Introduction
Within the generative‑AI growth of current years, big language fashions have dominated headlines, however they aren’t the one recreation on the town. Small language fashions (SLMs) – typically starting from a couple of hundred million to about ten billion parameters – are quickly rising as a realistic selection for builders and enterprises who care about latency, price and useful resource effectivity. Advances in distillation, quantization and inference‑time optimizations imply these nimble fashions can deal with many actual‑world duties with out the heavy GPU payments of their bigger siblings. In the meantime, suppliers and platforms are racing to supply low‑price, excessive‑velocity APIs in order that groups can combine SLMs into merchandise shortly. Clarifai, a market chief in AI platforms, affords a singular edge with its Reasoning Engine, Compute Orchestration and Native Runners, enabling you to run fashions anyplace and save on cloud prices.
This text explores the rising ecosystem of small and environment friendly mannequin APIs. We’ll dive into the why, cowl choice standards, examine prime suppliers, talk about underlying optimization methods, spotlight actual‑world use instances, discover rising tendencies and share sensible steps to get began. All through, we’ll weave in knowledgeable insights, trade statistics and inventive examples to complement your understanding. Whether or not you’re a developer in search of an reasonably priced API or a CTO evaluating a hybrid deployment technique, this information will aid you make assured choices.
Fast Digest
Earlier than diving in, right here’s a succinct overview to orient you:
- What are SLMs? Compact fashions (tons of of tens of millions to ~10 B parameters) designed for environment friendly inference on restricted {hardware}.
- Why select them? They ship decrease latency, diminished price and may run on‑premise or edge units; the hole in reasoning means is shrinking due to distillation and excessive‑high quality coaching.
- Key choice metrics: Value per million tokens, latency and throughput, context window size, deployment flexibility (cloud vs. native), and knowledge privateness.
- High suppliers: Clarifai, Collectively AI, Fireworks AI, Hyperbolic, Helicone (observability), enterprise SLM distributors (Private AI, Arcee AI, Cohere), open‑supply fashions reminiscent of Gemma, Phi‑4, Qwen and MiniCPM4.
- Optimizations: Quantization, speculative decoding, LoRA/QLoRA, combination‑of‑consultants and edge deployment methods.
- Use instances: Buyer‑service bots, doc summarization, multimodal cellular apps, enterprise AI employees and academic experiments.
- Tendencies: Multimodal SLMs, extremely‑lengthy context home windows, agentic workflows, decentralized inference and sustainability initiatives.
With this roadmap, let’s unpack the main points.
Why Do Small & Environment friendly Fashions Matter?
Fast Abstract: Why have small and environment friendly fashions grow to be indispensable in in the present day’s AI panorama?
Reply: As a result of they decrease the barrier to entry for generative AI by lowering computational calls for, latency and price. They permit on‑machine and edge deployments, help privateness‑delicate workflows and are sometimes adequate for a lot of duties due to advances in distillation and coaching knowledge high quality.
Understanding SLMs
Small language fashions are outlined much less by a precise parameter depend than by deployability. In follow, the time period consists of fashions from a few hundred million to roughly 10 B parameters. Not like their bigger counterparts, SLMs are explicitly engineered to run on restricted {hardware}—typically even on a laptop computer or cellular machine. They leverage methods like selective parameter activation, the place solely a subset of weights is used throughout inference, dramatically lowering reminiscence utilization. For instance, Google DeepMind’s Gemma‑3n E2B has a uncooked parameter depend round 5 B however operates with the footprint of a 2 B mannequin due to selective activation.
Advantages and Commerce‑offs
The first attract of SLMs lies in price effectivity and latency. Research report that operating giant fashions reminiscent of 70 B‑parameter LLMs can require tons of of gigabytes of VRAM and costly GPUs, whereas SLMs match comfortably on a single GPU and even CPU. As a result of they compute fewer parameters per token, SLMs can reply quicker, making them appropriate for actual‑time purposes like chatbots, interactive brokers and edge‑deployed companies. Because of this, some suppliers declare sub‑100 ms latency and as much as 11× price financial savings in comparison with deploying frontier fashions.
Nevertheless, there’s traditionally been a compromise: diminished reasoning depth and data breadth. Many SLMs wrestle with complicated logic, lengthy‑vary context or area of interest data. But the hole is closing. Distillation from bigger fashions transfers reasoning behaviours into smaller architectures, and excessive‑high quality coaching knowledge boosts generalization. Some SLMs now obtain efficiency corresponding to fashions 2–3× their dimension.
When Measurement Issues Much less Than Expertise
For a lot of purposes, velocity, price and management matter greater than uncooked intelligence. Working AI on private {hardware} could also be a regulatory requirement (e.g. in healthcare or finance) or a tactical determination to chop inference prices. Clarifai’s Native Runners enable organizations to deploy fashions on their very own laptops, servers or non-public clouds and expose them through a strong API. This hybrid strategy preserves knowledge privateness—delicate info by no means leaves your atmosphere—and leverages present {hardware}, yielding vital financial savings on GPU leases. The flexibility to make use of the identical API for each native and cloud inference, with seamless MLOps options like monitoring, mannequin chaining and versioning, blurs the road between small and huge fashions: you select the precise dimension for the duty and run it the place it is sensible.
Professional Insights
- Useful resource‑environment friendly AI is a analysis precedence. A 2025 evaluation of submit‑coaching quantization methods notes that quantization can lower reminiscence necessities and computational price considerably with out substantial accuracy loss.
- Inference serving challenges stay. A survey on LLM inference serving highlights that enormous fashions impose heavy reminiscence and compute overhead, prompting improvements like request scheduling, KV‑cache administration and disaggregated architectures to realize low latency.
- Business shift: Studies present that by late 2025, main suppliers launched mini variations of their flagship fashions (e.g., GPT‑5 Mini, Claude Haiku, Gemini Flash) that lower inference prices by an order of magnitude whereas retaining excessive benchmark scores.
- Product perspective: Clarifai engineers emphasize that SLMs allow customers to check and deploy fashions shortly on private {hardware}, making AI accessible to groups with restricted assets.
How you can Choose the Proper Small & Environment friendly Mannequin API
Fast Abstract: What elements must you think about when selecting a small mannequin API?
Reply: Consider price, latency, context window, multimodal capabilities, deployment flexibility and knowledge privateness. Search for clear pricing and help for monitoring and scaling.
Key Metrics
Deciding on an API isn’t nearly mannequin high quality; it’s about how the service meets your operational wants. Vital metrics embody:
- Value per million tokens: The value distinction between enter and output tokens might be vital. A comparability desk for DeepSeek R1 throughout suppliers exhibits enter prices starting from $0.55/M to $3/M and output prices from $2.19/M to $8/M. Some suppliers additionally supply free credit or free tiers for trial use.
- Latency and throughput: Time to first token (TTFT) and tokens per second (throughput) instantly affect person expertise. Suppliers like Collectively AI promote sub‑100 ms TTFT, whereas Clarifai’s Reasoning Engine has been benchmarked at 3.6 s TTFT and 544 tokens per second throughput. Inference serving surveys counsel evaluating metrics like TTFT, throughput, normalized latency and percentile latencies.
- Context window & modality: SLMs range broadly in context size—from 32 Ok tokens for Qwen 0.6B to 1 M tokens for Gemini Flash and 10 M tokens for Llama 4 Scout. Decide how a lot reminiscence your software wants. Additionally think about whether or not the mannequin helps multimodal enter (textual content, photographs, audio, video), as in Gemma‑3n E2B.
- Deployment flexibility: Are you locked right into a single cloud, or are you able to run the mannequin anyplace? Clarifai’s platform is {hardware}‑ and vendor‑agnostic—supporting NVIDIA, AMD, Intel and even TPUs—and allows you to deploy fashions on‑premise or throughout clouds.
- Privateness & safety: For regulated industries, on‑premise or native inference could also be necessary. Native Runners guarantee knowledge by no means leaves your atmosphere.
Sensible Issues
When evaluating suppliers, ask:
Does the API help the frameworks you employ? Many companies supply REST and OpenAI‑suitable endpoints. Clarifai’s API, as an example, is totally suitable with OpenAI’s shopper libraries.
How straightforward is it to change fashions? Collectively AI permits fast swapping amongst tons of of open‑supply fashions, whereas Hyperbolic focuses on reasonably priced GPU rental and versatile compute.
What help and observability instruments can be found? Helicone provides monitoring for token utilization, latency and price.
Professional Insights
- Unbiased benchmarks validate vendor claims. Synthetic Evaluation ranked Clarifai’s Reasoning Engine within the “most tasty quadrant” for delivering each excessive throughput and aggressive price per token.
- Value vs. efficiency commerce‑off: Analysis exhibits that SLMs can attain close to state‑of‑the‑artwork benchmarks for math and reasoning duties whereas costing one‑tenth of earlier fashions. Consider whether or not paying additional for barely larger efficiency is price it on your use case.
- Latency distribution issues: The inference survey recommends analyzing percentile latencies (P50, P90, P99) to make sure constant efficiency.
- Hybrid deployment: Clarifai consultants observe that combining Native Runners for delicate duties with cloud inference for public options can steadiness privateness and scalability.
Who Are the High Suppliers of Small & Environment friendly Mannequin APIs?
Fast Abstract: Which platforms lead the pack for low‑price, excessive‑velocity mannequin inference?
Reply: A mixture of established AI platforms (Clarifai, Collectively AI, Fireworks AI, Hyperbolic) and specialised enterprise suppliers (Private AI, Arcee AI, Cohere) supply compelling SLM APIs. Open‑supply fashions reminiscent of Gemma, Phi‑4, Qwen and MiniCPM4 present versatile choices for self‑internet hosting, whereas “mini” variations of frontier fashions from main labs ship finances‑pleasant efficiency.
Beneath is an in depth comparability of the highest companies and mannequin households. Every profile summarizes distinctive options, pricing highlights and the way Clarifai integrates or enhances the providing.
Clarifai Reasoning Engine & Native Runners
Clarifai stands out by combining state‑of‑the‑artwork efficiency with deployment flexibility. Its Reasoning Engine delivers 544 tokens per second throughput, 3.6 s time to first reply and $0.16 per million blended tokens in impartial benchmarks. Not like many cloud‑solely suppliers, Clarifai affords Compute Orchestration to run fashions throughout any {hardware} and Native Runners for self‑internet hosting. This hybrid strategy lets organizations save as much as 90 % of compute by optimizing workloads throughout environments. Builders may also add their very own fashions or select from trending open‑supply ones (GPT‑OSS‑120B, DeepSeek‑V3 1, Llama‑4 Scout, Qwen3 Subsequent, MiniCPM4) and deploy them in minutes.
Clarifai Integration Suggestions:
- Use Native Runners when coping with knowledge‑delicate duties or token‑hungry fashions to maintain knowledge on‑premise.
- Leverage Clarifai’s OpenAI‑suitable API for straightforward migration from different companies.
- Chain a number of fashions (e.g. extraction, summarization, reasoning) utilizing Clarifai’s workflow instruments for finish‑to‑finish pipelines.
Collectively AI
Collectively AI positions itself as a excessive‑efficiency inferencing platform for open‑supply fashions. It affords sub‑100 ms latency, automated optimization and horizontal scaling throughout 200+ fashions. Token caching, mannequin quantization and cargo balancing are constructed‑in, and pricing might be 11× cheaper than utilizing proprietary companies when operating fashions like Llama 3. A free tier makes it straightforward to check.
Clarifai Perspective: Clarifai’s platform can complement Collectively AI by offering observability (through Helicone) or serving fashions regionally. For instance, you would run analysis experiments on Collectively AI after which deploy the ultimate pipeline through Clarifai for manufacturing stability.
Fireworks AI
Fireworks AI focuses on serverless multimodal inference. Its proprietary FireAttention engine delivers sub‑second latency and helps textual content, picture and audio duties with HIPAA and SOC2 compliance. It’s designed for straightforward integration of open‑supply fashions and affords pay‑as‑you‑go pricing.
Clarifai Perspective: For groups requiring HIPAA compliance and multi‑modal processing, Fireworks might be built-in with Clarifai workflows. Alternatively, Clarifai’s Generative AI modules might deal with related duties with much less vendor lock‑in.
Hyperbolic
Hyperbolic gives a singular mixture of AI inferencing companies and reasonably priced GPU rental. It claims as much as 80 % decrease prices in contrast with giant cloud suppliers and affords entry to varied base, textual content, picture and audio fashions. The platform appeals to startups and researchers who want versatile compute with out lengthy‑time period contracts.
Clarifai Perspective: You should use Hyperbolic for prototype improvement or low‑price mannequin coaching, then deploy through Clarifai’s compute orchestration for manufacturing. This break up can scale back prices whereas gaining enterprise‑grade MLOps.
Helicone (Observability Layer)
Helicone isn’t a mannequin supplier however an observability platform that integrates with a number of mannequin APIs. It tracks token utilization, latency and price in actual time, enabling groups to handle budgets and establish efficiency bottlenecks. Helicone can plug into Clarifai’s API or companies like Collectively AI and Fireworks. For complicated pipelines, it’s a vital device to take care of price transparency.
Enterprise SLM Distributors – Private AI, Arcee AI & Cohere
The rise of enterprise‑targeted SLM suppliers displays the necessity for safe, customizable AI options.
- Private AI: Affords a multi‑reminiscence, multi‑modal “MODEL‑3” structure the place organizations can create AI personas (e.g., AI CFO, AI Authorized Counsel). It boasts a zero‑hallucination design and robust privateness assurances, making it very best for regulated industries.
- Arcee AI: Routes duties to specialised 7 B‑parameter fashions utilizing an orchestral platform, enabling no‑code agent workflows with deep compliance controls.
- Cohere: Whereas identified for bigger fashions, its Command R7B is a 7 B SLM with a 128 Ok context window and enterprise‑grade safety; it’s trusted by main firms.
Clarifai Perspective: Clarifai’s compute orchestration can host or interoperate with these fashions, permitting enterprises to mix proprietary fashions with open‑supply or customized ones in unified workflows.
Open‑Supply SLM Households
Open‑supply fashions give builders the liberty to self‑host and customise. Notable examples embody:
- Gemma‑3n E2B: A 5 B parameter multimodal mannequin from Google DeepMind. It makes use of selective activation to run with a footprint just like a 2 B mannequin and helps textual content, picture, audio and video inputs. Its cellular‑first structure and help for 140+ languages make it very best for on‑machine experiences.
- Phi‑4‑mini instruct: A 3.8 B parameter mannequin from Microsoft, educated on reasoning‑dense knowledge. It matches the efficiency of bigger 7 B–9 B fashions and affords a 128 Ok context window beneath an MIT license.
- Qwen3‑0.6B: A 0.6 B mannequin with a 32 Ok context, supporting 100+ languages and hybrid reasoning behaviours. Regardless of its tiny dimension, it competes with greater fashions and is good for world on‑machine merchandise.
- MiniCPM4: A part of a sequence of environment friendly LLMs optimized for edge units. By means of improvements in structure, knowledge and coaching, these fashions ship robust efficiency at low latency.
- SmolLM3 and different 3–4 B fashions: Excessive‑efficiency instruction fashions that outperform some 7 B and 4 B alternate options.
Clarifai Perspective: You possibly can add and deploy any of those open‑supply fashions through Clarifai’s Add Your Personal Mannequin characteristic. The platform handles provisioning, scaling and monitoring, turning uncooked fashions into manufacturing companies in minutes.
Funds & Pace Fashions from Main Suppliers
Main AI labs have launched mini variations of their flagship fashions, shifting the fee‑efficiency frontier.
- GPT‑5 Mini: Affords practically the identical capabilities as GPT‑5 with enter prices round $0.25/M tokens and output prices round $2/M tokens—dramatically cheaper than earlier fashions. It maintains robust efficiency on math benchmarks, reaching 91.1 % on the AIME contest whereas being way more reasonably priced.
- Claude 3.5 Haiku: Anthropic’s smallest mannequin within the 3.5 sequence. It emphasises quick responses with a 200 Ok token context and sturdy instruction following.
- Gemini 2.5 Flash: Google’s 1 M context hybrid mannequin optimized for velocity and price.
- Grok 4 Quick: xAI’s finances variant of the Grok mannequin, that includes 2 M context and modes for reasoning or direct answering.
- DeepSeek V3.2 Exp: An open‑supply experimental mannequin that includes Combination‑of‑Specialists and sparse consideration for effectivity.
Clarifai Perspective: Many of those fashions can be found through Clarifai’s Reasoning Engine or might be uploaded via its compute orchestration. As a result of pricing can change quickly, Clarifai displays token prices and throughput to make sure aggressive efficiency.
Professional Insights
- Hybrid technique: A standard sample is to make use of a draft small mannequin (e.g., Qwen 0.6B) for preliminary reasoning and name a bigger mannequin just for complicated queries. This speculative or cascade strategy reduces prices whereas sustaining high quality.
- Observability issues: Value, latency and efficiency range throughout suppliers. Combine observability instruments reminiscent of Helicone to observe utilization and keep away from finances surprises.
- Vendor lock‑in: Platforms like Clarifai tackle lock‑in by permitting you to run fashions on any {hardware} and change suppliers with an OpenAI‑suitable API.
- Enterprise AI groups: Private AI’s means to create specialised AI employees and keep excellent reminiscence throughout periods demonstrates how SLMs can scale throughout departments.
What Methods Make SLM Inference Environment friendly?
Fast Abstract: Which underlying methods allow small fashions to ship low‑price, quick inference?
Reply: Effectivity comes from a mix of quantization, speculative decoding, LoRA/QLoRA adapters, combination‑of‑consultants, edge‑optimized architectures and sensible inference‑serving methods. Clarifai’s platform helps or enhances many of those strategies.
Quantization
Quantization reduces the numerical precision of mannequin weights and activations (e.g. from 32‑bit to eight‑bit and even 4‑bit). A 2025 survey explains that quantization drastically reduces reminiscence consumption and compute whereas sustaining accuracy. By lowering the mannequin’s reminiscence footprint, quantization permits deployment on cheaper {hardware} and reduces vitality utilization. Publish‑coaching quantization (PTQ) methods enable builders to quantize pre‑educated fashions with out retraining them, making it very best for SLMs.
Speculative Decoding & Cascade Fashions
Speculative decoding accelerates autoregressive era through the use of a small draft mannequin to suggest a number of future tokens, which the bigger mannequin then verifies. This system can ship 2–3× velocity enhancements and is more and more obtainable in inference frameworks. It pairs properly with SLMs: you need to use a tiny mannequin like Qwen 0.6B because the drafter and a bigger reasoning mannequin for verification. Some analysis extends this concept to three‑mannequin speculative decoding, layering a number of draft fashions for additional features. Clarifai’s reasoning engine is optimized to help such speculative and cascade workflows.
LoRA & QLoRA
Low‑Rank Adaptation (LoRA) tremendous‑tunes solely a small subset of parameters by injecting low‑rank matrices. QLoRA combines LoRA with quantization to scale back reminiscence utilization even throughout tremendous‑tuning. These methods lower coaching prices by orders of magnitude and scale back the penalty on inference. Builders can shortly adapt open‑supply SLMs for area‑particular duties with out retraining the total mannequin. Clarifai’s coaching modules help tremendous‑tuning through adapters, enabling customized fashions to be deployed via its inference API.
Combination‑of‑Specialists (MoE)
MoE architectures allocate totally different “consultants” to course of particular tokens. As an alternative of utilizing all parameters for each token, a router selects a subset of consultants, permitting the mannequin to have very excessive parameter counts however solely activate a small portion throughout inference. This ends in decrease compute per token whereas retaining general capability. Fashions like Llama‑4 Scout and Qwen3‑Subsequent leverage MoE for lengthy‑context reasoning. MoE fashions introduce challenges round load balancing and latency, however analysis proposes dynamic gating and knowledgeable buffering to mitigate these.
Edge Deployment & KV‑Cache Optimizations
Working fashions on the sting affords privateness and price advantages. Nevertheless, useful resource constraints demand optimizations reminiscent of KV‑cache administration and request scheduling. The inference survey notes that occasion‑degree methods like prefill/decoding separation, dynamic batching and multiplexing can considerably scale back latency. Clarifai’s Native Runners incorporate these methods mechanically, enabling fashions to ship manufacturing‑grade efficiency on laptops or on‑premise servers.
Professional Insights
- Quantization commerce‑offs: Researchers warning that low‑bit quantization can degrade accuracy in some duties; use adaptive precision or blended‑precision methods.
- Cascade design: Specialists suggest constructing pipelines the place a small mannequin handles most requests and solely escalates to bigger fashions when essential. This reduces common price per request.
- MoE finest practices: To keep away from load imbalance, mix dynamic gating with load‑balancing algorithms that distribute visitors evenly throughout consultants.
- Edge vs. cloud: On‑machine inference reduces community latency and will increase privateness however might restrict entry to giant context home windows. A hybrid strategy—operating summarization regionally and lengthy‑context reasoning within the cloud—can ship the most effective of each worlds.
How Are Small & Environment friendly Fashions Used within the Actual World?
Fast Abstract: What sensible purposes profit most from SLMs and low‑price inference?
Reply: SLMs energy chatbots, doc summarization companies, multimodal cellular apps, enterprise AI groups and academic instruments. Their low latency and price make them very best for prime‑quantity, actual‑time and edge‑primarily based workloads.
Buyer‑Service & Conversational Brokers
Companies deploy SLMs to create responsive chatbots and AI brokers that may deal with giant volumes of queries with out ballooning prices. As a result of SLMs have shorter context home windows and quicker response instances, they excel at transactional conversations, routing queries or offering primary help. For extra complicated requests, methods can seamlessly hand off to a bigger reasoning mannequin. Clarifai’s Reasoning Engine helps such agentic workflows, enabling multi‑step reasoning with low latency.
Inventive Instance: Think about an e‑commerce platform utilizing a 3‑B SLM to reply product questions. For powerful queries, it invokes a deeper reasoning mannequin, however 95 % of interactions are served by the small mannequin in beneath 100 ms, slashing prices.
Doc Processing & Retrieval‑Augmented Era (RAG)
SLMs with lengthy context home windows (e.g., Phi‑4 mini with 128 Ok tokens or Llama 4 Scout with 10 M tokens) are properly‑suited to doc summarization, authorized contract evaluation and RAG methods. Mixed with vector databases and search algorithms, they’ll shortly extract key info and generate correct summaries. Clarifai’s compute orchestration helps chaining SLMs with vector search fashions for sturdy RAG pipelines.
Multimodal & Cellular Functions
Fashions like Gemma‑3n E2B and MiniCPM4 settle for textual content, photographs, audio and video inputs, enabling multimodal experiences on cellular units. As an example, a information app may use such a mannequin to generate audio summaries of articles or translate dwell speech to textual content. The small reminiscence footprint means they’ll run on smartphones or low‑energy edge units, the place bandwidth and latency constraints make cloud‑primarily based inference impractical.
Enterprise AI Groups & Digital Co‑Staff
Enterprises are transferring past chatbots towards AI workforces. Options like Private AI let corporations practice specialised SLMs – AI CFOs, AI attorneys, AI gross sales assistants – that keep institutional reminiscence and collaborate with people. Clarifai’s platform can host such fashions regionally for compliance and combine them with different companies. SLMs’ decrease token prices enable organizations to scale the variety of AI crew members with out incurring prohibitive bills.
Analysis & Training
Universities and researchers use SLM APIs to prototype experiments shortly. SLMs’ decrease useful resource necessities allow college students to tremendous‑tune fashions on private GPUs or college clusters. Open‑supply fashions like Qwen and Phi encourage transparency and reproducibility. Clarifai affords tutorial credit and accessible pricing, making it a priceless associate for instructional establishments.
Professional Insights
- Healthcare state of affairs: A hospital makes use of Clarifai’s Native Runners to deploy a multimodal mannequin regionally for radiology report summarization, making certain HIPAA compliance whereas avoiding cloud prices.
- Assist heart success: A tech firm changed its LLM‑primarily based help bot with a 3 B SLM, lowering common response time by 70 % and reducing month-to-month inference prices by 80 %.
- On‑machine translation: A journey app leverages Gemma‑3n’s multimodal capabilities to carry out speech‑to‑textual content translation on smartphones, delivering offline translations even with out connectivity.
What’s Subsequent? Rising & Trending Subjects
Fast Abstract: Which tendencies will form the way forward for small mannequin APIs?
Reply: Anticipate to see multimodal SLMs, extremely‑lengthy context home windows, agentic workflows, decentralized inference, and sustainability‑pushed optimizations. Regulatory and moral issues may even affect deployment selections.
Multimodal & Cross‑Area Fashions
SLMs are increasing past pure textual content. Fashions like Gemma‑3n settle for textual content, photographs, audio and video, demonstrating how SLMs can function common cross‑area engines. As coaching knowledge turns into extra various, anticipate fashions that may reply a written query, describe a picture and translate speech all inside the similar small footprint.
Extremely‑Lengthy Context Home windows & Reminiscence Architectures
Latest releases present fast development in context size: 10 M tokens for Llama 4 Scout, 1 M tokens for Gemini Flash, and 32 Ok tokens even for sub‑1 B fashions like Qwen 0.6B. Analysis into phase routing, sliding home windows and reminiscence‑environment friendly consideration will enable SLMs to deal with lengthy paperwork with out ballooning compute prices.
Agentic & Device‑Use Workflows
Agentic AI—the place fashions plan, name instruments and execute duties—requires constant reasoning and multi‑step determination making. Many SLMs now combine device‑use capabilities and are being optimized to work together with exterior APIs, databases and code. Clarifai’s Reasoning Engine, as an example, helps superior device invocation and may orchestrate chains of fashions for complicated duties.
Decentralized & Privateness‑Preserving Inference
As privateness rules tighten, the demand for on‑machine inference and self‑hosted AI will develop. Platforms like Clarifai’s Native Runners exemplify this development, enabling hybrid architectures the place delicate workloads run regionally whereas much less delicate duties leverage cloud scalability. Rising analysis explores federated inference and distributed mannequin serving to protect person privateness with out sacrificing efficiency.
Sustainability & Power Effectivity
Power consumption is a rising concern. Quantization and integer‑solely inference strategies scale back energy utilization, whereas combination‑of‑consultants and sparse consideration decrease computation. Researchers are exploring transformer alternate options—reminiscent of Mamba, Hyena and RWKV—that will supply higher scaling with fewer parameters. Sustainability will grow to be a key promoting level for AI platforms.
Professional Insights
- Regulatory foresight: Knowledge safety legal guidelines like GDPR and HIPAA will more and more favour native or hybrid inference, accelerating adoption of self‑hosted SLMs.
- Benchmark evolution: New benchmarks that issue vitality consumption, latency consistency and whole price of possession will information mannequin choice.
- Neighborhood involvement: Open‑supply collaborations (e.g., Hugging Face releases, tutorial consortia) will drive innovation in SLM architectures, making certain that enhancements stay accessible.
How you can Get Began with Small & Environment friendly Mannequin APIs
Fast Abstract: What are the sensible steps to combine SLMs into your workflow?
Reply: Outline your use case and finances, examine suppliers on key metrics, take a look at fashions with free tiers, monitor utilization with observability instruments and deploy through versatile platforms like Clarifai for manufacturing. Use code samples and finest practices to speed up improvement.
Step‑by‑Step Information
- Outline the Activity & Necessities: Determine whether or not your software wants chat, summarization, multimodal processing or complicated reasoning. Estimate token volumes and latency necessities. For instance, a help bot may tolerate 1–2 s latency however want low price per million tokens.
- Evaluate Suppliers: Use the factors in Part 2 to shortlist APIs. Take note of pricing tables, context home windows, multimodality and deployment choices. Clarifai’s Reasoning Engine, Collectively AI and Fireworks AI are good beginning factors.
- Signal Up & Acquire API Keys: Most companies supply free tiers. Clarifai gives a Begin free of charge plan and OpenAI‑suitable endpoints.
- Check Fashions: Ship pattern prompts and measure latency, high quality and price. Use Helicone or related instruments to observe token utilization. For area‑particular duties, strive tremendous‑tuning with LoRA or QLoRA.
- Deploy Regionally or within the Cloud: If privateness or price is a priority, run fashions through Clarifai’s Native Runners. In any other case, deploy in Clarifai’s cloud for elasticity. You possibly can combine each utilizing compute orchestration.
- Combine Observability & Management: Implement monitoring to trace prices, latency and error charges. Alter token budgets and select fallback fashions to take care of SLAs.
- Iterate & Scale: Analyze person suggestions, refine prompts and fashions, and scale up by including extra AI brokers or pipelines. Clarifai’s workflow builder can chain fashions to create complicated duties.
Instance API Name
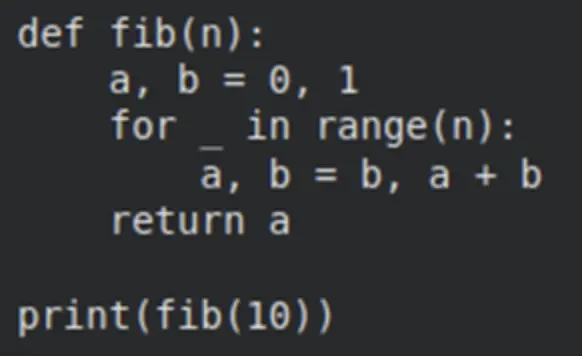
Beneath is a pattern Python snippet displaying tips on how to use Clarifai’s OpenAI‑suitable API to work together with a mannequin. Substitute YOUR_PAT together with your private entry token and choose any Clarifai mannequin URL (e.g., GPT‑OSS‑120B or your uploaded SLM):
import os
from openai import OpenAI
# Change these two parameters to level to Clarifai
shopper = OpenAI(
base_url=”https://api.clarifai.com/v2/ext/openai/v1″,
api_key=”YOUR_PAT”,
)
response = shopper.chat.completions.create(
mannequin=”https://clarifai.com/openai/chat-completion/fashions/gpt-oss-120b”,
messages=[
{“role”: “user”, “content”: “What is the capital of France?”}
]
)
print(response.selections[0].message.content material)
The identical sample works for different Clarifai fashions or your customized uploads.
Greatest Practices & Suggestions
- Immediate Engineering: Small fashions might be delicate to immediate formatting. Observe beneficial codecs (e.g., system/person/assistant roles for Phi‑4 mini).
- Caching: Use caching for repeated prompts to scale back prices. Clarifai mechanically caches tokens when attainable.
- Batching: Group a number of requests to enhance throughput and scale back per‑token overhead.
- Funds Alerts: Arrange price thresholds and alerts in your observability layer to keep away from surprising payments.
- Moral Deployment: Respect person knowledge privateness. Use on‑machine or native fashions for delicate info and guarantee compliance with rules.
Professional Insights
- Pilot first: Begin with non‑mission‑essential options to gauge price and efficiency earlier than scaling.
- Neighborhood assets: Take part in developer boards, attend webinars and watch movies on SLM integration to remain updated. Main AI educators emphasise the significance of sharing finest practices to speed up adoption.
- Lengthy‑time period imaginative and prescient: Plan for a hybrid structure that may modify as fashions evolve. You may begin with a mini mannequin and later improve to a reasoning engine or multi‑modal powerhouse as your wants develop.
Conclusion
Small and environment friendly fashions are reshaping the AI panorama. They permit quick, reasonably priced and personal inference, opening the door for startups, enterprises and researchers to construct AI‑powered merchandise with out the heavy infrastructure of big fashions. From chatbots and doc summarizers to multimodal cellular apps and enterprise AI employees, SLMs unlock a variety of potentialities. The ecosystem of suppliers—from Clarifai’s hybrid Reasoning Engine and Native Runners to open‑supply gems like Gemma and Phi‑4—affords selections tailor-made to each want.
Shifting ahead, we anticipate to see multimodal SLMs, extremely‑lengthy context home windows, agentic workflows and decentralized inference grow to be mainstream. Regulatory pressures and sustainability issues will drive adoption of privateness‑preserving and vitality‑environment friendly architectures. By staying knowledgeable, leveraging finest practices and partnering with versatile platforms reminiscent of Clarifai, you may harness the ability of small fashions to ship huge affect.
FAQs
What’s the distinction between an SLM and a conventional LLM? Massive language fashions have tens or tons of of billions of parameters and require substantial compute. SLMs have far fewer parameters (typically beneath 10 B) and are optimized for deployment on constrained {hardware}.
How a lot can I save through the use of a small mannequin? Financial savings rely on supplier and job, however case research point out as much as 11× cheaper inference in contrast with utilizing prime‑tier giant fashions. Clarifai’s Reasoning Engine prices about $0.16 per million tokens, highlighting the fee benefit.
Are SLMs adequate for complicated reasoning? Distillation and higher coaching knowledge have narrowed the hole in reasoning means. Fashions like Phi‑4 mini and Gemma‑3n ship efficiency corresponding to 7 B–9 B fashions, whereas mini variations of frontier fashions keep excessive benchmark scores at decrease price. For probably the most demanding duties, combining a small mannequin for draft reasoning with a bigger mannequin for last verification (speculative decoding) is efficient.
How do I run a mannequin regionally? Clarifai’s Native Runners allow you to deploy fashions in your {hardware}. Obtain the runner, join it to your Clarifai account and expose an endpoint. Knowledge stays on‑premise, lowering cloud prices and making certain compliance.
Can I add my very own mannequin? Sure. Clarifai’s platform lets you add any suitable mannequin and obtain a manufacturing‑prepared API endpoint. You possibly can then monitor and scale it utilizing Clarifai’s compute orchestration.
What’s the way forward for small fashions? Anticipate multimodal, lengthy‑context, vitality‑environment friendly and agentic SLMs to grow to be mainstream. Hybrid architectures that mix native and cloud inference will dominate as privateness and sustainability grow to be paramount.






 estimator")