

{kind=link}
Image this: a compliance officer wants a particular clause throughout an audit, an legal professional wants contract phrases whereas a consumer waits on the telephone, or a finance analyst wants numbers from final quarter’s report earlier than a gathering that begins in 10 minutes. In every case, ready for a scheduled job to complete just isn’t sensible. You want on-demand entry to the textual content inside your PDFs.
On this submit, you’ll construct a server that extracts textual content from PDF recordsdata in Amazon S3 in actual time. This protocol-based method gives programmatic doc entry. You’ll stroll by way of the structure, arrange the server, and run interactive doc queries. Alongside the best way, you’ll examine this method with Amazon Textract so you may resolve which software matches your workload.
We constructed this answer after working with a number of groups who shared the identical frustration: their paperwork lived in Amazon S3, however getting textual content out of them on demand meant both writing customized scripts or ready on batch pipelines. This MCP server method sits in between, providing you with interactive entry with minimal setup. Interactive PDF textual content extraction from Amazon S3 offers you real-time solutions out of your paperwork with out batch pipelines or heavy infrastructure.
This MCP-based choice works effectively for text-based PDFs in improvement and proof of idea settings. For advanced doc processing like optical character recognition (OCR), kind extraction, and structure evaluation, Amazon Textract stays the beneficial alternative.
Who advantages from this method
This answer matches a number of widespread roles. If these situations sound like your day-to-day, learn on.
Compliance and authorized groups: Throughout a time-sensitive evaluation, you could find a particular clause buried in a 200-page coverage doc or contract. Looking manually takes too lengthy. With this answer, you ask a query in pure language and get the related passage again in seconds.
Monetary providers groups: Throughout an audit session, you want fast entry to the precise wording of an inside threat coverage or regulatory submitting. This answer helps you to pull that data instantly out of your Amazon S3 doc repository with out leaving your terminal.
Government groups: Throughout strategic planning conferences, you may question a PDF on the spot when somebody asks a few knowledge level from final quarter’s earnings report. No flipping by way of printed copies or ready for somebody to look it up after the assembly.
These situations share a couple of widespread traits: they contain real-time data wants the place batch processing is simply too gradual, text-based PDF paperwork with normal formatting, price sensitivity in improvement and proof of idea environments, and integration necessities with current AWS workflows and tooling.
Amazon Textract is a totally managed AWS AI service purpose-built for doc processing at scale. It handles scanned pages, handwriting, and multi-column layouts. Select Amazon Textract whenever you want OCR for scanned paperwork, superior kind and desk extraction, advanced structure evaluation, production-scale batch processing with service stage settlement (SLA) necessities, or compliance options and enterprise help.
The MCP-based method addresses a complementary state of affairs: giving an AI assistant interactive, on-demand entry to textual content already encoded inside PDFs. Select this sample when your paperwork are text-based PDFs (no OCR required), your workflow is interactive moderately than batch, you might be working in improvement or proof of idea environments, and also you need minimal infrastructure between the AI assistant and the supply doc. For all the pieces else, together with any doc processing that advantages from OCR or structured extraction, route the work to Amazon Textract.
How the answer works
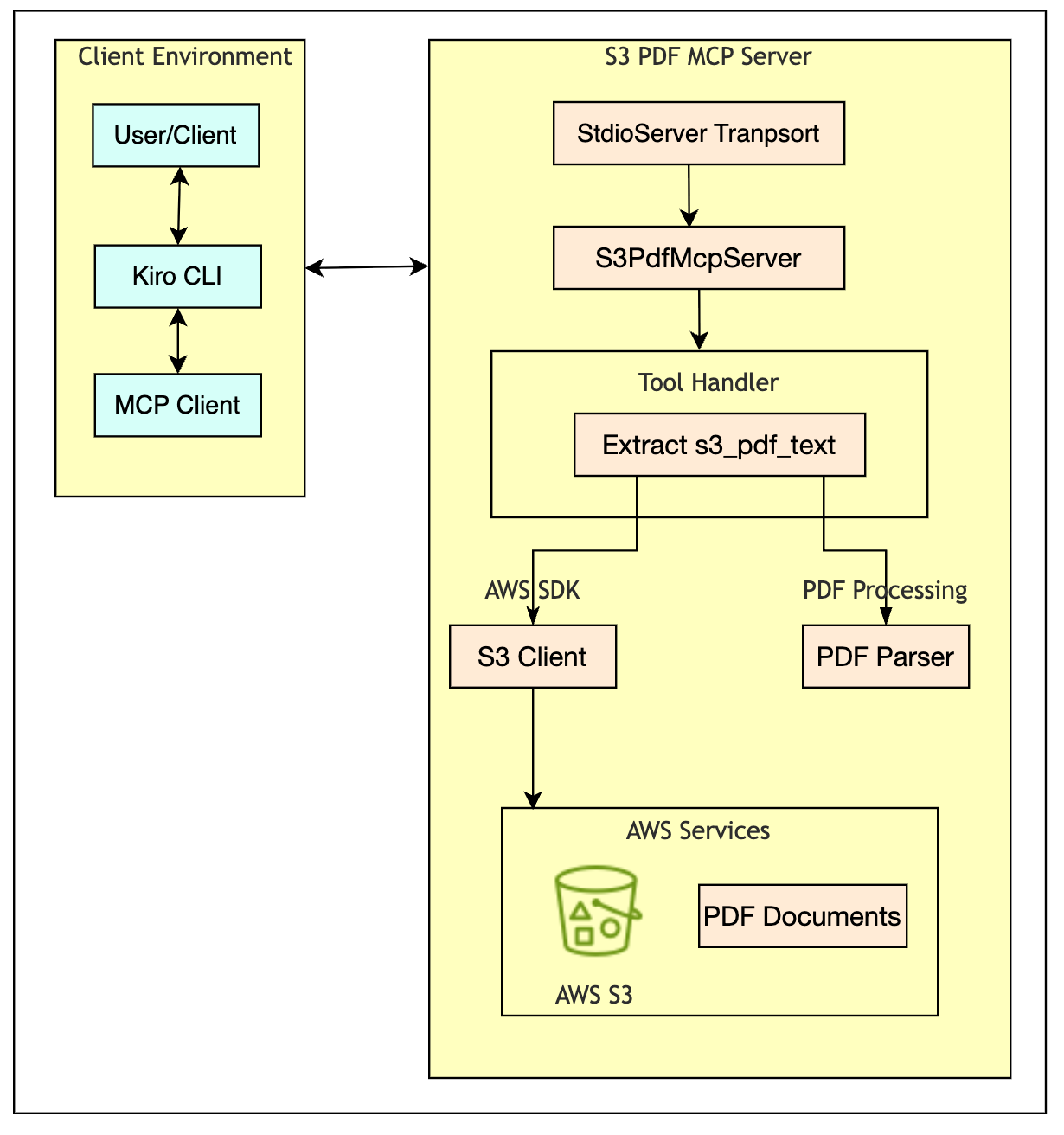
With this answer, you join your AI assistant on to your PDF paperwork in Amazon S3 and may get solutions shortly. Below the hood, the answer makes use of the Mannequin Context Protocol (MCP), an open normal that gives a structured strategy to entry exterior knowledge sources. MCP acts as a communication layer between your software and your knowledge. The structure has 4 elements: a command-line interface because the person interface, the MCP layer for communication, a customized MCP server for PDF processing, and Amazon S3 for doc storage, secured by AWS Id and Entry Administration (AWS IAM).
Price comparability
Select the method that matches your finances and necessities. For about 10,000 text-based PDF pages per thirty days in a proof of idea setting, right here is how the 2 approaches examine:
These two figures are value factors for various characteristic units and shouldn’t be learn as a head-to-head value comparability. Use them to select the fitting software for the workload, to not optimize purely on {dollars}. In case your workload entails scanned paperwork, varieties, tables, advanced layouts, or manufacturing SLAs, Amazon Textract is the suitable alternative and the extra capabilities are mirrored in its value.
Amazon Textract scope: page-level processing, OCR-ready, kind and desk extraction, structure understanding, enterprise SLAs
Indicative month-to-month price: Amazon Textract processing roughly $15, Amazon S3 storage $2, AWS Lambda compute $1, and huge language mannequin (LLM) token processing roughly $5 to $10, for a complete of roughly $23 to $28.
MCP server scope: direct textual content extraction from PDFs whose textual content is already encoded; no managed processing service concerned
Indicative month-to-month price: Amazon S3 storage $2 and knowledge switch $0.50, for a complete of roughly $2.50.
All price figures are illustrative and will change. Seek advice from the official AWS pricing pages for present charges.
Structure overview
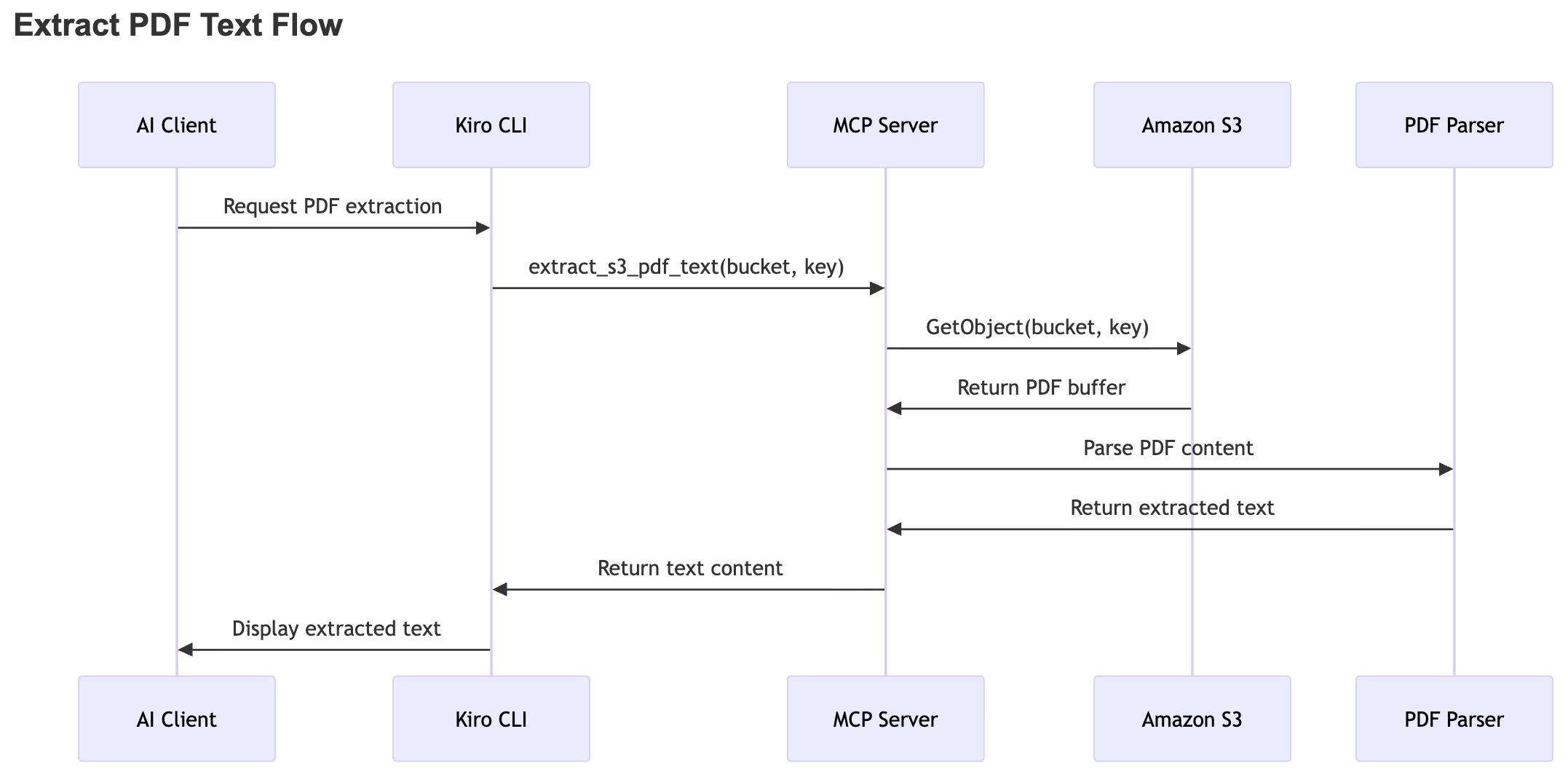
The next sequence diagram illustrates the end-to-end workflow for extracting textual content from a PDF saved in Amazon S3. The method begins when the AI consumer initiates a request for PDF extraction by way of the CLI. The system forwards this request to the MCP server, which retrieves the PDF file from Amazon S3 utilizing the offered bucket and object key.
After the MCP server fetches the PDF, it passes the file to a PDF parsing part. The part processes the doc and extracts the textual content material. The MCP server then returns the extracted textual content to the consumer, and the consumer shows it to the person.
Step-by-step implementation
Comply with these steps to arrange and configure the PDF textual content extraction answer. Start by confirming you will have the required stipulations in place.
Conditions
Earlier than you start, affirm that you’ve got the next gadgets prepared. You’ll additionally want primary familiarity with Python programming and AWS providers.
- An AWS account with Amazon S3 learn permissions.
- Python 3.10 or later put in.
- AWS Command Line Interface (AWS CLI) configured with legitimate credentials.
- Kiro CLI put in.
Set up
This part guides you thru putting in the MCP server and its dependencies. The method entails making a Python digital setting, putting in the required packages, and creating the server file. Comply with these steps so as. Run every command in your terminal.
Earlier than you begin, you want:
- Python 3.10 or newer put in in your machine.
- The Kiro CLI put in and logged in.
- AWS credentials arrange in your machine (run
aws configurein the event you haven’t). - An S3 bucket that comprises a minimum of one PDF file.
Step 1 — Create a folder for the undertaking
Run these two instructions in your terminal:
Step 2 — Navigate to the undertaking folder
Run this command:
Step 3 — Create a Python digital setting
Run this command:
Step 4 — Activate the digital setting
Run this command:
After this, your terminal immediate will present (venv) firstly. Preserve this terminal open. It’s essential keep on this digital setting for the following steps.
Step 5 — Set up the required Python packages
Run this one command:
Await it to complete. It ought to finish with “Efficiently put in…”.
Step 6 — Create the server file
Contained in the ~/s3-pdf-extractor folder, create a brand new file named precisely:
Paste the next code into that file and put it aside:
Step 7 — Take a look at that the server begins
In your terminal (nonetheless contained in the s3-pdf-extractor folder with the venv lively), run:
The terminal will seem to “pause” with no output. That’s right. It means the server is working and ready for requests. Press Ctrl+C to cease it.
In the event you see an error as a substitute, re-check Steps 2 and three.
Step 8 — Find or create the Kiro CLI configuration file
Kiro CLI makes use of a JSON configuration file to know which MCP servers can be found. It’s essential add your server to this file.
The Kiro CLI MCP configuration file is positioned at:
If this file doesn’t exist, create it by working these instructions in your terminal:
Step 9 — Add the MCP server configuration
Paste the next JSON into the file. Exchange /path/to/s3_pdf_extractor.py with the precise path from Step 1 (for instance, ~/s3-pdf-extractor/s3_pdf_extractor.py):
To get the complete absolute path, run echo ~/s3-pdf-extractor/s3_pdf_extractor.py in your terminal and use that output within the args subject.
Step 10 — Save the configuration file
Press Ctrl+O, then press Enter to avoid wasting the file.
Step 11 — Shut the file editor
Press Ctrl+X to exit nano.
Step 12 — Restart Kiro CLI
Restart Kiro CLI to load the brand new configuration. Shut and reopen Kiro CLI, or run:
Step 13 — Confirm the MCP server connection
Confirm the connection by working a take a look at extraction in Kiro CLI:
Safety issues
Safety is built-in from the start, not added as an afterthought. Right here is how the answer handles it:
- IAM integration: The answer makes use of your current AWS credentials. You don’t want to create or handle separate API keys.
- Least privilege entry: You grant solely Amazon S3 learn permissions, scoped to the precise buckets that comprise your PDF paperwork. Nothing extra.
- Momentary storage: The server deletes downloaded recordsdata robotically after it completes processing. No PDF knowledge lingers on the native file system.
- No knowledge persistence: Textual content extraction happens on demand with out storing outcomes.
- Audit path: AWS CloudTrail logs Amazon S3 entry requests in your account.
Efficiency and limitations
Right here is what to anticipate by way of efficiency:
- The server processes paperwork in actual time. For a typical 50-page text-based PDF, outcomes are usually out there in a couple of seconds, making it sensible for interactive workflows the place you ask follow-up questions.
- Processing time scales linearly with doc measurement. A ten-page doc processes roughly 5 instances quicker than a 50-page one.
- Reminiscence utilization is proportional to doc measurement. For many text-based PDFs beneath 100 pages, reminiscence consumption stays effectively inside typical improvement machine limits.
This method has clear limits. Know them earlier than you commit:
- Textual content-based PDFs solely. In case your paperwork are scanned photos or pictures of paper, the server can’t learn them. Amazon Textract handles these instances natively with OCR.
- No OCR functionality. The server reads embedded textual content from the PDF file format. It can’t interpret pixels in a picture.
- Restricted structure understanding. The server performs simple textual content extraction. It doesn’t reconstruct tables, columns, or advanced web page layouts. Amazon Textract handles this natively.
- No kind processing. In case your PDFs comprise fillable kind fields or structured knowledge, the server doesn’t extract these components. Amazon Textract handles this natively.
Actual-world use instances
These capabilities translate instantly into measurable outcomes throughout industries. Whether or not it’s authorized groups retrieving contract clauses mid-call, compliance officers finding coverage language throughout audits, or executives pulling earnings knowledge in actual time, the answer removes the friction of guide doc search. The next examples present how completely different groups put it to work.
Authorized providers agency
A mid-sized authorized agency adopted this answer for contract evaluation. Their attorneys used to spend 15 to twenty minutes looking out by way of PDF contracts to seek out particular indemnification clauses throughout consumer calls. That meant placing the consumer on maintain or promising to name again later. Now they kind a query into Kiro CLI and get the related passage in seconds. The agency stories that analysis time throughout consumer calls was considerably diminished.
Monetary providers compliance
A regional financial institution deployed the answer for regulatory examinations. Throughout audits, compliance officers must find particular coverage language shortly. Beforehand, they bookmarked key sections manually throughout dozens of PDF recordsdata, which was error-prone and laborious to keep up as insurance policies modified. With the MCP server linked to their S3 doc repository, they now pull up the precise paragraph an examiner asks about in actual time.
Company technique group
An enterprise management group makes use of the answer throughout quarterly technique conferences. When a board member asks a few particular metric from the earlier quarter’s earnings report, the group queries the PDF on the spot as a substitute of flipping by way of printed copies. This retains discussions shifting and grounded in precise knowledge.
Scaling and enhancement choices
This answer is a place to begin. As your wants develop, you may prolong it. Begin with caching in case your group accesses the identical paperwork repeatedly. Think about batch processing when you could deal with a whole lot of paperwork without delay. Add vector search when key phrase matching is now not adequate.
Particularly, you may prolong the answer in these methods:
- Add caching with Amazon DynamoDB for ceaselessly accessed paperwork.
- Implement batch processing with Amazon Easy Queue Service (Amazon SQS) for bulk operations.
- Combine vector search with Amazon OpenSearch Service for semantic doc discovery.
- Create hybrid workflows that route advanced paperwork to Amazon Textract robotically.
- Add monitoring with Amazon CloudWatch to trace utilization patterns and error charges.
Cleanup
Whenever you’re accomplished testing or need to take away the answer, observe these steps to keep away from pointless prices.
- Cease the MCP ServerPress Ctrl+C within the terminal the place the server is working.
- Take away the MCP ConfigurationOpen your Kiro CLI MCP configuration file (
~/.kiro/settings/instruments/mcp.json) and delete thes3-pdf-extractorentry. Save and shut the file. - Delete the undertaking recordsdataTake away the undertaking listing and all its contents:
Warning: This command completely deletes all recordsdata within the listing with out affirmation. Be sure you have saved any modifications earlier than continuing.
- Clear up S3 assets (non-compulsory)In the event you created take a look at PDFs in Amazon S3 particularly for this walkthrough, delete the take a look at recordsdata or the take a look at bucket utilizing the Amazon S3 console or the AWS CLI:
Solely delete assets you created for testing.
- Overview IAM permissions (non-compulsory)Navigate to the IAM console and take away any S3 learn permissions added particularly for this answer. Preserve permissions that different workflows rely on.
- Confirm cleanupVerify the listing now not exists:
Anticipated output: No such file or listing
After cleanup, you’ll now not incur S3 storage and knowledge switch prices for the assets you deleted. For detailed pricing data, see Amazon S3 Pricing. If you wish to redeploy later, repeat the set up steps. All code and configuration examples stay on this doc.
Conclusion
On this submit, you constructed an MCP server that extracts textual content from PDF recordsdata in Amazon S3 in actual time. You walked by way of the structure, in contrast prices with Amazon Textract, and noticed how 3 completely different groups put this method to work. The sample follows a transparent method: join your AI assistant to your paperwork, hold the infrastructure minimal, and scale up solely when the workload calls for it.
In abstract, the MCP server sample is a centered, interactive complement to Amazon Textract. Use it when an AI assistant must learn text-based PDFs in actual time. When your wants embody OCR, varieties, tables, or production-scale processing, Amazon Textract is the AWS service designed for that work, and the 2 approaches match cleanly collectively. That is precisely the sample proven within the hybrid workflow choice earlier on this submit.
Subsequent steps:
- Consider your use case towards the factors within the “The place this method matches alongside Amazon Textract” part.
- Deploy the answer in your improvement setting by following the Set up part on this submit. Take a look at with 5 to 10 consultant paperwork to ascertain baseline efficiency.
- Discover Amazon Textract for OCR capabilities, or be taught extra about Kiro CLI integration as your necessities evolve.
- In the event you do that answer or adapt it in your personal use case, we’d love to listen to about it within the feedback.
To be taught extra, discover the next assets:
In regards to the authors