

{kind=link}
Most net brokers at present drive a browser one motion at a time. The mannequin receives the present web page state — as a screenshot or DOM textual content — and predicts the following click on, keypress, or scroll. This action-at-a-time design made sense when language fashions had restricted reasoning skill. As fashions have change into extra succesful at writing and debugging code, that inflexible loop has change into a constraint reasonably than a construction that helps.
Microsoft Analysis’s AI Frontiers lab constructed a distinct method. Their new open-source framework, Webwright, offers the agent a terminal as an alternative of a stateful browser session. The agent writes Playwright code to regulate browsers, runs bash instructions, inspects logs, and iteratively refines scripts. Playwright is an open-source browser automation library, additionally from Microsoft, that helps programmatic management of Chromium, Firefox, and WebKit browsers.
What Webwright Does Otherwise
Webwright separates the agent from the browser and treats the browser as one thing the agent can launch, examine, and discard whereas growing a program. The persistent artifact isn’t the browser session however the code and logs within the native workspace.
This is similar mannequin a developer makes use of when writing an RPA (Robotic Course of Automation) script. As a substitute of manually clicking via a website every time, they write a script as soon as. That script may be rerun, tailored, and shared. Webwright applies this to LLM-powered brokers.
The system has three core parts: a Runner, a Mannequin Endpoint, and a terminal Atmosphere. The runner is about 150 strains of code, the mannequin interface about 550 strains, and the atmosphere about 300 strains. There is no such thing as a multi-agent orchestration or advanced planning hierarchy — only a single agent loop.
All intermediate code, logs, screenshots, and outcomes are saved within the workspace, making every run simple to examine.
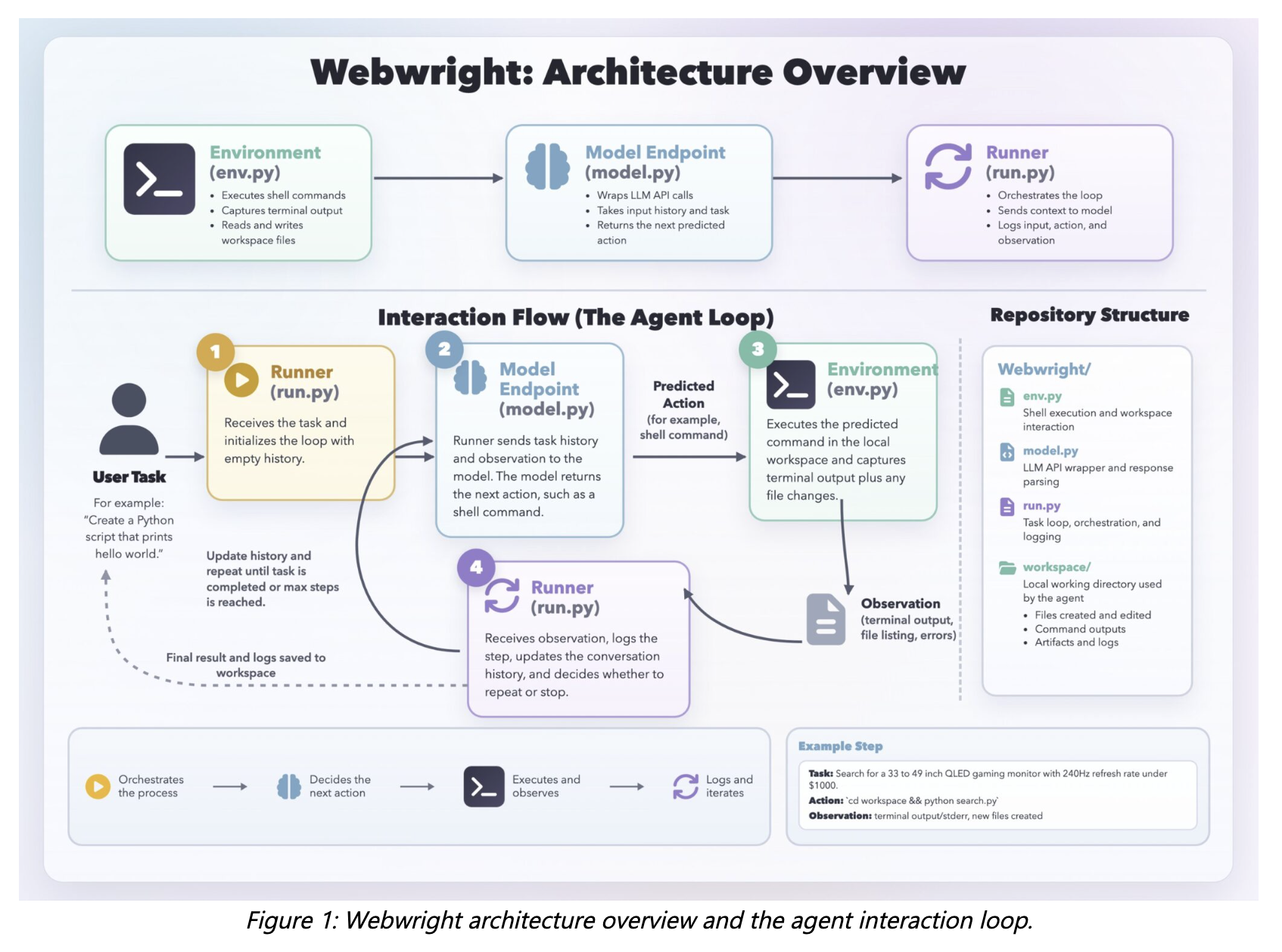
The Agent Loop
The Runner sends the present context to the mannequin. The mannequin returns a pondering block and a shell command. That command runs within the Atmosphere, which returns terminal output, logs, screenshots, or error tracebacks. These observations return into context, and the loop continues.
Slightly than issuing one primitive motion at a time, a coding agent can naturally specific multi-step interactions — akin to choosing a date or filling out a whole type — as a compact program. Loops, features, and abstractions enable the agent to generalize throughout related duties with out repeatedly predicting related sequences of low-level steps.
Two Engineering Challenges
Untimely ‘executed’ and context explosion are the 2 core points. With open-ended bash actions, the mannequin should self-report completion and infrequently claims success with out really ending. They added a gate: the agent should generate a self-reflection config, run a ultimate script in a contemporary folder with logs and screenshots, and go its personal self-reflection judgement that outputs success or failure earlier than emitting executed: true. In any other case, the flag is dropped and it retries.
For context size, lengthy coding trajectories shortly exceed context limits, so that they compact historical past each 20 steps right into a single abstract.
Benchmark Outcomes
Webwright was evaluated on two benchmarks: On-line-Mind2Web and Odysseys.
On-line-Mind2Web comprises 300 duties throughout 136 extensively used websites and makes use of an automatic LLM-as-a-Decide analysis framework. GPT-5.4 achieves 86.67% total accuracy, representing the best amongst all open-sourced harness recipes within the AutoEval class of the On-line-Mind2Web benchmark, with a 100-step price range. Claude Opus 4.7 reached 84.7% total however carried out higher on laborious duties at N=100 steps — 80.5% versus 76.6% for GPT-5.4.
In addition they reproduced a GPT-5.4 baseline in a standard screenshot-based agent setting, the place the mannequin predicts x,y coordinates for clicks and typing actions. Utilizing the identical underlying mannequin, Webwright achieves substantial good points throughout all three problem classes, highlighting the good thing about the code-driven terminal-based method over step-by-step coordinate prediction.
Odysseys evaluates long-horizon searching duties spanning a number of web sites. Duties common 272.3 phrases of directions. Within the April 2026 leaderboard, the best-performing mannequin was Opus 4.6, with a prime rating of 44.5. Webwright powered by GPT-5.4 reaches 60.1%, a 35.1% relative enchancment over the earlier state-of-the-art. In comparison with the bottom GPT-5.4 efficiency of 33.5%, this corresponds to a 79.4% relative enchancment — or 26.6 absolute factors.
Price Evaluation
Claude Opus 4.7 is extra environment friendly within the variety of steps to unravel every job (imply 21.9 steps) in comparison with GPT-5.4 (imply 26.3 steps). Nonetheless, Claude Opus 4.7 is priced considerably greater in comparison with GPT-5.4 ($5 vs. $2.50 per 1M enter tokens, and $25 vs. $15.00 per 1M output tokens, April 2026), which makes the common per-task price greater in comparison with GPT-5.4 ($2.37 vs. $6.09). The primary 50 steps ship 82% accuracy, and the following 50 steps ship 3–4 further factors.
Small Mannequin Efficiency
The analysis crew additionally examined Qwen3.5-9B on the laborious cut up of On-line-Mind2Web. When duties are augmented with pre-built reusable software scripts, Qwen3.5-9B achieves 66.2% on On-line-Mind2Web web sites with greater than 5 instruments. This exhibits that smaller, lower-cost fashions can deal with advanced net duties when paired with a pre-built software library.
Marktechpost’s Visible Explainer
Webwright
Fast Begin Information
What Is Webwright?
Webwright is an open-source, terminal-native net agent framework from Microsoft Analysis. As a substitute of predicting one browser click on at a time, the agent writes Playwright code, runs bash instructions, and shops reusable scripts in an area workspace.
- ~1,000 strains of harness code throughout 3 modules — no hidden orchestration
- Single agent loop: Runner, Mannequin Endpoint, and terminal Atmosphere
- 86.7% on On-line-Mind2Web | 60.1% on Odysseys with GPT-5.4
- Backends: OpenAI, Anthropic, OpenRouter
- Scripts reusable in Claude Code, Codex, OpenClaw
# GitHub repository
github.com/microsoft/Webwright
What You Want Earlier than Putting in
Verify the next are prepared earlier than working any set up instructions.
- Python 3.10+ — required minimal runtime
- Chromium — put in by way of Playwright within the subsequent step
- API key — OpenAI, Anthropic, or OpenRouter
- Git — to clone the repository
# Verify your Python model python --version # Should return Python 3.10 or greater
Clone and Set up Webwright
Clone the repo, set up in editable mode, then set up Chromium for Playwright browser management.
# 1. Clone the repository git clone https://github.com/microsoft/Webwright cd Webwright # 2. Set up the bundle in editable mode pip set up -e . # 3. Set up Chromium for Playwright playwright set up chromium
The -e flag means native supply edits apply instantly with out reinstalling.
Run Your First Net Activity
Export your API key, then go a job instruction and begin URL to the CLI.
# Export your key export OPENAI_API_KEY="sk-..." export ANTHROPIC_API_KEY="sk-ant-..." # Run a job python -m webwright.run.cli -c base.yaml -c model_openai.yaml -t "Discover most cost-effective economic system flight SEA to JFK on 2026-05-15" --start-url https://www.google.com/flights --task-id demo_openai -o outputs/default
| Flag | Description |
|---|---|
| -c | Config file from src/webwright/config/ — stackable |
| -t | Activity instruction in plain English |
| –start-url | Preliminary URL for the browser session |
| –task-id | Output subfolder identify |
| -o | Root output listing for logs and scripts |
Use Webwright as a Claude Code Ability
Webwright ships a built-in Claude Code ability. No separate LLM API key’s wanted past your Claude Code subscription. Claude Code reads PNG screenshots natively.
# Undertaking-scoped (inside this repo solely) mkdir -p .claude/abilities .claude/instructions ln -s "$PWD/abilities/webwright" .claude/abilities/webwright ln -s "$PWD/abilities/webwright/instructions" .claude/instructions/webwright # Consumer-scoped (all tasks) mkdir -p ~/.claude/abilities ~/.claude/instructions ln -s "$PWD/abilities/webwright" ~/.claude/abilities/webwright ln -s "$PWD/abilities/webwright/instructions" ~/.claude/instructions/webwright
Restart Claude Code after putting in, then use slash instructions:
# One-shot job /webwright:run search Google Flights SEA to JFK 2026-05-15 # Reusable parameterized CLI software /webwright:craft search a ticket from LAX to SFO depart June 7
Key Takeaways
- Webwright makes use of a terminal loop the place the agent writes and runs Playwright code as an alternative of predicting one browser motion at a time.
- GPT-5.4 reached 86.7% on On-line-Mind2Web (100-step price range) and 60.1% on Odysseys — 26.6 factors above the bottom GPT-5.4 rating of 33.5%.
- The harness is ~1,000 strains throughout three modules with no multi-agent orchestration.
- Qwen3.5-9B reached 66.2% on the laborious cut up of On-line-Mind2Web when augmented with pre-built software scripts.
- Activity scripts are packaged as reusable CLIs, shareable throughout Claude Code, Codex, and OpenClaw.
Try the Repo and Technical particulars. Additionally, be happy to observe us on Twitter and don’t overlook to hitch our 150k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
Must accomplice with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so forth.? Join with us