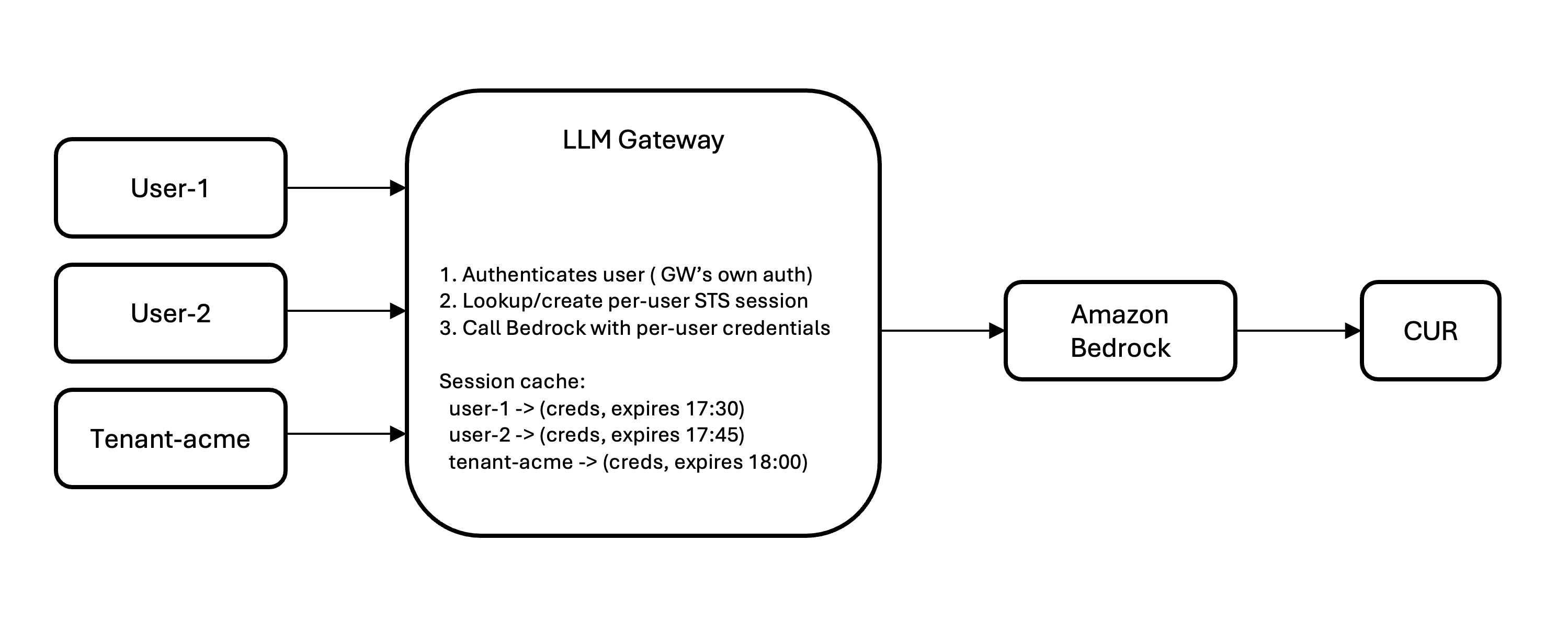
Merging issues combining datasets on the identical observations to provide a outcome with extra variables. We are going to name the datasets one.dta and two.dta.
With regards to combining datasets, the choice to merging is appending, which is combining datasets on the identical variables to provide a outcome with extra observations. Appending datasets just isn’t the topic for immediately. However simply to repair concepts, appending appears to be like like this:
+-------------------+
| var1 var2 var3 | one.dta
+-------------------+
1. | one.dta |
2. | |
. | |
. | |
+-------------------+
+
+-------------------+
| var1 var2 var3 | two.dta
+-------------------+
1. | two.dta |
2. | |
. | |
+-------------------+
=
+-------------------+
| var1 var2 var3 |
+-------------------+
1. | | one.dta
2. | |
. | |
. | |
+ + +
N1+1. | | two.dta appended
N2+2. | |
. | |
+-------------------+
Merging appears to be like like this:
+-------------------+ +-----------+
| var1 var2 var3 | | var4 var5 |
+-------------------+ +-----------+
1. | | 1. | |
2. | | + 2. | | =
. | | . | |
. | | . | |
+-------------------+ +-----------+
one.dta two.dta
+-------------------+-----------+
| var1 var2 var3 var4 var5 |
+-------------------------------+
1. | |
2. | |
. | |
. | |
+-------------------+-----------+
one.dta + two.dta merged
The matching of the 2 datasets — deciding which observations in a single.dta are mixed with which observations in two.dta — could possibly be achieved merely on the statement numbers: Match one.dta statement 1 with two.dta statement 1, match one.dta statement 2 with two.dta statement 2, and so forth. In Stata, you may acquire that outcome by typing
. use one, clear . merge 1:1 utilizing two
By no means do that as a result of it’s too harmful. You might be merely assuming that statement 1 matches with statement 1, statement 2 matches with statement 2, and so forth. What if you’re incorrect? If statement 2 in a single.dta is Bob and statement 2 in two.dta is Mary, you’ll mistakenly mix the observations for Bob and Mary and, maybe, by no means discover the error.
The higher answer is to match the observations on equal values of an identification variable. This fashion, the statement with id=”Mary” is matched with the statement with id=”Mary”, id=”Bob” with id=”Bob”, id=”United States” with id=”United States”, and id=4934934193 with id=4934934193. In Stata, you do that by typing
. use one, clear . merge 1:1 id utilizing two
Issues can nonetheless go incorrect. For example, id=”Bob” is not going to match id=”Bob ” (with the trailing clean), however for those who anticipated all of the observations to match, you’ll in the end discover the error. Mistakenly unmatched observations are inclined to get observed due to all of the lacking values they trigger in subsequent calculations.
It’s the mistakenly mixed observations that may go unnoticed.
And that’s the subject for immediately, mistakenly matched observations, or merges gone dangerous.
Observations are mistakenly mixed extra typically than many researchers notice. I’ve seen it occur. I’ve seen it occur, be found later, and necessitate withdrawn outcomes. You critically want to think about the chance that this might occur to you. Solely three issues are sure on this world: dying, taxes, and merges gone dangerous.
I’m going to imagine that you’re conversant in merging datasets each conceptually and virtually; that you simply already know what 1:1, m:1, 1:m, and m:n imply; and that you already know the position performed by “key” variables similar to ID. I’m going to imagine you’re conversant in Stata’s merge command. If any of that is unfaithful, learn [D] merge. Sort assist merge in Stata and click on on [D] merge on the high to take you to the complete PDF manuals. We’re going to choose up the place the dialogue in [D] merge leaves off.
Detecting when merges go dangerous
As I mentioned, the subject for immediately is merges gone dangerous, by which I imply producing a merged outcome with the incorrect information mixed. It’s troublesome to think about that typing
. use one, clear . merge 1:1 id utilizing two
may produce such a outcome as a result of, to be matched, the observations needed to have equal values of the ID. Bob matched with Bob, Mary matched with Mary, and so forth.
Proper you’re. There isn’t any drawback assuming the values within the id variable are appropriate and constant between datasets. However what if id==4713 means Bob in a single dataset and Mary within the different? That may occur if the id variable is solely incorrect from the outset or if the id variable turned corrupted in prior processing.
1. Use concept to verify IDs if they’re numeric
A method the id variable can turn into corrupted is that if it isn’t saved correctly or whether it is learn improperly. This will occur to each string and numeric variables, however proper now, we’re going to emphasize the numeric case.
Say the identification variable is Social Safety quantity, an instance of which is 888-88-8888. Social Safety numbers are invariably saved in computer systems as 888888888, which is to say that they’re run collectively and look loads just like the quantity 888,888,888. Generally they’re even saved numerically. Say you’ve gotten a uncooked knowledge file containing completely legitimate Social Safety numbers recorded in simply this fashion. Say you learn the quantity as a float. Then 888888888 turns into 888888896, and so does each Social Safety quantity between 888888865 and 888888927, some 63 in complete. If Bob has Social Safety quantity 888888869 and Mary has 888888921, and Bob seems in dataset one and Mary in dataset two, then Bob and Mary will probably be mixed as a result of they share the identical rounded Social Safety quantity.
All the time be suspicious of numeric ID variables saved numerically, not simply these saved as floats.
Once I learn uncooked knowledge and retailer the ID variables as numeric, I fear whether or not I’ve specified a storage kind adequate to keep away from rounding. Once I acquire knowledge from different sources that comprise numeric ID variables, I assume that the opposite supply improperly saved the values till confirmed in any other case.
Maybe you do not forget that 16,775,215 is the most important integer that may be saved exactly as a float and 9,007,199,254,740,991 is the most important that may be saved exactly as a double. I by no means do.
As an alternative, I ask Stata to indicate me the most important theoretical ID quantity in hexadecimal. For Social Safety numbers, the most important is 999-99-9999, so I kind
. inbase 16 999999999 3b9ac9ff
Stata’s inbase command converts decimal numbers to totally different bases. I study that 999999999 base-10 is 3b9ac9ff base-16, however I don’t care in regards to the particulars; I simply need to know the variety of base-16 digits required. 3b9ac9ff has 8 digits. It takes 8 base-16 digits to file 999999999. As you realized in learn the %21x format, half 2, I do do not forget that doubles can file 13 base-16 digits and floats can file 5.75 digits (the 0.75 half being as a result of the final digit should be even). If I didn’t keep in mind these numbers, I might simply show a quantity in %21x format and depend the digits to the suitable of the binary level. Anyway, Social Safety numbers could be saved in doubles as a result of 8<13, the variety of digits double offers, however not in floats as a result of 8 just isn’t < 5.75, the variety of digits float offers.
If Social Safety numbers contained 12 digits slightly than 9, the most important can be
. inbase 16 999999999999 38d4a50fff
which has 10 base-16 digits, and since 10<13, it could nonetheless match right into a double.
Anyway, if I uncover that the storage kind is inadequate to retailer the ID quantity, I do know the ID numbers should be rounded.
2. Verify uniqueness of IDs
I mentioned that after I acquire knowledge from different sources, I assume that the opposite supply improperly saved the ID variables till confirmed in any other case. I ought to have mentioned, till proof accumulates on the contrary. Even when the storage kind used is adequate, I have no idea what occurred in earlier processing of the info.
Right here’s a method utilizing datasets one.dta and two.dta to build up a few of that proof:
. use one, clear // take a look at 1 . kind id . by id: assert _N==1 . use two, clear // take a look at 2 . kind id . by id: assert _N==1
In these exams, I’m verifying that the IDs actually are distinctive within the two datasets that I’ve. Exams 1 and a couple of are pointless after I plan later to merge 1:1 as a result of the 1:1 half will trigger Stata itself to verify that the IDs are distinctive. However, I run the exams. I do that as a result of the datasets I merge are sometimes subsets of the unique knowledge, and I need to use all of the proof I’ve to invalidate the declare that the ID variables actually are distinctive.Generally I obtain datasets the place it takes two variables to verify I’m calling a novel ID. Maybe I obtain knowledge on individuals over time, together with the declare that the ID variable is identify. The documentation additionally notes that variable date information when the statement was made. Thus, to uniquely determine every of the observations requires each identify and date, and I kind
. kind identify date . by identify date: assert _N==1
I’m not suspicious of solely datasets I obtain. I run this identical take a look at on datasets I create.
3. Merge on all widespread variables
At this level, I do know the ID variable(s) are distinctive in every dataset. Now I contemplate the concept that the ID variables are inconsistent throughout datasets, which is to say that Bob in a single dataset, nevertheless he’s recognized, means Mary within the different. Detecting such issues is all the time problematic, however not almost as problematic as you may guess.
It’s uncommon that the datasets I have to merge haven’t any variables in widespread besides the ID variable. If the datasets are on individuals, maybe each datasets comprise every individual’s intercourse. In that case, I may merge the 2 datasets and confirm that the intercourse is identical in each. Really, I can do one thing simpler than that: I can add variable intercourse to the important thing variables of the merge:
. use one, clear . merge 1:1 id intercourse utilizing two
Assume I’ve a legitimate ID variable. Then including variable intercourse doesn’t have an effect on the result of the merge as a result of intercourse is fixed inside id. I acquire the identical outcomes as typing merge 1:1 id utilizing two.
Now assume the id variable is invalid. In contrast with the outcomes of merge 1:1 id utilizing two, Bob will not match with Mary even when they’ve the identical ID. As an alternative I’ll acquire separate, unmatched observations for Bob and Mary within the merged knowledge. Thus to finish the take a look at that there aren’t any such mismatches, I have to confirm that the id variable is exclusive within the merged outcome. The entire code reads
. use one, clear . merge 1:1 id intercourse utilizing two . kind id . by id: assert _N==1
And now you already know why in take a look at 2 I checked the individuality of ID inside dataset by hand slightly than relying on merge 1:1. The 1:1 merge I simply carried out is on id and intercourse, and thus merge doesn’t verify the individuality of ID in every dataset. I checked by hand the individuality of ID in every dataset after which checked the individuality of the outcome by hand, too.
Passing the above take a look at doesn’t show that that the ID variable is constant and thus the merge is appropriate, but when the assertion is fake, I do know with certainty both that I’ve an invalid ID variable or that intercourse is miscoded in one of many datasets. If my knowledge has roughly equal variety of women and men, then the take a look at has a 50 p.c probability of detecting a mismatched pair of observations, similar to Bob and Mary. If I’ve simply 10 mismatched observations, I’ve a 1-0.910 = 0.9990 likelihood of detecting the issue.
I ought to warn you that if you wish to hold simply the matched observations, don’t carry out the merge by coding merge 1:1 id intercourse utilizing two, hold(matched). It’s essential to hold the unrivaled observations to carry out the ultimate a part of the take a look at, particularly, that the ID numbers are distinctive. Then you possibly can drop the unrivaled observations.
. use one, clear . merge 1:1 id intercourse utilizing two . kind id . by id: assert _N==1 . hold if _merge==3
There could also be a couple of variable that you simply anticipate to be the identical in mixed observations. A handy characteristic of this take a look at is you can add as many expected-to-be-constant variables to merge‘s keylist as you want:
. use one, clear . merge 1:1 id intercourse hiredate groupnumber utilizing two . kind id . by id: assert _N==1 . hold if _merge==3
It’s uncommon that there’s not no less than one variable apart from the ID variable that’s anticipated to be equal, however it does occur. Even when you have expected-to-be-constant variables, they could not work as properly in detecting issues as variable intercourse within the instance above. The distribution of the variable issues. In case your knowledge are of individuals identified to be alive in 1980 and the known-to-be-constant variable is whether or not born after 1900, even mismatched observations can be prone to have the identical worth of the variable as a result of most individuals alive in 1980 had been born after 1900.
4. Take a look at a random pattern
This take a look at is weak, however it is best to do it anyway, if solely as a result of it’s really easy. Checklist a number of the mixed observations and take a look at them.
. listing in 1/5
Do the mixed outcomes appear to be they go collectively?
By the way in which, the suitable method to do that is
. gen u = uniform() . kind u . listing in 1/5 . drop u
You don’t want to have a look at the primary observations as a result of, having small values of ID, they’re in all probability not consultant. Nevertheless IDs are assigned, the method is unlikely to be randomized. Individuals with low values of ID will probably be youthful, or older; or more healthy, or sicker; or ….
5. Take a look at a nonrandom pattern
You simply merged two datasets, so clearly you probably did that since you wanted the variables and people variables are by some means associated to the present variables. Maybe your knowledge is on individuals, and also you mixed the 2009 knowledge with the 2010 knowledge. Maybe your knowledge is on nations, and also you added export knowledge to your import knowledge. No matter you simply added, it isn’t random. If it had been, you may have saved your self time by merely producing the brand new variables containing random numbers.
So generate an index that measures a brand new variable when it comes to an outdated one, similar to
. gen diff = income2010 - income2009
or
. gen diff = exports - imports
Then kind on the variable and take a look at the observations containing essentially the most outlandish values of your index:
. kind diff . listing in 1/5 . listing in -5/l
These are the observations most definitely to be mistakenly mixed. Do you consider these observations had been mixed appropriately?
Conclusion
I admit I’m not suspicious of each merge I carry out. I’ve constructed up belief over time in datasets that I’ve labored with beforehand. Even so, my capacity to make errors is the same as yours, and even with reliable datasets, I can introduce issues lengthy earlier than I get to the merge. It is advisable to rigorously contemplate the implications of a mistake. I have no idea anybody who performs merges who has not carried out a merge gone dangerous. The query is whether or not she or he detected it. I hope so.