

{kind=link}
By: Vivek Krishnamoorthy, Aacashi Nawyndder and Udisha Alok
Ever want you had a crystal ball for the monetary markets? Whereas we won’t fairly do this, regression is a brilliant great tool that helps us discover patterns and relationships hidden in information – it is like being an information detective!
The most typical start line is linear regression, which is mainly about drawing one of the best straight line by information factors to see how issues are related. Easy, proper?
In Half 1 of this collection, we explored methods to make these line-based fashions even higher, tackling issues like curvy relationships (Polynomial Regression) and messy information with too many variables (utilizing Ridge and Lasso Regression). We discovered easy methods to refine these linear predictions.
However what if a line (even a curvy one) simply does not match? Or what if it’s essential to predict one thing completely different, like a “sure” or “no”?
Prepare for Half 2, my good friend! The place we enterprise past the linear world and discover an interesting set of regression methods designed for various sorts of issues:
- Logistic Regression: For predicting chances and binary outcomes (Sure/No).
- Quantile Regression: For understanding relationships at completely different factors within the information distribution, not simply the typical (nice for danger evaluation!).
- Determination Tree Regression: An intuitive flowchart strategy for complicated, non-linear patterns.
- Random Forest Regression: Harnessing the “knowledge of the gang” by combining a number of choice timber for accuracy and stability.
- Assist Vector Regression (SVR): A strong technique utilizing “margins” to deal with complicated relationships, even in excessive dimensions.
Let’s dive into these highly effective instruments and see how they’ll unlock new insights from monetary information!
Stipulations
Hey there! Earlier than we get into the good things, it helps to be aware of just a few key ideas. You possibly can nonetheless comply with alongside intuitively, however brushing up on these will provide you with a significantly better understanding. Right here’s what to take a look at:
1. Statistics and Chance
Know the necessities—imply, variance, correlation, and chance distributions. New to this? Chance Buying and selling is a good intro.
2. Linear Algebra Fundamentals
Fundamentals like matrices and vectors are tremendous helpful, particularly for methods like Principal Part Regression.
3. Regression Fundamentals
Get comfortable with linear regression and its assumptions. Linear Regression in Finance is a strong start line.
4. Monetary Market Information
Phrases like inventory returns, volatility, and market sentiment will come up loads. Statistics for Monetary Markets may also help you sweep up.
5. Discover Half 1 of This Collection
Take a look at Half 1 for an outline of Polynomial, Ridge, Lasso, Elastic Web, and LARS. It’s not obligatory, however it supplies glorious context for various regression varieties.
When you’re good with these, you’ll be all set to dive deeper into how regression methods reveal insights in finance. Let’s get began!
What Precisely is Regression Evaluation?
At its core, regression evaluation fashions the connection between a dependent variable (the result we need to predict) and a number of unbiased variables (predictors).
Consider it as determining the connection between various things – for example, how does an organization’s income (the result) relate to how a lot they spend on promoting (the predictor)? Understanding these hyperlinks helps you make educated guesses about future outcomes based mostly on what you recognize.
When that relationship appears like a straight line on a graph, we name it linear regression – good and easy!
What Makes These Fashions ‘Non-Linear’?
Good query! In Half 1, we talked about that ‘linear’ in regression refers to how the mannequin’s coefficients are mixed.
Non-linear fashions, like those we’re exploring right here, break that rule. Their underlying equations or buildings do not simply add up coefficients multiplied by predictors in a easy means. Take into consideration Logistic Regression utilizing that S-shaped curve (sigmoid operate) to squash outputs between 0 and 1, or Determination Bushes making splits based mostly on situations moderately than a easy equation, or SVR utilizing ‘kernels’ to deal with complicated relationships in doubtlessly greater dimensions.
These strategies basically work otherwise from linear fashions, permitting them to seize patterns and deal with issues (like classification or modelling particular information segments) that linear fashions usually cannot.
Logistic (or Logit) regression
You employ Logistic regression when the dependent variable (right here, a dichotomous variable) is binary (consider it as a “sure” or “no” consequence, like a inventory going up or down). It helps predict the binary consequence of an incidence based mostly on the given information.
It’s a non-linear mannequin that offers a logistic curve with values restricted to between 0 and 1. This chance is then in comparison with a threshold worth of 0.5 to categorise the information. So, if the chance for a category is greater than 0.5, we label it as 1; in any other case, it’s 0.
This mannequin is mostly used to predict the efficiency of shares.
Notice: You cannot use linear regression right here as a result of it might give values outdoors the 0 to 1 vary. Additionally, the dependent variable can take solely two values right here, so the residuals received’t be usually distributed concerning the predicted line.
Wish to be taught extra? Take a look at this weblog for extra on logistic regression and easy methods to use Python code to foretell inventory motion.
Quantile Regression: Understanding Relationships Past the Common
Conventional linear regression fashions predict the imply of a dependent variable based mostly on unbiased variables. Nevertheless, monetary time collection information usually comprise skewness and outliers, making linear regression unsuitable.
To resolve this drawback, Koenker and Bassett (1978) launched quantile regression. As a substitute of modeling simply the imply, it helps us see the connection between variables at completely different factors (quantiles and percentiles) within the dependent variable’s distribution, equivalent to:
- tenth percentile (low good points/losses)
- fiftieth percentile (median returns)
- 99th percentile (excessive good points/losses)
It estimates completely different quantiles (like medians or quartiles) of the dependent variables for the given unbiased variables, as a substitute of simply the imply. We name these conditional quantiles.
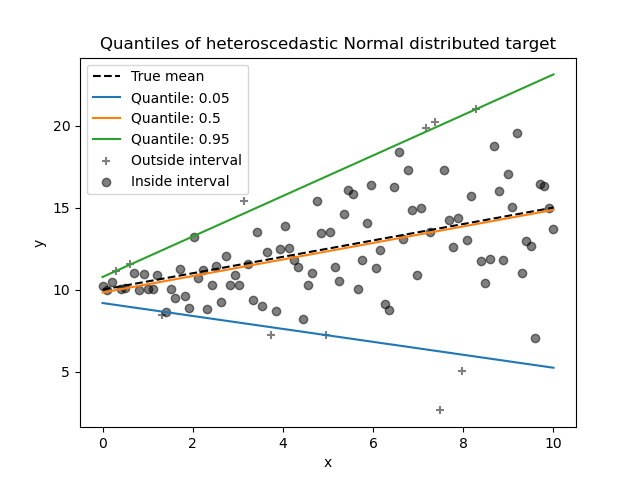
Like OLS regression coefficients, which present the adjustments from one-unit adjustments of the predictor variables, quantile regression coefficients present the adjustments within the specified quantile from one-unit adjustments within the predictor variables.
Benefits:
- Robustness to Outliers: In line with Lim et al. (2020), common linear regression assumes errors within the information are usually distributed, however this is not dependable when you’ve gotten outliers or excessive values (“fats tails”). Quantile regression handles outliers higher as a result of it focuses on minimizing absolute errors, not the squared ones like common regression. This fashion the affect of utmost values is diminished, offering extra dependable estimates in datasets that aren’t actually “nicely behaved” (with heavy tails or skewed distributions)
- Estimating Conditional Median: The conditional median is estimated utilizing the median estimator, which minimizes the sum of absolute errors.
- Dealing with Heteroskedasticity: OLS assumes fixed variance of errors (homoskedasticity), however that is usually unrealistic. Quantile regression permits for various error variances, making it efficient when predictor variables affect completely different components of the response variable’s distribution (Koenker & Bassett, 1978).
Let’s take a look at an instance to higher perceive how quantile regression works:
For instance you are attempting to know how the general “temper” of the market (measured by a sentiment index) impacts the each day returns of a selected inventory. Conventional regression would let you know the typical affect of a change in sentiment on the typical inventory return.
However what when you’re notably excited about excessive actions? Quantile regression is used right here:
- Wanting on the tenth percentile: You possibly can use quantile regression to see how a adverse shift in market sentiment impacts the worst 10% of potential each day returns (the massive losses). It’d present that adverse sentiment has a a lot stronger adverse affect throughout these excessive downturns than it does on common.
- Wanting on the ninetieth percentile: Equally, you would see how optimistic sentiment impacts the greatest 10% of each day returns (the massive good points). It’d reveal that optimistic sentiment has a unique (presumably bigger or smaller) affect on these important upward swings in comparison with the typical.
- Wanting on the fiftieth percentile (median): You can even see the affect of sentiment on the standard each day return (the median), which is likely to be completely different from the impact on the typical if the return distribution is skewed.
So, as a substitute of only one common impact, quantile regression offers you a extra full image of how market sentiment influences completely different components of the inventory’s return distribution, particularly the possibly dangerous excessive losses. Isn’t that nice?
Determination Bushes Regression: The Flowchart Method
Think about attempting to foretell a numerical worth – like the value of one thing or an organization’s future income. A Determination Tree provides an intuitive means to do that, working like a flowchart or a sport of ‘sure/no’ questions.
A choice tree is split into smaller and smaller subsets based mostly on sure situations associated to the predictor variables. Consider it like this:
Determination timber begin together with your whole dataset and progressively splits it into smaller and smaller subsets on the nodes, thereby making a tree-like construction. Every of the nodes the place the information is break up based mostly on a situation is known as an inside/break up node, and the ultimate subsets are referred to as the terminal/leaf nodes.
In finance, choice timber could also be used for classification issues like predicting whether or not the costs of a monetary instrument will go up or down.

Determination Tree Regression is after we use a choice tree to foretell steady values (like the value of a home or temperature) as a substitute of classes (like predicting sure/no or up/down).
Right here’s the way it works in regression:
- The tree asks a collection of questions based mostly on the enter options (like “Is sq. footage > 1500?”).
- Based mostly on the solutions, the information level strikes down the tree till it reaches a leaf.
- In that leaf, the prediction is the common (or generally the median) of the particular values from the coaching information that additionally landed there.
So, the tree splits the information into teams, and every group will get a set quantity because the prediction.
Issues to Watch Out For:
- Overfitting: Determination timber can get too detailed and match the coaching information too completely, making them carry out poorly on new, unseen information.
- Instability: Small adjustments within the coaching information can generally result in considerably completely different tree buildings. (Strategies like Random Forests and Gradient Boosting usually assist with this).
You could have a full description of the mannequin on this weblog and its use in buying and selling on this weblog.
To be taught extra about choice timber in buying and selling take a look at this Quantra course.
Let’s see a state of affairs the place this is likely to be a great tool:
Think about you are attempting to foretell an organization’s gross sales income for the subsequent quarter. You could have information on its previous efficiency and components like: advertising spend within the present quarter, variety of salespeople, the corporate’s trade sector (e.g., Tech, Retail, Healthcare), and so forth.
The tree would possibly ask:
“Advertising and marketing spend > $500k?” If sure, “Trade = Tech?”. Based mostly on the trail taken, you land on a leaf.
The prediction for a brand new firm following that path could be the typical income of all previous firms that fell into that very same leaf (e.g., the typical income for tech firms with excessive advertising spend).
Random forest regression: Knowledge of the Crowd for Predictions
Keep in mind how particular person Determination Bushes can generally be a bit unstable or would possibly overfit the coaching information? What if we might harness the facility of many choice timber as a substitute of counting on only one?
That is the concept behind Random Forest Regression!
It is an “ensemble” technique, which means it combines a number of fashions (on this case, choice timber) to realize higher efficiency than any single one might alone. You possibly can consider it utilizing the “knowledge of the gang” precept: as a substitute of asking one professional, you ask many, barely completely different specialists and mix their insights. Usually, Random Forests carry out considerably higher than particular person choice timber (Breiman, 2001).
How does the forest get “random”?
The “random” a part of Random Forest comes from two key methods used when constructing the person timber:
- Random Information Subsets (Bootstrapping): Every tree within the forest is educated on a barely completely different random pattern of the unique coaching information. This pattern will be chosen “with alternative” (which means some information factors is likely to be chosen a number of instances, and a few is likely to be not noted for that particular tree). This ensures every tree sees a barely completely different perspective of the information.
- Random Function Subsets: When deciding easy methods to break up the information at every step inside a tree, the algorithm can solely take into account a random choice of the enter options, not all of them. This stops one or two highly effective options from dominating all of the timber and encourages range.
Making Predictions (Regression = Averaging)
To foretell a price for brand new information, you run it by each tree within the forest. Every tree offers its personal prediction. The Random Forest’s last prediction is solely the common of all these particular person tree predictions. This averaging smooths issues out and makes the mannequin far more secure.

Picture illustration of a Random forest regressor: Supply
Why Use Random Forest Regression?
- Excessive Accuracy: Typically supplies very correct predictions.
- Robustness: Much less liable to overfitting in comparison with single choice timber and handles outliers moderately nicely. (Breiman, L. , 2001)
- Non-linearity: Simply captures complicated, non-linear relationships.
- Function Significance: Can present estimates of which predictors are most essential.
Issues to Contemplate:
- Interpretability: It acts extra like a “black field.” It is more durable to know precisely why it made a particular prediction in comparison with visualizing a single choice tree.
- Computation: Coaching many timber will be computationally intensive and require extra reminiscence.
Take a look at this submit if you wish to be taught extra about random forests and the way they can be utilized in buying and selling.
Assume we’d go away you hanging? No means!
Right here’s an instance that will help you higher perceive how random forests work in apply:
You need to predict how a lot a inventory’s value will swing (its volatility) subsequent month, utilizing information like latest volatility, buying and selling quantity, and market concern (VIX index).
A single choice tree would possibly latch onto a particular sample previously information and provides a jumpy prediction. A Random Forest strategy is extra strong:
It builds lots of of timber. Every tree sees barely completely different historic information and considers completely different characteristic combos at every break up. Every tree estimates the volatility. The ultimate prediction is the typical of all these estimates, giving a extra secure and dependable forecast of future volatility than one tree alone might present.
Assist vector regression (SVR): Regression Inside a ‘Margin’ of Error
You is likely to be aware of Assist Vector Machines (SVM) for classification. Assist Vector Regression (SVR) takes the core concepts of SVM and applies them to regression duties – that’s, predicting steady numerical values.
SVR approaches regression a bit otherwise than many different strategies. Whereas strategies like commonplace linear regression attempt to decrease the error between the anticipated and precise values for all information factors, SVR has a unique philosophy.
The Epsilon (ε) Insensitive Tube:
Think about you are attempting to suit a line (or curve) by your information factors. SVR tries to discover a “tube” or “road” round this line with a sure width, outlined by a parameter referred to as epsilon (ε). The purpose is to suit as many information factors as attainable inside this tube.

Picture illustration of Assist vector regression: Supply
Here is the important thing thought: For any information factors that fall inside this ε-tube, SVR considers the prediction “ok” and ignores their error. It solely begins penalizing errors for factors that fall outdoors the tube. This makes SVR much less delicate to small errors in comparison with strategies that attempt to get each level good. The regression line (or hyperplane in greater dimensions) runs down the center of this tube.
Dealing with Curves (Non-Linearity):
What if the connection between your predictors and the goal variable is not straight? SVR makes use of a “kernel trick”. That is like projecting the information right into a higher-dimensional area the place a posh, curvy relationship would possibly appear like an easier straight line (or flat airplane). By discovering one of the best “tube” on this greater dimension, SVR can successfully mannequin non-linear patterns. Frequent kernels embody linear, polynomial, and RBF (Radial Foundation Operate). Your best option depends upon the information.
Execs:
- Efficient in high-dimensional areas.
- Can mannequin non-linear relationships utilizing kernels.
- The ε-margin provides some robustness to small errors/outliers (Muthukrishnan & Jamila, 2020).
Cons:
- Could be computationally gradual on massive datasets.
- Efficiency is delicate to parameter tuning (selecting ε, a price parameter C, and the proper kernel).
- Interpretability will be much less direct than linear regression.
The reason for the entire mannequin will be discovered right here.
And if you wish to be taught extra about how assist vector machines can be utilized in buying and selling, make sure to take a look at this weblog, my good friend!
By now, you most likely understand how this works, so let’s take a look at a real-life instance that makes use of SVR:
Take into consideration predicting the value of a inventory choice (like a name or put). Choice costs rely upon a number of complicated, non-linear components: the underlying inventory’s value, time left till expiration, anticipated future volatility (implied volatility), rates of interest, and so forth.
SVR (particularly with a non-linear kernel like RBF) is appropriate for this. It may possibly seize these complicated relationships utilizing the kernel trick. The ε-tube focuses on getting the prediction inside a suitable small vary (e.g., predicting the value +/- 5 cents), moderately than stressing about tiny deviations for each single choice.
Abstract
|
Regression Mannequin |
One-Line Abstract |
One-Line Use Case |
|
Logistic Regression |
Predicts the chance of a binary consequence. |
Predicting whether or not a inventory will go up or down. |
|
Quantile Regression |
Fashions relationships at completely different quantiles of the dependent variable’s distribution. |
Understanding how market sentiment impacts excessive inventory value actions. |
|
Determination Bushes Regression |
Predicts steady values by partitioning information into subsets based mostly on predictor variables. |
Predicting an organization’s gross sales income based mostly on varied components. |
|
Random Forest Regression |
Improves prediction accuracy by averaging predictions from a number of choice timber. |
Predicting the volatility of a inventory. |
|
Assist Vector Regression (SVR) |
Predicts steady values by discovering a “tube” that most closely fits the information. |
Predicting choice costs, which rely upon a number of non-linearly associated components. |
Conclusion
And that concludes our tour by the extra numerous landscapes of regression! We have seen how Logistic Regression helps us deal with binary predictions, how Quantile Regression offers us insights past the typical, particularly for danger, and the way Determination Bushes and Random Forests supply intuitive but highly effective methods to mannequin complicated, non-linear relationships. Lastly, Assist Vector Regression supplies a singular, margin-based strategy sensible even in high-dimensional areas.
From the refined linear fashions in Half 1 to the various methods explored right here, you now have a much wider regression toolkit at your disposal. Every mannequin has its strengths and is suited to completely different monetary questions and information challenges.
The important thing takeaway? Regression will not be a one-size-fits-all resolution. Understanding the nuances of various methods permits you to select the proper device for the job, resulting in extra insightful evaluation and highly effective predictive fashions.
And as you proceed studying my good friend, don’t simply cease at idea. Maintain exploring, hold working towards with actual information, and hold refining your abilities. Completely happy modeling!
Maybe you are eager on an entire, holistic understanding of regression utilized on to buying and selling? In that case, take a look at this Quantra course.
In case you’re severe about taking your abilities to the subsequent degree, take into account QuantInsti’s EPAT program—a strong path to mastering monetary algorithmic buying and selling.
With the proper coaching and steerage from trade specialists, it may be attainable so that you can be taught it in addition to Statistics & Econometrics, Monetary Computing & Know-how, and Algorithmic & Quantitative Buying and selling. These and varied points of Algorithmic buying and selling are lined on this algo buying and selling course. EPAT equips you with the required ability units to construct a promising profession in algorithmic buying and selling. Make sure you test it out.
References
- Koenker, R., & Bassett, G. (1978). Regression quantiles. Econometrica, 46(1), 33–50. https://doi.org/10.2307/1913643
- Lim, D., Park, B., Nott, D., Wang, X., & Choi, T. (2020). Sparse sign shrinkage and outlier detection in high-dimensional quantile regression with variational Bayes. Statistica Sinica, 13(2), 1. https://archive.intlpress.com/web site/pub/recordsdata/_fulltext/journals/sii/2020/0013/0002/SII-2020-0013-0002-a008.pdf
- Breiman, L. (2001). Random forests. Machine Studying, 45(1), 5–32. https://hyperlink.springer.com/article/10.1023/A:1010933404324
- Muthukrishnan, R., & Jamila, S. M. (2020). Predictive modeling utilizing assist vector regression. Worldwide Journal of Scientific & Know-how Analysis, 9(2), 4863–4875. Retrieved from https://www.ijstr.org/final-print/feb2020/Predictive-Modeling-Utilizing-Assist-Vector-Regression.pdf
Disclaimer: All investments and buying and selling within the inventory market contain danger. Any choice to position trades within the monetary markets, together with buying and selling in inventory or choices or different monetary devices, is a private choice that ought to solely be made after thorough analysis, together with a private danger and monetary evaluation and the engagement {of professional} help to the extent you consider needed. The buying and selling methods or associated data talked about on this article is for informational functions solely.