As nice as your AI brokers could also be in your POC surroundings, that very same success might not make its technique to manufacturing. Usually, these good demo experiences don’t translate to the identical stage of reliability in manufacturing, if in any respect.
Taking your brokers from POC to manufacturing requires overcoming these 5 basic challenges:
- Defining success by translating enterprise intent into measurable agent efficiency.
Constructing a dependable agent begins by changing imprecise enterprise objectives, akin to “enhance customer support,” into concrete, quantitative analysis thresholds. The enterprise context determines what it’s best to consider and the way you’ll monitor it.
For instance, a monetary compliance agent usually requires 99.9% practical accuracy and strict governance adherence, even when that comes on the expense of pace. In distinction, a buyer help agent might prioritize low latency and financial effectivity, accepting a “ok” 90% decision fee to stability efficiency with value.
- Proving your brokers work throughout fashions, workflows, and real-world circumstances.
To succeed in manufacturing readiness, it is advisable to consider a number of agentic workflows throughout totally different mixtures of huge language fashions (LLMs), embedding methods, and guardrails, whereas nonetheless assembly strict high quality, latency, and value targets.
Analysis extends past practical accuracy to cowl nook circumstances, red-teaming for poisonous prompts and responses, and defenses towards threats akin to immediate injection assaults.
This effort combines LLM-based evaluations with human evaluate, utilizing each artificial information and real-world use circumstances. In parallel, you assess operational efficiency, together with latency, throughput at a whole bunch or 1000’s of requests per second, and the power to scale up or down with demand.
- Making certain agent habits is observable so you’ll be able to debug and iterate with confidence.
Tracing the execution of agent workflows step-by-step lets you perceive why an agent behaves the best way it does. By making every choice, device name, and handoff seen, you’ll be able to establish root causes of sudden habits, debug failures rapidly, and iterate towards the specified agentic workflow earlier than deployment.
- Monitoring brokers repeatedly in manufacturing and intervening earlier than failures escalate.
Monitoring deployed brokers in manufacturing with real-time alerting, moderation, and the power to intervene when habits deviates from expectations is essential. Alerts from monitoring, together with periodic opinions, ought to set off re-evaluation so you’ll be able to iterate on or restructure agentic workflows as brokers drift from desired habits over time. And hint root causes of those simply.
- Implement governance, safety, and compliance throughout the complete agent lifecycle.
You could apply governance controls at each stage of agent improvement and deployment to handle operational, safety, and compliance dangers. Treating governance as a built-in requirement, slightly than a bolt-on on the finish, ensures brokers stay protected, auditable, and compliant as they evolve.
Letting success hinge on hope and good intentions isn’t ok. Strategizing round this framework is what separates profitable enterprise synthetic intelligence initiatives from those who get caught as a proof of idea.
Why agentic methods require analysis, monitoring, and governance
As Agentic AI strikes past POCs to manufacturing methods to automate enterprise workflows, their execution and outcomes will instantly affect enterprise operations. The waterfall results of agent failures can considerably affect enterprise processes, and it might all occur very quick, stopping the power of people to intervene.
For a complete overview of the ideas and greatest practices that underpin these enterprise-grade necessities, see The Enterprise Information to Agentic AI
Evaluating agentic methods throughout a number of reliability dimensions
Earlier than rolling out brokers, organizations want confidence in reliability throughout a number of dimensions, every addressing a distinct class of manufacturing threat.
Practical
Reliability on the practical stage will depend on whether or not an agent accurately understands and carries out the duty it was assigned. This includes measuring accuracy, assessing process adherence, and detecting failure modes akin to hallucinations or incomplete responses.
Operational
Operational reliability will depend on whether or not the underlying infrastructure can persistently help agent execution at scale. This contains validating scalability, excessive availability, and catastrophe restoration to stop outages and disruptions.
Operational reliability additionally will depend on the robustness of integrations with present enterprise methods, CI/CD pipelines, and approval workflows for deployments and updates. As well as, groups should assess runtime efficiency traits akin to latency (for instance, time to first token), throughput, and useful resource utilization throughout CPU and GPU infrastructure.
Safety
Safe operation requires that agentic methods meet enterprise safety requirements. This contains validating authentication and authorization, implementing role-based entry controls aligned with organizational insurance policies, and limiting agent entry to instruments and information primarily based on least-privilege ideas. Safety validation additionally contains testing guardrails towards threats akin to immediate injection and unauthorized information entry.
Governance and Compliance
Efficient governance requires a single supply of fact for all agentic methods and their related instruments, supported by clear lineage and versioning of brokers and parts.
Compliance readiness additional requires real-time monitoring, moderation, and intervention to deal with dangers akin to poisonous or inappropriate content material and PII leakage. As well as, agentic methods should be examined towards relevant {industry} and authorities rules, with audit-ready documentation available to display ongoing compliance.
Financial
Sustainable deployment will depend on the financial viability of agentic methods. This contains measuring execution prices akin to token consumption and compute utilization, assessing architectural trade-offs like devoted versus on-demand fashions, and understanding total time to manufacturing and return on funding.
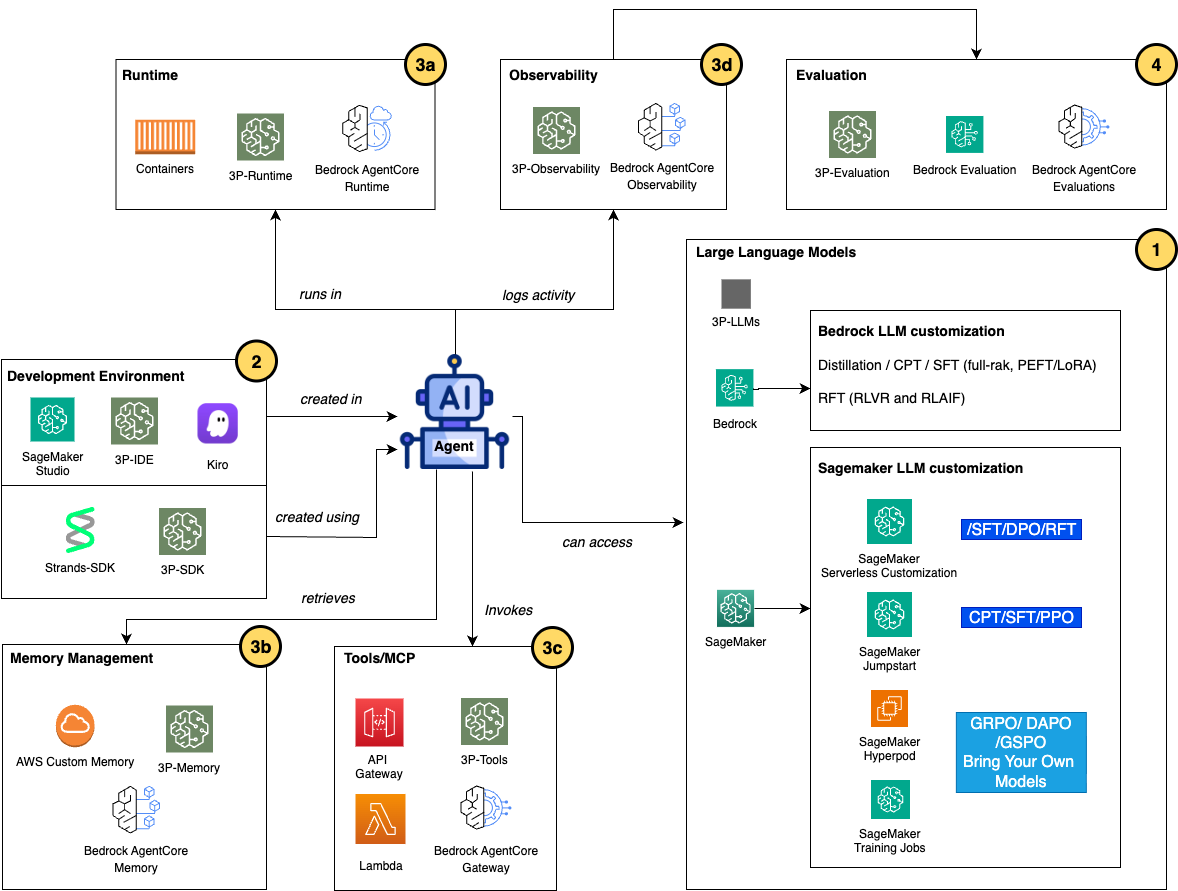
Monitoring, tracing, and governance throughout the agent lifecycle
Pre-deployment analysis alone is just not adequate to make sure dependable agent habits. As soon as brokers function in manufacturing, steady monitoring turns into important to detect drift from anticipated or desired habits over time.
Monitoring usually focuses on a subset of metrics drawn from every analysis dimension. Groups configure alerts on predefined thresholds to floor early indicators of degradation, anomalous habits, or rising threat. Monitoring gives visibility into what is occurring throughout execution, nevertheless it doesn’t by itself clarify why an agent produced a selected final result.
To uncover root causes, monitoring should be paired with execution tracing. Execution tracing exposes:
- How an agent arrived at a end result by capturing the sequence of reasoning steps it adopted
- The instruments or features it invoked
- The inputs and outputs at every stage of execution.
This visibility extends to related metrics akin to accuracy or latency at each the enter and output of every step, enabling efficient debugging, quicker iteration, and extra assured refinement of agentic workflows.
And eventually, governance is critical at each part of the agent lifecycle, from constructing and experimentation to deployment in manufacturing.
Governance will be labeled broadly into 3 classes:
- Governance towards safety dangers: Ensures that agentic methods are shielded from unauthorized or unintended actions by implementing sturdy, auditable approval workflows at each stage of the agent construct, deployment, and replace course of. This contains strict role-based entry management (RBAC) for all instruments, sources, and enterprise methods an agent can entry, in addition to customized alerts utilized all through the agent lifecycle to detect and forestall unintentional or malicious deployments.
- Governance towards operational dangers: Focuses on sustaining protected and dependable habits throughout runtime by implementing multi-layer protection mechanisms that stop undesirable or dangerous outputs, together with PII or different confidential data leakage. This governance layer depends on real-time monitoring, notifications, intervention, and moderation capabilities to establish points as they happen and allow fast response earlier than operational failures propagate.
- Governance towards regulatory dangers: Ensures that every one agentic options stay compliant with relevant industry-specific and authorities rules, insurance policies, and requirements whereas sustaining robust safety controls throughout the complete agent ecosystem. This contains validating agent habits towards regulatory necessities, implementing compliance persistently throughout deployments, and supporting auditability and documentation wanted to display adherence to evolving regulatory frameworks.
Collectively, monitoring, tracing, and governance kind a steady management loop for working agentic methods reliably in manufacturing.
Monitoring and tracing present the visibility wanted to detect and diagnose points, whereas governance ensures ongoing alignment with safety, operational, and regulatory necessities. We are going to study governance in additional element later on this article.
Lots of the analysis and monitoring practices used at present have been designed for conventional machine studying methods, the place habits is basically deterministic and execution paths are nicely outlined. Agentic methods break these assumptions by introducing autonomy, state, and multi-step decision-making. Consequently, evaluating and working agentic instruments requires essentially totally different approaches than these used for traditional ML fashions.
From deterministic fashions to autonomous agentic methods
Basic ML system analysis is rooted in determinism and bounded habits, because the system’s inputs, transformations, and outputs are largely predefined. Metrics akin to accuracy, precision/recall, latency, and error charges assume a hard and fast execution path: the identical enter reliably produces the identical output. Observability focuses on recognized failure modes, akin to information drift, mannequin efficiency decay, and infrastructure well being, and analysis is usually carried out towards static take a look at units or clearly outlined SLAs.
Against this, agentic device analysis should account for autonomy and decision-making below uncertainty. An agent doesn’t merely produce an output; it decides what to do subsequent: which device to name, in what order, and with what parameters.
Consequently, analysis shifts from single-output correctness to trajectory-level correctness, measuring whether or not the agent chosen applicable instruments, adopted supposed reasoning steps, and adhered to constraints whereas pursuing a purpose.
State, context, and compounding failures
Agentic methods by design are advanced multi-component methods, consisting of a mix of huge language fashions and different instruments, which can embrace predictive AI fashions. They obtain their outcomes utilizing a sequence of interactions with these instruments, and thru autonomous decision-making by the LLMs primarily based on device responses. Throughout these steps and interactions, brokers keep state and make selections from collected context.
These components make agentic analysis considerably extra advanced than that of predictive AI methods. Predictive AI methods are evaluated merely primarily based on the standard of their predictions, whether or not the predictions have been correct or not, and there’s no preservation of state. Agentic AI methods, however, have to be judged on high quality of reasoning, consistency of decision-making, and adherence to the assigned process. Moreover, there may be at all times a threat of errors compounding throughout a number of interactions resulting from state preservation.
Governance, security, and economics as first-class analysis dimensions
Agentic analysis additionally locations far higher emphasis on governance, security, and value. As a result of brokers can take actions, entry delicate information, and function repeatedly, analysis should observe lineage, versioning, entry management, and coverage compliance throughout complete workflows.
Financial metrics, akin to token utilization, device invocation value, and compute consumption, develop into first-class indicators, since inefficient reasoning paths translate instantly into increased operational value.
Agentic methods protect state throughout interactions and use it as context in future interactions. For instance, to be efficient, a buyer help agent wants entry to earlier conversations, account historical past, and ongoing points. Shedding context means beginning over and degrading the person expertise.
In brief, whereas conventional analysis asks, “Was the reply right?”, agentic device analysis asks, “Did the system act accurately, safely, effectively, and in alignment with its mandate whereas reaching the reply?”
Metrics and frameworks to guage and monitor brokers
As enterprises undertake advanced, multi-agent autonomous AI workflows, efficient analysis requires extra than simply accuracy. Metrics and frameworks should span practical habits, operational effectivity, safety, and financial value.
Under, we outline 4 key classes for agentic workflow analysis obligatory to determine visibility and management.
Practical metrics
Practical metrics measure whether or not the agentic workflow performs the duty it was designed for and adheres to its anticipated habits.
Core practical metrics:
- Agent purpose accuracy: Evaluates the efficiency of the LLM in figuring out and attaining the objectives of the person. May be evaluated with reference datasets the place “right” objectives are recognized or with out them.
- Agent process adherence: Assesses whether or not the agent’s ultimate response satisfies the unique person request.
- Instrument name accuracy: Measures whether or not the agent accurately identifies and calls exterior instruments or features required to finish a process (e.g., calling a climate API when requested about climate).
- Response high quality (correctness / faithfulness): Past success/failure, evaluates whether or not the output is correct and corresponds to floor fact or exterior information sources. Metrics akin to correctness and faithfulness assess output validity and reliability.
Why these matter: Practical metrics validate whether or not agentic workflows remedy the issue they have been constructed to resolve and are sometimes the primary line of analysis in playgrounds or take a look at environments.
Operational metrics
Operational metrics quantify system effectivity, responsiveness, and the usage of computational sources throughout execution.
Key operational metrics
- Time to first token (TTFT): Measures the delay between sending a immediate to the agent and receiving the primary mannequin response token. It is a widespread latency measure in generative AI methods and important for person expertise.
- Latency & throughput: Measures of whole response time and tokens per second that point out responsiveness at scale.
- Compute utilization: Tracks how a lot GPU, CPU, and reminiscence the agent consumes throughout inference or execution. This helps establish bottlenecks and optimize infrastructure utilization.
Why these matter: Operational metrics be sure that workflows not solely work however achieve this effectively and predictably, which is important for SLA compliance and manufacturing readiness.
Safety and security metrics
Safety metrics consider dangers associated to information publicity, immediate injection, PII leakage, hallucinations, scope violation, and management entry inside agentic environments.
Safety controls & metrics
- Security metrics: Actual-time guards evaluating if agent outputs adjust to security and behavioral expectations, together with detection of poisonous or dangerous language, identification and prevention of PII publicity, prompt-injection resistance, adherence to subject boundaries (stay-on-topic), and emotional tone classification, amongst different safety-focused controls.
- Entry administration and RBAC: Function-based entry management (RBAC) ensures that solely approved customers can view or modify workflows, datasets, or monitoring dashboards.
- Authentication compliance (OAuth, SSO): Imposing safe authentication (OAuth 2.0, single sign-on) and logging entry makes an attempt helps audit trails and reduces unauthorized publicity.
Why these matter: Brokers typically course of delicate information and might work together with enterprise methods; safety metrics are important to stop information leaks, abuse, or exploitation.
Financial & value metrics
Financial metrics quantify the associated fee effectivity of workflows and assist groups monitor, optimize, and finances agentic AI purposes.
Frequent financial metrics
- Token utilization: Monitoring the variety of immediate and completion tokens used per interplay helps perceive billing affect since many suppliers cost per token.
- General value and value per process: Aggregates efficiency and value metrics (e.g., value per profitable process) to estimate ROI and establish inefficiencies.
- Infrastructure prices (GPU/CPU Minutes): Measures compute value per process or session, enabling groups to attribute workload prices and align finances forecasting.
Why these matter: Financial metrics are essential for sustainable scale, value governance, and displaying enterprise worth past engineering KPIs.
Governance and compliance frameworks for brokers
Governance and compliance measures guarantee workflows are traceable, auditable, compliant with rules, and ruled by coverage. Governance will be labeled broadly into 3 classes.
Governance within the face of:
- Safety Dangers
- Operational Dangers
- Regulatory Dangers
Basically, they should be ingrained in the complete agent improvement and deployment course of, versus being bolted on afterwards.
Safety threat governance framework
Making certain safety coverage enforcement requires monitoring and adhering to organizational insurance policies throughout agentic methods.
Duties embrace, however are usually not restricted to, validation and enforcement of entry administration by authentication and authorization that mirror broader organizational entry permissions for all instruments and enterprise methods that brokers entry.
It additionally contains establishing and implementing sturdy, auditable approval workflows to stop unauthorized or unintended deployments and updates to agentic methods inside the enterprise.
Operational threat governance framework
Making certain operational threat governance requires monitoring, evaluating, and implementing adherence to organizational insurance policies akin to privateness necessities, prohibited outputs, equity constraints, and red-flagging cases the place insurance policies are violated.
Past alerting, operational threat governance methods for brokers ought to present efficient real-time moderation and intervention capabilities to deal with undesired inputs or outputs.
Lastly, a important element of operational threat governance includes lineage and versioning, together with monitoring variations of brokers, instruments, prompts, and datasets utilized in agentic workflows to create an auditable file of how selections have been made and to stop behavioral drift throughout deployments.
Regulatory threat governance framework
Making certain regulatory threat governance requires validating that every one agentic methods adjust to relevant industry-specific and authorities rules, insurance policies, and requirements.
This contains, however is just not restricted to, testing for compliance with frameworks such because the EU AI Act, NIST RMF, and different country- or state-level tips to establish dangers together with bias, hallucinations, toxicity, immediate injection, and PII leakage.
Why governance metrics matter
Governance metrics cut back authorized and reputational publicity whereas assembly rising regulatory and stakeholder expectations round trustworthiness and equity. They supply enterprises with the arrogance that agentic methods function inside outlined safety, operational, and regulatory boundaries, at the same time as workflows evolve over time.
By making coverage enforcement, entry controls, lineage, and compliance repeatedly measurable, governance metrics allow organizations to scale agentic AI responsibly, keep auditability, and reply rapidly to rising dangers with out slowing innovation.
Turning agentic AI into dependable, production-ready methods
Agentic AI introduces a essentially new working mannequin for enterprise automation, one the place methods purpose, plan, and act autonomously at machine pace.
This enhanced energy comes with threat. Organizations that succeed with agentic AI are usually not those with probably the most spectacular demos, however the ones that rigorously consider habits, monitor methods repeatedly in manufacturing, and embed governance throughout the complete agent lifecycle. Reliability, security, and scale are usually not unintentional outcomes. They’re engineered by disciplined metrics, observability, and management.
If you happen to’re working to maneuver agentic AI from proof of idea into manufacturing, adopting a full-lifecycle method can assist cut back threat and enhance reliability. Platforms akin to DataRobot help this by bringing collectively analysis, monitoring, tracing, and governance to provide groups higher visibility and management over agentic workflows.
To see how these capabilities will be utilized in apply, you’ll be able to discover a free DataRobot demo.















")




{kind=link}