

{kind=link}
In the present day, we’re excited to announce the day-zero availability of NVIDIA Nemotron 3 Extremely on Amazon SageMaker JumpStart.
With this launch, now you can deploy the Nemotron 3 Extremely mannequin utilizing a one-click deployment expertise. Nemotron 3 Extremely is an open mannequin constructed for frontier reasoning and orchestration in long-running autonomous brokers, delivering 5x sooner inference and as much as 30% decrease value for agentic workloads. Nemotron 3 Extremely is optimized for the NVFP4 format, which makes the mannequin a lot sooner and value efficient to host.
Overview of NVIDIA Nemotron 3 Extremely
NVIDIA Nemotron 3 Extremely is an open massive language mannequin with 550 billion whole parameters and 55 billion energetic parameters. It’s constructed on a hybrid Transformer-Mamba Combination-of-Consultants (MoE) structure, designed to ship frontier intelligence at a fraction of the compute value of dense fashions of equal high quality.
| Specification | Particulars |
|---|---|
| Structure | Hybrid Transformer-Mamba MoE |
| Parameters | 550B whole / 55B energetic |
| Context size | As much as 1M tokens |
| Enter / Output | Textual content in, textual content out |
| Precision | NVFP4 |
| Inference velocity | 5x sooner for long-running agent workflows |
| Value | As much as 30% decrease for complicated agentic duties |
Why agentic AI wants purpose-built fashions
Brokers don’t simply reply as soon as. They plan, name instruments, delegate work to sub-agents, test outcomes, and hold going throughout a whole lot of turns. Each step provides tokens and compute, so the metrics that matter are activity completion at helpful accuracy, time-to-finish, and cost-per-task.
Nemotron 3 Extremely addresses this instantly. Its MoE structure prompts solely 55B of its 550B parameters per ahead go, maintaining throughput excessive even at million-token context lengths. This implies brokers can maintain planning, software calling, and self-correction loops that span a whole lot of turns whereas serving to preserve coherence and handle value.
Enterprise use instances
Nemotron 3 Extremely excels in workloads that require sustained multi-step reasoning:
- Agent orchestrators – coordinate a number of sub-agents, handle state throughout lengthy tool-calling chains
- Coding brokers – generate, take a look at, debug, and iterate on code throughout massive repositories
- Deep analysis – synthesize info from a number of sources, preserve coherent reasoning over prolonged context
- Complicated enterprise workflows – automate multi-step enterprise processes with choice branching and error restoration
Getting began with SageMaker JumpStart
You’ll be able to deploy Nemotron 3 Extremely by way of Amazon SageMaker JumpStart with one-click deployment, eradicating the necessity to handle infrastructure or configure serving frameworks.
Stipulations
Earlier than you start, ensure you have:
- An AWS account
- Appropriately scoped permissions for SageMaker JumpStart
- Enough service quota for GPU situations (for instance, ml.p5en.48xlarge, ml.p5.48xlarge, or ml.g7e.48xlarge)
Vital: Deploying this mannequin creates a SageMaker endpoint that incurs fees whereas operating. GPU situations like ml.p5en.48xlarge can value a number of {dollars} per hour. See Amazon SageMaker AI pricing for particulars. Keep in mind to delete your endpoint when completed to keep away from ongoing fees.
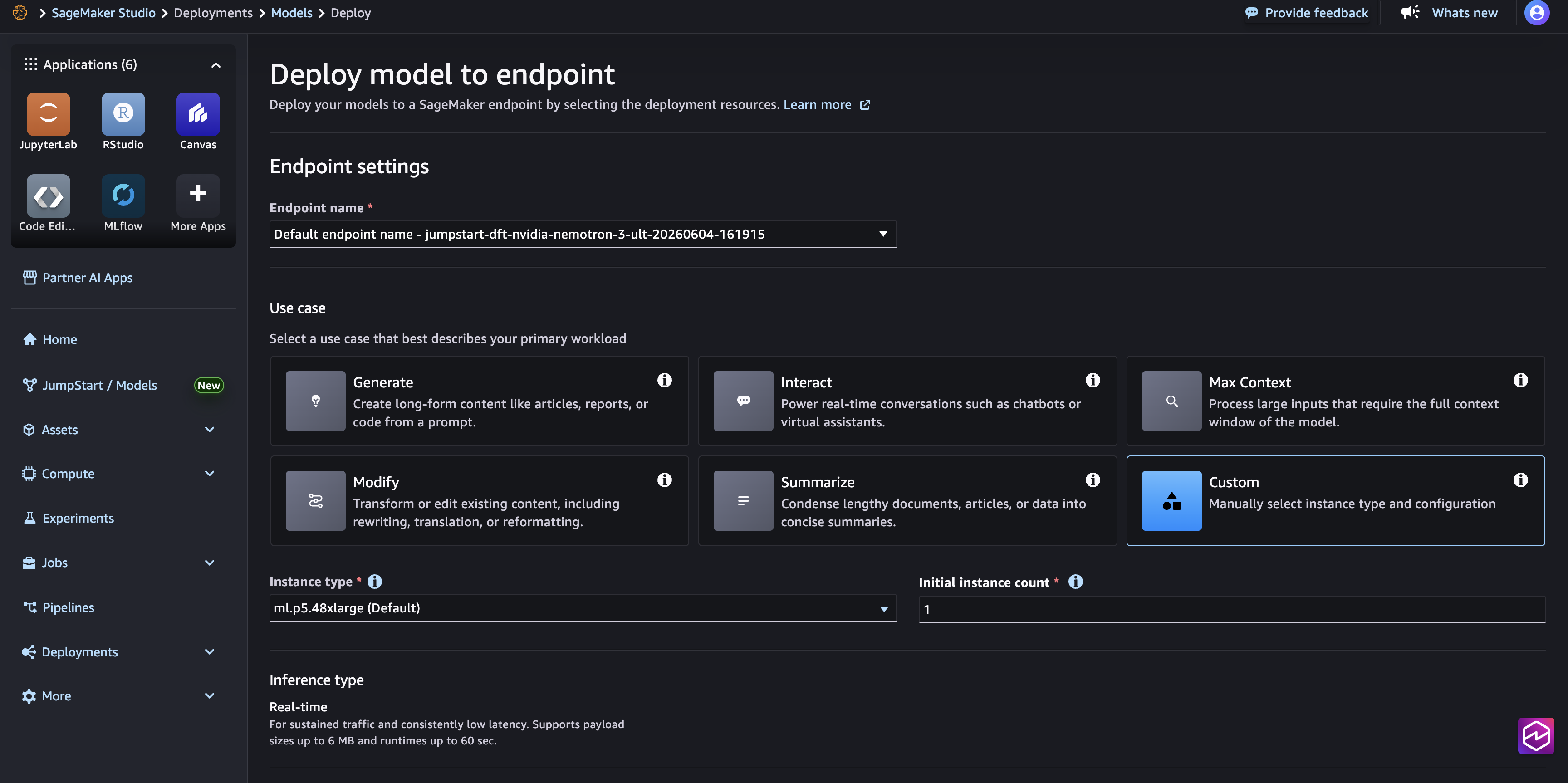
Deploy utilizing SageMaker Studio
- Open Amazon SageMaker Studio
- Within the left navigation pane, select SageMaker JumpStart
- Seek for Nemotron 3 Extremely
- Choose the mannequin card
- Select Deploy
- Choose your occasion kind (supported occasion sorts are ml.p5en.48xlarge, ml.p5.48xlarge, or ml.g7e.48xlarge)
- Assessment deployment settings (defaults are adequate for many use instances)
- Select Deploy to create the endpoint
- Look ahead to the endpoint standing to point out InService earlier than continuing to inference
Deploy utilizing the SageMaker Python SDK
Run inference
Clear up
To keep away from incurring pointless fees, delete the SageMaker endpoint when you find yourself carried out:predictor.delete_endpoint()
Conclusion
NVIDIA Nemotron 3 Extremely brings frontier-class reasoning to Amazon SageMaker JumpStart with 5x sooner inference and as much as 30% decrease value for agentic workloads. Its hybrid Transformer-Mamba MoE structure and million-token context window make it purpose-built for the sustained, multi-step reasoning that manufacturing brokers demand.
Whether or not you might be constructing agent orchestrators, coding brokers, deep analysis techniques, or complicated enterprise automation, Nemotron 3 Extremely is able to deploy in the present day from SageMaker JumpStart.
Get began now by looking for Nemotron 3 Extremely in Amazon SageMaker JumpStart.
In regards to the authors
 Dan Ferguson is a Options Architect at AWS, primarily based in New York, USA. As a machine studying providers skilled, Dan works to assist prospects on their journey to integrating ML workflows effectively, successfully, and sustainably.
Dan Ferguson is a Options Architect at AWS, primarily based in New York, USA. As a machine studying providers skilled, Dan works to assist prospects on their journey to integrating ML workflows effectively, successfully, and sustainably.
 Malav Shastri is a Software program Growth Engineer at AWS, the place he works on the Amazon SageMaker JumpStart and Amazon Bedrock groups. His position focuses on enabling prospects to make the most of state-of-the-art open supply and proprietary basis fashions. Malav holds a Grasp’s diploma in Laptop Science.
Malav Shastri is a Software program Growth Engineer at AWS, the place he works on the Amazon SageMaker JumpStart and Amazon Bedrock groups. His position focuses on enabling prospects to make the most of state-of-the-art open supply and proprietary basis fashions. Malav holds a Grasp’s diploma in Laptop Science.
 Vivek Gangasani is a Worldwide Chief for Options Structure, SageMaker Inference. He leads Resolution Structure, Technical Go-to-Market (GTM) and Outbound Product technique for SageMaker Inference. He additionally helps enterprises and startups deploy and optimize a GenAI fashions and construct AI workflows with SageMaker and GPUs. At present, he’s targeted on creating methods and content material for optimizing inference efficiency and use-cases comparable to Agentic workflows, RAG and so forth. In his free time, Vivek enjoys mountain climbing, watching motion pictures, and making an attempt completely different cuisines.
Vivek Gangasani is a Worldwide Chief for Options Structure, SageMaker Inference. He leads Resolution Structure, Technical Go-to-Market (GTM) and Outbound Product technique for SageMaker Inference. He additionally helps enterprises and startups deploy and optimize a GenAI fashions and construct AI workflows with SageMaker and GPUs. At present, he’s targeted on creating methods and content material for optimizing inference efficiency and use-cases comparable to Agentic workflows, RAG and so forth. In his free time, Vivek enjoys mountain climbing, watching motion pictures, and making an attempt completely different cuisines.