

{kind=link}
We deployed 100 reinforcement studying (RL)-controlled automobiles into rush-hour freeway visitors to clean congestion and scale back gasoline consumption for everybody. Our aim is to deal with “stop-and-go” waves, these irritating slowdowns and speedups that often haven’t any clear trigger however result in congestion and vital power waste. To coach environment friendly flow-smoothing controllers, we constructed quick, data-driven simulations that RL brokers work together with, studying to maximise power effectivity whereas sustaining throughput and working safely round human drivers.
Total, a small proportion of well-controlled autonomous autos (AVs) is sufficient to considerably enhance visitors stream and gasoline effectivity for all drivers on the highway. Furthermore, the skilled controllers are designed to be deployable on most trendy autos, working in a decentralized method and counting on commonplace radar sensors. In our newest paper, we discover the challenges of deploying RL controllers on a large-scale, from simulation to the sphere, throughout this 100-car experiment.
The challenges of phantom jams
A stop-and-go wave transferring backwards by freeway visitors.
If you happen to drive, you’ve certainly skilled the frustration of stop-and-go waves, these seemingly inexplicable visitors slowdowns that seem out of nowhere after which instantly clear up. These waves are sometimes attributable to small fluctuations in our driving habits that get amplified by the stream of visitors. We naturally modify our pace based mostly on the automobile in entrance of us. If the hole opens, we pace as much as sustain. In the event that they brake, we additionally decelerate. However attributable to our nonzero response time, we would brake only a bit tougher than the automobile in entrance. The subsequent driver behind us does the identical, and this retains amplifying. Over time, what began as an insignificant slowdown turns right into a full cease additional again in visitors. These waves transfer backward by the visitors stream, resulting in vital drops in power effectivity attributable to frequent accelerations, accompanied by elevated CO2 emissions and accident danger.
And this isn’t an remoted phenomenon! These waves are ubiquitous on busy roads when the visitors density exceeds a essential threshold. So how can we deal with this drawback? Conventional approaches like ramp metering and variable pace limits try to handle visitors stream, however they usually require expensive infrastructure and centralized coordination. A extra scalable method is to make use of AVs, which may dynamically modify their driving habits in real-time. Nevertheless, merely inserting AVs amongst human drivers isn’t sufficient: they need to additionally drive in a wiser approach that makes visitors higher for everybody, which is the place RL is available in.
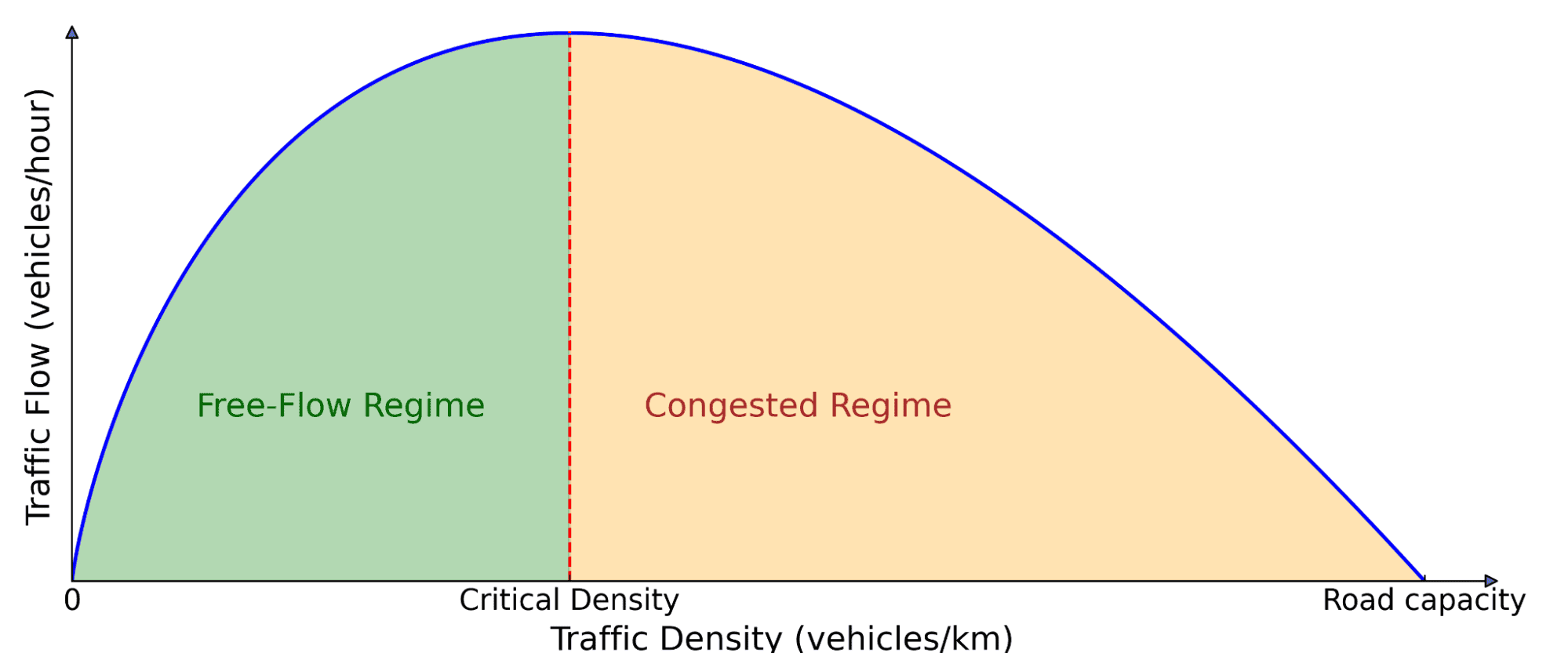
Basic diagram of visitors stream. The variety of automobiles on the highway (density) impacts how a lot visitors is transferring ahead (stream). At low density, including extra automobiles will increase stream as a result of extra autos can move by. However past a essential threshold, automobiles begin blocking one another, resulting in congestion, the place including extra automobiles really slows down total motion.
Reinforcement studying for wave-smoothing AVs
RL is a robust management method the place an agent learns to maximise a reward sign by interactions with an surroundings. The agent collects expertise by trial and error, learns from its errors, and improves over time. In our case, the surroundings is a mixed-autonomy visitors situation, the place AVs study driving methods to dampen stop-and-go waves and scale back gasoline consumption for each themselves and close by human-driven autos.
Coaching these RL brokers requires quick simulations with real looking visitors dynamics that may replicate freeway stop-and-go habits. To realize this, we leveraged experimental information collected on Interstate 24 (I-24) close to Nashville, Tennessee, and used it to construct simulations the place autos replay freeway trajectories, creating unstable visitors that AVs driving behind them study to clean out.
Simulation replaying a freeway trajectory that displays a number of stop-and-go waves.
We designed the AVs with deployment in thoughts, making certain that they will function utilizing solely fundamental sensor details about themselves and the automobile in entrance. The observations include the AV’s pace, the pace of the main automobile, and the house hole between them. Given these inputs, the RL agent then prescribes both an instantaneous acceleration or a desired pace for the AV. The important thing benefit of utilizing solely these native measurements is that the RL controllers may be deployed on most trendy autos in a decentralized approach, with out requiring extra infrastructure.
Reward design
Essentially the most difficult half is designing a reward operate that, when maximized, aligns with the completely different goals that we need the AVs to attain:
- Wave smoothing: Scale back stop-and-go oscillations.
- Power effectivity: Decrease gasoline consumption for all autos, not simply AVs.
- Security: Guarantee cheap following distances and keep away from abrupt braking.
- Driving consolation: Keep away from aggressive accelerations and decelerations.
- Adherence to human driving norms: Guarantee a “regular” driving habits that doesn’t make surrounding drivers uncomfortable.
Balancing these goals collectively is tough, as appropriate coefficients for every time period should be discovered. For example, if minimizing gasoline consumption dominates the reward, RL AVs study to return to a cease in the midst of the freeway as a result of that’s power optimum. To stop this, we launched dynamic minimal and most hole thresholds to make sure protected and cheap habits whereas optimizing gasoline effectivity. We additionally penalized the gasoline consumption of human-driven autos behind the AV to discourage it from studying a egocentric habits that optimizes power financial savings for the AV on the expense of surrounding visitors. Total, we intention to strike a steadiness between power financial savings and having an inexpensive and protected driving habits.
Simulation outcomes
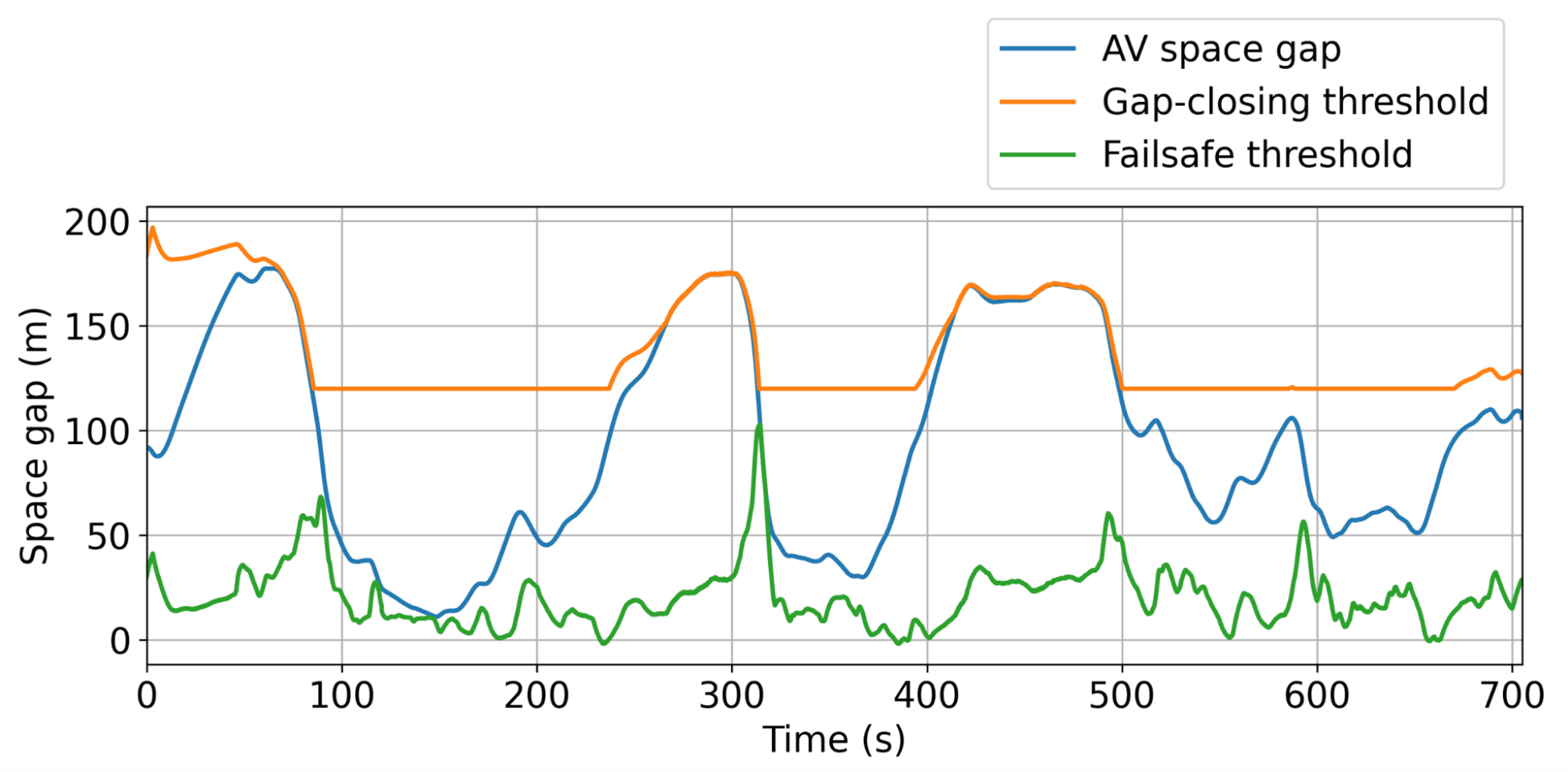
Illustration of the dynamic minimal and most hole thresholds, inside which the AV can function freely to clean visitors as effectively as attainable.
The standard habits discovered by the AVs is to keep up barely bigger gaps than human drivers, permitting them to soak up upcoming, presumably abrupt, visitors slowdowns extra successfully. In simulation, this method resulted in vital gasoline financial savings of as much as 20% throughout all highway customers in essentially the most congested eventualities, with fewer than 5% of AVs on the highway. And these AVs don’t must be particular autos! They’ll merely be commonplace shopper automobiles outfitted with a sensible adaptive cruise management (ACC), which is what we examined at scale.
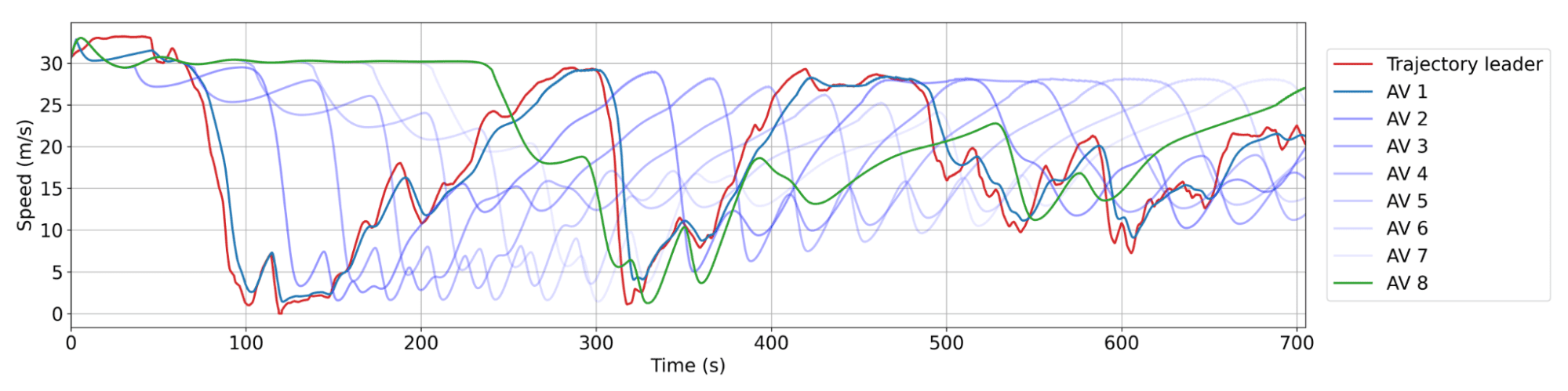
Smoothing habits of RL AVs. Crimson: a human trajectory from the dataset. Blue: successive AVs within the platoon, the place AV 1 is the closest behind the human trajectory. There may be usually between 20 and 25 human autos between AVs. Every AV doesn’t decelerate as a lot or speed up as quick as its chief, resulting in reducing wave amplitude over time and thus power financial savings.
100 AV discipline take a look at: deploying RL at scale


Our 100 automobiles parked at our operational heart through the experiment week.
Given the promising simulation outcomes, the pure subsequent step was to bridge the hole from simulation to the freeway. We took the skilled RL controllers and deployed them on 100 autos on the I-24 throughout peak visitors hours over a number of days. This massive-scale experiment, which we referred to as the MegaVanderTest, is the most important mixed-autonomy traffic-smoothing experiment ever performed.
Earlier than deploying RL controllers within the discipline, we skilled and evaluated them extensively in simulation and validated them on the {hardware}. Total, the steps in direction of deployment concerned:
- Coaching in data-driven simulations: We used freeway visitors information from I-24 to create a coaching surroundings with real looking wave dynamics, then validate the skilled agent’s efficiency and robustness in quite a lot of new visitors eventualities.
- Deployment on {hardware}: After being validated in robotics software program, the skilled controller is uploaded onto the automotive and is ready to management the set pace of the automobile. We function by the automobile’s on-board cruise management, which acts as a lower-level security controller.
- Modular management framework: One key problem through the take a look at was not gaining access to the main automobile data sensors. To beat this, the RL controller was built-in right into a hierarchical system, the MegaController, which mixes a pace planner information that accounts for downstream visitors situations, with the RL controller as the ultimate choice maker.
- Validation on {hardware}: The RL brokers had been designed to function in an surroundings the place most autos had been human-driven, requiring sturdy insurance policies that adapt to unpredictable habits. We confirm this by driving the RL-controlled autos on the highway underneath cautious human supervision, making modifications to the management based mostly on suggestions.

Every of the 100 automobiles is related to a Raspberry Pi, on which the RL controller (a small neural community) is deployed.
The RL controller straight controls the onboard adaptive cruise management (ACC) system, setting its pace and desired following distance.
As soon as validated, the RL controllers had been deployed on 100 automobiles and pushed on I-24 throughout morning rush hour. Surrounding visitors was unaware of the experiment, making certain unbiased driver habits. Information was collected through the experiment from dozens of overhead cameras positioned alongside the freeway, which led to the extraction of thousands and thousands of particular person automobile trajectories by a pc imaginative and prescient pipeline. Metrics computed on these trajectories point out a pattern of lowered gasoline consumption round AVs, as anticipated from simulation outcomes and former smaller validation deployments. For example, we are able to observe that the nearer individuals are driving behind our AVs, the much less gasoline they seem to devour on common (which is calculated utilizing a calibrated power mannequin):
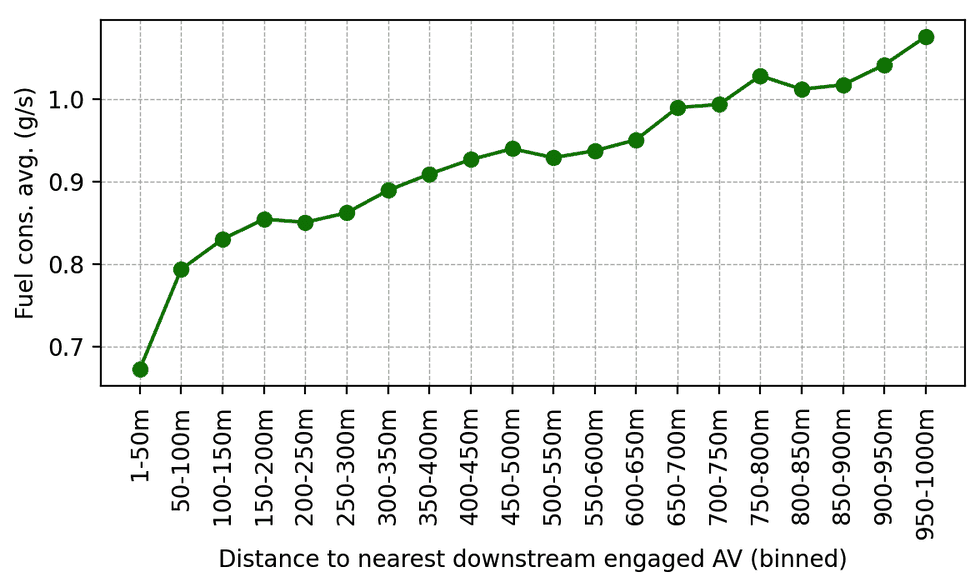
Common gasoline consumption as a operate of distance behind the closest engaged RL-controlled AV within the downstream visitors. As human drivers get additional away behind AVs, their common gasoline consumption will increase.
One other approach to measure the affect is to measure the variance of the speeds and accelerations: the decrease the variance, the much less amplitude the waves ought to have, which is what we observe from the sphere take a look at information. Total, though getting exact measurements from a considerable amount of digicam video information is sophisticated, we observe a pattern of 15 to twenty% of power financial savings round our managed automobiles.
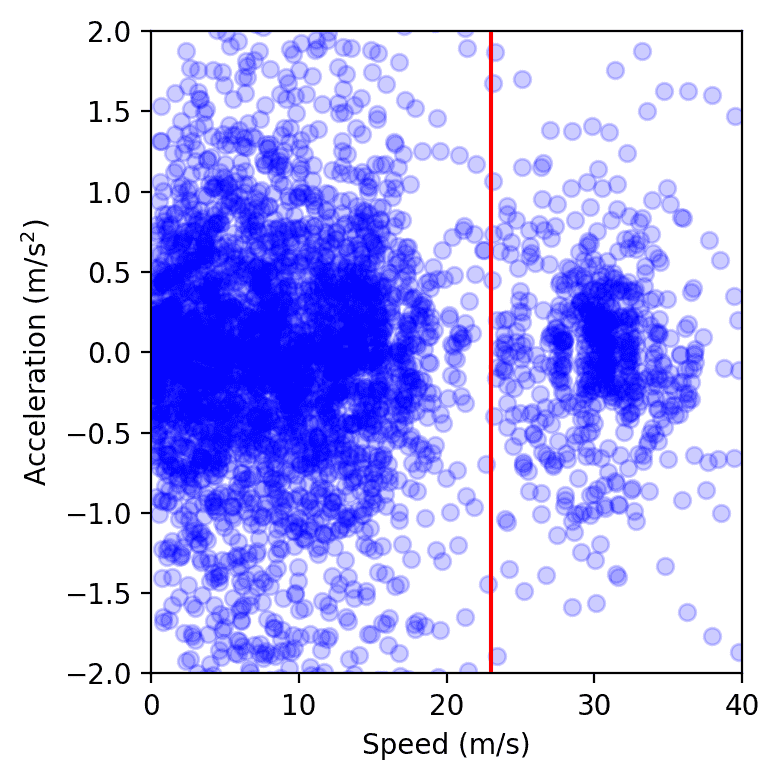
Information factors from all autos on the freeway over a single day of the experiment, plotted in speed-acceleration house. The cluster to the left of the pink line represents congestion, whereas the one on the proper corresponds to free stream. We observe that the congestion cluster is smaller when AVs are current, as measured by computing the world of a tender convex envelope or by becoming a Gaussian kernel.
Remaining ideas
The 100-car discipline operational take a look at was decentralized, with no express cooperation or communication between AVs, reflective of present autonomy deployment, and bringing us one step nearer to smoother, extra energy-efficient highways. But, there may be nonetheless huge potential for enchancment. Scaling up simulations to be sooner and extra correct with higher human-driving fashions is essential for bridging the simulation-to-reality hole. Equipping AVs with extra visitors information, whether or not by superior sensors or centralized planning, might additional enhance the efficiency of the controllers. For example, whereas multi-agent RL is promising for enhancing cooperative management methods, it stays an open query how enabling express communication between AVs over 5G networks might additional enhance stability and additional mitigate stop-and-go waves. Crucially, our controllers combine seamlessly with present adaptive cruise management (ACC) methods, making discipline deployment possible at scale. The extra autos outfitted with good traffic-smoothing management, the less waves we’ll see on our roads, that means much less air pollution and gasoline financial savings for everybody!
Many contributors took half in making the MegaVanderTest occur! The complete listing is out there on the CIRCLES venture web page, together with extra particulars concerning the venture.
Learn extra: [paper]