Healthcare is standing at an inflection level the place medical experience meets clever expertise, and the alternatives made in the present day will form affected person care for many years to come back. On this, synthetic Intelligence is not a pilot confined to innovation labs; it’s actively influencing:
- How Illnesses Are Detected Earlier
- How Clinicians Make Sooner And Extra Assured Choices,
- How Well being Programs Function Underneath Rising Stress
But, the true alternative lies not simply in understanding AI, however in understanding how and when to behave on the traits that matter most.
On this weblog, we discover essentially the most vital AI traits in healthcare, redefining healthcare, and extra importantly, the perfect practices for implementing AI in healthcare to make sure expertise strengthens, fairly than replaces, the human core.
Summarize this text with ChatGPT
Get key takeaways & ask questions
The Present State of AI Tendencies in Healthcare
In 2026, the combination of AI traits in healthcare has progressed from remoted pilot initiatives to a core part of worldwide medical infrastructure.
This shift is pushed by substantial capital funding and a robust emphasis on operational effectivity, with the healthcare AI market projected to develop at a CAGR of 43% between 2024 and 2032, reaching an estimated worth of $491 billion.
The sector’s fast evolution is marked by a number of key monetary and operational indicators, equivalent to:
- Generative AI is on the forefront, increasing sooner in healthcare than in every other trade and anticipated to develop at a CAGR of 85% to succeed in $22 billion by 2027, enabling automation throughout medical documentation and drug discovery.
- Early adopters are already demonstrating clear financial worth, reporting annual returns of 10–15% over 5-year funding cycles.
- At a system degree, AI-driven diagnostics and administrative automation are projected to cut back general healthcare expenditure by roughly 10%, whereas concurrently enhancing medical productiveness by enabling clinicians to dedicate extra time to affected person care.
Collectively, these traits place AI as a strategic enabler of sustainable, high-quality healthcare supply worldwide. To navigate this fast adoption, professionals should bridge the hole between technical potential and enterprise execution.
The Publish Graduate Program in Synthetic Intelligence & Machine Studying from Texas McCombs is designed to supply this precise basis. This complete program covers the complete spectrum of AI from supervised and unsupervised studying to Deep Studying and Generative AI.
By mastering these core applied sciences, healthcare leaders can higher interpret market indicators and make knowledgeable, strategic choices that drive AI adoption of their organizations.
Rising AI Tendencies In Healthcare
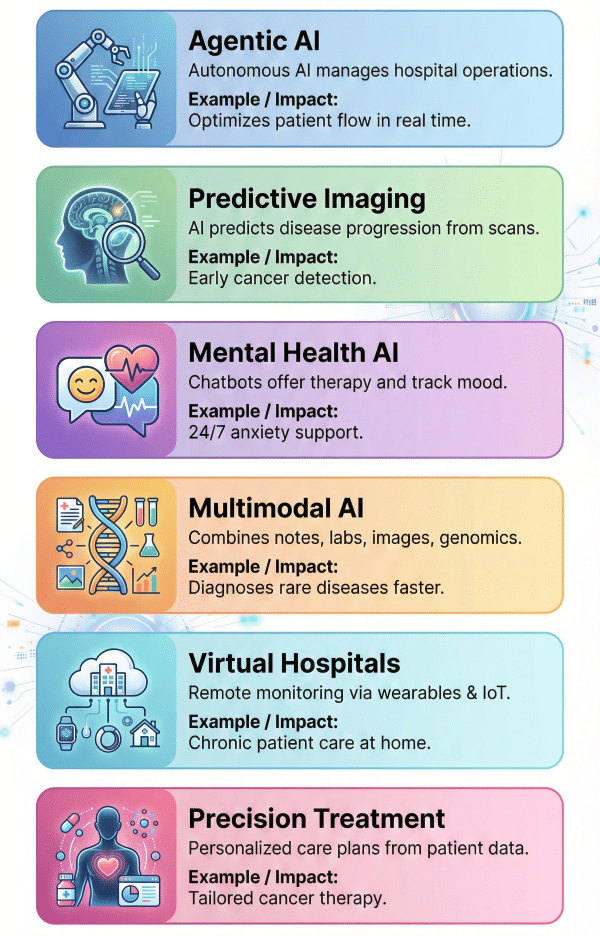
1. Agentic AI for Clever Course of Automation
We’re transferring from “passive” AI instruments that anticipate instructions to “agentic” AI that may act independently. Agentic AI refers to programs able to perceiving their surroundings, reasoning, and executing advanced workflows with out fixed human oversight.
In a hospital setting, this implies AI brokers that may coordinate affected person schedules, handle provide chains, and even autonomously triage incoming knowledge streams.
How Does It Assist?
Instance: Managing affected person move in a big tertiary hospital
- Step 1: Steady Surroundings Monitoring: The AI agent screens real-time knowledge from the emergency division, mattress administration programs, digital well being data, and staffing schedules to keep up a dwell view of hospital capability.
- Step 2: Clever Threat and Precedence Evaluation: Based mostly on incoming affected person signs, very important indicators, and historic outcomes, the agent autonomously classifies sufferers by acuity, for instance, figuring out high-risk cardiac circumstances that require speedy admission.
- Step 3: Autonomous Workflow: The AI agent allocates beds, schedules diagnostic assessments, and notifies related care groups, robotically adjusting plans when delays or emergencies come up.
- Step 4: Operational Coordination & Optimization: If bottlenecks happen, equivalent to delayed discharges or employees shortages, the agent reassigns sources, updates shift plans, and reroutes sufferers to different models to keep up care continuity.
- Step 5: Clinician Oversight & Resolution Assist: Clinicians obtain prioritized dashboards with AI-generated suggestions, enabling them to validate choices, intervene when essential, and give attention to direct affected person care fairly than administrative coordination.
2. Predictive Well being Evaluation & Imaging
Predictive diagnostics makes use of historic knowledge and real-time imaging to foresee well being points earlier than they develop into vital.
AI algorithms is not going to simply analyze X-rays or MRI scans for present anomalies however will examine them in opposition to huge datasets to foretell the longer term development of ailments like most cancers or neurodegenerative problems.
How Does It Assist?
Instance: Early detection and intervention in Oncology (Most cancers Care)
- Step 1: Excessive-Decision Knowledge Ingestion: The AI system ingests high-resolution pictures from CT scans, MRIs, and tissue slides, alongside the affected person’s genetic profile and household historical past.
- Step 2: Sample Recognition and Comparability: The mannequin compares the affected person’s imaging knowledge in opposition to a worldwide dataset of thousands and thousands of confirmed most cancers circumstances, in search of microscopic irregularities invisible to the human eye.
- Step 3: Predictive Modeling of Illness: Relatively than simply figuring out a tumor, the AI predicts the chance of metastasis (unfold) and the potential development fee based mostly on acknowledged organic patterns.
- Step 4: Threat Stratification and Alert Technology: The system flags “silent” or pre-cancerous markers and generates a danger rating, alerting the radiologist to particular areas of curiosity that require speedy consideration.
- Step 5: Remedy Pathway Suggestion: The AI suggests a customized screening schedule or biopsy plan, permitting docs to intervene months or years earlier than the illness turns into life-threatening.
3. AI-Pushed Psychological Well being Assist
With the rising international demand for psychological well being providers, AI is stepping in to supply accessible, 24/7 assist. Superior Pure Language Processing (NLP) chatbots and therapeutic apps can provide cognitive-behavioral remedy (CBT) strategies, monitor temper patterns, and flag customers who could also be liable to a disaster.
How Does It Assist?
Instance: Offering assist to a person with nervousness throughout off-hours
- Step 1: Conversational Engagement: A person logs right into a psychological well being app late at evening, feeling overwhelmed; the AI initiates a dialog utilizing empathetic, non-judgmental language.
- Step 2: Sentiment and Key phrase Evaluation: The NLP engine analyzes the person’s textual content for particular key phrases indicating misery ranges, self-harm dangers, or particular nervousness triggers.
- Step 3: Therapeutic Approach Software: Based mostly on the evaluation, the AI guides the person via evidence-based workout routines, equivalent to deep respiratory or cognitive reframing (difficult adverse ideas).
- Step 4: Longitudinal Temper Monitoring: The AI data the interplay and updates the person’s temper chart, figuring out patterns or triggers over weeks to share with a human therapist later.
- Step 5: Disaster Intervention Protocols: If the AI detects language indicating speedy hazard, it shifts from remedy mode to disaster mode, offering emergency hotline numbers and alerting pre-designated human contacts.
4. Multimodal AI Integration
Future healthcare AI programs will not be restricted to single knowledge varieties; they are going to be multimodal, able to analyzing and correlating numerous data equivalent to medical notes, lab outcomes, medical pictures, and genomic knowledge concurrently.
By integrating these knowledge streams, multimodal AI gives a holistic view of a affected person’s situation, enabling sooner, extra correct, and customized diagnoses.
How Does It Assist?
Instance: Diagnosing a fancy, uncommon illness with conflicting signs
- Step 1: Multi-Supply Knowledge Aggregation: The AI system collects affected person knowledge from a number of sources: handwritten doctor notes, lab experiences, genomic sequences, and diagnostic pictures like X-rays or dermatology photographs.
- Step 2: Cross-Modal Correlation: It identifies patterns throughout these knowledge varieties linking signs described in textual content to visible indicators in pictures and genetic predispositions, uncovering connections which may be missed by people analyzing them individually.
- Step 3: Synthesis and Reasoning: The AI synthesizes all inputs to slim down potentialities, revealing, for instance, {that a} pores and skin rash aligns with a uncommon genetic mutation indicated within the DNA report.
- Step 4: Proof-Based mostly Reporting: A complete diagnostic report is generated, clearly citing the mixed proof from textual content, imaging, and genetic knowledge that helps the conclusion.
- Step 5: Unified Medical View: The built-in report permits a multidisciplinary group, equivalent to dermatologists and geneticists, to evaluate findings collectively and quickly work on an correct therapy plan.
5. Digital Hospitals and Distant Monitoring
Digital hospitals are remodeling healthcare supply by extending steady care past bodily amenities.
Leveraging wearable units, IoT sensors, and cloud-based platforms, these programs monitor sufferers’ very important indicators, remedy adherence, and persistent situation metrics in actual time.
This enables healthcare suppliers to intervene proactively, scale back pointless hospital visits, and ship care to distant or underserved populations.
How Does It Assist?
Instance: Managing persistent coronary heart failure sufferers remotely
- Step 1: Steady Distant Monitoring: Wearable units observe coronary heart fee, blood strain, oxygen ranges, and each day exercise, transmitting real-time knowledge to a centralized digital hospital platform.
- Step 2: Automated Threat Evaluation: AI algorithms analyze incoming knowledge traits to detect early indicators of degradation, equivalent to fluid retention or irregular coronary heart rhythms.
- Step 3: Alerts and Intervention: When dangers are recognized, the system robotically sends alerts to clinicians and sufferers, prompting well timed interventions like remedy changes or teleconsultations.
- Step 4: Coordinated Care Supply: The digital hospital schedules follow-up assessments, digital appointments, and updates care plans based mostly on real-time insights, minimizing the necessity for bodily visits.
- Step 5: Final result Monitoring and Suggestions: Affected person restoration, adherence, and response to interventions are repeatedly monitored, enabling care groups to refine therapy protocols and stop hospital readmissions.
6. Personalised Care and Precision Remedy
Personalised care leverages AI to maneuver past one-size-fits-all medication towards remedies tailor-made to a person’s medical profile, way of life, and genetic make-up.
By analyzing longitudinal affected person knowledge, together with medical historical past, biomarkers, genomics, and real-world conduct, AI programs can suggest interventions which might be optimized for every affected person, enhancing outcomes whereas decreasing pointless remedies.
How Does It Assist?
Instance: Designing a customized most cancers therapy plan
- Step 1: Complete Affected person Profiling: The AI system aggregates knowledge from digital well being data, tumor genomics, imaging experiences, previous therapy responses, and affected person way of life data.
- Step 2: Predictive Remedy Modeling: Utilizing historic outcomes from related affected person profiles, the AI predicts how the affected person is probably going to reply to completely different remedy choices, together with focused medication and immunotherapies.
- Step 3: Threat and Facet-Impact Evaluation: The system evaluates potential hostile results based mostly on the affected person’s genetics, age, and comorbidities, serving to clinicians keep away from remedies with excessive toxicity danger.
- Step 4: Personalised Care Suggestion: AI generates a ranked therapy plan, outlining the simplest remedy, optimum dosage, and anticipated outcomes, supported by proof from comparable circumstances.
- Step 5: Steady Adaptation and Monitoring: Because the affected person progresses, real-time knowledge from lab outcomes and follow-up scans are fed again into the mannequin, permitting the therapy plan to be dynamically adjusted for optimum effectiveness.
These rising AI traits usually are not simply remodeling workflows; they’re enabling a brand new period of predictive, customized, and environment friendly healthcare supply.
Implementing AI Efficiently
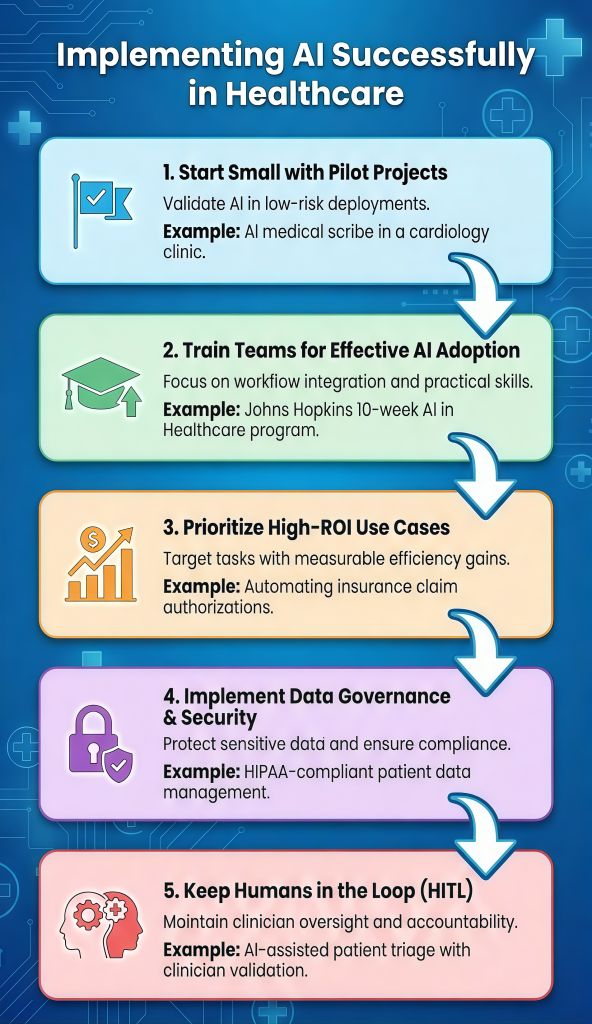
1. Begin Small with Pilot Initiatives
Massive-scale digital transformations usually fail resulting from operational complexity. Organizations ought to as an alternative undertake focused pilot initiatives, managed, low-risk deployments designed to validate worth earlier than scaling. This method limits disruption whereas constructing stakeholder confidence.
Instance: AI Medical Scribe in an Outpatient Clinic
- Centered Deployment: Relatively than a hospital-wide rollout, the AI scribe is launched to a small group of volunteer cardiologists to deal with a selected concern, extreme medical documentation time.
- Efficiency Benchmarking: Key metrics equivalent to documentation time, accuracy, and clinician satisfaction are measured in opposition to baseline ranges to evaluate impression objectively.
- Proof-Based mostly Scaling: Confirmed outcomes, equivalent to a measurable discount in documentation time, present the justification for broader adoption throughout departments.
2. Prepare Groups for Efficient AI Adoption
Even essentially the most superior AI algorithms ship restricted worth if medical groups can not use them successfully. Bridging this hole requires a shift from conventional technical coaching to workflow-focused training, educating employees not solely how the expertise features however the way it integrates seamlessly into each day medical and operational routines.
The Johns Hopkins College AI in Healthcare Certificates Program provides a structured, 10-week curriculum tailor-made for healthcare and enterprise leaders.
This system emphasizes sensible utility protecting predictive analytics, Massive Language Fashions (LLMs), moral issues, and methods for scaling AI pilots, guaranteeing groups can translate data into actionable outcomes.
Program Advantages:
- Sensible AI Information: Covers predictive analytics, Massive Language Fashions (LLMs), and moral frameworks, guaranteeing groups can apply AI in actual medical and operational workflows.
- Healthcare Integration Expertise: Introduces the R.O.A.D. Administration Framework for implementing AI throughout care processes.
- Threat & Knowledge Administration: Teaches employees to determine undertaking dangers, deal with moral and regulatory issues, and handle datasets in Digital Well being Data (EHRs) successfully.
This method equips clinicians and leaders to confidently validate, undertake, and scale AI options, bridging the hole between expertise and affected person care impression.
3. Prioritize Excessive-ROI Use Case
To safe sustained stakeholder assist, early AI initiatives should display clear return on funding (ROI). ROI needs to be outlined broadly to embody time financial savings, error discount, operational effectivity, and improved affected person outcomes. Organizations ought to give attention to high-volume, repetitive duties which might be resource-intensive and prone to human error.
Instance: Automating Insurance coverage Declare Prior Authorizations
- Bottleneck Identification: Excessive-volume administrative processes, equivalent to guide insurance coverage code verification, are focused to cut back backlogs and speed up affected person entry to care.
- Scalable Automation: AI programs course of giant volumes of claims in parallel, finishing in a single day duties that might in any other case take human groups weeks.
- Worth Reinvestment: Quantifiable effectivity good points and price financial savings are reinvested into medical staffing, clearly demonstrating how AI adoption enhances affected person care supply.
4. Implement Knowledge Governance & Safety
Healthcare knowledge is very delicate and ruled by rules equivalent to HIPAA and GDPR. Efficient AI adoption requires a robust governance framework that defines how knowledge is accessed, used, and guarded whereas guaranteeing compliance and belief.
Instance: Securing Affected person Knowledge for AI Analysis
- Knowledge Anonymization & Entry Management: Affected person knowledge is anonymized or encrypted, with strict role-based entry limiting publicity to identifiable data.
- Steady Compliance Monitoring: Automated audits repeatedly assess programs in opposition to HIPAA, GDPR, and cybersecurity requirements.
- Bias & Incident Response: Datasets are routinely examined for bias, and predefined breach-response protocols allow speedy system containment.
5. Maintain People within the Loop (HITL)
AI programs ought to increase, not substitute human experience, significantly in high-stakes healthcare choices. A Human-in-the-Loop (HITL) method ensures that clinicians and directors retain oversight, validate AI outputs, and intervene when essential, preserving accountability, belief, and moral decision-making.
Instance: Medical Resolution Assist in Affected person Triage
- Resolution Validation: AI-generated triage suggestions are reviewed and authorized by clinicians earlier than care pathways are finalized.
- Exception Dealing with: Clinicians can override AI outputs when contextual or patient-specific components fall exterior the mannequin’s assumptions.
- Steady Studying: Suggestions from human choices is fed again into the system to enhance mannequin accuracy, transparency, and reliability over time.
Combining cautious planning, strong coaching, and robust governance, healthcare suppliers can harness AI to enhance operations, assist clinicians, and elevate affected person care.
Conclusion
AI traits in healthcare are remodeling the sector, enabling sooner diagnoses, customized therapy, and improved affected person outcomes. By staying knowledgeable about rising traits and adopting AI-driven options, medical professionals and leaders can drive innovation, improve effectivity, and form the way forward for healthcare.





 Samit Kumbhani is an Amazon Internet Providers (AWS) Senior Options Architect within the New York Metropolis space with over 18 years of expertise. He at the moment companions with impartial software program distributors (ISVs) to construct extremely scalable, modern, and safe cloud options. Outdoors of labor, Samit enjoys enjoying cricket, touring, and biking.
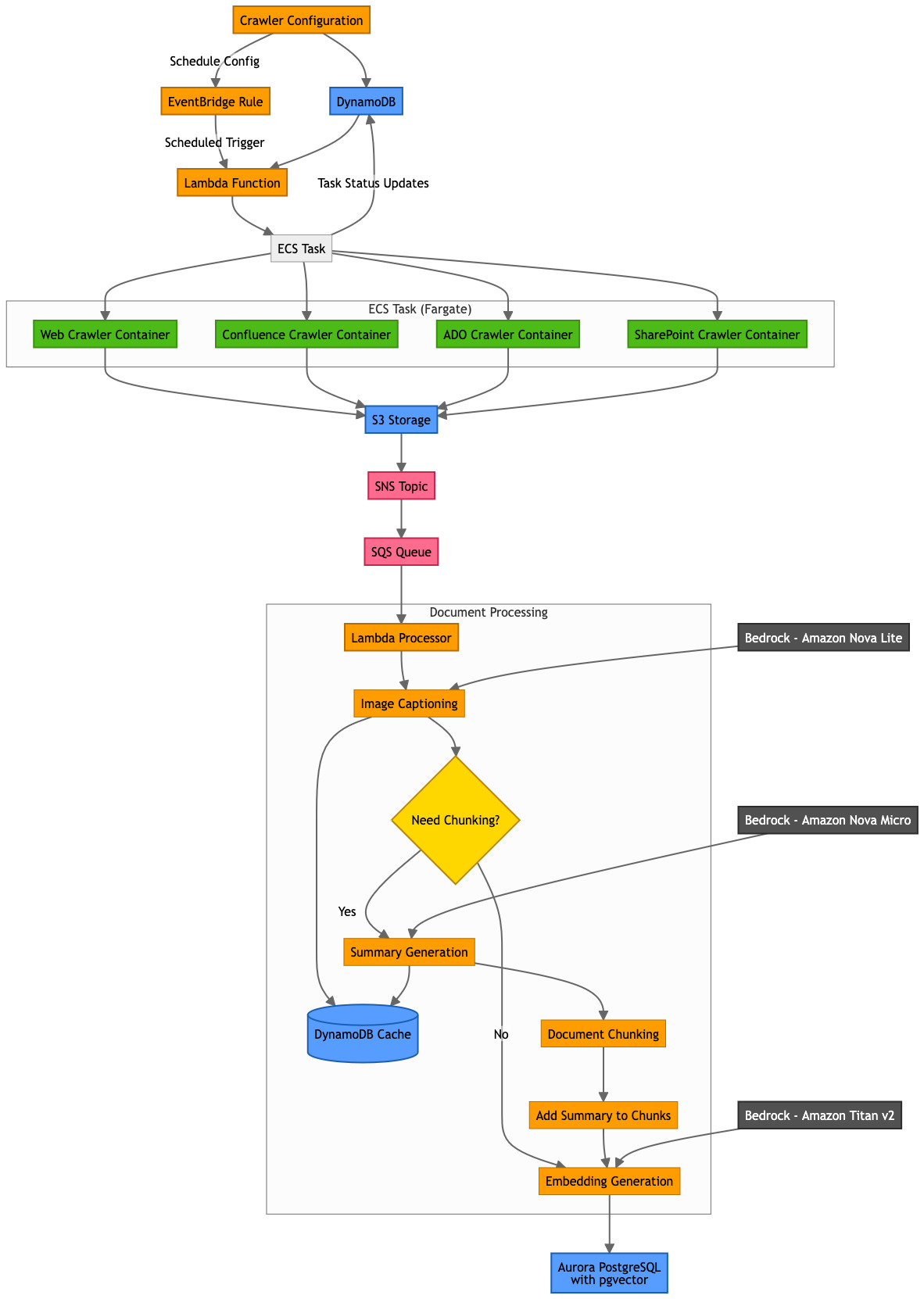
Samit Kumbhani is an Amazon Internet Providers (AWS) Senior Options Architect within the New York Metropolis space with over 18 years of expertise. He at the moment companions with impartial software program distributors (ISVs) to construct extremely scalable, modern, and safe cloud options. Outdoors of labor, Samit enjoys enjoying cricket, touring, and biking. Jhorlin De Armas is an Architect II at PDI Applied sciences, the place he leads the design of AI-driven platforms on Amazon Internet Providers (AWS). Since becoming a member of PDI in 2024, he has architected a compositional AI service that allows configurable assistants, brokers, information bases, and guardrails utilizing Amazon Bedrock, Aurora Serverless, AWS Lambda, and DynamoDB. With over 18 years of expertise constructing enterprise software program, Jhorlin makes a speciality of cloud-centered architectures, serverless platforms, and AI/ML options.
Jhorlin De Armas is an Architect II at PDI Applied sciences, the place he leads the design of AI-driven platforms on Amazon Internet Providers (AWS). Since becoming a member of PDI in 2024, he has architected a compositional AI service that allows configurable assistants, brokers, information bases, and guardrails utilizing Amazon Bedrock, Aurora Serverless, AWS Lambda, and DynamoDB. With over 18 years of expertise constructing enterprise software program, Jhorlin makes a speciality of cloud-centered architectures, serverless platforms, and AI/ML options. David Mbonu is a Sr. Options Architect at Amazon Internet Providers (AWS), serving to horizontal enterprise utility ISV clients construct and deploy transformational options on AWS. David has over 27 years of expertise in enterprise options structure and system engineering throughout software program, FinTech, and public cloud firms. His latest pursuits embrace AI/ML, knowledge technique, observability, resiliency, and safety. David and his household reside in Sugar Hill, GA.
David Mbonu is a Sr. Options Architect at Amazon Internet Providers (AWS), serving to horizontal enterprise utility ISV clients construct and deploy transformational options on AWS. David has over 27 years of expertise in enterprise options structure and system engineering throughout software program, FinTech, and public cloud firms. His latest pursuits embrace AI/ML, knowledge technique, observability, resiliency, and safety. David and his household reside in Sugar Hill, GA.





.jpg "Sorry MAGA, Turns Out Folks Nonetheless Like ‘Woke’ Artwork")