

{kind=link}
Companies face a rising problem: prospects want solutions quick, however assist groups are overwhelmed. Help documentation like product manuals and data base articles usually require customers to go looking via a whole lot of pages, and assist brokers usually run 20–30 buyer queries per day to find particular info.
This publish demonstrates the right way to clear up this problem by constructing an AI-powered web site assistant utilizing Amazon Bedrock and Amazon Bedrock Data Bases. This resolution is designed to learn each inner groups and exterior prospects, and may provide the next advantages:
- Prompt, related solutions for purchasers, assuaging the necessity to search via documentation
- A strong data retrieval system for assist brokers, decreasing decision time
- Round the clock automated assist
Resolution overview
The answer makes use of Retrieval-Augmented Technology (RAG) to retrieve related info from a data base and return it to the consumer based mostly on their entry. It consists of the next key elements:
- Amazon Bedrock Data Bases – Content material from the corporate’s web site is crawled and saved within the data base. Paperwork from an Amazon Easy Storage Service (Amazon S3) bucket, together with manuals and troubleshooting guides, are additionally listed and saved within the data base. With Amazon Bedrock Data Bases, you may configure a number of knowledge sources and use the filter configurations to distinguish between inner and exterior info. This helps shield inner knowledge via superior safety controls.
- Amazon Bedrock managed LLMs – A big language mannequin (LLM) from Amazon Bedrock generates AI-powered responses to consumer questions.
- Scalable serverless structure – The answer makes use of Amazon Elastic Container Service (Amazon ECS) to host the UI, and an AWS Lambda operate to deal with the consumer requests.
- Automated CI/CD deployment – The answer makes use of the AWS Cloud Improvement Equipment (AWS CDK) to deal with steady integration and supply (CI/CD) deployment.
The next diagram illustrates the structure of this resolution.
The workflow consists of the next steps:
- Amazon Bedrock Data Bases processes paperwork uploaded to Amazon S3 by chunking them and producing embeddings. Moreover, the Amazon Bedrock net crawler accesses chosen web sites to extract and ingest their contents.
- The online utility runs as an ECS utility. Inner and exterior customers use browsers to entry the applying via Elastic Load Balancing (ELB). Customers log in to the applying utilizing their login credentials registered in an Amazon Cognito consumer pool.
- When a consumer submits a query, the applying invokes a Lambda operate, which makes use of the Amazon Bedrock APIs to retrieve the related info from the data base. It additionally provides the related knowledge supply IDs to Amazon Bedrock based mostly on consumer sort (exterior or inner) so the data base retrieves solely the knowledge obtainable to that consumer sort.
- The Lambda operate then invokes the Amazon Nova Lite LLM to generate responses. The LLM augments the knowledge from the data base to generate a response to the consumer question, which is returned from the Lambda operate and exhibited to the consumer.
Within the following sections, we show the right way to crawl and configure the exterior web site as a data base, and in addition add inner documentation.
Stipulations
You should have the next in place to deploy the answer on this publish:
Create data base and ingest web site knowledge
Step one is to construct a data base to ingest knowledge from an internet site and operational paperwork from an S3 bucket. Full the next steps to create your data base:
- On the Amazon Bedrock console, select Data Bases underneath Builder instruments within the navigation pane.
- On the Create dropdown menu, select Data Base with vector retailer.
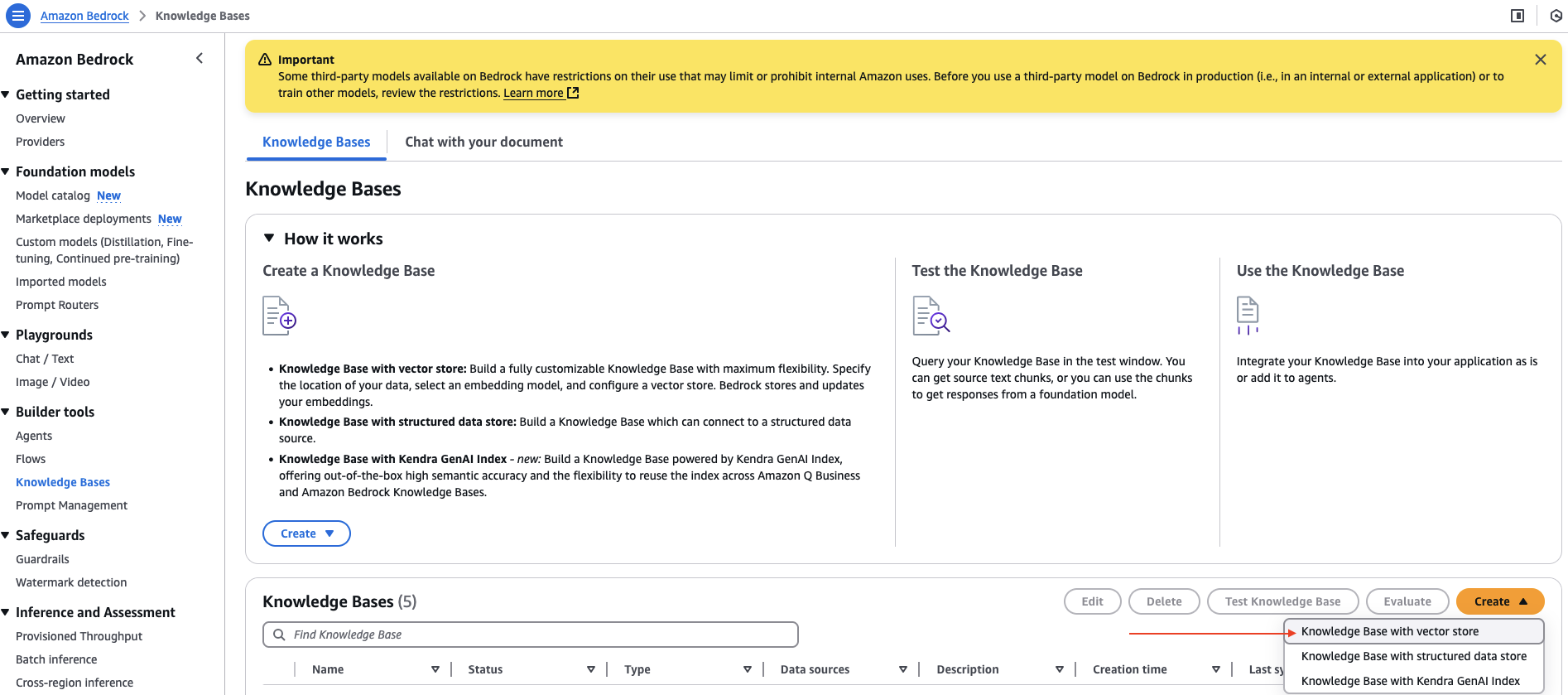
- For Data Base title, enter a reputation.
- For Select an information supply, choose Net Crawler.
- Select Subsequent.
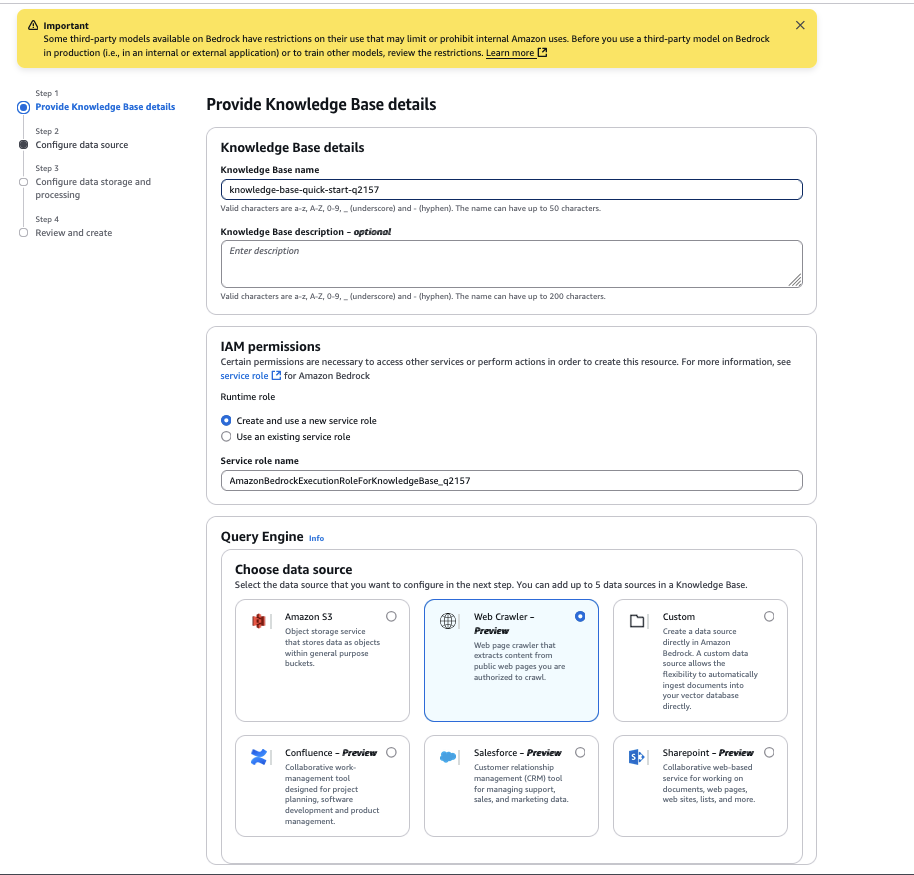
- For Knowledge supply title, enter a reputation in your knowledge supply.
- For Supply URLs, enter the goal web site HTML web page to crawl. For instance, we use
https://docs.aws.amazon.com/AmazonS3/newest/userguide/GetStartedWithS3.html. - For Web site area vary, choose Default because the crawling scope. You can even configure it to host solely domains or subdomains if you wish to limit the crawling to a selected area or subdomain.
- For URL regex filter, you may configure the URL patterns to incorporate or exclude particular URLs. For this instance, we go away this setting clean.
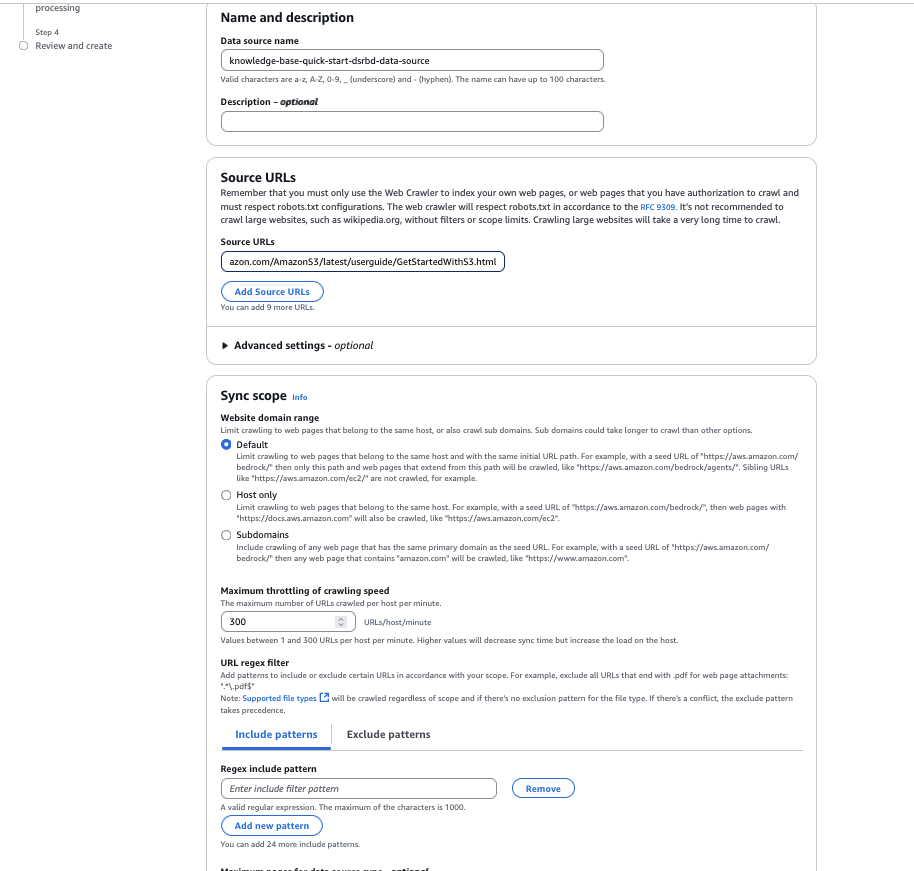
- For Chunking technique, you may configure the content material parsing choices to customise the information chunking technique. For this instance, we go away it as Default chunking.
- Select Subsequent.
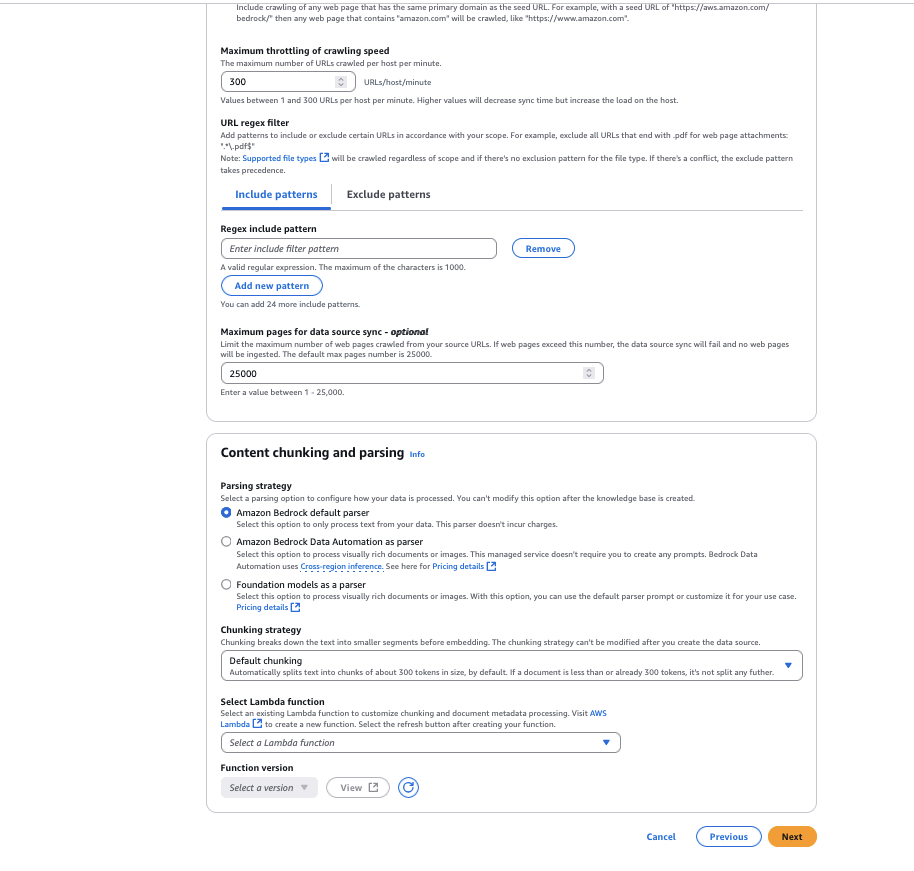
- Select the Amazon Titan Textual content Embeddings V2 mannequin, then select Apply.
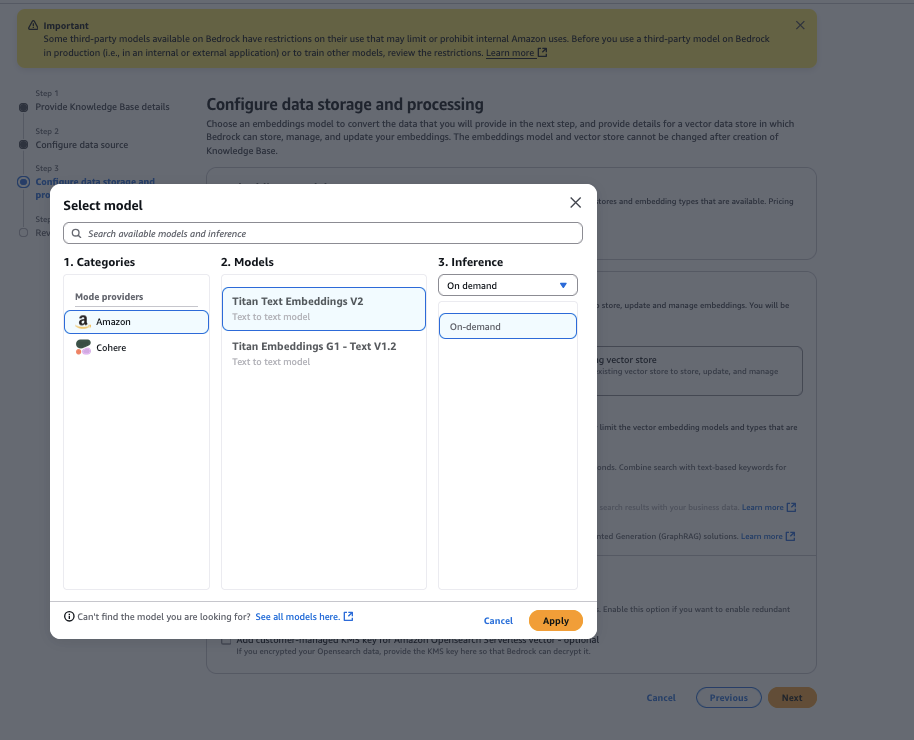
- For Vector retailer sort, choose Amazon OpenSearch Serverless, then select Subsequent.
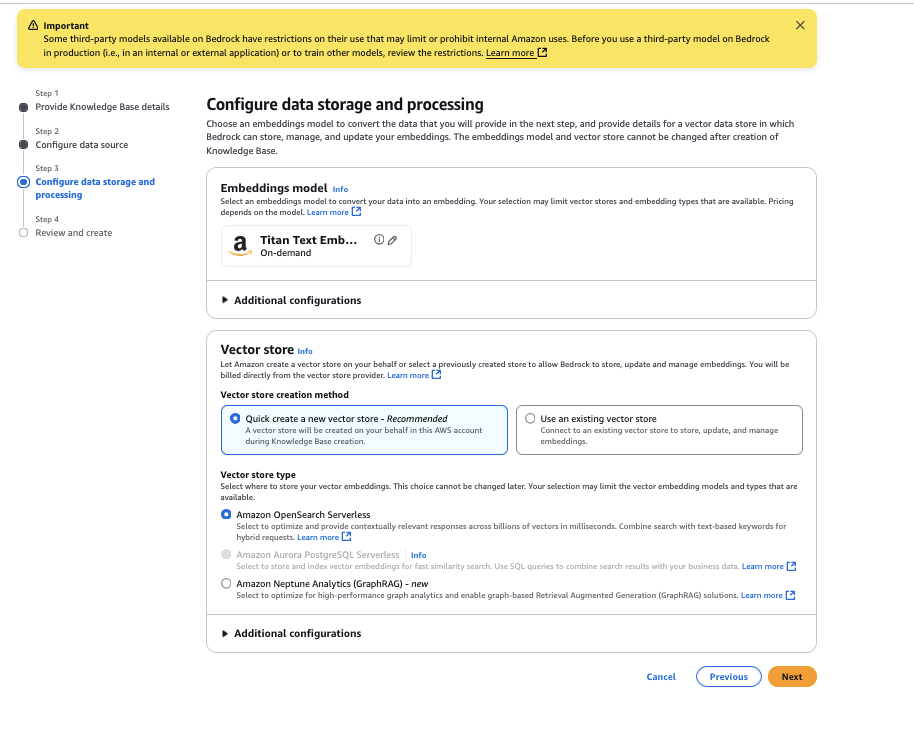
- Overview the configurations and select Create Data Base.
You’ve gotten now created a data base with the information supply configured as the web site hyperlink you supplied.
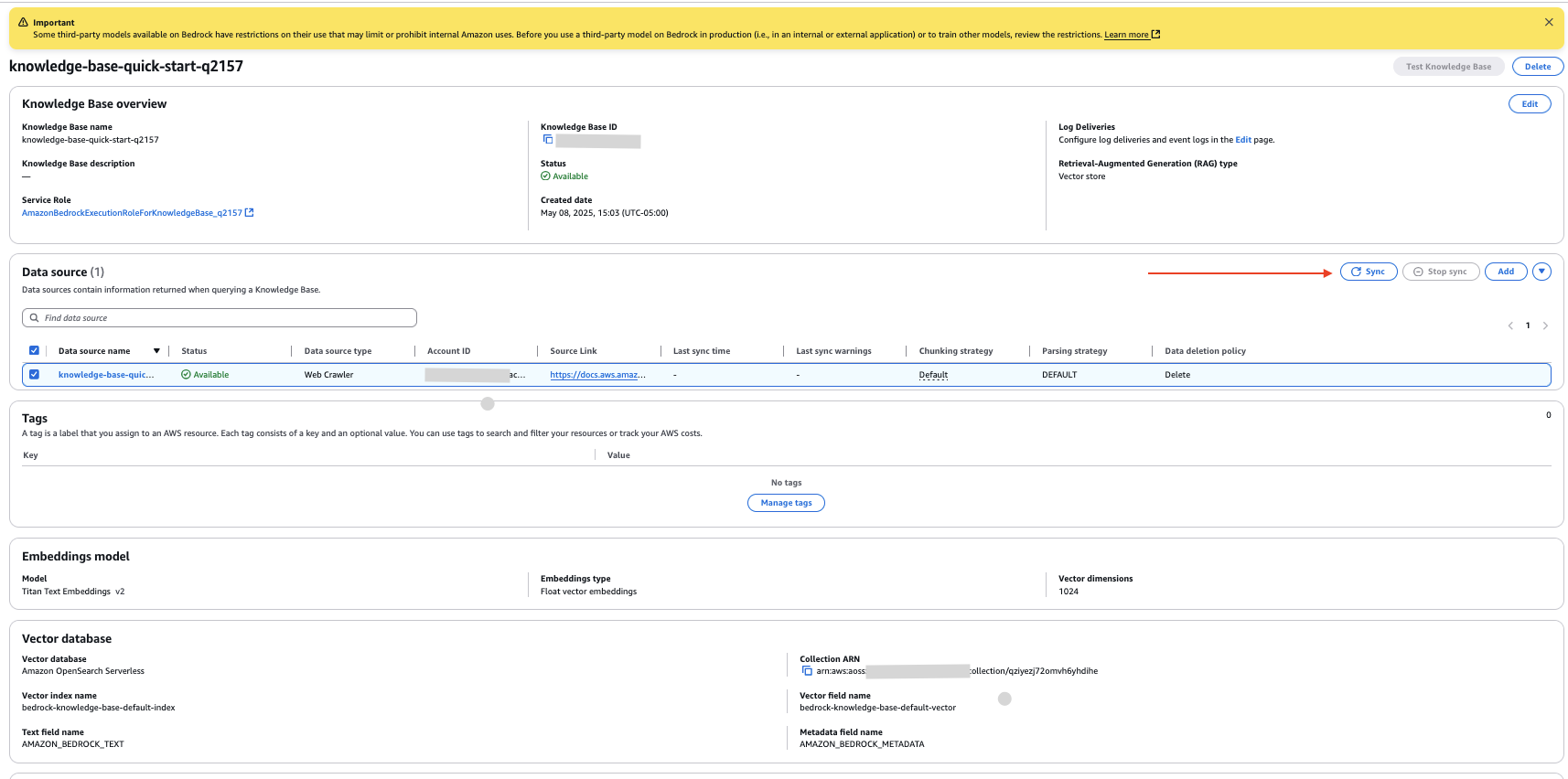
- On the data base particulars web page, choose your new knowledge supply and select Sync to crawl the web site and ingest the information.
Configure Amazon S3 knowledge supply
Full the next steps to configure paperwork out of your S3 bucket as an inner knowledge supply:
- On the data base particulars web page, select Add within the Knowledge supply part.
- Specify the information supply as Amazon S3.
- Select your S3 bucket.
- Go away the parsing technique because the default setting.
- Select Subsequent.
- Overview the configurations and select Add knowledge supply.
- Within the Knowledge supply part of the data base particulars web page, choose your new knowledge supply and select Sync to index the information from the paperwork within the S3 bucket.
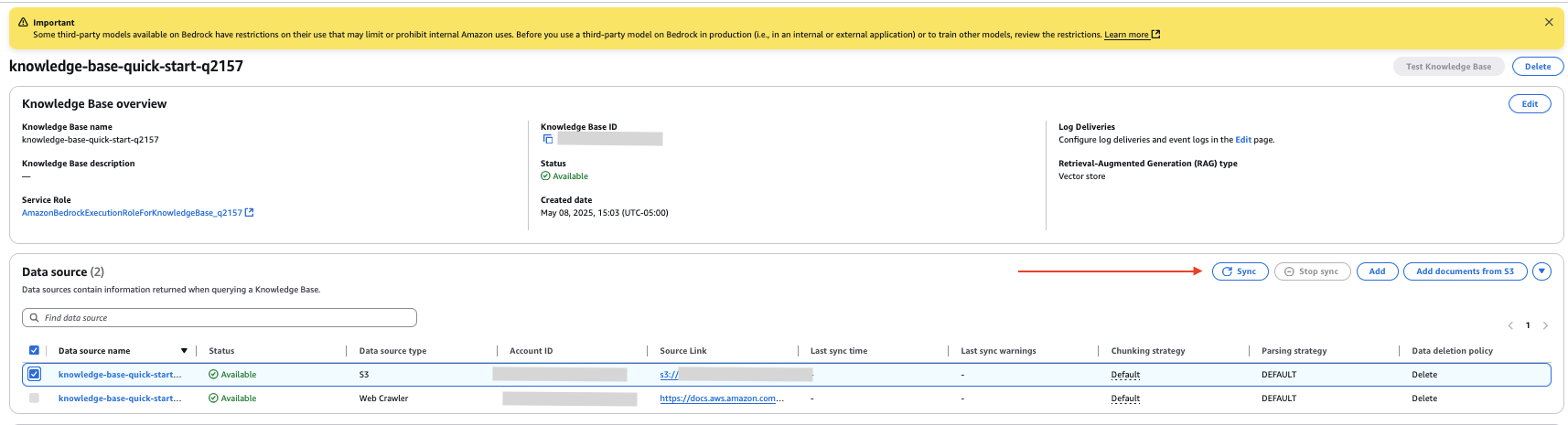
Add inner doc
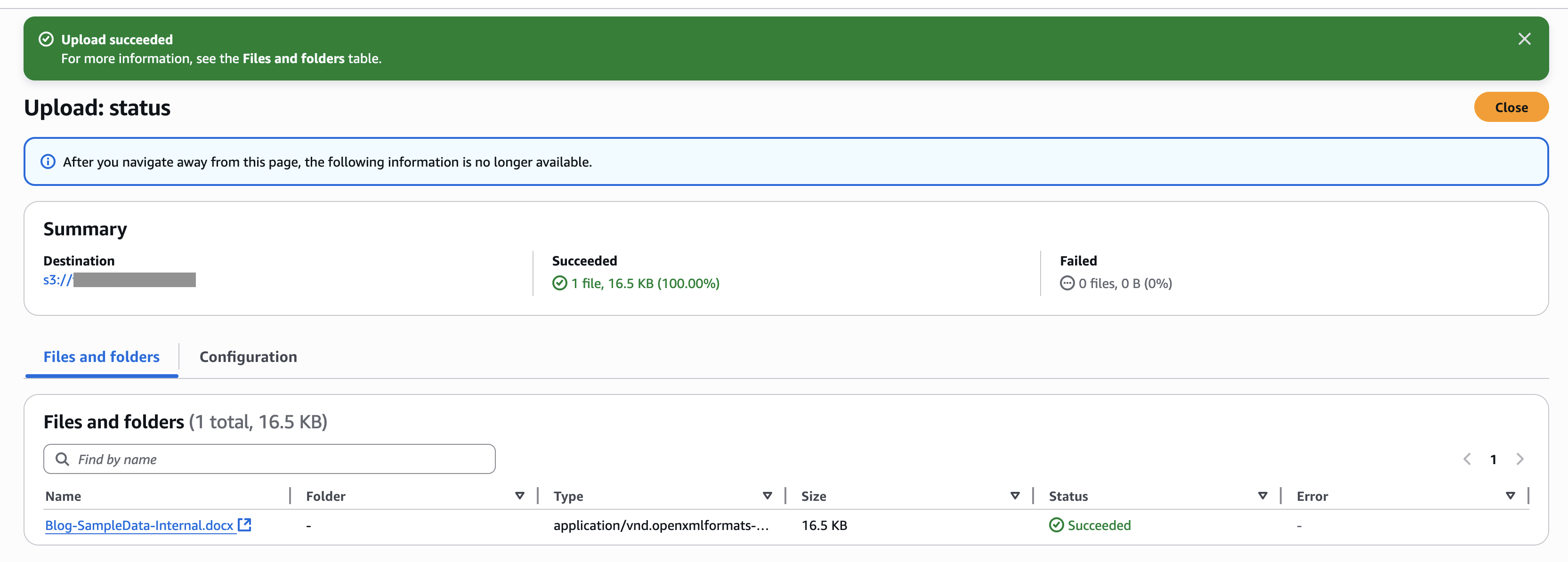
For this instance, we add a doc within the new S3 bucket knowledge supply. The next screenshot exhibits an instance of our doc.

Full the next steps to add the doc:
- On the Amazon S3 console, select Buckets within the navigation pane.
- Choose the bucket you created and select Add to add the doc.
- On the Amazon Bedrock console, go to the data base you created.
- Select the inner knowledge supply you created and select Sync to sync the uploaded doc with the vector retailer.
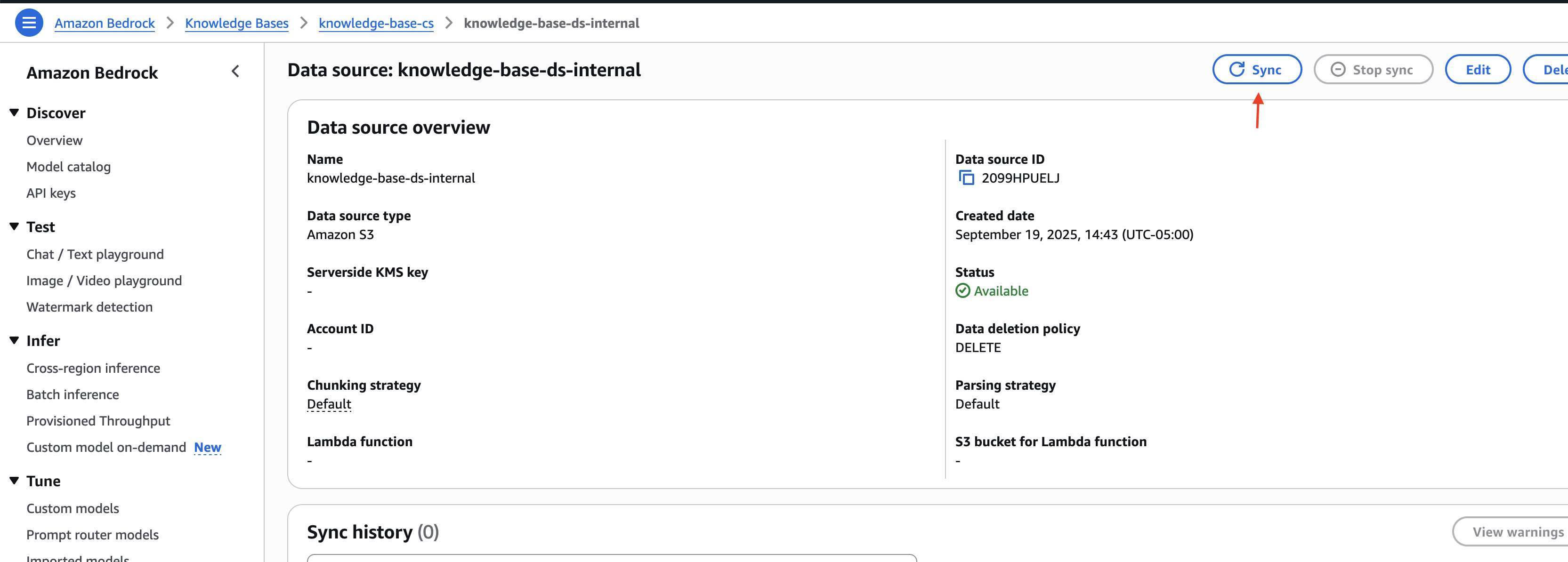
Notice the data base ID and the information supply IDs for the exterior and inner knowledge sources. You employ this info within the subsequent step when deploying the answer infrastructure.
Deploy resolution infrastructure
To deploy the answer infrastructure utilizing the AWS CDK, full the next steps:
- Obtain the code from code repository.
- Go to the iac listing contained in the downloaded mission:
cd ./customer-support-ai/iac
- Open the parameters.json file and replace the data base and knowledge supply IDs with the values captured within the earlier part:
- Observe the deployment directions outlined within the customer-support-ai/README.md file to arrange the answer infrastructure.
When the deployment is full, you’ll find the Software Load Balancer (ALB) URL and demo consumer particulars within the script execution output.
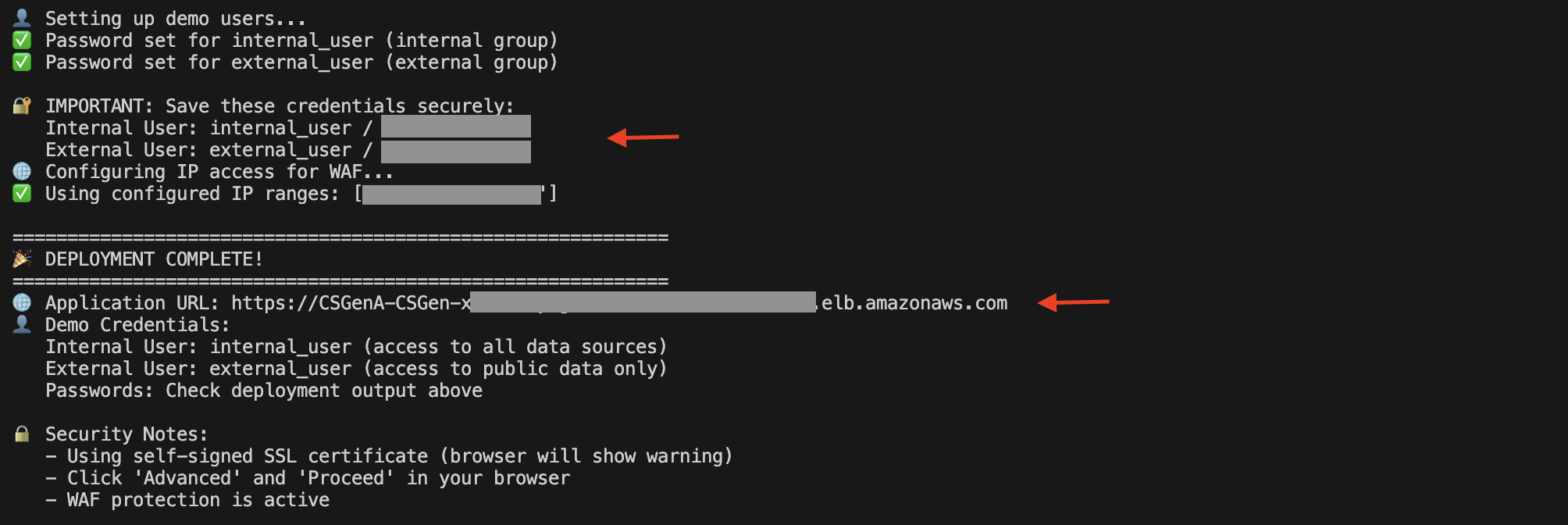
You can even open the Amazon EC2 console and select Load Balancers within the navigation pane to view the ALB.

On the ALB particulars web page, copy the DNS title. You should utilize it to entry the UI to check out the answer.

Submit questions
Let’s discover an instance of Amazon S3 service assist. This resolution helps completely different lessons of customers to assist resolve their queries whereas utilizing Amazon Bedrock Data Bases to handle particular knowledge sources (equivalent to web site content material, documentation, and assist tickets) with built-in filtering controls that separate inner operational paperwork from publicly accessible info. For instance, inner customers can entry each company-specific operational guides and public documentation, whereas exterior customers are restricted to publicly obtainable content material solely.
Open the DNS URL within the browser. Enter the exterior consumer credentials and select Login.

After you’re efficiently authenticated, you can be redirected to the house web page.
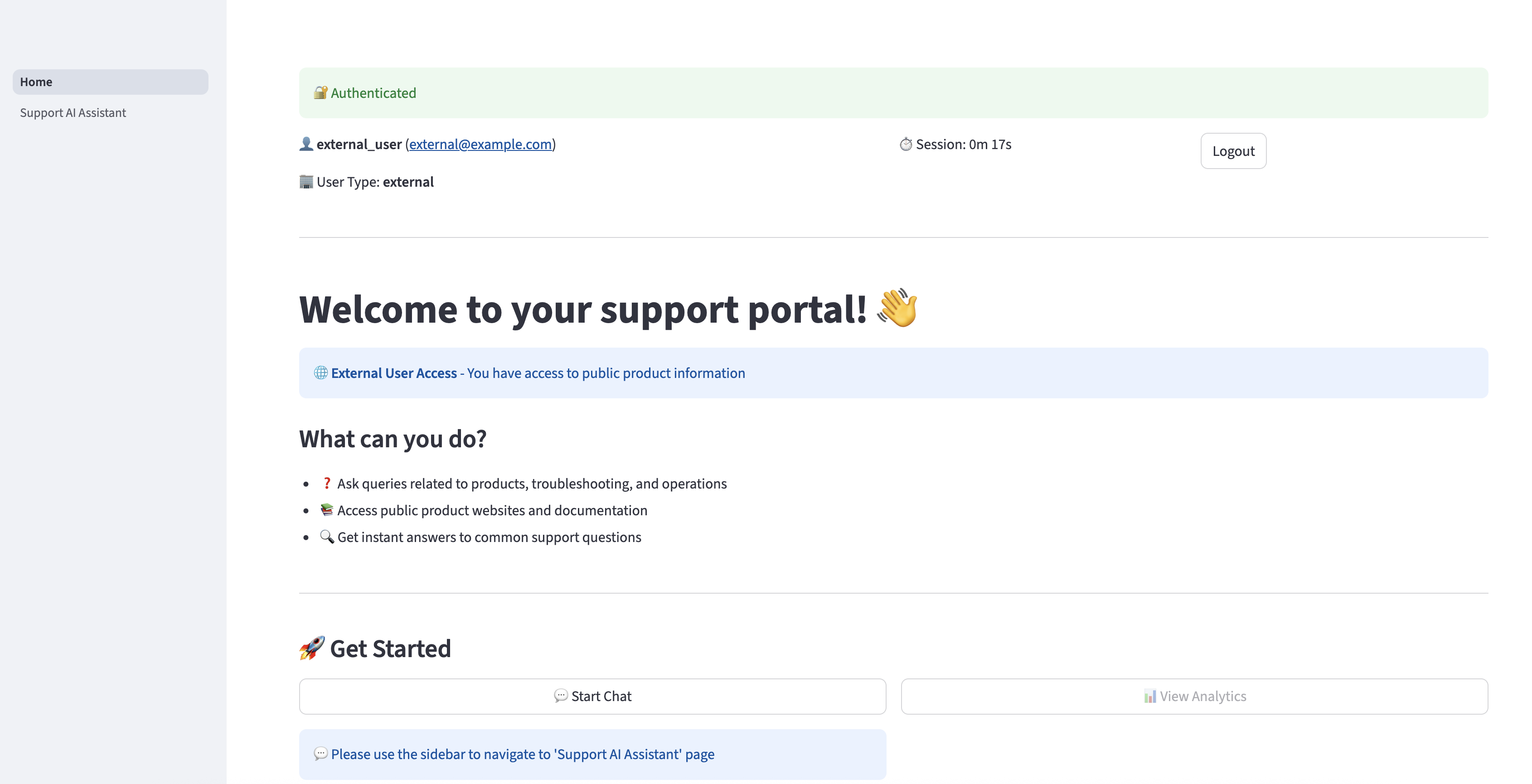
Select Help AI Assistant within the navigation pane to ask questions associated to Amazon S3. The assistant can present related responses based mostly on the knowledge obtainable within the Getting began with Amazon S3 information. Nevertheless, if an exterior consumer asks a query that’s associated to info obtainable just for inner customers, the AI assistant is not going to present the inner info to consumer and can reply solely with info obtainable for exterior customers.
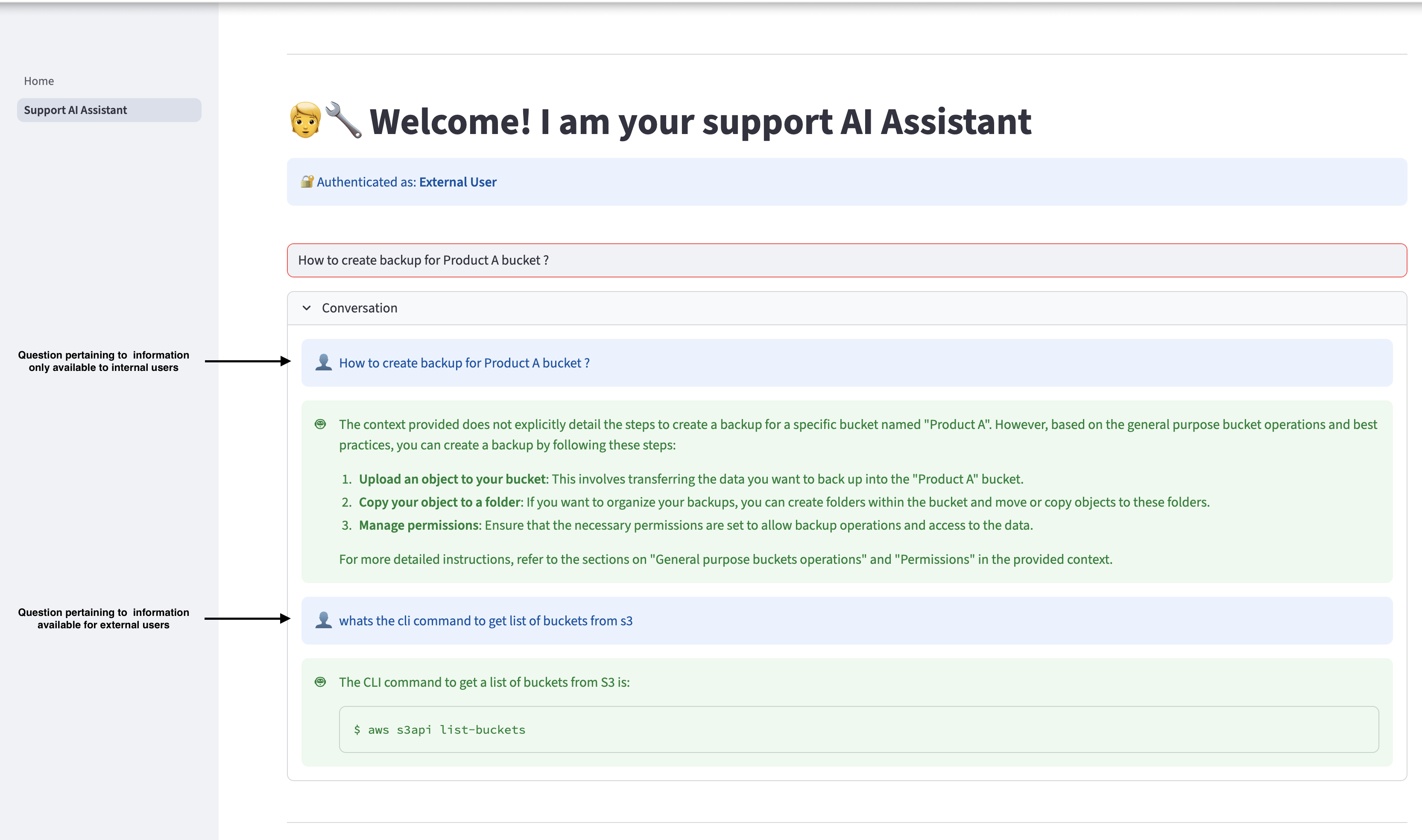
Sign off and log in once more as an inner consumer, and ask the identical queries. The inner consumer can entry the related info obtainable within the inner paperwork.

Clear up
For those who determine to cease utilizing this resolution, full the next steps to take away its related sources:
- Go to the iac listing contained in the mission code and run the next command from terminal:
- To run a cleanup script, use the next command:
- To carry out this operation manually, use the next command:
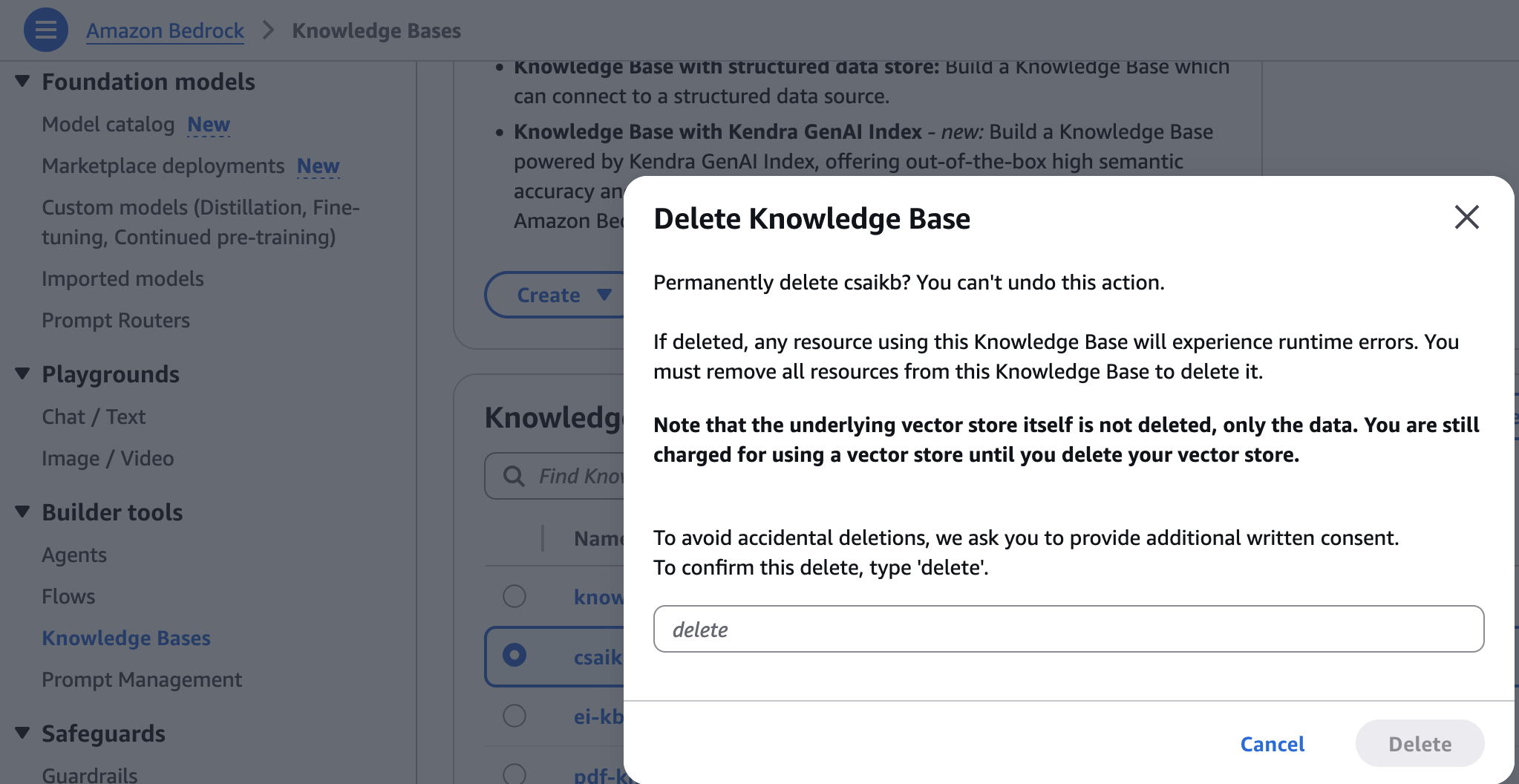
- On the Amazon Bedrock console, select Data Bases underneath Builder instruments within the navigation pane.
- Select the data base you created, then select Delete.
- Enter delete and select Delete to substantiate.
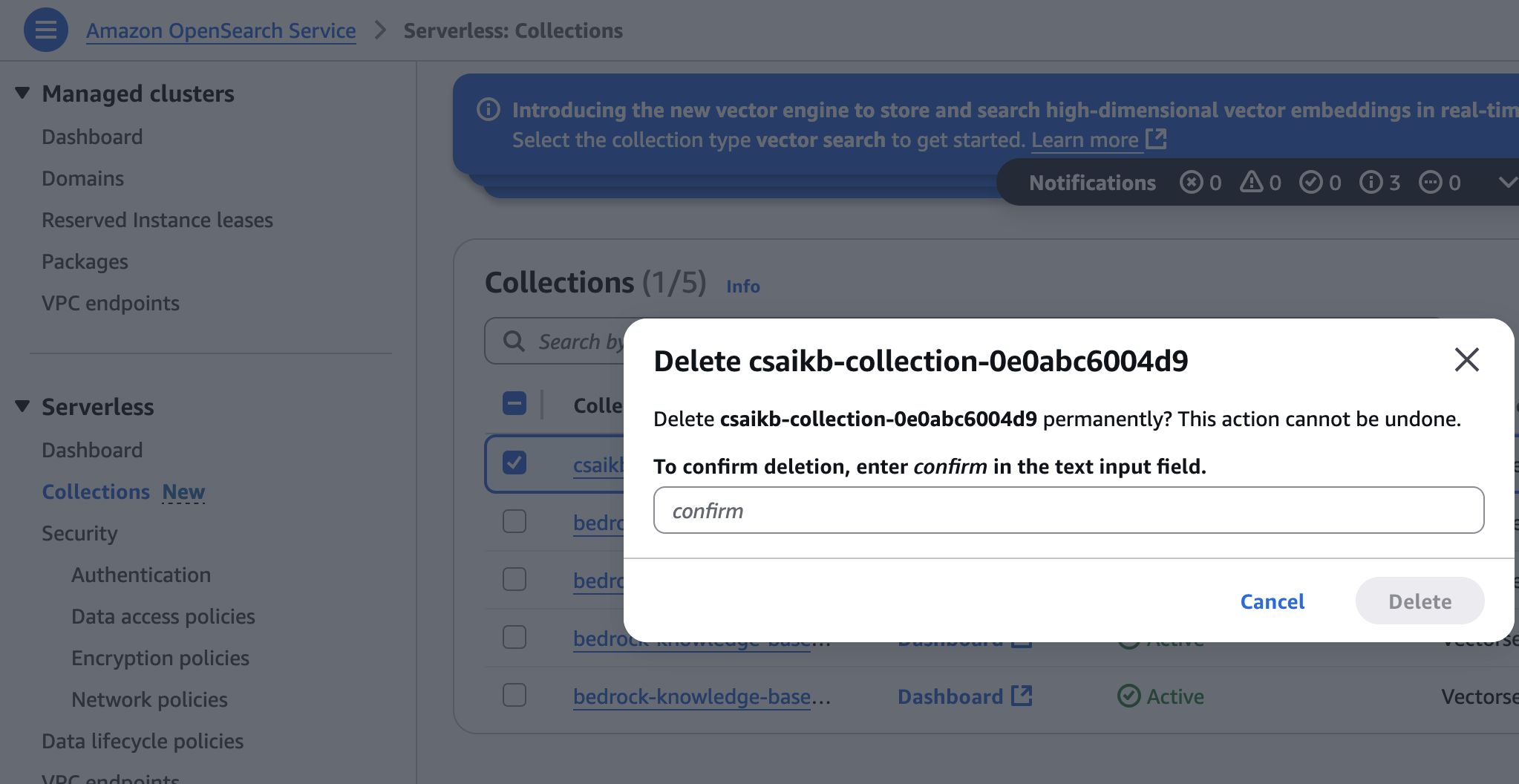
- On the OpenSearch Service console, select Collections underneath Serverless within the navigation pane.
- Select the gathering created throughout infrastructure provisioning, then select Delete.
- Enter affirm and select Delete to substantiate.
Conclusion
This publish demonstrated the right way to create an AI-powered web site assistant to retrieve info shortly by establishing a data base via net crawling and importing paperwork. You should utilize the identical strategy to develop different generative AI prototypes and functions.
For those who’re within the fundamentals of generative AI and the right way to work with FMs, together with superior prompting methods, try the hands-on course Generative AI with LLMs. This on-demand, 3-week course is for knowledge scientists and engineers who need to discover ways to construct generative AI functions with LLMs. It’s the great basis to begin constructing with Amazon Bedrock. Join to be taught extra about Amazon Bedrock.
Concerning the authors
 Shashank Jain is a Cloud Software Architect at Amazon Net Companies (AWS), specializing in generative AI options, cloud-native utility structure, and sustainability. He works with prospects to design and implement safe, scalable AI-powered functions utilizing serverless applied sciences, trendy DevSecOps practices, Infrastructure as Code, and event-driven architectures that ship measurable enterprise worth.
Shashank Jain is a Cloud Software Architect at Amazon Net Companies (AWS), specializing in generative AI options, cloud-native utility structure, and sustainability. He works with prospects to design and implement safe, scalable AI-powered functions utilizing serverless applied sciences, trendy DevSecOps practices, Infrastructure as Code, and event-driven architectures that ship measurable enterprise worth.
 Jeff Li is a Senior Cloud Software Architect with the Skilled Companies staff at AWS. He’s enthusiastic about diving deep with prospects to create options and modernize functions that assist enterprise improvements. In his spare time, he enjoys taking part in tennis, listening to music, and studying.
Jeff Li is a Senior Cloud Software Architect with the Skilled Companies staff at AWS. He’s enthusiastic about diving deep with prospects to create options and modernize functions that assist enterprise improvements. In his spare time, he enjoys taking part in tennis, listening to music, and studying.
 Ranjith Kurumbaru Kandiyil is a Knowledge and AI/ML Architect at Amazon Net Companies (AWS) based mostly in Toronto. He focuses on collaborating with prospects to architect and implement cutting-edge AI/ML options. His present focus lies in leveraging state-of-the-art synthetic intelligence applied sciences to unravel complicated enterprise challenges.
Ranjith Kurumbaru Kandiyil is a Knowledge and AI/ML Architect at Amazon Net Companies (AWS) based mostly in Toronto. He focuses on collaborating with prospects to architect and implement cutting-edge AI/ML options. His present focus lies in leveraging state-of-the-art synthetic intelligence applied sciences to unravel complicated enterprise challenges.