

{kind=link}
As pc imaginative and prescient researchers, we consider that each pixel can inform a narrative. Nevertheless, there appears to be a author’s block settling into the sector on the subject of coping with massive photographs. Giant photographs are not uncommon—the cameras we stock in our pockets and people orbiting our planet snap photos so massive and detailed that they stretch our present greatest fashions and {hardware} to their breaking factors when dealing with them. Usually, we face a quadratic improve in reminiscence utilization as a operate of picture measurement.
Right this moment, we make one in all two sub-optimal decisions when dealing with massive photographs: down-sampling or cropping. These two strategies incur important losses within the quantity of knowledge and context current in a picture. We take one other take a look at these approaches and introduce $x$T, a brand new framework to mannequin massive photographs end-to-end on modern GPUs whereas successfully aggregating international context with native particulars.
Structure for the $x$T framework.
Why Hassle with Huge Pictures Anyway?
Why trouble dealing with massive photographs in any case? Image your self in entrance of your TV, watching your favourite soccer group. The sector is dotted with gamers throughout with motion occurring solely on a small portion of the display at a time. Would you be satisified, nonetheless, if you happen to may solely see a small area round the place the ball at present was? Alternatively, would you be satisified watching the sport in low decision? Each pixel tells a narrative, regardless of how far aside they’re. That is true in all domains out of your TV display to a pathologist viewing a gigapixel slide to diagnose tiny patches of most cancers. These photographs are treasure troves of knowledge. If we are able to’t totally discover the wealth as a result of our instruments can’t deal with the map, what’s the purpose?

Sports activities are enjoyable when you already know what is going on on.
That’s exactly the place the frustration lies in the present day. The larger the picture, the extra we have to concurrently zoom out to see the entire image and zoom in for the nitty-gritty particulars, making it a problem to know each the forest and the timber concurrently. Most present strategies drive a alternative between shedding sight of the forest or lacking the timber, and neither choice is nice.
How $x$T Tries to Repair This
Think about attempting to unravel a large jigsaw puzzle. As an alternative of tackling the entire thing directly, which might be overwhelming, you begin with smaller sections, get take a look at every bit, after which determine how they match into the larger image. That’s principally what we do with massive photographs with $x$T.
$x$T takes these gigantic photographs and chops them into smaller, extra digestible items hierarchically. This isn’t nearly making issues smaller, although. It’s about understanding every bit in its personal proper after which, utilizing some intelligent methods, determining how these items join on a bigger scale. It’s like having a dialog with every a part of the picture, studying its story, after which sharing these tales with the opposite components to get the complete narrative.
Nested Tokenization
On the core of $x$T lies the idea of nested tokenization. In easy phrases, tokenization within the realm of pc imaginative and prescient is akin to chopping up a picture into items (tokens) {that a} mannequin can digest and analyze. Nevertheless, $x$T takes this a step additional by introducing a hierarchy into the method—therefore, nested.
Think about you’re tasked with analyzing an in depth metropolis map. As an alternative of attempting to absorb all the map directly, you break it down into districts, then neighborhoods inside these districts, and at last, streets inside these neighborhoods. This hierarchical breakdown makes it simpler to handle and perceive the small print of the map whereas preserving monitor of the place the whole lot matches within the bigger image. That’s the essence of nested tokenization—we break up a picture into areas, every which could be break up into additional sub-regions relying on the enter measurement anticipated by a imaginative and prescient spine (what we name a area encoder), earlier than being patchified to be processed by that area encoder. This nested strategy permits us to extract options at totally different scales on a neighborhood stage.
Coordinating Area and Context Encoders
As soon as a picture is neatly divided into tokens, $x$T employs two forms of encoders to make sense of those items: the area encoder and the context encoder. Every performs a definite function in piecing collectively the picture’s full story.
The area encoder is a standalone “native skilled” which converts impartial areas into detailed representations. Nevertheless, since every area is processed in isolation, no data is shared throughout the picture at massive. The area encoder could be any state-of-the-art imaginative and prescient spine. In our experiments we’ve got utilized hierarchical imaginative and prescient transformers equivalent to Swin and Hiera and likewise CNNs equivalent to ConvNeXt!
Enter the context encoder, the big-picture guru. Its job is to take the detailed representations from the area encoders and sew them collectively, guaranteeing that the insights from one token are thought-about within the context of the others. The context encoder is mostly a long-sequence mannequin. We experiment with Transformer-XL (and our variant of it referred to as Hyper) and Mamba, although you could possibly use Longformer and different new advances on this space. Despite the fact that these long-sequence fashions are usually made for language, we display that it’s attainable to make use of them successfully for imaginative and prescient duties.
The magic of $x$T is in how these parts—the nested tokenization, area encoders, and context encoders—come collectively. By first breaking down the picture into manageable items after which systematically analyzing these items each in isolation and in conjunction, $x$T manages to keep up the constancy of the unique picture’s particulars whereas additionally integrating long-distance context the overarching context whereas becoming huge photographs, end-to-end, on modern GPUs.
Outcomes
We consider $x$T on difficult benchmark duties that span well-established pc imaginative and prescient baselines to rigorous massive picture duties. Significantly, we experiment with iNaturalist 2018 for fine-grained species classification, xView3-SAR for context-dependent segmentation, and MS-COCO for detection.
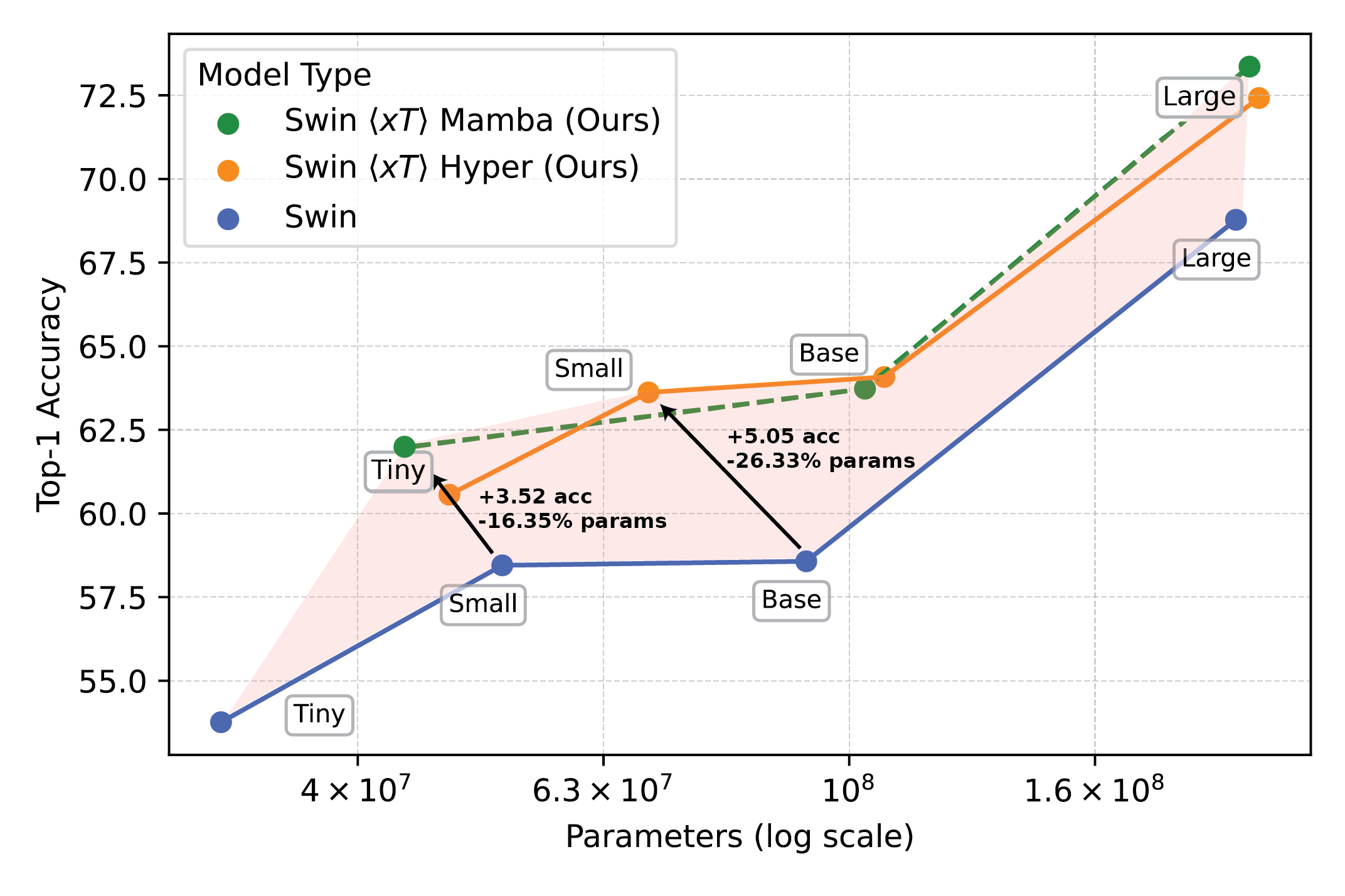
Highly effective imaginative and prescient fashions used with $x$T set a brand new frontier on downstream duties equivalent to fine-grained species classification.
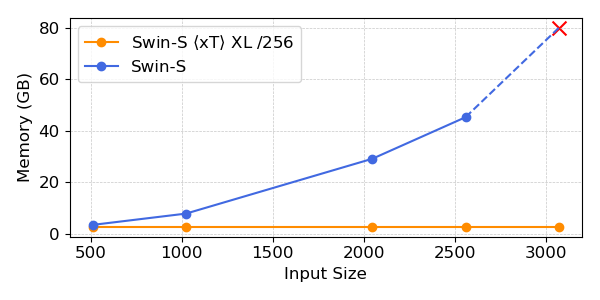
Our experiments present that $x$T can obtain increased accuracy on all downstream duties with fewer parameters whereas utilizing a lot much less reminiscence per area than state-of-the-art baselines*. We’re in a position to mannequin photographs as massive as 29,000 x 25,000 pixels massive on 40GB A100s whereas comparable baselines run out of reminiscence at solely 2,800 x 2,800 pixels.
Highly effective imaginative and prescient fashions used with $x$T set a brand new frontier on downstream duties equivalent to fine-grained species classification.
*Relying in your alternative of context mannequin, equivalent to Transformer-XL.
Why This Issues Extra Than You Assume
This strategy isn’t simply cool; it’s mandatory. For scientists monitoring local weather change or docs diagnosing illnesses, it’s a game-changer. It means creating fashions which perceive the complete story, not simply bits and items. In environmental monitoring, for instance, having the ability to see each the broader modifications over huge landscapes and the small print of particular areas can assist in understanding the larger image of local weather impression. In healthcare, it may imply the distinction between catching a illness early or not.
We aren’t claiming to have solved all of the world’s issues in a single go. We hope that with $x$T we’ve got opened the door to what’s attainable. We’re entering into a brand new period the place we don’t need to compromise on the readability or breadth of our imaginative and prescient. $x$T is our massive leap in the direction of fashions that may juggle the intricacies of large-scale photographs with out breaking a sweat.
There’s much more floor to cowl. Analysis will evolve, and hopefully, so will our potential to course of even greater and extra complicated photographs. In reality, we’re engaged on follow-ons to $x$T which is able to broaden this frontier additional.
In Conclusion
For a whole remedy of this work, please try the paper on arXiv. The undertaking web page accommodates a hyperlink to our launched code and weights. For those who discover the work helpful, please cite it as beneath:
@article{xTLargeImageModeling,
title={xT: Nested Tokenization for Bigger Context in Giant Pictures},
creator={Gupta, Ritwik and Li, Shufan and Zhu, Tyler and Malik, Jitendra and Darrell, Trevor and Mangalam, Karttikeya},
journal={arXiv preprint arXiv:2403.01915},
12 months={2024}
}