

{kind=link}
Massive language fashions (LLMs) ship robust outcomes on normal duties, however they typically battle with specialised work that requires understanding proprietary information, inner processes, or domain-specific terminology. Amazon Nova Forge addresses this by enabling you to construct your personal frontier fashions utilizing Amazon Nova. You can begin improvement from early mannequin checkpoints, mix proprietary information with Amazon Nova-curated coaching information, and host customized fashions securely on AWS. A key functionality is information mixing, which blends your coaching information with curated datasets. This helps the mannequin take up your area whereas retaining broad reasoning, instruction-following, and language capabilities. This prevents catastrophic forgetting that sometimes undermines area customization.
Profitable customization requires cautious hyperparameter tuning. Studying price, information mixing ratio, checkpoint choice, and coaching strategies all work together in methods that may silently undermine a coaching run. If any of them are flawed, you commerce one drawback for one more. This submit covers the artwork (strategic trade-offs) and science (metric-driven selections) of hyperparameter tuning on Amazon Nova Forge that will help you keep away from costly failed coaching runs.
Effective-tuning for domain-specific duties means enhancing efficiency in a single space with out degrading the mannequin’s normal capabilities, and getting that stability proper is more durable than it appears to be like. This submit walks by way of easy methods to navigate that stability, from deciding on the suitable customization technique to your information and job, to configuring the coaching parameters that the majority affect outcomes, like studying price, batch dimension, and checkpointing. We additionally cowl the frequent errors that result in wasted coaching runs and easy methods to catch them early, so you may enhance area efficiency with out degrading normal capabilities or burning by way of compute on avoidable failures.
By the top, you’ll know easy methods to enhance area efficiency with out degrading normal capabilities and easy methods to keep away from the costly failures that come from getting the stability flawed.
The hyperparameter tuning problem
Reaching this stability is more durable than it seems. Three elementary challenges make hyperparameter tuning notably troublesome on domain-specialized fashions.
Problem 1: Catastrophic forgetting
If you practice a mannequin on slender area information, the mannequin can overwrite normal capabilities it realized throughout pre-training. This phenomenon, known as catastrophic forgetting, reveals up as degraded efficiency on duties outdoors your coaching area. The mannequin turns into extremely specialised however loses instruction-following capability, reasoning functionality, and broad information. In manufacturing, this implies a customer support mannequin fine-tuned in your assist tickets might not purpose about ambiguous requests or preserve coherent multi-turn conversations.
This creates a stability-flexibility tradeoff. Ideally, the mannequin is versatile sufficient to study a company’s area however secure sufficient to retain normal capabilities. Nova Forge addresses this by way of information mixing, which blends your coaching information with curated datasets throughout coaching, and checkpoint choice, which helps you to select how a lot present alignment to protect.
Problem 2: Discovering the suitable studying price
The training price controls how a lot the mannequin’s weights change in response to every batch of coaching examples. It’s essentially the most delicate hyperparameter throughout all customization strategies. A studying price that’s too excessive causes the mannequin to overshoot the optimum state, destabilize throughout coaching, or neglect base capabilities quickly. A studying price that’s too low wastes compute on very gradual convergence. The correct worth relies on your information distribution, mixing ratio, and coaching method.
Nova Forge offers calibrated service defaults for every coaching method that account for these interactions. If you use information mixing, the sensitivity will increase additional. Deviating from the default studying price when mixing Nova information with your personal information is the most typical supply of coaching instability, so these service defaults are the advisable place to begin.
Problem 3: Baseline efficiency constraints
Reinforcement fine-tuning (RFT) is a method that improves mannequin habits by producing a number of candidate responses and scoring them in opposition to high quality standards. The mannequin learns by evaluating its personal outputs and reinforcing the higher ones. RFT works at its full capability inside a particular vary of baseline job accuracy, measured by how typically the mannequin produces right or high-quality responses earlier than fine-tuning. If baseline accuracy is just too low (the mannequin hardly ever produces right responses), there aren’t sufficient good examples for reward-guided exploration to be taught from. If baseline accuracy is already very excessive, extra coaching yields diminishing returns and dangers degrading present efficiency. This implies RFT can’t shut giant competence gaps the place the mannequin essentially lacks the information or reasoning capability to aim a job. It refines and strengthens behaviors the mannequin can already partially display, relatively than educating fully new capabilities from scratch.
The Nova Forge pipeline addresses each bounds. For low-baseline eventualities, run supervised fine-tuning (SFT) first to determine the foundational capabilities wanted for efficient reward-based studying. For top-baseline duties, guarantee that your reward operate has discriminative energy throughout the mannequin’s high quality vary. If most responses already rating extremely, RFT has no significant sign to optimize in opposition to.
The Nova Forge customization pipeline
Understanding these challenges frames how the Amazon Nova Forge customization pipeline is designed to handle them. Nova Forge offers three complementary customization strategies, every serving a definite objective within the mannequin improvement lifecycle.
| Method | What it does | When to make use of | Enter information |
| Continued pre-training (CPT) | Expands foundational mannequin (FM) information by way of self-supervised studying on giant portions of unlabeled, domain-specific proprietary information. CPT teaches the mannequin area terminology and patterns out of your textual content corpus. | You want the mannequin to know specialised vocabulary, trade ideas, or organizational information that doesn’t exist within the base mannequin. | Massive volumes of unlabeled area textual content. Nova Forge helps CPT with information mixing and three checkpoint choices (pre-trained, mid-trained, and post-trained), every suited to completely different information scales and downstream necessities. |
| Supervised fine-tuning (SFT) | Customizes mannequin habits utilizing a coaching dataset of input-output pairs particular to your goal duties. SFT teaches the mannequin “given X, output Y” habits by way of demonstrations. | You want the mannequin to comply with particular response codecs, undertake explicit tones, or carry out structured duties like classification or extraction. | 1,000–10,000 high-quality demonstrations per job. High quality, consistency, and variety matter greater than quantity. Nova Forge helps SFT with information mixing utilizing Amazon Nova-curated datasets, together with reasoning-instruction-following classes that protect normal capabilities. |
| Reinforcement fine-tuning (RFT) | Steers mannequin output towards most well-liked outcomes utilizing reward alerts. RFT optimizes the mannequin inside a behavioral neighborhood established by prior coaching for single-turn or multi-turn conversational duties. | You’ve a transparent reward operate that may consider response high quality and need to push efficiency past what SFT alone achieves. | Prompts and a reward operate. Nova Forge helps bringing your personal exterior reward atmosphere by way of AWS Lambda, enabling customized verification logic for domain-specific high quality evaluation. |
When all three levels are used collectively (CPT, then SFT, then RFT), they produce the strongest outcomes. Nevertheless, with the suitable pipeline, every stage will be optionally available. It relies on your information availability, job kind, and place to begin. CPT is barely wanted when the bottom mannequin lacks area vocabulary or information your job requires. SFT and RFT can be utilized independently or mixed relying on what your job calls for.
Determine 1: The Amazon Nova Forge customization pipeline. CPT teaches area information from unlabeled textual content, SFT teaches task-specific habits from demonstrations, and RFT optimizes efficiency utilizing reward alerts. Every stage is optionally available, and the total pipeline (CPT, then SFT, then RFT) produces the strongest outcomes when all three are relevant to your use case.
Amazon SageMaker AI provides completely different environments for personalisation: SageMaker Serverless offers a UI-driven expertise with automated compute provisioning, SageMaker AI coaching jobs (SMTJ) present a totally managed expertise with out cluster administration, whereas Amazon SageMaker HyperPod provides specialised environments for superior distributed coaching eventualities.
Strategic selections
With the customization pipeline in view, the following step is knowing the qualitative trade-offs that form your configuration. These strategic selections matter as a lot as any particular person hyperparameter worth: checkpoint choice, information mixing, and coaching mode.
Checkpoint choice (most impactful resolution)
For CPT, checkpoint choice is extra impactful than any hyperparameter. Amazon Nova Forge offers three checkpoint choices, every suited to completely different information scales and downstream necessities.
- Pre-trained checkpoints are essentially the most versatile and supply the quickest convergence. These checkpoints settle for new patterns readily and work finest for large-scale CPT with substantial token budgets exceeding 100 billion tokens. When utilizing pre-trained checkpoints with giant datasets, you need to use the next studying price (similar to 1e-4) to speed up information absorption. You then have to regularly cut back the training price again to roughly 1e-6 for mannequin stability earlier than working SFT to let the mannequin “settle” into what it realized with out overshooting. Bear in mind that pre-trained checkpoints don’t have any directions for tuning. After CPT, you need to run SFT to make the mannequin helpful for downstream duties.
- Mid-trained checkpoints stability flexibility and alignment. They settle for area information whereas retaining some instruction-following habits. Use mid-trained checkpoints for medium-sized datasets the place you need quicker area adaptation than post-trained however extra stability than pre-trained. Mid-trained checkpoints work nicely for full rank coaching, which updates each parameter within the mannequin throughout fine-tuning, with giant, structured datasets.
- Put up-trained checkpoints are essentially the most proof against new patterns however protect instruction-following and normal capabilities. Use post-trained for smaller-scale CPT the place preserving alignment issues greater than maximizing area information absorption. Put up-trained checkpoints are the advisable place to begin for LoRA (Low-Rank Adaptation), which freezes the unique mannequin weights and trains small adapter matrices on high, and different parameter-efficient fine-tuning strategies, as they preserve the mannequin’s present capabilities whereas permitting focused adaptation. For small datasets or later-stage checkpoints, use conservative studying price values from the service defaults.
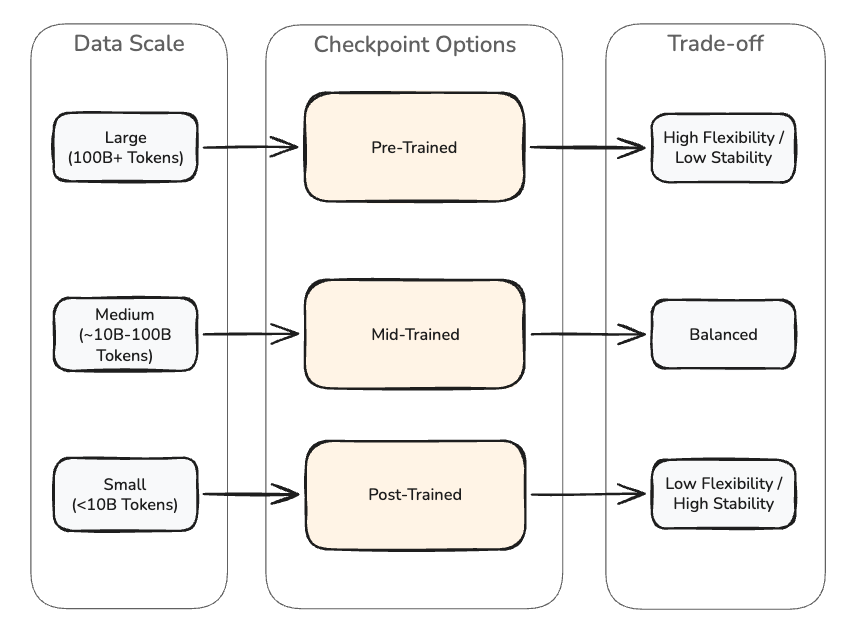
Determine 2: Checkpoint choice for continued pre-training. Pre-trained checkpoints supply most flexibility for big datasets however require SFT afterward to revive instruction-following. Put up-trained checkpoints protect alignment and swimsuit smaller datasets or parameter-efficient strategies like LoRA.
Information mixing technique
With out information mixing, coaching on slender area information could cause the mannequin to turn into unstable, leading to erratic coaching habits (gradient instability or loss spikes) or a sudden degradation in efficiency.
When configuring information mixing, stability your buyer information round 50 p.c of the full combine for many use circumstances. For SFT, at all times embrace the “reasoning-instruction-following” class in your Nova information combine. This single class considerably improves generic benchmark efficiency after fine-tuning. Skipping this class is a standard reason for degraded reasoning efficiency in fine-tuned fashions.
Information mixing may be very delicate to studying price. Deviating from the default studying price when utilizing information mixing causes instability. That is the most typical mistake practitioners make. For those who observe coaching instability with information mixing, the training price is the primary suspect.
Discovering the optimum mixing ratio requires experimentation. Maintain your area information fixed and range the Nova information proportion throughout a number of runs. Area efficiency sometimes stays fixed whereas normal capabilities hold enhancing the extra Nova information is combined in. Place your highest-quality information towards the top of coaching for higher convergence.
Coaching mode: Low-Rank Adaptation (LoRA) vs Full Rank
Amazon Nova Forge helps two coaching modes that decide how mannequin parameters are up to date throughout coaching:
- LoRA updates solely adapter layers, providing decrease compute prices, quicker iteration, and compatibility with on-demand inference. LoRA achieves close to Full Rank efficiency for many duties whereas being extra forgiving of suboptimal hyperparameters. The default alpha scaling issue of 64 works for many duties. Improve alpha if LoRA is under-adapting to your information or lower it if LoRA is over-adapting and dropping normal capabilities. Use post-trained checkpoints as your place to begin for LoRA coaching.
- Full Rank updates all mannequin parameters, offering most adaptation capability. Full Rank requires Amazon Bedrock Provisioned Throughput for deployment (On-Demand is barely obtainable for LoRA-based customization) and better compute throughout coaching. Use Full Rank when you have got validated your pipeline and your deployment structure justifies the extra price. Mid-trained checkpoints work nicely for Full Rank coaching with giant, structured datasets.
Begin with LoRA to validate your pipeline, information high quality, and reward operate (for RFT). Graduate to Full Rank when you have got confirmed the strategy works, and your manufacturing necessities justify it (for instance, mannequin efficiency or price constraints).
Really helpful workflow
Making use of these strategic selections to your particular state of affairs relies on what information and aims you have got. The next paths map your beginning circumstances to the suitable sequence of strategies.
You probably have labeled demonstrations and a verifiable reward operate (SFT then RFT):
- Begin with SFT utilizing LoRA to show the goal habits and set up baseline competency.
- Allow information mixing with “reasoning-instruction-following” included to protect the mannequin’s capability to comply with structured prompts and produce well-formatted outputs throughout area adaptation.
- Use default studying charges with out modification.
- Monitor validation loss to pick out the most effective SFT checkpoint.
- Graduate to RFT on the SFT checkpoint to optimize additional by way of reward alerts.
- Take into account Full Rank coaching solely after validating the strategy with LoRA.
- Check totally on each your area job and normal benchmarks earlier than manufacturing deployment (see the Experiments and insights part for an instance).
For those who can outline verifiable outcomes however can’t simply label responses at scale (RFT solely):
- Consider base mannequin efficiency on a consultant pattern of your job first.
- Proceed with RFT straight if the bottom mannequin achieves greater than roughly 5 p.c constructive reward.
- Fall again to SFT if reward scores are persistently close to zero. The mannequin wants baseline competency earlier than reward-guided studying can take impact.
If the bottom mannequin lacks area vocabulary or information your job requires, begin with CPT:
- Run CPT to soak up area information from unlabeled textual content.
- Comply with with SFT. Pre-trained checkpoints used for CPT don’t have any instruction tuning, so SFT is required after CPT to make the mannequin helpful.
- Optionally comply with with RFT to additional optimize efficiency.
Parameter configuration
With strategic selections made, now you can optimize particular hyperparameters that govern how every method executes. This part offers steerage for every method.
Studying price configuration
Studying price controls how rapidly the mannequin updates primarily based on coaching alerts. Service defaults signify examined configurations that work throughout numerous use circumstances.
- For CPT: Begin at service defaults. For giant datasets exceeding one trillion tokens, you need to use the next studying price (similar to 1e-4) to speed up information absorption, however you want a ramp-down stage to cut back the training price again to roughly 1e-6 for mannequin stability earlier than SFT. The
constant_stepsparameter controls what number of steps the mannequin trains on the peak studying price earlier than this ramp-down stage begins. Improveconstant_stepsfor very giant token runs the place extra steps at full studying price assist area absorption. For smaller datasets or later-stage checkpoints, use the default (decrease) studying price from the beginning. - For SFT: Keep on with service defaults, particularly with information mixing. The advisable studying price is 1e-5 for LoRA and 5e-6 for full-rank SFT. Deviating from the default studying price when mixing Nova information causes instability. For those who observe coaching instability with information mixing, the training price is the primary suspect.
- For RFT: Begin at service defaults. Modify in small multiplier increments provided that wanted. If reward drops all of the sudden and doesn’t recuperate, the training price is probably going too excessive. Even a small multiplier enhance can drop efficiency under baseline.
Configure warmup steps to roughly 15 p.c of your whole coaching steps. Warmup stabilizes preliminary coaching by regularly growing the training price relatively than beginning on the full worth.
Batch dimension and coaching period
Batch dimension (managed by global_batch_size) is the batch parameter throughout all coaching strategies (CPT, SFT, RFT) and all environments (SageMaker Serverless, SMTJ, HyperPod). It defines the variety of coaching samples processed per optimizer step. For CPT and SFT, that is easy with one pattern equal to 1 input-output pair (SFT) or one token sequence (CPT). RFT introduces a further parameter, number_generation, that controls what number of candidate responses are generated per immediate for reward scoring. This parameter doesn’t exist in CPT or SFT recipes, as a result of these strategies practice straight on supplied input-output pairs relatively than producing candidates. When the variety of generations parameter is current, batch dimension semantics differ between environments. Getting this flawed results in sudden habits.
- On SMTJ (RFT solely): Batch dimension means prompts per step. Every immediate generates N candidate responses (managed by
number_generation). Complete samples per step equals batch dimension multiplied by variety of generations. - On SageMaker HyperPod (RFT solely): Batch dimension means whole samples per step (prompts multiplied by generations). Translate fastidiously when shifting configurations between environments.
For CPT, goal 2-20 million tokens per step. Use 20 million for big token budgets and a pair of million for smaller budgets. Calculate international batch dimension as the closest energy of two of tokens per step divided by max sequence size. For instance, 4 million tokens per step with a 4096-sequence size yields a batch dimension of roughly 1024. Smaller batch sizes produce noisier gradients, which might help generalization and allow quicker iteration. Bigger batch sizes produce smoother gradients however might over-smooth domain-specific alerts. Begin with reasonable batch sizes for stability.
Match your max sequence size to your information distribution. Don’t exceed what your information wants. Smaller context lengths enhance token throughput and cut back coaching prices. For CPT, course of at most one epoch of your dataset. Keep away from repeating information, as a number of epochs on restricted CPT information results in overfitting and lack of normal capabilities. Monitor validation loss to trace progress. For SFT, Full Rank coaching sometimes wants fewer epochs than LoRA. LoRA coaching can tolerate barely extra epochs. Monitor validation loss to detect overfitting and choose the most effective checkpoint.
RFT-specific parameters
RFT introduces extra parameters not current in CPT or SFT.
- Variety of generations controls what number of candidate responses the mannequin generates per immediate for the reward operate to check. Fewer candidates imply quicker coaching however much less sign range. Too many candidates add noise with out enhancing sign and practically double coaching time. Reasonable values hit the most effective accuracy-to-time ratio. Improve in case your job has excessive variance in response high quality. Lower for fast reward operate iteration throughout improvement.
- KL-Divergence Loss Coefficient constrains how far the mannequin’s coverage can drift from its authentic habits. This parameter is offered on SMTJ solely. A low coefficient lets the mannequin discover freely however dangers discovering shortcuts that sport the reward operate. A excessive coefficient prevents significant studying by pulling the mannequin again to its place to begin. Improve if KL divergence spikes throughout coaching to stability real studying in opposition to behavioral drift.
- Reasoning Effort controls how a lot chain-of-thought reasoning the mannequin performs earlier than answering. Excessive reasoning effort produces the most effective accuracy however will increase latency and serving price. Low reasoning effort provides quicker inference with modest accuracy trade-offs. Use excessive for optimum accuracy throughout validation, then take into account decreasing for latency-sensitive manufacturing deployments.
- Lambda Concurrency Restrict (SMTJ solely) controls parallel AWS Lambda capabilities for reward analysis. Improve considerably for quick reward capabilities to keep away from analysis throughput turning into a bottleneck.
Keep in mind that batch dimension semantics differ between platforms. On SMTJ, global_batch_size means prompts per step the place every generates N candidates. On SageMaker HyperPod, global_batch_size means whole samples (prompts multiplied by generations). Translate fastidiously between environments.
Regularization parameters
Regularization parameters assist forestall overfitting, particularly on smaller datasets.
- Weight decay defaults to zero. Improve modestly in the event you observe overfitting on small datasets. Weight decay applies L2 regularization to constrain parameter magnitudes.
- Dropout (hidden and a focus) defaults to zero. Improve hidden dropout modestly for smaller datasets to cut back overfitting. Improve consideration dropout cautiously, as excessive values can harm advanced reasoning capabilities.
- Clip ratio and age tolerance are superior SageMaker HyperPod parameters. Clip ratio limits how a lot the coverage can change in a single coaching step. Age tolerance determines how lengthy coaching information stays legitimate earlier than being thought-about too stale. Refit frequency controls how typically the mannequin collects recent coaching information. Defaults work for many use circumstances. Solely modify these superior settings in the event you perceive the particular stability problem you might be addressing.
Experiments and insights
With these hyperparameters in thoughts, we ran a collection of HPO experiments utilizing Amazon Nova 2.0 throughout public benchmarks together with CoCoHD, MedReason and LLaVA-CoT. The next desk summarizes the experimental configurations and key findings for every parameter sweep.
| Dataset | Rank | Alpha | GBS | LR | Max Steps | Warmup | Base Goal Perf. | SFT Goal Perf. | Rank | Perf Diff |
| MedReason | 32 | 64 | 32 | 1.00E-05 | 312 | 47 | 57.38% | 63.54% | 2 | 10.75% ↑ |
| MedReason | 64 | 64 | 32 | 1.00E-05 | 312 | 47 | 57.38% | 63.78% | 1 | 11.16% ↑ |
| MedReason | 32 | 64 | 32 | 5.00E-06 | 312 | 47 | 57.38% | 63.33% | ||
| MedReason | 32 | 64 | 32 | 1.00E-05 | 624 | 94 | 57.38% | 61.42% | ||
| LLavaCOT | 64 | 64 | 32 | 1.00E-05 | 312 | 47 | 16.22% | 68.47% | 1 | 322.13% ↑ |
| LLavaCOT | 32 | 128 | 32 | 1.00E-05 | 312 | 47 | 16.22% | 65.77% | 2 | 305.49% ↑ |
We ran LoRA SFT on Amazon Nova 2 Lite utilizing Nova Forge with rank 32, alpha 64, batch dimension 32, 15 p.c warmup, and 1 epoch, sweeping solely the training price to isolate its impact heading in the right direction accuracy. The service default of 1e-5 produced the most effective outcome at 63.54 p.c, a ten.75 p.c elevate over the v4 base. Dropping the training price to 5e-6 adversely impacted goal efficiency with out meaningfully defending normal capabilities, as MMLU, IFEval, and GPQA scores have been inside noise of the 1e-5 run. Doubling to 2 epochs on the identical studying price dropped accuracy to 61.42 p.c, confirming that overtraining on slender area information erodes each area and normal efficiency.
We diversified LoRA rank (32 vs 64) and alpha (64 vs 128) on a multimodal reasoning job the place the bottom mannequin begins at solely 16.22 p.c accuracy. One of the best configuration, rank 64 with alpha 64, lifted accuracy to 68.47 p.c, a 322 p.c relative enchancment over the bottom. Doubling alpha to 128 at rank 32 produced an identical goal achieve at 65.77 p.c, however at a meaningfully larger general-capability regression price. For duties the place the baseline accuracy is low, growing rank is a higher-leverage adjustment than growing alpha. Alpha must be elevated solely when LoRA is under-adapting, and decreased if the mannequin is dropping normal capabilities.
No single hyperparameter configuration works finest for all use circumstances. These advisable defaults are robust beginning factors, not ensures of optimum efficiency.
Widespread pitfalls and easy methods to keep away from them
The next desk summarizes the most typical errors practitioners ought to keep away from when tuning Amazon Nova Forge fashions.
| Pitfall | Symptom | Resolution |
| Skipping SFT earlier than RFT | RFT produces no enchancment or degrades efficiency | Run SFT first to get the mannequin into the suitable behavioral neighborhood earlier than RFT optimization. |
| Deviating from default LR with information mixing | Coaching instability, loss spikes, functionality collapse | Keep on with service defaults when utilizing information mixing. That is the most typical mistake. |
| Poor reward operate high quality | Accuracy decreases regardless of coaching, or mannequin video games the metric | Refine your reward operate earlier than altering any coaching parameter. Validate with no less than two unbiased judges. |
| A number of epochs on restricted CPT information | Overfitting, lack of normal capabilities, memorization | Course of at most one epoch of your CPT dataset. Monitor validation loss to detect overfitting early. |
| Mismatched reasoning settings | Inference habits doesn’t match coaching habits | Match reasoning_enabled between coaching and inference. For those who practice with reasoning, infer with reasoning. |
When tuning fashions with Nova Forge, spend money on your reward operate earlier than anything. A poor reward operate will lower accuracy no matter different hyperparameter selections, whereas a refined one produces constant positive factors on an identical infrastructure. Ensure your reward operate has discriminative energy throughout the mannequin’s high quality vary, as a result of if all the pieces scores excessive, RFT has no gradient to optimize.
The identical validation self-discipline applies to LLM-as-judge choice. Your choose mannequin should reliably distinguish high quality variations throughout the mannequin’s output vary. Validate choose settlement with no less than two unbiased evaluators earlier than committing to a coaching run.
Bear in mind that coaching atmosphere stability mechanisms differ between platforms. SMTJ applies steady KL penalty as a smooth constraint, whereas SageMaker HyperPod makes use of gradient clipping as a tough cap per step. Each obtain comparable accuracy, however they require completely different tuning intuitions. Don’t assume parameters switch straight between environments.
All through all of this, prioritize information high quality over quantity. Filtering aggressively and ensuring coaching examples precisely signify the goal habits will outperform merely scaling up low-quality information.
Measuring success
If you apply correct hyperparameter tuning, the outcomes will be substantial. The AWS China Utilized Science crew demonstrated this of their analysis of Amazon Nova Forge, attaining 17 p.c F1 rating enchancment on a posh Voice of Buyer classification job whereas sustaining near-baseline MMLU scores.
Key metrics to watch
Coaching loss ought to lower steadily with out sudden spikes. Spikes typically point out studying price points or information high quality issues.
Validation loss reveals overfitting. If validation loss will increase whereas coaching loss decreases, you might be overfitting. Cut back epochs, enhance regularization, or add extra numerous information.
KL divergence (for RFT) reveals how far the coverage has drifted. Sudden spikes recommend the mannequin is making giant, doubtlessly unstable updates. Improve the KL loss coefficient if this happens.
Reward metrics (for RFT) ought to enhance steadily. If reward improves quickly then plateaus or drops, the mannequin could also be gaming the reward operate. Revisit your reward design.
Conclusion
Optimizing mannequin customization with Amazon Nova Forge requires balancing artwork and science. The artwork includes understanding trade-offs: checkpoint choice, information mixing technique, and coaching mode selections form your end result greater than any single hyperparameter. The science includes systematic tuning: studying price, batch dimension, and technique-specific parameters require cautious configuration primarily based in your information and aims.
Information and reward high quality exceed any hyperparameter in significance. Earlier than tuning coaching parameters, optimize your information pipeline and reward operate. Begin with service defaults, particularly for studying price and information mixing, as these defaults exist as a result of they work throughout a variety of use circumstances.
For many manufacturing eventualities, the strongest pipeline is SFT adopted by RFT. RFT refines present functionality however can’t recuperate from a low baseline, so supervised fine-tuning wants to determine strong efficiency first. Information mixing must be handled as important for manufacturing workloads, not optionally available. It prevents catastrophic forgetting and offers optimization stability wanted for dependable outcomes.
When working with continued pre-training, checkpoint choice is essentially the most impactful resolution you’ll make. Match checkpoint flexibility to your information scale: earlier checkpoints for large-scale area adaptation, later checkpoints for smaller datasets the place preserving instruction-following habits issues.
To get began with Amazon Nova Forge, discover the Amazon Nova documentation and the SageMaker HyperPod recipes repository on GitHub. For hands-on examples of knowledge mixing in motion, see the Nova Forge information mixing weblog submit. For a deeper dive into RFT with Nova Forge see the Reinforcement fine-tuning for Amazon Nova: Educating AI by way of suggestions weblog submit.
Acknowledgements
The authors want to thank Zheng Du, Bharathan Balaji, Anjie Fang, and Mengnong Xu from the AWS AGI Customization Science crew for his or her technical steerage.
Concerning the authors