

{kind=link}
Everybody talks about huge AI fashions like ChatGPT, Gemini, and Grok. What many individuals don’t understand is that the majority of those fashions use the identical core structure known as the Transformer. Not too long ago, one other time period has began trending within the generative AI area known as Combination of Consultants or MoE. This has created quite a lot of confusion round transformer vs MoE. Some folks suppose MoE is a very new structure. Others imagine it’s only a bigger Transformer. This makes it onerous to grasp what is definitely occurring behind the scenes.
Is MoE a substitute for Transformers, or is it merely a better option to scale them? Are the 2 actually totally different? These questions come up usually when folks hear about Transformers and MoE.
On this article, I’ll clarify all the things in easy phrases. You’ll study what Transformers are, what MoE provides, how they differ, and whenever you would select one over the opposite.
Let’s dive in.
Understanding Transformers
Earlier than we evaluate Transformers and MoE, we have to perceive what a Transformer truly is.
At a excessive degree, a Transformer is a neural community structure designed to deal with sequences like textual content, code, or audio. It does this with out processing tokens one after the other like RNNs or LSTMs. As a substitute of studying left to proper and carrying a hidden state, it appears on the total sequence without delay. It then decides which tokens matter most to one another. This choice course of known as self-attention.
I do know this will sound complicated, so right here is an easy method to consider it. Think about a Transformer as a black field. You give it an enter and it provides you an output. For instance, consider a machine translation device. You kind a sentence in a single language and it produces the translated sentence in one other language.
Elements of Transformers
Now how is the Transformer changing one sentence into one other?
There are two essential elements: an encoding element and a decoding element, each chargeable for the conversion. The encoding element is a stack of encoders, and the decoding element is a stack of decoders of the identical quantity.
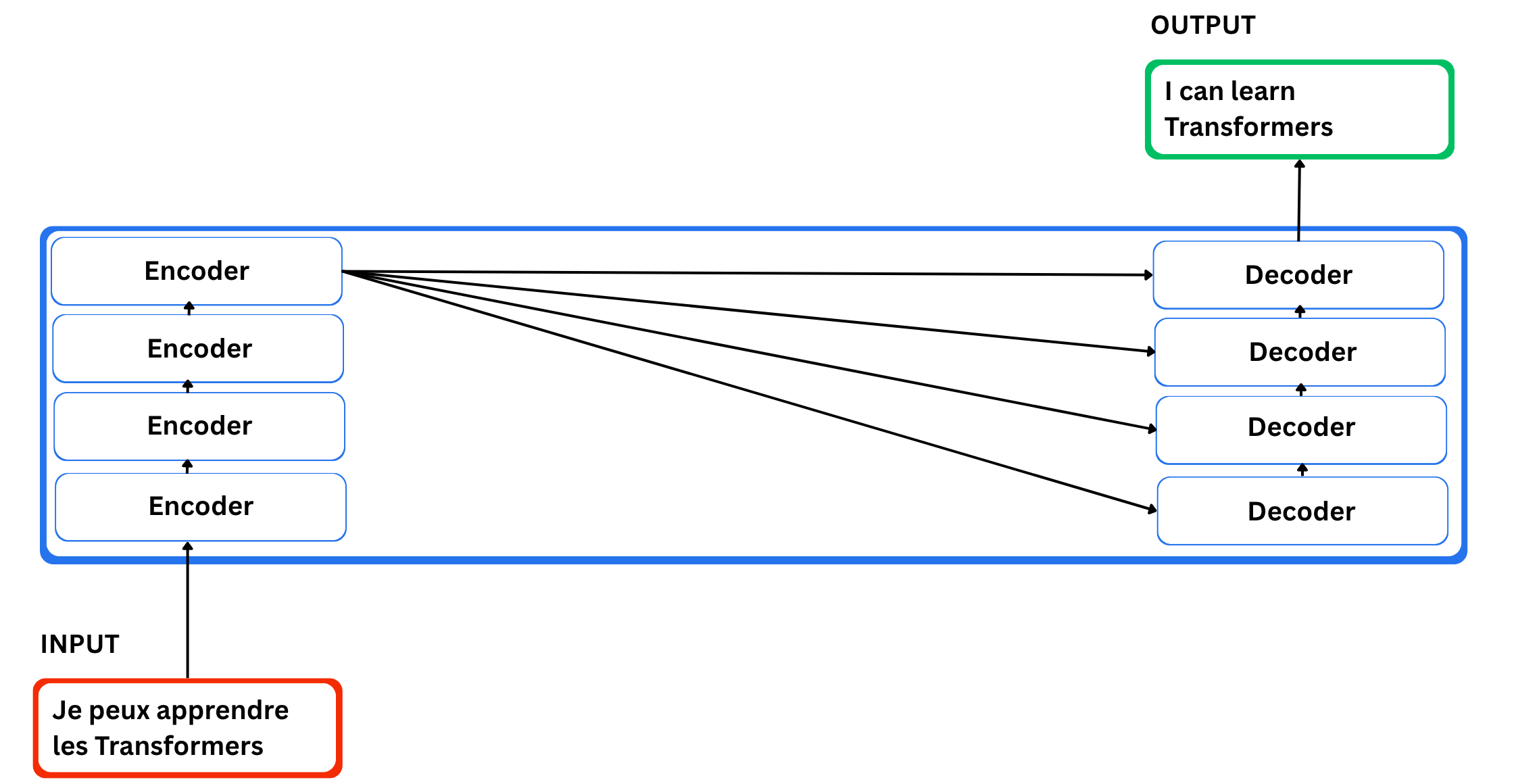
The Position of Encoders
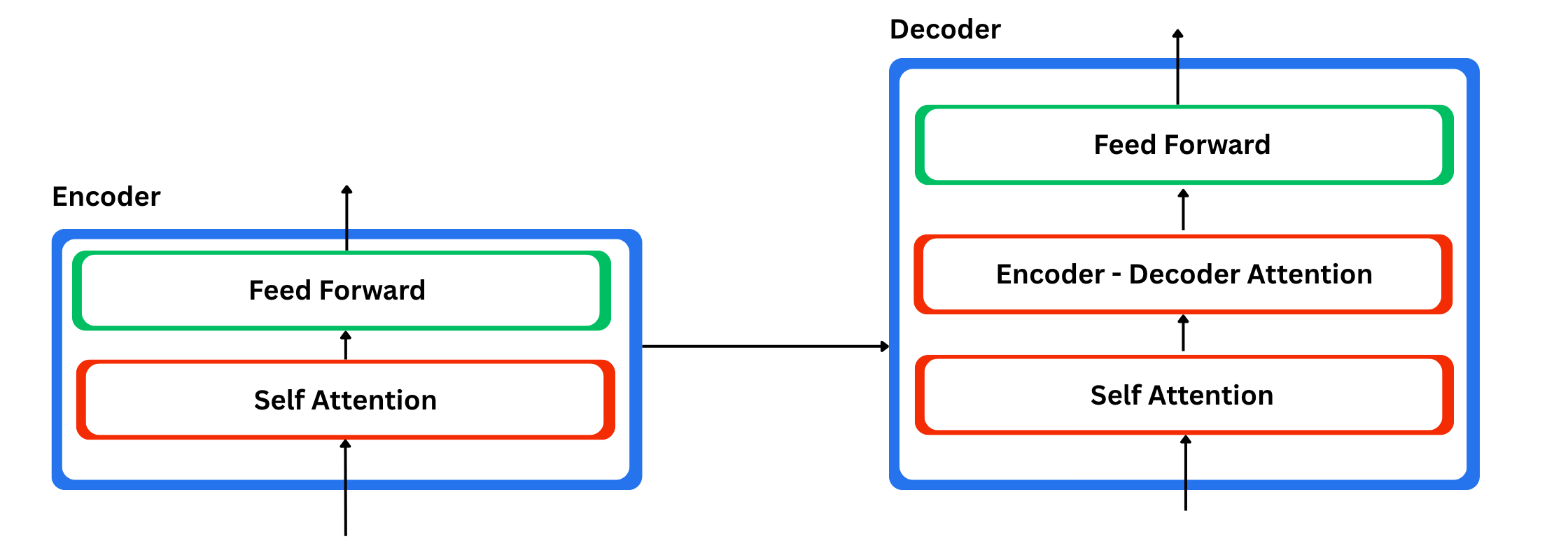
These encoders are all related in construction, and every of them is split into two sublayers: a feed-forward neural community and a self-attention layer. Within the encoder, the enter tokens first undergo the self-attention layer. This layer permits the mannequin to take a look at all the opposite phrases within the sentence whereas it processes a given phrase, so it might perceive that phrase in context. The results of self-attention is then handed right into a feed-forward community, which is a small MLP. The identical community is utilized to each place within the sequence.
The Position of the Decoder
The decoder makes use of these two components as nicely, however it has an additional consideration layer in between. That further layer lets the decoder give attention to probably the most related components of the encoder output, just like how consideration labored in basic seq2seq fashions.
If you’d like an in depth understanding of Transformers, you’ll be able to take a look at this wonderful article by Jay Alammar. He explains all the things about Transformers and self-attention in a transparent and complete method. He covers all the things from primary to superior ideas.
When and the place to make use of Transformers?
Transformers work finest when you must seize relationships throughout a sequence and you’ve got sufficient information or a powerful pretrained mannequin.
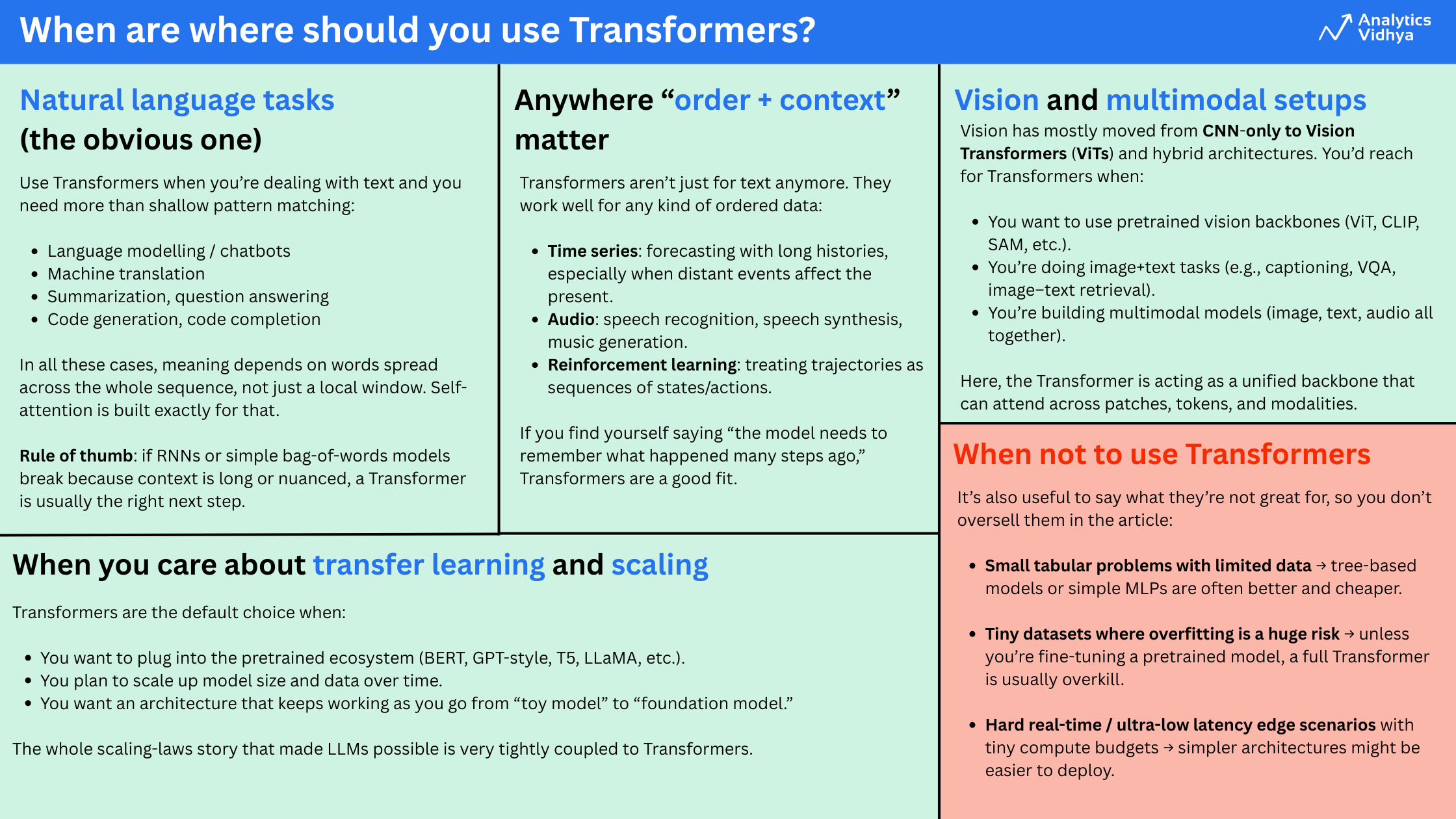
Use Transformers when your information has order and context, and when the relationships between totally different components of the sequence matter over lengthy ranges. They work extraordinarily nicely for textual content duties like chatbots, translation, summarization, and code. They’re additionally efficient for time sequence, audio, and even imaginative and prescient and multimodal issues that mix textual content, pictures, or audio.
In observe, Transformers carry out finest when you can begin from a pretrained mannequin or when you have got sufficient information and compute to coach one thing significant. For very small tabular datasets, tiny issues, or conditions with strict latency limits, less complicated fashions are often a greater match. However as soon as you progress into wealthy sequential or structured information, Transformers are virtually all the time the default alternative.
Understanding Combination of Consultants(MoE)
Combination of Consultants is common structure that use a number of consultants to enhance the prevailing transformer mannequin or you’ll be able to say to enhance the standard of the LLMs. There are majorly two element that outline a MoE:
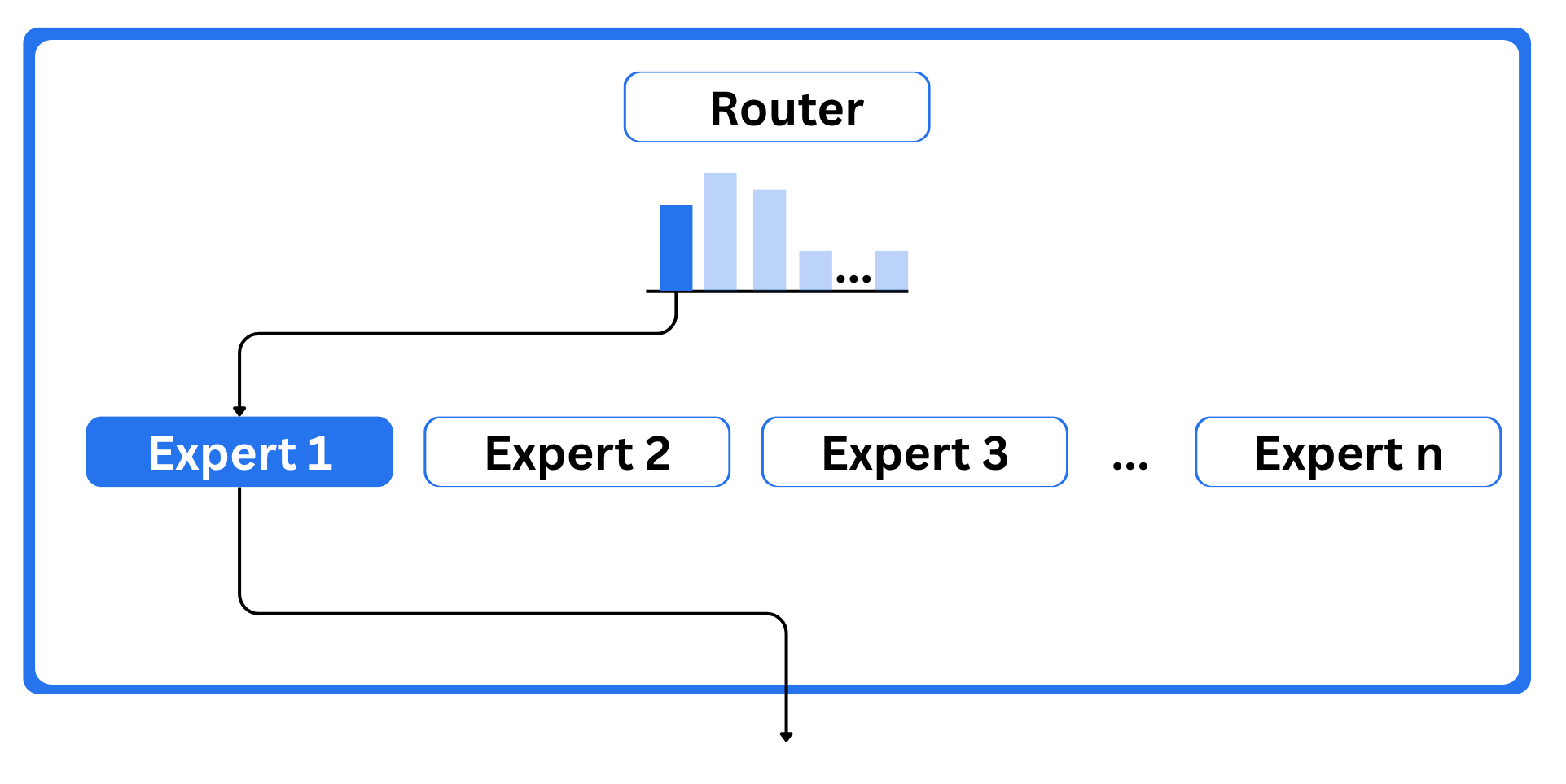
- Consultants: Every feed-forward neural community layer is changed by a bunch of consultants, and solely a subset of them is used for any given token. These consultants are usually separate FFNNs.
- Router or gate community: This decides which tokens are despatched to which consultants. It acts like a watch guard.
To maintain this text brief and centered on Transformers and MoE, I’m solely protecting the core concepts fairly than each element. If you’d like a deeper dive, you’ll be able to take a look at this weblog by Marteen.
When and the place to make use of Combination of Consultants?
Let’s break it down into the 2 issues you’re actually asking:
- When is MoE truly price it?
- The place in a mannequin does it make sense to plug it in?
It is best to use MoE when:

The place in a mannequin / pipeline do you have to use MoE?
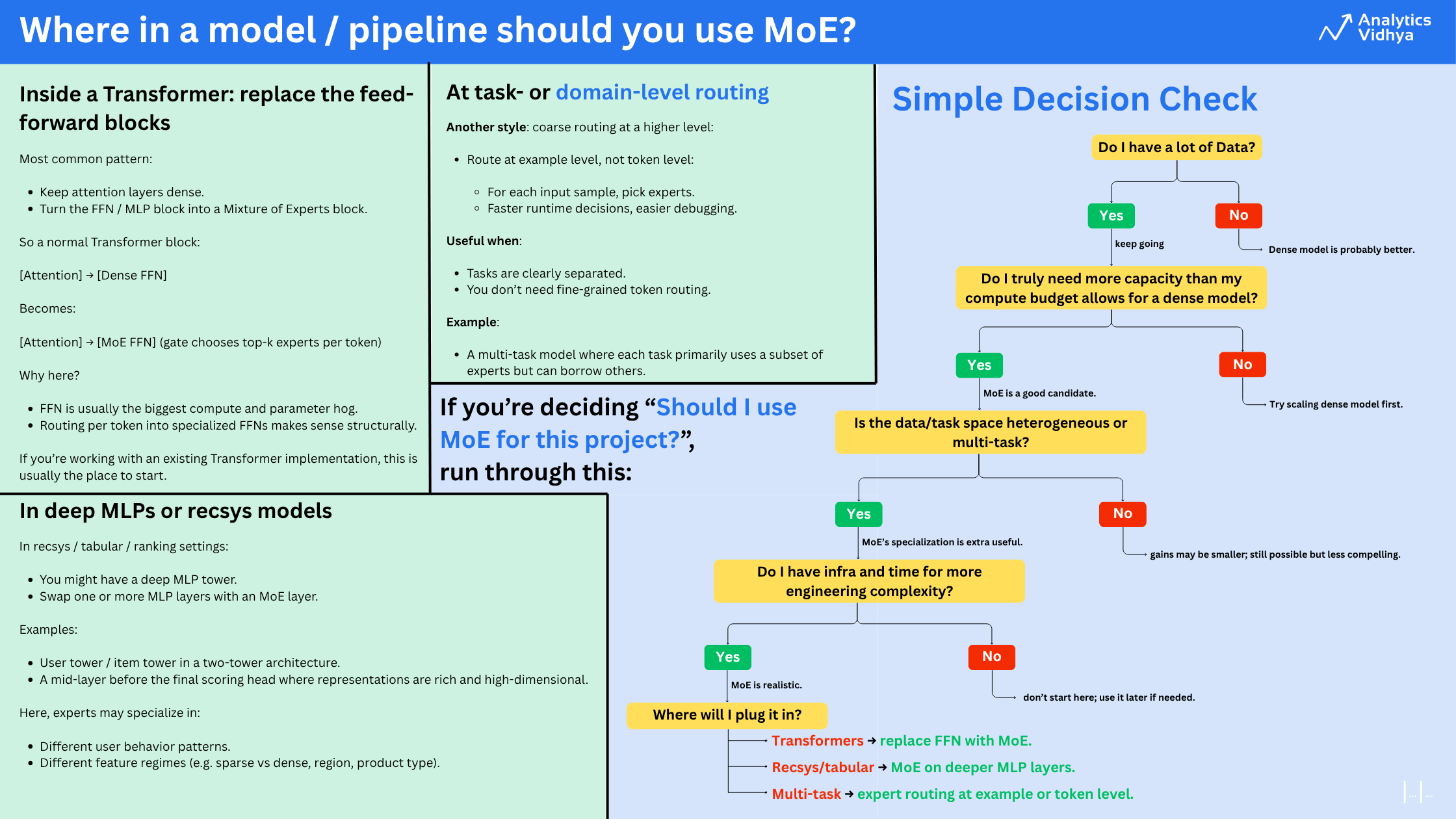
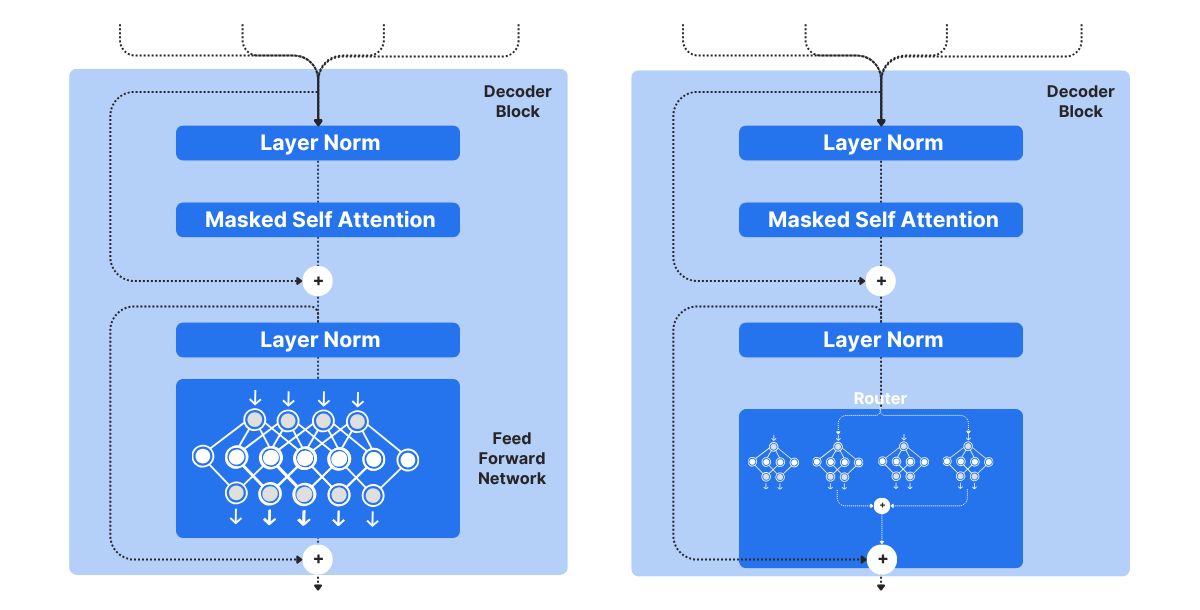
Distinction between Transformers and MoE
They primarily differ within the decoder block.
A Transformer makes use of a single feed-forward community, whereas MoE makes use of a number of consultants, that are smaller FFNNs in comparison with these in Transformers. Throughout inference, solely a subset of those consultants is chosen. This makes inference sooner in MoE.
The community in MoE accommodates a number of decoder layers:
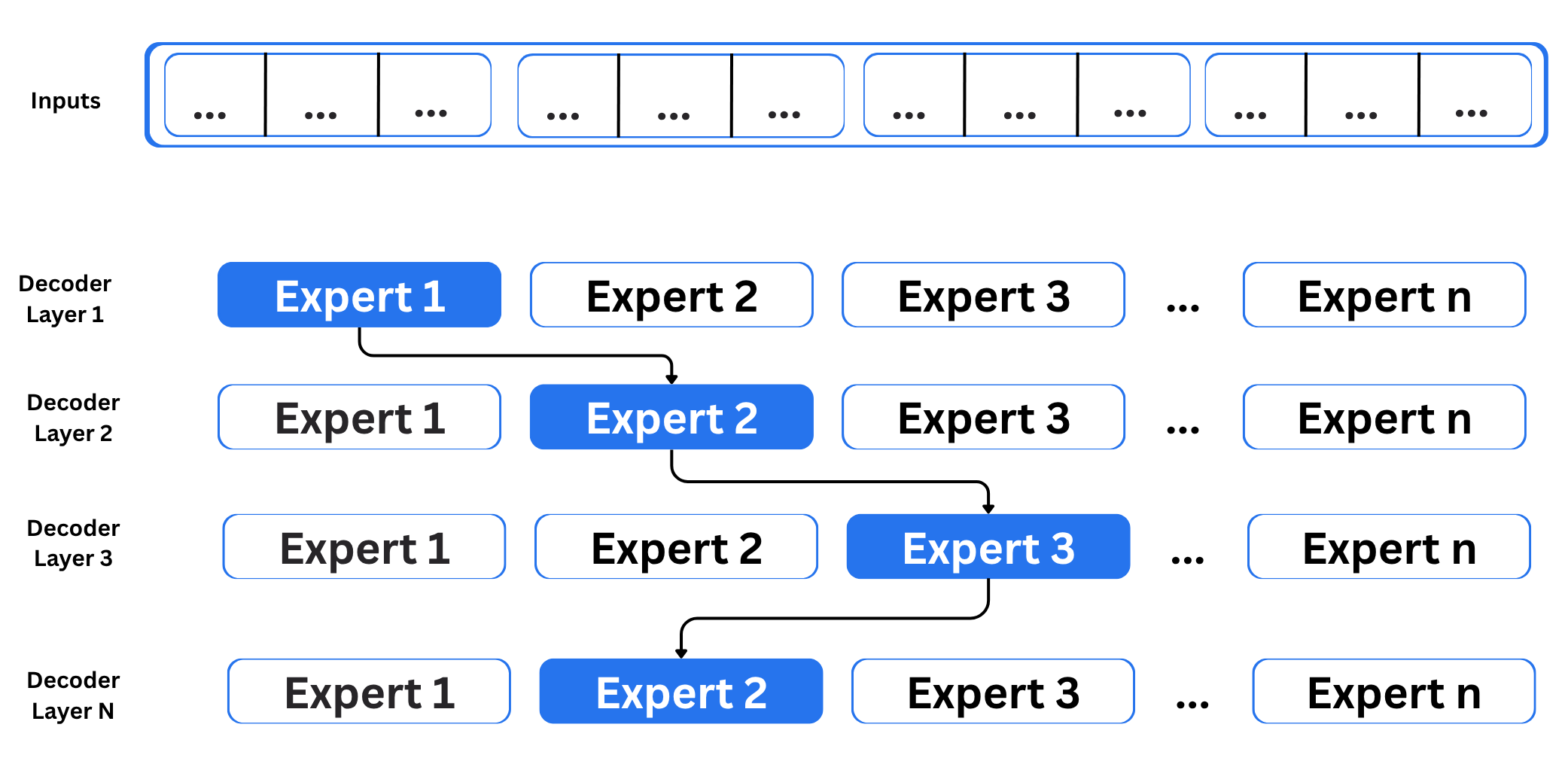
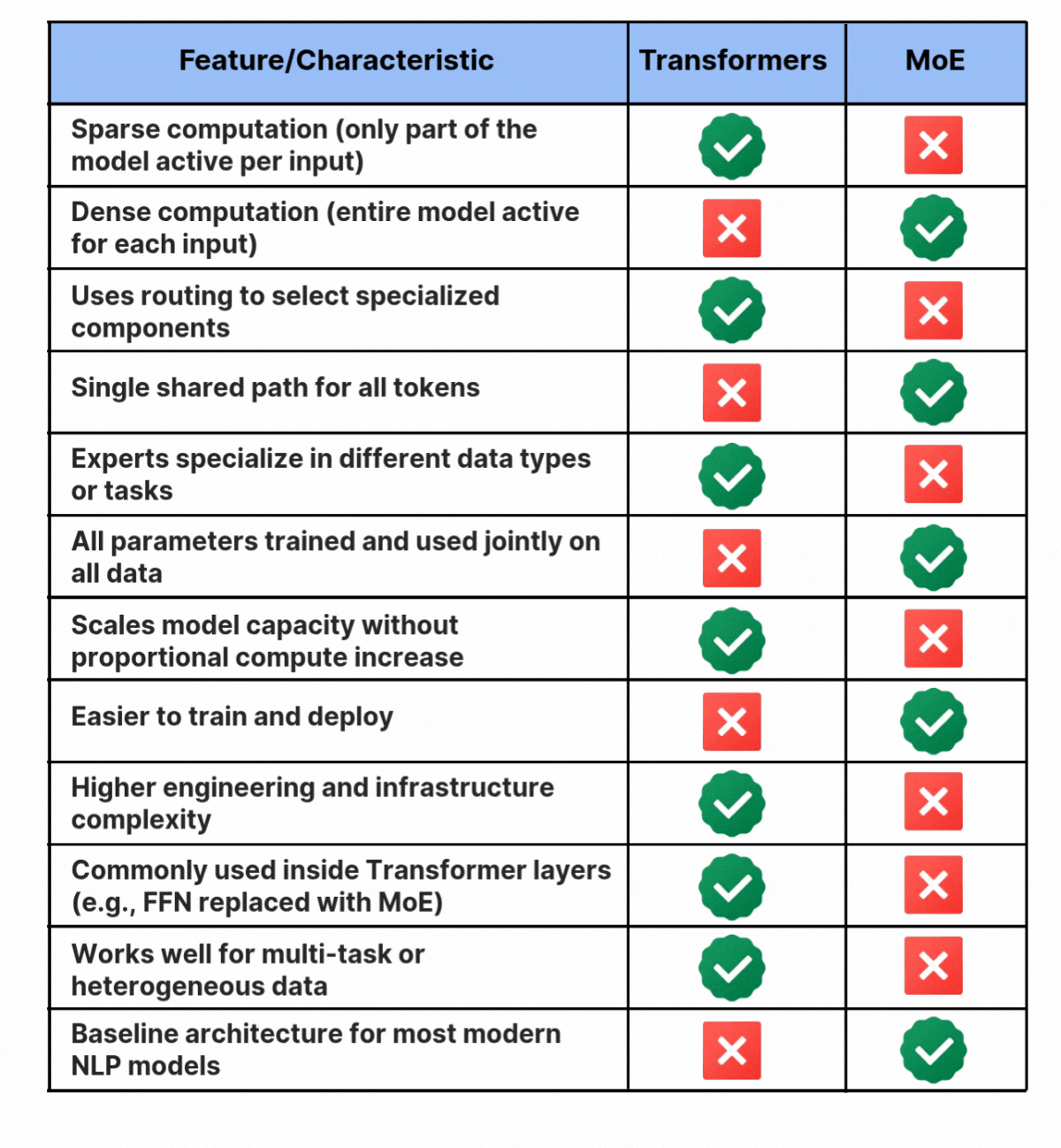
Because the community consists of a number of decoder layers, the textual content is processed by totally different consultants at every layer, and even inside a single layer the chosen consultants can change from token to token. The query is how the mannequin decides which consultants to make use of. That is dealt with by the router. The router works like a multi-class classifier that produces softmax scores for all consultants. The mannequin then selects the highest Ok consultants based mostly on these scores. The router is skilled collectively with the remainder of the community and learns over time which consultants are finest suited to every enter. You may confer with the desk under for extra details about the variations between the 2.
Conclusion
Each Combination of Consultants and Transformers purpose to scale mannequin intelligence, however they do it in several methods. Transformers use dense computation, the place each parameter contributes to each prediction. This makes them easy, highly effective, and simple to deploy. MoE makes use of conditional computation, activating solely a subset of parameters for every enter. This offers the mannequin bigger capability with out rising compute in the identical proportion and permits totally different consultants to specialize.
In easy phrases, Transformers outline how data flows via a mannequin, and MoE decides which components of the mannequin ought to deal with every enter. As fashions develop and duties grow to be extra advanced, the simplest methods will probably mix each approaches.
Incessantly Requested Questions
A. ChatGPT is constructed on the Transformer structure, however it’s not only a Transformer. It consists of large-scale coaching, alignment strategies, security layers, and generally MoE elements. The inspiration is the Transformer, however the full system is way more superior.
A. GPT makes use of the Transformer decoder structure as its core constructing block. It depends on self-attention to grasp relationships throughout textual content and generate coherent output. Since its total design is predicated on Transformer rules, it’s categorised as a Transformer mannequin.
A. Transformers are typically grouped into encoder-only fashions, decoder-only fashions, and encoder–decoder fashions. Encoder-only fashions work finest for understanding duties, decoder-only fashions for technology duties, and encoder–decoder fashions for structured input-to-output duties like translation or summarization.
A. Transformers use dense computation the place each parameter helps with each prediction. MoE makes use of conditional computation and prompts only some consultants for every enter. This permits a lot bigger capability with out proportional compute value. Transformers deal with movement, whereas MoE handles specialization.
Development Hacker | Generative AI | LLMs | RAGs | FineTuning | 62K+ Followers https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/
Login to proceed studying and revel in expert-curated content material.