
![Black Forest Labs Releases FLUX.2 [klein]: Compact Move Fashions for Interactive Visible Intelligence](https://www.marktechpost.com/wp-content/uploads/2026/01/blog-banner23-30-1024x731.png "Black Forest Labs Releases FLUX.2 [klein]: Compact Move Fashions for Interactive Visible Intelligence")
{kind=link}
Black Forest Labs releases FLUX.2 [klein], a compact picture mannequin household that targets interactive visible intelligence on client {hardware}. FLUX.2 [klein] extends the FLUX.2 line with sub second technology and modifying, a unified structure for textual content to picture and picture to picture, and deployment choices that vary from native GPUs to cloud APIs, whereas holding state-of-the-art picture high quality.
From FLUX.2 [dev] to interactive visible intelligence
FLUX.2 [dev] is a 32 billion parameter rectified movement transformer for textual content conditioned picture technology and modifying, together with composition with a number of reference pictures, and runs primarily on knowledge middle class accelerators. It’s tuned for max high quality and suppleness, with lengthy sampling schedules and excessive VRAM necessities.
FLUX.2 [klein] takes the identical design path and compresses it into smaller rectified movement transformers with 4 billion and 9 billion parameters. These fashions are distilled to very quick sampling schedules, assist the identical textual content to picture and multi reference modifying duties, and are optimized for response instances beneath 1 second on fashionable GPUs.
Mannequin household and capabilities
The FLUX.2 [klein] household consists of 4 predominant open weight variants by means of a single structure.
- FLUX.2 [klein] 4B
- FLUX.2 [klein] 9B
- FLUX.2 [klein] 4B Base
- FLUX.2 [klein] 9B Base
FLUX.2 [klein] 4B and 9B are step distilled and steerage distilled fashions. They use 4 inference steps and are positioned because the quickest choices for manufacturing and interactive workloads. FLUX.2 [klein] 9B combines a 9B movement mannequin with an 8B Qwen3 textual content embedder and is described because the flagship small mannequin on the Pareto frontier for high quality versus latency throughout textual content to picture, single reference modifying, and multi reference technology.
The Base variants are undistilled variations with longer sampling schedules. The documentation lists them as basis fashions that protect the entire coaching sign and supply larger output variety. They’re supposed for effective tuning, LoRA coaching, analysis pipelines, and customized submit coaching workflows the place management is extra essential than minimal latency.
All FLUX.2 [klein] fashions assist three core duties in the identical structure. They’ll generate pictures from textual content, they will edit a single enter picture, and so they can carry out multi reference technology and modifying the place a number of enter pictures and a immediate collectively outline the goal output.
Latency, VRAM, and quantized variants
The FLUX.2 [klein] mannequin web page gives approximate finish to finish inference instances on GB200 and RTX 5090. FLUX.2 [klein] 4B is the quickest variant and is listed at about 0.3 to 1.2 seconds per picture, relying on {hardware}. FLUX.2 [klein] 9B targets about 0.5 to 2 seconds at larger high quality. The Base fashions require a number of seconds as a result of they run with 50 step sampling schedules, however they expose extra flexibility for customized pipelines.
The FLUX.2 [klein] 4B mannequin card states that 4B suits in about 13 GB of VRAM and is appropriate for GPUs just like the RTX 3090 and RTX 4070. The FLUX.2 [klein] 9B card experiences a requirement of about 29 GB of VRAM and targets {hardware} such because the RTX 4090. This implies a single excessive finish client card can host the distilled variants with full decision sampling.
To increase the attain to extra units, Black Forest Labs additionally releases FP8 and NVFP4 variations for all FLUX.2 [klein] variants, developed along with NVIDIA. FP8 quantization is described as as much as 1.6 instances sooner with as much as 40 % decrease VRAM utilization, and NVFP4 as as much as 2.7 instances sooner with as much as 55 % decrease VRAM utilization on RTX GPUs, whereas holding the core capabilities the identical.
Benchmarks towards different picture fashions
Black Forest Labs evaluates FLUX.2 [klein] by means of Elo fashion comparisons on textual content to picture, single reference modifying, and multi reference duties. The efficiency charts present FLUX.2 [klein] on the Pareto frontier of Elo rating versus latency and Elo rating versus VRAM.The commentary states that FLUX.2 [klein] matches or exceeds the standard of Qwen based mostly picture fashions at a fraction of the latency and VRAM, and that it outperforms Z Picture whereas supporting unified textual content to picture and multi reference modifying in a single structure.
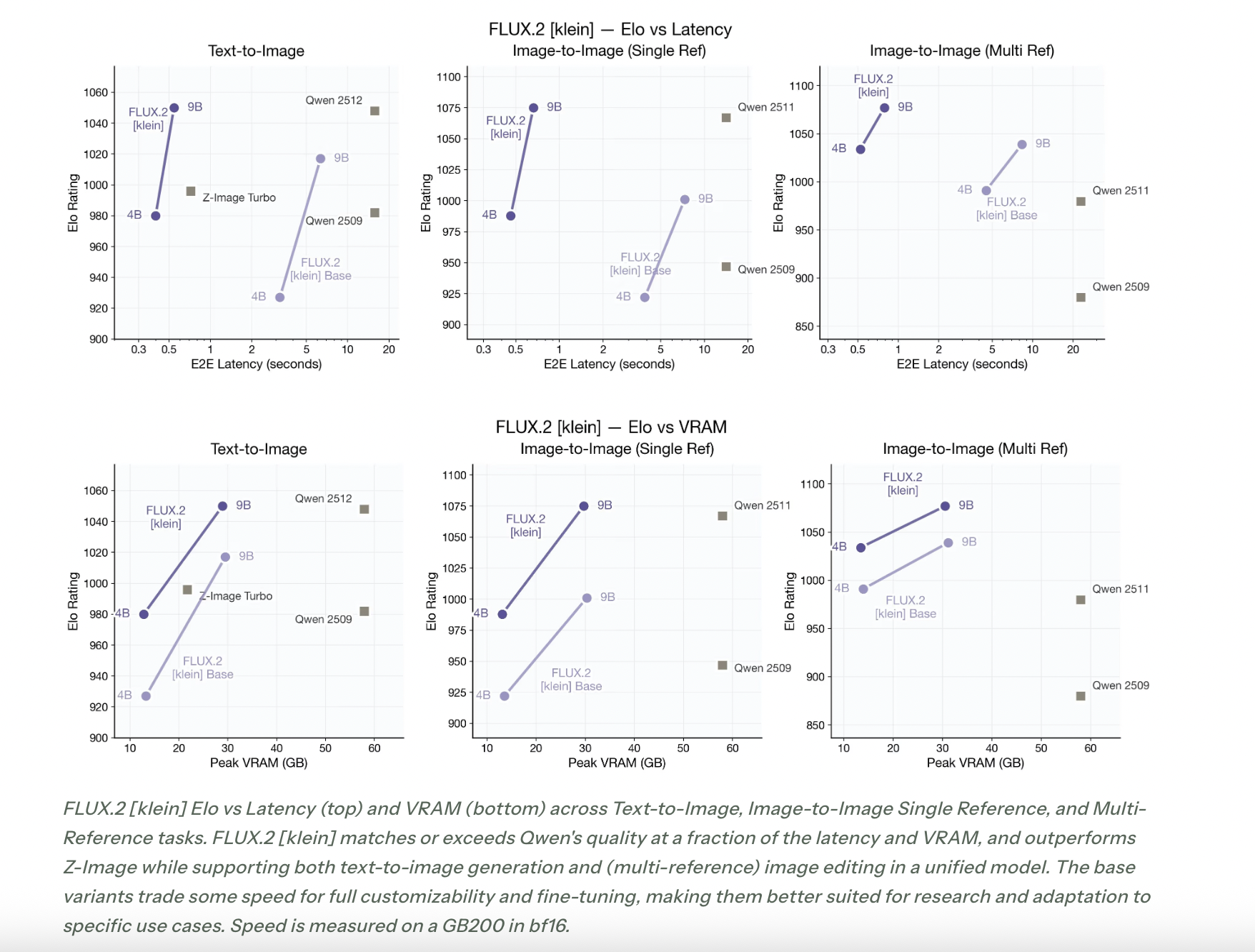
The bottom variants commerce some pace for full customizability and effective tuning, which aligns with their position as basis checkpoints for brand spanking new analysis and area particular pipelines.
Key Takeaways
- FLUX.2 [klein] is a compact rectified movement transformer household with 4B and 9B variants that helps textual content to picture, single picture modifying, and multi reference technology in a single unified structure.
- The distilled FLUX.2 [klein] 4B and 9B fashions use 4 sampling steps and are optimized for sub second inference on a single fashionable GPU, whereas the undistilled Base fashions use longer schedules and are supposed for effective tuning and analysis.
- Quantized FP8 and NVFP4 variants, constructed with NVIDIA, present as much as 1.6 instances speedup with about 40 % VRAM discount for FP8 and as much as 2.7 instances speedup with about 55 % VRAM discount for NVFP4 on RTX GPUs.
Try the Technical particulars, Repo and Mannequin weights. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as nicely.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at remodeling advanced datasets into actionable insights.