
 Deployment")
{kind=link}
Desk of Contents
Changing a PyTorch Mannequin to ONNX for FastAPI (Docker) Deployment
On this lesson, you’ll learn to convert a pre-trained ResNetV2-50 mannequin utilizing PyTorch Picture Fashions (TIMM) to ONNX, analyze its construction, and check inference utilizing ONNX Runtime. We’ll additionally examine inference velocity and mannequin measurement in opposition to normal PyTorch execution to spotlight why ONNX is best suited to light-weight AI inference. This prepares the mannequin for integration with FastAPI and Docker, guaranteeing setting consistency earlier than deploying to AWS Lambda.
This lesson is the 2nd in a 4-part collection on AWS Lambda:
- Introduction to Serverless Mannequin Deployment with AWS Lambda and ONNX
- Changing a PyTorch Mannequin to ONNX for FastAPI (Docker) Deployment (this tutorial)
- Lesson 3
- Lesson 4
To learn to convert a ResNetV2-50 mannequin to ONNX, examine it with PyTorch, and put together it for FastAPI and Docker earlier than AWS Lambda deployment, simply preserve studying.
Introduction
Deploying AI fashions in manufacturing requires quick, scalable, and environment friendly inference. Nonetheless, when transferring to cloud environments like AWS Lambda, there are a number of constraints to think about:
- Restricted Reminiscence: AWS Lambda helps as much as 10GB of reminiscence, which is probably not sufficient for giant fashions.
- Execution Time Limits: A single Lambda perform execution can’t exceed quarter-hour.
- Chilly Begins: If a Lambda perform is inactive for some time, it takes longer to begin up, slowing inference velocity.
- Storage Restrictions: Lambda packages have a 250MB restrict (together with dependencies), making it essential to optimize mannequin measurement.
To make sure easy deployment and environment friendly inference, we should first check and optimize our AI mannequin domestically earlier than integrating it right into a FastAPI API. This implies:
- Changing the mannequin to a light-weight, optimized format (ONNX).
- Evaluating ONNX vs. PyTorch to research variations in velocity, efficiency, and file measurement.
- Serving the mannequin through an API (FastAPI) for simple inference requests.
- Containerizing the setup utilizing Docker for constant execution throughout environments.
By the tip of this tutorial, you’ll not solely perceive find out how to convert a PyTorch mannequin to ONNX, however you’ll additionally see how ONNX compares to PyTorch when it comes to inference velocity and effectivity. This prepares the mannequin for integration with FastAPI and Docker, guaranteeing that it really works precisely as anticipated earlier than deploying to AWS Lambda.
Recap of the Earlier Lesson
In Lesson 1: Introduction to Serverless AI Deployment, we explored:
- The basics of serverless AI inference utilizing AWS Lambda, API Gateway, and ONNX Runtime.
- Why ONNX is a perfect alternative for AI inference in resource-constrained environments.
- How AWS Lambda processes inference requests in a serverless setup.
- Establishing the event setting to work with ONNX and FastAPI.
We additionally launched our end-to-end AI inference move diagram, showcasing how API Gateway, AWS Lambda, and ONNX Runtime work collectively for seamless inference.
Now, on this lesson, we are going to take the subsequent step by:
- Changing our PyTorch mannequin to ONNX.
- Evaluating ONNX and PyTorch when it comes to inference velocity and mannequin measurement.
- Serving the mannequin with FastAPI and working it in Docker (within the subsequent lesson).
Why This Step Issues
Many builders wrestle to deploy AI fashions on to AWS Lambda with out correctly testing them in a managed setting. This usually results in:
- Errors in mannequin execution as a result of compatibility points.
- Excessive inference latency in cloud environments.
- Inefficient reminiscence utilization resulting in perform failures.
As an alternative of deploying prematurely, we first construct, check, and refine our inference server domestically utilizing ONNX Runtime and FastAPI. This enables us to:
- Optimize our mannequin for deployment by lowering measurement and bettering inference velocity.
- Examine ONNX vs. PyTorch to find out one of the best format for AWS Lambda.
- Catch and debug errors domestically somewhat than coping with deployment failures on AWS.
- Preserve a constant setting with Docker in order that what works domestically additionally works in manufacturing.
AWS Lambda runs inside a containerized setting, so by testing our API inside a Docker container first, we be sure that it behaves constantly when deployed.
What You’ll Be taught in This Lesson
On this lesson, we’ll begin by:
- Changing a PyTorch ResNetV2-50 (TIMM) mannequin to ONNX format for environment friendly inference.
- Analyzing the ONNX mannequin construction to know the way it differs from PyTorch.
- Evaluating ONNX vs. PyTorch inference efficiency, together with execution time and mannequin measurement.
- Validating inference outcomes utilizing ONNX Runtime to make sure accuracy.
As soon as that is executed, within the subsequent lesson, we’ll:
- Construct a FastAPI-based inference API to deal with picture classification requests.
- Check the API domestically earlier than deployment.
- Containerize the FastAPI server utilizing Docker for a constant runtime.
Applied sciences Used
ONNX Runtime
ONNX (Open Neural Community Change) is an open normal for machine studying fashions that enables us to:
- Optimize mannequin execution throughout completely different {hardware} architectures.
- Scale back inference latency in comparison with native PyTorch or TensorFlow fashions.
- Make fashions extra moveable throughout completely different cloud and edge environments.
PyTorch Picture Fashions (TIMM)
As an alternative of utilizing uncooked PyTorch, we’ll leverage TIMM (Torch Picture Fashions) — a robust library that gives pre-trained fashions with environment friendly implementations. TIMM makes it simpler to:
- Load and fine-tune state-of-the-art picture classification fashions.
- Convert fashions to ONNX format with minimal effort.
- Guarantee compatibility with ONNX Runtime for optimized inference.
FastAPI (Lined in Subsequent Lesson)
FastAPI is a high-performance net framework that enables us to:
- Expose our ONNX mannequin as an API for inference.
- Deal with real-time requests effectively with minimal overhead.
- Guarantee a seamless transition to AWS Lambda later by conserving the API light-weight.
Docker (Lined in Subsequent Lesson)
Containerizing our FastAPI inference server ensures:
- Constant execution throughout completely different environments (native, AWS Lambda, cloud, edge).
- Dependency isolation prevents conflicts between system packages.
- Simplified deployment, since AWS Lambda helps containerized purposes.
Configuring Your Improvement Setting
To make sure a easy growth course of, we first have to arrange our surroundings with the required dependencies. This consists of putting in FastAPI, ONNX Runtime, PyTorch Picture Fashions (TIMM), and Docker to run the inference API inside a container earlier than deploying to AWS Lambda.
Fortunately, all required Python packages are pip-installable. Run the next command to put in them:
$ pip set up fastapi[all]==0.98.0 numpy==1.25.2 onnxruntime==1.15.1 mangum==0.17.0 Pillow==9.5.0 timm==0.9.5 onnx==1.14.0
Now that our surroundings is ready up, let’s convert the PyTorch mannequin to ONNX!
Want Assist Configuring Your Improvement Setting?

All that mentioned, are you:
- Brief on time?
- Studying in your employer’s administratively locked system?
- Desirous to skip the trouble of combating with the command line, bundle managers, and digital environments?
- Able to run the code instantly in your Home windows, macOS, or Linux system?
Then be part of PyImageSearch College right this moment!
Acquire entry to Jupyter Notebooks for this tutorial and different PyImageSearch guides pre-configured to run on Google Colab’s ecosystem proper in your net browser! No set up required.
And better of all, these Jupyter Notebooks will run on Home windows, macOS, and Linux!
Undertaking Construction
We first have to evaluate our undertaking listing construction.
Begin by accessing this tutorial’s “Downloads” part to retrieve the supply code and instance photographs.
From there, check out the listing construction:
$ tree . -L 1 resnet-aws-serverless-classifier/ ├── src/ │ ├── convert.py # Used right here – converts PyTorch mannequin to ONNX │ ├── onnxt.py # For later – ONNX Runtime inference │ ├── onnx_local.py # For later – native ONNX inference testing │ ├── server.py # Can be utilized in Lesson 3 (FastAPI backend) │ └── __init__.py ├── fashions/ │ ├── resnetv2_50.onnx # Generated ONNX mannequin saved after conversion │ └── imagenet_classes.txt # Maps numeric predictions to class labels ├── knowledge/ │ ├── cat.jpg / canine.jpg # Pattern photographs for verifying ONNX inference │ ├── cat_base64.txt # Used later for Lambda enter payloads │ ├── occasion.json / payload.json / response.json # For Lambda testing (future) ├── assessments/ │ ├── prepare_event.py # Prepares Lambda check occasions (future) │ ├── test_boto3_lambda.py # Exams AWS Lambda invocation (future) │ └── test_lam.py # Native Lambda perform assessments (future) ├── frontend/ # For Classes 7–8 (Subsequent.js frontend) ├── Dockerfile # For AWS Lambda deployment (future) ├── Dockerfile.native # For native FastAPI testing (Lesson 3) ├── docker-compose.native.yml # Used later for multi-container setup ├── dev.sh # Helper script for growth duties ├── necessities.txt # Python dependencies for deployment ├── requirements-local.txt # Dependencies for native growth ├── .dockerignore ├── .gitignore └── README.md
Let’s rapidly evaluate the parts we use on this lesson:
convert.py: Converts the pre-trained ResNetV2-50 mannequin from PyTorch to ONNX format, defines the enter tensor, and saves the exported file.resnetv2_50.onnx: The ONNX mannequin file generated from conversion, prepared for deployment throughout a number of frameworks and {hardware} targets.imagenet_classes.txt: A easy textual content file containing ImageNet class labels used to interpret the mannequin’s numeric outputs.cat.jpg/canine.jpg: Pattern check photographs for verifying that the exported ONNX mannequin performs right picture classification earlier than transferring on to deployment.
Changing ResNetV2-50 (TIMM) to ONNX
Now that our growth setting is ready up, we’ll convert a pre-trained ResNetV2-50 mannequin from PyTorch Picture Fashions (TIMM) to ONNX format. ONNX (Open Neural Community Change) is an optimized format for inference throughout completely different platforms, guaranteeing quick execution in environments similar to AWS Lambda.
Why Convert to ONNX?
- Cross-Platform Compatibility: ONNX fashions can be utilized throughout PyTorch, TensorFlow, and different frameworks.
- Optimized for Inference: ONNX fashions run sooner than conventional PyTorch fashions in manufacturing.
- Light-weight and Environment friendly: ONNX fashions have smaller reminiscence footprints, making them ultimate for cloud deployments.
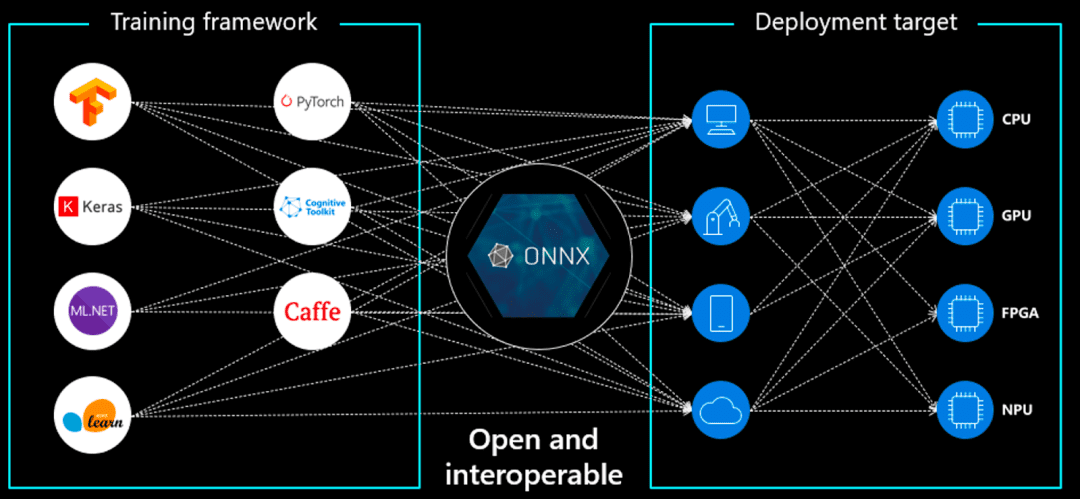
AWS Lambda has execution constraints, similar to restricted reminiscence and storage, so utilizing ONNX Runtime ensures that inference is optimized and environment friendly.
Exporting ResNetV2-50 (TIMM) to ONNX
We’ll now create a script (convert.py) to:
- Load the pre-trained ResNetV2-50 mannequin from TIMM.
- Outline a dummy enter tensor (matching the mannequin’s enter measurement).
- Convert and export the mannequin to ONNX format.
Creating convert.py
Create a brand new file named convert.py and add the next code:
import torch
import torch.onnx
import timm
import onnxruntime as ort
import numpy as np
import requests
from PIL import Picture
from io import BytesIO
mannequin = timm.create_model('resnetv2_50', pretrained=True)
mannequin = mannequin.eval()
model_script = torch.jit.script(mannequin)
import os
print("exporting onnx...")
# Use setting variable to find out output path, default to fashions listing
output_dir = os.getenv("MODEL_PATH", "../fashions")
output_path = os.path.be part of(output_dir, "resnetv2_50.onnx")
torch.onnx.export(model_script, torch.randn(1, 3, 224, 224), output_path, verbose=True, input_names=[
'input'], output_names=['output'], dynamic_axes={'enter': {0: 'batch'}})
We convert a pre-trained ResNetV2-50 mannequin from PyTorch (through TIMM) to ONNX format for optimized inference. We first
- Load the ResNetV2-50 mannequin and set it to analysis mode.
- Then, apply TorchScript (
torch.jit) to hint the mannequin, guaranteeing compatibility earlier than exporting it to ONNX. - The
torch.onnx.export()perform is used to transform the scripted mannequin to ONNX, specifying a dummy enter tensor of form (1, 3, 224, 224) to outline the enter construction. Theverbose=Trueflag logs the export course of, whereasdynamic_axespermits versatile batch sizes. - The ultimate ONNX mannequin (
resnetv2_50.onnx) is saved, making it prepared for inference with ONNX Runtime.
Understanding the ONNX Mannequin Construction
As soon as the mannequin is transformed, we are able to examine its construction utilizing onnx:
import onnx
# Load ONNX mannequin
onnx_model = onnx.load("resnetv2_50.onnx")
# Verify mannequin construction
print(onnx.helper.printable_graph(onnx_model.graph))
This printable graph represents the ONNX computational graph of the ResNetV2-50 mannequin, displaying how enter tensors, weights, and layers are linked. It begins with the enter tensor %enter, adopted by initializers for convolution weights, batch normalization parameters, and biases throughout layers. The graph defines the mannequin’s phases and blocks, together with convolutional layers (conv), downsampling operations (downsample.conv), and normalization layers (norm1). The ultimate a part of the graph applies a worldwide common pooling layer, adopted by a totally linked (fc) layer, and flattens the output to provide the ultimate mannequin predictions.
graph main_graph ( %enter[FLOAT, batchx3x224x224] ) initializers ( %stem.conv.weight[FLOAT, 64x3x7x7] %phases.0.blocks.0.norm1.running_mean[FLOAT, 64] %phases.0.blocks.0.norm1.running_var[FLOAT, 64] %phases.0.blocks.0.norm1.weight[FLOAT, 64] %phases.0.blocks.0.norm1.bias[FLOAT, 64] %phases.0.blocks.0.downsample.conv.weight[FLOAT, 256x64x1x1] %phases.0.blocks.0.conv3.weight[FLOAT, 256x64x1x1] %phases.0.blocks.1.norm1.running_mean[FLOAT, 256] %phases.0.blocks.1.norm1.running_var[FLOAT, 256] %phases.0.blocks.1.norm1.weight[FLOAT, 256] %phases.1.blocks.0.conv3.weight[FLOAT, 512x128x1x1] %phases.1.blocks.1.norm1.running_mean[FLOAT, 512] %phases.1.blocks.1.norm1.running_var[FLOAT, 512] %phases.1.blocks.1.norm1.weight[FLOAT, 512] %phases.1.blocks.1.norm1.bias[FLOAT, 512] %phases.1.blocks.1.conv3.weight[FLOAT, 512x128x1x1] %phases.1.blocks.2.norm1.running_mean[FLOAT, 512] %phases.1.blocks.2.norm1.running_var[FLOAT, 512] ..... ...... ..... ...... GlobalAveragePool(%/norm/Relu_output_0) %/head/fc/Conv_output_0 = Conv[dilations = [1, 1], group = 1, kernel_shape = [1, 1], pads = [0, 0, 0, 0], strides = [1, 1]](%/head/global_pool/pool/GlobalAveragePool_output_0, %head.fc.weight, %head.fc.bias) %output = Flatten[axis = 1](%/head/fc/Conv_output_0) return %output }
Evaluating ONNX vs. PyTorch for AI Inference
Now that we now have transformed our ResNetv2-50 mannequin to ONNX, it’s necessary to know how ONNX compares to PyTorch when it comes to inference efficiency. We’ll examine the 2 within the following areas:
- Mannequin File Dimension: Is ONNX extra light-weight than PyTorch?
- Inference Pace: Which format runs inference sooner?
- Efficiency Commerce-Offs: What are the benefits and limitations of every?
By the tip of this part, you’ll clearly see why ONNX is a better option for optimized AI inference in resource-constrained environments like AWS Lambda.
Evaluating Mannequin File Sizes
One of many largest expectations for ONNX is that it reduces mannequin measurement, making it simpler to deploy in environments (e.g., AWS Lambda), the place storage constraints are frequent.
Let’s examine the file sizes of the unique PyTorch mannequin vs. the transformed ONNX mannequin:
import os
# Paths to saved fashions
pytorch_model_path = "resnetv2_50.pth"
onnx_model_path = "resnetv2_50.onnx"
# Verify file sizes (Convert bytes to MB)
pytorch_size = os.path.getsize(pytorch_model_path) / (1024 * 1024)
onnx_size = os.path.getsize(onnx_model_path) / (1024 * 1024)
print(f"PyTorch Mannequin Dimension: {pytorch_size:.2f} MB")
print(f"ONNX Mannequin Dimension: {onnx_size:.2f} MB")
Right here, we examine the file sizes of the PyTorch (.pth) and ONNX (.onnx) fashions to evaluate the scale discount ONNX offers.
We use os.path.getsize() to get the file measurement in bytes, then convert it to megabytes (MB) for simpler readability.
Lastly, print the sizes of each fashions to find out whether or not ONNX is extra light-weight, which is necessary for deployment in serverless environments like AWS Lambda, the place storage is proscribed.
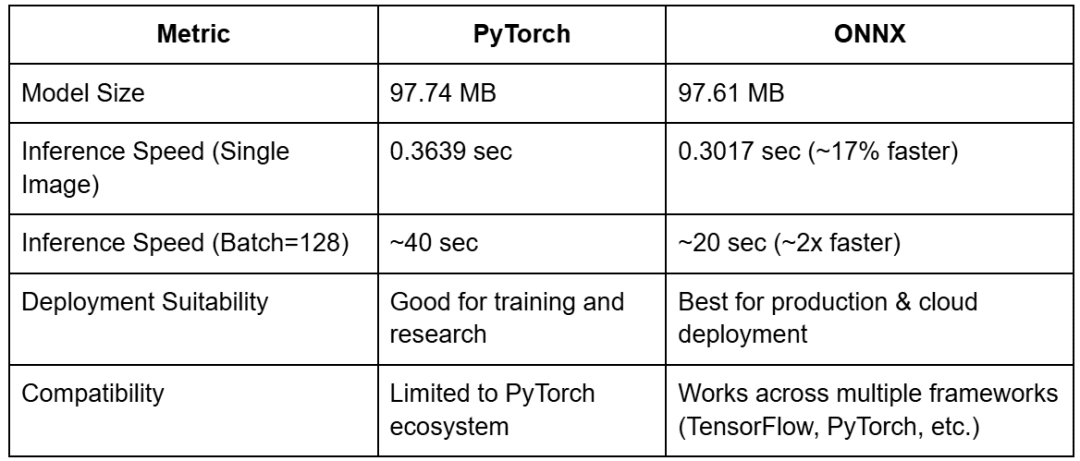
PyTorch Mannequin Dimension: 97.74 MB ONNX Mannequin Dimension: 97.61 MB
ONNX ought to ideally be smaller than PyTorch, however as we noticed, each have been practically the identical ( 97MB).
97MB).
Evaluating Inference Pace: PyTorch vs. ONNX
Whereas mannequin measurement is necessary, inference velocity is much more crucial, particularly in real-time AI purposes the place latency impacts person expertise.
Let’s examine how lengthy it takes to run inference utilizing PyTorch and ONNX Runtime.
PyTorch Inference Pace
import torch
import timm
import time
# Load PyTorch mannequin
pytorch_model = timm.create_model("resnetv2_50", pretrained=True)
pytorch_model.eval()
# Generate a dummy enter tensor (Batch Dimension: 1, Channels: 3, Top: 224, Width: 224)
dummy_input = torch.randn(1, 3, 224, 224)
# Measure inference time
start_time = time.time()
with torch.no_grad():
_ = pytorch_model()
pytorch_inference_time = time.time() - start_time
print(f"PyTorch Inference Time: {pytorch_inference_time:.4f} seconds")
Subsequent, we measure how lengthy it takes for the PyTorch mannequin to course of an enter tensor and return an output.
First, we load the ResNetV2-50 mannequin from TIMM and set it to analysis mode (eval()), disabling gradient updates since we’re solely working inference.
Generate a random dummy enter tensor with the form (1, 3, 224, 224), representing a single RGB picture of measurement 224×224 pixels. The mannequin is then timed utilizing time.time() to measure inference time.
You’ll want to flip off Gradient monitoring (torch.no_grad()) to hurry up execution, since we’re not coaching the mannequin.
PyTorch Inference Time: 0.3639 seconds
The PyTorch mannequin takes 0.36 seconds for a single picture inference in our assessments.
ONNX Inference Pace
import numpy as np
import time
# Load ONNX mannequin
ort_session = ort.InferenceSession("resnetv2_50.onnx")
# Convert PyTorch tensor to NumPy array
onnx_input = dummy_input.numpy()
# Measure ONNX inference time
start_time = time.time()
_ = ort_session.run({"enter": onnx_input})
onnx_inference_time = time.time()
print(f"ONNX Inference Time: {onnx_inference_time:.4f} seconds")
Then we run inference with ONNX Runtime and measure how rapidly it processes the identical enter utilized in PyTorch.
- It masses the ONNX mannequin (
resnetv2_50.onnx) utilizingonnxruntime.InferenceSession(). - Since ONNX requires inputs in NumPy format, the PyTorch tensor is transformed to a NumPy array (
dummy_input.numpy()) earlier than inference. - The script measures the inference time taken utilizing
time.time(), just like the PyTorch model. - Lastly, print the ONNX inference time for comparability.
ONNX Inference Time: 0.3017 seconds
ONNX inference is 17% sooner than PyTorch for single-image inference.
Batch Inference: The place ONNX Shines Even Extra
Whereas single-image inference was solely 17% sooner, we additionally examined batch inference (batch=128 photographs), the place ONNX’s optimizations actually present enhancements.
Batch Dimension = 128
PyTorch Inference Time: ~40 seconds ONNX Inference Time: ~20 seconds
ONNX is  2x sooner than PyTorch when processing bigger batches, making it a superior alternative for AI inference workloads.
2x sooner than PyTorch when processing bigger batches, making it a superior alternative for AI inference workloads.
Why Is ONNX Sooner for Bigger Batches?
- ONNX Runtime optimizes batch execution extra effectively than PyTorch.
- Decrease overhead → PyTorch dynamically constructs the computation graph per batch, whereas ONNX makes use of a static graph.
- ONNX avoids Python’s International Interpreter Lock (GIL), permitting parallel execution of a number of inputs.
For giant-scale AI deployments, ONNX offers vital velocity enhancements over PyTorch.
Efficiency Commerce-Offs and Evaluation
Key Takeaways
- ONNX inference is 17% sooner for single-image inference and 2x sooner for batch inference (128 photographs).
- Mannequin measurement stays practically an identical (97MB), however minor optimizations can scale back it barely.
- ONNX is cross-platform, that means it may be utilized in completely different AI ecosystems.
- ONNX Runtime is best suited to large-scale AI inference, whereas PyTorch continues to be higher for coaching and analysis.
Nonetheless, ONNX is finest suited to inference solely. If that you must prepare or fine-tune a mannequin, PyTorch stays the higher alternative.
Now that we’ve confirmed ONNX is the higher alternative for optimized inference, let’s transfer to testing the ONNX mannequin with ONNX Runtime.
Testing the ONNX Mannequin with ONNX Runtime
Now that we’ve confirmed that ONNX is quicker than PyTorch for AI inference, it’s important to validate our ONNX mannequin’s correctness utilizing ONNX Runtime.
We’ll check the mannequin by:
- Working inference on ONNX Runtime to make sure right execution.
- Evaluating ONNX predictions with PyTorch to substantiate that the conversion didn’t have an effect on accuracy.
- Dealing with potential ONNX mannequin errors and debugging any inconsistencies.
Working Inference on ONNX Runtime
We’ll now run inference with ONNX Runtime and confirm that the mannequin appropriately processes a picture.
Load the ONNX Mannequin and Run a Pattern Inference
import numpy as np
from PIL import Picture
import onnxruntime as ort
import torch
import timm
import torchvision.transforms as transforms
# Load the ONNX mannequin
ort_session = ort.InferenceSession("resnetv2_50.onnx")
# Load an instance picture
image_path = "cat.jpg" # Change this to any check picture
picture = Picture.open(image_path)
# Outline picture preprocessing
rework = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Preprocess picture and convert to numpy array
input_tensor = rework(picture).unsqueeze(0).numpy()
# Get enter and output names from the mannequin
input_name = ort_session.get_inputs()[0].identify
output_name = ort_session.get_outputs()[0].identify
# Run inference utilizing ONNX Runtime
outputs = ort_session.run([output_name], {input_name: input_tensor})
# Get the expected class index
predicted_class_idx = np.argmax(outputs[0])
print(f"ONNX Mannequin Prediction: Class Index {predicted_class_idx}")
We run inference with ONNX Runtime to make sure the transformed ONNX mannequin capabilities appropriately. We begin by
- Loading the ResNetV2-50 ONNX mannequin and a check picture (e.g.,
"cat.jpg"). - The picture is then preprocessed utilizing Torchvision transforms, resized to (224, 224), transformed to a tensor, and normalized utilizing ImageNet’s imply and normal deviation.
- Since ONNX requires inputs in NumPy format, the processed tensor is transformed to NumPy format earlier than inference.
- The mannequin then runs a ahead move, and the expected class index is extracted utilizing
argmax(), figuring out the almost definitely classification.
The ONNX mannequin ought to efficiently course of the picture and output a legitimate class index.
Evaluating ONNX Predictions with PyTorch
To make sure the ONNX mannequin is functionally an identical to the unique PyTorch mannequin, let’s run the identical picture by the PyTorch model of the mannequin and examine predictions.
# Load PyTorch mannequin
pytorch_model = timm.create_model("resnetv2_50", pretrained=True)
pytorch_model.eval
# Convert picture to PyTorch tensor
input_tensor_torch = rework(picture).unsqueeze(0)
# Run PyTorch inference
with torch.no_grad():
output_torch = pytorch_model()
# Get the expected class index
predicted_class_torch = torch.argmax(output, dim=-1).merchandise()
print(f"PyTorch Mannequin Prediction: Class Index {predicted_class_torch}")
# Examine ONNX and PyTorch predictions
if predicted_class_idx == predicted_torch:
print("Success! ONNX and PyTorch predictions match.")
else:
print("Warning: ONNX and PyTorch predictions don't match. Additional debugging required.")
We then carry out the identical inference however utilizing PyTorch.
- We load the unique ResNetV2-50 mannequin from TIMM and set it to analysis mode (
eval()) for inference. - The identical picture undergoes an identical preprocessing and is handed by the PyTorch mannequin.
- The output is a likelihood distribution over lessons, from which the category with the very best likelihood is chosen.
- Lastly, the PyTorch prediction is in contrast with the ONNX mannequin’s output.
If ONNX and PyTorch predictions match, the mannequin conversion was profitable. In the event that they don’t match, we could have to debug the ONNX mannequin conversion.
Now that our ONNX mannequin is totally examined, we’re able to combine it right into a FastAPI AI inference server (within the subsequent lesson).
What’s subsequent? We suggest PyImageSearch College.
86+ complete lessons • 115+ hours hours of on-demand code walkthrough movies • Final up to date: November 2025
★★★★★ 4.84 (128 Scores) • 16,000+ College students Enrolled
I strongly imagine that in the event you had the best instructor you may grasp laptop imaginative and prescient and deep studying.
Do you assume studying laptop imaginative and prescient and deep studying needs to be time-consuming, overwhelming, and sophisticated? Or has to contain advanced arithmetic and equations? Or requires a level in laptop science?
That’s not the case.
All that you must grasp laptop imaginative and prescient and deep studying is for somebody to elucidate issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter training and the way advanced Synthetic Intelligence matters are taught.
When you’re severe about studying laptop imaginative and prescient, your subsequent cease ought to be PyImageSearch College, essentially the most complete laptop imaginative and prescient, deep studying, and OpenCV course on-line right this moment. Right here you’ll learn to efficiently and confidently apply laptop imaginative and prescient to your work, analysis, and tasks. Be part of me in laptop imaginative and prescient mastery.
Inside PyImageSearch College you may discover:
- &verify; 86+ programs on important laptop imaginative and prescient, deep studying, and OpenCV matters
- &verify; 86 Certificates of Completion
- &verify; 115+ hours hours of on-demand video
- &verify; Model new programs launched repeatedly, guaranteeing you’ll be able to sustain with state-of-the-art strategies
- &verify; Pre-configured Jupyter Notebooks in Google Colab
- &verify; Run all code examples in your net browser — works on Home windows, macOS, and Linux (no dev setting configuration required!)
- &verify; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
- &verify; Straightforward one-click downloads for code, datasets, pre-trained fashions, and so forth.
- &verify; Entry on cellular, laptop computer, desktop, and so forth.
Abstract
On this lesson, we efficiently transformed a PyTorch ResNetV2-50 mannequin to ONNX, examined its efficiency, and validated its correctness utilizing ONNX Runtime. By analyzing each mannequin measurement and inference velocity, we confirmed that ONNX gives vital benefits for AI inference in serverless environments like AWS Lambda.
We discovered that ONNX retains practically the identical measurement as PyTorch (97MB), however we optimized it by stripping pointless metadata. ONNX was 17% sooner for single-image inference and 2x sooner for batch inference (128 photographs). We validated that ONNX predictions matched PyTorch, confirming a profitable conversion.
With the ONNX mannequin totally examined and optimized, we at the moment are able to serve it through an API and containerize it for deployment. Within the subsequent lesson, we are going to construct a FastAPI-based AI inference server that exposes our ONNX mannequin through an API. We’ll additionally containerize it utilizing Docker, guaranteeing a constant runtime setting earlier than deployment to AWS Lambda.
Quotation Info
Singh, V. “Changing a PyTorch Mannequin to ONNX for FastAPI (Docker) Deployment,” PyImageSearch, P. Chugh, S. Huot, A. Sharma, and P. Thakur, eds., 2025, https://pyimg.co/muf0c
@incollection{Singh_2025_converting-pytorch-model-to-onnx-for-fastapi-docker-deployment,
creator = {Vikram Singh},
title = {{Changing a PyTorch Mannequin to ONNX for FastAPI (Docker) Deployment}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Aditya Sharma and Piyush Thakur},
12 months = {2025},
url = {https://pyimg.co/muf0c},
}
To obtain the supply code to this publish (and be notified when future tutorials are printed right here on PyImageSearch), merely enter your e-mail tackle within the kind under!

Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your e-mail tackle under to get a .zip of the code and a FREE 17-page Useful resource Information on Pc Imaginative and prescient, OpenCV, and Deep Studying. Inside you may discover my hand-picked tutorials, books, programs, and libraries that can assist you grasp CV and DL!
The publish Changing a PyTorch Mannequin to ONNX for FastAPI (Docker) Deployment appeared first on PyImageSearch.