

{kind=link}
Like lots of you, I’m working from house and checking the most recent information on COVID-19 often. I see a variety of numbers and graphs, so I appeared round for the “official information”. Probably the greatest information sources I’ve discovered is on the GitHub web site for Johns Hopkins Whiting College of Engineering Middle for Techniques Science and Engineering. The info for every day are saved in a separate file, so I wrote just a little Stata command referred to as covid19 to obtain, mix, save, and graph these information.
The command creates a desk that incorporates the date, the variety of confirmed instances, the variety of deaths, and the quantity recovered. I added a calculated variable named newcases, which is the distinction between confirmed instances for 2 contiguous days.
The unique information embody all reporting nations, so I added a nation() choice that permits me to view the desk for a selected nation.
. covid19, nation("US") graph saving(covid19_usa)
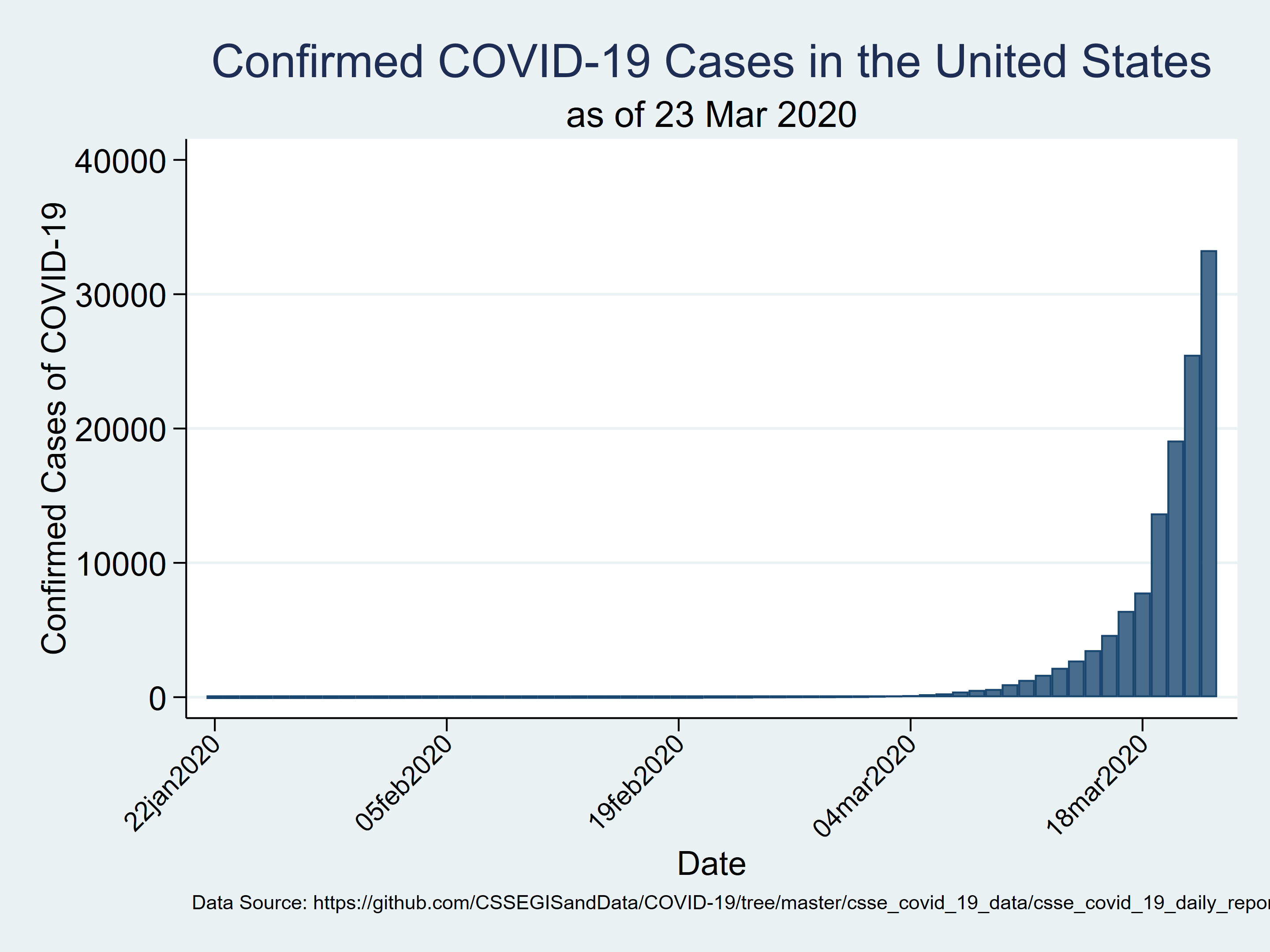
COVID-19 information for US as of 19 Mar 2020
+--------------------------------------------------------+
| date confirmed newcases deaths recovered |
|--------------------------------------------------------|
| 01/22/2020 1 1 0 0 |
| 01/23/2020 1 0 0 0 |
| 01/24/2020 2 1 0 0 |
| 01/25/2020 2 0 0 0 |
(Output omitted)
| 03/14/2020 2726 547 54 12 |
| 03/15/2020 3499 773 63 12 |
| 03/16/2020 4632 1133 85 17 |
| 03/17/2020 6421 1789 108 17 |
| 03/18/2020 7786 1365 118 106 |
+--------------------------------------------------------+
I additionally added a graph choice that plots the variety of confirmed instances.
Determine 1: Confirmed instances of COVID-19 in the USA
{kind=link}
The saving() choice saves the information to a file named covid19_usa.dta.
. use covid19_usa, clear
. listing in -10/l
+------------------------------------------------------+
| date confir~d newcases deaths recove~d |
|------------------------------------------------------|
48. | 03/09/2020 605 68 22 8 |
49. | 03/10/2020 959 354 28 8 |
50. | 03/11/2020 1281 322 36 8 |
51. | 03/12/2020 1663 382 40 12 |
52. | 03/13/2020 2179 516 47 12 |
|------------------------------------------------------|
53. | 03/14/2020 2726 547 54 12 |
54. | 03/15/2020 3499 773 63 12 |
55. | 03/16/2020 4632 1133 85 17 |
56. | 03/17/2020 6421 1789 108 17 |
57. | 03/18/2020 7786 1365 118 106 |
+------------------------------------------------------+
I like my covid19 command, however I’ve no plans to distribute it. I haven’t examined it totally, and it may very well be rendered ineffective if or when Johns Hopkins modifications its information. So I’m going to indicate you the steps to obtain and course of the information so you are able to do this your self. If the information change, you’ll have the instruments to switch your code and obtain future information.
Johns Hopkins College GitHub information
GitHub is a well-liked web site/platform for software program improvement and distribution. The Johns Hopkins Whiting College of Engineering Middle for Techniques Science and Engineering has a GitHub repository that features usually up to date COVID-19 information from all over the world. The uncooked information can be found right here: Johns Hopkins GitHub information.
Determine 2: Johns Hopkins GitHub information for COVID-19
The info are saved in separate .csv information for every day. Let’s click on on the file named 01-29-2020.csv to view its contents. This file incorporates information for the Province/State, the Nation/Area, the date and time of the Final Replace, the variety of Confirmed instances, the variety of Deaths, and the quantity Recovered.
Determine 3: Contents of 01-29-2020.csv
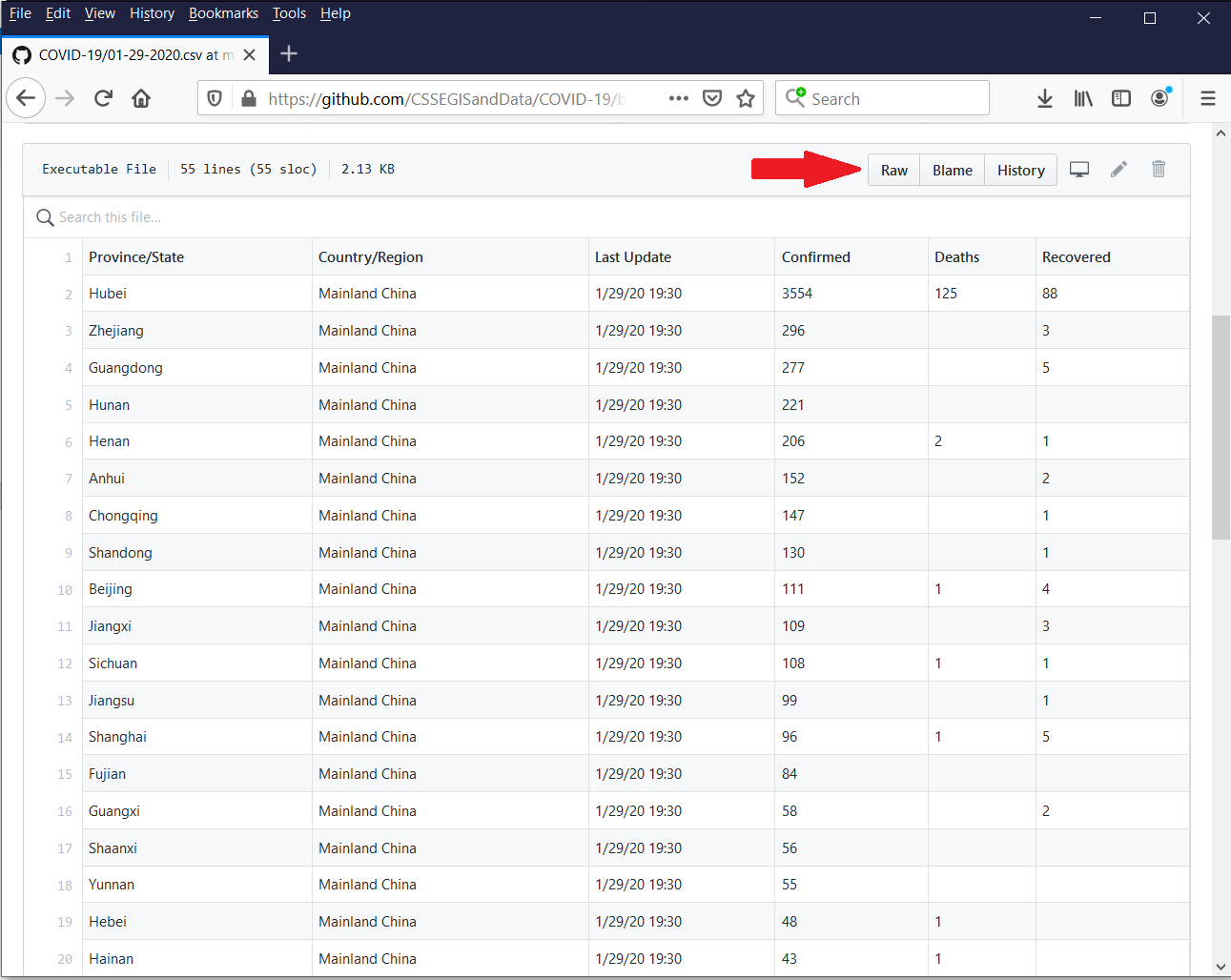
You’ll be able to view the uncooked, comma-delimited information by clicking on the “Uncooked” button subsequent to the pink arrow. Word that I added the pink arrow; it doesn’t seem on the web site.
Determine 4: Uncooked comma-delimited information in 01-29-2020.csv
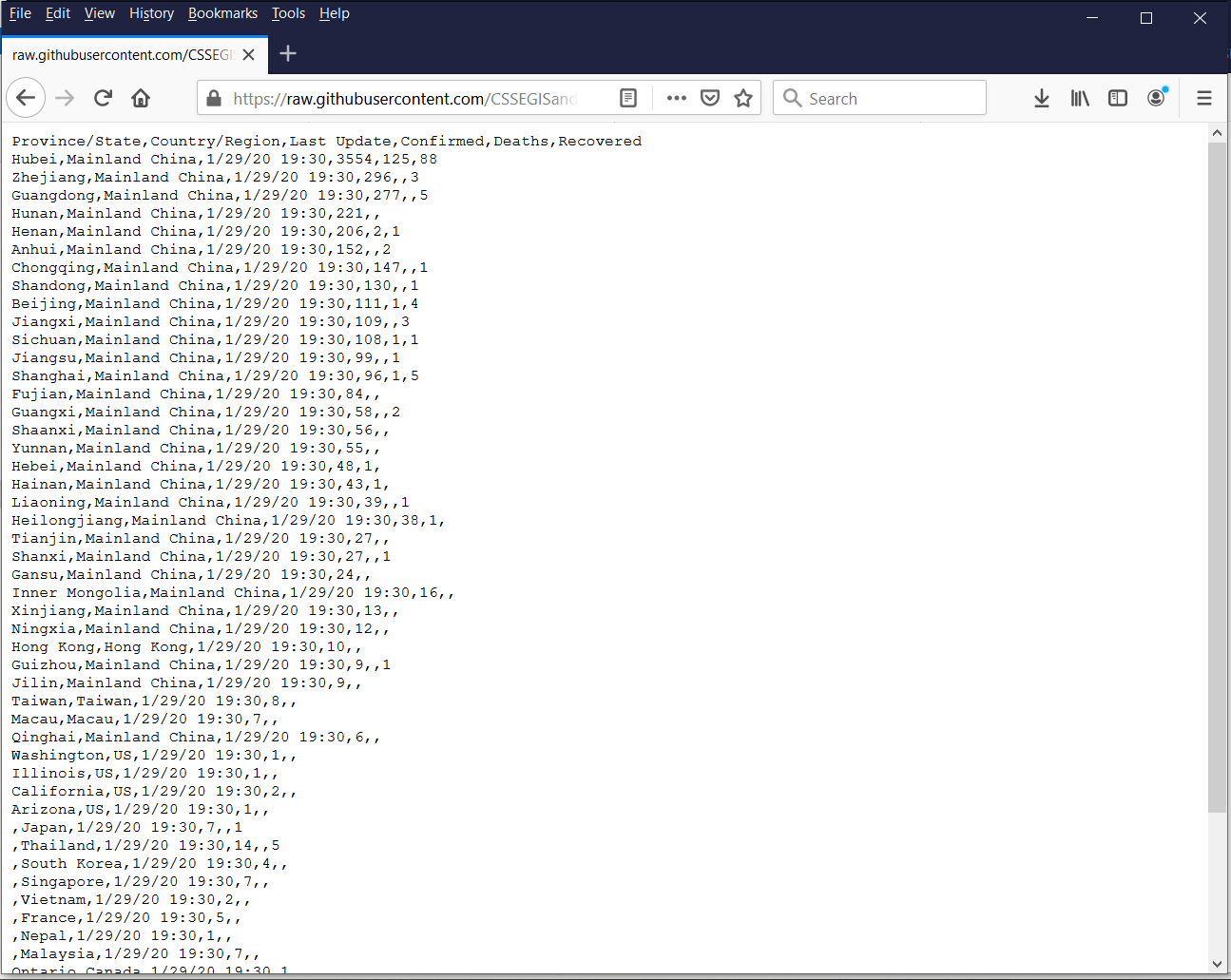
You’ll be able to import these uncooked information from the web site into Stata utilizing import delimited. The filename is the URL within the deal with bar of your internet browser.
import delimited "https://uncooked.githubusercontent.com/CSSEGISandData/COVID-19/grasp/csse_covid_19_data/csse_covid_19_daily_reports/01-29-2020.csv"
Your internet browser will seemingly wrap the URL to a second line. Word that it is a one-line command in Stata. I can then describe and listing the information in Stata.
. describe
Incorporates information
obs: 54
vars: 6
------------------------------------------------------------------------
storage show worth
variable title sort format label variable label
------------------------------------------------------------------------
ïprovincestate str16 %16s Province/State
countryregion str20 %20s Nation/Area
lastupdate str13 %13s Final Replace
confirmed int %8.0g Confirmed
deaths int %8.0g Deaths
recovered byte %8.0g Recovered
------------------------------------------------------------------------
Sorted by:
Word: Dataset has modified since final saved.
. listing in 1/5
+---------------------------------------------------------------------------+
| ïprovin~e countryregion lastupdate confir~d deaths recove~d |
|---------------------------------------------------------------------------|
1. | Hubei Mainland China 1/29/20 19:30 3554 125 88 |
2. | Zhejiang Mainland China 1/29/20 19:30 296 . 3 |
3. | Guangdong Mainland China 1/29/20 19:30 277 . 5 |
4. | Hunan Mainland China 1/29/20 19:30 221 . . |
5. | Henan Mainland China 1/29/20 19:30 206 2 1 |
+---------------------------------------------------------------------------+
We did it! We efficiently imported the uncooked information for January 29, 2020, from the Johns Hopkins GitHub repository into Stata! It’s just one file, and there may be no less than one apparent subject with the information (the variable named ïprovincestate), nevertheless it’s a very good place to begin.
Utilizing verify and if to repair variable names
I realized by way of trial and error that the variable provincestate is imported as ïprovincestate in some information and provincestate in others. We need to import many information, and we don’t need to should look by way of every file manually. So let’s use verify to verify every file for a variable named ïprovincestate.
. verify variable ïprovincestate . show _rc 0
If the variable ïprovincestate exists, the command will retailer a worth of zero to _rc. We will use this end in an if assertion that can rename and appropriately label the variable.
if _rc == 0 {
rename ïprovincestate provincestate
label variable provincestate "Province/State"
}
This dataset incorporates the variable ïprovincestate, so the instructions contained in the if block are executed. We will verify this utilizing describe.
. describe provincestate
storage show worth
variable title sort format label variable label
------------------------------------------------------------------------
provincestate str16 %16s Province/State
Our dataset now incorporates a variable named provincestate. Let’s sort verify variable once more to see what occurs if the variable ïprovincestate shouldn’t be in our dataset.
. verify variable ïprovincestate
variable ïprovincestate not discovered
r(111);
This dataset doesn’t comprise a variable named ïprovincestate, so verify variable returns an error message. If we execute verify variable inside a do-file, the do-file will cease working. We will use seize to permit our do-file to proceed working even when verify variable returns an error.
. seize verify variable ïprovincestate . show _rc 111
Word that _rc equals 111, which isn’t equal to 0. So the code under will import the uncooked information and “repair” ïprovincestate if obligatory.
import delimited "https://uncooked.githubusercontent.com/CSSEGISandData/COVID-19/grasp/csse_covid_19_data/csse_covid_19_daily_reports/01-29-2020.csv"
if _rc == 0 {
rename ïprovincestate provincestate
label variable provincestate "Province/State"
}
Utilizing macros to import completely different information
Subsequent let’s see how macros might help us import completely different information from the web site. We will retailer phrases or numbers quickly in reminiscence utilizing macros. Macros might be native or world. International macros, as soon as outlined, are obtainable anyplace in Stata. Native macros exist solely throughout the program or do-file wherein they’re outlined. You’ll be able to outline an area macro like this:
. native right now = "3-19-2020"
You’ll be able to consult with the macro by typing a left single quote (to the left of the “one key”) on the left aspect of the macro title and a proper single quote (to the left of the “Enter” key) on the fitting aspect of the macro title.
. show "`right now'" 3-19-2020
We will create macros by combining different macros like this:
. native month = "3" . native day = "19" . native yr = "2020" . native right now = "`month'-`day'-`yr'" . show "`right now'" 3-19-2020
We want to import information with names like 01-29-2020.csv. Word that the month features a “main zero”. Months 1–9 are specified as “01”, “02”, and so forth. Months 10–12 are specified as “10”, “11”, and “12”. We want a approach to assign values to native macros that features a main zero when applicable. The string() perform is a technique to do that.
. native month = string(3, "%02.0f") . native day = string(19, "%02.0f") . native yr = "2020" . native right now = "`month'-`day'-`yr'" . show "`right now'" 03-19-2020
The string() perform for the macro month saved the quantity 3 to a two-character string with a number one zero. The string() perform for the macro day saved the quantity 19 to a two-character string with a number one zero, however the main zero shouldn’t be obligatory. This may permit us to specify arbitrary dates with the right format for the information we want to import.
Subsequent, let’s contemplate the whole filename. Many of the prolonged filename is identical for each file. Let’s retailer the URL for the filenames to an area macro.
. native URL = "https://uncooked.githubusercontent.com/CSSEGISandData/ > COVID-19/grasp/csse_covid_19_data/csse_covid_19_daily_reports/" . show "`URL'" https://uncooked.githubusercontent.com/CSSEGISandData/COVID-19/grasp/ > csse_covid_19_data/csse_covid_19_daily_reports/
This permits us to specify a filename like this:
. native FileName = "`URL'`right now'.csv" . import delimited "`FileName'" (8 vars, 284 obs)
Utilizing loops to import a number of information
We will repeat a command or assortment of instructions by inserting them in a loop. A method to do that is with forvalues.
forvalues month = 1/12 {
show "month = `month'"
}
Word that month is saved as an area macro, and we will consult with it as `month’ contained in the loop. So the outcomes of our loop appear like this:
. forvalues month = 1/12 {
2. show "month = `month'"
3. }
month = 1
month = 2
month = 3
month = 4
month = 5
month = 6
month = 7
month = 8
month = 9
month = 10
month = 11
month = 12
We will additionally create a loop inside a loop. For instance, we may loop over days inside months like this:
forvalues month = 1/12 {
forvalues day = 1/31 {
show "month = `month', day = `day'"
}
}
The outcomes of this loop are fairly prolonged, so I’ve omitted a lot of the output.
. forvalues month = 1/12 {
2. forvalues day = 1/31 {
3. show "month = `month', day = `day'"
4. }
5. }
month = 1, day = 1
month = 1, day = 2
month = 1, day = 3
month = 1, day = 4
(Output omitted)
month = 12, day = 28
month = 12, day = 29
month = 12, day = 30
month = 12, day = 31
Let’s use our loop to create names for the information we want to obtain.
forvalues month = 1/12 {
forvalues day = 1/31 {
native month = string(`month', "%02.0f")
native day = string(`day', "%02.0f")
native yr = "2020"
native right now = "`month'-`day'-`yr'"
show "`right now'"
}
}
This loop additionally returns a variety of output, so I’ve omitted most of it for brevity. Word that the string() perform provides main zeros for month and day the place obligatory.
. forvalues month = 1/12 {
2. forvalues day = 1/31 {
3. native month = string(`month', "%02.0f")
4. native day = string(`day', "%02.0f")
5. native yr = "2020"
6. native right now = "`month'-`day'-`yr'"
7. show "`right now'"
8. }
9. }
01-01-2020
01-02-2020
01-03-2020
01-04-2020
(Output omitted)
12-28-2020
12-29-2020
12-30-2020
12-31-2020
We will use the macro URL together with import delimited to import the uncooked information for day-after-day in 2020. We might want to clear Stata’s reminiscence earlier than we import every uncooked information file. Then, we will save a replica of every file as a Stata dataset.
native URL = "https://uncooked.githubusercontent.com/CSSEGISandData/COVID-19/grasp/csse_covid_19_data/csse_covid_19_daily_reports/"
forvalues month = 1/12 {
forvalues day = 1/31 {
native month = string(`month', "%02.0f")
native day = string(`day', "%02.0f")
native yr = "2020"
native right now = "`month'-`day'-`yr'"
native FileName = "`URL'`right now'.csv"
clear
import delimited "`FileName'"
save "`right now'"
}
}
I’m positive you might have already anticipated the flaw with the code above. It loops over day-after-day of each month of 2020. However the information information start on January 21, 2020, so there isn’t a information file for January 1. Our program returns an error message.
. native URL = "https://uncooked.githubusercontent.com/CSSEGISandData/
> COVID-19/grasp/csse_covid_19_data/csse_covid_19_daily_reports/"
. forvalues month = 1/12 {
2. forvalues day = 1/31 {
3. native month = string(`month', "%02.0f")
4. native day = string(`day', "%02.0f")
5. native yr = "2020"
6. native right now = "`month'-`day'-`yr'"
7. native FileName = "`URL'`right now'.csv"
8. clear
9. import delimited "`FileName'"
10. save "`right now'"
11. }
12. }
file
https://uncooked.githubusercontent.com/CSSEGISandData/COVID-19/grasp/
> csse_covid_19_data/csse_covid_19_daily_reports/01-01-2020.csv not discovered
couldn't open url
r(603);
New information may even be added day-after-day, and I want to import future information as soon as they’re posted. There are numerous intelligent methods to deal with this example. A method is to easily precede import delimited and save with seize. Information information shall be imported in the event that they exist. If the information file doesn’t exist, this system will proceed. It’s a gradual and crude methodology, however it’ll work for our functions.
native URL = "https://uncooked.githubusercontent.com/CSSEGISandData/COVID-19/grasp/csse_covid_19_data/csse_covid_19_daily_reports/"
forvalues month = 1/12 {
forvalues day = 1/31 {
native month = string(`month', "%02.0f")
native day = string(`day', "%02.0f")
native yr = "2020"
native right now = "`month'-`day'-`yr'"
native FileName = "`URL'`right now'.csv"
clear
seize import delimited "`FileName'"
seize save "`right now'"
}
}
Our seize trick labored, and I can view a listing of the Stata information information in my native listing.
. ls3/19/20 16:23 . 3/19/20 16:23 .. 6.0k 3/19/20 16:23 01-22-2020.dta 6.3k 3/19/20 16:23 01-23-2020.dta 6.1k 3/19/20 16:23 01-24-2020.dta 6.2k 3/19/20 16:23 01-25-2020.dta (Output omitted) 30.0k 3/19/20 16:23 03-15-2020.dta 31.3k 3/19/20 16:23 03-16-2020.dta 31.7k 3/19/20 16:23 03-17-2020.dta 32.4k 3/19/20 16:23 03-18-2020.dta
Let’s open the file 01-22-2020.dta and describe the information.
. describe utilizing 01-22-2020.dta
Incorporates information
obs: 38 19 Mar 2020 16:45
vars: 6
------------------------------------------------------------------------
storage show worth
variable title sort format label variable label
------------------------------------------------------------------------
ïprovincestate str14 %14s Province/State
countryregion str14 %14s Nation/Area
lastupdate str15 %15s Final Replace
confirmed int %8.0g Confirmed
deaths byte %8.0g Deaths
recovered byte %8.0g Recovered
------------------------------------------------------------------------
Sorted by:
That is a kind of information that comprise the variable ïprovincestate. We realized learn how to repair this earlier utilizing verify and if, so let’s put our “repair” in our code and rerun it. Word that I’ve added the choice , exchange to the save instructions as a result of the information exist already in our listing.
native URL = "https://uncooked.githubusercontent.com/CSSEGISandData/COVID-19/grasp/csse_covid_19_data/csse_covid_19_daily_reports/"
forvalues month = 1/12 {
forvalues day = 1/31 {
native month = string(`month', "%02.0f")
native day = string(`day', "%02.0f")
native yr = "2020"
native right now = "`month'-`day'-`yr'"
native FileName = "`URL'`right now'.csv"
clear
seize import delimited "`FileName'"
seize verify variable ïprovincestate
if _rc == 0 {
rename ïprovincestate provincestate
label variable provincestate "Province/State"
}
seize save "`right now'", exchange
}
}
Now we will describe the dataset 01-22-2020.dta and confirm that the variable ïprovincestate has been modified to provincestate.
. describe utilizing 01-22-2020.dta
Incorporates information
obs: 38 19 Mar 2020 16:35
vars: 6
------------------------------------------------------------------------
storage show worth
variable title sort format label variable label
------------------------------------------------------------------------
provincestate str14 %14s Province/State
countryregion str14 %14s Nation/Area
lastupdate str15 %15s Final Replace
confirmed int %8.0g Confirmed
deaths byte %8.0g Deaths
recovered byte %8.0g Recovered
------------------------------------------------------------------------
Sorted by:
Our native listing now incorporates a set of Stata information information that we want to mix right into a single file. We will do that utilizing append. We may append two information information manually like this:
. clear . append utilizing 01-22-2020.dta . append utilizing 01-23-2020.dta
However that might be tedious, and we must frequently replace our code. One other loop would permit us to automate this course of. Word that I’ve used the seize trick earlier than append as a result of we don’t have a file for day-after-day of 2020.
clear
forvalues month = 1/12 {
forvalues day = 1/31 {
native month = string(`month', "%02.0f")
native day = string(`day', "%02.0f")
native yr = "2020"
native right now = "`month'-`day'-`yr'"
seize append utilizing "`right now'"
}
}
I’ve described our information under and see that there are two new variables. Among the uncooked information information comprise the variables latitude and longitude, and so they have been appended to our full dataset.
. describe
Incorporates information
obs: 6,722
vars: 8
------------------------------------------------------------------------
storage show worth
variable title sort format label variable label
------------------------------------------------------------------------
provincestate str43 %43s Province/State
countryregion str32 %32s Nation/Area
lastupdate str19 %19s Final Replace
confirmed lengthy %8.0g Confirmed
deaths int %8.0g Deaths
recovered lengthy %8.0g Recovered
latitude float %9.0g Latitude
longitude float %9.0g Longitude
------------------------------------------------------------------------
Sorted by:
Word: Dataset has modified since final saved.
A listing of the final 10 observations confirms that the dataset consists of some information for latitude and longitude.
. listing countryregion latitude longitude in -10/l
+---------------------------------------------+
| countryregion latitude longit~e |
|---------------------------------------------|
7917. | France -12.8431 45.1383 |
7918. | France -21.1351 55.2471 |
7919. | Greenland 72 -40 |
7920. | Guam 13.4443 144.7937 |
7921. | Guernsey 49.45 -2.58 |
|---------------------------------------------|
7922. | Jersey 49.19 -2.11 |
7923. | Puerto Rico 18.2 -66.5 |
7924. | Republic of the Congo -1.44 15.556 |
7925. | The Bahamas 24.25 -76 |
7926. | The Gambia 13.4667 -16.6 |
+---------------------------------------------+
Conclusion and objectives for subsequent time
Let’s cease right here and take into consideration what we’ve achieved. We now have efficiently downloaded all of the uncooked information obtainable for COVID-19 from the Johns Hopkins GitHub repository and mixed them right into a single dataset utilizing the next code:
native URL = "https://uncooked.githubusercontent.com/CSSEGISandData/COVID-19/grasp/csse_covid_19_data/csse_covid_19_daily_reports/"
forvalues month = 1/12 {
forvalues day = 1/31 {
native month = string(`month', "%02.0f")
native day = string(`day', "%02.0f")
native yr = "2020"
native right now = "`month'-`day'-`yr'"
native FileName = "`URL'`right now'.csv"
clear
seize import delimited "`FileName'"
seize verify variable ïprovincestate
if _rc == 0 {
rename ïprovincestate provincestate
label variable provincestate "Province/State"
}
seize save "`right now'", exchange
}
}
clear
forvalues month = 1/12 {
forvalues day = 1/31 {
native month = string(`month', "%02.0f")
native day = string(`day', "%02.0f")
native yr = "2020"
native right now = "`month'-`day'-`yr'"
seize append utilizing "`right now'"
}
}
A lot of you’ll discover that we may accomplish this job with a single loop (trace: use frames!). However I wished to maintain issues so simple as potential on this put up. Let’s save this dataset so we will use it later.
. save covid19_raw file covid19_raw.dta saved
There are numerous issues we may do with this uncooked dataset. We may create time-series information to look at patterns over time. We may do that by nation and even provinces or states inside nations. And we’ve details about latitude and longitude for a few of the information, so we may discover patterns by time and placement. I’ll talk about these in future posts.
Please be aware that we’ve not checked and cleaned these information. The code above and the ensuing information needs to be used for educational functions solely.