’s to get a neighborhood agentic setup operating on an older laptop computer with Ollama, Qwen3.5, and OpenCode. For a light-weight, low-cost setup, it really works surprisingly effectively and makes native AI really feel way more sensible than many individuals anticipate.
That stated, it isn’t all clean crusing.
As a result of this setup depends on a smaller and quantized mannequin, the outcomes aren’t at all times robust sufficient for extra advanced coding duties. In my expertise, it will possibly deal with easy initiatives, fundamental scripting, analysis assist, and general-purpose duties fairly effectively, however it begins to battle when the software program engineering work turns into extra demanding or multi-step.
One problem I bumped into repeatedly was that the mannequin would generally cease midway via a process. When that occurred, I needed to manually kind proceed to get it to maintain going and end the job. That’s manageable for experimentation, however it does make the workflow much less dependable once you need constant output for bigger coding duties.
Abid Ali Awan (@1abidaliawan) is an authorized information scientist skilled who loves constructing machine studying fashions. At the moment, he’s specializing in content material creation and writing technical blogs on machine studying and information science applied sciences. Abid holds a Grasp’s diploma in know-how administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college students battling psychological sickness.