

{kind=link}
The panorama of multimodal massive language fashions (MLLMs) has shifted from experimental ‘wrappers’—the place separate imaginative and prescient or audio encoders are stitched onto a text-based spine—to native, end-to-end ‘omnimodal’ architectures. Alibaba Qwen group newest launch, Qwen3.5-Omni, represents a big milestone on this evolution. Designed as a direct competitor to flagship fashions like Gemini 3.1 Professional, the Qwen3.5-Omni collection introduces a unified framework able to processing textual content, photographs, audio, and video concurrently inside a single computational pipeline.
The technical significance of Qwen3.5-Omni lies in its Thinker-Talker structure and its use of Hybrid-Consideration Combination of Specialists (MoE) throughout all modalities. This method permits the mannequin to deal with huge context home windows and real-time interplay with out the standard latency penalties related to cascaded techniques.
Mannequin Tiers
The collection is obtainable in three sizes to stability efficiency and value:
- Plus: Excessive-complexity reasoning and most accuracy.
- Flash: Optimized for high-throughput and low-latency interplay.
- Mild: A smaller variant for efficiency-focused duties.
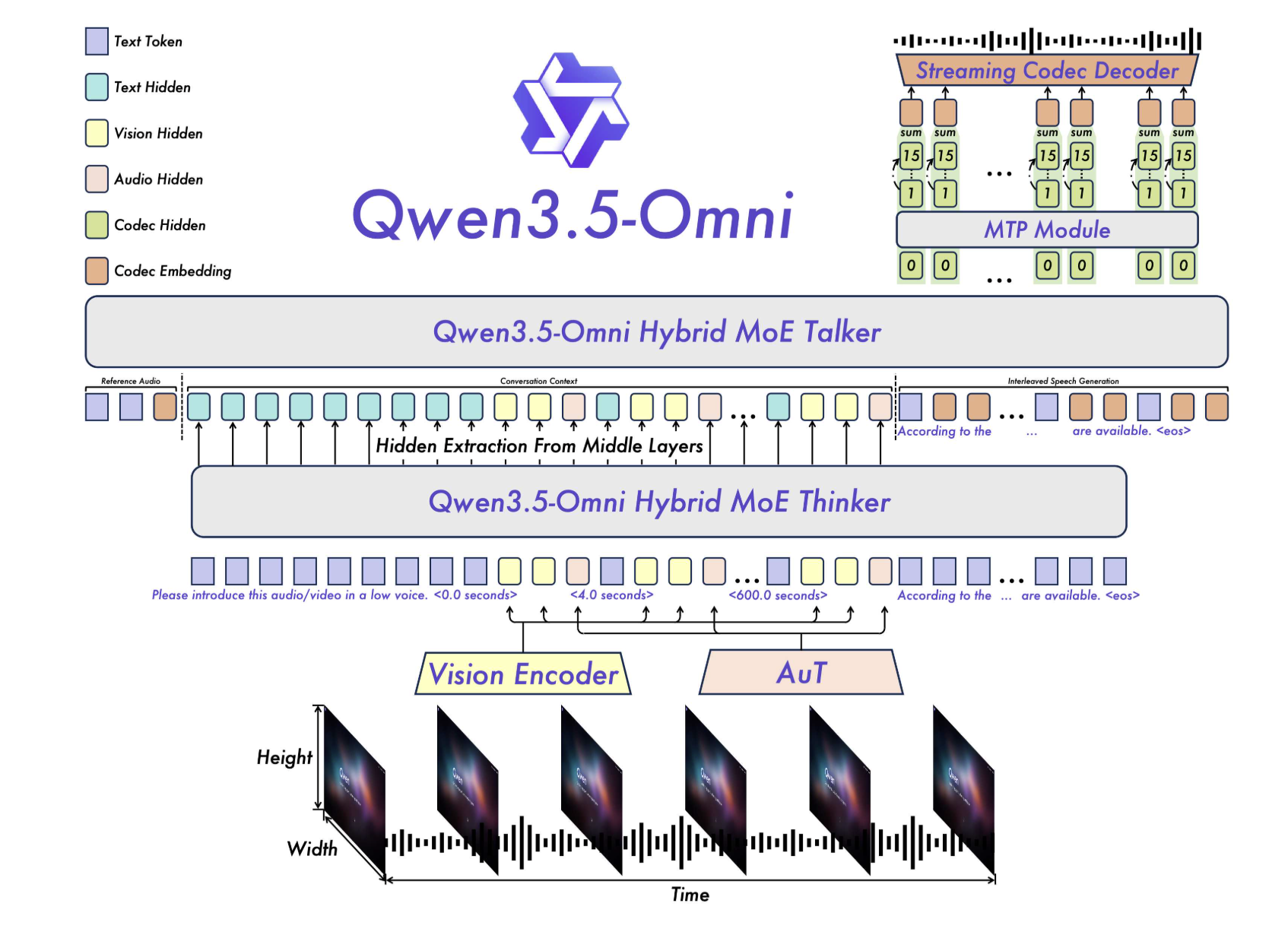
The Thinker-Talker Structure: A Unified MoE Framework
On the core of Qwen3.5-Omni is a bifurcated but tightly built-in structure consisting of two predominant elements: the Thinker and the Talker.
In earlier iterations, multimodal fashions usually relied on exterior pre-trained encoders (equivalent to Whisper for audio). Qwen3.5-Omni strikes past this by using a local Audio Transformer (AuT) encoder. This encoder was pre-trained on greater than 100 million hours of audio-visual information, offering the mannequin with a grounded understanding of temporal and acoustic nuances that conventional text-first fashions lack.
Hybrid-Consideration Combination of Specialists (MoE)
Each the Thinker and the Talker leverage Hybrid-Consideration MoE. In a normal MoE setup, solely a subset of parameters (the ‘consultants’) are activated for any given token, which permits for a excessive whole parameter rely with decrease energetic computational prices. By making use of this to a hybrid-attention mechanism, Qwen3.5-Omni can successfully weigh the significance of various modalities (e.g., focusing extra on visible tokens throughout a video evaluation process) whereas sustaining the throughput required for streaming providers.
This structure helps a 256k long-context enter, enabling the mannequin to ingest and cause over:
- Over 10 hours of steady audio.
- Over 400 seconds of 720p audio-visual content material (sampled at 1 FPS).
Benchmarking Efficiency: The ‘215 SOTA’ Milestone
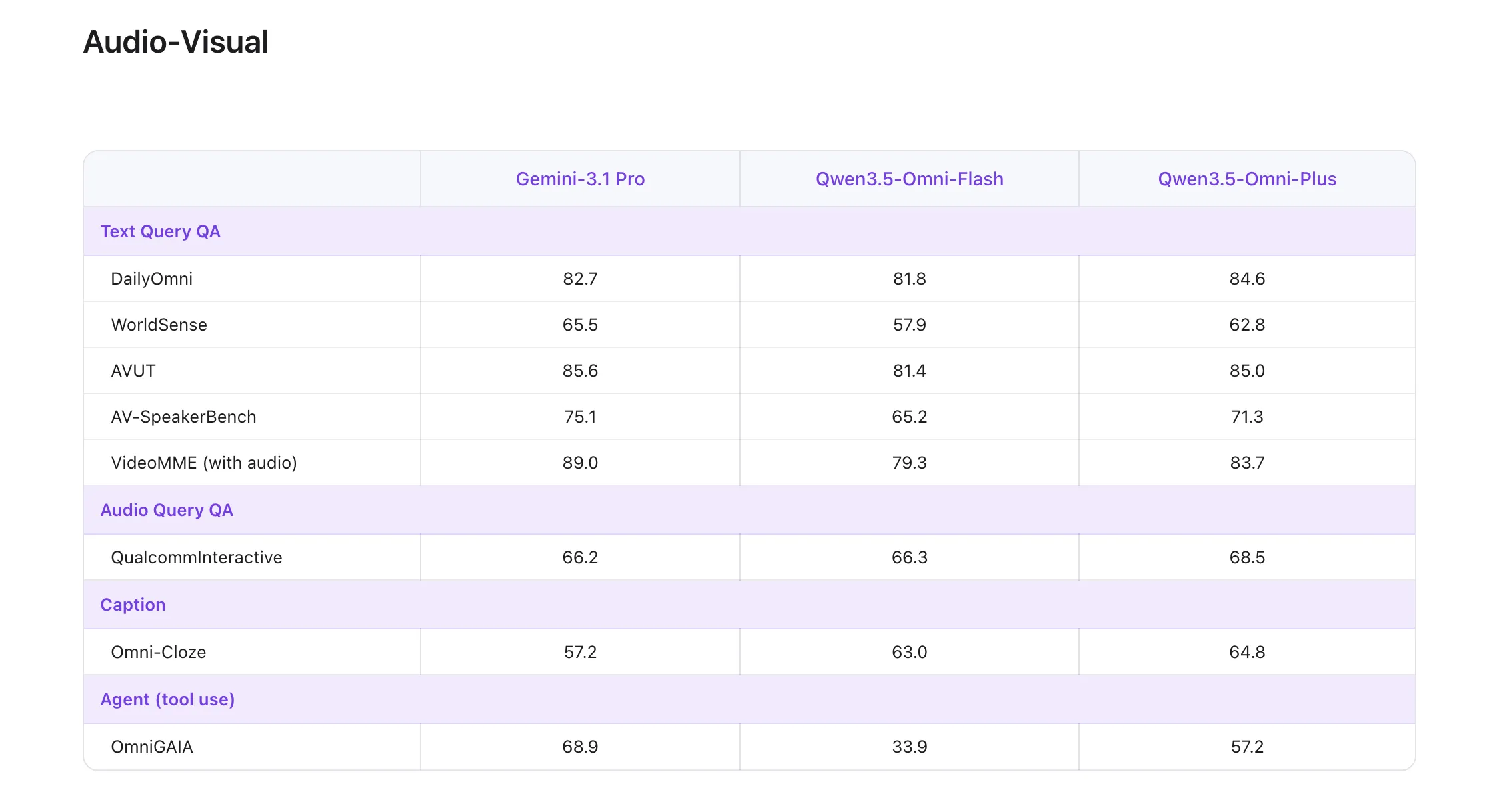
One of the vital highlighted technical claims relating to the flagship Qwen3.5-Omni-Plus mannequin is its efficiency on the worldwide leaderboard. The mannequin achieved State-of-the-Artwork (SOTA) outcomes on 215 audio and audio-visual understanding, reasoning, and interplay subtasks.
These 215 SOTA wins will not be merely a measure of broad analysis however span particular technical benchmarks, together with:
- 3 audio-visual benchmarks and 5 normal audio benchmarks.
- 8 ASR (Automated Speech Recognition) benchmarks.
- 156 language-specific Speech-to-Textual content Translation (S2TT) duties.
- 43 language-specific ASR duties.
In line with their official technical stories, Qwen3.5-Omni-Plus surpasses Gemini 3.1 Professional typically audio understanding, reasoning, recognition, and translation. In audio-visual understanding, it achieves parity with Google’s flagship, whereas sustaining the core textual content and visible efficiency of the usual Qwen3.5 collection.
Technical Options for Actual-Time Interplay
Constructing a mannequin that may ‘speak’ and ‘hear’ in real-time requires fixing particular engineering challenges associated to streaming stability and conversational circulation.
ARIA: Adaptive Fee Interleave Alignment
A typical failure mode in streaming voice interplay is ‘speech instability.’ As a result of textual content tokens and speech tokens have totally different encoding efficiencies, a mannequin could misinterpret numbers or stutter when trying to synchronize its textual content reasoning with its audio output.
To handle this, Alibaba Qwen group developed ARIA (Adaptive Fee Interleave Alignment). This method dynamically aligns textual content and speech items throughout technology. By adjusting the interleave charge primarily based on the density of the data being processed, ARIA improves the naturalness and robustness of speech synthesis with out rising latency.
Semantic Interruption and Flip-Taking
For AI builders constructing voice assistants, dealing with interruptions is notoriously troublesome. Qwen3.5-Omni introduces native turn-taking intent recognition. This enables the mannequin to differentiate between ‘backchanneling’ (non-meaningful background noise or listener suggestions like ‘uh-huh’) and an precise semantic interruption the place the person intends to take the ground. This functionality is baked immediately into the mannequin’s API, enabling extra human-like, full-duplex conversations.
Emergent Functionality: Audio-Visible Vibe Coding
Maybe probably the most distinctive function recognized in the course of the native multimodal scaling of Qwen3.5-Omni is Audio-Visible Vibe Coding. In contrast to conventional code technology that depends on textual content prompts, Qwen3.5-Omni can carry out coding duties primarily based immediately on audio-visual directions.
For example, a developer might file a video of a software program UI, verbally describe a bug whereas pointing at particular components, and the mannequin can immediately generate the repair. This emergence means that the mannequin has developed a cross-modal mapping between visible UI hierarchies, verbal intent, and symbolic code logic.
Key Takeaways
- Qwen3.5-Omni makes use of a local Thinker-Talker multimodal structure for unified textual content, audio, and video processing.
- The mannequin helps 256k context, 10+ hours of audio, and 400+ seconds of 720p video at 1 FPS.
- Alibaba stories speech recognition in 113 languages/dialects and speech technology in 36 languages/dialects.
- Key system options embrace semantic interruption, turn-taking intent recognition, TMRoPE, and ARIA for realtime interplay.
Take a look at the Technical particulars, Qwenchat, On-line demo on HF and Offline demo on HF. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as effectively.