


Picture by Creator
# Introducing the Experiment
Hyperparameter tuning is commonly touted as a magic bullet for machine studying. The promise is easy: tweak some parameters for a couple of hours, run a grid search, and watch your mannequin’s efficiency soar.
However does it truly work in observe?

Picture by Creator
We examined this premise on Portuguese scholar efficiency knowledge utilizing 4 completely different classifiers and rigorous statistical validation. Our method utilized nested cross-validation (CV), sturdy preprocessing pipelines, and statistical significance testing — the entire 9 yards.
The end result? efficiency dropped by 0.0005. That’s proper — tuning truly made the outcomes barely worse, although the distinction was not statistically vital.
Nevertheless, this isn’t a failure story. It’s one thing extra helpful: proof that in lots of circumstances, default settings work remarkably effectively. Typically one of the best transfer is understanding when to cease tuning and focus your efforts elsewhere.
Need to see the complete experiment? Try the full Jupyter pocket book with all code and evaluation.
# Setting Up the Dataset

Picture by Creator
We used the dataset from StrataScratch’s “Scholar Efficiency Evaluation” venture. It comprises data for 649 college students with 30 options masking demographics, household background, social components, and school-related data. The target was to foretell whether or not college students move their closing Portuguese grade (a rating of ≥ 10).
A essential resolution on this setup was excluding the G1 and G2 grades. These are first- and second-period grades that correlate 0.83–0.92 with the ultimate grade, G3. Together with them makes prediction trivially straightforward and defeats the aim of the experiment. We wished to establish what predicts success past prior efficiency in the identical course.
We used the pandas library to load and put together the information:
# Load and put together knowledge
df = pd.read_csv('student-por.csv', sep=';')
# Create move/fail goal (grade >= 10)
PASS_THRESHOLD = 10
y = (df['G3'] >= PASS_THRESHOLD).astype(int)
# Exclude G1, G2, G3 to forestall knowledge leakage
features_to_exclude = ['G1', 'G2', 'G3']
X = df.drop(columns=features_to_exclude)
The category distribution confirmed that 100 college students failed (15.4%) whereas 549 handed (84.6%). As a result of the information is imbalanced, we optimized for the F1-score somewhat than easy accuracy.
# Evaluating the Classifiers
We chosen 4 classifiers representing completely different studying approaches:

Picture by Creator
Every mannequin was initially run with default parameters, adopted by tuning through grid search with 5-fold CV.
# Establishing a Sturdy Methodology
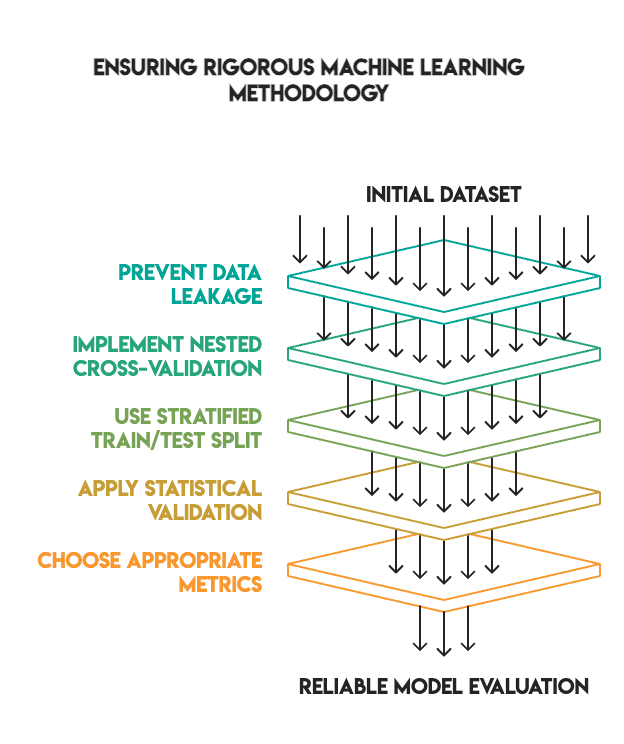
Many machine studying tutorials reveal spectacular tuning outcomes as a result of they skip essential validation steps. We maintained a excessive normal to make sure our findings have been dependable.
Our methodology included:
- No knowledge leakage: All preprocessing was carried out inside pipelines and match solely on coaching knowledge
- Nested cross-validation: We used an internal loop for hyperparameter tuning and an outer loop for closing analysis
- Applicable prepare/take a look at cut up: We used an 80/20 cut up with stratification, retaining the take a look at set separate till the top (i.e., no “peeking”)
- Statistical validation: We utilized McNemar’s take a look at to confirm if the variations in efficiency have been statistically vital
- Metric choice: We prioritized the F1-score for imbalanced lessons somewhat than accuracy
Picture by Creator
The pipeline construction was as follows:
# Preprocessing pipeline - match solely on coaching folds
numeric_transformer = Pipeline([
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline([
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# Mix transformers
from sklearn.compose import ColumnTransformer
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, X.select_dtypes(include=['int64', 'float64']).columns),
('cat', categorical_transformer, X.select_dtypes(embrace=['object']).columns)
])
# Full pipeline with mannequin
pipeline = Pipeline([
('preprocessor', preprocessor),
('classifier', model)
])
# Analyzing the Outcomes
After finishing the tuning course of, the outcomes have been stunning:
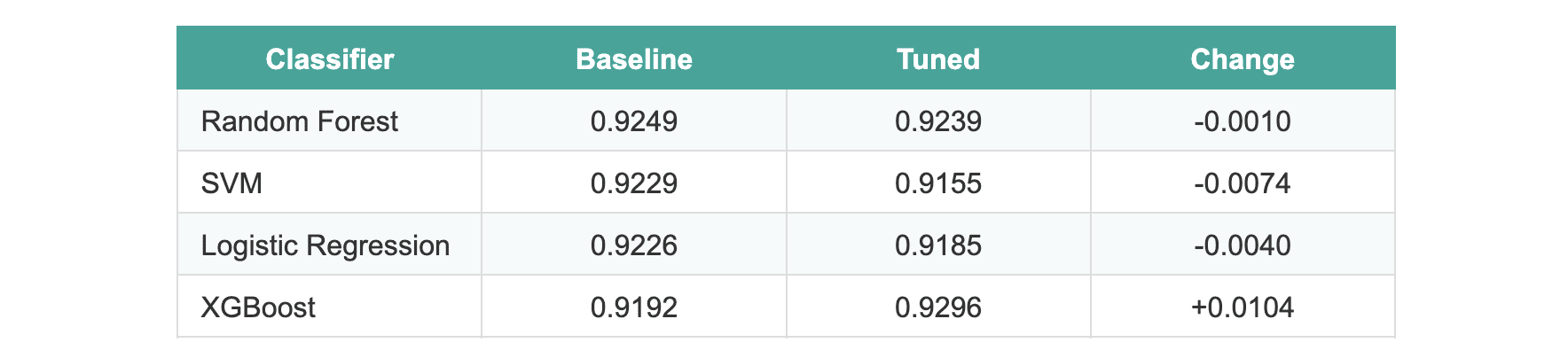
The common enchancment throughout all fashions was -0.0005.
Three fashions truly carried out barely worse after tuning. XGBoost confirmed an enchancment of roughly 1%, which appeared promising till we utilized statistical assessments. When evaluated on the hold-out take a look at set, not one of the fashions exhibited statistically vital variations.
We ran McNemar’s take a look at evaluating the 2 best-performing fashions (random forest versus XGBoost). The p-value was 1.0, which interprets to no vital distinction between the default and tuned variations.
# Explaining Why Tuning Failed

Picture by Creator
A number of components clarify these outcomes:
- Sturdy defaults. scikit-learn and XGBoost ship with extremely optimized default parameters. Library maintainers have refined these values over years to make sure they work successfully throughout all kinds of datasets.
- Restricted sign. After eradicating the G1 and G2 grades (which might have brought on knowledge leakage), the remaining options had much less predictive energy. There merely was not sufficient sign left for hyperparameter optimization to use.
- Small dataset dimension. With solely 649 samples cut up into coaching folds, there was inadequate knowledge for the grid search to establish actually significant patterns. Grid search requires substantial knowledge to reliably distinguish between completely different parameter units.
- Efficiency ceiling. Most baseline fashions already scored between 92–93% F1. There may be naturally restricted room for enchancment with out introducing higher options or extra knowledge.
- Rigorous methodology. Whenever you remove knowledge leakage and make the most of nested CV, the inflated enhancements usually seen in improper validation disappear.
# Studying From the Outcomes
Picture by Creator
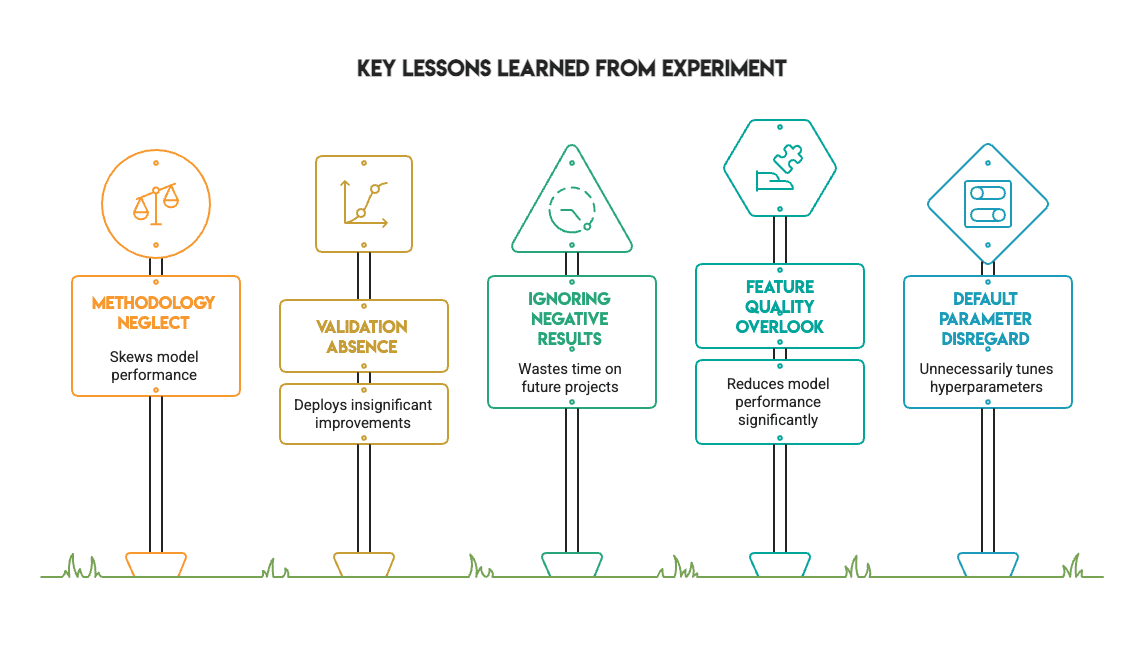
This experiment supplies a number of helpful classes for any practitioner:
- Methodology issues greater than metrics. Fixing knowledge leakage and utilizing correct validation adjustments the end result of an experiment. The spectacular scores obtained from improper validation evaporate when the method is dealt with accurately.
- Statistical validation is important. With out McNemar’s take a look at, we’d have incorrectly deployed XGBoost based mostly on a nominal 1% enchancment. The take a look at revealed this was merely noise.
- Detrimental outcomes have immense worth. Not each experiment wants to point out an enormous enchancment. Figuring out when tuning doesn’t assist saves time on future tasks and is an indication of a mature workflow.
- Default hyperparameters are underrated. Defaults are sometimes ample for traditional datasets. Don’t assume you should tune each parameter from the beginning.
# Summarizing the Findings
We tried to spice up mannequin efficiency by way of exhaustive hyperparameter tuning, following business greatest practices and making use of statistical validation throughout 4 distinct fashions.
The end result: no statistically vital enchancment.

Picture by Creator
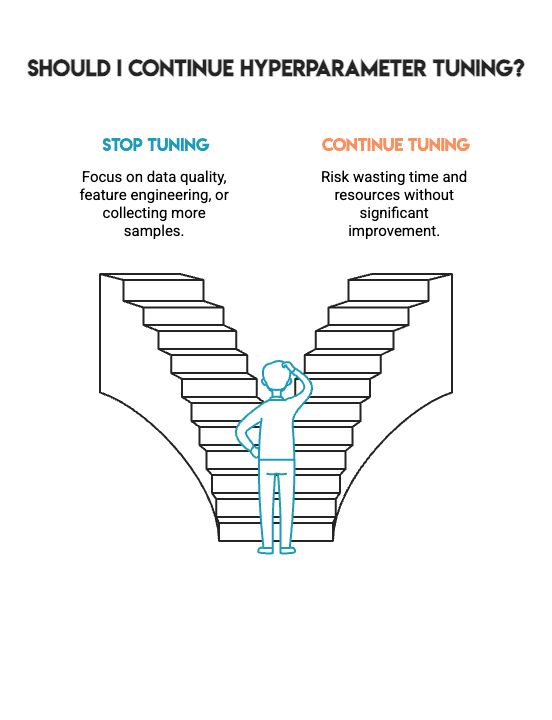
That is *not* a failure. As an alternative, it represents the form of sincere outcomes that can help you make higher selections in real-world venture work. It tells you when to cease hyperparameter tuning and when to shift your focus towards different essential features, akin to knowledge high quality, function engineering, or gathering further samples.
Machine studying isn’t about attaining the best attainable quantity by way of any means; it’s about constructing fashions that you could belief. That belief stems from the methodological course of used to construct the mannequin, not from chasing marginal good points. The toughest talent in machine studying is understanding when to cease.
Picture by Creator
Nate Rosidi is an information scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to knowledge scientists put together for his or her interviews with actual interview questions from prime corporations. Nate writes on the most recent tendencies within the profession market, provides interview recommendation, shares knowledge science tasks, and covers the whole lot SQL.





















{kind=link}