The outcomes of installs and upgrades may be completely different every time, even with the very same mannequin, but it surely will get loads worse if you happen to improve or swap fashions. When you’re supporting infrastructure for 5, 10, or 20 years, you will be upgrading fashions. It’s arduous to even think about what the world of generative AI will appear like in 10 years, however I’m positive Gemini 3 and Claude Opus 4.5 won’t be round then.
The risks of AI brokers enhance with complexity
Enterprise “functions” are not single servers. Right now they’re constellations of techniques—internet entrance ends, software tiers, databases, caches, message brokers, and extra—usually deployed in a number of copies throughout a number of deployment fashions. Even with solely a handful of service sorts and three primary footprints (packages on a standard server, picture‑primarily based hosts, and containers), the mixtures broaden into dozens of permutations earlier than anybody has written a line of enterprise logic. That complexity makes it much more tempting to ask an agent to “simply deal with it”—and much more harmful when it does.
In cloud‑native outlets, Kubernetes solely amplifies this sample. A “easy” software would possibly span a number of namespaces, deployments, stateful units, ingress controllers, operators, and exterior managed companies, all stitched collectively by means of YAML and Customized Useful resource Definitions (CRDs). The one sane option to run that at scale is to deal with the cluster as a declarative system: GitOps, immutable photos, and YAML saved someplace outdoors the cluster, and model managed. In that world, the job of an agentic AI is to not sizzling‑patch working pods, nor the Kubernetes YAML; it’s to assist people design and take a look at the manifests, Helm charts, and pipelines that are saved in Git.
It’s a recurring function of anti-ICE protests: the presence of pastors, clergymen, and reverends on the entrance strains of demonstrations, and behind-the-scenes, organizing of their communities.
Non secular leaders in Minnesota have been each publicly and quietly tending to their communities within the wake of ICE and DHS surges to the state as a part of the Trump administration’s mass deportation agenda.
Many view this second as a time for ethical readability and resistance. However not each congregation or denomination is responding in the identical approach.
There’s each purpose to imagine this dynamic will intensify as long as ICE continues to function within the state.
In Chicago final yr, non secular leaders had been pepper sprayed or shot with pepper balls. In Minneapolis this month, they’ve joined protesters in calling for restraint from federal brokers and humane therapy of immigrants. And nationally, there’s rising realization from some leaders of the necessity for ethical readability and pushback to the Trump administration.
However non secular leaders and their followers aren’t all reacting in the identical strategy to the federal authorities’s mass deportation surges.
A latest anti-ICE protest in St. Paul, which interrupted a service at a Southern Baptist church with alleged ties to US Immigration and Customs Enforcement, grabbed nationwide consideration, sparked outrage from the non secular proper, and impelled the White Home to vow arrests and investigations. And it additionally triggered responses from some Christian leaders who’ve been extra reticent to criticize the administration.
To interrupt down these divisions and the completely different ways in which non secular leaders in and past Minnesota are responding, I made a decision to ask an professional. Jack Jenkins is a nationwide reporter for the Faith Information Service, the place he covers faith and politics. He spoke to me in between journeys to Minneapolis, the place multifaith leaders can be assembly this week to prepare and focus on methods to are inclined to their communities and reply to ICE’s presence.
Our dialog has been edited for size and readability.
I need to begin off with a hen’s-eye view. Are you able to describe how non secular communities, each believers and their leaders, are responding to ICE’s presence in Minnesota proper now?
I spent most of my time in Minneapolis and it’s a lot simpler to seek out somebody who’s vehemently against ICE than the other. I feel for lots of religion communities there’s a direct concern for the individuals they serve.
For example, pastors that oversee immigrant-heavy congregations. I spoke to a pastor on the market; that’s lots of stress. They’re additionally very a lot organizing, however for a wide range of causes that organizing isn’t essentially public. And it’s comparatively uncommon for lots of these pastors to be at the same time as public or speaking to the press due to considerations for his or her neighborhood. And that’s not simply Christian pastors, that’s additionally imams as a result of the Somali American neighborhood additionally has turn out to be a goal of this administration.
Then there’s additionally this piece of non secular communities that aren’t as in danger, not as weak, who’ve been very concerned in pushback to ICE and to DHS brokers. That runs the gamut. There’s one church particularly who helps collect meals and provides to feed massive numbers of immigrant households which can be afraid to depart their houses within the midst of heavy DHS presence within the area. Lots of church buildings are concerned in that form of effort.
There’s additionally extra direct acts of resistance too, although, aren’t there?
Sure. I rode together with a pastor who was concerned in patrolling the neighborhood the place she lives, which occurs to be the identical neighborhood the place Renee Good was killed, on the lookout for DHS brokers. Within the hour and a half that I rode alongside along with her, we noticed possible DHS brokers at the least twice as they had been driving by being tailed by different vehicles that had been honking horns and blowing whistles to alert the neighborhood.
Even after Renee Good was killed, there have been a number of clergy that ran to the location of the killing, together with that very same Unitarian minister, Reverend Ashley Horan, who lives a block away, to attempt to present some degree of quick response. Each that pastor and one other had been shot at or hit with pepper spray or pepper powder.
However once I was patrolling that space with that pastor, each different nook had someone with a whistle round their neck searching for DHS. Religion teams are very a lot part of that.
Does there appear to be any distinction in how religion leaders or communities inside the state are responding in comparison with how voices nationally are speaking about this?
“We’re seeing way more religion leaders get immediately concerned as cities are focused.”
Non secular pushback to President Trump’s mass deportation agenda started on day one.
There was that sermon that Bishop Mariann Budde, the Episcopal bishop of Washington, gave on the Washington Nationwide Cathedral with Trump sitting within the pews in entrance of her asking the president to have mercy on immigrants. That drew headlines. Non secular pushback to his immigration insurance policies hasn’t let up since. We’ve had two popes criticize Trump’s immigration insurance policies. Pope Leo particularly addressed considerations about whether or not detainees in Chicago had been being granted entry to religion leaders.
However what’s fascinating is what has occurred because the administration has launched concentrated efforts in numerous cities. Early on, I lined a pastor in Southern California the place obvious DHS brokers confirmed up on her church property. She ran out and filmed them, demanding they depart. Equally in California, a pastor bought a name that two parishioners had been being detained. He ran out and filmed the DHS brokers whereas questioning them.
As these campaigns moved from LA to Portland to DC to Chicago to North Carolina, religion leaders have instructed me they had been in dialog with clergy in cities focused earlier, coaching them and sharing details about tips on how to push again towards ICE and DHS. When Border Patrol had an inflow of brokers in Charlotte, inside 24 to 48 hours, a whole lot of individuals packed church buildings internet hosting ICE watch trainings. These trainings had really been deliberate months earlier.
We’re seeing way more religion leaders get immediately concerned as cities are focused. Chicago was a superb instance, the place religion leaders had been arrested at one protest outdoors a DHS facility. That possible wouldn’t have occurred with out these concentrated campaigns.
I need to ask in regards to the outrage after the ICE protest that interrupted a church service in St. Paul. What occurred?
The allegation, which I can’t independently affirm, is that one of many pastors of that church can be head of a neighborhood ICE or DHS workplace. Previous variations of the church web site checklist him as having been concerned in regulation enforcement. That seems to have been the impetus for that protest.
What adopted was fascinating. Even non secular leaders essential of DHS had been uneasy with the character of that protest and stated so publicly. On the similar time, many had been pissed off by the administration’s response and by conservative Christian responses, as a result of dozens of religion teams have opposed DHS actions, have signed onto lawsuits towards the administration for claims of violations of non secular freedom.
In Chicago final yr, viral footage confirmed DHS brokers capturing a Presbyterian minister within the head with pepper balls. I’ve spoken to a number of pastors who’ve been hit with pepper spray or pepper balls. By my depend, between eight and 10 pastors over the past yr. That Presbyterian minister, Reverend David Black, was a part of a lawsuit that received a brief restraining order primarily based on non secular freedom claims.
Some religion leaders argue there’s a selective concern for non secular liberty. One activist concerned in that St. Paul protest stated, paraphrasing, that homes of worship are both sanctuaries or they’re not. Who will get consideration for non secular freedom considerations has turn out to be a operating theme.
What about Catholic leaders? I’ve seen criticism about once they do or don’t communicate up, towards Trump, particularly a number of the most vocal Catholic bishops, like Robert Barron, a conservative leaning Catholic media mogul, and the bishop of the diocese of Winona-Rochester in Minnesota.
It’s very uncommon to see a bishop concerned in a protest. That’s why it stood out when an auxiliary bishop in Chicago participated in an indication outdoors a DHS facility over detainees being denied entry to clergymen. There may be additionally a lawsuit filed by Catholic organizations, clergymen, and nuns on that concern.
There’s been a clumsy dance the place the pope has typically spoken louder and quicker than native bishops. The US Convention of Catholic Bishops has issued a essential assertion and video opposing the administration’s immigration insurance policies, and the convention has sued the administration earlier than.
Now Bishop Barron is an fascinating determine. He sits on the president’s Non secular Liberty Fee and has monumental affect. When considerations had been raised about detainee entry to clergymen, Barron joined in voicing concern, however later emphasised that he was not criticizing the administration.
There’s growing rigidity contained in the bishops’ convention. Teams of bishops are issuing statements independently on immigration. That didn’t use to occur. It displays deeper division over how to reply to the president’s immigration agenda.
Why does that division exist?
Some bishops occupy completely different institutional positions. Sitting on a federal non secular liberty fee is completely different than main a diocese. Holding management inside the USCCB convention issues. Since Pope Francis and now Pope Leo, the pope has typically been extra vocal than the convention as a complete, which creates rigidity. Now that there’s an American pope from Chicago, these tensions are sharper.
Let me ask you a few quote from a bishop in New England. You spoke to him as a result of he attracted consideration for telling different religion leaders that the time is coming when they might need to to “put [their] our bodies on the road.” What did he imply by that?
Once I spoke to the Episcopal bishop of New Hampshire, who stated clergy ought to get their “wills so as,” he instructed me he’s stated comparable issues up to now round gun management advocacy. He was seconded by the Episcopal bishop of Minnesota. In Chicago, greater than 200 religion leaders signed a letter referencing placing their our bodies on the road.
Many reference Selma, the protests and marches of the civil rights motion, clergy who had been killed there, and figures like Bonhoeffer, the Lutheran pastor who was in the end killed for his half in an try to assassinate Adolf Hitler. Many religion leaders I communicate to say these in additional privileged positions ought to go first as a result of they’re least weak. If religion leaders aren’t doing it, they argue, then who will?
Ought to we count on extra of this?
I’m about to return to Minneapolis for a gathering of clergy from across the nation. They’re explicitly likening it to a name to Selma. So long as the administration continues focused campaigns in cities, I’d count on extra of this.
Most animals could be afraid to go close to a crocodile, however biting flies haven’t any qualms about touchdown on this fearsome predator and ingesting its blood. This photograph, taken by Zeke Rowe in Panama’s Coiba Nationwide Park, was chosen as the general winner of the British Ecological Society’s annual Capturing Ecology pictures competitors.
“This crocodile was lurking in a tidal marsh off the seaside,” mentioned Rowe, a PhD candidate at Vrije Universiteit Amsterdam within the Netherlands, in an announcement. “I received as shut and low as I dared, ready for that direct eye contact.”
Cape sparrows and different birds disturbed by a lioness
Willem Kruger/British Ecological Society
The judges additionally chosen 10 class winners, together with this shot by Willem Kruger, a South African-based photographer, which received within the interactions class. Through the dry season in Kgalagadi Transfrontier Park on the border between South Africa and Botswana, flocks of birds have been ingesting at a waterhole when a satisfaction of lions approached, scaring the birds away.
Wallace’s flying frog
Jamal Kabir/British Ecological Society
Jamal Kabir on the College of Nottingham, UK, received within the animals class with this picture of a Wallace’s flying frog (Rhacophorus nigropalmatus). These amphibians, named for the biologist Alfred Russel Wallace, use their webbed toes to glide between timber within the rainforests of South-East Asia.
A bighorn sheep has its nosed swabbed
Peter Hudson/British Ecological Society
A bighorn sheep (Oviscanadensis) within the Rocky mountains has its nostril swabbed on this photograph by Peter Hudson, a photographer and biologist at Penn State College, which was extremely counseled within the ecologists in motion class. Pneumonia is a serious situation for bighorn herds, usually wiping out younger lambs within the spring. Researchers suspected that asymptomatic adults have been spreading the illness to susceptible children, in order that they applied a marketing campaign to check wild sheep and deal with the contaminated people. This helped to scale back mortality and let populations get well.
Fly on mushroom
Francisco Gamboa/British Ecological Society
Within the mountainous Altos de Cantillana nature reserve in Chile, wildlife photographer Francisco Gamboa captured this photograph of a fly resting on a mushroom, which received within the vegetation and fungi class.
Intertidal schooling
Liam Brennan/British Ecological Society
In one other extremely counseled picture from the ecologists in motion class, taken by wildlife researcher and photographer Liam Brennan, three undergraduate college students are utilizing a seaside seine – a kind of fishing internet – to rely coastal fish species in New Brunswick, Canada, as a part of a mission monitoring seasonal inhabitants adjustments.
Insect and ecosystems expedition safari: Sri Lanka
Journey into the richly biodiverse coronary heart of Sri Lanka on this distinctive entomology and ecosystems-focused expedition.
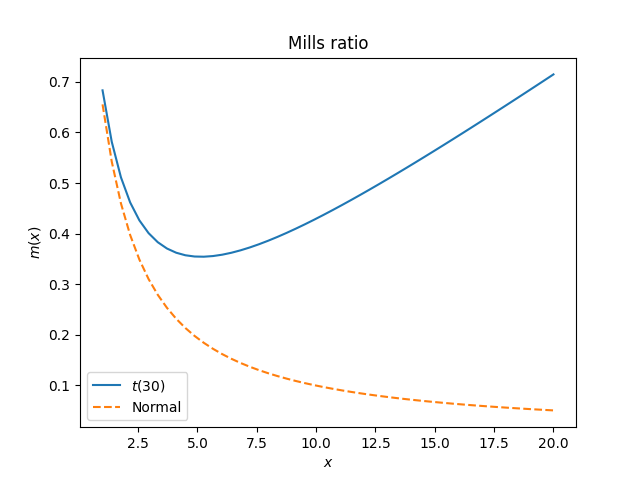
The Mills ratio [1] is the ratio of the CCDF to the PDF. That’s, for a random variable X, the Mills ratio at x is the complementary cumulative distribution perform divided by the density perform. If the density perform of X is f, then
The Mills ratio highlights an necessary distinction between the Pupil t distribution and the conventional distribution.
Introductory statistics courses will say issues like “you possibly can approximate a t distribution with a standard if it has greater than 30 levels of freedom.” Which may be true, relying on the appliance. A t(30) distribution and a standard distribution behave equally within the center however not within the tails.
The Mills ratio for a t distribution with ν levels of freedom is asymptotically x/ν, whereas the Mills ratio for the standard regular distribution is asymptotically 1/x. Observe that rising ν does make the Mills perform smaller, nevertheless it nonetheless ultimately grows linearly whereas the Mills perform of a standard distribution decays linearly.
Usually, the Mills ratio is a reducing perform for thin-tailed distributions and an rising perform for fat-tailed distributions. The exponential distribution is within the center, with fixed Mills perform.
Associated posts
[1] Named after John P. Mills, so there’s no apostrophe earlier than the s.
Right now’s manufacturing facility flooring are buzzing with innovation, pushed by synthetic intelligence, automation, and hyper-automation. From autonomous automobiles gracefully navigating warehouses to vertical farms rising crops with unprecedented precision, the economic panorama is present process a radical transformation. However behind each good robotic and each AI-powered system lies a vital, usually invisible, hero: the community.
Conventional Wi-Fi, whereas nice in your laptop computer, usually struggles to maintain up with the acute calls for of commercial environments. Think about difficult situations: quite a few obstacles and vital RF interference severely impacting wi-fi connectivity, all whereas requiring absolute, unwavering connection for transferring equipment. That is the place the rubber meets the highway – or relatively, the place the wi-fi meets the robotic.
E80 Group: A serious participant in automation, E80 focuses on automated warehouses and their flagship product, Laser-Guided Autos (LGVs). These autonomous automobiles must obtain instructions and knowledge seamlessly, working in vegetation with dozens and even tons of of automobiles, all assembly tight deadlines. Any community slowdown or outage can deliver a whole operation to a halt.
Planet Farms: Revolutionizing agriculture with vertical farming, Planet Farms manages plant development in absolutely climate-controlled environments. Their amenities are a symphony of AI programs performing duties as soon as dealt with by agronomists, and automatic robots doing the work of farmers. Cameras monitor each plant, and 3D photos are transmitted and processed continually, demanding a community much more refined than typical agricultural wants.
The Problem: Wired Reliability, Wirelessly Delivered
In industrial IoT and robotic mobility, each wired and wi-fi networks should ship resilience, responsiveness, and ultra-low latency. These should not simply buzzwords; they’re non-negotiable necessities for security and effectivity. For transferring property like AGVs, shedding connection isn’t simply an inconvenience – it will probably imply a security cease, halting manufacturing.
That is exactly why Cisco’s Extremely-Dependable Wi-fi Backhaul (URWB) know-how is a game-changer. It’s the closest factor in wi-fi to a wired community, providing unparalleled reliability within the hardest environments. As highlighted by the interview contributors, URWB was chosen as a result of it gives the resilience, responsiveness, and ultra-low latency important for AI-powered industrial automation. For Planet Farms, coping with difficult situations like excessive humidity, water, and low temperatures, URWB delivers the bodily reliability vital for his or her operations, making certain their autonomous programs keep related and responsive.
Why URWB Over 5G? Simplicity, Management, and Convergence
Each industrial surroundings is exclusive and choosing the proper wi-fi answer is essential. With the rise of 5G, many marvel why industrial leaders like E80 and Planet Farms would go for URWB. Each firms extensively studied 5G, even operating pilots. Their conclusion? Cisco’s URWB answer provided the reliability they wanted for his or her purposes and clear benefits for his or her particular eventualities.
Throughout the interview, representatives from E80 Group and Planet Farms defined their resolution to decide on URWB over 5G for his or her industrial networks. They famous that 4G and 5G options had been usually extra advanced and costly to handle in comparison with URWB. A key differentiator was Cisco’s integration of URWB and Wi-Fi, which permits for using a single infrastructure to assist each industrial machines and typical consumer gadgets like laptops and tablets – a functionality not simply matched by 5G. For Planet Farms, as an organization born within the digital transformation period, the convergence of IT and OT applied sciences was paramount, making Cisco’s answer extremely preferable for its value, reliability, and consistency in manufacturing. Moreover, they discovered that URWB provided simpler community governance, permitting them to retain full management over their community, much like conventional Wi-Fi.
Right here’s a abstract of why URWB stood out:
Complexity and Value: 4G and 5G networks are sometimes extra advanced and costly to handle than URWB, making them much less ideally suited for devoted industrial purposes the place effectivity and cost-effectiveness are paramount.
Unified Infrastructure: Cisco has built-in URWB and Wi-Fi, permitting firms to make use of the similar infrastructure for each industrial machines (like AGVs) and typical consumer gadgets (laptops, tablets). This convergence simplifies administration and reduces operational overhead – one thing not simply achievable with 5G.
IT/OT Convergence: For younger, digitally native firms like Planet Farms, there’s no distinction between Data Know-how (IT) and Operational Know-how (OT). Convergent applied sciences are extremely preferable, enabling a holistic view and administration of their total operation.
Management and Governance: URWB gives simpler community governance, permitting firms to retain full management over their industrial community, very similar to conventional Wi-Fi. This degree of autonomy is essential for delicate industrial processes.
Reliability and Consistency: Each E80 and Planet Farms discovered Cisco’s answer preferable for its cost-effectiveness, reliability, and consistency in manufacturing environments.
The Energy of Integration: Simplifying Operations, Boosting Safety
The mixing of URWB with current Cisco Wi-Fi entry factors is a game-changer. It means you possibly can activate this cutting-edge know-how in your present Cisco Wi-fi infrastructure that may be managed from a single pane of glass. This dramatically saves value, lowers complexity, streamlines governance, and fortifies cybersecurity.
Think about AGVs transferring throughout an unlimited facility with out ever dropping a connection, due to URWB’s seamless roaming capabilities. This uninterrupted mobility is significant for security and steady automation. And on the similar time, the identical entry factors operating URWB can ship entry to Wi-Fi gadgets.
Moreover, Cisco’s industrial switches, coupled with options like Cyber Imaginative and prescient for community visibility and safety, and ISE for system authentication, deliver safety proper to the machines. This “safety near the sting” is basically completely different and more practical than conventional IT safety fashions when coping with industrial protocols and environments.
The community is the nervous system of commercial AI and automation. By offering safe, high-performing, and versatile community infrastructure, Cisco empowers innovators like E80 Group and Planet Farms to push the boundaries of what’s attainable, driving effectivity, security, and unprecedented development.
Wish to be taught extra about how Cisco’s industrial networking options can rework your operations? Discover our choices at Cisco Industrial Networking Options.
It’s straightforward to get caught up within the technical facet of information science like perfecting your SQL and pandas expertise, studying machine studying frameworks, and mastering libraries like Scikit-Study. These expertise are priceless, however they solely get you to date. With no sturdy grasp of the statistics behind your work, it’s troublesome to inform when your fashions are reliable, when your insights are significant, or when your information is likely to be deceptive you.
The very best information scientists aren’t simply expert programmers; additionally they have a powerful understanding of information. They know easy methods to interpret uncertainty, significance, variation, and bias, which helps them assess whether or not outcomes are dependable and make knowledgeable choices.
On this article, we’ll discover seven core statistical ideas that present up again and again in information science — comparable to in A/B testing, predictive modeling, and data-driven decision-making. We are going to start by trying on the distinction between statistical and sensible significance.
# 1. Distinguishing Statistical Significance from Sensible Significance
Right here is one thing you’ll run into typically: You run an A/B take a look at in your web site. Model B has a 0.5% increased conversion price than Model A. The p-value is 0.03 (statistically important!). Your supervisor asks: “Ought to we ship Model B?”
The reply may shock you: perhaps not. Simply because one thing is statistically important does not imply it issues in the actual world.
Statistical significance tells you whether or not an impact is actual (not as a result of probability)
Sensible significance tells you whether or not that impact is large enough to care about
As an example you’ve got 10,000 guests in every group. Model A converts at 5.0% and Model B converts at 5.05%. That tiny 0.05% distinction might be statistically important with sufficient information. However here is the factor: if every conversion is value $50 and also you get 1 million annual guests, this enchancment solely generates $2,500 per yr. If implementing Model B prices $10,000, it isn’t value it regardless of being “statistically important.”
All the time calculate impact sizes and enterprise impression alongside p-values. Statistical significance tells you the impact is actual. Sensible significance tells you whether or not you must care.
# 2. Recognizing and Addressing Sampling Bias
Your dataset isn’t an ideal illustration of actuality. It’s all the time a pattern, and if that pattern is not consultant, your conclusions will probably be improper regardless of how refined your evaluation.
Sampling bias occurs when your pattern systematically differs from the inhabitants you are attempting to know. It is one of the crucial frequent causes fashions fail in manufacturing.
Here is a refined instance: think about you are attempting to know your common buyer age. You ship out an internet survey. Youthful prospects are extra probably to answer on-line surveys. Your outcomes present a mean age of 38, however the true common is 45. You’ve got underestimated by seven years due to the way you collected the information.
Take into consideration coaching a fraud detection mannequin on reported fraud circumstances. Sounds cheap, proper? However you are solely seeing the apparent fraud that obtained caught and reported. Refined fraud that went undetected is not in your coaching information in any respect. Your mannequin learns to catch the straightforward stuff however misses the really harmful patterns.
The way to catch sampling bias: Examine your pattern distributions to identified inhabitants distributions when doable. Query how your information was collected. Ask your self: “Who or what’s lacking from this dataset?”
# 3. Using Confidence Intervals
While you calculate a metric from a pattern — like common buyer spending or conversion price — you get a single quantity. However that quantity would not inform you how sure you need to be.
Confidence intervals (CI) offer you a spread the place the true inhabitants worth probably falls.
A 95% CI means: if we repeated this sampling course of 100 occasions, about 95 of these intervals would include the true inhabitants parameter.
As an example you measure buyer lifetime worth (CLV) from 20 prospects and get a mean of $310. The 95% CI is likely to be $290 to $330. This tells you the true common CLV for all prospects in all probability falls in that vary.
Here is the vital half: pattern dimension dramatically impacts CI. With 20 prospects, you might need a $100 vary of uncertainty. With 500 prospects, that vary shrinks to $30. The identical measurement turns into way more exact.
As an alternative of reporting “common CLV is $310,” you must report “common CLV is $310 (95% CI: $290-$330).” This communicates each your estimate and your uncertainty. Huge confidence intervals are a sign you want extra information earlier than making massive choices. In A/B testing, if the CI overlap considerably, the variants may not really be completely different in any respect. This prevents overconfident conclusions from small samples and retains your suggestions grounded in actuality.
# 4. Deciphering P-Values Accurately
P-values are in all probability essentially the most misunderstood idea in statistics. Here is what a p-value really means: If the null speculation have been true, the chance of seeing outcomes no less than as excessive as what we noticed.
Here is what it does NOT imply:
The chance the null speculation is true
The chance your outcomes are as a result of probability
The significance of your discovering
The chance of creating a mistake
Let’s use a concrete instance. You are testing if a brand new characteristic will increase consumer engagement. Traditionally, customers spend a mean of quarter-hour per session. After launching the characteristic to 30 customers, they common 18.5 minutes. You calculate a p-value of 0.02.
Improper interpretation: “There is a 2% probability the characteristic would not work.”
Proper interpretation: “If the characteristic had no impact, we might see outcomes this excessive solely 2% of the time. Since that is unlikely, we conclude the characteristic in all probability has an impact.”
The distinction is refined however vital. The p-value would not inform you the chance your speculation is true. It tells you ways stunning your information could be if there have been no actual impact.
Keep away from reporting solely p-values with out impact sizes. All the time report each. A tiny, meaningless impact can have a small p-value with sufficient information. A big, vital impact can have a big p-value with too little information. The p-value alone would not inform you what it’s essential to know.
# 5. Understanding Kind I and Kind II Errors
Each time you do a statistical take a look at, you can also make two sorts of errors:
Kind I Error (False Constructive): Concluding there’s an impact when there is not one. You launch a characteristic that does not really work.
Kind II Error (False Destructive): Lacking an actual impact. You do not launch a characteristic that truly would have helped.
These errors commerce off in opposition to one another. Scale back one, and also you usually improve the opposite.
Take into consideration medical testing. A Kind I error means a false constructive prognosis: somebody will get pointless therapy and nervousness. A Kind II error means lacking a illness when it is really there: no therapy when it is wanted.
In A/B testing, a Kind I error means you ship a ineffective characteristic and waste engineering time. A Kind II error means you miss an excellent characteristic and lose the chance.
Here is what many individuals do not realize: pattern dimension helps keep away from Kind II errors. With small samples, you will typically miss actual results even after they exist. Say you are testing a characteristic that will increase conversion from 10% to 12% — a significant 2% absolute carry. With solely 100 customers per group, you may detect this impact solely 20% of the time. You may miss it 80% of the time despite the fact that it is actual. With 1,000 customers per group, you will catch it 80% of the time.
That is why calculating required pattern dimension earlier than operating experiments is so vital. You’ll want to know in case you’ll really have the ability to detect results that matter.
# 6. Differentiating Correlation and Causation
That is essentially the most well-known statistical pitfall, but folks nonetheless fall into it continually.
Simply because two issues transfer collectively does not imply one causes the opposite. Here is an information science instance. You discover that customers who have interaction extra along with your app even have increased income. Does engagement trigger income? Possibly. However it’s additionally doable that customers who get extra worth out of your product (the actual trigger) each have interaction extra AND spend extra. Product worth is the confounder creating the correlation.
Customers who research extra are inclined to get higher take a look at scores. Does research time trigger higher scores? Partly, sure. However college students with extra prior data and better motivation each research extra and carry out higher. Prior data and motivation are confounders.
Corporations with extra staff are inclined to have increased income. Do staff trigger income? In a roundabout way. Firm dimension and progress stage drive each hiring and income will increase.
Listed here are a number of pink flags for spurious correlation:
Very excessive correlations (above 0.9) with out an apparent mechanism
A 3rd variable might plausibly have an effect on each
Time sequence that simply each pattern upward over time
Establishing precise causation is tough. The gold commonplace is randomized experiments (A/B checks) the place random project breaks confounding. You can too use pure experiments whenever you discover conditions the place project is “as if” random. Causal inference strategies like instrumental variables and difference-in-differences assist with observational information. And area data is important.
# 7. Navigating the Curse of Dimensionality
Newcomers typically suppose: “Extra options = higher mannequin.” Skilled information scientists know this isn’t right.
As you add dimensions (options), a number of dangerous issues occur:
Information turns into more and more sparse
Distance metrics grow to be much less significant
You want exponentially extra information
Fashions overfit extra simply
Here is the instinct. Think about you’ve got 1,000 information factors. In a single dimension (a line), these factors are fairly densely packed. In two dimensions (a airplane), they’re extra unfold out. In three dimensions (a dice), much more unfold out. By the point you attain 100 dimensions, these 1,000 factors are extremely sparse. Each level is way from each different level. The idea of “nearest neighbor” turns into nearly meaningless. There isn’t any such factor as “close to” anymore.
The counterintuitive consequence: Including irrelevant options actively hurts efficiency, even with the identical quantity of information. Which is why characteristic choice is vital. You’ll want to:
# Wrapping Up
These seven ideas kind the inspiration of statistical considering in information science. In information science, instruments and frameworks will preserve evolving. However the capacity to suppose statistically — to query, take a look at, and cause with information — will all the time be the ability that units nice information scientists aside.
So the following time you are analyzing information, constructing a mannequin, or presenting outcomes, ask your self:
Is that this impact large enough to matter, or simply statistically detectable?
Might my pattern be biased in methods I have never thought of?
What’s my uncertainty vary, not simply my level estimate?
Am I complicated statistical significance with fact?
What errors might I be making, and which one issues extra?
Am I seeing correlation or precise causation?
Do I’ve too many options relative to my information?
These questions will information you towards extra dependable conclusions and higher choices. As you construct your profession in information science, take the time to strengthen your statistical basis. It isn’t the flashiest ability, nevertheless it’s the one that may make your work really reliable. Comfortable studying!
Bala Priya C is a developer and technical author from India. She likes working on the intersection of math, programming, information science, and content material creation. Her areas of curiosity and experience embrace DevOps, information science, and pure language processing. She enjoys studying, writing, coding, and low! Presently, she’s engaged on studying and sharing her data with the developer neighborhood by authoring tutorials, how-to guides, opinion items, and extra. Bala additionally creates participating useful resource overviews and coding tutorials.
A distinction between two broadly used blood assessments for kidney well being could function an early warning signal for critical outcomes, together with kidney failure, coronary heart illness, and loss of life, in keeping with new analysis.
For a few years, medical doctors have relied on a blood marker known as creatinine to estimate how effectively the kidneys filter waste produced by muscle exercise. Newer medical tips additionally advocate measuring cystatin C, a small protein produced by all cells within the physique, as one other strategy to assess kidney perform. As a result of these two markers are affected by completely different organic processes, utilizing each collectively can supply a clearer image of kidney well being and future danger than both take a look at alone.
Two Checks, One Regarding Hole
Researchers from NYU Langone Well being discovered that giant variations between creatinine and cystatin C outcomes are widespread, notably amongst people who find themselves already unwell. In a big worldwide evaluation, multiple third of hospitalized sufferers had cystatin C outcomes that recommended kidney perform was at the very least 30% worse than what their creatinine ranges indicated. This hole, the researchers say, could level to underlying illness that will in any other case go unnoticed.
“Our findings spotlight the significance of measuring each creatinine and cystatin C to realize a real understanding of how effectively the kidneys are working, notably amongst older and sicker adults,” stated research co-corresponding writer Morgan Grams, MD, PhD. “Evaluating each biomarkers could establish way more folks with poor kidney perform, and earlier within the illness course of, by masking the blind spots that go along with both take a look at.”
The research was revealed within the Journal of the American Medical Affiliation and was introduced on the American Society of Nephrology’s annual Kidney Week convention.
Why Kidney Testing Issues Past Prognosis
Correct kidney perform measurements are crucial not just for detecting illness, but additionally for figuring out protected treatment doses. Kidney efficiency helps information dosing for most cancers remedies, antibiotics, and lots of generally prescription drugs, in keeping with Grams, who’s the Susan and Morris Mark Professor of Drugs on the NYU Grossman Faculty of Drugs.
In a separate research launched the identical day, the identical analysis group reported that persistent kidney illness now impacts extra folks worldwide than ever earlier than and has develop into the ninth main reason behind loss of life globally. Grams notes that higher instruments for early detection may permit sufferers to start remedy sooner and scale back the necessity for excessive measures comparable to dialysis or organ transplantation. She can also be a professor within the Division of Inhabitants Well being at NYU Grossman Faculty of Drugs.
A Large World Evaluation
For the present research, investigators reviewed medical data, blood take a look at outcomes, and demographic info from 860,966 adults representing six completely different nationalities. All members had each creatinine and cystatin C measured on the identical day and had been adopted for a median of 11 years. The evaluation accounted for elements that may affect these markers however aren’t straight associated to kidney perform, together with smoking, weight problems, and a historical past of most cancers.
Carried out by way of the worldwide Power Kidney Illness Prognosis Consortium, the analysis is the most important investigation up to now to look at how variations between these two assessments relate to long-term well being outcomes. The consortium was created to enhance understanding of persistent kidney illness and to help constant international definitions of the situation and its dangers.
Larger Dangers Linked to Bigger Variations
The research discovered that individuals whose cystatin C outcomes confirmed kidney filtration at the very least 30% decrease than their creatinine outcomes confronted considerably larger dangers of loss of life, coronary heart illness, and coronary heart failure. They had been additionally extra more likely to develop extreme persistent kidney illness that required dialysis or an organ transplant. Comparable patterns had been noticed in 11% of outpatients and people who appeared wholesome on the time of testing.
Grams identified that cystatin C testing was first really useful in 2012 by the worldwide group Kidney Illness — Bettering World Outcomes. Regardless of that steerage, a 2019 survey confirmed that fewer than 10% of medical laboratories in the USA carried out the take a look at in-house. Since then, the 2 largest laboratory corporations, Quest Diagnostics and Labcorp, have begun providing it.
“These outcomes underscore the necessity for physicians to reap the benefits of the truth that extra hospitals and well being care suppliers are beginning to supply cystatin C testing,” stated research co-corresponding writer Josef Coresh, MD, PhD, director of NYU Langone’s Optimum Getting older Institute. “Physicians would possibly in any other case miss out on worthwhile details about their sufferers’ well-being and future medical considerations.”
Coresh, who can also be the Terry and Mel Karmazin Professor of Inhabitants Well being at NYU Grossman Faculty of Drugs, famous that amongst hospitalized People included within the research, fewer than 1% had been examined for cystatin C.
Examine Help and Contributors
The analysis was funded by Nationwide Institutes of Well being grant R01DK100446 and by the Nationwide Kidney Basis.
Michelle Estrella, MD, MHS, of the College of California, San Francisco, served because the research’s first writer, whereas Kai-Uwe Eckardt, MD, of Charite-Universitatsmedizin Berlin in Germany, was the senior writer. Together with Grams and Coresh, co-leaders of the Power Kidney Illness Prognosis Consortium, NYU Langone contributors included Shoshana Ballew, PhD; Yingying Sang, MS; and Aditya Surapaneni, PhD. Further investigators got here from establishments throughout the USA, Europe, Asia, and Australia, reflecting the worldwide scope of the analysis effort.
Last yr college students typically face the problem of selecting the best venture. Deciding on a subject that’s fascinating, sensible, and related to present expertise tendencies just isn’t straightforward. Giant Language Fashions (LLMs) are gaining big reputation in AI and are utilized in chatbots, digital assistants, content material technology, summarization, and extra. Engaged on an LLM venture concept helps college students perceive how machines course of language, enhance problem-solving abilities, and be taught real-world AI purposes. Good venture additionally strengthens a scholar’s resume and tutorial profile. On this weblog, we current 10 finest LLM venture concepts for closing yr college students which can be sensible, idea-based, and straightforward to implement with out requiring direct coding options.
Why select LLM venture concepts for the ultimate yr?
Last yr tasks usually are not simply tutorial necessities. They present your problem-solving potential, technical abilities, and understanding of recent applied sciences.
LLM tasks assist college students:
Work with real-world AI purposes.
Perceive pure language processing deeply.
Construct industry-relevant abilities
Strengthen resumes for jobs or greater research.
These tasks are nice for college students of their final yr in faculty as a result of they focus extra on sensible data than heavy principle.
Description: Create an idea for a system that reads paperwork or articles and supplies solutions to consumer queries. The thought focuses on understanding textual content and producing related responses.
Abilities Gained: Pure language understanding, analytical considering and the issue fixing.
Device: Python
Sensible Software: Helpful for analysis, on-line schooling platforms and the data administration methods
2. Sensible School Chatbot Concept
Description: Think about a chatbot that may reply frequent questions that college students have relating to courses, actions, and the varsity’s facilities. The examine focuses on how AI interacts with pure language.
Abilities Gained: Realizing learn how to use NLP, determining what somebody desires and protecting discussions going Device: Rasa
Sensible Software: Improves scholar communication and reduces handbook help workload
3. Resume Analyzer Concept
Description: Concept for a system that evaluates resumes and supplies solutions based mostly on job necessities. College students can discover how textual content comparability and ability matching work in LLMs.
Abilities Gained: Textual content processing, knowledge evaluation and logical reasoning.
Device: Python
Sensible Software: Helps college students or job seekers enhance their resumes and match abilities with job necessities
4. Textual content Summarization Device Concept
Description: Concept for a software that turns huge articles, analysis papers or paperwork into quick, clear textual content. Concentrates on discovering essential phrases and sentences.
Abilities Gained: NLP fundamentals, knowledge evaluation and the summarization strategies
Device: Hugging Face Transformers
Sensible Software: Helpful for college students and professionals to shortly perceive prolonged content material
5. Faux Information Detection Concept
Description: A plan for a venture to search out pretend information or incorrect data on web sites and social media. Largely about discovering tendencies and placing textual content into teams.
Sensible Software: Helps in media verification and social media monitoring
6. Automated Essay Suggestions Concept
Description: An method to grading and concept distribution that takes into consideration the article’s substance, language, and relevancy. By breaking issues down into their elements, college students learn to assess them.
Abilities Gained: Textual content evaluation, AI analysis strategies and demanding considering.
Device: Python
Sensible Software: Helpful in schooling for suggestions and automatic grading
7. Buyer Question Classifier Concept
Description: A man-made intelligence-based method to grouping customer support inquiries into a number of classes. focuses on comprehending categorization and patterns in language.
Abilities Gained: NLP, knowledge group and the downside fixing
Device: Python
Sensible Software: Useful for companies to automate question routing and enhance customer support
8. Language Translation Idea
Description: Concepts for a system that might use synthetic intelligence to make translating phrases between languages simpler. Take note of studying NLP concepts and translation strategies that work throughout languages.
Abilities Gained: Multilingual textual content processing, NLP and AI reasoning.
Device: Google Translate API
Sensible Software: World contact, on-line websites, and academic instruments can all use it.
9. Sentiment Evaluation Concept
Description: Idea for a system that analyzes textual content opinions or social media posts to find out constructive, destructive, or impartial sentiment. The main focus is on understanding emotion detection in language.
Abilities Gained: NLP, textual content evaluation and sample recognition
Device: Python
Sensible Software: Helpful for advertising and marketing, model monitoring and suggestions evaluation
10. Subject Modeling and Development Evaluation Concept
Description: Concept for figuring out major matters and tendencies from a group of paperwork or social media posts. Focus is on understanding large-scale textual content knowledge.
Sensible Software: Helps companies, researchers, and entrepreneurs perceive present tendencies.
The best way to Select the Proper LLM Undertaking Subject
Earlier than deciding on your venture, take into account these factors:
Out there time and sources
Your curiosity degree
Steering from school
Undertaking complexity
Select a subject you could full confidently moderately than one thing too advanced.
Tricks to Rating Excessive in LLM Last Yr Initiatives
Clearly outline the issue assertion.
Clarify why LLM is used.
Present real-world purposes
Maintain documentation easy and clear.
Put together nicely for the venture, Viva.
Good clarification issues greater than advanced options.
Conclusion
LLM venture concepts for closing yr college students assist in understanding how fashionable language fashions clear up actual world issues. These tasks enable college students to use theoretical data in a sensible method and develop downside fixing abilities. Engaged on LLM venture concepts improves logical considering, primary AI ideas and confidence throughout closing yr evaluations.
A well-chosen venture additionally strengthens a scholar’s resume and prepares them for greater research or {industry} roles in synthetic intelligence and knowledge science. By specializing in clear goals, correct planning and sincere effort, closing yr college students can full significant LLM tasks that help their tutorial progress and future profession targets.
Ceaselessly Requested Questions (FAQs)
1. What are LLM venture concepts for newbies?
Newbie pleasant tasks embody chatbots, sentiment evaluation and textual content summarization instruments.
2. Which software is finest for LLM tasks?
Python and Hugging Face Transformers are generally really helpful for scholar tasks.
3. Can I full an LLM venture with out coding expertise?
Sure, you may work on conceptual tasks and perceive the workflow earlier than implementation.
4. How do LLM tasks assist in profession progress?
They supply abilities in AI, NLP and downside fixing, that are extremely invaluable in analysis, tech and data-driven roles.
Gold is a key monetary asset and is extensively thought to be a protected haven in periods of financial uncertainty, making it a most popular selection for buyers looking for stability and portfolio diversification.
We’ll create a machine studying linear regression mannequin that takes data from the previous Gold ETF (GLD) costs and returns a Gold worth prediction the subsequent day.
GLD is the biggest ETF to speculate immediately in bodily gold. (Supply)
This mission prioritizes establishing a stable basis with extensively used machine studying strategies as an alternative of instantly turning to superior fashions. The target is to construct a sturdy and scalable pipeline for predicting gold costs, designed to be simply adaptable for incorporating extra subtle algorithms sooner or later.
Import the libraries and skim the Gold ETF knowledge
First issues first: import all the required libraries that are required to implement this technique. Importing libraries and knowledge information is an important first step in any knowledge science mission, because it ensures you might have all dependencies and exterior knowledge sources prepared for evaluation.
Then, we learn the previous 14 years of every day Gold ETF worth knowledge from a file and retailer it in Df. This knowledge set features a date column, which is crucial for time collection evaluation and plotting developments over time. We take away the columns which aren’t related and drop NaN values utilizing dropna() perform. Then, we plot the Gold ETF shut worth.
Output:
Gold ETF (Ticker: GLD) Value Sequence
Outline explanatory variables
An explanatory variable, also referred to as a function or unbiased variable, is used to clarify or predict modifications in one other variable. On this case, it helps predict the next-day worth of the Gold ETF.
These are the inputs or predictors we use in a mannequin to forecast the goal consequence.
On this technique, we begin with two easy options: the 3-day shifting common and the 9-day shifting common of the Gold ETF. These shifting common function smoothed representations of short-term and barely longer-term developments, serving to seize momentum or mean-reversion habits in costs. Earlier than utilizing these options in modeling, we get rid of any lacking values utilizing the .dropna() perform to make sure the dataset is clear and prepared for evaluation. The ultimate function matrix is saved in X.
Nevertheless, that is just the start of the function engineering course of. You’ll be able to prolong X by incorporating extra variables which may enhance the mannequin’s predictive energy. These could embrace:
Technical indicators reminiscent of RSI (Relative Power Index), MACD (Transferring Common Convergence Divergence), Bollinger Bands, or ATR (Common True Vary).
Cross-asset options, reminiscent of the value or returns of associated ETFs just like the Gold Miners ETF (GDX) or the Oil ETF (USO), which can affect gold costs by means of macroeconomic or sector-specific linkages.
Macroeconomic indicators reminiscent of inflation knowledge (CPI), rates of interest, and USD index actions can affect gold costs as a result of gold is perceived as a safe-haven asset throughout occasions of financial uncertainty.
The method of figuring out and establishing such variables known as function engineering. Individually, choosing probably the most related variables for a mannequin is named function choice.
The higher your options replicate significant patterns within the knowledge, the extra correct your forecasts are more likely to be.
Outline dependent variable
The dependent variable, also referred to as the goal variable in machine studying, is the result we goal to foretell. Its worth is assumed to be influenced by the explanatory (or unbiased) variables. Within the context of our technique, the dependent variable is the value of the Gold ETF (GLD) on the next day.
In our dataset, the Shut column accommodates the historic costs of the Gold ETF. This column serves because the goal variable as a result of we’re constructing a mannequin to study patterns from historic options (reminiscent of shifting averages) and use them to foretell future GLD costs. We assign this goal collection to the variable y, which will likely be used throughout mannequin coaching and analysis.
To create the goal variable, we apply the shift(-1) perform to the Shut column. This shifts the value knowledge one step backward, making every row’s goal the subsequent day’s closing worth. This strategy allows the mannequin to make use of as we speak’s options to forecast tomorrow’s worth.
Clearly defining the goal variable is crucial for any supervised studying drawback, because it shapes your entire modelling goal. On this case, the purpose is to forecast future actions in gold costs utilizing related monetary and financial indicators.
Alternatively, as an alternative of predicting absolutely the worth of gold, we are able to use gold returns because the goal variable. Returns characterize the proportion change in gold costs over a specified time interval, reminiscent of every day, weekly, or month-to-month intervals.
Non-stationary variables in linear regression
In time collection evaluation, it is common to work with uncooked monetary knowledge reminiscent of inventory or commodity costs. Nevertheless, these worth collection are usually non-stationary, that means their statistical properties like imply and variance change over time. This poses a major problem as a result of many analytical strategies depend on the idea that the information behaves constantly. When the information is non-stationary, its underlying construction shifts. Traits evolve, volatility varies, and historic patterns could not maintain sooner or later.
Working with non-stationary knowledge can result in a number of issues:
Spurious Relationships: Variables could look like associated just because they share related developments, not as a result of there is a real connection.
Unstable Insights: Any patterns or relationships recognized could not maintain over time, as the information’s behaviour continues to evolve.
Deceptive Forecasts: Predictive fashions constructed on non-stationary knowledge usually battle to carry out reliably sooner or later.
The core challenge is that non-stationary processes don’t comply with mounted guidelines. Their dynamic nature makes it tough to attract conclusions or make predictions that stay legitimate as circumstances change. Earlier than performing any critical evaluation, it is essential to check for stationarity and, if wanted, rework the information to stabilize its behaviour.
Two Methods to Work with Non-Stationary Knowledge
Slightly than discarding non-stationary variables, there are two dependable methods to deal with them in linear regression fashions:
1. Make Variables Stationary (Differencing Strategy)
One widespread technique is to rework the information to make it stationary. That is usually executed by specializing in modifications in values. For instance, worth collection may be transformed into returns or variations. This transformation helps stabilize the imply and reduces developments or seasonality. As soon as the information is reworked, it turns into extra appropriate for linear modeling as a result of its statistical properties stay constant over time.
2. Use Unique Non-Stationary Sequence (Cointegration Strategy)
The second technique permits us to make use of the unique non-stationary collection with out transformation, offered sure circumstances are met. Particularly, it entails checking whether or not the variables, when mixed in a selected means, share a long-term equilibrium relationship. This idea is named cointegration.
Even when the person variables are non-stationary, their linear mixture may be stationary. If that is so, the residuals from the regression (the variations between precise and predicted values) stay steady over time. This stability makes the regression legitimate and significant, because it displays a real relationship somewhat than a statistical coincidence.
In our evaluation, we are going to use this second technique by testing for residual stationarity to verify that the regression setup is suitable.
Output:
Cointegration p-value between S_3 and next_day_price: 3.1342217460742354e-16
Cointegration p-value between S_9 and next_day_price: 1.268049574487298e-15
S_3 and next_day_price are cointegrated.
S_9 and next_day_price are cointegrated.
The time collection S_3 (3-day shifting common) and next_day_price, in addition to S_9 (9-day shifting common) and next_day_price, are cointegrated. Thus, we are able to proceed with working a linear regression immediately with out reworking the collection to attain stationarity.
Why You Can Run the Regression Immediately?
Cointegration implies that there’s a steady, long-term relationship between the 2 non-stationary collection. Which means whereas the person collection could every include unit roots (i.e., be non-stationary), their linear mixture is stationary and working an Abnormal Least Squares (OLS) regression is not going to result in a spurious regression. It is because the residuals of the regression (i.e., the distinction between the expected and precise values) will likely be stationary.
Key Factors to Bear in mind
As cointegration already ensures a sound statistical relationship, making OLS acceptable for estimating the parameters, there isn’t a have to distinction the collection to make them stationary earlier than working the regression
The regression run between S_3 (or S_9) and next_day_price will seize a sound long-term equilibrium relationship, which cointegration confirms.
Cut up the information into practice and take a look at dataset
On this step, we break up the predictors and output knowledge into practice and take a look at knowledge. The coaching knowledge is used to create the linear regression mannequin, by pairing the enter with anticipated output.
Mannequin coaching is carried out on the coaching dataset, the place the mannequin learns from the options and labels.
The take a look at knowledge is used to estimate how properly the mannequin has been skilled. Evaluating completely different fashions and evaluating their coaching time and accuracy is a crucial a part of the mannequin choice course of. Mannequin analysis, together with the usage of validation units and cross-validation, ensures the mannequin generalizes properly to unseen knowledge.
First 80% of the information is used for coaching and remaining knowledge for testing
X_train & y_train are coaching dataset
X_test & y_test are take a look at dataset
Create a linear regression mannequin
We’ll now create a linear regression mannequin. However, what’s linear regression?
Linear regression is likely one of the easiest and most generally used algorithms in machine studying for supervised studying duties, the place the purpose is to foretell a steady goal variable based mostly on enter options. At its core, linear regression captures a mathematical relationship between the unbiased variables (x) and the dependent variable (y) by becoming a straight line that finest describes how modifications in x have an effect on the values of y.
When the information is plotted as a scatter plot, linear regression identifies the road that minimizes the distinction between the precise values and the expected values. This fitted line represents the regression equation and is used to make future predictions.
To interrupt it down additional, regression explains the variation in a dependent variable when it comes to unbiased variables. The dependent variable – ‘y’ is the variable that you just need to predict. The unbiased variables – ‘x’ are the explanatory variables that you just use to foretell the dependent variable. The next regression equation describes that relation:
Y = m1 * X1 + m2 * X2 + CGold ETF worth = m1 * 3 days shifting common + m2 * 9 days shifting common + c
Then we use the match technique to suit the unbiased and dependent variables (x’s and y’s) to generate coefficient and fixed for regression.
Output:
Linear Regression mannequin
Gold ETF Value (y) = 1.19 * 3 Days Transferring Common (x1) + -0.19 * 9 Days Transferring Common (x2) + 0.28 (fixed)
Predict the Gold ETF costs
Now, it’s time to examine if the mannequin works within the take a look at dataset. We predict the Gold ETF costs utilizing the linear mannequin created utilizing the practice dataset. The predict technique finds the Gold ETF worth (y) for the given explanatory variable X.
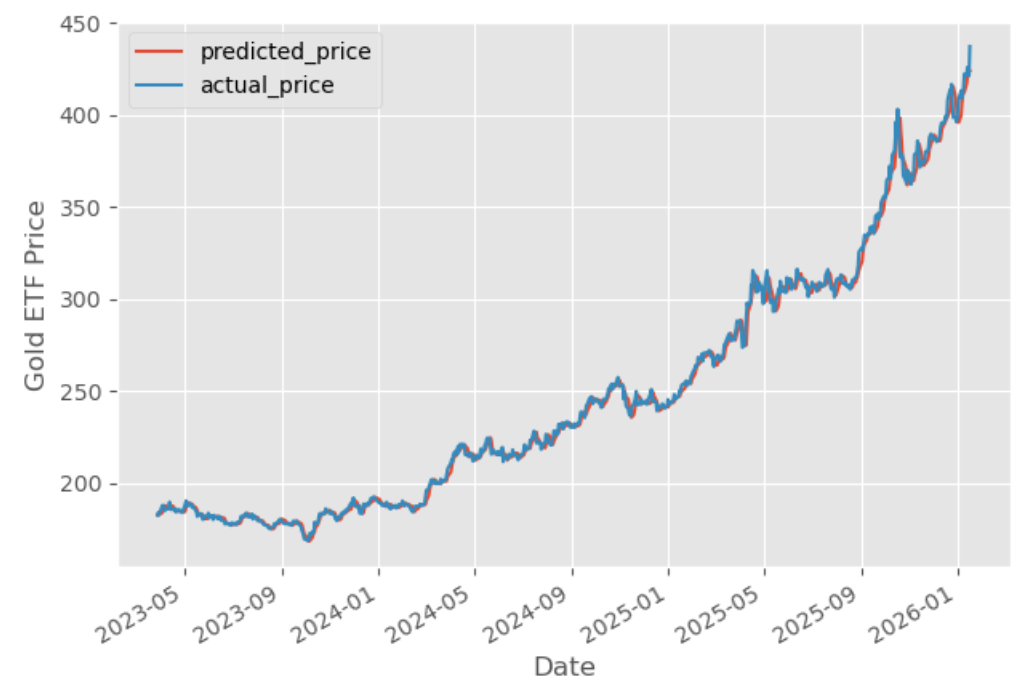
Output:
Gold ETF (GLD) Predicted Value Versus Precise Value
The graph exhibits the expected costs and precise costs of the Gold ETF. Evaluating predicted costs to precise costs helps consider the efficiency of the skilled mannequin and exhibits how carefully the predictions match real-world values. Capabilities like evaluate_model() can be utilized to generate diagnostic plots and additional consider the mannequin’s high quality.
Now, let’s compute the goodness of the match utilizing the rating() perform.
Output:
99.70
As it may be seen, the R-squared of the mannequin is 99.70%. R-squared is at all times between 0 and 100%. A rating near 100% signifies that the mannequin explains the Gold ETF costs properly.
On the floor, this appears spectacular. It exhibits a near-perfect match between the mannequin’s outputs and actual market values.
Nevertheless, translating this predictive accuracy right into a worthwhile buying and selling technique just isn’t simple. In follow, it’s essential make vital choices reminiscent of:
When to enter a commerce (sign era)
How lengthy to maintain the place
When to exit (e.g., based mostly on a predicted reversal or mounted threshold)
And the right way to handle threat (e.g., utilizing stop-loss or place sizing)
As an instance this problem, we tried to make use of predicted costs to generate a easy long-only buying and selling sign.
A place is taken provided that the subsequent day’s predicted worth is greater than as we speak’s closing worth. This creates a unidirectional sign with no shorting or hedging. The place is exited (and doubtlessly re-entered) each time the sign situation is not met.
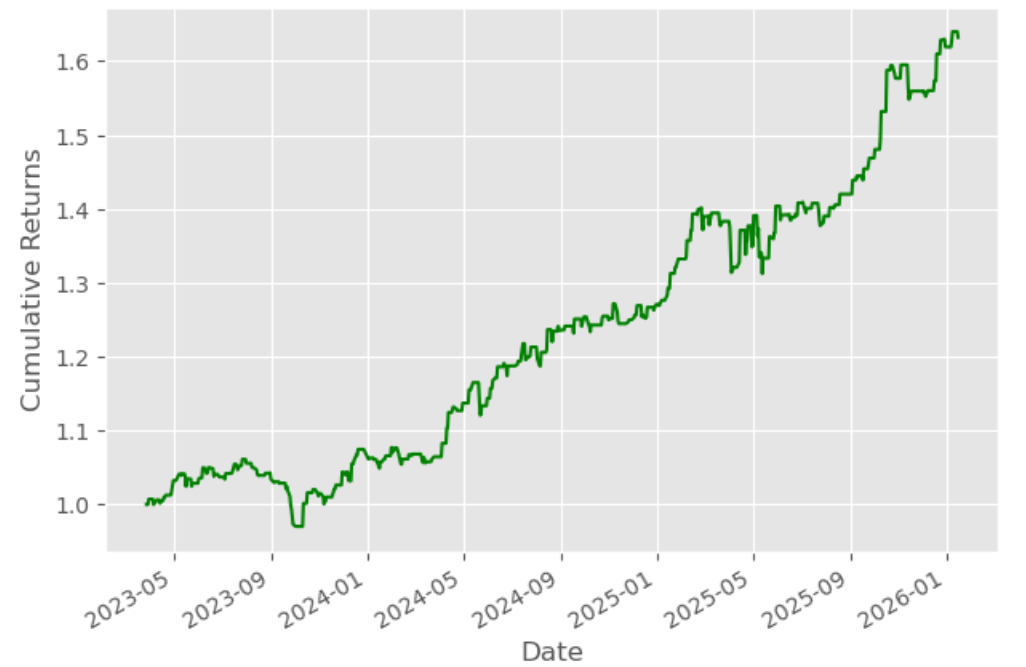
Plotting cumulative returns
Let’s calculate the cumulative returns of this technique to analyse its efficiency.
The steps to calculate the cumulative returns are as follows:
Generate every day share change of gold worth
Shift the every day share change forward by in the future to align with our place when there’s a sign.
Create a purchase buying and selling sign represented by “1” when the subsequent day’s predicted worth is greater than the present day worth. No place is taken in any other case
Calculate the technique returns by multiplying the every day share change with the buying and selling sign.
Lastly, we are going to plot the cumulative returns graph
The output is given beneath:
Cumulative Returns of Gold ETF Value Prediction Utilizing Linear Regression
We may even calculate the Sharpe ratio.
The output is given beneath:
‘Sharpe Ratio 1.82′
Giventhe mannequin’s excessive predictive accuracy, the Sharpe Ratio of the ensuing buying and selling technique is just one.82, which isn’t excellent for a scalable and sensible buying and selling system.
This disparity highlights a vital level: good worth prediction doesn’t at all times result in extraordinarily worthwhile or risk-adjusted buying and selling efficiency. A number of components could clarify the decrease Sharpe Ratio:
The technique could endure from unidirectional bias, ignoring shorting or range-bound intervals.
It may not adapt properly to market volatility, resulting in sharp drawdowns.
The buying and selling guidelines are too simplistic, failing to seize timing nuances or noise within the predictions.
In abstract, whereas the mannequin performs properly in predicting worth ranges, changing this into a sturdy buying and selling technique requires considerate design. Sign logic, timing, place administration, and threat controls all play a major position in enhancing precise technique efficiency.
Steered Reads:
Tips on how to use this mannequin to foretell every day strikes?
You need to use the next code to foretell the gold costs and provides a buying and selling sign whether or not we should always purchase GLD or take no place.
The output is as proven beneath:
Newest Sign and Prediction
Date
2026-01-20
Value
Shut
437.230011
sign
No Place
predicted_gold_price
427.961362
Congrats! You’ve got simply applied a easy but efficient machine studyingmethod utilizing linear regression to forecast gold costs and derive buying and selling indicators. You now perceive the right way to:
Engineer options from uncooked worth knowledge (utilizing shifting averages),
Construct and match a predictive mannequin,
Use the mannequin for making forward-looking forecasts,and
Translate these forecasts into actionable indicators.
What’s Subsequent?
Linear regression is a superb place to begin resulting from its simplicity and interpretability. However in real-world monetary modeling,extra complicated patterns and nonlinear relationships usually exist that linear fashions may not absolutely seize.
To enhance accuracy,you’ll be able to discover extra highly effective machine studying regression fashions,reminiscent of:
Random Forest Regression
Gradient Boosted Bushes (like XGBoost or LightGBM)
Assist Vector Regression (SVR)
Neural Networks (MLPs for tabular knowledge)
The core construction of your pipeline stays the identical:knowledge preprocessing,function engineering,forecasting,and sign era. The one change is the mannequin itself. You merely change the .match() and .predict() strategies with these out of your chosen algorithm,probably adjusting a number of extra hyperparameters.
Hold Exploring
Wish to dive deeper into utilizing machine studying for buying and selling? Be taught step-by-step the right way to construct your first ML-based buying and selling technique with our guidedcourse. When you’re able to take it to the subsequent stage,discover our Studying Monitor. Consultants like Dr. Ernest Chan will information you thru your entire lifecycle,from concept era and backtesting to dwell deployment,utilizing superior machine studying strategies.
File within the obtain:
Gold Value Prediction Technique –Python Pocket book
Disclaimer:All investments and buying and selling within the inventory market contain threat. Any choices to put trades within the monetary markets,together with buying and selling in inventory or choices or different monetary devices is a private resolution that ought to solely be made after thorough analysis,together with a private threat and monetary evaluation and the engagement{of professional}help to the extent you consider needed. The buying and selling methods or associated data talked about on this article is for informational functions solely.
MIT researchers have recognized important examples of machine-learning mannequin failure when these fashions are utilized to knowledge aside from what they have been educated on,elevating questions on the necessity to check every time a mannequin is deployed in a brand new setting.
“We exhibit that even whenever you prepare fashions on giant quantities of information,and select the most effective common mannequin,in a brand new setting this ‘greatest mannequin’ may very well be the worst mannequin for 6-75 % of the brand new knowledge,” says Marzyeh Ghassemi,an affiliate professor in MIT’s Division of Electrical Engineering and Laptop Science (EECS),a member of the Institute for Medical Engineering and Science,and principal investigator on the Laboratory for Info and Determination Methods.
In a paperthat was offered on the Neural Info Processing Methods (NeurIPS 2025) convention in December,the researchers level out that fashions educated to successfully diagnose sickness in chest X-rays at one hospital,for instance,could also be thought of efficient in a unique hospital,on common. The researchers’ efficiency evaluation,nevertheless,revealed that a few of the best-performing fashions on the first hospital have been the worst-performing on as much as 75 % of sufferers on the second hospital,regardless that when all sufferers are aggregated within the second hospital,excessive common efficiency hides this failure.
Their findings exhibit that though spurious correlations — a easy instance of which is when a machine-learning system,not having “seen” many cows pictured on the seaside,classifies a photograph of a beach-going cow as an orca merely due to its background — are regarded as mitigated by simply bettering mannequin efficiency on noticed knowledge,they really nonetheless happen and stay a threat to a mannequin’s trustworthiness in new settings. In lots of cases — together with areas examined by the researchers resembling chest X-rays,most cancers histopathology photographs,and hate speech detection — such spurious correlations are a lot more durable to detect.
Within the case of a medical analysis mannequin educated on chest X-rays,for instance,the mannequin might have discovered to correlate a particular and irrelevant marking on one hospital’s X-rays with a sure pathology. At one other hospital the place the marking is just not used,that pathology may very well be missed.
Earlier analysis by Ghassemi’s group has proven that fashions can spuriously correlate such elements as age,gender,and race with medical findings. If,as an example,a mannequin has been educated on extra older folks’s chest X-rays which have pneumonia and hasn’t “seen” as many X-rays belonging to youthful folks,it’d predict that solely older sufferers have pneumonia.
“We wish fashions to learn to have a look at the anatomical options of the affected person after which decide primarily based on that,” says Olawale Salaudeen,an MIT postdoc and the lead creator of the paper,“however actually something that’s within the knowledge that’s correlated with a call can be utilized by the mannequin. And people correlations won’t really be sturdy with adjustments within the setting,making the mannequin predictions unreliable sources of decision-making.”
Spurious correlations contribute to the dangers of biased decision-making. Within the NeurIPS convention paper,the researchers confirmed that,for instance,chest X-ray fashions that improved total analysis efficiency really carried out worse on sufferers with pleural circumstances or enlarged cardiomediastinum,that means enlargement of the guts or central chest cavity.
Different authors of the paper included PhD college students Haoran Zhang and Kumail Alhamoud,EECS Assistant Professor Sara Beery,and Ghassemi.
Whereas earlier work has usually accepted that fashions ordered best-to-worst by efficiency will protect that order when utilized in new settings,referred to as accuracy-on-the-line,the researchers have been in a position to exhibit examples of when the best-performing fashions in a single setting have been the worst-performing in one other.
Salaudeen devised an algorithm referred to as OODSelect to search out examples the place accuracy-on-the-line was damaged. Principally,he educated 1000’s of fashions utilizing in-distribution knowledge,that means the info have been from the primary setting,and calculated their accuracy. Then he utilized the fashions to the info from the second setting. When these with the very best accuracy on the first-setting knowledge have been fallacious when utilized to a big share of examples within the second setting,this recognized the issue subsets,or sub-populations. Salaudeen additionally emphasizes the hazards of mixture statistics for analysis,which may obscure extra granular and consequential details about mannequin efficiency.
In the midst of their work,the researchers separated out the “most miscalculated examples” in order to not conflate spurious correlations inside a dataset with conditions which can be merely troublesome to categorise.
The NeurIPS paper releases the researchers’ code and a few recognized subsets for future work.
As soon as a hospital,or any group using machine studying,identifies subsets on which a mannequin is performing poorly,that data can be utilized to enhance the mannequin for its explicit activity and setting. The researchers advocate that future work undertake OODSelect as a way to spotlight targets for analysis and design approaches to bettering efficiency extra persistently.
“We hope the launched code and OODSelect subsets grow to be a steppingstone,” the researchers write,“towards benchmarks and fashions that confront the hostile results of spurious correlations.”












")