

{kind=link}
In my final two posts, I confirmed you find out how to use the new-and-improved desk command to create a desk and find out how to use the accumulate instructions to customise and export the desk. On this submit, I wish to present you find out how to use these instruments to create a desk of descriptive statistics that’s usually referred to as a “basic desk 1”. Our aim is to create the desk within the Microsoft Phrase doc beneath.
Create the essential desk
Let’s start by typing webuse nhanes2l to open the NHANES dataset and use desk to create the desk from my earlier weblog posts. I’ve included the nototal choice to take away the row totals from the desk.
. webuse nhanes2l
(Second Nationwide Well being and Vitamin Examination Survey)
. desk (var) (highbp),
> statistic(fvfrequency intercourse )
> statistic(fvpercent intercourse)
> statistic(imply age)
> statistic(sd age)
> nototal
----------------------------------------------------
| Hypertension
| 0 1
----------------------------+-----------------------
Intercourse=Male |
Issue variable frequency | 2,611 2,304
Issue variable % | 43.70 52.65
Intercourse=Feminine |
Issue variable frequency | 3,364 2,072
Issue variable % | 56.30 47.35
Age (years) |
Imply | 42.16502 54.97281
Commonplace deviation | 16.77157 14.90897
----------------------------------------------------
Recall that desk routinely creates a assortment and that we will kind accumulate dims to view the scale in our assortment.
. accumulate dims
Assortment dimensions
Assortment: Desk
-----------------------------------------
Dimension No. ranges
-----------------------------------------
Format, type, header, label
cmdset 1
colname 3
command 1
highbp 2
end result 4
statcmd 4
var 3
Header, label
intercourse
Fashion solely
border_block 4
cell_type 4
-----------------------------------------
The dimension end result was created by the statistic() choices in our desk command. Let’s kind accumulate label checklist end result to view the degrees and labels of the dimension end result.
. accumulate label checklist end result, all
Assortment: Desk
Dimension: end result
Label: End result
Degree labels:
fvfrequency Issue variable frequency
fvpercent Issue variable %
imply Imply
sd Commonplace deviation
The output tells us that end result has 4 dimensions: fvfrequency, fvpercent, imply, and sd. By default, these ranges are stacked on high of one another in our desk, and I want to place them facet by facet. Let’s use accumulate recode to create two new ranges named column1 and column2. Then, we will place the data from fvfrequency and imply in column1 and the data from fvpercent and sd in column2.
. accumulate recode end result fvfrequency = column1 > fvpercent = column2 > imply = column1 > sd = column2 (18 objects recoded in assortment Desk)
Let’s kind accumulate label checklist end result to view the brand new ranges we created for the dimension end result.
. accumulate label checklist end result, all
Assortment: Desk
Dimension: end result
Label: End result
Degree labels:
column1
column2
fvfrequency Issue variable frequency
fvpercent Issue variable %
imply Imply
sd Commonplace deviation
The output tells us that the dimension end result now contains the degrees column1 and column2 along with the opposite ranges.
Subsequent, we will use accumulate format to alter the format of our desk. The row dimension continues to be var, and the primary column dimension continues to be highbp. We are able to nest column1 and column2 underneath highbp by specifying the column dimension as highbp#end result[column1 column2]. Word the # operator between highbp and end result[column1 column2]. The dimension end result has six ranges, however we wish to embrace solely the degrees column1 and column2. So we enclose the degrees we wish to embrace in brackets.
. accumulate format (var) (highbp#end result[column1 column2])
Assortment: Desk
Rows: var
Columns: highbp#end result[column1 column2]
Desk 1: 3 x 4
--------------------------------------------------------
| Hypertension
| 0 1
| column1 column2 column1 column2
------------+-------------------------------------------
Intercourse=Male | 2611 43.69874 2304 52.65082
Intercourse=Feminine | 3364 56.30126 2072 47.34918
Age (years) | 42.16502 16.77157 54.97281 14.90897
--------------------------------------------------------
Create a bigger desk
Now that we have now the essential format of our desk, let’s add some further variables. We are able to embrace a number of variables in a statistic() possibility. For instance, I’ve included each age and bmi within the first statistic() possibility. I would really like age and bmi to look first in our desk, intercourse, race, and hlthstat to look subsequent, adopted by tcresult, tgresult, and hdresult. The order of the rows is decided by the order of the statistic() choices. I’ve included the nototal possibility once more to scale back the width of the desk on this weblog submit, however I eliminated the nototal choice to create the ultimate desk within the Microsoft Phrase doc beneath.
. desk (var) (highbp), > statistic(imply age bmi) > statistic(sd age bmi) > statistic(fvfrequency intercourse race hlthstat) > statistic(fvpercent intercourse race hlthstat) > statistic(imply tcresult tgresult hdresult) > statistic(sd tcresult tgresult hdresult) > nototal (output omitted)
I’ve used accumulate recode once more to create ranges column1 and column2 for the dimension end result. And I’ve used accumulate format once more to alter the format of our desk.
. accumulate recode end result fvfrequency = column1
> fvpercent = column2
> imply = column1
> sd = column2
(60 objects recoded in assortment Desk)
. accumulate format (var) (highbp#end result[column1 column2])
Assortment: Desk
Rows: var
Columns: highbp#end result[column1 column2]
Desk 1: 15 x 4
------------------------------------------------------------------------
| Hypertension
| 0 1
| column1 column2 column1 column2
----------------------------+-------------------------------------------
Age (years) | 42.16502 16.77157 54.97281 14.90897
Physique mass index (BMI) | 24.20231 4.100279 27.36081 5.332119
Intercourse=Male | 2611 43.69874 2304 52.65082
Intercourse=Feminine | 3364 56.30126 2072 47.34918
Race=White | 5317 88.98745 3748 85.64899
Race=Black | 545 9.121339 541 12.36289
Race=Different | 113 1.891213 87 1.988117
Well being standing=Glorious | 1649 27.65387 758 17.3376
Well being standing=Excellent | 1666 27.93896 925 21.15737
Well being standing=Good | 1572 26.36257 1366 31.24428
Well being standing=Honest | 766 12.84588 904 20.67704
Well being standing=Poor | 310 5.198725 419 9.583715
Serum ldl cholesterol (mg/dL) | 208.7272 47.28725 229.8798 49.58294
Serum triglycerides (mg/dL) | 129.2284 83.92955 166.0427 109.1998
Excessive density lipids (mg/dL) | 49.94449 14.14055 49.21784 14.54068
------------------------------------------------------------------------
Customise the show of numbers
Now we will customise the type of our desk. Let’s start by customizing the show of the numbers. In my earlier posts, we formatted the numbers utilizing the nformat() and sformat() choices in our desk command. We are able to additionally use these choices with accumulate type cell. We might want to apply totally different codecs to totally different cells within the desk, and accumulate type cell makes use of dimensions and ranges to seek advice from cells in a desk.
The primary line within the output beneath is an efficient instance. We want to format the frequencies for our issue variables. Subsequently, we wish to format cells within the desk that meet two situations. The primary situation is that the row dimension var has stage intercourse, race, or hlthstat. The second situation is that the column dimension end result has stage column1. We wish to format solely cells that meet each situations so we use the # operator to specify the intersection of these two situations. And we will use nformat(%6.0fc) to show these cells with no digits to the precise of the decimal and embrace a comma within the 1000’s place.
The second line within the output beneath codecs the chances. These are cells the place var has stage intercourse, race, or hlthstat and the place end result has stage column2. We are able to use nformat(%6.1f) to show these cells with one digit to the precise of the decimal and use sformat(“%s%%”) to put % after the quantity.
The third line within the output beneath codecs the means and customary deviations. These are cells the place var has stage age, bmi, tcresult, tgresult, or hdresult and the place end result has stage column1 or column2. We are able to use nformat(%6.1f) to show these cells with one digit to the precise of the decimal.
The fourth line within the output beneath codecs the usual deviations. These are cells the place var has stage age, bmi, tcresult, tgresult, or hdresult and the place end result has stage column2. We are able to use sformat(“(%s)”) to put parentheses across the quantity.
Lastly, we will kind accumulate preview to view the adjustments to the desk.
. accumulate type cell var[sex race hlthstat]#end result[column1], nformat(%6.0fc)
. accumulate type cell var[sex race hlthstat]#end result[column2],
> nformat(%6.1f) sformat("%s%%")
. accumulate type cell
> var[age bmi tcresult tgresult hdresult]#end result[column1 column2],
> nformat(%6.1f)
. accumulate type cell
> var[age bmi tcresult tgresult hdresult]#end result[column2],
> sformat("(%s)")
. accumulate preview
--------------------------------------------------------------------
| Hypertension
| 0 1
| column1 column2 column1 column2
----------------------------+---------------------------------------
Age (years) | 42.2 (16.8) 55.0 (14.9)
Physique mass index (BMI) | 24.2 (4.1) 27.4 (5.3)
Intercourse=Male | 2,611 43.7% 2,304 52.7%
Intercourse=Feminine | 3,364 56.3% 2,072 47.3%
Race=White | 5,317 89.0% 3,748 85.6%
Race=Black | 545 9.1% 541 12.4%
Race=Different | 113 1.9% 87 2.0%
Well being standing=Glorious | 1,649 27.7% 758 17.3%
Well being standing=Excellent | 1,666 27.9% 925 21.2%
Well being standing=Good | 1,572 26.4% 1,366 31.2%
Well being standing=Honest | 766 12.8% 904 20.7%
Well being standing=Poor | 310 5.2% 419 9.6%
Serum ldl cholesterol (mg/dL) | 208.7 (47.3) 229.9 (49.6)
Serum triglycerides (mg/dL) | 129.2 (83.9) 166.0 (109.2)
Excessive density lipids (mg/dL) | 49.9 (14.1) 49.2 (14.5)
--------------------------------------------------------------------
Customise the column labels
Subsequent, let’s customise the column labels in our desk utilizing instructions that we realized in my second weblog submit. The primary line within the output beneath makes use of accumulate label dim to alter the label of the dimension highbp to “Hypertension”. The second line within the output beneath makes use of accumulate label ranges to label the extent 0 “No” and the extent 1 “Sure”.
The third line within the output beneath makes use of accumulate type header to cover the degrees of dimension end result within the column header. This removes column1 and column2 from the column header.
. accumulate label dim highbp "Hypertension", modify
. accumulate label ranges highbp 0 "No" 1 "Sure"
. accumulate type header end result, stage(disguise)
. accumulate preview
---------------------------------------------------------------
| Hypertension
| No Sure
----------------------------+----------------------------------
Age (years) | 42.2 (16.8) 55.0 (14.9)
Physique mass index (BMI) | 24.2 (4.1) 27.4 (5.3)
Intercourse=Male | 2,611 43.7% 2,304 52.7%
Intercourse=Feminine | 3,364 56.3% 2,072 47.3%
Race=White | 5,317 89.0% 3,748 85.6%
Race=Black | 545 9.1% 541 12.4%
Race=Different | 113 1.9% 87 2.0%
Well being standing=Glorious | 1,649 27.7% 758 17.3%
Well being standing=Excellent | 1,666 27.9% 925 21.2%
Well being standing=Good | 1,572 26.4% 1,366 31.2%
Well being standing=Honest | 766 12.8% 904 20.7%
Well being standing=Poor | 310 5.2% 419 9.6%
Serum ldl cholesterol (mg/dL) | 208.7 (47.3) 229.9 (49.6)
Serum triglycerides (mg/dL) | 129.2 (83.9) 166.0 (109.2)
Excessive density lipids (mg/dL) | 49.9 (14.1) 49.2 (14.5)
---------------------------------------------------------------
Customise the row labels
Subsequent, let’s customise the row labels in our desk. The primary line within the output beneath makes use of accumulate type row to alter a number of issues. The argument stack stacks the classes of the degrees on high of one another fairly than facet by facet. For instance, Male and Feminine are positioned beneath the extent label Intercourse. The nobinder possibility removes the = that beforehand appeared between every stage and its classes. And the spacer possibility provides an area between ranges created with totally different statistic() choices.
The second line within the output beneath makes use of accumulate type cell to take away the vertical line from the desk. Recall from my final submit that the vertical line is a border alongside the precise facet of the primary column within the desk. The choice border(proper, sample(nil)) adjustments the road sample to nil.
. accumulate type row stack, nobinder spacer
. accumulate type cell border_block, border(proper, sample(nil))
. accumulate preview
-------------------------------------------------------------
Hypertension
No Sure
-------------------------------------------------------------
Age (years) 42.2 (16.8) 55.0 (14.9)
Physique mass index (BMI) 24.2 (4.1) 27.4 (5.3)
Intercourse
Male 2,611 43.7% 2,304 52.7%
Feminine 3,364 56.3% 2,072 47.3%
Race
White 5,317 89.0% 3,748 85.6%
Black 545 9.1% 541 12.4%
Different 113 1.9% 87 2.0%
Well being standing
Glorious 1,649 27.7% 758 17.3%
Excellent 1,666 27.9% 925 21.2%
Good 1,572 26.4% 1,366 31.2%
Honest 766 12.8% 904 20.7%
Poor 310 5.2% 419 9.6%
Serum ldl cholesterol (mg/dL) 208.7 (47.3) 229.9 (49.6)
Serum triglycerides (mg/dL) 129.2 (83.9) 166.0 (109.2)
Excessive density lipids (mg/dL) 49.9 (14.1) 49.2 (14.5)
-------------------------------------------------------------
Export the desk to a Microsoft Phrase doc
I’m pleased with the format of our desk, and I’m able to export it to a Microsoft Phrase doc. Let’s use putdocx so as to add a title, part header, and a few textual content to our doc earlier than we insert the desk.
Subsequent, we will use accumulate type putdocx so as to add a title to our desk. By default, Microsoft Phrase will stretch our desk to suit the width of the doc. We are able to use the format(autofitcontents) choice to retain the unique width of the desk.
Lastly, we will use putdocx accumulate to export our desk to the doc. I’ve used a purple font within the code block beneath to emphasise the traces that customise and export the graph.
Word that the graph within the doc beneath contains columns labeled “Complete”. I eliminated these columns within the examples above in order that the tables wouldn’t exceed the default width for this weblog submit. I’ve merely eliminated the nototals possibility from the desk command so as to add the “Complete” columns to the desk within the Microsoft Phrase doc.
putdocx start
putdocx paragraph, type(Title)
putdocx textual content ("Hypertension in america")
putdocx paragraph, type(Heading1)
putdocx textual content ("The Nationwide Well being and Vitamin Examination Survey (NHANES)")
putdocx paragraph
putdocx textual content ("Hypertension is a serious explanation for morbidity and mortality in ")
putdocx textual content ("america. This report will discover the predictors ")
putdocx textual content ("of hypertension utilizing the NHANES dataset.")
accumulate type putdocx, format(autofitcontents) ///
title("Desk 1: Descriptive Statistics by Hypertension Standing")
putdocx accumulate
putdocx save MyTable1.docx, change
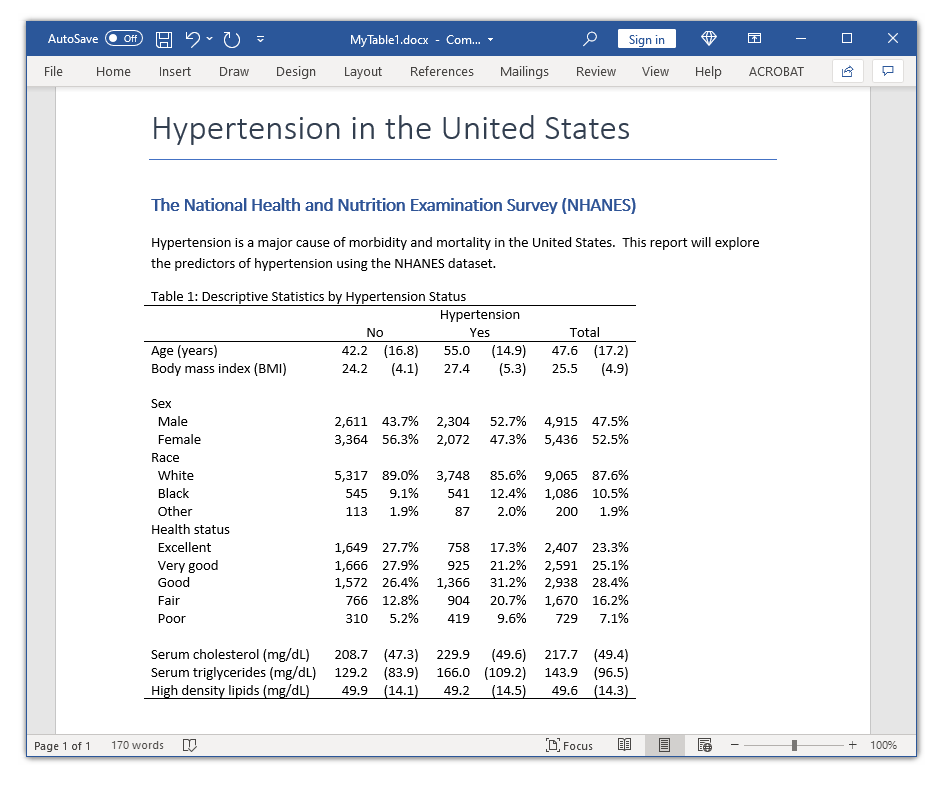
Conclusion
On this weblog submit, we used most of the instruments we realized about in my final two posts. We used desk with the statistic() choice to create our primary desk, then used accumulate label to switch the labels of dimensions and ranges, accumulate type row to customise the row labels, and accumulate type cell to take away the vertical line. And we used accumulate type putdocx and putdocx accumulate to customise and export our desk to a Microsoft Phrase doc.
We additionally realized find out how to use some new accumulate instructions on this submit. We realized find out how to use accumulate recode to recode ranges of a dimension, find out how to use accumulate format to alter the format of our desk, and find out how to use accumulate type cell to format the numbers in our tables.
I’ll present you find out how to create a desk of statistical exams in my subsequent submit.