Google publicizes Gemini for Google TV, revolutionizing person interplay with good options and intuitive responses.
Gemini enhances TV expertise with picture reminiscence searches, customizable edits, and interactive content material throughout varied units.
New options debut on choose TCL fashions, requiring Android TV OS 14 and a Google account for entry.
CES 2026 is in full swing in Las Vegas, and Google is not shying away from making main bulletins for its merchandise. Be it taking up the Sphere in Vegas to point out off Gemini‘s expertise on XR, to now launching Gemini for Google TV, making it much more useful, intuitive, and giving customers extra methods to “work together together with your TV throughout extra manufacturers and surfaces like projectors,” Google acknowledged in a press launch this week.
Gemini is bringing a giant shift to the large screens because the AI assistant will now be capable to use photos, movies, and reside sports activities scores whenever you ask it questions, just about turning your TV into a sensible, speaking journal. However it goes past simply easy questions on sports activities or TV exhibits.
You too can ask the TV, “How do black holes work?” or “Who had been the Vikings?” and it offers you “Deep dives” on the subject with interactive summaries that each adults and children can perceive.
Subsequent up, you may as well ask Gemini on Google TV to lookup a particular reminiscence out of your Photographs. For example, you can say, “Gemini, discover that picture of my daughter consuming blue ice cream on the seaside three summers in the past,” and it’ll immediately pull up the precise picture, even in case you by no means tagged it with that particular person.
Not simply that, you may ask it to edit images with Photographs Remix or remodel recollections into motion pictures and even immersive slideshows.
(Picture credit score: Google)
Moreover, Google says you may even take it a step additional and use Nano Banana and Veo to personalize these pictures, like “Make this picture seem like a 3D Pixar animation” or “Change the background to a sundown.” You may even entry each these AI fashions to create media from scratch with a brand new question.
Lastly, this new replace permits customers to make use of easy language to alter settings. You may inform Gemini issues like “the display screen is just too dim” or “the dialogue is misplaced” whereas watching, and it’ll modify the image or sound based mostly in your desire, neat proper?
Get the newest information from Android Central, your trusted companion on the earth of Android
That mentioned, these new Gemini options for Google TV are scheduled for a staggered launch, debuting first on choose TCL good TV fashions and the Google TV Streamer earlier than a broader rollout to different producers all through 2026.
To entry these new tips, customers have to have a tool that’s up to date to Android TV OS 14 or increased and be linked to an ordinary Google account with an energetic web connection.
It is very important observe that whereas fundamental AI features can be found to all customers, superior high-resolution picture era and premium video creation by Veo usually require a Google AI Professional (Gemini Superior) subscription.
How do I get Gemini on my Google TV?
Gemini is presently being rolled out as a software program replace. To entry it, your gadget usually must be operating Android TV OS 14 or later. In case your gadget is eligible, the replace will sometimes occur routinely, or you may test for updates in your TV’s Settings > System > About > System replace.
RFK, Jr., Upsets Meals Pyramid, Urging Individuals to Eat Extra Meat
Dietary pointers launched on Wednesday by Secretary of Well being and Human Providers Robert F. Kennedy, Jr., and the USDA emphasize “actual meals” that’s excessive in saturated fats, departing from a long time of proof on healthful diets
On Wednesday Secretary of Well being and Human Providers Robert F. Kennedy, Jr., and the U.S. Division of Agriculture launched new official steerage that successfully overturns the meals pyramid. The suggestions encourage Individuals to eat “actual meals” and to eat extra saturated-fat-rich meals similar to crimson meat and whole-fat dairy.
The brand new dietary pointers contradict a long time’ value of previous suggestions and scientific proof that had directed folks to eat much less saturated fat and extra unsaturated fat, similar to these present in olive oil. In a single part, nevertheless, the steerage recommends that not more than 10 p.c of an individual’s energy ought to come from saturated fat and states that reducing out ultraprocessed meals will make that a straightforward goal to satisfy.
The adjustments displays Kennedy’s avowed aversion to ultraprocessed meals, which play an more and more massive half within the common American’s weight loss program. He has centered a lot of his ire on seed oils particularly, arguing that they need to be swapped out for animal fat. However specialists say that seed oils are typically secure when they’re used correctly and that encouraging Individuals to eat extra saturated, animal-derived fat probably poses a graver danger to coronary heart well being.
On supporting science journalism
For those who’re having fun with this text, take into account supporting our award-winning journalism by subscribing. By buying a subscription you might be serving to to make sure the way forward for impactful tales in regards to the discoveries and concepts shaping our world right this moment.
“I do know of no proof to point that there can be a bonus to growing the saturated fats content material of the weight loss program,” says Alice Lichtenstein, senior scientist on the Jean Mayer USDA Human Vitamin Analysis Middle on Getting older at Tufts College.
It’s unclear what proof the brand new pointers are primarily based on. Kennedy and Secretary of Agriculture Brooke Rollins are anticipated to carry a press briefing in regards to the pointers on Thursday. Scientific American has reached out to each the HHS and USDA for remark.
People want fats for fundamental mobile and organic capabilities within the physique—fat, or lipids, are important for creating mobile membranes, absorbing hormones and nutritional vitamins and regulating physique temperature. “Folks should not be frightened of fats, however they need to remember the fact that it’s higher to get it from crops than animals,” Lichtenstein says. “That’s what the majority of the present proof suggests.” The fats we eat typically falls into the 2 essential classes of saturated and unsaturated. The first distinction is their association of fatty acids—chains of hydrogen and carbon molecules.
In saturated fat, that are generally present in meat, cheese and butter, the carbon molecules within the chain are linked with single carbon bonds and comprise so many hydrogen atoms that the chain lies flat. This construction permits chains to align and pack tightly collectively, which is why saturated fat—similar to these in butter and tallow (rendered animal fats)—typically keep strong at room temperature.
Unsaturated fatty acid chains, however, have double carbon bonds that trigger them to twist and kink, so these fat largely keep liquid at room temperature. These embody monounsaturated fat (similar to these in avocado and olive oils), polyunsaturated fat (similar to sunflower oil) and trans fat (similar to chemically processed vegetable oils which can be usually utilized in processed meals).
The association and size of fatty acid chains additionally affect how our physique processes fat . Unsaturated fatty acid chains are typically included into numerous elements of cells, similar to cell membranes, to assist them perform correctly. Saturated fatty acid chains typically get saved in fats tissue.
“Biology isn’t black or white, however the kind of fatty acid just about tells you the place it’s going to go and the way your physique goes to make use of it,” says Martha Belury, a meals science researcher and professor on the Ohio State College.
Most meals naturally comprise each saturated and unsaturated fat. It’s the general quantity consumed that issues for well being, Lichtenstein says. Generally, animal fat, together with meat and dairy fats, have the next proportion of saturated fatty acids.
Quite a few research and randomized medical trials that in contrast diets excessive in saturated fats with these excessive in unsaturated fats have proven that the previous improve ranges of low-density lipoproteins (LDL), a sort of ldl cholesterol that, at excessive ranges, can result in strokes or coronary heart assaults. Newer analysis additionally means that saturated fat are linked to an elevated danger of insulin resistance, a precursor to kind 2 diabetes and obesity-associated coronary heart illness, Belury says.
Main medical societies supply their very own steerage on dietary fats consumption. The American Coronary heart Affiliation recommends that lower than 6 p.c of whole energy ought to come from saturated fats. In a 2,000-calorie weight loss program, that’s about 13 grams or much less of saturated fats per day—roughly equal to 2 tablespoons of salted butter or a single quarter-pound fast-food cheeseburger.
Specialists have traditionally reevaluated and adjusted diet suggestions primarily based on new, high-quality proof. For instance, the U.S. Meals and Drug Administration beforehand tweaked steerage round trans fat after analysis discovered that these fat improve LDL ldl cholesterol at a comparable degree to saturated fat whereas concurrently lowering “good” ldl cholesterol. Suggestions usually are not made and not using a complete evaluate of the literature, Lichtenstein says. “It’s the cumulating proof that’s what’s actually vital,” she provides. On Wednesday Kennedy didn’t current any robust new proof together with the brand new dietary steerage.
Editor’s Observe: This can be a breaking information story and could also be up to date additional.
It’s Time to Stand Up for Science
For those who loved this text, I’d wish to ask on your help. Scientific American has served as an advocate for science and business for 180 years, and proper now could be the most crucial second in that two-century historical past.
I’ve been a Scientific American subscriber since I used to be 12 years outdated, and it helped form the way in which I have a look at the world. SciAm all the time educates and delights me, and evokes a way of awe for our huge, lovely universe. I hope it does that for you, too.
For those who subscribe to Scientific American, you assist make sure that our protection is centered on significant analysis and discovery; that we have now the sources to report on the selections that threaten labs throughout the U.S.; and that we help each budding and dealing scientists at a time when the worth of science itself too usually goes unrecognized.
Truncation and censoring are two distinct phenomena that trigger our samples to be incomplete. These phenomena come up in medical sciences, engineering, social sciences, and different analysis fields. If we ignore truncation or censoring when analyzing our knowledge, our estimates of inhabitants parameters might be inconsistent.
Truncation or censoring occurs through the sampling course of. Let’s start by defining left-truncation and left-censoring:
Our knowledge are left-truncated when people beneath a threshold should not current within the pattern. For instance, if we wish to research the dimensions of sure fish based mostly on the specimens captured with a web, fish smaller than the online grid gained’t be current in our pattern.
Our knowledge are left-censored at (kappa) if each particular person with a worth beneath (kappa) is current within the pattern, however the precise worth is unknown. This occurs, for instance, when now we have a measuring instrument that can’t detect values beneath a sure degree.
We are going to focus our dialogue on left-truncation and left-censoring, however the ideas we’ll talk about generalize to all forms of censoring and truncation—proper, left, and interval.
When performing estimations with truncated or censored knowledge, we have to use instruments that account for that sort of incomplete knowledge. For truncated linear regression, we are able to use the truncreg command, and for censored linear regression, we are able to use the intreg or tobit command.
On this weblog put up, we’ll analyze the traits of truncated and censored knowledge and talk about utilizing truncreg and tobit to account for the unfinished knowledge.
Truncated knowledge
Instance: Royal Marines
Fogel et al. (1978) revealed a dataset on the peak of Royal Marines that extends over two centuries. It may be used to find out the imply peak of males in Britain for various intervals of time. Trussell and Bloom (1979) level out that the pattern is truncated resulting from minimal peak restrictions for the recruits. The information are truncated (versus censored) as a result of people with heights beneath the minimal allowed peak don’t seem within the pattern in any respect. To account for this reality, they match a truncated distribution to the heights of Royal Marines from the interval 1800–1809.
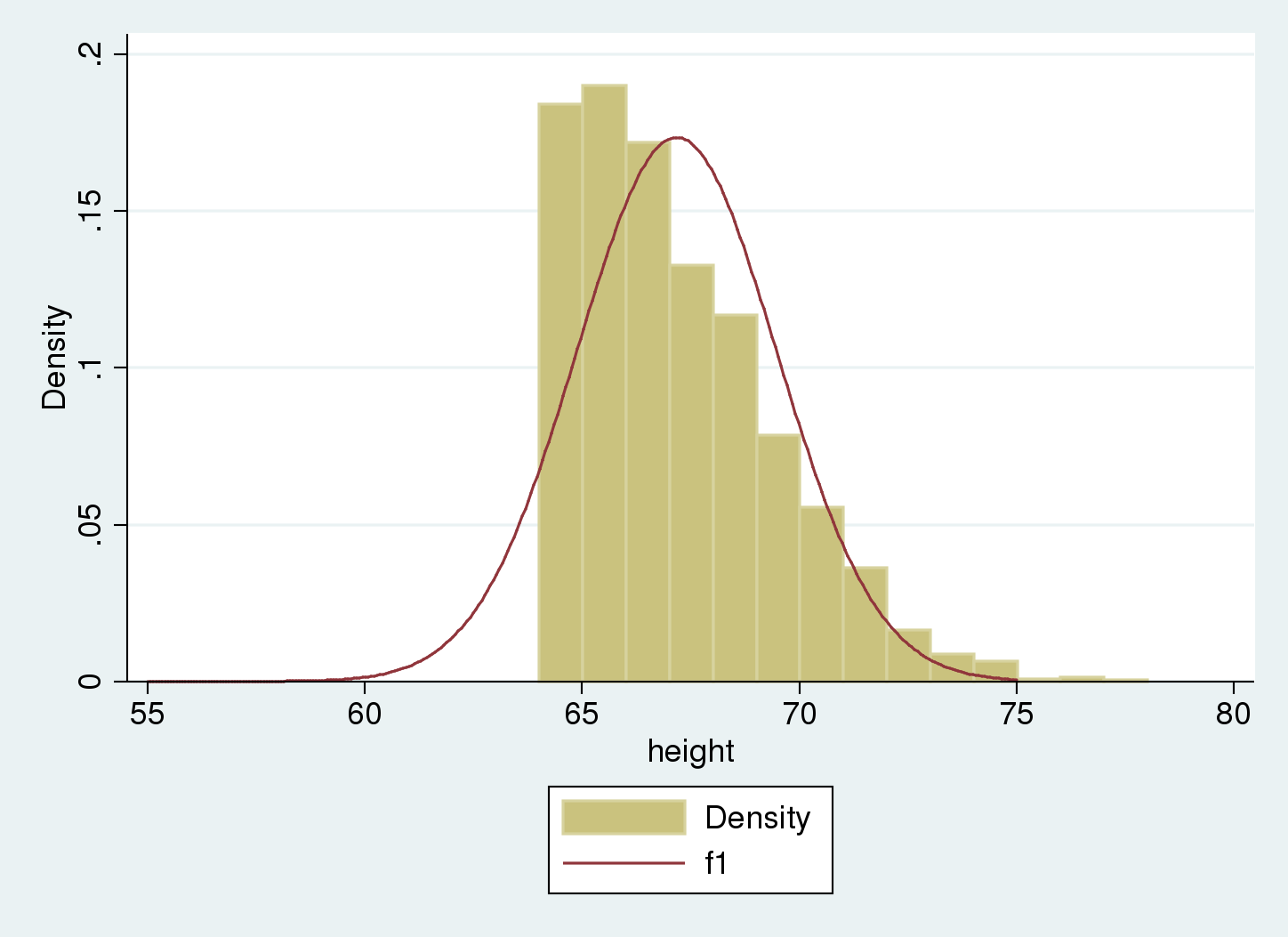
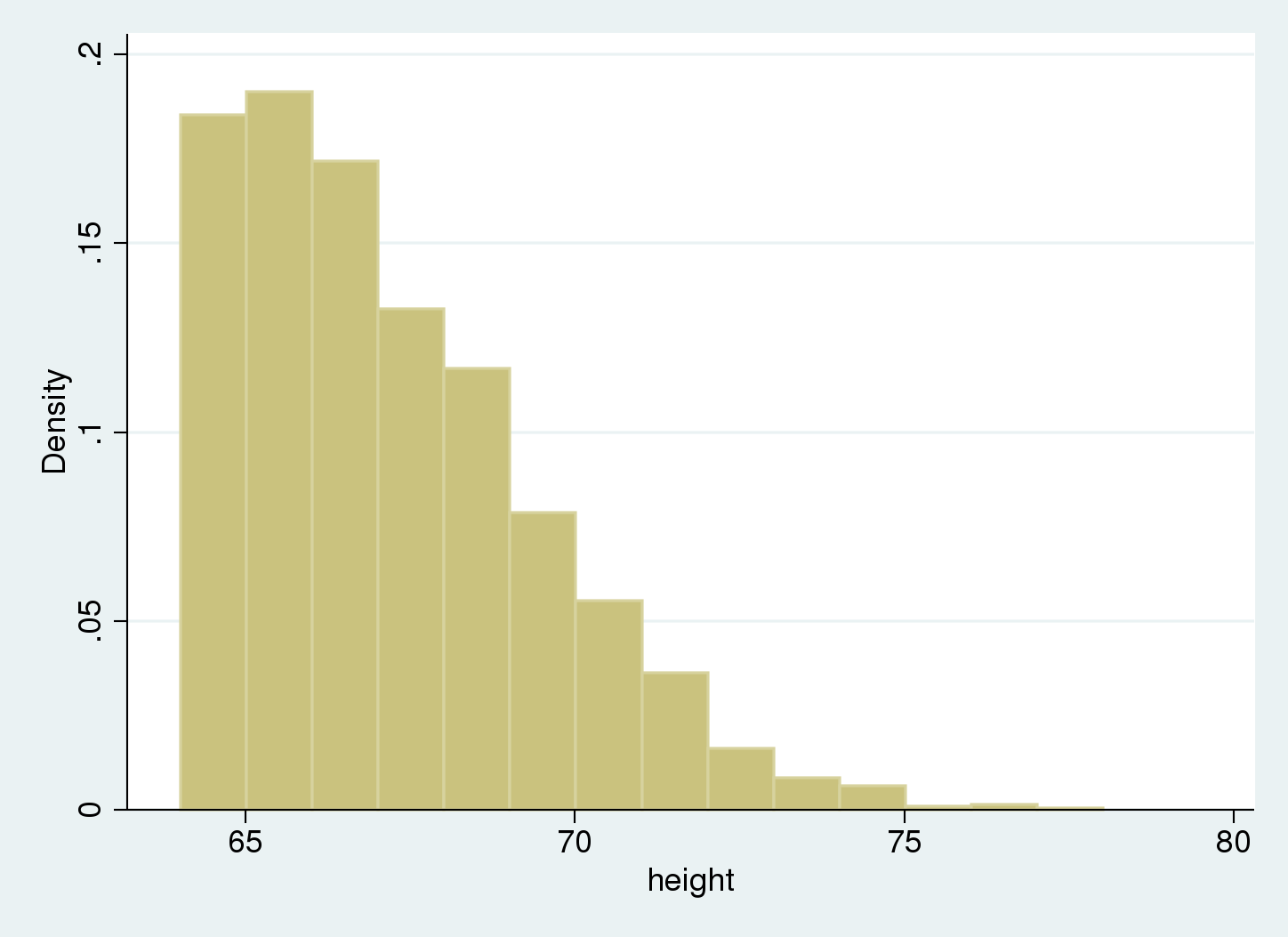
We’re utilizing a man-made dataset based mostly on the issue described by Trussell and Bloom. We’ll assume that the inhabitants knowledge observe a traditional distribution with (mu=65) and (sigma=3.5), and that they’re left-truncated at 64.
We use a histogram to summarize our knowledge.
We see there are not any knowledge beneath 64, our truncation level.
What occurs if we ignore truncation?
If we ignore the truncation and deal with the unfinished knowledge as full, the pattern common is inconsistent for the inhabitants imply, as a result of all observations beneath the truncation level are lacking. In our instance, the true imply is exterior the 95% confidence interval for the estimated imply.
We are able to examine the histogram of our pattern to the traditional distribution that we get if we ignore truncation, and take into account these values as estimates of the imply and normal deviation of the inhabitants.
We see that the Gaussian density estimate, (f_1), which ignored truncation, is shifted to the correct of the histogram, and the variance appears to be underestimated. We are able to confirm this as a result of we used synthetic knowledge that have been simulated with an underlying imply of 65 and normal deviation of three.5 for the nontruncated distribution, versus the estimated imply of 67.2 and normal deviation of two.3.
Utilizing truncreg to account for truncation
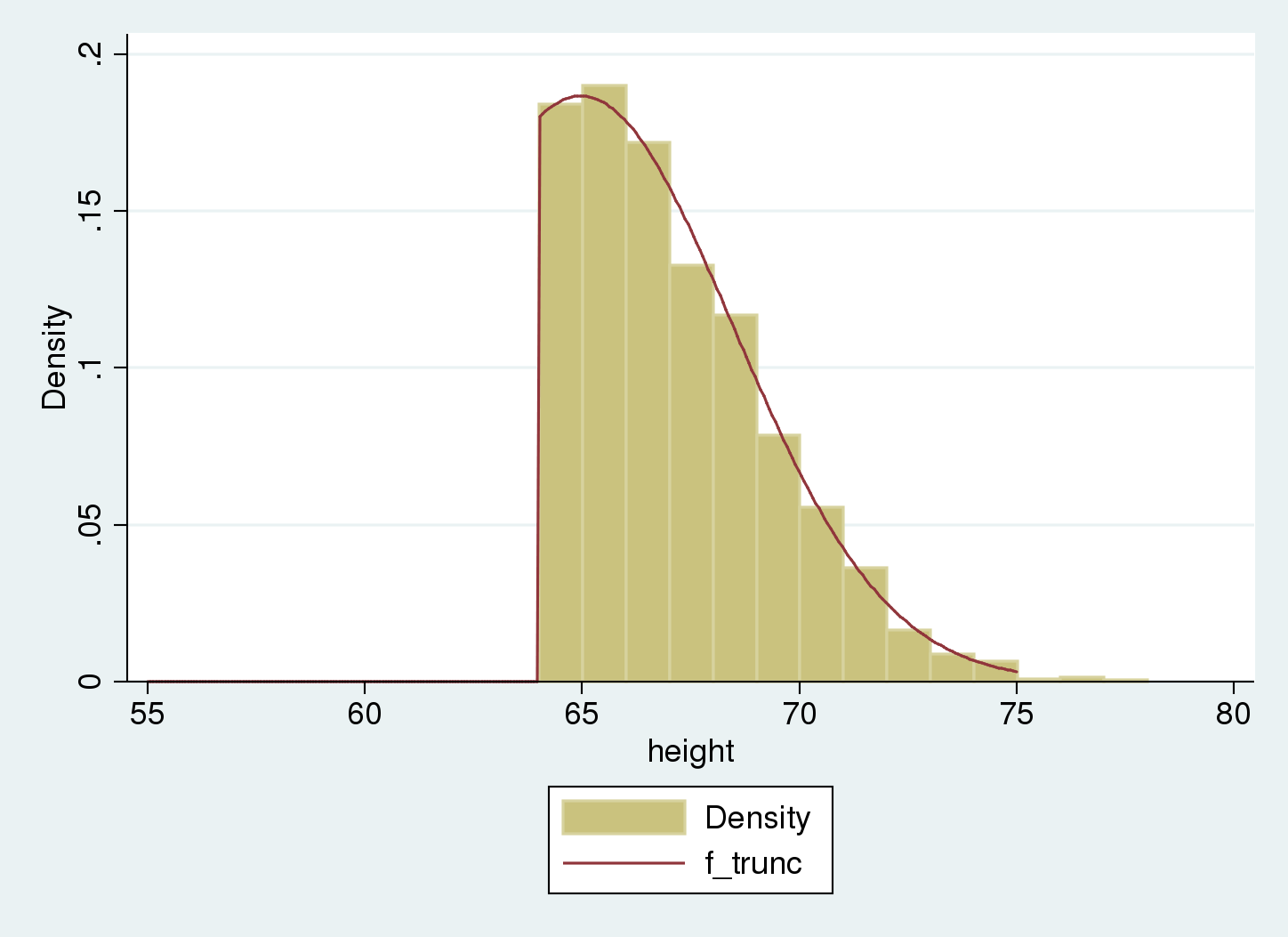
We are able to use truncreg to estimate the parameters for the underlying nontruncated distribution; to account for the left-truncation at 64, we use choice ll(64).
The truncated distribution matches our pattern. We estimate the inhabitants distribution as regular with imply equal to 65 and normal deviation equal to three.5.
Censored knowledge
Now we take into account an instance with censored knowledge slightly than truncated knowledge to display the distinction between the 2.
Instance: Nicotine ranges on family surfaces
Matt et al. (2004) carried out a research to evaluate contamination with tobacco smoke on surfaces in households of people who smoke. One measurement of curiosity was the extent of nicotine on furnishings surfaces. For every family, space wipe samples have been taken from the furnishings. Nonetheless, the measurement instrument couldn’t detect nicotine contamination beneath a sure restrict.
The information have been censored versus truncated. When the nicotine degree fell beneath the detection restrict, the remark was nonetheless included within the pattern with the nicotine degree recorded as being equal to that restrict.
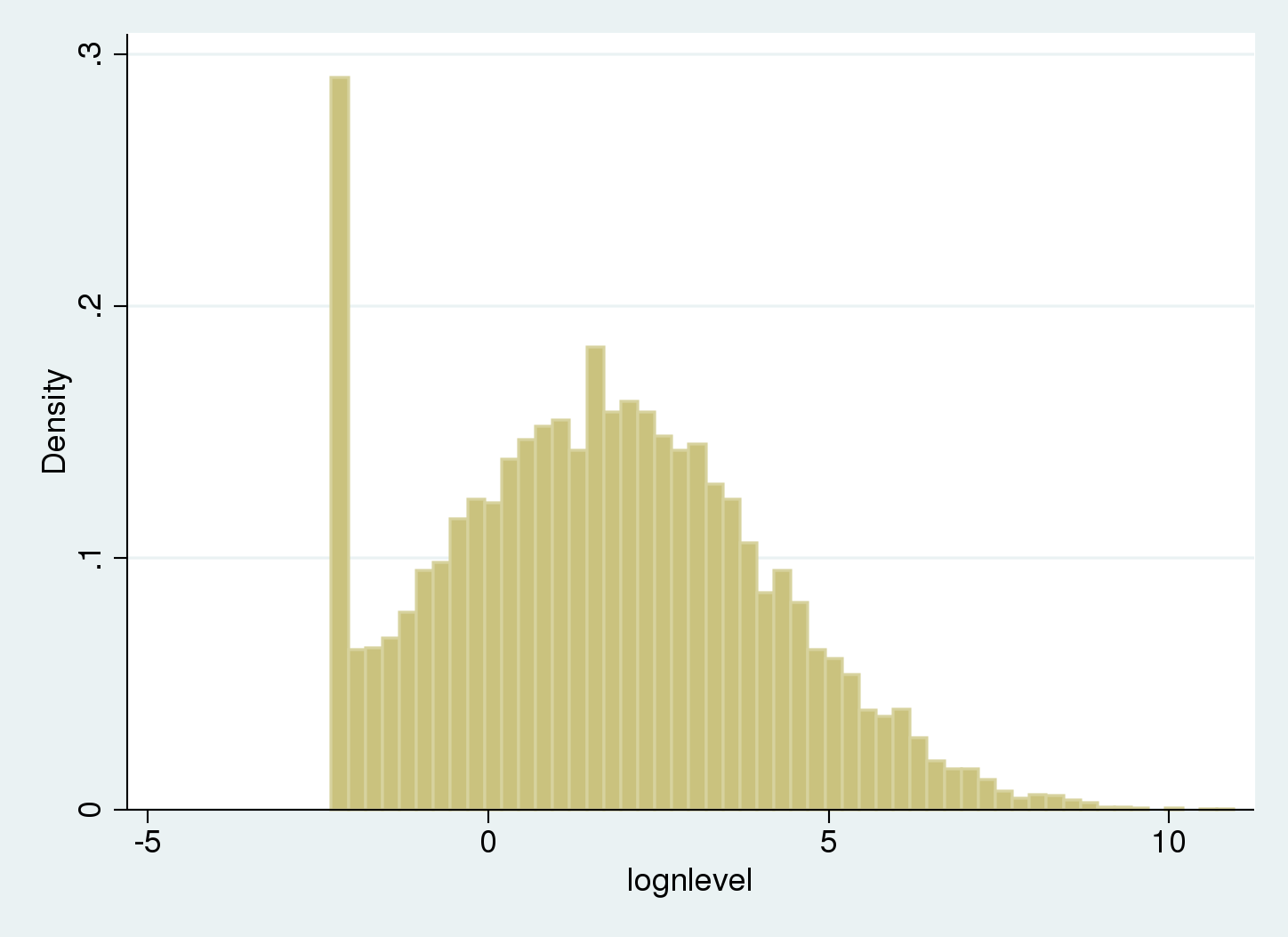
I’ve created a man-made dataset loosely impressed by the issue on this research. The log of nicotine contamination ranges are assumed to be regular. Right here, lognlevel incorporates log nicotine ranges. The parameters used for simulating the log nicotine ranges for uncensored knowledge are (mu=ln(5)) and (sigma=2.5), and the information have been left-censored at 0.1. We begin by drawing a histogram.
There’s a spike on the left of the histogram as a result of values beneath the restrict of detection (LOD) are recorded as being equal to the LOD.
Computing the uncooked imply and normal deviation for the pattern won’t present acceptable estimates for the underlying uncensored Gaussian distribution.
. summarize lognlevel
Variable | Obs Imply Std. Dev. Min Max
-------------+---------------------------------------------------------
lognlevel | 10,000 1.683339 2.360516 -2.302585 10.73322
Imply and normal deviation are estimated as 1.68 and a pair of.4 respectively, the place the precise parameters are ln(5) =1.61 and a pair of.5.
Utilizing tobit to account for censoring
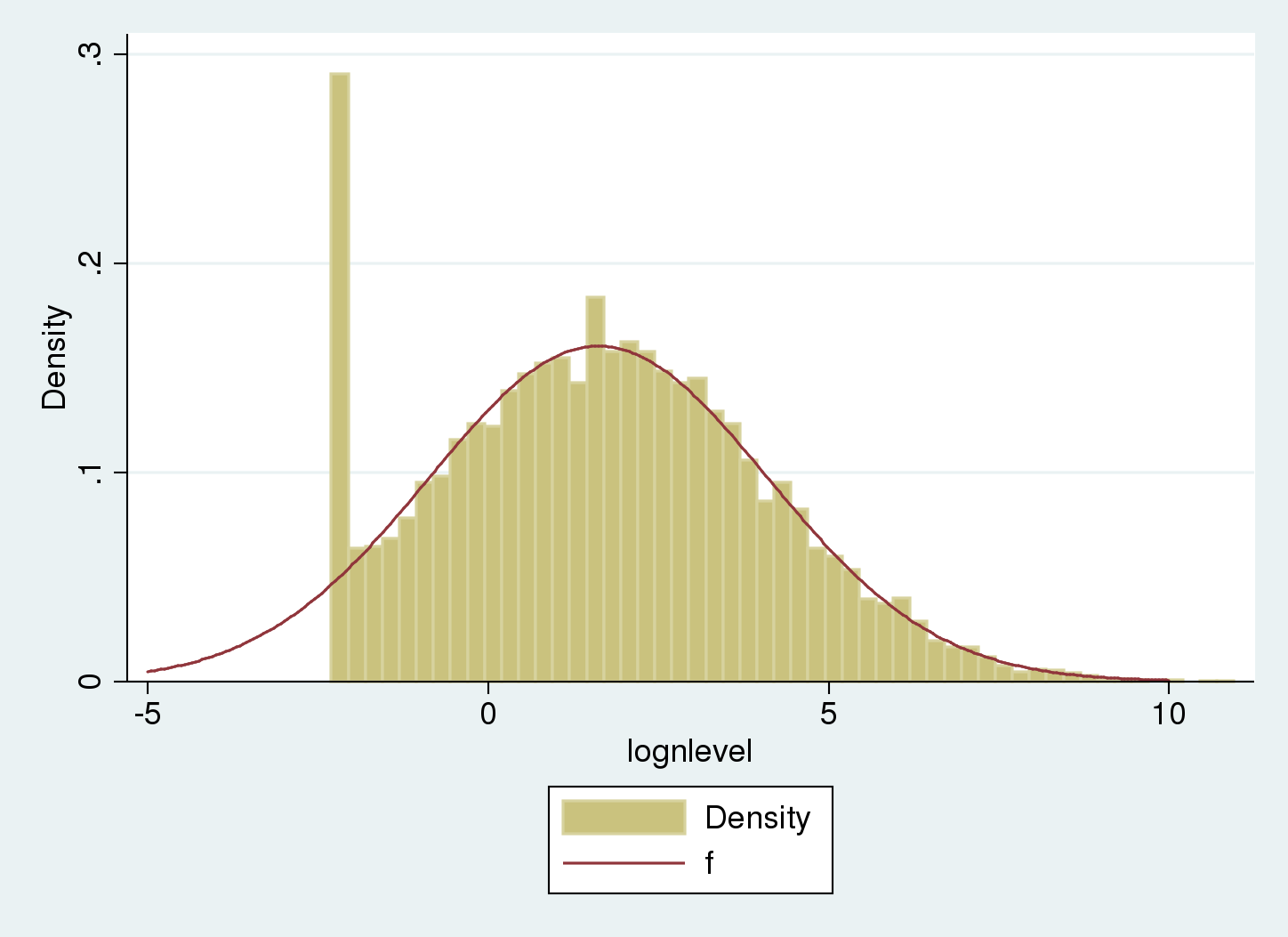
We estimate the imply and normal deviation of the distribution and account for the left-censoring through the use of tobit with the ll choice. (If censoring limits various amongst observations, we might use intreg as an alternative).
The underlying uncensored distribution matches the common a part of the histogram. The tail on the left compensates the spike on the censoring level.
Abstract
Censoring and truncation are two distinct phenomena that occur when sampling knowledge.
The underlying inhabitants parameters for a truncated Gaussian pattern will be estimated with truncreg. The underlying inhabitants parameters for a censored Gaussian pattern will be estimated with intreg or tobit.
Last remarks
We have mentioned the ideas of censoring and truncation, and proven examples for example these ideas.
There are some related factors associated to this dialogue that I wish to level out:
The dialogue above is predicated on the Gaussian mannequin, however the principle ideas prolong to any distribution.
The examples above match regression fashions with out covariates, so we are able to higher visualize the form of the censored and truncated distributions. Nonetheless, these ideas are simply prolonged to a regression framework with covariates the place the anticipated worth of a specific remark is a operate of the covariates.
I’ve mentioned using truncreg and tobit for censored and truncated knowledge. Nonetheless, these instructions may also be utilized to knowledge that aren’t truncated or censored however which might be sampled from a inhabitants with sure particular distributions.
References
Fogel, R. W., S. L. Engerman, J. Trussell, R. Floud, C. L. Pope and L. T. Wimmer. 1978. The economics of mortality in North America, 1650–1910: An outline of a analysis challenge. Historic Strategies 11: 75–108.
Matt, G. E., P. J. E. Quintana, M. F. Hovell, J. T. Bernert, S. Track, N. Novianti, T. Juarez, J. Floro, C. Gehrman, M. Garcia, S. Larson. 2004. Households contaminated by environmental tobacco smoke: sources of toddler exposures. Tobacco Management 13: 27–29.
Trussell, J. and D. E. Bloom. 1979. A mannequin distribution of peak or weight at a given age. Human Biology 51: 523–536.
Now, I do know what you’re pondering. Yet one more CSS pseudo-class… However I feel this suggestion is reasonably cool.
Earlier this yr, it was proposed so as to add a brand new pseudo-class, :drag, that might allow builders to use types when a component is being actively dragged by the consumer. Presently, CSS lacks a mechanism to detect drag interactions, making it troublesome to handle UI behaviors that rely upon this motion with out counting on JavaScript.
No JavaScript! I like the concept of getting a pseudo-class devoted to this operate reasonably than going by the classList.toggle() route.
drag (fires each few milliseconds when the factor is dragged),
dragstart (occasion fires on the preliminary drag), and
dragend (occasion fires when the dragging the factor stops).
Let’s take a fast have a look at how these drag-and-drop occasions work in JavaScript so as to perceive how they’d translate in CSS. Think about we now have seven button components in a
We will make all the .menu-bar draggable by slapping an attribute on it:
For our CSS, we merely give the is-dragging class some styling, which might be utilized solely when the factor is dragged or moved:
In CSS, we are able to arrange an .is-dragging class that we’ll set on the factor with JavaScript when it’s within the technique of being dragged. These are the types we apply to the factor when that’s occurring:
And right here’s the JavaScript to toggle between the beginning of the mouse drag and its finish. It listens for a dragstar occasion and provides the .is-dragging class to the .menu-bar. And once we drop the .menu-bar, the dragging enjoyable stops and the .is-dragging class is eliminated:
Our output would look one thing like this. Drag the dropdown factor to see:
Not unhealthy! When the menu bar is dragged, it retains a picture of itself in its authentic place that's styled with the .is-dragging class. And whereas we had been completely capable of knock this out with JavaScript, how cool would it not be to have that proposed :drag pseudo-class to summary all that script-y stuff:
+1 for efficiency! +1 for one much less dependency! +1 for maintainability!
How concerning the preview picture?
Do you know we are able to fashion the precise factor itself because it’s being dragged across the display screen? That’s referred to as the preview picture and we are able to exchange it with a
that we are able to add customized styling to.
The browser shows a “preview” of the factor as it's dragged.
const dragPreview = doc.createElement("div");
dragPreview.textContent = "📦 Dragging...";
dragPreview.fashion.cssText = `
background: #fff6d6;
border: 2px dashed orange;
border-radius: 0.5rem;
colour: #333;
padding: 0.5rem 1rem;
`;
doc.physique.appendChild(dragPreview);
// This replaces the default drag preview
occasion.dataTransfer.setDragImage(dragPreview, 0, 0);
// Take away after the occasion fires
setTimeout(() => dragPreview.take away(), 0);
Right here’s the place I’ll exit on a limb and recommend one other CSS pseudo particularly for that ::drag-image. Think about having the ability to sidestep all that JavaScript and straight-up write the types in CSS:
I suppose it might be a pseudo-class as an alternative, nevertheless it appears like a pseudo-element makes extra sense since we’re speaking a couple of particular object reasonably than a state.
I opened a problem for that — give it a thumbs-up for those who’d discover it helpful to have a ::drag-image pseudo-element like that. The CSSWG is already slated to debate the :drag proposal. If that will get baked into the specs, then I’d push for the pseudo-element, too.
Ideas?
Yea or nay for drag-related pseudos? Would you attain for one thing like that, or do you're feeling steps on JavaScript’s toes an excessive amount of?
. Compliance desires equity. The enterprise desires accuracy. At a small scale, you’ll be able to’t have all three. At enterprise scale, one thing shocking occurs.
Disclaimer:This text presents findings from my analysis on federated studying for credit score scoring. Whereas I supply strategic choices and proposals, they replicate my particular analysis context. Each group operates underneath totally different regulatory, technical, and enterprise constraints. Please seek the advice of your personal authorized, compliance, and technical groups earlier than implementing any strategy in your group.
The Regulator’s Paradox
You’re a credit score danger supervisor at a mid-sized financial institution. Your inbox simply landed three conflicting mandates:
Out of your Privateness Officer (citing GDPR): “Implement differential privateness. Your mannequin can’t leak buyer monetary information.”
Out of your Truthful Lending Officer (citing ECOA/FCRA): “Guarantee demographic parity. Your mannequin can’t discriminate towards protected teams.”
Out of your CTO: “We’d like 96%+ accuracy to remain aggressive.”
Right here’s what I found by analysis on 500,000 credit score information: All three are tougher to attain collectively than anybody admits. At a small scale, you face a real mathematical rigidity. However there’s a sublime answer hiding at enterprise scale.
Let me present you what the info reveals—and learn how to navigate this rigidity strategically.
Understanding the Three Targets (And Why They Conflict)
Earlier than I present you the stress, let me outline what we’re measuring. Consider these as three dials you’ll be able to flip:
Privateness (ε — “epsilon”)
ε = 0.5: Very non-public. Your mannequin reveals virtually nothing about people. However studying takes longer, so accuracy suffers.
ε = 1.0: Average privateness. A candy spot between safety and utility. Trade normal for regulated finance.
ε = 2.0: Weaker privateness. The mannequin learns quicker and reaches greater accuracy, however reveals extra details about people.
Decrease epsilon = stronger privateness safety (counterintuitive, I do know!).
Equity (Demographic Parity Hole)
This measures approval charge variations between teams:
Instance: If 71% of younger prospects are accredited however solely 68% of older prospects are accredited, the hole is 3 proportion factors.
Regulators take into account <2% acceptable underneath Truthful Lending legal guidelines.
0.069% (our manufacturing outcome) is outstanding—offering a 93% security margin under regulatory thresholds
Accuracy
Customary accuracy: proportion of credit score choices which are appropriate. Increased is best. Trade expects >95%.
The Plot Twist: Right here’s What Truly Occurs
Earlier than I clarify the small-scale trade-off, it is best to know the shocking ending.
At manufacturing scale (300 federated establishments collaborating), one thing exceptional occurs:
Accuracy: 96.94% ✓
Equity hole: 0.069% ✓ (~29× tighter than a 2% threshold)
However first, let me clarify why small-scale programs wrestle. Understanding the issue clarifies why the answer works.
The Small-Scale Stress: Privateness Noise Blinds Equity
Right here’s what occurs if you implement privateness and equity individually at a single establishment:
Differential privateness works by injecting calibrated noise into the coaching course of. This noise provides randomness, making it mathematically unattainable to reverse-engineer particular person information from the mannequin.
The issue: This identical noise blinds the equity algorithm.
A Concrete Instance
Your equity algorithm tries to detect: “Group A has 72% approval charge, however Group B has solely 68%. That’s a 4% hole—I want to regulate the mannequin to appropriate this bias.”
However when privateness noise is injected, the algorithm sees one thing fuzzy:
Group A approval charge ≈ 71.2% (±2.3% margin of error)
Group B approval charge ≈ 68.9% (±2.4% margin of error)
Determine 2. Privateness noise turns clear approval charge variations (left) into overlapping uncertainty ranges (proper), stopping the equity optimizer from confidently correcting bias.* Supply: Creator’s illustration based mostly on outcomes from Kaarat et al., “Unified Federated AI Framework for Credit score Scoring: For Privateness, Equity, and Scalability,” IJAIM (accepted, pending revisions)
Now the algorithm asks: “Is the hole actual bias, or simply noise from the privateness mechanism?”
When uncertainty will increase, the equity constraint turns into cautious. It doesn’t confidently appropriate the disparity, so the hole persists and even widens.
In less complicated phrases: Privateness noise drowns out the equity sign.
The Proof: 9 Experiments at Small Scale
I evaluated this trade-off empirically. Right here’s what I discovered throughout 9 totally different configurations:
The Outcomes Desk
Privateness Stage
Equity Hole
Accuracy
Sturdy Privateness (ε=0.5)
1.62–1.69%
79.2%
Average Privateness (ε=1.0)
1.63–1.78%
79.3%
Weak Privateness (ε=2.0)
1.53–1.68%
79.2%
What This Means
Accuracy is steady: Solely 0.15 proportion level variation throughout all 9 combos. Privateness constraints don’t tank accuracy.
Equity is inconsistent: Gaps vary from 1.53% to 2.07%, a 54% unfold. Most configurations cluster between 1.63% and 1.78%, however excessive variance seems on the extremes. The privacy-fairness relationship is weak.
Correlation is weak: r = -0.145. Tighter privateness (decrease ε) doesn’t strongly predict wider equity gaps.
Key perception: The trade-off exists, but it surely’s delicate and noisy on the small scale. You may’t clearly predict how tightening privateness will have an effect on equity. This isn’t a measurement error—it displays actual unpredictability when working with small datasets and restricted demographic variety. One outlier configuration (ε=1.0, δ_dp=0.05) reached 2.07%, however this represents a boundary situation moderately than typical conduct. Most settings keep under 1.8%.
Determine 3: Throughout 9 configurations (3 privateness ranges × 3 equity budgets), accuracy stays steady (~79.2%) whereas equity gaps fluctuate extensively (1.53%-2.07%), demonstrating the fragility of small-scale equity optimization. Supply: Kaarat et al., “Unified Federated AI Framework for Credit score Scoring: Privateness, Equity, and Scalability,” IJAIM (accepted, pending revisions).
Why This Occurs: The Mathematical Actuality
Right here’s the mechanism. While you mix privateness and equity constraints, complete error decomposes as:
The privateness penalty is the important thing: It grows as 1/ε²
This implies:
Reduce privateness finances by half (ε: 2.0 → 1.0)? The privateness penalty quadruples.
Reduce it by half once more (ε: 1.0 → 0.5)? It quadruples once more.
As privateness noise will increase, the equity optimizer loses sign readability. It could possibly’t confidently distinguish actual bias from noise, so it hesitates to appropriate disparity. The maths is unforgiving: Privateness and equity don’t simply commerce off—they work together non-linearly.
Three Practical Working Factors (For Small Establishments)
Slightly than count on perfection, listed here are three viable methods:
Now, right here’s the place it will get attention-grabbing.
Every little thing above assumes a single establishment with its personal information. Most banks have 5K to 100K prospects—sufficient for mannequin coaching, however not sufficient for equity throughout all demographic teams.
What if 300 banks collaborated?
Not by sharing uncooked information (privateness nightmare), however by coaching a shared mannequin the place:
Every financial institution retains its information non-public
Every financial institution trains domestically
Solely encrypted mannequin updates are shared
The worldwide mannequin learns from 500,000 prospects throughout various establishments
Determine 4. Enterprise-scale federation resolves the privateness–equity paradox: by aggregating information from 300 establishments, the federated mannequin reaches 96.94% accuracy with a 0.069% demographic parity hole at ε=1.0—round 23× fairer than the most effective single‑establishment mannequin at comparable accuracy. Supply: Creator’s illustration based mostly on experimental outcomes from Kaarat et al., “Unified Federated AI Framework for Credit score Scoring: Privateness, Equity, and Scalability,” IJAIM (accepted, pending revisions).
Right here’s the important thing perception: Completely different establishments have totally different buyer demographics.
Financial institution A (city): Largely younger, high-income prospects
Financial institution B (rural): Older, lower-income prospects
Financial institution C (on-line): Mixture of each
When the worldwide federated mannequin trains throughout all three, it should study characteristic representations that work pretty for everybody. A characteristic illustration that’s biased towards younger prospects fails Financial institution B. One biased towards rich prospects fails Financial institution C.
The worldwide mannequin self-corrects by competitors. Every establishment’s native equity constraint pushes again towards the worldwide mannequin, forcing it to be honest to all teams throughout all establishments concurrently.
This isn’t magic. It’s a consequence of information heterogeneity (a technical time period: “non-IID information”) serving as a pure equity regularizer.
What Regulators Truly Require
Now that you just perceive the stress, right here’s learn how to speak to compliance:
GDPR Article 25 (Privateness by Design)
“We’ll implement ε-differential privateness with finances ε = 1.0. Right here’s the mathematical proof that particular person information can’t be reverse-engineered from our mannequin, even underneath probably the most aggressive assaults.”
Translation: You decide to a particular ε worth and present the maths. No hand-waving.
ECOA/FCRA (Truthful Lending)
“We’ll preserve <0.1% demographic parity gaps throughout all protected attributes. Right here’s our monitoring dashboard. Right here’s the algorithm we use to implement equity. Right here’s the audit path.”
Translation: Equity is measurable, monitored, and adjustable.
EU AI Act (2024)
“We’ll obtain each privateness and equity by federated studying throughout [N] establishments. Listed below are the empirical outcomes. Right here’s how we deal with mannequin versioning, shopper dropout, and incentive alignment.”
Translation: You’re not simply constructing a good mannequin. You’re constructing a *system* that stays honest underneath life like deployment situations.
Your Strategic Choices (By Situation)
If You’re a Mid-Sized Financial institution (10K–100K Clients)
Actuality: You may’t obtain <0.1% equity gaps alone. Too little information per demographic group.
Medium-term (12 months): Be part of a consortium. Suggest federated studying collaboration to five–10 peer establishments.
Lengthy-term (18 months): Entry the federated international mannequin. Take pleasure in 96%+ accuracy + 0.069% equity hole.
Anticipated final result: Regulatory compliance + aggressive accuracy.
If You’re a Small Fintech (<5K Clients)
Actuality: You’re too small to attain equity alone AND too small to demand privateness shortcuts.
Technique:
Don’t go at it alone. Federated studying is constructed for this situation.
Begin a consortium or be part of one. Credit score union networks, group growth finance establishments, or fintech alliances.
Contribute your information (by way of privacy-preserving protocols, not uncooked).
Get entry to the worldwide mannequin skilled on 300+ establishments’ information.
Anticipated final result: You get world-class accuracy with out constructing it your self.
If You’re a Giant Financial institution (>500K Clients)
Actuality: You’ve gotten sufficient information for robust equity. However centralization exposes you to breach danger and regulatory scrutiny (GDPR, CCPA).
Technique:
Transfer from centralized to federated structure. Cut up your information by area or enterprise unit. Practice a federated mannequin.
Add exterior companions optionally. You may keep closed or divulge heart’s contents to different establishments for broader equity.
Leverage federated studying for explainability. Regulators want distributed programs (much less concentrated energy, simpler to audit).
Anticipated final result: Identical accuracy, higher privateness posture, regulatory defensibility.
What to Do This Week
Motion 1: Measure Your Present State
Ask your information staff:
“What’s our approval charge for Group A? For Group B?” (Outline teams: age, gender, revenue stage)
Calculate the hole: |Rate_A – Rate_B|
Is it >2%? If sure, you’re at regulatory danger.
Motion 2: Quantify Your Privateness Publicity
Ask your safety staff:
“Have we ever had an information breach? What was the monetary value?”
“If we suffered a breach with 100K buyer information, what’s the regulatory fantastic?”
This makes privateness not theoretical.
Motion 3: Resolve Your Technique
Small financial institution? Begin exploring federated studying consortiums (credit score unions, group banks, fintech alliances).
Giant financial institution? Architect an inner federated studying pilot.
Motion 4: Talk with Compliance
Cease imprecise guarantees. Decide to numbers:
“We’ll preserve ε = 1.0 differential privateness”
“We’ll maintain demographic parity hole <0.1%”
“We’ll audit equity month-to-month”
Numbers are defensible. Guarantees aren’t.
The Regulatory Implication: You Need to Select
Present rules assume privateness, equity, and accuracy are unbiased dials. They’re not.
You can not maximize all three concurrently at small scale.
The dialog along with your board needs to be:
“We will have: (1) Sturdy privateness + Truthful outcomes however decrease accuracy. OR (2) Sturdy privateness + Accuracy however weaker equity. OR (3) Federation fixing all three, however requiring partnership with different establishments.”
Select based mostly in your danger tolerance, not on regulatory fantasy.
Federation (Possibility 3) is the one path to all three. But it surely requires collaboration, governance complexity, and a consortium mindset.
The Backside Line
The impossibility of good AI isn’t a failure of engineers. It’s an announcement about studying from biased information underneath formal constraints.
At small scale: Privateness and equity commerce off. Select your level on the curve based mostly in your establishment’s values.
At enterprise scale: Federation eliminates the trade-off. Collaborate, and also you get accuracy, equity, and privateness.
The maths is unforgiving. However the choices are clear.
Begin measuring your equity hole this week. Begin exploring federation partnerships subsequent month. The regulators count on you to have a solution by subsequent quarter.
References & Additional Studying
This text is predicated on experimental outcomes from my forthcoming analysis paper:
Kaarat et al. “Unified Federated AI Framework for Credit score Scoring: Privateness, Equity, and Scalability.” Worldwide Journal of Utilized Intelligence in Medication (IJAIM), accepted, pending revisions.
Foundational ideas and regulatory frameworks cited:
McMahan et al. “Communication-Environment friendly Studying of Deep Networks from Decentralized Knowledge.” AISTATS, 2017. (The foundational paper on Federated Studying).
Common Knowledge Safety Regulation (GDPR), Article 25 (“Knowledge Safety by Design and Default”), European Union, 2018.
EU AI Act, Regulation (EU) 2024/1689, Official Journal of the European Union, 2024.
Equal Credit score Alternative Act (ECOA) & Truthful Credit score Reporting Act (FCRA), U.S. Federal Laws governing honest lending.
Questions or ideas? Please be happy to attach with me within the feedback. I’d love to listen to how your group is navigating the privacy-fairness trade-off.
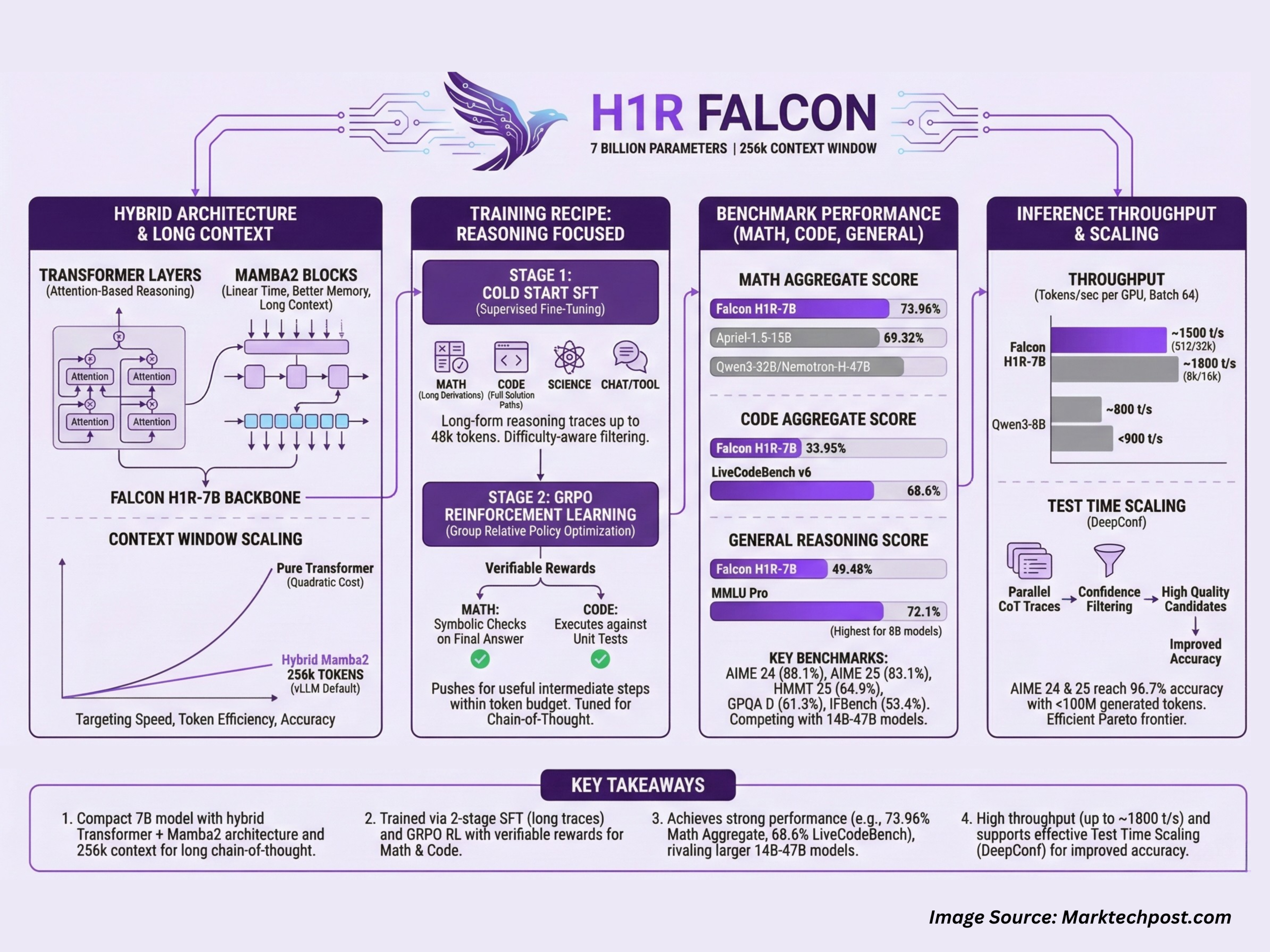
Expertise Innovation Institute (TII), Abu Dhabi, has launched Falcon-H1R-7B, a 7B parameter reasoning specialised mannequin that matches or exceeds many 14B to 47B reasoning fashions in math, code and common benchmarks, whereas staying compact and environment friendly. It builds on Falcon H1 7B Base and is obtainable on Hugging Face underneath the Falcon-H1R assortment.
Falcon-H1R-7B is fascinating as a result of it combines 3 design decisions in 1 system, a hybrid Transformer together with Mamba2 spine, a really lengthy context that reaches 256k tokens in commonplace vLLM deployments, and a coaching recipe that mixes supervised lengthy type reasoning with reinforcement studying utilizing GRPO.
Hybrid Transformer plus Mamba2 structure with lengthy context
Falcon-H1R-7B is a causal decoder solely mannequin with a hybrid structure that mixes Transformer layers and Mamba2 state area elements. The Transformer blocks present commonplace consideration based mostly reasoning, whereas the Mamba2 blocks give linear time sequence modeling and higher reminiscence scaling as context size grows. This design targets the three axes of reasoning effectivity that the crew describes, pace, token effectivity and accuracy.
The mannequin runs with a default --max-model-len of 262144 when served via vLLM, which corresponds to a sensible 256k token context window. This enables very lengthy chain of thought traces, multi step device use logs and huge multi doc prompts in a single go. The hybrid spine helps management reminiscence use at these sequence lengths and improves throughput in contrast with a pure Transformer 7B baseline on the identical {hardware}.
Coaching recipe for reasoning duties
Falcon H1R 7B makes use of a 2 stage coaching pipeline:
Within the first stage, the crew runs chilly begin supervised wonderful tuning on prime of Falcon-H1-7B Base. The SFT (supervised wonderful tuning) knowledge mixes step-by-step lengthy type reasoning traces in 3 foremost domains, arithmetic, coding and science, plus non reasoning domains reminiscent of chat, device calling and security. Issue conscious filtering upweights more durable issues and downweights trivial ones. Targets can attain as much as 48k tokens, so the mannequin sees lengthy derivations and full resolution paths throughout coaching.
Within the second stage, the SFT checkpoint is refined with GRPO, which is a bunch relative coverage optimization methodology for reinforcement studying. Rewards are given when the generated reasoning chain is verifiably appropriate. For math issues, the system makes use of symbolic checks on the ultimate reply. For code, it executes the generated program towards unit assessments. This RL stage pushes the mannequin to maintain helpful intermediate steps whereas staying inside a token finances.
The result’s a 7B mannequin that’s tuned particularly for chain of thought reasoning, moderately than common chat.
Benchmarks in math, coding and common reasoning
The Falcon-H1R-7B benchmark scores are grouped throughout math, code and agentic duties, and common reasoning duties.
Within the math group, Falcon-H1R-7B reaches an mixture rating of 73.96%, forward of Apriel-1.5-15B at 69.32% and bigger fashions like Qwen3-32B and Nemotron-H-47B. On particular person benchmarks:
AIME 24, 88.1%, increased than Apriel-1.5-15B at 86.2%
AIME 25, 83.1%, increased than Apriel-1.5-15B at 80%
HMMT 25, 64.9%, above all listed baselines
AMO Bench, 36.3%, in contrast with 23.3% for DeepSeek-R1-0528 Qwen3-8B
For code and agentic workloads, the mannequin reaches 33.95% as a bunch rating. On LiveCodeBench v6, Falcon-H1R-7B scores 68.6%, which is increased than Qwen3-32B and different baselines. It additionally scores 28.3% on the SciCode sub downside benchmark and 4.9% on Terminal Bench Exhausting, the place it ranks second behind Apriel 1.5-15B however forward of a number of 8B and 32B methods.
On common reasoning, Falcon-H1R-7B achieves 49.48% as a bunch rating. It information 61.3% on GPQA D, near different 8B fashions, 72.1% on MMLU Professional, which is increased than all different 8B fashions within the above desk, 11.1% on HLE and 53.4% on IFBench, the place it’s second solely to Apriel 1.5 15B.
The important thing takeaway is {that a} 7B mannequin can sit in the identical efficiency band as many 14B to 47B reasoning fashions, if the structure and coaching pipeline are tuned for reasoning duties.
Inference throughput and check time scaling
The crew additionally benchmarked Falcon-H1R-7B on throughput and check time scaling underneath reasonable batch settings.
For a 512 token enter and 32k token output, Falcon-H1R-7B reaches about 1,000 tokens per second per GPU at batch dimension 32 and about 1,500 tokens per second per GPU at batch dimension 64, practically double the throughput of Qwen3-8B in the identical configuration. For an 8k enter and 16k output, Falcon-H1R-7B reaches round 1,800 tokens per second per GPU, whereas Qwen3-8B stays under 900. The hybrid Transformer together with Mamba structure is a key issue on this scaling conduct, as a result of it reduces the quadratic value of consideration for lengthy sequences.
Falcon-H1R-7B can also be designed for check time scaling utilizing Deep Assume with confidence, generally known as DeepConf. The thought is to run many chains of thought in parallel, then use the mannequin’s personal subsequent token confidence scores to filter noisy traces and maintain solely prime quality candidates.
On AIME 24 and AIME 25, Falcon-H1R-7B reaches 96.7% accuracy with fewer than 100 million generated tokens, which places it on a good Pareto frontier of accuracy versus token value in contrast with different 8B, 14B and 32B reasoning fashions. On the parser verifiable subset of AMO Bench, it reaches 35.9% accuracy with 217 million tokens, once more forward of the comparability fashions at comparable or bigger scale.
Key Takeaways
Falcon-H1R-7B is a 7B parameter reasoning mannequin that makes use of a hybrid Transformer together with Mamba2 structure and helps a 256k token context for lengthy chain of thought prompts.
The mannequin is educated in 2 levels, supervised wonderful tuning on lengthy reasoning traces in math, code and science as much as 48k tokens, adopted by GRPO based mostly reinforcement studying with verifiable rewards for math and code.
Falcon-H1R-7B achieves robust math efficiency, together with about 88.1% on AIME 24, 83.1% on AIME 25 and a 73.96% mixture math rating, which is aggressive with or higher than bigger 14B to 47B fashions.
On coding and agentic duties, Falcon-H1R-7B obtains 33.95% as a bunch rating and 68.6% on LiveCodeBench v6, and it is usually aggressive on common reasoning benchmarks reminiscent of MMLU Professional and GPQA D.
The hybrid design improves throughput, reaching round 1,000 to 1,800 tokens per second per GPU within the reported settings, and the mannequin helps check time scaling via Deep Assume with confidence to enhance accuracy utilizing a number of reasoning samples underneath a managed token finances.
Try our newest launch of ai2025.dev, a 2025-focused analytics platform that turns mannequin launches, benchmarks, and ecosystem exercise right into a structured dataset you may filter, evaluate, and export
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.
Spotify Messages now presents an opt-in Listening exercise function, permitting linked family and friends to see what you might be taking part in in real-time.
A brand new Request to Jam button has been added to chats, making it simpler to coordinate and begin distant shared listening periods.
The options are rolling out to iOS and Android customers in markets the place Messages is enabled. Group chat help is deliberate for the close to future.
Spotify rolled out a Messages function in August final 12 months, and at the moment, the corporate is increasing its performance with Listening Exercise and Request to Jam.
Listening exercise is an opt-in function that enables Spotify customers to show the music they’re presently listening to inside Spotify Messages in real-time. In the event you’re not actively listening, your most just lately performed tune shall be displayed as a substitute.
Listening exercise is seen solely to family and friends you’ve gotten already linked with on Spotify Messages. You may see others’ exercise even when you haven’t turned your individual exercise on, so long as they’ve opted in.
If a person faucets on their good friend or member of the family’s listening exercise, they’ll be capable of add tracks to their library, begin playback, open the monitor’s context menu, or react with one in all six commonplace emojis.
Don’t wish to miss the very best from Android Authority?
Spotify Jam is one in all my favourite options, and I continuously use it for joint listening periods with my long-distance buddies. Nonetheless, coordinating a Jam session is a activity by itself. With Listening exercise now being a function, it’s simpler to determine when somebody is actively listening to music on Spotify, and so, the corporate is including a Request to Jam function to enrich it.
Inside a Spotify Messages chat, customers can faucet Jam within the high proper nook to ship a request for a distant Jam session. Your good friend can both settle for or decline the Jam, and in the event that they settle for it, they change into the host of the Jam session. Each members can add tracks to a shared queue and hear collectively. Pending Jam invites will trip in the event that they aren’t accepted inside a couple of minutes.
Listening exercise and Request to Jam at the moment are rolling out to customers in Messages-enabled markets on iOS and Android units, and shall be broadly accessible in these markets by early February. Listening exercise is offered to all customers with Messages entry, and Free customers can be part of a Request to Jam session when invited by a Premium person.
Moreover, Spotify additionally plans to broaden Messages to help Teams in choose markets within the close to future. The corporate talked about this in an e-mail to us, though the general public press launch makes no point out of it but.
Thanks for being a part of our neighborhood. Learn our Remark Coverage earlier than posting.
Betelgeuse is without doubt one of the weirdest stars within the sky, however astronomers can now clarify considered one of its most enduring mysteries. A small companion star has been confirmed, revealed by the wake it leaves because it plows by way of the crimson large’s environment.
Ignoring interference from the occasional dusty sneeze, Betelgeuse’s gentle appears to fluctuate in keeping with two distinct cycles. One lasts about 400 days and has been linked to inside pulsations. The second, nonetheless, lasts round 2,100 days, and has been a lot more durable to account for.
The main speculation suggests a small, dim companion star on a decent orbit across the crimson large, with observations culminating in a possible detection final July. Now, Betelgeuse’s buddy has lastly been confirmed, a number of months after its proposed title, Siwarha, was accepted.
Nearly eight years of observations utilizing the Hubble Area Telescope, the Fred Lawrence Whipple Observatory in Arizona, and Roque de Los Muchachos Observatory within the Canary Islands, Spain, supplied adequate proof of a second star’s ‘wake’ within the guise of a high-density path of gasoline in Betelgeuse’s bloated environment.
“It’s kind of like a ship shifting by way of water. The companion star creates a ripple impact in Betelgeuse’s environment that we will really see within the knowledge,” says Andrea Dupree, an astronomer on the Harvard & Smithsonian Heart for Astrophysics (CfA).
“For the primary time, we’re seeing direct indicators of this wake, or path of gasoline, confirming that Betelgeuse actually does have a hidden companion shaping its look and conduct.”
A chart highlighting how Siwarha’s wake modifications the spectrum of sunshine from Betelgeuse, relying on whether or not Siwarha is passing in entrance (orange line) or behind (blue line) the crimson supergiant. (NASA/ESA/Elizabeth Wheatley, STScI)
Siwarha is not dimming Betelgeuse’s gentle – as a substitute, it is altering the crimson supergiant’s spectrum, particularly UV wavelengths emitted by ionized iron. When the companion is in entrance of Betelgeuse, there is a sturdy peak within the gentle emitted by iron.
However after Siwarha ‘eclipses’ the star, its trailing tail of gasoline begins to soak up these wavelengths, resulting in a shorter peak. The impact slowly fades till Siwarha makes one other lap – some 2,109 days, or about 5.77 years, later.
“With this new direct proof, Betelgeuse provides us a front-row seat to observe how an enormous star modifications over time,” says Dupree.
“Discovering the wake from its companion means we will now perceive how stars like this evolve, shed materials, and finally explode as supernovae.”
Siwarha has now ducked again behind Betelgeuse and will not present its face once more till August 2027.
The examine has been accepted for publication in The Astrophysical Journal, and is at present out there on the preprint server arXiv.
This story appeared in The Logoff, a day by day publication that helps you keep knowledgeable in regards to the Trump administration with out letting political information take over your life. Subscribe right here.
Welcome to The Logoff: As we speak marks 5 years for the reason that January 6, 2021, assault on the US Capitol by a mob of President Donald Trump’s supporters. To commemorate the event, the White Home launched a brand new web page promising the “TRUTH” about “a date which can stay in infamy.” Put merely, it’s bonkers.
How does the White Home describe January 6? The web page, which prominently encompasses a black-and-white picture of former Speaker Nancy Pelosi looming over different members of Congress, claims that “it was the Democrats who staged the actual revolt” and describes the 2020 election as “stolen.” (They didn’t, and it was not.)
It additionally claims, falsely, that no regulation enforcement officers misplaced their lives and suggests Capitol Police “escalate[d] tensions” with rioters. In actuality, three officers who died within the days following the assault are thought-about to have died “within the line of responsibility.”
The complete checklist of distortions and false statements is simply too lengthy to get into right here, and it could be simpler to checklist the issues the web page does get proper. For instance, the proper date, January 6, 2021, is in block letters on the prime of the web page.
Why does this matter? Trump and the Republican Social gathering have each taken many swings at rewriting the narrative of January 6, however that is their most complete effort up to now. Notably, it’s not merely coming off the cuff in a Trump rally speech. It is a deliberate, taxpayer-funded try and rewrite historical past (and, seemingly, to troll Trump’s opponents).
What’s the large image? In some ways, Trump has already succeeded the place it counts on January 6. He’s president once more, and he has his celebration absolutely behind him on this difficulty. Marco Rubio, who was a senator on January 6 and described it as “anti-American anarchy,” is now his secretary of state. And whereas the assault nonetheless isn’t widespread with voters writ massive, it’s additionally fading as an animating difficulty. The White Home web page could also be greatest considered as a victory lap.
And with that, it’s time to log out…
Boy, that was a bleak one. Let’s finish with one fast good factor and get off the web. I actually loved this week’s New Yorker cowl, which depicts a cat in a window as passersby trudge by winter climate outdoors. It’s the sort of small second that at all times brightens my day when it occurs in actual life, too. Have an excellent night, and we’ll see you again right here tomorrow!
Historic people taking up an elephant – our ancestors could have begun butchering the animals 1.8 million years in the past
NATURAL HISTORY MUSEUM, LONDON/SCIENCE PHOTO LIBRARY
Butchering an elephant is an awfully tough feat, requiring severe instruments and cooperation, with the reward being a protein bonanza.
Now a staff of researchers led by Manuel Domínguez-Rodrigo at Rice College in Texas say that historical people could have achieved this milestone 1.78 million years in the past at Olduvai Gorge in Tanzania.
“At about 2 million years in the past people have been systematically consuming animals like gazelles or waterbucks, however not greater recreation,” says Domínguez-Rodrigo.
Somewhat later, proof from Olduvai Gorge hints that issues modified. The gorge is wealthy in animal and hominin fossils that shaped between about 2 million and 17,000 years in the past, and at roughly 1.8 million years in the past there’s a sudden change in the kind of animal bones preserved, with stays of elephants and hippos turning into far more considerable. Even so, proving they’d been butchered by people remained tough, he says.
Then, in June 2022, Domínguez-Rodrigo and his colleagues found what seems to be an historical elephant butchery web site at Olduvai.
The positioning, which they named the EAK web site, consisted of the partial skeleton of an extinct elephant species known as Elephas recki, surrounded by giant numbers of stone instruments of a kind a lot bigger and extra heavy-duty than the stone instruments that had been utilized by hominins earlier than the two million 12 months mark. These new instruments, says Domínguez-Rodrigo, have been possible manufactured by an historical human known as Homo erectus.
“They embody Pleistocene knives which can be as sharp once we excavated them as they have been when [ancient] people used them.”
Domínguez-Rodrigo and his colleagues suppose that the stone instruments have been used to butcher the elephant. Among the giant limb bones appear to have been damaged shortly after the elephant’s dying, whereas the bones have been nonetheless recent – or “inexperienced”. Scavengers like hyenas may have torn flesh from the carcasses, however they’re unable to interrupt the shafts of grownup or virtually grownup elephant bones, he says.
“We documented a few such bones in our web site bearing inexperienced fractures, thereby displaying that people had damaged them utilizing hammerstones,” he says. “These inexperienced damaged bones are considerable throughout the panorama sampled 1.7 million years in the past and likewise bear often percussion marks related to them.”
There’s, nevertheless, little proof of the scratches – or minimize marks – that butchery can typically go away on bones when meat is eliminated.
What is just not recognized is whether or not people killed the elephant or simply stumbled throughout the carcass and opportunistically took benefit of it.
“The one safe factor that we will say is that they butchered it, or a part of it, and within the course of left a number of instruments with its bones,” says Domínguez-Rodrigo.
He provides that the transition to butchering elephants was not merely because of the invention of higher stone instruments but in addition an indication that hominin teams have been starting to develop bigger, leading to social and cultural modifications.
However Michael Pante at Colorado State College is just not satisfied by the analysis.
The proof that this particular person elephant was exploited by human ancestors is weak, says Pante. It’s because the interpretation depends on the stone instruments and the elephant bones being shut collectively and the presence of fractures interpreted to have been made by human ancestors in search of marrow, says Pante.
“Not like the EAK web site the bones of those taxa [at the HWK EE site] have minimize marks and are in affiliation with hundreds of different bones and artifacts in archaeological context,” he says.
Discovery Excursions: Archaeology and palaeontology
New Scientist recurrently reviews on the numerous wonderful websites worldwide, which have modified the best way we take into consideration the daybreak of species and civilisations. Why not go to them your self?






")














{kind=link}