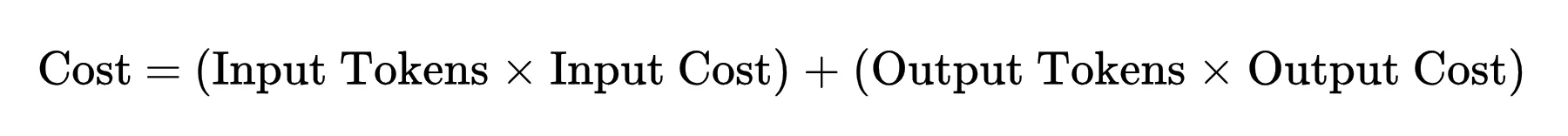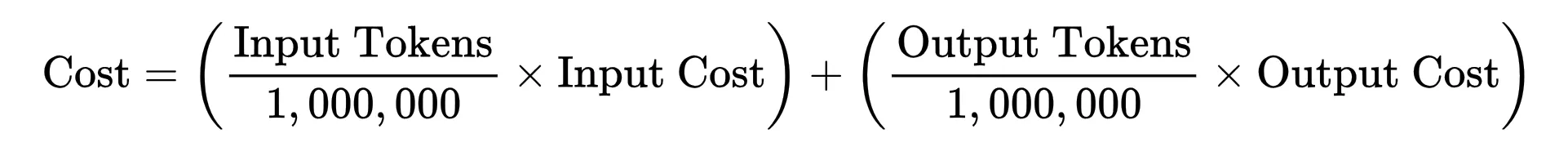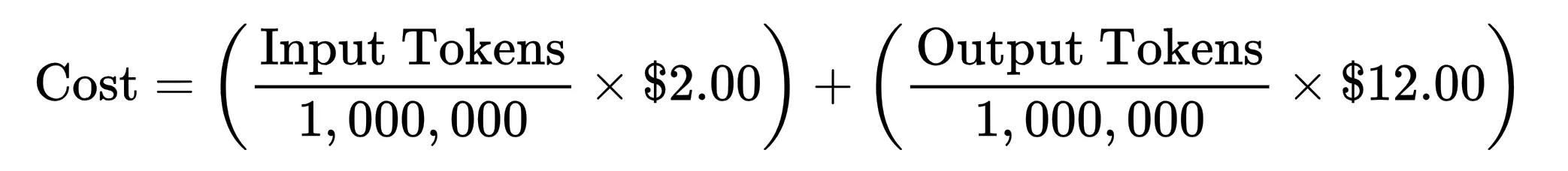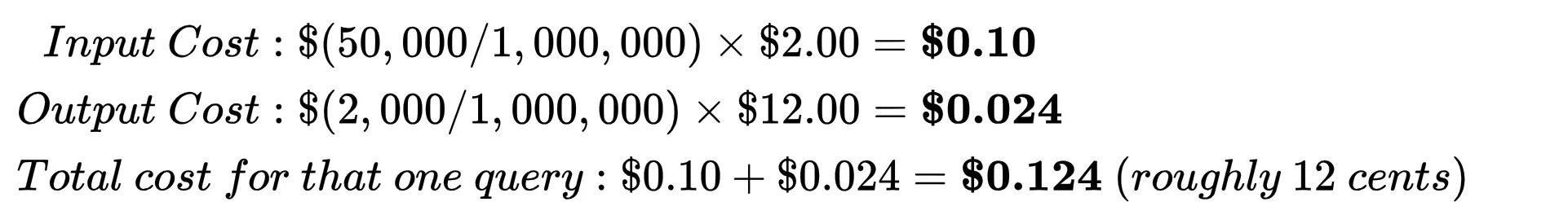I promised the total agenda would drop quickly. At this time’s the day. The schedule is locked in, the permitted periods are on the board, and I wish to stroll you thru what three days of deep-technical, engineering-led Azure content material appears like.
A fast refresher earlier than we get into the content material: this occasion is free, it’s digital, and it’s constructed by engineering for engineering. Most periods are on the L300–L400 stage, which implies we’re skipping the advertising and marketing slide and getting straight to the structure, the gotchas, and the “right here’s what truly occurs in manufacturing” tales you got here for.
We’re beginning at 8:00 AM Pacific every day and working stable technical content material by means of the afternoon. You’ll be able to nonetheless register right here (https://aka.ms/MAIS-reg)
We organized the three days across the pillars our group retains coming again to, Construct, Function, and Optimize. Day 1 leans into Construct so you allow the keynote with momentum, Day 2 bridges Construct into Function (the place most of us truly spend our workdays), and Day 3 is pure Optimize, resiliency, price, efficiency, and networking, earlier than we shut issues out.
Day 1, Mon, Could 19 · BUILD
Day 2, Tue, Could 20 · BUILD + OPERATE
Day 3, Wed, Could 21 · OPTIMIZE + Closing
8:00 KEYNOTE: Welcome & Azure Infrastructure Imaginative and prescient
8:00, Construct and Optimize a Knowledge Lakehouse for Unified Knowledge Intelligence
8:00, Reaching Zonal Resiliency in Azure Infrastructure
9:00, Construct a Sovereign Non-public Cloud with Azure Native
8:45, Designing Azure Networks That Scale: From Small Deployments to Enterprise-Grade
8:30, Architecting Resilient Azure Platforms: Sturdy Features, Cosmos DB, and DR by Design
9:45, The Azure Deployment Agent: How AI Turns a Immediate right into a Manufacturing-Prepared Workload
9:30, From Alert to Resolved: Constructing a Self-Therapeutic Azure Platform with SRE Agent
9:00, Optimizing EDA & HPC Pipelines on Azure: Excessive-Efficiency Shared Storage with Azure NetApp Information
10:15, ALZ IaC Accelerator: Deploy Your Azure Platform Touchdown Zone with IaC
10:15, Agentic Migrations & Modernization
9:30, Elastic SAN for AVS Datastores: Greatest Worth-Efficiency Exterior Storage
11:00, Constructing Safe, Effectively-Architected Azure Workloads by Default with Azure Verified Modules and GitHub Copilot
10:45, Simplifying File Share Administration and Management for Azure Information
10:00, Premium SSD v2 Disk: Greatest Worth-Efficiency Block Storage for VMs and Containers
11:45, Greatest Practices for Infrastructure as Code CI/CD on Azure
11:30, Market Picture Safety: Safeguarding Workloads By Patching and Swish Deprecation
10:45, Optimizing File Storage for AI and Cloud-Native Workloads on Azure
12:30, Trendy Ingress for AKS: Introducing Software Gateway for Containers (AGC)
12:00, Working Hybrid at Scale: Actual-World Azure Arc Patterns for Governance, Safety, and Value Management
11:30, Minimize Storage Prices, Increase ROI: Optimizing Your Storage TCO on Azure Object Storage
13:15, Finish-to-Finish Safety on AKS Utilizing Azure Software Gateway for Containers with Managed Cilium
12:45, Run At-Scale On-Premises and Cloud Assessments and Migrations to Azure Storage
12:15, Easy methods to Construct Resilient Networks Utilizing Azure Networking, What’s New in Azure Software program Load Balancing
14:00, Deployment Stacks: Getting Began
13:30, Modernize VDI with Azure Information and Entra Cloud-Native Identities
13:00, AKS Networking at Scale, CNI, Safety, and Multi-Cluster Networking with Accelerated Efficiency
14:30, Accelerating Automated VM Picture Pipelines with Azure Picture Builder and Azure Compute Gallery
14:15, Working Azure Backup at Scale: Day-2 Excellence for IaaS, PaaS, and Storage Workloads
13:45, Kubenet Deprecation, Futureproofing AKS IPAM and Dataplane Configurations
15:00, Troubleshooting Kubernetes Networking with an AI Diagnostic Assistant
14:15, Implement Zero-Tolerance Downtime Internet Apps with Azure Entrance Door
14:45, Closing: Azure Infrastructure Utilized Abilities and Certifications
Block your calendar, Could 19, 20, and 21, 8:00 AM PT begin every day. Take a look at www.azureinfrasummit.com for extra info.
Choose your periods, the net schedule has ICS recordsdata for every session. Construct your private monitor throughout Construct, Function, and Optimize.
Deliver your staff, the agenda is intentionally huge: platform engineers, SREs, storage people, community people, AKS operators, IaC builders, and backup/DR homeowners will all discover their periods.
We put lots of work into ensuring each slot earned its place, these are engineering-delivered, production-grounded, no-fluff periods. The audio system are the folks delivery the options you’re utilizing in Azure.
The checklist builds on our annual 10 Breakthrough Applied sciences, however takes a wider view of the concepts, subjects, and analysis shaping AI, spotlighting the tendencies and breakthroughs shaping the world.
We’ll be unpacking one merchandise from the checklist every day right here in The Obtain, explaining what it means and why it issues. Learn the complete rundown now—and keep tuned for the times forward.
MIT Expertise Assessment Narrated: desalination crops within the Center East are more and more susceptible
Because the battle in Iran has escalated, a vital useful resource is underneath fireplace: the desalinization know-how that provides water within the area.
President Donald Trump not too long ago threatened to destroy “presumably all desalinization crops” in Iran if the Strait of Hormuz just isn’t reopened. The impression on farming, business, and—crucially—ingesting within the Center East could possibly be extreme. Discover out why.
—Casey Crownhart
That is our newest story to be was an MIT Expertise Assessment Narrated podcast, which we publish every week on Spotify and Apple Podcasts. Simply navigate to MIT Expertise Assessment Narrated on both platform, and comply with us to get all our new content material because it’s launched.
The must-reads
I’ve combed the web to seek out you immediately’s most enjoyable/essential/scary/fascinating tales about know-how.
1 An unauthorized group has reportedly accessed Anthropic’s Mythos Customers in a personal on-line discussion board might have gained entry. (Bloomberg $) + Anthropic mentioned the mannequin was too harmful for a full launch. (Axios) + Mozilla used it to seek out 271 safety vulnerabilities in Firefox. (Wired $)
2 Meta will observe staff’ clicks and keystrokes for AI coaching Monitoring software program is being put in on staff’ computer systems.(Reuters $) + Workers are up in arms about this system. (Enterprise Insider) + LLMs may supercharge mass surveillance within the US. (MIT Expertise Assessment)
3 ChatGPT allegedly suggested the Florida State shooter About when and the place to strike, and which ammunition to make use of. (Washington Submit $) + Florida’s legal professional basic is probing ChatGPT’s position within the taking pictures. (Ars Technica) + Does AI trigger delusions or simply amplify them? (MIT Expertise Assessment)
In 2001 scientists learning human language made a breakthrough: by trying on the DNA of a household with a uncommon speech incapacity, they discovered {that a} mutation in a single gene referred to as FOXP2 had been chargeable for the situation. On the time, scientists thought the gene could possibly be the important thing to how people developed language.
“That was the gene that launched 1,000 ships,” says Jacob Michaelson, a professor of psychiatry on the College of Iowa. Since then the image has blurred: throughout the inhabitants, FOXP2 doesn’t appear to be single-handedly driving our language talents. One thing else should be happening.
And now new analysis from Michaelson and his colleagues provides a chunk to the puzzle: some areas of our genome which might be influenced by the exercise of genes like FOXP2 could also be far more historical than scientists realized.
On supporting science journalism
If you happen to’re having fun with this text, think about supporting our award-winning journalism by subscribing. By buying a subscription you might be serving to to make sure the way forward for impactful tales in regards to the discoveries and concepts shaping our world as we speak.
In a examine printed in Science Advances on Wednesday, Michaelson and his workforce grouped areas of the human genome by age and regarded for which teams tracked closest to language potential. They discovered that the areas that “pack probably the most punch,” in keeping with Michaelson, are among the many most historical components of our genome—having developed earlier than fashionable people cut up from Neanderthals. Scientists name these genetic areas “human ancestor rapidly developed areas” (HAQERs).
“It’s not very a lot of the genome,” Michaelson says, explaining that these areas account for round a tenth of a p.c of our DNA. “However we discovered that an enormous quantity of the genetic variation that explains particular person [language] variations was in there.”
The researchers analyzed the genomes of 350 elementary college college students in Iowa who took 17 language potential checks at varied occasions between kindergarten and fourth grade. A pattern emerged: the traditional HAQERs tracked with an individual’s language potential. They discovered the identical pattern amongst greater than 100,000 people enrolled in different research, such because the UK Biobank well being examine and SPARK (Simons Powering Autism Analysis), a big examine on autism.
HAQERs aren’t genes. They’re areas of the genome that act like “quantity knobs” or “dials” that fine-tune how and when genes are expressed, Michaelson explains. “Individually, these don’t have an enormous impact, and they also’re usually very exhausting to review. However collectively, they will have a giant impact.” Proteins made by genes like FOXP2, in the meantime, act as “fingers” on the dials all through the genome.
Collectively, these “dials” and “fingers” seem to affect human language improvement, in keeping with the findings. “It’s the collective impact of variation throughout all these totally different websites that appears to be the key explainer of particular person variations in language,” Michaelson says. “There’s no single gene for language.”
Importantly, HAQERs are simply one in every of many elements that might play a job in how fashionable people developed speech, and it’s unclear what Neanderthals’ “language” might need regarded like. However Michaelson says that his workforce’s findings recommend that “they actually had the organic {hardware} and the propensity to have language.” Extra analysis is required to clarify what function HAQERs performed in Neanderthals, nonetheless.
“The authors could have recognized genetic sequences related to variation in language potential in fashionable people, however we can not know with certainty if these sequences arose in our historical previous as a result of they granted language talents in our ancestors,” says Mark Pagel, a professor of evolutionary biology on the College of Studying in England, who was not concerned within the examine. “They developed throughout a time of fast enlargement of the hominin mind, and so their origin would possibly lie in selling that evolutionary mind progress.”
On a extra philosophical stage, Michaelson says, the findings are a reminder that that our need to have interaction in face-to-face communication—and to be understood by others—has historical evolutionary roots.
Human language “resonates with the code that’s inside us,” Michaelson says. “By eons of evolution, our species has been optimized for this.”
It’s Time to Stand Up for Science
If you happen to loved this text, I’d prefer to ask to your assist. Scientific American has served as an advocate for science and trade for 180 years, and proper now will be the most crucial second in that two-century historical past.
I’ve been a Scientific American subscriber since I used to be 12 years outdated, and it helped form the way in which I have a look at the world. SciAm at all times educates and delights me, and evokes a way of awe for our huge, stunning universe. I hope it does that for you, too.
If you happen to subscribe to Scientific American, you assist be certain that our protection is centered on significant analysis and discovery; that now we have the sources to report on the choices that threaten labs throughout the U.S.; and that we assist each budding and dealing scientists at a time when the worth of science itself too usually goes unrecognized.
That is going to be the core formulation that I’m going to study greatest though it is just one of many 4 decompositions that the authors report in their paper (Desk 1).
Discover then that the TWFE coefficient principally has 4 distinct items:
integrating over doses. The TWFE is a weighted common over the help of the remedy dosage. That makes use of the density f_D(l) to map out help over l, the remedy dosage values.
the load. There’s three items to the load. There’s the re-centering of the dose, l-E[D]. This takes a selected unit’s dosage and subtracts the imply over your complete pattern. So perhaps my dose is 0.1 however the imply 1, then the recentering can be 0.1-1 or -0.9. Discover there that the recentering introduces a adverse worth although — if you’re under the imply, that’s mechanically adverse.
variance. And final, the variance of the dose itself rescales the load.
lengthy differenced outcomes. The final piece is m(l)-m(0), the place m() is the result of curiosity.
In the present day what I need to do is pretty simple. I need to use our dataset Lu & Yu (2015), estimate two-way mounted results, report that, after which reconstruct the identical coefficient utilizing the weighted common of the differenced m(l)-m(0), the place the weights are these scaled recentered doses I simply talked about.
However first, I flipped a coin 3 times, and as soon as once more, it got here up heads twice. As that is primarily a diff-in-diff publish in the present day, and fewer so a Claude Code publish, I’m going to paywall it. However perhaps in the present day contemplate turning into a paying subscriber! However as a teaser, right here’s the video of the up to date shiny app so as to see what’s under.
A 12 months or two in the past, utilizing superior AI fashions felt costly sufficient that you just needed to suppose twice earlier than asking something. Immediately, utilizing those self same fashions feels low-cost sufficient that you just don’t even discover the associated fee.
This isn’t simply because “know-how improved” in a imprecise sense. There are particular causes behind it, and it comes right down to how AI methods spend computation. That’s what individuals imply after they speak about token economics.
Tokens: The Elementary Unit
AI doesn’t learn phrases the way in which we do. It chops textual content into smaller constructing blocks referred to as tokens.
A token isn’t all the time a full phrase. It may be a complete phrase (like apple), a part of a phrase (like un and plausible), and even only a comma.
GPT 5.2 token rely for this part of the article
Every token generated requires a specific amount of computation. So should you zoom out, the price of utilizing AI comes right down to a easy relationship:
Since AI token prices are per million tokens, the equation evaluates to:
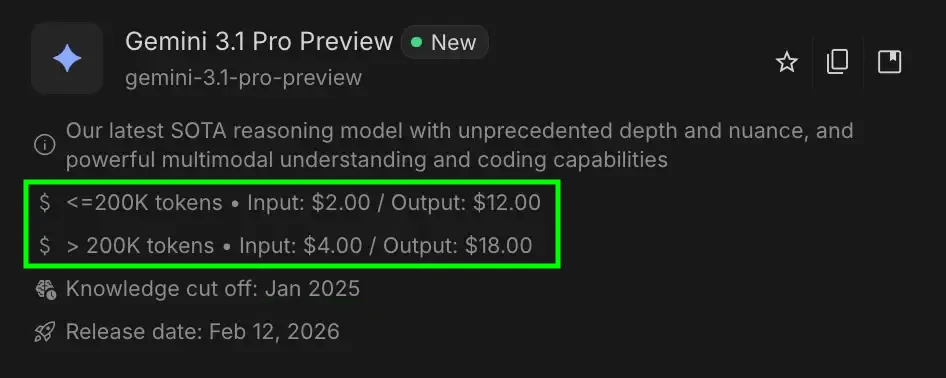
Click on right here to see how the associated fee is calculated for a mannequin
Let’s say you ship a immediate that’s 50,000 tokens (Enter Tokens) and the AI writes again 2,000 tokens (Output Tokens).
Since tokens are the foreign money of AI. In case you management tokens, you management prices.
If AI is getting cheaper, it means we’re doing considered one of two issues:
Decreasing how a lot compute every token wants (Enter/Output tokens)
Making that compute cheaper (Token value)
In actuality, we did each!
Utilizing much less compute per token
The primary wave of enhancements got here from a easy realization:
We have been utilizing extra computation than crucial.
Early fashions handled each request the identical method. Small or massive question, textual content or picture inputs, run the complete mannequin at full precision each time. That works, nevertheless it’s wasteful.
So the query grew to become: the place can we lower compute with out hurting output high quality?
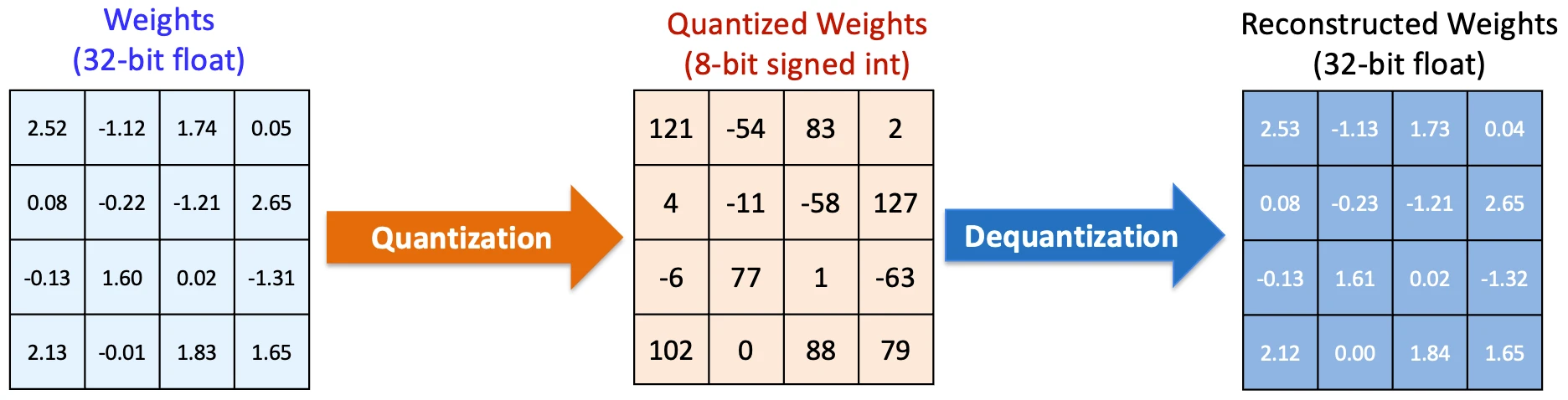
Quantization: Making every operation lighter
Probably the most direct enchancment got here from quantization. Fashions initially used high-precision numbers for calculations. Nevertheless it seems you possibly can cut back that precision considerably with out degrading efficiency usually.
As a substitute of 16-bit or 32-bit numbers, you utilize 8-bit (and even decrease). The maths stays the identical in construction, however turns into cheaper to execute.
This impact compounds shortly. Each token passes by 1000’s of such operations, so even a small discount per operation results in a significant drop in price per token.
Notice: Full-precision quantization constants (a scale and a zero level) should be saved for each block. This storage is crucial so the AI can later de-quantize the info.
MoE Structure: Not utilizing the entire mannequin each time
The following realization was much more impactful:
Perhaps we don’t want the whole mannequin to work for each response.
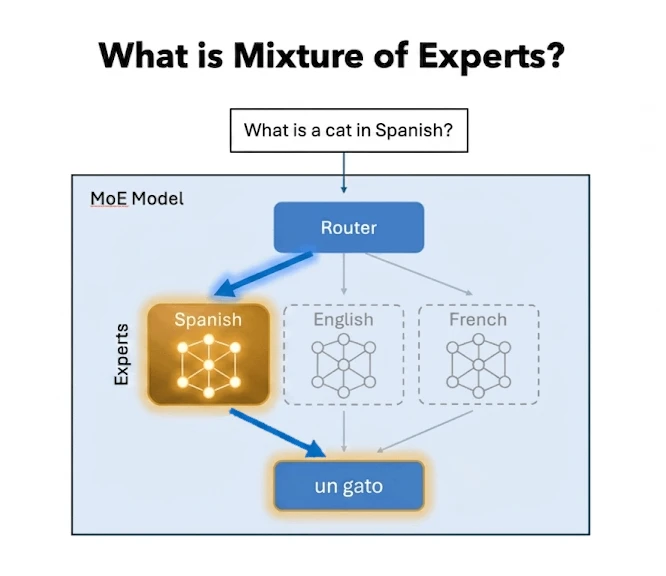
This led to architectures like Combination of Specialists (MoE).
As a substitute of 1 massive community dealing with every part, the mannequin is break up into smaller “consultants,” and only some of them are activated for a given enter. A routing mechanism decides which of them matter.
A MOE language mannequin activating solely its spanish nodes and never the entire mannequin
So the mannequin can nonetheless be massive and succesful general, however for any question, solely a fraction of it’s truly doing work.
That instantly reduces compute per token with out shrinking the mannequin’s general intelligence.
SLM: Choosing the proper mannequin measurement
Then got here a extra sensible remark.
Most real-world duties aren’t that complicated. A variety of what we ask AI to do is repetitive or easy: summarizing textual content, formatting output, answering easy questions.
That’s the place Small Language Fashions (SLMs) are available. These are lighter fashions designed to deal with easier duties effectively. In trendy methods, they usually deal with the majority of the workload, whereas bigger fashions are reserved for tougher issues.
So as a substitute of optimizing one mannequin endlessly, use a a lot smaller mannequin that matches your objective.
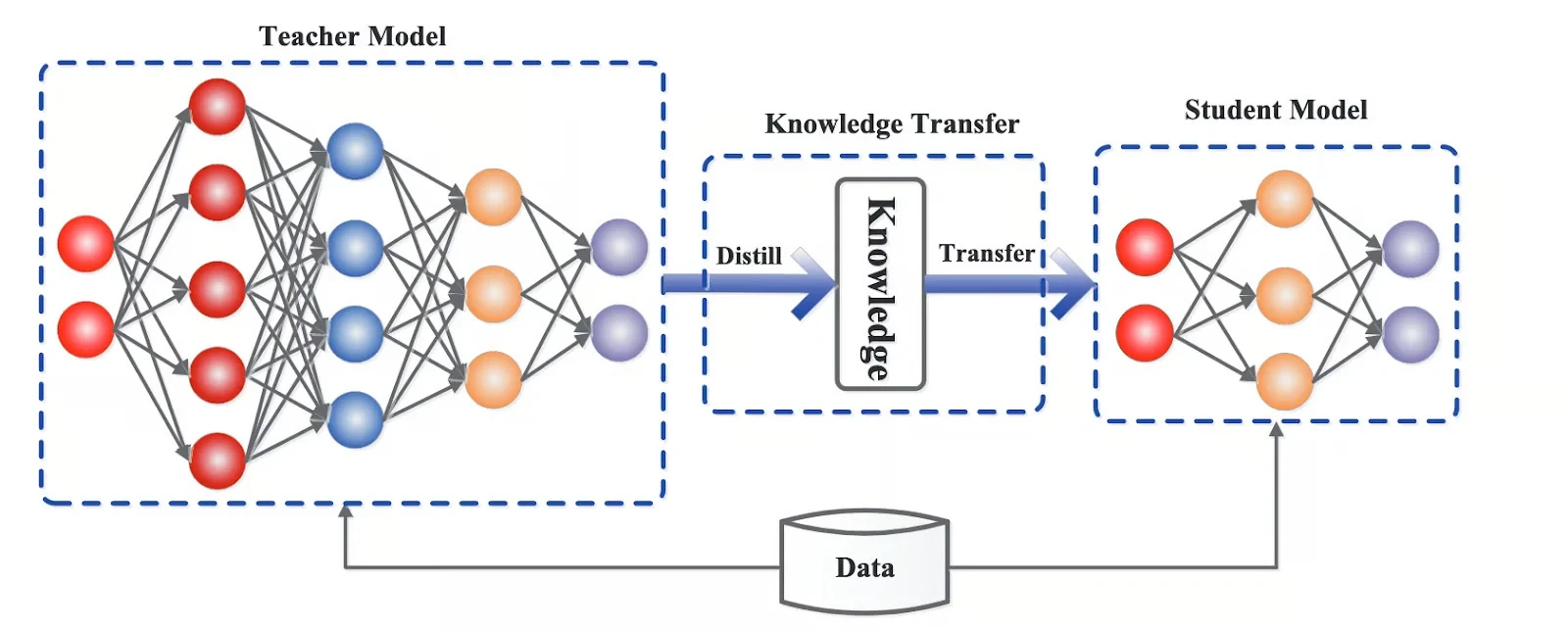
Distillation: Compressing massive fashions into smaller ones
Distillation is when a big mannequin is used to coach a smaller one, transferring its conduct in a compressed kind. The smaller mannequin received’t match the unique in each situation, however for a lot of duties, it will get surprisingly shut.
An Overview of How LLM Distillation Works
This implies you possibly can serve a less expensive mannequin whereas preserving a lot of the helpful conduct.
Once more, the theme is identical: cut back how a lot computation is required per token.
KV Caching: Avoiding repeated work
Lastly, there’s the conclusion that not each computation must be carried out from scratch.
In actual methods, inputs overlap. Conversations repeat patterns. Prompts share construction.
Fashionable implementations reap the benefits of this by caching which is reusing intermediate states from earlier computations. As a substitute of recalculating every part, the mannequin picks up from the place it left off.
This doesn’t change the mannequin in any respect. It simply removes redundant work.
Notice: There are trendy caching strategies like TurboQuant which presents excessive compression in KV caching method. Resulting in even larger financial savings.
Making compute itself cheaper
As soon as the quantity of compute per token was diminished, the subsequent step was apparent:
Make the remaining compute cheaper to run.
Executing the identical mannequin extra effectively
A variety of progress right here comes from optimizing inference itself. Even with the identical mannequin, the way you execute it issues. Enhancements in batching, reminiscence entry, and parallelization imply that the identical computation can now be carried out sooner and with fewer sources.
You’ll be able to see this in observe with fashions like GPT-4 Turbo or Claude 4 Haiku. These are solely new intelligence layers that are engineered to be sooner and cheaper to run in comparison with earlier variations.
That is what usually exhibits up as “optimized” or “turbo” variants. The intelligence hasn’t modified: the execution has merely grow to be tighter and extra environment friendly.
{Hardware} that amplifies all of this
All these enhancements profit from {hardware} that’s designed for this sort of workload.
Corporations like NVIDIA and Google have constructed chips particularly optimized for the sorts of operations AI fashions depend on, particularly large-scale matrix multiplications.
These chips are higher at:
dealing with lower-precision computations (vital for quantization)
shifting knowledge effectively
processing many operations in parallel
{Hardware} doesn’t cut back prices by itself. Nevertheless it makes each different optimization more practical.
Placing all of it collectively
Early AI methods have been wasteful. Each token used the complete mannequin, full precision, each time.
Then issues shifted. We began chopping pointless work:
lighter operations
partial mannequin utilization
smaller fashions for easier duties
avoiding recomputation
As soon as the workload shrank, the subsequent step was making it cheaper to run:
higher execution
smarter batching
{hardware} constructed for these precise operations.
That’s why prices dropped sooner than anticipated.
There isn’t only a single issue main this modification. As a substitute it’s a regular shift towards utilizing solely the compute that’s truly wanted.
Often Requested Questions
Q1. What are tokens in AI and why do they matter?
A. Tokens are chunks of textual content AI processes. Extra tokens imply extra computation, instantly impacting price and efficiency.
Q2. Why is AI getting cheaper over time?
A. AI is cheaper as a result of methods cut back compute per token and make computation extra environment friendly by optimization strategies and higher {hardware}.
Q3. How is AI price calculated utilizing tokens?
A. AI price is predicated on enter and output tokens, priced per million tokens, combining utilization and per-token charges.
I focus on reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, knowledge evaluation, and knowledge retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and revel in expert-curated content material.
What are the Challenges of SAP EWM Implementation & Deal with Them?
Most implementation dangers are identified upfront. The distinction lies in preparation. A well-planned SAP EWM doesn’t take away challenges. It stops them from changing into crises.
Problem 1: Legacy System Integration
Legacy ERP and warehouse programs weren’t constructed for real-time integration. Even decentralized situations of present SAP programs may pose a problem and result in knowledge gaps and course of breakdowns. Because of this, knowledge falls out of sync, and as soon as that occurs, processes start to fail.
Response: Outline integration structure early. Use middleware to standardize communication and guarantee knowledge strikes between programs with out handbook intervention.
Problem 2: Knowledge High quality Points and inconsistent knowledge result in incorrect process execution.
Migration of giant quantities of information has its personal set of issues. Errors in grasp knowledge, equivalent to bin areas or inventory portions, floor instantly as soon as the system goes dwell. Mapping previous knowledge constructions to the usual format required by SAP and making certain that there’s seamless knowledge move is usually a problem.
Response: Set up knowledge governance.
Run a number of validation cycles earlier than migration to catch and proper discrepancies earlier than they attain the warehouse flooring.
Problem 3: Consumer Resistance
Customers revert to handbook processes when the system will get of their approach. Used to doing it manually, they may see any glitch or slowdown as a hindrance quite than as an answer.
Response: Practice utilizing actual workflows. Guarantee interfaces help fast execution so customers see the system as an support, not an impediment.
Problem 4: Operational Disruption Throughout Transition
Go-live impacts each day operations if not managed. Even groups which might be well-prepared encounter unexpected obstacles. This might particularly occur when dwell volumes are launched to a brand new system for the primary time.
Response: Implement a gradual rollout. Maintain contingency plans in place, well-prepared groups, and oversee implementation in actual time to determine and tackle issues earlier than they worsen.
How the Proper SAP Companion Drives Execution Success
Implementation succeeds when system design precisely displays how operations really run. The best companion gives group and accountability in these methods:
Confirmed supply frameworks
Deep understanding of warehouse processes
Integration experience throughout programs
Sturdy change administration functionality
They determine gaps early. They resolve them earlier than they have an effect on execution. With out this, implementation turns into reactive. With it, execution stays managed from design by means of deployment.
Unlock True Potential of EWM Public Cloud Align Your SAP EWM Implementation With Your Enterprise Targets
FAQs
Q. How lengthy does SAP EWM implementation take?
A. The warehouse’s complexity and degree of integration affect deadlines. Sometimes, mid-sized initiatives require six to 9 months to finish. In depth deployments throughout a number of websites might require over a yr. Delays are often attributed to knowledge preparedness and course of synchronization quite than system configuration.
Q. How do you select between embedded and decentralized EWM?
A. Embedded EWM operates inside SAP S/4HANA and is good for enterprises merging their programs. Decentralized EWM brings flexibility the place complexity lives. Select it provided that it matches your long-term structure.
Q. How does SAP EWM enhance stock accuracy?
A. It screens inventory on the bin degree and logs every motion in actual time. This implies no estimation or ready for each day summaries. The end result? What the system exhibits is what’s really on the shelf. It removes the same old suspects behind stock errors, delayed updates, and handbook reconciliation. In batch-based programs, errors sit quietly till somebody goes trying. In SAP EWM, they don’t get that likelihood.
Q. What are the primary dangers throughout implementation?
A. The largest dangers are surprisingly unusual: poor knowledge high quality, weak course of design, and half-baked testing. Simply the sort of fundamentals folks assume will “kind themselves out.”
In truth, they don’t.
These points present up quick after go-live, and after they do, operations really feel it instantly. What appeared effective on paper all of a sudden slows down the warehouse flooring. Fixing them early shouldn’t be non-obligatory. It’s the distinction between a clean rollout and each day firefighting.
Q. Can SAP EWM combine with warehouse automation programs?
A. Sure. It connects with conveyors, automated storage options, and robotics by way of specified interfaces. This allows seamless coordination between system-driven processes and bodily warehouse exercise.
Q. How can organizations guarantee person adoption?
A. Adoption is dependent upon usability and relevance. Coaching should replicate actual duties. Customers ought to observe in managed environments earlier than go-live. Publish-deployment monitoring ensures that system processes are persistently adopted.
How Fingent Can Assist
Fingentapproaches SAP EWM implementation with a transparent deal with execution.
Structured supply methodology
Deep SAP and provide chain experience
Sturdy integration capabilities
Trade-aligned options
Our goal is easy: Ship steady programs. Allow predictable execution.
Warehouse operations don’t fail all of a sudden. They degrade over time when management is weak. SAP EWM introduces construction, visibility, and execution self-discipline. However the consequence is dependent upon how it’s applied.
Our well-executed SAP EWM implementation creates steady, scalable warehouse operations that maintain underneath strain.
Allow us to show you how to strengthen execution, not take up inefficiency.
The rising demand for synthetic intelligence (AI) has basically shifted the trendy enterprise period. Present information reveals that 69% of execs consider their jobs are being impacted by know-how, particularly AI.
Regardless of this disruption, optimism stays remarkably excessive, with 78% of execs feeling constructive in regards to the potential influence of AI on their careers.
Nevertheless, as investments in generative and predictive fashions skyrocket, organizations face a essential problem: separating tangible monetary returns from technological hype.
To really capitalize on these instruments, companies should transition from experimental pilots to sustainable, ROI-driven ecosystems. Let’s discover deeper:
Summarize this text with ChatGPT Get key takeaways & ask questions
Why AI ROI Is So Laborious to Measure?
Measuring the Return on Funding (ROI) for synthetic intelligence tasks is complicated in comparison with conventional software program deployments.
Not like commonplace IT upgrades, AI programs evolve, be taught, and infrequently influence the group in methods that aren’t instantly quantifiable.
Intangible Advantages vs. Direct Income Impression: Conventional software program supplies clear operational outputs. AI, nonetheless, usually drives intangible advantages like enhanced buyer satisfaction, improved worker morale, or higher strategic forecasting. Translating a 15% enhance in buyer sentiment right into a direct greenback quantity is inherently troublesome.
Lengthy Gestation Intervals of AI Initiatives: AI options require vital time for information gathering, mannequin coaching, validation, and steady fine-tuning. Optimistic ROI is never quick. Stakeholders should be ready for an extended runway earlier than the algorithm begins to generate measurable worth.
Cross-Practical Dependencies: A profitable AI deployment isn’t siloed. It requires seamless collaboration between information engineers, IT infrastructure groups, compliance officers, and enterprise unit leaders. If one dependency fails, your complete undertaking’s ROI suffers.
Hidden Prices: The sticker worth of an AI software is simply a fraction of the Complete Value of Possession (TCO). Hidden bills rapidly erode ROI: – Information cleansing and preparation: Algorithms require pristine information. Getting ready this information is very labor-intensive. – Infrastructure and cloud prices: Coaching machine studying fashions, particularly Massive Language Fashions (LLMs), calls for large computational energy and costly cloud storage. – Expertise acquisition: Hiring extremely specialised Information Scientists and ML Engineers drives up undertaking prices considerably.
When evaluating vendor pitches or inner undertaking proposals, leaders should preserve a wholesome skepticism. Inflated claims usually obscure the true enterprise worth of an AI implementation.
Over-Reliance on Vainness Metrics: Distributors steadily spotlight metrics like mannequin accuracy (e.g., “99% accuracy price”) or processing pace. Whereas technically spectacular, excessive accuracy doesn’t robotically equate to price financial savings or income technology.
No Baseline Comparability: A declare that an AI software saves 100 hours every week is meaningless if the group doesn’t know what number of hours had been beforehand spent on the duty or how the saved hours are being utilized. An absence of rigorous “earlier than vs. after” information is a serious purple flag.
Ignoring Operational Prices: An AI answer would possibly enhance gross sales income by 5%, but when the cloud computing prices required to run the mannequin devour 6% of income, the web ROI is damaging. At all times search for claims that account for steady operational overhead.
“Pilot Success” Projected as Enterprise-Scale ROI: A mannequin that works completely on a clear, localized dataset usually breaks down when uncovered to the messy, unstructured information of a whole enterprise. Scaling success isn’t completely linear.
Lack of Clear Enterprise KPIs: If an AI initiative can’t be tied again to a core enterprise goal, similar to churn discount or stock optimization, it’s possible an arrogance undertaking. For instance, utilizing AI to automate reporting ought to immediately tie to decreased labor prices or quicker choice cycles.
To carefully audit these claims, professionals ought to perceive the technical lifecycle of those instruments, a competency lined completely in programs defining AI Product Supervisor Roles, Abilities, and Duties.
Key Metrics That Really Matter
To chop via the noise, organizations should categorize their AI evaluations into clear, measurable buckets that align immediately with company goals.
Monetary Metrics:
Income Uplift: Will increase in cross-selling alternatives, increased conversion charges, and optimized pricing methods.
ROI Components: The last word benchmark stays ROI = (Web Achieve from Funding – Value of Funding) / Value of Funding.
Value Financial savings: Discount in human capital expenditures, lowered operational overhead, and decreased {hardware} prices.
Operational Metrics:
Course of Effectivity Enhancements: Measuring the discount of bottlenecks in workflows.
Time Saved: Quantifying the precise hours reclaimed from handbook, repetitive duties.
Error Discount: Monitoring the lower in human errors, notably in compliance, information entry, and manufacturing.
Strategic Metrics:
Buyer Expertise Enchancment: Monitoring Web Promoter Scores (NPS) and buyer retention charges pre- and post-implementation.
To know how these strategic metrics apply to consumer interactions, the AI and Buyer Journey Necessities course provides wonderful ideas and foundational information.
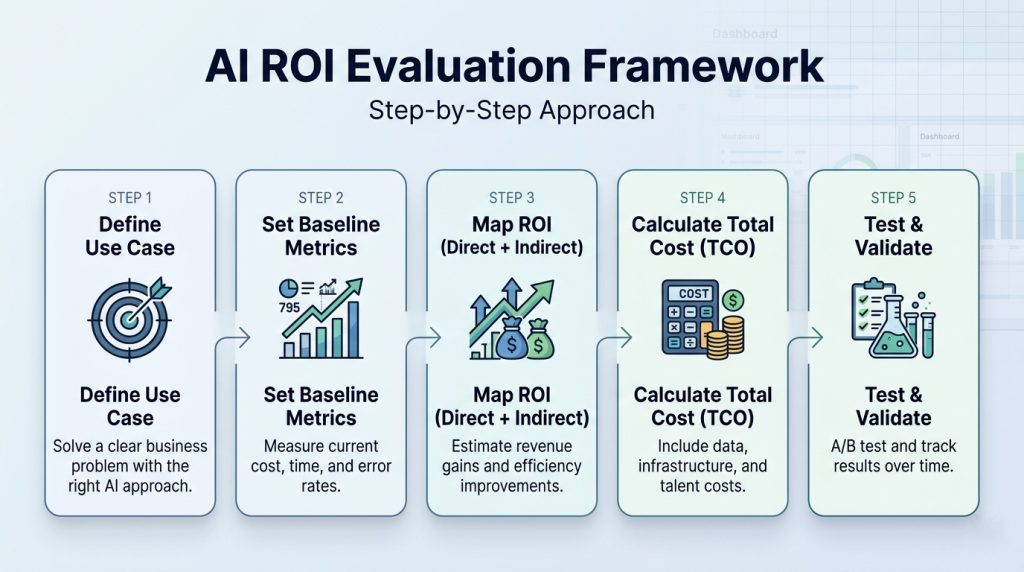
Framework to Consider AI ROI (Step-by-Step)
To successfully measure the monetary and operational returns of your synthetic intelligence initiatives, it’s essential to observe a step-by-step analysis framework.
Step 1: Outline the Enterprise Drawback and AI Use Case Clearly
Earlier than investing in any know-how, it’s essential to isolate a extremely particular enterprise bottleneck. Keep away from the lure of deploying Massive Language Fashions (LLMs) or neural networks merely to look progressive.
Conduct a Wants Evaluation: Establish in case your drawback requires predictive analytics (forecasting gross sales), pure language processing (buyer assist), or laptop imaginative and prescient (high quality management).
Map Capabilities to Goals: Guarantee the chosen algorithm immediately addresses the remoted bottleneck. For those who battle to translate overarching enterprise objectives into actionable technical necessities, you would possibly select the flawed AI mannequin in your operations.
Decide Feasibility: Assess whether or not you could have the required information high quality to assist this particular use case earlier than continuing to the following step.
Step 2: Set up Quantitative Baseline Metrics
You can not calculate an correct return on funding and not using a exact understanding of your present operational prices and efficiency ranges.
Audit Present Workflows: Doc the precise human hours at the moment spent on the processes you propose to optimize. That is essential earlier than automating routine duties with AI so that you’ve a definitive “earlier than” and “after” snapshot.
Quantify Error Charges: Document the present frequency of handbook errors, buyer churn charges, or manufacturing defects.
Set the Benchmark: Set up these pre-AI figures as your definitive baseline. Any future efficiency generated by the AI mannequin shall be subtracted from this baseline to calculate your absolute achieve.
Step 3: Map Direct vs. Oblique ROI Trajectories
AI generates worth throughout a number of spectrums. You should categorize these returns to construct a complete monetary case.
Forecast Direct ROI: Calculate the projected arduous monetary positive factors. This consists of anticipated income uplift from AI-driven cross-selling and direct price reductions from decreased software program licensing or handbook labor necessities.
Forecast Oblique ROI: Assign proxy values to intangible advantages. Estimate the monetary influence of improved worker bandwidth, accelerated strategic decision-making, and enhanced buyer satisfaction scores (CSAT).
Step 4: Calculate the Complete Complete Value of Possession (TCO)
The preliminary buy or licensing worth of an AI software is simply a fraction of its true price. You should meticulously calculate the TCO to forestall hidden bills from destroying your ROI.
Compute Information Prices: Price range for the intensive hours required for information extraction, cleansing, and labeling. AI fashions require pristine information pipelines to perform.
Calculate Infrastructure Overhead: Issue within the ongoing prices of cloud storage, API tokens, and the extraordinary GPU compute energy required to coach and run machine studying fashions.
Account for Expertise Acquisition: Issue within the premium salaries required to rent Information Scientists, ML Ops Engineers, and specialised analysts wanted to take care of the system.
Step 5: Execute Structured Testing and Outline Timeframes
By no means deploy an AI mannequin enterprise-wide with out rigorous, remoted testing to validate your ROI projections.
Implement A/B Testing: Run your new AI mannequin (the variant) concurrently towards your conventional human workflow (the management). Evaluate the output high quality and pace immediately.
Set up a Real looking Runway: Acknowledge that machine studying fashions require a “burn-in” interval. Set distinct timelines for whenever you anticipate short-term operational efficiencies versus long-term strategic income positive factors.
Professionals are already adapting to those workflows; 80% of execs report that they use GenAI to be taught new abilities, with 60% saying they use it of their work ‘all the time’ or ‘steadily’.
To guide this cost, the Duke Chief Synthetic Intelligence Officer Program is a premier alternative. This program equips leaders with actionable frameworks to establish high-impact AI alternatives, handle complicated digital transformations, and navigate the moral and operational challenges of scaling AI ecosystems globally.
Moreover, participating in specialised coaching like AI for Enterprise Innovation: From GenAI to PoCs ensures your framework transitions seamlessly from idea to viable product.
Case Examples: Actual vs Inflated AI ROI
Analyzing sensible purposes helps make clear the boundaries between real looking returns and inflated projections.
Instance 1: Fraud Detection System (Clear ROI)
A monetary companies agency deploys a machine learning-based fraud detection system. Pre-implementation fraud losses are documented at $4.2M yearly. Publish-deployment, losses drop to $1.1M. With a $600K TCO, the web ROI is measurable, attributable, and defensible. That is textbook AI ROI: clear baseline, direct price saving, documented causal hyperlink.
Instance 2: Chatbot Implementation (Combined ROI)
A telecom operator deploys a conversational AI chatbot to deflect inbound assist calls. Pilot metrics present 65% deflection. Nevertheless, at enterprise scale, deflection falls to 38% attributable to question complexity and integration gaps. Unaccounted escalation prices and buyer dissatisfaction partially erode projected financial savings. ROI is constructive however considerably overstated within the enterprise case.
Instance 3: AI Personalization (Lengthy-Time period ROI, More durable to Measure)
A retail model makes use of a advice engine to personalize digital experiences. Direct attribution is difficult by multi-touch buyer journeys and seasonality. ROI emerges over 18–24 months via buyer retention uplift and common order worth enhance. It is a authentic however illiquid funding, one which requires persistence and strong attribution modeling to judge.
What separates the primary and third examples shouldn’t be know-how; it’s the rigor of the enterprise case.
In case your workforce is on the stage of transferring from thought to proof of idea, the premium AI for Enterprise Innovation: From GenAI to POCs course from Nice Studying supplies a structured strategy to validating AI use instances earlier than full funding, lowering the danger of committing sources to initiatives that can’t reveal clear P&L influence at scale.
Constructing an AI-First But ROI-Pushed Tradition
Know-how alone doesn’t ship AI ROI. The organizational atmosphere should be intentionally formed to transform AI functionality into enterprise outcomes.
1. Educating Management Past Buzzwords
Executives who perceive solely the surface-level promise of AI, with out greedy ideas like mannequin bias, information governance, and inference prices, are poorly geared up to sponsor or consider AI applications. The core AI abilities that leaders should grasp signify the minimal viable fluency for sponsoring high-stakes AI investments that result in higher progress and better ROI.
2. Setting Real looking Expectations
AI shouldn’t be a silver bullet. Setting over-optimistic timelines or ROI projections is a major driver of stakeholder disillusionment. Construct ROI instances conservatively and revisit them quarterly.
3. Investing within the Proper Expertise
Sustainable AI ROI requires a human capital technique. Organizations should put money into information scientists, ML engineers, MLOps practitioners, and AI product managers, roles which can be in rising demand globally.
The rising demand for AI expertise continues to outpace provide, making in-house upskilling a aggressive benefit. Furthermore, cloud infrastructure literacy can also be turning into a non-negotiable for leaders overseeing AI budgets.
As AWS continues to dominate enterprise AI infrastructure, the premium AWS Generative AI for Leaders course from Nice Studying equips decision-makers with the vocabulary, frameworks, and value fashions wanted to judge cloud-based AI investments intelligently, with out being wholly depending on technical groups for monetary oversight.
4. Creating Suggestions Loops
Set up steady suggestions mechanisms between AI system outputs and downstream enterprise KPIs. Mannequin efficiency dashboards ought to be reviewed alongside P&L information, not in isolation inside a technical workforce.
To champion this cultural transformation, the Synthetic Intelligence Course for Managers & Leaders is very advisable. This complete course empowers non-technical managers to confidently consider AI vendor proposals, spearhead data-driven initiatives, and align technical groups with overarching enterprise objectives, guaranteeing each AI undertaking has a direct line of sight to profitability.
Organizations critical about AI ROI measurement ought to deploy the next strategies:
A/B Testing for AI Fashions: Randomized managed experiments that evaluate AI-assisted outcomes towards a management group set up causal attribution, the gold commonplace for ROI measurement.
KPI Dashboards: Centralized dashboards that align AI operational metrics (prediction accuracy, throughput) with enterprise KPIs (price per unit, income per buyer) in actual time.
Attribution Fashions: Multi-touch attribution fashions that distribute enterprise worth throughout the AI system, human decision-making, and exterior elements, stopping each over-crediting and under-crediting AI.
Value-Profit Monitoring Methods: Steady monitoring of TCO towards realized advantages, up to date at the very least quarterly.
Conclusion
Evaluating AI ROI and figuring out sustainable implementation methods requires organizations to look previous the business hype and focus strictly on tangible enterprise worth.
By establishing clear baseline metrics, acknowledging the overall price of possession, and demanding rigorous “earlier than and after” information, companies can safeguard their investments.
In the end, transitioning from remoted AI experiments to enterprise-wide, ROI-positive ecosystems calls for a tradition that values steady studying, strategic persistence, and relentless monetary accountability.
Apple has launched out-of-band safety updates for iPhone and iPad gadgets to repair a Notification Companies flaw that would permit notifications marked for deletion to stay saved on the gadget.
The bug, tracked as CVE-2026-28950, was mounted on April 22, 2026, in iOS 26.4.2 and iPadOS 26.4.2 and in iOS 18.7.8 and iPadOS 18.7.8.
“Notifications marked for deletion might be unexpectedly retained on the gadget,” reads the Apple safety bulletin.
Apple says the flaw was mounted by improved knowledge redaction however supplied no further info.
Nevertheless, the corporate has not stated whether or not the flaw was exploited in assaults or why it was addressed exterior the traditional safety replace cycle. Apple additionally didn’t share technical particulars about how lengthy notification knowledge remained on the gadget or the way it may probably be recovered.
Whereas Apple has not defined why it launched this emergency replace, latest reporting by 404 Media described how the FBI recovered copies of Sign messages from a suspect’s iPhone, even after that they had been deleted within the app.
In response to trial notes revealed by supporters of the defendants, the recovered knowledge didn’t come from Sign’s encrypted message retailer, however as an alternative from iPhone’s notification storage.
“Messages had been recovered from Sharp’s cellphone by Apple’s inner notification storage — Sign had been eliminated, however incoming notifications had been preserved in inner reminiscence,” the notes state.
404 additionally reported the notification knowledge was retained even after Sign was deleted from the gadget.
Apple’s advisory doesn’t reference the case, however its description of notifications being retained on the gadget carefully aligns with the kind of knowledge persistence described in that report.
Customers are suggested to put in the most recent updates as quickly as doable to forestall deleted notification knowledge from being unexpectedly retained on their gadgets.
Moreover, it’s doable to forestall Sign message content material from being retained within the iOS notification knowledge storage by going to Sign Settings > Notifications> Notification content material and setting Present to “Title Solely” or “No Title or Content material”.
BleepingComputer contacted Apple with questions on these updates, however has not but obtained a response.
AI chained 4 zero-days into one exploit that bypassed each renderer and OS sandboxes. A wave of latest exploits is coming.
On the Autonomous Validation Summit (Might 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls maintain, and closes the remediation loop.
Researchers at Iowa State College have now collected the memorial information of 505 individuals who died with CFS/ME to color an image of what life is like for hundreds of thousands of sufferers worldwide.
The group’s hope is to achieve “a deeper understanding of the lived experiences and deaths of these with ME/CFS.”
In complete, 4 main themes emerged from the phrases of household and mates, which had been publicly out there from the Nationwide Continual Fatigue and Immune Dysfunction Syndrome Basis memorial web page.
The themes had been: systemic neglect and institutional failure, scientific neglect and failure, social disconnection, and private burden.
The deceased people didn’t essentially die from CFS/ME, however the illness appeared to have a big influence on their high quality of life, whether or not it’s by means of practical impairments, monetary stress, or psychological well being.
Some household and mates additionally recounted the influence the illness had on their liked one’s loss of life.
“Some shared hope and remembrance of the progress that the deceased people sought,” write kinesiologist Zoe Sirotiak and psychologist Hailey Amro of their overview, “whereas others shared anguish, grief, and anger on the programs that they perceived as contributing elements to the lived expertise and infrequently loss of life of people with ME/CFS.”
Nonetheless, analysis on CFS/ME isn’t proportionate to what number of sufferers are impacted or how a lot their lives are affected. To be commensurate with the true burden of the illness, specialists recommend the US Nationwide Institutes of Well being (NIH) would want to extend analysis funding by 40-fold.
Unsurprisingly, hopelessness and frustration over a sheer lack of sources had been widespread feelings raised within the current overview.
The memorial entries reported that sufferers confronted substantial institutional obstacles to acknowledgment and lacked acceptable monetary funding. Additionally they described struggles with insufficient fee from insurance coverage corporations, in addition to acquiring authorized incapacity standing.
Isolation and lack of friendships had been widespread challenges. Memorial entries continuously described a scarcity of competent well being care and dismissal by members of the family and shut acquaintances.
“The substantial challenges confronted by people with ME/CFS have been recommended to affect suicide danger, and our evaluation helps this conclusion,” Sirotiak and Amro write.
“The entries on the memorial record illustrated the contexts through which people died by suicide, typically noting contributing elements corresponding to hopelessness, ache, social isolation, lack of independence, and dismissal or poor therapy by healthcare suppliers.”
As an instance the immense influence the illness can have on somebody’s life, Sirotiak and Amro finish their overview reflecting on one father’s phrases:
“Her father … was quoted saying his daughter lived with ‘intractable and unrelenting ache’ and, although he definitely was not blissful to see his solely baby die, ‘There are issues on this world worse than loss of life.'”
Organizations are racing to deploy generative AI fashions into manufacturing to energy clever assistants, code technology instruments, content material engines, and customer-facing purposes. However deploying these fashions to manufacturing stays a weeks-long means of navigating GPU configurations, optimization strategies, and handbook benchmarking, delaying the worth these fashions are constructed to ship.
In the present day, Amazon SageMaker AI helps optimized generative AI inference suggestions. By delivering validated, optimum deployment configurations with efficiency metrics, Amazon SageMaker AI retains your mannequin builders centered on constructing correct fashions, not managing infrastructure.
We evaluated a number of benchmarking instruments and selected NVIDIA AIPerf, a modular element of NVIDIA Dynamo, as a result of it exposes detailed, constant metrics and helps numerous workloads out of the field. Its CLI, concurrency controls, and dataset choices give us the pliability to iterate shortly and check throughout totally different situations with minimal setup.
“With the combination of modular elements of the open supply NVIDIA Dynamo distributed inference framework immediately into Amazon SageMaker AI, AWS is making it simpler for enterprises to deploy generative AI fashions with confidence. AWS has been instrumental in advancing AIPerf by way of deep collaboration and technical contributions. The combination of NVIDIA AIPerf demonstrates how standardized benchmarking can eradicate weeks of handbook testing and ship validated, deployment-ready configurations to finish customers.”
– Eliuth Triana, Developer Relations Supervisor of NVIDIA.
The problem: From mannequin to manufacturing takes weeks
Deploying fashions at scale requires manufacturing inference endpoints that fulfill clear efficiency targets, whether or not that may be a latency service degree settlement (SLA), a throughput goal, or a value ceiling. Attaining that requires discovering the fitting mixture of GPU occasion kind, serving container, parallelism technique, and optimization strategies, all tuned to the precise mannequin and site visitors patterns.
Determine 1: The three core challenges groups face when deploying generative AI fashions to manufacturing
The choice house is impossibly massive. A single deployment includes selecting from over a dozen GPU occasion varieties, a number of serving containers, varied parallelism levels, and a rising set of optimization strategies similar to speculative decoding. These all work together with one another, and there’s no validated steerage to slender the search. The one method to discover the fitting configuration is to check, and that’s the place the true value begins. Groups provision cases, deploy the mannequin, run load checks, analyze outcomes, and repeat. This cycle takes two to a few weeks per mannequin and requires experience in GPU infrastructure, serving frameworks, and efficiency optimization that almost all groups shouldn’t have in-house.
Many groups begin manually: they choose a number of occasion varieties, deploy the mannequin, run load checks, examine latency, throughput, and value, then repeat. Extra mature groups usually script elements of the method utilizing benchmarking instruments, deployment templates, or steady integration and steady supply (CI/CD) pipelines. Even when workloads are scripted, groups nonetheless face important work. They should check and validate their scripts, select which configurations to benchmark, arrange the benchmarking surroundings, interpret the outcomes, and stability trade-offs between latency, throughput, and value.
Groups are sometimes left making high-stakes infrastructure selections with out understanding whether or not a greater, less expensive choice exists. They default to over-provisioning, selecting dearer GPU infrastructure than they want and operating configurations that don’t totally use the compute sources they’re paying for. The danger of under-performing in manufacturing is much worse than overspending on compute. The result’s wasted GPU spend that compounds with each mannequin deployed and each month the endpoint runs.
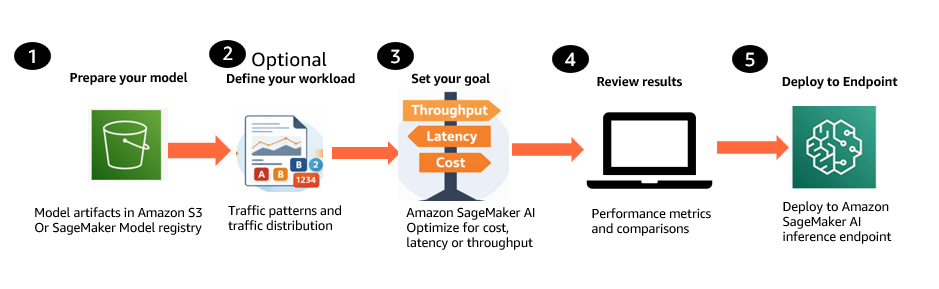
How optimized generative AI inference suggestions work
You deliver your personal generative AI mannequin, outline your anticipated site visitors patterns, and specify a single efficiency aim: optimize for value, decrease latency, or maximize throughput. From there, SageMaker AI takes over in three phases.
Stage 1: Slim the configuration house
SageMaker AI analyzes the mannequin’s structure, measurement, and reminiscence necessities to establish the occasion varieties and parallelism methods that may realistically meet your aim. As a substitute of testing each attainable mixture, it narrows the search to the configurations value evaluating, throughout the occasion varieties you choose (as much as three).
Stage 2: Apply goal-aligned optimizations
Based mostly in your chosen efficiency aim, SageMaker AI applies the optimization strategies to every candidate configuration similar to:
For throughput targets, it trains speculative decoding fashions (similar to EAGLE 3.0) that permit the mannequin to generate a number of tokens per ahead move, considerably rising tokens per second.
For latency targets, it tunes compute kernels to cut back per-token processing time, reducing time to first token.
Tensor parallelism is utilized based mostly on mannequin measurement and occasion functionality, distributing the mannequin throughout obtainable GPUs to deal with fashions that exceed single-GPU reminiscence.
You do not want to know which approach is correct to your aim. SageMaker AI selects and applies the optimizations routinely.
Stage 3: Benchmark and return ranked suggestions
SageMaker AI benchmarks every optimized configuration on actual GPU infrastructure utilizing NVIDIA AIPerf, measuring time to first token, inter-token latency, P50/P90/P99 request latency, throughput, and value. The result’s a set of ranked, deployment-ready suggestions with validated metrics for every configuration and occasion kind. Here’s what the workflow appears to be like like out of your perspective utilizing SageMaker AI APIs.
Determine 2: Generative AI inference suggestions workflow
Put together your mannequin. Carry your generative AI mannequin from Amazon Easy Storage Service (Amazon S3) or the SageMaker Mannequin Registry, together with Hugging Face checkpoint codecs with SafeTensor weights, base fashions, and customized or fine-tuned fashions skilled by yourself information.
Outline your workload (non-obligatory). Describe anticipated site visitors patterns, together with enter and output token distributions and concurrency ranges. You possibly can present these inline or use a consultant dataset from Amazon S3.
Set your optimization aim. Select a single goal: optimize for value, decrease latency, or maximize throughput. Choose as much as three occasion varieties to check.
Evaluation ranked suggestions. SageMaker AI returns deployment-ready configurations with validated metrics similar to Time to First Token, inter-token latency, P50/P90/P99 request latency, throughput, and value projections. Evaluate the suggestions and choose one of the best match.
Deploy the chosen configuration. Deploy the chosen configuration to a SageMaker inference endpoint programmatically by way of the API.
Further choices: You may as well benchmark current manufacturing endpoints to validate present efficiency or examine them in opposition to new configurations. SageMaker AI can use current machine studying (ML) Reservations (Versatile Coaching Plans) at no extra compute value, or use on-demand compute provisioned routinely.
Pricing
There isn’t a extra prices for producing optimized generative AI inference suggestions. Clients incur commonplace compute prices for the optimization jobs that generate optimized configurations and for the endpoints provisioned throughout benchmarking. Clients with current ML Reservations (Versatile Coaching Plans) can run benchmarking on their reserved capability at no extra value, that means the one value is the optimization job itself.
Getting began with optimized generative AI inference suggestions requires just a few API calls with SageMaker AI.
Each suggestion from SageMaker AI is grounded in actual measurements, not estimates or simulations. Beneath the hood, SageMaker AI benchmarks each configuration on actual GPU infrastructure utilizing NVIDIA AIPerf, an open-source benchmarking instrument that measures key inference metrics together with time to first token, inter-token latency, throughput, and requests per second.
AWS has contributed to AIPerf to strengthen the statistical basis of benchmarking outcomes. These contributions embody multi-run confidence reporting, enabling you to measure variance throughout repeated benchmark trials and quantify consequence high quality with statistically grounded confidence intervals. This strikes you past fragile single-run numbers towards benchmark outcomes you’ll be able to belief when making selections about mannequin choice, infrastructure sizing, and efficiency regressions. AWS additionally contributed adaptive convergence and early stopping, permitting benchmarks to cease as soon as metrics have stabilized as a substitute of all the time operating a hard and fast variety of trials. This implies decrease benchmarking value and sooner time to outcomes with out sacrificing rigor. For the broader inference neighborhood, it raises the standard of benchmarking methodology by specializing in repeatability, statistical confidence, and distribution-aware evaluation quite than headline numbers from a single trial.
Optimizations in motion
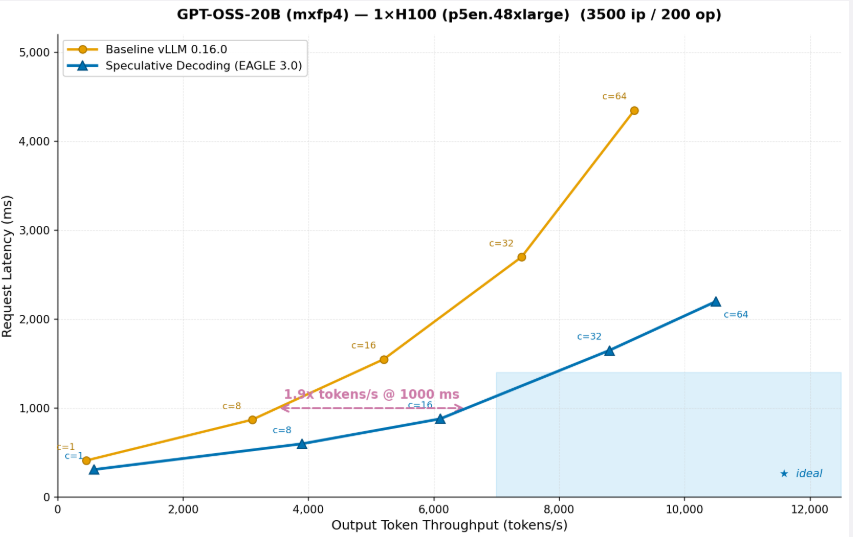
To see what these goal-aligned optimizations seem like in follow, take into account an actual instance. A buyer deploying GPT-OSS-20B on a single ml.p5en.48xlarge (H100) occasion selects maximize throughput as their efficiency aim. SageMaker AI identifies speculative decoding as the fitting optimization for this aim, trains an EAGLE 3.0 draft mannequin, applies it to the serving configuration, and benchmarks each the baseline and the optimized configuration on actual GPU infrastructure.
Determine 3: GPT-OSS-20B (mxfp4) on 1x H100 (p5en.48xlarge) (3500 ip / 200 op)
The graph reveals that after operating throughput optimization on the OSS-20B mannequin, the identical occasion can serve 2x extra tokens on the identical request latency. After throughput optimization, the identical occasion delivers 2x extra tokens/s at 1,000ms latency means you’ll be able to serve twice as many customers on the identical {hardware}, successfully chopping inference value per token in half. That is precisely the form of optimization that SageMaker AI applies routinely when you choose a throughput aim. You do not want to know that speculative decoding is the fitting approach, or the way to practice a draft mannequin, or the way to configure it to your particular mannequin and {hardware}. SageMaker AI handles it finish to finish and returns the validated outcomes as a part of the ranked suggestions.
Buyer worth
Value effectivity and transparency: Clear price-performance comparisons throughout occasion sorts of your selection allow right-sizing as a substitute of defaulting to the costliest choice. As a substitute of over-provisioning since you can’t afford to danger under-performing, you’ll be able to choose the configuration that delivers the efficiency you want on the proper value. Financial savings compound with each mannequin deployed and each month the endpoint runs.
Velocity to manufacturing: Groups iterate sooner, check extra configurations, and get to manufacturing sooner. Each day saved in deployment is a day your generative AI funding is delivering worth to clients.
Confidence in manufacturing: Each suggestion is backed by actual measurements on actual GPU infrastructure utilizing NVIDIA AIPerf, not estimates or simulations. Deploy understanding your configuration has been validated in opposition to your particular mannequin and workload, at percentile-level precision that matches manufacturing circumstances.
Use circumstances
Pre-deployment validation: Optimize and benchmark a brand new mannequin earlier than committing to a manufacturing deployment. Know precisely the way it will carry out earlier than you spend money on scaling it.
Regression testing after updates: Validate efficiency after a container replace, framework improve, or serving library launch. Verify that your configuration remains to be optimum earlier than pushing to manufacturing.
Proper-sizing when circumstances change: When site visitors patterns shift or new occasion varieties change into obtainable, re-run optimized generative AI inference suggestions in hours quite than restarting a weeks-long handbook course of.
Mannequin comparability: Evaluate the efficiency and value of various mannequin variants throughout occasion varieties to make an knowledgeable choice earlier than manufacturing deployment.
Value optimization: Benchmark current manufacturing endpoints to establish over-provisioned infrastructure. Use the outcomes to right-size and cut back recurring inference spend.
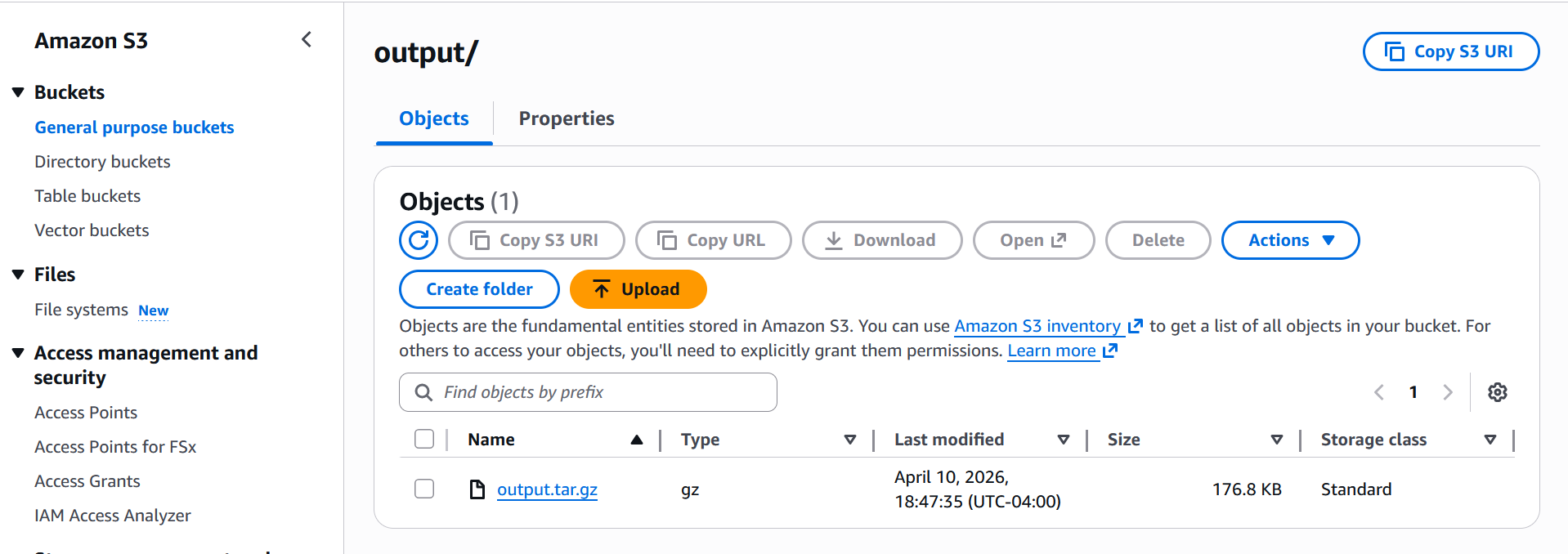
Benchmark inference endpoints
An AI benchmark job runs efficiency benchmarks in opposition to your SageMaker AI inference endpoints utilizing a predefined workload configuration. Use benchmark jobs to measure the efficiency of your generative AI inference infrastructure earlier than and after optimization. When the benchmark job is accomplished, the outcomes are saved within the Amazon S3 output location that you simply specified. As soon as the benchmark job completes, all outcomes are written to your S3 output path in output folder as proven beneath screenshot:
When you obtain and extract the zip output file, you’re going to get beneath information
output/
├── profile_export_aiperf.json # aggregated metrics
├── profile_export_aiperf.csv # identical metrics in CSV
├── profile_export.jsonl # uncooked per-request information
├── inputs.json # prompts despatched throughout the run
├── benchmark_summary.txt # completion abstract
├── MANIFEST.txt # index of all information with sizes
├── plot_generation.log # plot technology log
├── plots/
│ ├── ttft_timeline.png # TTFT per request over time
│ ├── ttft_over_time.png # TTFT aggregated over run period
│ ├── abstract.txt # checklist of generated plots
│ └── aiperf_plot.log # plot technology hint
└── logs/
└── aiperf.log # full AIPerf execution log
The principle output is profile_export_aiperf.json and its CSV counterpart profile_export_aiperf.csv each include the identical aggregated metrics: latency percentiles (p50, p90, p99), output token throughput, time-to-first-token (TTFT), and inter-token latency (ITL). These are the numbers you’d use to judge how the mannequin carried out beneath the simulated load.
Alongside that, profile_export.jsonl provides you the uncooked per-request information each particular person request logged with its personal latency, token counts, and timestamp. That is helpful if you wish to do your personal evaluation or spot outliers that the aggregated stats may conceal.
Now we have created a pattern pocket book in Github which benchmarks openai/gpt-oss-20b deployed on a ml.g6.12xlarge occasion (4× NVIDIA L40S GPUs), served through the vLLM container as an Inference Part. It simulates a practical workload utilizing artificial prompts: 300 requests at 10 concurrent customers, with ~500 enter and ~150 output tokens per request, to measure how the mannequin performs beneath that load.
Deploying mannequin from suggestions
After the AI Advice Job completes, the output is a SageMaker Mannequin Bundle which is a versioned useful resource that bundles all instance-specific deployment configurations right into a single artifact.
To deploy, you first convert the Mannequin Bundle right into a Deployable Mannequin by calling CreateModel with the ModelPackageName and the InferenceSpecificationName for the occasion you wish to goal, then create an endpoint configuration and deploy as a typical SageMaker real-time endpoint or Inference Part.
Alternatively, if you wish to use Inference Parts as a substitute of a single-model endpoint, You possibly can comply with the pocket book for particulars. This design means a single Advice Job produces one Mannequin Bundle with a number of InferenceSpecifications, one per evaluated occasion kind. So you’ll be able to choose the configuration that matches your latency, throughput, or value goal and deploy it immediately with out re-running the job.
Getting began
This functionality is accessible immediately in seven AWS Areas: US East (N. Virginia), US West (Oregon), US East (Ohio), Asia Pacific (Tokyo), Europe (Eire), Asia Pacific (Singapore), and Europe (Frankfurt). Entry it by way of the SageMaker AI APIs.
Conclusion
On this publish, we confirmed how optimized generative AI inference suggestions in Amazon SageMaker AI cut back deployment time from weeks to hours. With this functionality, you’ll be able to give attention to constructing correct fashions and the merchandise that matter to your clients, not on infrastructure tuning. Each configuration is validated on actual GPU infrastructure in opposition to your particular mannequin and workload, so you’ll be able to deploy with confidence and right-size with readability.