In my final submit, I confirmed how you can use putexcel to jot down easy expressions to Microsoft Excel and format the ensuing textual content and cells. As we speak, I need to present you how you can write extra complicated expressions resembling macros, graphs, and matrices. I’ll even present you how you can write formulation to Excel to create calculated cells. These are vital steps towards our aim of automating the creation of stories in Excel.
Earlier than we start the examples, I need to level out that I’m going to create a single Excel file referred to as putexcel2.xlsx and write every instance to a separate sheet inside that file. So the putexcel set instructions will appear like this:
putexcel set putexcel2.xlsx, sheet(example1) change
putexcel set putexcel2.xlsx, sheet(example2) modify
...
putexcel set putexcel2.xlsx, sheet(example8) modify
I may create a separate Excel file for every instance, however I would favor to have a single file with a number of sheets. It’s possible you’ll want to use the same strategy when creating massive stories.
You’ll be able to obtain the dataset used within the examples by typing webuse nhanes2. I’m utilizing a subset of the information and have relabeled a few of the variables so don’t be involved in case your numbers don’t match mine precisely.
Instance 1: Writing returned outcomes to Excel
Many Stata instructions return scalars, macros, and matrices. We are able to write every of those to an Excel desk utilizing putexcel. For instance, I would want to write the imply of age to Excel. I can sort return listing after summarize age to see a listing of returned outcomes. The imply is saved within the scalar r(imply).
. summarize age
Variable | Obs Imply Std. Dev. Min Max
-------------+---------------------------------------------------------
age | 1,266 48.44076 16.98858 20 74
. return listing
scalars:
r(N) = 1266
r(sum_w) = 1266
r(imply) = 48.44075829383886
r(Var) = 288.6119026656426
r(sd) = 16.98858153777539
r(min) = 20
r(max) = 74
r(sum) = 61326
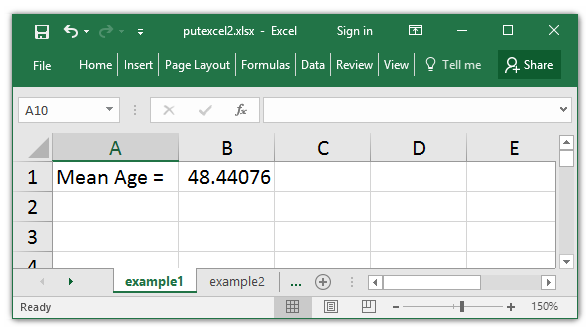
I start by setting the vacation spot to the sheet “example1” within the file putexcel2.xlxs. I can then write the expression “Imply Age = ” to cell A1 and the expression `r(imply)’ to cell B1. Notice that r(imply) is enclosed in single quotes. This tells Stata that I need to write the worth of r(imply) to cell B2.
. putexcel set putexcel2.xlsx, sheet(example1) change
Notice: file might be changed when the primary putexcel command is issued
. putexcel A1 = "Imply Age = "
file putexcel2.xlsx saved
. putexcel B1 = `r(imply)'
file putexcel2.xlsx saved
I can open the ensuing Excel file and see that the imply was efficiently written to cell B2.
Instance 2: Formatting numbers with Excel codecs
I can specify the show format of a quantity utilizing Excel codecs within the nformat() choice. For instance, I may show the imply with three decimal locations utilizing the choice nformat(“#.###”).
. putexcel set putexcel2.xlsx, sheet(example2) modify
. putexcel A1 = "Imply Age = "
file putexcel2.xlsx saved
. putexcel B1 = `r(imply)', nformat("#.###")
file putexcel2.xlsx saved
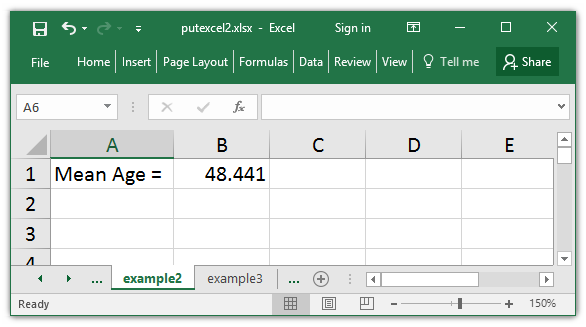
You’ll be able to view an entire description of Excel’s formatting choices within the Choices part of [P] putexcel superior.
Instance 3: Formatting numbers with Stata codecs
Stata contains many shortcut format codes that can be utilized with nformat(). For instance, I may show the imply with two decimal locations utilizing the choice number_d2.
. putexcel set putexcel2.xlsx, sheet(example3) modify
. putexcel A1 = "Imply Age = "
file putexcel2.xlsx saved
. putexcel B1 = `r(imply)', nformat(number_d2)
file putexcel2.xlsx saved
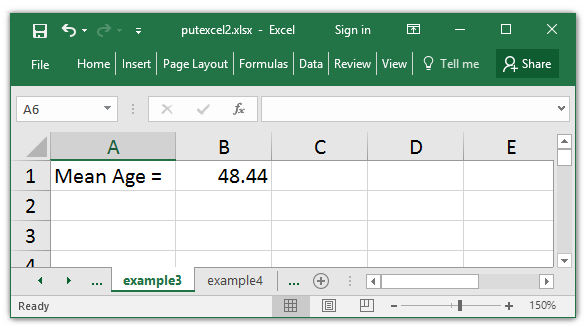
You’ll be able to view an entire listing of codes for numeric codecs within the Appendix of [P] putexcel.
Instance 4: Formatting numbers with the string() perform
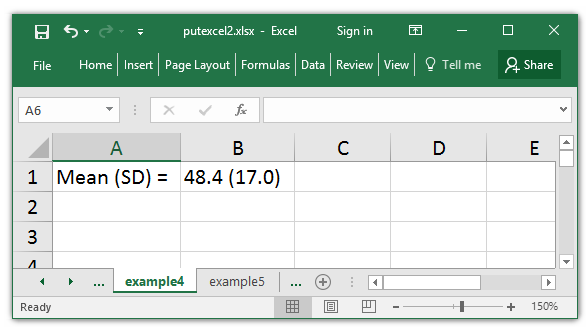
I may additionally report the imply and customary deviation in a single cell. This may be completed in two steps. First, I retailer r(imply) and r(sd) to the native macros meanage and sdage, respectively. The string() perform permits me to specify one decimal place. Second, I create an area macro named meansd that mixes meanage and sdage right into a single expression. Notice that I have to use double quotes within the command putexcel B1 = “`meansd’” as a result of meansd is a string.
. // put the imply of age in a cell utilizing the string() perform
. putexcel set putexcel2.xlsx, sheet(example4) modify
. putexcel A1 = "Imply (SD) = "
file putexcel2.xlsx saved
. native meanage = string(`r(imply)',"%9.1f")
. native sdage = string(`r(sd)',"%9.1f")
. native meansd = "`meanage' (`sdage')"
. putexcel B1 = "`meansd'"
file putexcel2.xlsx saved
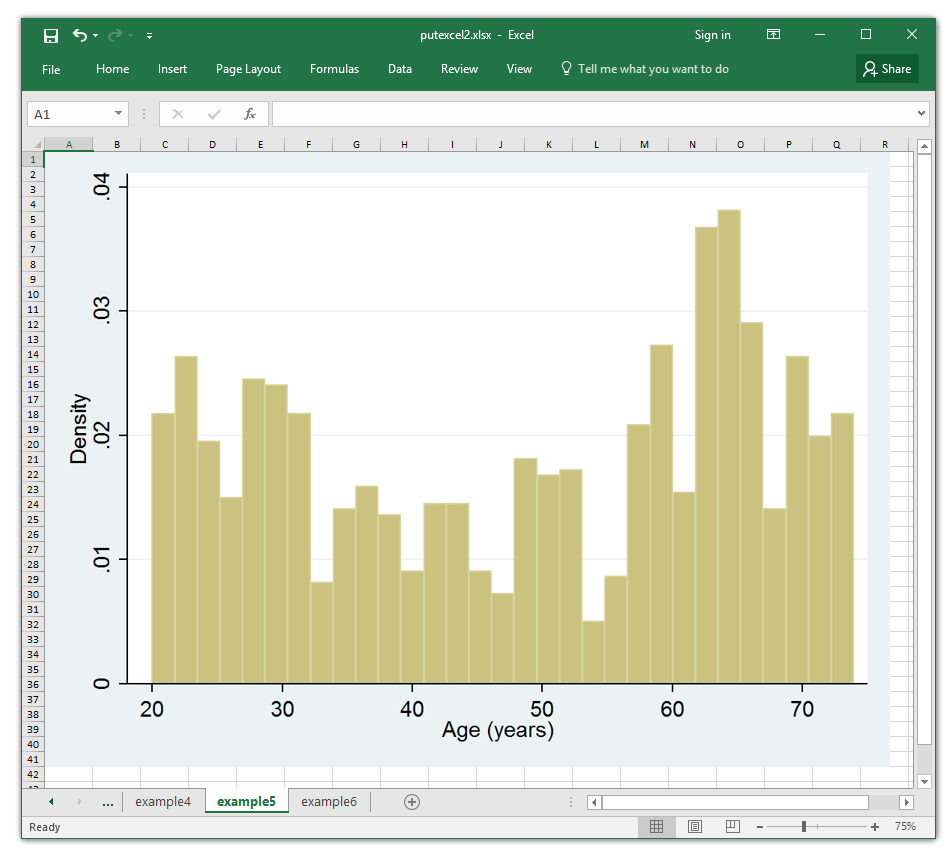
Instance 5: Including a graph to an Excel file
I would want to embody a histogram of age in my Excel file. First, I create the histogram and use graph export to avoid wasting the graph to a .png file.
. histogram age
(bin=31, begin=20, width=1.7419355)
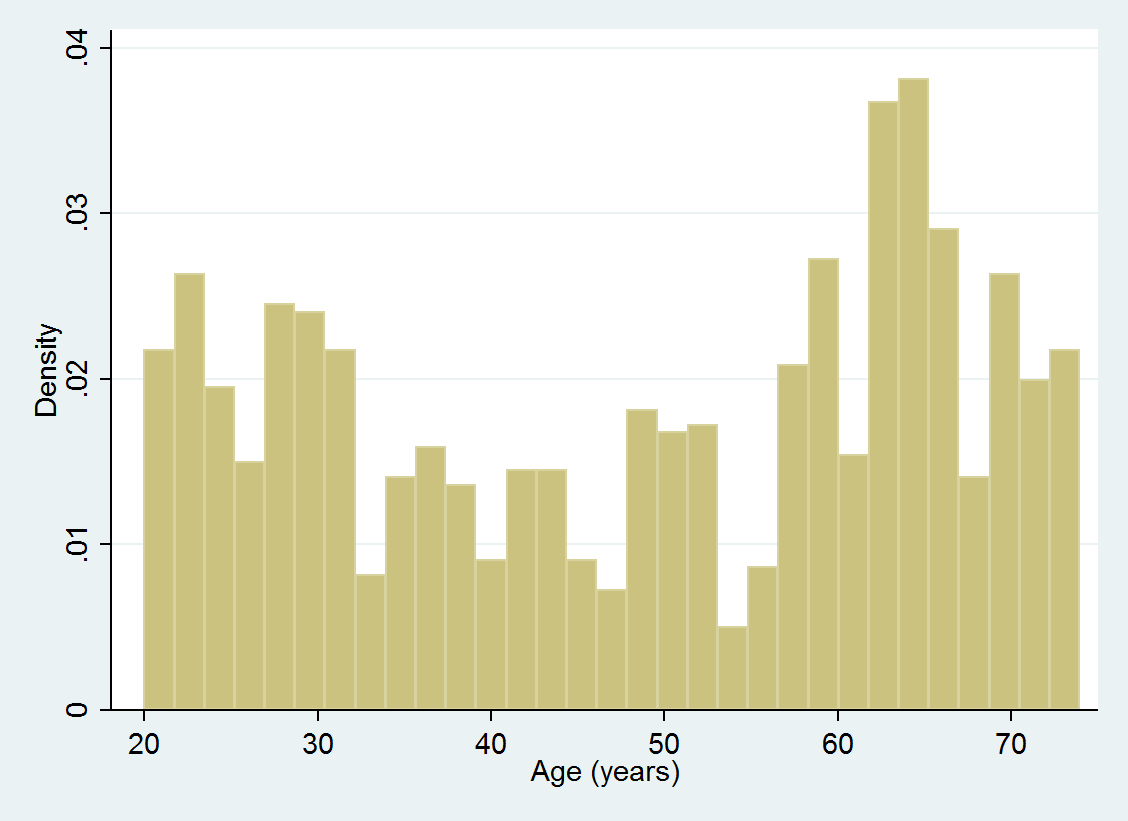
. graph export age.png, change
(file age.png written in PNG format)
Then, I can put the graph within the spreadsheet utilizing the expression image(age.png)
. putexcel set putexcel2.xlsx, sheet(example5) modify
. putexcel A1 = image(age.png)
file putexcel2.xlsx saved
Instance 6: Writing a matrix to Excel
Some Stata instructions return matrices. For instance, I can use tabstat to calculate descriptive statistics for a listing of variables. The save choice tells tabstat to avoid wasting the outcomes to a matrix.
. tabstat age peak weight sbp dbp, stat(n imply sd min max) save
stats | age peak weight sbp dbp
---------+--------------------------------------------------
N | 1266 1266 1266 1267 1267
imply | 48.44076 167.1308 72.17252 130.6843 80.54854
sd | 16.98858 9.61487 16.28185 24.34302 13.99187
min | 20 144.199 39.12 65 35
max | 74 193.398 175.88 254 150
------------------------------------------------------------
After I sort return listing, I see that tabstat returned the matrix r(StatTotal).
. return listing
matrices:
r(StatTotal) : 5 x 5
. matlist r(StatTotal)
| age peak weight sbp dbp
-------------+-------------------------------------------------------
N | 1266 1266 1266 1267 1267
imply | 48.44076 167.1308 72.17252 130.6843 80.54854
sd | 16.98858 9.61487 16.28185 24.34302 13.99187
min | 20 144.199 39.12 65 35
max | 74 193.398 175.88 254 150
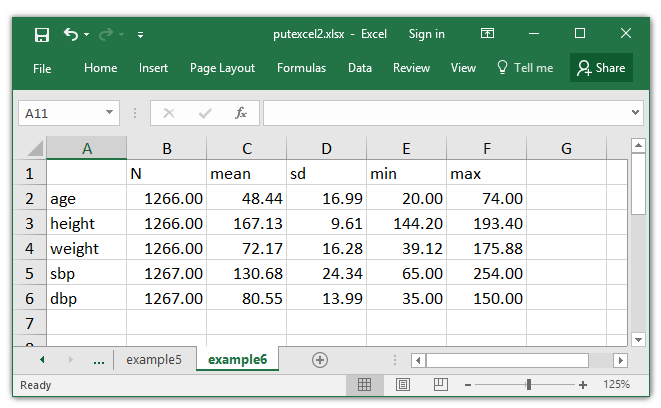
I would favor to create an Excel desk that appears just like the output from summarize with variables in rows and statistics in columns. So I create a matrix referred to as outcomes, which is the same as the transpose of r(StatTotal).
. matrix outcomes = r(StatTotal)'
. matlist outcomes
| N imply sd min max
-------------+-------------------------------------------------------
age | 1266 48.44076 16.98858 20 74
peak | 1266 167.1308 9.61487 144.199 193.398
weight | 1266 72.17252 16.28185 39.12 175.88
sbp | 1267 130.6843 24.34302 65 254
dbp | 1267 80.54854 13.99187 35 150
Then, I write the matrix outcomes to Excel utilizing the expression matrix(outcomes). I may use the expression matrix(r(StatTotal)’) slightly than creating a brand new matrix, however I needed to indicate you the transposed matrix earlier than writing it to Excel. The upper-left nook of the matrix might be positioned in cell A1 of the Excel desk. The names choice tells putexcel to jot down the row and column names to Excel together with the matrix. The nformat(number_d2) choice tells putexcel to show the matrix with two decimal locations.
. putexcel set putexcel2.xlsx, sheet(example6) modify
. putexcel A1 = matrix(outcomes), names nformat(number_d2)
file putexcel2.xlsx saved
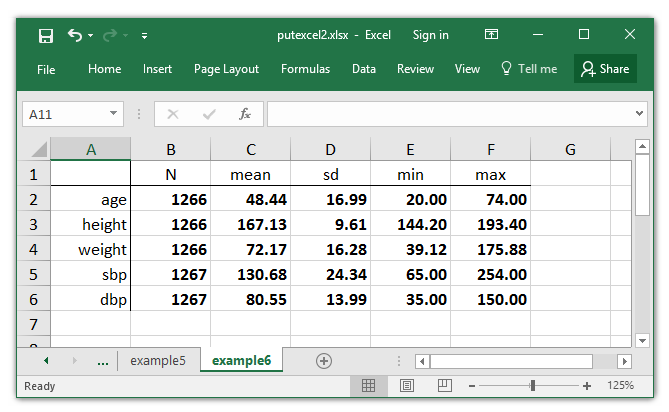
Subsequent, I want to format the Excel desk to make it look extra like a desk of outcomes slightly than a matrix. I can change the format of a cell with out writing something to the cell. I may even format a spread of cells utilizing the syntax ul:br, the place ul is the upper-left nook of the cell vary and br is the bottom-right cell.
The pattern sizes for every variable displayed in cells B2:B6 don’t want two decimal locations. I can show cells B2:B6 with no decimals utilizing the nformat(quantity) choice. The choice overwritefmt tells putexcel to overwrite the present cell format.
. putexcel B2:B6, nformat(quantity) overwritefmt
file putexcel2.xlsx saved
Subsequent, I format the cells A1:A6. The proper choice aligns the textual content to the appropriate facet of the cells, and the border(proper) choice provides a border to the appropriate facet of the cells.
. putexcel A1:A6, proper border(proper) overwritefmt
file putexcel2.xlsx saved
I format cells A1:F1 equally. The hcenter choice facilities the labels horizontally, and the border(backside) choice provides a border to the underside of cells A1:F1.
. putexcel A1:F1, hcenter daring border(backside) overwritefmt
file putexcel2.xlsx saved
Lastly, I show the numbers in cells B2:F1 utilizing a daring font to make the desk look much like the output of summarize.
. putexcel B2:F6, daring
file putexcel2.xlsx saved
The formatted Excel desk seems to be like this:
Instance 7: Writing regression coefficients to Excel
Most Stata regression instructions return the desk of coefficients in a matrix named r(desk). For instance, I may match the next linear regression mannequin with regress.
. regress sbp age intercourse
Supply | SS df MS Variety of obs = 1,266
-------------+---------------------------------- F(2, 1263) = 236.23
Mannequin | 204030.521 2 102015.261 Prob > F = 0.0000
Residual | 545432.459 1,263 431.854678 R-squared = 0.2722
-------------+---------------------------------- Adj R-squared = 0.2711
Whole | 749462.98 1,265 592.460854 Root MSE = 20.781
------------------------------------------------------------------------------
sbp | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
age | .7328247 .0343946 21.31 0.000 .6653479 .8003014
intercourse | 5.292591 1.170872 4.52 0.000 2.995522 7.58966
_cons | 92.6976 1.852992 50.03 0.000 89.06232 96.33289
------------------------------------------------------------------------------
and sort matlist r(desk) to see the coefficient matrix.
. matlist r(desk)
| age intercourse _cons
-------------+---------------------------------
b | .7328247 5.292591 92.6976
se | .0343946 1.170872 1.852992
t | 21.30641 4.520211 50.02589
pvalue | 2.65e-86 6.76e-06 6.9e-302
ll | .6653479 2.995522 89.06232
ul | .8003014 7.58966 96.33289
df | 1263 1263 1263
crit | 1.961844 1.961844 1.961844
eform | 0 0 0
r(desk) comprises the rows df, crit, and eform, which aren’t displayed within the regression output. I want to reproduce the desk of coefficients in my Excel desk, so I retailer r(desk) to the matrix outcomes, extract the primary six rows of outcomes, after which transpose outcomes.
. matrix outcomes = r(desk)
. matrix outcomes = outcomes[1..6,1...]'
. matlist outcomes
| b se t pvalue ll ul
-------------+------------------------------------------------------------------
age | .7328247 .0343946 21.30641 2.65e-86 .6653479 .8003014
intercourse | 5.292591 1.170872 4.520211 6.76e-06 2.995522 7.58966
_cons | 92.6976 1.852992 50.02589 6.9e-302 89.06232 96.33289
Now, I can write outcomes to my Excel file.
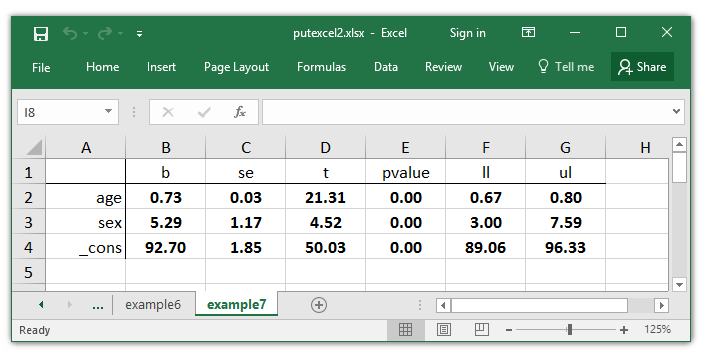
. putexcel set putexcel2.xlsx, sheet(example8) modify
. putexcel A1 = matrix(outcomes), names nformat(number_d2) hcenter
file putexcel2.xlsx saved
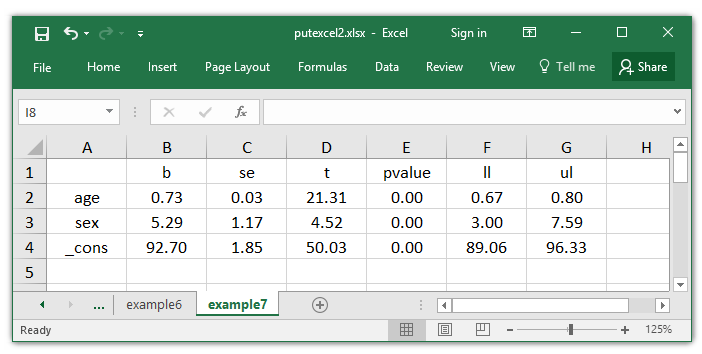
A number of changes to the font and cell codecs make my matrix look extra like a desk of coefficients.
. putexcel B2:G4, daring overwritefmt
file putexcel2.xlsx saved
. putexcel A1:A4, proper border(proper) overwritefmt
file putexcel2.xlsx saved
. putexcel A1:G1, hcenter border(backside) overwritefmt
file putexcel2.xlsx saved
Instance 8: Writing cross-tabulations to Excel
We are able to additionally write the outcomes from tabulate to Excel utilizing matrices. The matcell() choice shops the cell counts from tabulate in a matrix. For instance, I can retailer the outcomes of the tabulate command beneath within the matrix cellcounts.
. tabulate intercourse race, matcell(cellcounts)
| Race
Intercourse | Black Different White | Whole
-----------+---------------------------------+----------
Feminine | 101 12 563 | 676
Male | 75 10 506 | 591
-----------+---------------------------------+----------
Whole | 176 22 1,069 | 1,267
. matlist cellcounts
| c1 c2 c3
-------------+---------------------------------
r1 | 101 12 563
r2 | 75 10 506
I can rename the rows of cellcounts with the worth labels from intercourse utilizing the next steps. First, intercourse is saved as a numeric variable, so I can use decode to create a string variable referred to as sex_s. I may omit this step if intercourse was saved as a string variable. Subsequent, I exploit levelsof to retailer the degrees of sex_s to the native macro sexlabels. Then, I exploit matrix rownames to label the rows of cellcounts with the labels saved sexlabels.
. decode intercourse, generate(sex_s)
. levelsof sex_s, native(sexlabels)
`"Feminine"' `"Male"'
. matrix rownames cellcounts = `sexlabels'
. matlist cellcounts
| c1 c2 c3
-------------+---------------------------------
Feminine | 101 12 563
Male | 75 10 506
I can use the identical steps to rename the columns of cellcounts with the worth labels of race.
. decode race, generate(race_s)
. levelsof race_s, native(racelabels)
`"Black"' `"Different"' `"White"'
. matrix colnames cellcounts = `racelabels'
. matlist cellcounts
| Black Different White
-------------+---------------------------------
Feminine | 101 12 563
Male | 75 10 506
I can then write cellcounts to Excel identical to I did within the final two examples.
. putexcel set putexcel2.xlsx, sheet(example9) modify
. putexcel A1 = matrix(cellcounts), names hcenter
file putexcel2.xlsx saved
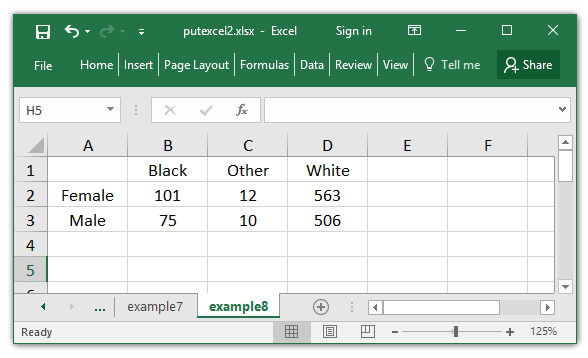
This strategy labored, however there aren’t any row and column totals in my Excel desk. A technique so as to add them is to place calculated cells within the desk utilizing system() expressions. For instance, the primary line of putexcel beneath places the Excel perform SUM(B2:D2) in cell E2. This calculates the full for the primary row of the desk. The putexcel command beneath places formulation within the desk to calculate the row, column, and total totals.
. putexcel E2 = system(=SUM(B2:D2)) ///
> E3 = system(=SUM(B3:D3)) ///
> B4 = system(=SUM(B2:B3)) ///
> C4 = system(=SUM(C2:C3)) ///
> D4 = system(=SUM(D2:D3)) ///
> E4 = system(=SUM(B2:D3)), hcenter
file putexcel2.xlsx saved

I can visually differentiate the row and column totals from the cells by including labels and borders. I also can show the numbers with a daring font.
. putexcel A4 = "Whole" E1 = "Whole", hcenter
file putexcel2.xlsx saved
. putexcel A1:A4 D1:D4, border(proper) overwritefmt
file putexcel2.xlsx saved
. putexcel A1:E1 A3:E3, border(backside) overwritefmt
file putexcel2.xlsx saved
. putexcel B2:E4, daring
file putexcel2.xlsx saved
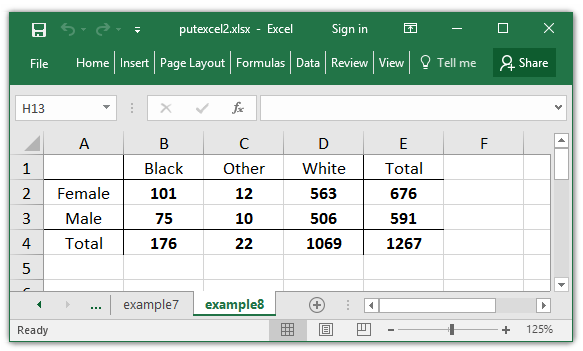
The Excel desk seems to be much like the output from tabulate.
Re-creating Stata output in Excel tables is straightforward with putexcel utilizing returned scalars, macros, and matrices. Examples 1-7 generalize nicely for arbitrary variables, however I hardcoded the row and column totals for the variables intercourse and race in instance 8.
Subsequent time, I’ll present you how you can generalize these examples for arbitrary variables and put extra eleborate expressions within the desk cells.























.jpg)




{kind=link}
{kind=link}