

{kind=link}
Some individuals wish to “be taught AI.” Others wish to construct the longer term. When you’re within the second class, bookmark this proper now – as a result of the Generative AI Scientist Roadmap 2026 isn’t one other cute syllabus. It’s the no-nonsense, industry-level blueprint for turning you from “I do know Python loops” into “I can architect brokers that run corporations.” That is the stuff Massive Tech received’t spoon-feed you however expects you to magically know in interviews.
The reality is, AI mastery isn’t one ability. It’s seven evolving worlds. Information, transformers, prompting, RAG, brokers, fine-tuning, ops – every one a boss stage. So as an alternative of drowning in 10 random programs, right here’s the one roadmap constructed for 2026 and past: step-by-step, skill-by-skill, project-by-project. No fluff or filler. This Generative AI Scientist Roadmap 2026 is the precise improve path to go from being a consumer to a builder to an architect to a frontrunner.
Part 1: The Information Basis (Weeks 1-6)
Aim: Converse the language of knowledge. You can not construct AI should you can’t manipulate the information it feeds on.
Python (The AI Dialect):
- Fundamentals: Variables, capabilities, loops.
- Information Science Stack: NumPy (math), Pandas (knowledge manipulation).
Knowledgeable Addition: Be taught AsyncIO. Fashionable GenAI is asynchronous (streaming tokens). When you don’t know async/await, your apps will likely be gradual.
Checkout: A Full Python Tutorial to Be taught Information Science from Scratch
SQL (The Information Fetcher):
- Grasp the basics: Be taught SELECT, WHERE, ORDER BY, and LIMIT to fetch and filter knowledge effectively.
- Work with tables: Use JOIN to mix datasets and carry out fundamentals like INSERT, UPDATE, and DELETE.
- Summarize and rework: Apply GROUP BY, aggregates, CASE WHEN, and easy string/date capabilities.
- Write cleaner queries: Keep away from SELECT *, use correct filters, and know primary indexing ideas.
Knowledgeable Addition: Be taught pgvector. Commonplace SQL is for textual content; pgvector (PostgreSQL) is for vector similarity search, which is the spine of RAG.
Get began right here: SQL: A Full Fledged Information from Fundamentals to Advance Degree
Information Preprocessing:
- Convert uncooked knowledge right into a usable format for mannequin coaching.
- Key Steps Embody:
- Cleansing: Dealing with lacking values, noise, and textual content hygiene.
- Transformation: Scaling, encoding categorical knowledge, and normalization.
- Engineering: Creating new, significant options from present ones.
- Discount: Lowering complexity by way of dimensionality strategies.
- Function: Ensures high-quality enter for dependable mannequin efficiency.
Full information: Sensible Information on Information Preprocessing in Python utilizing Scikit Be taught
Part 2: The Mind – ML, DL, & Transformers (Weeks 7-14)
Aim: Perceive how the magic works so you may debug it when it breaks.
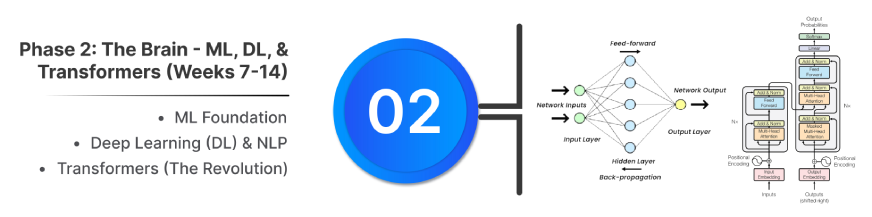
ML Basis:
Additionally Learn: Newbie’s Information to Machine Studying Ideas and Strategies
Deep Studying (DL) & NLP:
- ANN (Foundational Mannequin): Community of linked neurons utilizing weights and activation capabilities (ReLU, Softmax, and so forth.).
- Sequential Networks (Reminiscence):
- Conventional Textual content Illustration:
- Bag-of-Phrases (BoW): Counts phrase frequency, ignoring order/grammar.
- TF-IDF: Weights phrase significance by doc frequency vs. corpus rarity.
- Embeddings: Dense vectors that seize semantic that means and relationships (e.g., $King – Man + Girl approx Queen$).
Checkout: Free course on NLP and DL foundation
Transformers (The Revolution):
- Basis: Based mostly on the 2017 paper “Consideration Is All You Want.” It’s the core of recent LLMs (GPT, Llama).
- Core Innovation: Self-Consideration Mechanism. This permits the mannequin to course of all tokens in parallel, assigning a weighted significance to each phrase to seize long-range dependencies and context decision effectively.
- Construction: Makes use of Multi-Head Consideration and Feed-Ahead Networks inside an Encoder-Decoder or Decoder-only stack.
- Key Enabler: Positional Encoding ensures the mannequin retains phrase order data regardless of parallel processing.
- Revolutionary: Allows quicker coaching and higher dealing with of lengthy textual content sequences than earlier architectures (RNNs).
Knowledgeable Addition: Perceive “Context Window” limits and “KV Cache” (how LLMs keep in mind earlier tokens effectively).
Additionally Learn: Information to Transformers
Part 3: The Operator – LLMs & Prompting (Weeks 15-18)
Aim: Grasp the present state-of-the-art fashions on this step of the Generative AI Scientist Roadmap 2026.

LLM Literacy
Knowledgeable Addition: Find out about Inference Suppliers like Groq (tremendous quick) and OpenRouter (entry to all fashions by way of one API).
Immediate Engineering:
- Zero-Shot: Request the duty immediately from the mannequin with none previous examples (preferrred for easy, well-known duties).
- Few-Shot: Improve accuracy and formatting by offering the mannequin with 2-5 input-output examples inside the immediate.
- Chain-of-Thought (CoT): Instruct the mannequin to “suppose step-by-step” earlier than answering, considerably bettering accuracy in complicated reasoning duties.
- Tree-of-Thought (ToT): A classy technique the place the mannequin explores and evaluates a number of doable reasoning paths concurrently earlier than deciding on the optimum resolution (finest for strategic or inventive planning).
- Self-Correction: Drive the mannequin to evaluate and revise its personal output towards specified constraints or necessities to make sure larger reliability and adherence to guidelines.
Knowledgeable Addition: System Prompting- Use a high-priority, invisible instruction set to outline the mannequin’s persona, persistent guidelines, and security boundaries, which is essential for constant tone and stopping undesirable habits.
Additionally Learn: Information to Immediate Engineering
Part 4: The Builder – RAG & Graph RAG (Weeks 19-24)
Aim: Cease hallucinations. Make the AI “know” your non-public knowledge.

RAG (Retrieval Augmented Technology)
RAG is a core approach for grounding LLMs in exterior, up-to-date, or non-public knowledge, drastically lowering hallucinations. It includes retrieving related paperwork or chunks from a information supply and feeding them into the LLM’s context window together with the consumer’s question.
To make this whole course of work end-to-end, a set of supporting elements ties the RAG pipeline collectively.
- Orchestration Framework (LangChain & LlamaIndex): These frameworks are used to connect collectively your complete RAG pipeline. They deal with the total knowledge lifecycle – from loading paperwork and splitting textual content to querying the Vector Database and feeding the ultimate context to the LLM. LangChain is understood for its big selection of basic instruments and chains, whereas LlamaIndex makes a speciality of knowledge ingestion and indexing methods, making it extremely optimized for complicated RAG workflows.
- Vector Databases: Specialised databases like ChromaDB (native), Pinecone (scalable cloud resolution), Milvus (high-scale open-source), Weaviate (hybrid search), or Qdrant (high-performance) retailer your paperwork as numerical representations known as embeddings.
- Retrieval Mechanism: The first technique is Cosine Similarity search, which measures the “closeness” between the question’s embedding and the doc embeddings.
- Knowledgeable Addition: Hybrid Search: For finest outcomes, depend on Hybrid Search. This combines Vector Search(semantic that means) with Key phrase Search (BM25) (time period frequency/precise matches) to make sure each conceptual relevance and needed key phrases are retrieved.
Graph RAG
Graph RAG (The 2026 Commonplace): As knowledge complexity grows, RAG evolves into methods that perceive relationships, not simply similarity. Agentic RAG and Graph RAG are essential for complicated, multi-hop reasoning.
- Graph RAG (The 2026 Commonplace): This method strikes past vectors to seek out linked issues slightly than simply related issues.
- Idea: It extracts entities (e.g., individuals, locations) and relationships (e.g., WORKS_FOR, LOCATED_IN) to construct a Data Graph.
- Software: Graph databases like Neo4j are used to retailer and question these relationships, permitting the LLM to reply complicated, relational questions like, “How are these two corporations linked?”
Additionally Learn: Easy methods to Turn into a RAG Specialist in 2026?
Part 5: The Commander – Brokers & Agentic RAG (Weeks 25-32)
Aim: Transfer from “Chatbots” (passive) to “Brokers” (energetic doers).
Agent Varieties (The Theoretical Basis):
These classifications symbolize how clever an agent will be and the way complicated its decision-making turns into. Whereas Easy Reflex, Mannequin-Based mostly Reflex, Aim-Based mostly, and Utility-Based mostly Brokers kind the foundational classes, the next sorts are actually changing into more and more in style:
- Studying Brokers: Improves its efficiency over time by studying from expertise and suggestions, adapting its habits and information.
- Hierarchical Brokers: Organized in a multi-level construction the place higher-level brokers delegate duties and information lower-level brokers, enabling environment friendly problem-solving.
- Multi-Agent Techniques: A computational framework composed of a number of interacting autonomous brokers (like CrewAI or AutoGen) that collaborate or compete to resolve complicated duties.
Additionally Learn: Information to Varieties of AI Brokers
Brokers Frameworks
- LangGraph (The State Machine):
- Focus: Necessary for 2026. Allows complicated loops, cycles, and conditional branching with express state administration.
- Finest Use: Manufacturing-grade brokers requiring reflection, retries, and deterministic management move (e.g., superior RAG, dynamic planning).
- Permits an agent to verify its work and determine to repeat or department to a brand new step.
- CrewAI (The Workforce Supervisor):
- Focus: Excessive-level abstraction for constructing intuitive multi-agent methods primarily based on outlined roles, objectives, and backstories.
- Finest Use: Initiatives that naturally map to a human workforce construction (e.g., Researcher to Author to Critic).
- Wonderful for fast, collaborative, and role-based agent design.
- AutoGen (The Dialog Designer):
- Focus: Constructing dynamic, conversational multi-agent methods the place brokers talk by way of versatile messages.
- Finest Use: Collaborative coding, debugging, and iterative analysis workflows that require self-evolving dialogue or human-in-the-loop oversight.
- Preferrred for peer-review type duties the place the workflow adapts primarily based on the brokers’ interplay.
Additionally Learn: High 7 Frameworks for Constructing AI Agent
Agentic Design Patterns
These are the established finest practices for constructing sturdy, clever brokers:
- ReAct Sample (Reasoning + Motion): The elemental sample the place the agent interleaves Thought (Reasoning), Motion (Software Name), and Remark (Software End result).
- Multi-Agent Sample: Designing a system the place specialised brokers cooperate to resolve a fancy drawback utilizing distinct roles and communication protocols.
- Software Calling / Perform Calling: The agent’s capacity to determine when and the best way to name exterior capabilities (like a calculator or API).
- Reflection / Self-Correction: The agent generates an output, then makes use of a separate inside immediate to critically consider its personal outcome earlier than presenting the ultimate reply.
- Planning / Decomposition: The agent first breaks the high-level aim into smaller, manageable sub-tasks earlier than executing any actions.
Checkout: High Agentic AI Design Patterns for Architecting AI Techniques
Agentic RAG:
- Definition: RAG enhanced by an autonomous AI agent that plans, acts, and displays on the consumer question.
- Workflow: The agent decomposes the query into sub-tasks, selects one of the best device (Vector Search, Internet API) for every half, and iteratively refines the outcomes.
- Influence: Solves complicated queries by being dynamic and proactive, shifting past passive, linear retrieval.
Part 6: The Tuner – Effective-tuning (Weeks 33-38)
Aim: When prompting isn’t sufficient, change the mannequin’s mind.
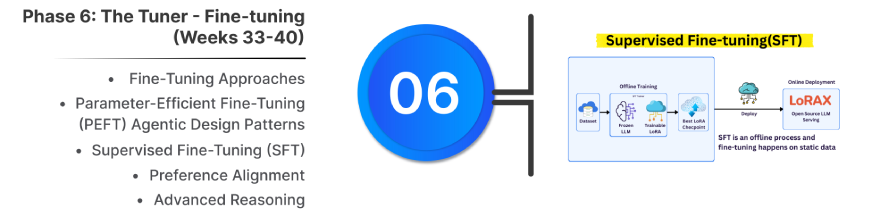
Effective-tuning adapts a pre-trained mannequin to a selected area, persona, or process by coaching it on a curated dataset.
1. Effective-Tuning Approaches
- LLMs (70B+): Used to inject proprietary information or enhance complicated reasoning; requires sturdy compute.
- SLMs (1–8B): Tuned for specialised, production-ready duties the place small fashions can outperform giant ones on slender use instances.
2. Parameter-Environment friendly Effective-Tuning (PEFT)
- PEFT: Trains small adapter layers as an alternative of the entire mannequin.
- LoRA: Business normal; makes use of low-rank matrices to chop compute and reminiscence.
- QLoRA: Additional reduces reminiscence by 4-bit quantization of frozen weights.
3. Supervised Effective-Tuning (SFT)
- Teaches new behaviors utilizing (immediate, preferrred response) pairs. Excessive-quality, clear knowledge is important.
4. Desire Alignment
Refines mannequin habits after SFT utilizing human suggestions.
- DPO: Optimizes immediately on most well-liked vs. rejected responses; easy and secure.
- ORPO: Combines SFT + desire loss for higher outcomes.
- RLHF + PPO: Conventional RL-based method utilizing reward fashions.
5. Superior Reasoning
GRPO: Improves multi-step reasoning and logical consistency.
Part 7: The Engineer – LLMOps and AgentOps (Weeks 39-42)
Aim: Transfer from “It really works on my laptop computer” to “It really works for 10,000 customers.” Transition from writing scripts to constructing sturdy, scalable methods.

Deployment & Environment friendly Serving
- The API Layer: Don’t simply run a Python script. Wrap your agent logic in a high-performance, asynchronous net framework utilizing FastAPI. This permits your agent to deal with concurrent requests and combine simply with frontends.
- Inference Engines: Commonplace Hugging Face pipelines will be gradual. For manufacturing, swap to optimized inference servers:
- vLLM: Use this for high-throughput manufacturing environments. It makes use of PagedAttention to drastically improve pace and handle reminiscence effectively.
- llama.cpp: Use this for working quantized fashions (GGUF) on shopper {hardware} or edge gadgets with restricted VRAM.
Observability (The “Black Field” Drawback)
- You can not debug an Agent with print() statements. You want to visualize your complete chain of thought.
- Instruments: Combine LangSmith, LangFuse, or Arize Phoenix.
- What to trace: View the “hint” of each resolution, examine intermediate inputs/outputs, establish the place the agent entered a loop, and debug latency spikes.
Analysis (LLM-as-a-Decide)
- Cease counting on “vibe checks” or eyeballing the output. Deal with your prompts like code.
- Frameworks: Use RAGAS or DeepEval to construct a testing pipeline.
- Metrics: Routinely rating your software on “Faithfulness” (did it make issues up?), “Context Recall” (did it discover the best doc?), and “Reply Relevance.”
Value & Governance
- Token Administration: Observe utilization per consumer and per session to calculate unit economics.
- Guardrails: Implement primary security checks to stop the agent from going off-topic or producing dangerous content material earlier than the associated fee is incurred.
The “Quick Observe” Milestone Initiatives
To remain motivated, construct these 4 tasks as you progress:
- Mission Alpha (After Part 3): A Python script that summarizes YouTube movies utilizing the Gemini API.
- Mission Beta (After Part 4): A “Chat together with your Finance PDF” device utilizing RAG and ChromaDB.
- Mission Gamma (After Part 5): An Autonomous Researcher Agent utilizing LangGraph that browses the net and writes a weblog submit.
- Capstone (After Part 7): A specialised Medical/Authorized Assistant powered by Graph RAG, fine-tuned on area knowledge, with full LangSmith monitoring.
Conclusion
When you observe this roadmap with even 70% seriousness, you received’t simply “be taught AI,” you’ll outgrow 90% of the {industry} sleepwalking via outdated tutorials. The Generative AI Scientist Roadmap 2026 is designed to show you into the sort of builder corporations combat to rent, founders wish to associate with, and buyers quietly scout for.
As a result of the longer term isn’t going to be written by individuals who merely use AI. It will likely be constructed by those that perceive knowledge, command fashions, architect brokers, fine-tune brains, and ship methods that truly scale. With the Generative AI Scientist Roadmap 2026, you now have the blueprint. The one factor left is the half no roadmap can train, displaying up each single day and levelling up such as you imply it.
Information Analyst with over 2 years of expertise in leveraging knowledge insights to drive knowledgeable choices. Captivated with fixing complicated issues and exploring new tendencies in analytics. When not diving deep into knowledge, I get pleasure from taking part in chess, singing, and writing shayari.
Login to proceed studying and revel in expert-curated content material.