

The position of a Knowledge Analyst in 2026 appears very completely different from even a couple of years in the past. As we speak’s analysts are anticipated to work with messy knowledge, automate reporting, clarify insights clearly to enterprise stakeholders, and responsibly use AI to speed up their workflow. This Knowledge Analyst studying path for 2026 is designed as a sensible, month-by-month roadmap that mirrors actual {industry} expectations slightly than educational idea. It focuses on constructing sturdy foundations, creating analytical depth, mastering storytelling, and getting ready you for hiring and on-the-job success. By following this roadmap, you’ll not solely be taught instruments like Excel, SQL, Python, and BI platforms, but in addition perceive find out how to apply them to actual enterprise issues with confidence.
Part 1: Constructing Foundations
Part 1 focuses on constructing the core analytical muscular tissues each knowledge analyst should have earlier than touching superior instruments or machine studying inside a roadmap. This part emphasizes structured pondering, clear knowledge dealing with, and analytical logic utilizing industry-standard instruments resembling Excel, SQL, and BI platforms. As a substitute of superficial publicity, the aim is depth—writing clear SQL, constructing automated Excel workflows, and studying find out how to clarify insights visually. By the tip of this part, learners ought to really feel comfy working with uncooked datasets, performing exploratory evaluation, and speaking insights clearly. Part 1 lays the groundwork for all the pieces that follows, guaranteeing you don’t depend on fragile shortcuts or copy-paste evaluation later in your profession.
Month 0: Absolute Fundamentals (Preparation Month)
Earlier than diving into superior Excel, SQL, and BI instruments, learners ought to spend Month 0 constructing absolute fundamentals. That is particularly essential for newbies or profession switchers.
Focus Areas:
- Fundamental Excel formulation like SUM, AVERAGE, COUNT, IF, AND, OR
- Understanding rows, columns, sheets, and cell references
- Sorting and filtering knowledge
- Fundamental charts (bar, line, column)
- Understanding what knowledge sorts are (numbers, textual content, dates)
Purpose:
Change into comfy navigating spreadsheets and pondering in rows, columns, and logic earlier than introducing superior features or automation.
Month 1: Excel + SQL (Knowledge Foundations)
Excel + SQL (Knowledge Foundations) focuses on constructing sturdy, job-ready knowledge dealing with abilities by combining superior Excel workflows with clear, scalable SQL querying. By the tip of this month, learners will exchange handbook reporting with automated pipelines, write interview-grade SQL, and confidently deal with complicated analytical logic throughout instruments.
Excel
- Superior Excel features: VLOOKUP/XLOOKUP, Pivot Tables, Charts
- Energy Question for knowledge cleansing & transformations
- Excel Tables, named ranges, structured references
SQL
- Core SQL: SELECT, WHERE, GROUP BY, HAVING, JOINs
- Superior SQL (interview-focused):
– CTEs (WITH clauses)
– Window features (ROW_NUMBER, RANK, LAG, LEAD)
– Fundamental efficiency ideas (indexes, question optimization instinct)
End result
Listed here are the three outcomes:
- Zero-Contact Automation: You’ll exchange handbook knowledge entry with automated workflows by feeding SQL queries instantly into Energy Question for “one-click” report refreshes.
- Complicated Analytical Energy: You’ll deal with subtle logic,like operating totals, year-over-year progress, and rankings, utilizing SQL Window Capabilities and Excel Pivot Tables.
- Skilled Code High quality: You’ll write clear, scalable, and interview-passing code utilizing CTEs (SQL) and Structured References (Excel) slightly than messy, fragile formulation.
Month 2: Knowledge Storytelling & Visualization
Month 2: Knowledge Storytelling & Visualization shifts the main focus from evaluation to communication, instructing you find out how to translate uncooked knowledge into clear, compelling tales utilizing BI instruments. By the tip of this month, you’ll publish an interactive dashboard and confidently clarify insights to non-technical stakeholders by visuals and narrative.
Visualization & BI
- Select one BI instrument primarily based on curiosity/market demand:
– Tableau
– Energy BI
– Qlik - Construct dashboards utilizing actual datasets (COVID-19, sports activities, enterprise KPIs)
- Publish a minimum of one interactive dashboard:
– Tableau Public
– Energy BI Service
Superior BI Ideas
- Study:
– Fundamental DAX (Energy BI)
– Tableau LOD expressions - Carry out knowledge cleansing instantly inside BI instruments:
– Energy Question
– knowledge transforms
End result
- 1 reside interactive dashboard
- Quick written clarification of insights (storytelling focus)
Month 3: Exploratory Knowledge Evaluation (EDA) + AI Utilization
Month 3: Exploratory Knowledge Evaluation (EDA) + AI Utilization focuses on deeply understanding knowledge high quality, patterns, and dangers earlier than drawing any conclusions.
EDA
- Univariate & bivariate evaluation
- Knowledge high quality checks:
– Lacking worth patterns
– Duplicates
– Outliers
– Distribution drift
AI / LLM Integration
Use LLMs to:
- Ask higher EDA questions (lacking knowledge, anomalies, helpful segmentations)
- Recommend applicable visualizations primarily based on knowledge kind and aim
- Summarize findings into clear, business-friendly insights
- Problem conclusions by highlighting assumptions or gaps
- Velocity up documentation (pocket book notes, slide outlines, portfolio textual content)
Instance:
1. EDA Discovery & Query Framing (MOST IMPORTANT)
Given this dataset’s schema and pattern rows, what are a very powerful exploratory questions I ought to ask to grasp key patterns, dangers, and alternatives?
Observe-up:
Which columns are doubtless drivers of variation within the goal KPI, and why ought to they be explored first?
2. Visualization & Storytelling Steerage
Primarily based on the information kind and enterprise aim, what visualization would finest clarify this development to a non-technical stakeholder?
Different:
How can I visualize seasonality, developments, or cohort conduct on this knowledge in a means that’s simple to interpret?
3. Perception Summarization for Enterprise
Summarize the important thing insights from this evaluation in 5 concise bullet factors appropriate for a non-technical supervisor.
Government model:
Convert these findings right into a one-page perception abstract with key takeaways and advisable actions.
Guardrails
- By no means share delicate or private knowledge
- All the time validate LLM outputs towards precise evaluation
End result
Sooner EDA, clearer insights, higher communication with stakeholders
Accountable AI Guidelines
When utilizing LLMs and AI instruments throughout evaluation, at all times observe these guardrails:
- By no means add PII or delicate enterprise knowledge
- Deal with LLMs as assistants, not decision-makers
- Be cautious of hallucinations and incorrect assumptions
- All the time manually confirm AI-generated insights towards precise knowledge and calculations
- Validate logic, numbers, and conclusions independently
Word: LLMs can confidently generate incorrect or deceptive outputs. They need to be used to speed up pondering—not exchange analytical judgment.
Tender Abilities
- Current insights verbally
- Write brief weblog posts / slide decks / video explainers
End result
Listed here are the three outcomes:
- Systematic Knowledge Vetting: You’ll grasp EDA to systematically diagnose dataset well being, figuring out each situation from outliers to distribution drift earlier than any closing evaluation or modeling.
- Accountable AI Acceleration: You’ll use LLMs to shortly generate visualization options and perception summaries, strictly adhering to the Accountable AI Guidelines (no PII, handbook validation).
- Actionable Perception Supply: You’ll translate complicated findings into persuasive outputs by mastering comfortable skillslike verbal presentation and creating clear, high-impact slide decks or weblog posts.
Part 2 transitions learners from instrument utilization to analytical reasoning and modeling. Python and statistics are launched not as summary ideas, however as sensible instruments for answering enterprise questions with proof. This part teaches find out how to work with real-world datasets, carry out statistical testing, and construct reproducible analyses that others can belief. Learners additionally get their first publicity to machine studying from an analyst’s perspective—specializing in interpretation slightly than black-box optimization. By the tip of Part 2, you have to be able to operating end-to-end analyses independently, validating assumptions, and explaining outcomes utilizing each code and visuals.
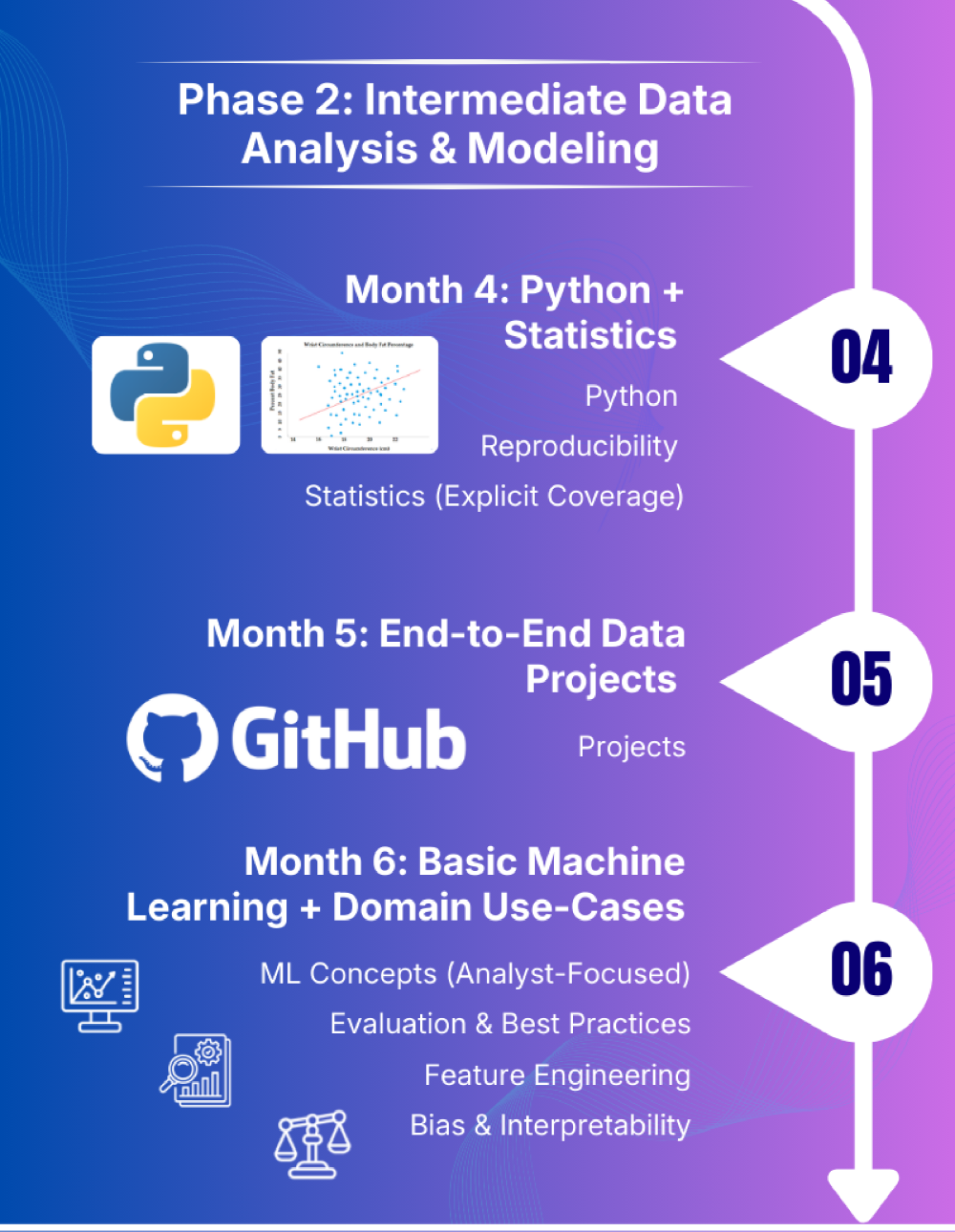
Month 4: Python + Statistics
Month 4: Python + Statistics introduces code-driven evaluation and statistical reasoning to help defensible, data-backed choices. You’ll use Python and core statistical strategies to run experiments, visualize outcomes, and ship reproducible analyses that stakeholders can belief.
Python
- Pandas, NumPy
- Matplotlib / Seaborn
- Key abilities:
– Datetime dealing with
– GroupBy patterns
– Joins & merges
– Working with massive CSV information
Reproducibility
- Use Jupyter Pocket book / Google Colab
- Clear narrative markdown cells
- Keep a necessities.txt or atmosphere setup
Statistics (Specific Protection)
- Descriptive statistics
- Confidence intervals
- Speculation testing:
– t-tests
– Chi-square exams
– ANOVA - Regression fundamentals (linear & logistic)
- Impact dimension & interpretation
- Sensible workouts tied to datasets
End result
Listed here are the three core outcomes
- Code-Pushed Experimentation: You’ll use Pandas and NumPy to execute formal statistical exams (t-tests, ANOVA) and decide Impact Measurement for defensible, data-backed conclusions.
- Scalable Visible Evaluation: You’ll effectively course of massive knowledge information utilizing superior Pandas strategies and talk findings successfully utilizing Matplotlib/Seaborn visualizations.
- Reproducible Undertaking Supply: You’ll create absolutely documented, shareable tasks utilizing Jupyter Notebookswith narrative markdown and necessities.txt for assured reproducibility.
Month 5: Finish-to-Finish Knowledge Tasks
Month 5: Finish-to-Finish Knowledge Tasks focuses on making use of all the pieces realized to this point to actual enterprise issues from begin to end. You’ll ship polished, portfolio-ready tasks that exhibit structured pondering, analytical depth, and clear communication to non-technical stakeholders.
Choose 2–3 real-world drawback statements. Every undertaking should embrace:
- Clear enterprise query
- Outlined KPIs
- Knowledge cleansing → EDA → visualization → evaluation
- GitHub repository with README
- Remaining 5–7 slide deck geared toward non-technical stakeholders
High quality & Reliability
- Add fundamental unit exams or sanity checks:
– Row counts
– Null thresholds
– Schema checks
End result
- 2 polished, end-to-end tasks
- Sturdy portfolio-ready belongings
Month 6: Fundamental Machine Studying + Area Use-Instances
Month 6: Fundamental Machine Studying + Area Use-Instances introduces predictive analytics from an analyst’s perspective, emphasizing interpretation over complexity. You’ll construct easy, explainable fashions and clearly talk what the mannequin predicts, why it predicts it, and the place it ought to or shouldn’t be trusted.
ML Ideas (Analyst-Centered)
- Algorithms:
– Linear Regression
– Logistic Regression
– Determination Bushes
– KNN
Analysis & Finest Practices
Regression:
- RMSE, MAE
- R² (interpretability, not optimization)
- MAPE (with warning for small denominators)
Classification:
- Precision, Recall
- F1-score (stability between precision & recall)
- ROC-AUC
- Confusion Matrix (error kind evaluation)
Characteristic Engineering
- Scaling
- Encoding
- Easy transformations
Bias & Interpretability
- Coefficient interpretation
- Intro to SHAP / function significance
End result
- 1 predictive analytics undertaking
- Clear clarification of mannequin choices
Hiring, AI Integration & Skilled Readiness
After finishing the core technical roadmap for a knowledge analyst, the main focus shifts towards employability {and professional} readiness. This part prepares learners for actual hiring eventualities, the place communication, enterprise understanding, and readability of thought matter as a lot as technical talent. You’ll learn to use AI to generate stories, summarize dashboards, and clarify insights to non-technical stakeholders—with out compromising ethics or accuracy. Portfolio refinement, resume optimization, mock interviews, and networking play a central position right here. The target is easy: make you interview-ready, project-confident, and able to including worth from day one in a knowledge analyst position.
AI / LLM Integration
Use LLMs to:
- Generate narrative stories
- Clarify developments to enterprise customers
- Summarize dashboards
Tender & Enterprise Abilities
- Stakeholder pondering
- Translating insights into enterprise actions
- Presenting to non-technical audiences
Portfolio & Job Preparation
- Finalize 3–4 sturdy tasks
- Resume, LinkedIn, GitHub optimized for Knowledge Analyst roles
- Observe interview questions:
– SQL
– Excel
– Statistics
– Enterprise case research
– Knowledge storytelling
Interview Observe
- SQL + Excel timed drills (30–45 minutes)
- No less than 10 mock interviews (technical + case-based)
Functions & Networking
- Apply for full-time roles, internships, freelance gigs
- Kaggle competitions, hackathons
- Be part of analytics communities, webinars, workshops
- Keep up to date on knowledge ethics, AI & privateness
Really helpful Undertaking Concepts (Decide Any 3)
Tasks are the strongest proof of your analytical capability. This part of the Knowledge Analyst Roadmap for 2026 offers domain-driven undertaking concepts that intently resemble real-world analyst work in product, advertising, and operations groups. Every undertaking is designed to mix knowledge cleansing, evaluation, visualization, and storytelling right into a single coherent narrative. Fairly than chasing flashy fashions, these tasks emphasize enterprise questions, KPIs, and decision-making. Finishing a minimum of three well-documented tasks from this listing will provide you with portfolio belongings that recruiters truly care about—clear drawback framing, strong evaluation, and actionable insights offered in a business-friendly format.
- Product Analytics
– Funnel conversion evaluation
– Retention & cohort evaluation - Advertising and marketing Analytics
– Marketing campaign attribution
– LTV estimation - Operations Analytics
– Provide chain lead-time evaluation
– Easy time-series aggregation & forecasting
Every undertaking should embrace
- 1 pocket book
- 1 dashboard
- 1 concise enterprise story (5 slides)
Conclusion
This knowledge analyst roadmap is designed to maneuver you from fundamentals to skilled readiness with readability and intent.
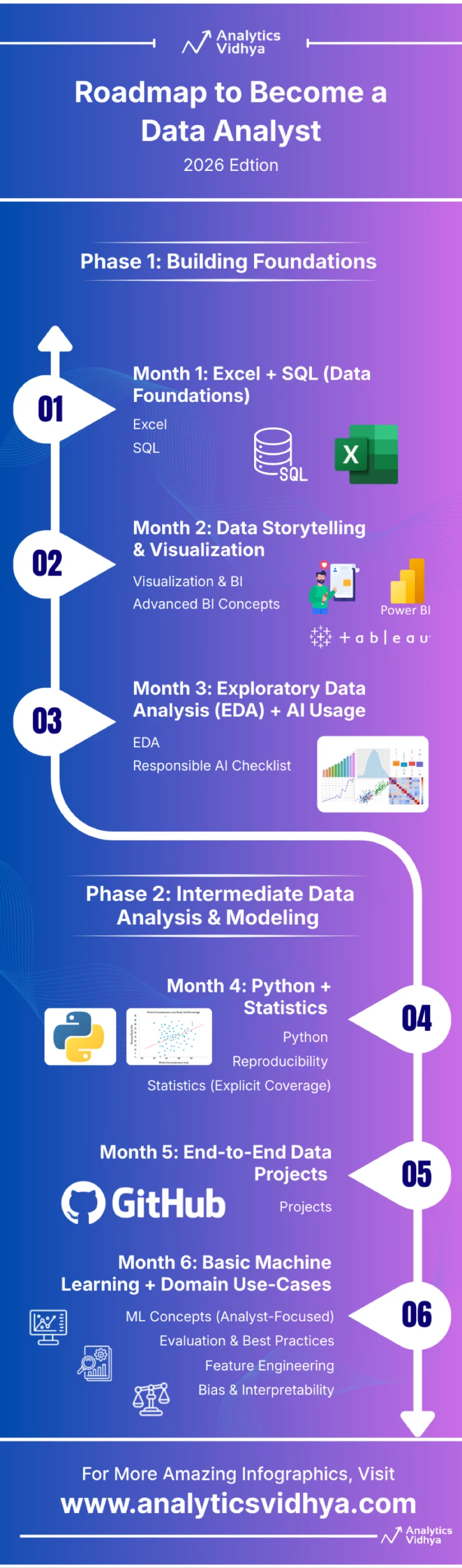
Fairly than chasing instruments blindly, the roadmap emphasizes sturdy foundations, structured pondering, and real-world software throughout every part. By progressing from Excel and SQL to Python, statistics, visualization, and accountable AI utilization, you construct abilities that instantly map to {industry} expectations. Most significantly, this knowledge analyst roadmap prioritizes communication, reproducibility, and enterprise affect – areas the place many analysts battle. If adopted with self-discipline and hands-on apply, this path won’t solely put together you for interviews but in addition enable you to carry out confidently when you’re on the job.
Knowledge Analyst with over 2 years of expertise in leveraging knowledge insights to drive knowledgeable choices. Enthusiastic about fixing complicated issues and exploring new developments in analytics. When not diving deep into knowledge, I take pleasure in enjoying chess, singing, and writing shayari.
Login to proceed studying and revel in expert-curated content material.























")




{kind=link}
{kind=link}