

{kind=link}
That is from a moderated dialogue on the NBER Functions of AI in Healthcare assembly that occurred in Cambridge, Massachusetts Could eighth, 2026. The panel consisted of Kosali Simon, Scott Cunningham, David Bradford, and Coady Wing. This can be a writeup of the occasions and contains retrospective commentary by Emily Beam, Jason Fletcher and Paul Goldsmith-Pinkham.
Two days into the NBER’s spring assembly on how AI is affecting the supply and group of well being care, a gaggle of us sat down to speak about how AI is affecting the way in which economists do their work. It’s already clear that expertise is altering how analysis is produced, how it’s reviewed, and the way it’s taught. It’s beginning to have an effect on the way in which our establishments steadiness analysis wants and information privateness dangers. Now we have not but had a convention season but to soak up these new instruments. We’re fairly positive we’re at first of a really steep curve.
Take-aways:
The marginal value has fallen, and we have no idea what which means but
Scott Cunningham opened by pointing to the Autonomous Coverage Evaluation (APE) venture that’s being run out of the Social Catalyst Lab on the College of Zurich. As of April 13, the venture had generated 1,000 “autonomously written analysis papers”, which had been drawn from a pool of greater than 3,000 concepts. There’s a distribution of high quality among the many AI written papers. However it’s already clear that they aren’t hallucinations. The brokers pose a query, choose an identification technique, pull publicly obtainable information, write scriptable R code, run robustness checks, and produce a 20- to 25-page manuscript, with all the pieces (papers, code, information, failures, GitHub repo) made public.
Within the analysis section of the venture, autonomous papers compete head-to-head towards 43 printed AER and AEJ: Coverage benchmark papers, in matches judged by Gemini 3.1 Flash Lite prompted as a top-journal editor. Greater than 18,000 matchups have been performed to date. The typical scores of the autonomous papers sit effectively beneath the human benchmarks, however the precise tail is the story. The highest autonomous papers are incomes scores in the identical vary as printed work in AER and AEJ.
That is the half that we predict most economists are nonetheless underestimating. A submission-quality manuscript just isn’t the identical factor as a publication, and it isn’t the identical factor as information. However the precise tail of what AI brokers can now produce — finish to finish, autonomously — is already crossing into the distribution of peer-reviewed work in top-tier journals.
Scott put it bluntly: if he had been keen to spend $20,000 a yr and had no scruples, he might swarm well being economics with working papers. Since this was theoretically doable, Scott famous then that the one factor stopping anybody from doing this might be restraint on the a part of the researcher, versus incapacity to take action. It isn’t clear that traditionally researchers would have felt restraint in sending manuscripts to journals given the stakes at play, and it’s unclear how a lot restraint shall be exercised now, by how a lot, and by whom. However insofar as there is a rise, then relying on its magnitude, determining the way to take in, evaluate, and distribute all of those papers may very well be a serious problem for the economics career.
One under-discussed twist: reasoning fashions like Claude Code preserve a operating JSON log of each alternative they made on the way in which to a consequence. Scott has been studying these logs and finds that they’re stuffed with specification looking. Telling the mannequin {that a} literature finds destructive employment results of the minimal wage seems to make it quietly abandon specs that time the opposite method. None of this exhibits up in a pre-registration. None of it’s seen to a referee. The recordsdata are trivially edited or deleted. We don’t but have norms or instruments that catch this. (Commenter Jason Fletcher’s current publish on the t-statistic distributions in APE papers, choosing up on Scott’s earlier evaluation, is likely one of the few public makes an attempt to take a look at this systematically.)
What this does to look evaluate
David Bradford spoke as editor of Well being Economics. His journal receives about 1,300 submissions a yr. Lots of the papers he desk-rejects are competently executed analysis with out main methodological or technical errors. He rejects them as a result of they merely should not well being economics or should not fascinating sufficient for the journal. The papers could also be a greater match for scientific or well being companies analysis journals. Such judgements have already got a component of subjectivity that Bradford is typically uncomfortable with however doesn’t see every other solution to handle submissions and scarce peer reviewer provide. And lots of papers have clear tipoffs that they aren’t a great match for well being economics: construction and formatting and writing kinds which might be extra widespread in medical journals or well being companies analysis journals, for instance. However AI threatens the editorial desk rejection filter, which depends closely on his personal time to take a look at every paper and make judgement calls. It’s now a trivial matter to make use of AI to transform a manuscript that didn’t begin out as well being economics into one that’s organized and written in order that it “seems to be like all the pieces printed on this journal for the previous ten years”. This may make it a lot more durable for editors to effectively decide what papers seem in-scope for the journal.
It’s very doable that would result in a 30 % enhance in papers that seem at preliminary editor learn to be doubtlessly a match for the journal. A 30 % enhance in not-obviously-desk-rejectable submissions might severely pressure present peer-review workflows. A 50 % enhance or a doubling can be catastrophic with out some vital adjustments. Journals at the moment invite seven to 9 referees to get two reviewers to agree to simply accept the task. That math doesn’t survive an actual flood.
David is convening eight health-economics journal editors on the ASHEcon assembly this summer time to start a dialog about harmonizing positions on AI-assisted submissions. Authors want readability about what’s allowed the place. Editors have to suppose truthfully about whether or not people will nonetheless be capable to have a look at all the pieces, or whether or not AI help in evaluate turns into unavoidable.
He may even be operating an experiment at Well being Economics. Editors shall be offered anonymized manuscripts which have already been processed together with both the 2 unique referee studies or one unique referee report and one new AI generated report. The purpose is to check whether or not their choices will differ.
Extra papers or higher papers?
Coady Wing identified that the flood has not really occurred but. It’s doable that the expertise, utilized by individuals who already cared about doing good work, is producing higher papers in addition to extra papers. Iteration that used to take months of time with aresearch assistant now takes ninety minutes in your individual workplace. The replication package deal is mainly at all times updated since you by no means needed to assemble it after the very fact.
One-shot autonomous papers could also be a curiosity. Studying them is extra like studying a paper written by another person than like studying your individual work, as a result of you haven’t lived by the judgment calls. What will we do with 1000’s of papers that no human creator has actually thought of? A tree falling in a forest with nobody to listen to it? Some researchers will probably use AI instruments to tackle tasks or sub-analyses that will have been too expensive earlier than. The optimistic prediction is that buyers of empirical economics will begin to demand extra of producers. Our requirements will shift in order that papers shall be distributed with clear replications packages, better-documented code, Public-use or sharable information wherever doable. In a subject the place a few of the most fun work makes use of restricted-access information, the norm of non-shareable information might grow to be more durable to defend.
Whether or not the sector heads towards “extra” or “higher” just isn’t actually a expertise query. It’s an incentives query, which suggests it’s a tenure query.
The restricted-data drawback
Well being economists usually use restricted use information, akin to insurance coverage claims from Medicare, Medicaid, or non-public insurance coverage, Important Statistics recordsdata on births and deaths, or digital medical information from giant well being care techniques. The contracts that govern theuse of those information usually comprise strict guidelines about the place the information should be saved and analyzed. Transferring information a third-party server like AI service is often prohibited. In some instances, contracts are silent on AI itself however prohibit disclosure and switch in ways in which make it laborious to make use of a 3rd celebration AI instrument like claude code or codex. Resolving these issues is a serious challenge for well being economists.
Kosali Simon laid out three choices that researchers and distributors might take into account, now or sooner or later:
-
Containerized Growth With AI and Artificial Information. The information resides in a safe atmosphere, unreachable by AI instruments. The code base is developed utilizing AI instruments with artificial information that mimics the construction of the true information. Then the code is run individually on the true information. Domestically Hosted Open Weight Fashions. Researchers use native hosted AI instruments to help evaluation and code growth with full entry to the information. This method complies with privateness requirements set out in typical information use agreements as a result of the domestically hosted AI fashions are run contained in the safe atmosphere with no outbound calls. Openweight fashions are decrease high quality than fronteir AI fashions, however the high quality of the openweight fashions has continued to enhance and at some pointthey could also be completely sufficient to the duties of most researchers. This can be a actual choice, however it require substantial GPU capability which may be possible at some universities and never others. Vendor-secured platforms with Enterprise Affiliate Agreements (BAAs) in place. Universities have began to discover new contractual preparations to make it doable to question frontier AI instruments utilizing safe strategies. For the second, that is an costly and sluggish choice, however it might grow to be commonplace over time.
An viewers member instructed that artificial, privacy-preserving variations of the underlying information is apt to grow to be more and more essential. The privacy-protection work accomplished round census information is the apparent precedent. A hybrid model can also be interesting: you develop your replication package deal on artificial information, and the company runs it on the true information and returns the tables. You by no means contact the uncooked information, however you get actual outcomes. The talent curve for writing the required code has fallen sharply, which makes this method extra possible than it was even two years in the past.
That is additionally the place the institutional infrastructure query issues. For the second, the compute prices related to querying frontier AI fashions is closely sponsored by AI companies and their buyers. This may probably change over time and AI associated compute prices might grow to be a key a part of analysis budgets. Smaller establishments threat being priced out of formidable empirical if it is extremely computationally intensive. This can be an area for grant funders to make sure that AI instruments result in an enlargement of the researcher bench relatively than a narrowing.
Verification, attribution, and what publication is for
The thread operating by the dialogue was the hole between mechanics and concepts. AI is superb on the mechanics: writing the code, formatting the tables, discovering technical errors, constructing the appendix. It isn’t but working on the stage of human ideation about what’s value learning. Which means evaluate processes constructed to catch technical errors are about to grow to be much less discriminating, as a result of technical errors shall be rarer. The factor referees and editors really need to guage, and have traditionally been least snug evaluating, is whether or not a paper is fascinating and essential.
David put this plainly. He has at all times struggled to reject a paper only for being uninteresting and infrequently seems to be for technical flaws as cowl. As technical flaws skinny out, the sector has to study to say “that is well-executed however not essential” with out embarrassment.
An viewers member raised a associated concern. The educational publication course of has is partly a labeling train. Publication in a high-quality journal is a stamp that claims “this paper is actual and top quality” and universities use the stamp as proof for hiring, promotion, and retention of school. Going ahead, these attribution issues might grow to be extra expensive as a result of the underlying work is less complicated to automate. Possibly the response is to shift again towards direct suggestions from human consultants and away from the stamp. None of us have a transparent plan for that, however the query is now on the desk.
We additionally want to debate the way to prepare college students who’re going to make use of these instruments. The bottleneck papers that used to disclose whether or not a scholar might suppose like a researcher at the moment are writable by an agent in a day. We want new diagnostics.
The place we landed
Three issues we agree on, although we have no idea what to do about any of them:
-
The manufacturing aspect of empirical analysis has decoupled from the verification aspect. Manufacturing scales. Verification, as at the moment organized, doesn’t.
-
Restricted-data norms and AI tooling are on a collision course, and the reply might be not “no AI.” It’s most likely some mixture of native open-weight fashions, privacy-preserving artificial information, and submission pipelines that ship code to information relatively than information to code.
-
Incentives, not expertise, will resolve whether or not AI makes the sector higher or simply greater. Departments that rely papers will get extra papers. Departments that learn them will get higher ones.
We’re on the child stage of all of those conversations. Will probably be fascinating to be in the identical room in six months and see what has moved.
Please see https://franklythecounterfactual.substack.com/publish/publish/198301947 for the complete transcript of the Could 8th NBER Panel.
Three commentaries
We requested three economists who’ve been writing publicly and thoughtfully about these inquiries to react to the panel. Their responses comply with.
Emily Beam
The panel thoughtfully navigates a number of themes which have come up in my very own discussions with economists about AI: nice pleasure alongside a way of dread, a sense of urgency, and an open query about who this expertise in the end serves. I wish to give attention to that final piece.
One theme from the panel is that extra analysis manufacturing is, on internet, a menace. The verification concern is actual. Peer evaluate doesn’t scale the way in which manufacturing does, and the hole between work that seems to be like a contribution and work that is one is getting more durable to see. But when we imagine that what economists produce is helpful information, and that information is a public good, then a expertise that lowers manufacturing prices isn’t inherently zero-sum. The response to a verification hole shouldn’t be to limit who will get to provide, however to put money into the norms, coaching, and establishments that preserve judgment on the middle.
One group that stands to learn significantly from AI is researchers with some however not all the assets: economists with heavy instructing or service masses and restricted RA help, who’ve well-developed analysis agendas and the experience to pursue them. For this fairly giant group, AI relaxes a number of binding constraints. However proper now, loads of researchers don’t or can’t entry these instruments in any respect. However proper now, loads of researchers can’t entry these instruments as a result of they lack assets, want help to retool, or work at establishments that prohibit AI utilization. If we’re critical about economics as a worldwide self-discipline, the entry query can’t cease at R1 departments.
As Coady notes, the flood hasn’t really occurred but. Retooling is genuinely laborious, particularly when it means accepting that abilities you spent years constructing now matter much less. Probably the most frequent engagement I’ve seen is colleagues making an attempt to AI-proof programs or automating busywork, that are essential however fall in need of rethinking analysis manufacturing. This slower adoption curve means the window for deliberate norm-setting is wider than it’d look. However with out higher information on what the broader career is definitely doing, early adopters find yourself driving the dialog.
This connects to a query about what we worth. If our publication system exists to floor analysis more than likely to remodel our understanding, we should always welcome instruments that permit extra folks contribute to that purpose. Extra retailers and totally different incentives could also be wanted. If it capabilities primarily as a match—figuring out who’s the very best at doing economics—then AI disrupts the sign, and the temptation shall be to limit relatively than adapt.
From my very own work coaching college students and researchers to work with AI analysis instruments (together with Considering with Brokers, with Erkmen Aslim), the expertise isn’t the laborious half. Altering how you’re employed is. Some researchers bolt AI onto present workflows and discover it ineffective; others undertake with out adapting their judgment. Underestimating how laborious and heterogeneous the transition is dangers constructing insurance policies that may tackle unhealthy actors however fail to herald the remainder of the career. And coaching questions go effectively past doctoral college students. The a lot bigger group of undergraduate and grasp’s college students heading into enterprise, coverage, and authorities wants the judgment and expertise to work alongside these instruments responsibly.
A few of this work is already underway, akin to Bradford’s work to convene journal editors. We additionally want organizations just like the AEA to put money into skilled training, collect higher information on what the broader membership wants, and supply clearer steering for establishments starting from departments to IRBs. None of this can be a full reply, however it strikes us from figuring out the issue to constructing the infrastructure that retains the career advancing.
Jason Fletcher (College of Wisconsin-Madison)
I actually loved the dialogue and the feedback. I believe the dialogue raised the precise points.
A pair points I seen and have feedback on are about Scott’s level on one-shot papers and verification; the panel’s define on AI could also be built-in into analysis, and a pair notes on information use restrictions and AI integration.
A pair overarching assumptions/observations. On “one-shot” AI papers, I believe we imply many various issues once we speak about AI generated papers. As I’ve outlined, I believe these papers are both not really one-shot (i.e. there may be lots of, doubtlessly unknown, context from the person) or of fairly low high quality. This isn’t to say that there are not any researchers who may grow to be dominated by ‘true’ one-shot papers. I believe we are going to (and will) insist that papers have a human proprietor/voucher–so that ‘verification’ points fall to the human proprietor. In distinction to a few of the panel dialogue, I can envision a fairly restricted ‘new’ function of journals right here. I believe the human ‘proprietor/voucher’ would comply with present apply when RAs are a part of the paper manufacturing. With this insistence, journals haven’t any further challenge to think about with AI-assisted analysis round verification (the buck stops with the voucher), although journals might have to revamp and rethink their investments in post-publication errata and retractions.
However, to me, by far the larger level is that AI-assisted papers can increase most researcher manufacturing capabilities. Three variations of this come to thoughts: (A) Partial/Full Substitute for RAs: Many researchers have restricted entry to RAs, so AI-as-RA is model new and only a bonus. For these with RAs, there’s a core tradeoff across the public good side of coaching your division’s college students and the probability that the AI is best than an RA on most duties. Subsequently, I believe coaching of the subsequent technology of researchers is unsure—a shrinking of PhD slots might the truth is be a helpful end result in lots of fields. I’ve heard some speak about combining RAs with AI to supercharge analysis labs and ration out the PI’s restricted consideration. It’s not clear to me how we mix the general public good side of RA coaching with this specific use of already-trained RAs (as untrained RAs are AI passengers relatively than drivers). (B) Partial/Full Substitute for co-authors: Maybe co-authorship shall be extra of a luxurious than present use patterns—it’s not clear what the pure-research-efficiency story is that will counsel co-authorships would proceed to type. Possibly there’s a senior/junior alignment the place the senior particular person provides the “researcher style” and expertise and the junior researcher drives the AIs (i.e. senior doesn’t should cope with the AI fireplace hose) and in flip generates extra talent growth in style. However the instances of two junior (or two senior) co-authors are unclear to me, what are the features from commerce right here? (e.g. present pairs generally give attention to the empirics or the writing of the venture, however it looks as if AI is a close to good substitute right here). (C) Partial Substitute for You. Right here the concept is about leveling up the sub-set of abilities that AI brokers are good at, together with coding, evaluation, and writing. Maybe even concept technology and execution. Although, on this latter case, the AI is the driving force and the PI is the passenger, such that there’s nothing particular concerning the output (see my level above about one-shot papers) and this must be ‘bid down’ to having zero profit as journals regulate. As David and others on the panel mentioned, a key challenge is that gatekeepers should be capable to set the bar excessive sufficient that these papers are screened out–right now, many journals don’t enable the usage of AI as a display screen for editors or reviewers. I think this coverage will change fairly rapidly. A key maintained assumption I’ve is that some researchers can’t be completely substituted for (i.e. human concepts/style will proceed to dominate AI concepts/style), and these researchers produce high quality above the brink (with or with out AI help). I do suppose there’s a constraint on variety of applied concepts for an higher tail of researchers that will have fairly massive payoffs following AI-integration (together with letting AI kill off tasks that gained’t work).
Lastly, just a few ideas on points with information use settlement prohibitions on AI-assisted analysis. These had been mentioned by the panelists and viewers members, so I’ll make some transient notes. First, creating artificial variations of actual information to make use of AI-assistance. I fear that the usefulness of AI is degraded when utilizing artificial information. This apply takes off the desk “AI discovery” use-cases, as a result of AI would usually be basing discoveries on noise within the information (overfitting). One of many key benefits of AI-assistance is the rapidity of revising code and chugging by analyses, tables, figures, and so forth on the fly, and that is all off the desk—or a minimum of vastly degraded. So the remaining benefit is to only have AI generate your code and import it into your workspace (after somebody’s evaluate, presumably), which remains to be considerably helpful, however a really small proportion of the doable features from AI-assistance. Second, I’d guess towards native/open weight fashions as the answer. Possibly an open weight “Stata grasp LLM” can be useful (however nonetheless has challenge of not being allowed to question the web for solutions (?). I fear that the fastened value challenge of a college (or division) particular open weight mannequin is simply too excessive (vs. the payoff) to get a lot traction on this within the close to future. I don’t doubt that some universities will throw some cash on this path beneath the umbrella on interdisciplinary scholarship, however the fashions appear too bespoke to me to be ‘the’ reply. Third, the vender secured platform is of curiosity. My guess is that this shall be hit or missand nowhere close to a common choice attributable to college insurance policies and value. Particular person investigators would wish to weigh whether or not the hassle/expense of setting these agreements up (and compliance) is near the price of simply (over)paying RAs to do the work at regular pace. Outdoors of those three choices (artificial information, open fashions, industrial merchandise), I stay a bit extra hopeful of a yet-undiscovered answer that aligns extra with our extra typical restricted-vs-public variations of information might emerge as a solution. Lastly, maybe an apparent level is that, a minimum of within the brief time period, there shall be a big push towards utilizing information that may be built-in with Agentic AI.
Paul Goldsmith-Pinkham (Yale)
There’s a Chinese language curse which says “Could he stay in fascinating occasions.” These are occasions of hazard and uncertainty; however they’re additionally probably the most inventive of any time within the historical past of mankind.
Robert F. Kennedy (1966, College of Capetown)
We stay in fascinating occasions. Economists’ analysis manufacturing is altering quick, and the impulse to nihilism is powerful. My response to the panel rests on two factors: agentic AI’s trajectory is genuinely unsure, and when AI accelerates the analysis pipeline, it amplifies the significance of the human frictions that stay.
The determine above replicates the graph made by the non-profit METR (Mannequin Analysis & Risk Analysis), which benchmarks the time that it takes totally different AI fashions to do duties (“the 50%-time horizon is the period at which an agent is predicted to succeed half the time”). The METR benchmarks make a convincing case that functionality development is exponential. However the error bounds widen because the horizon extends — any economist forecasting exponentials will sympathize — and the mapping from benchmark to real-world disruption is tough.
On the pipeline, I believe analysis is finest described by an O-ring manufacturing operate within the type of Kremer (1993): output is the product of enter qualities, so one weak enter drags the entire chain down. If AI is superb at some duties (code, tables, technical errors) and weaker at others (ideation, writing, presentation), people nonetheless anchor the weak hyperlinks. There’s additionally a friction Kremer doesn’t mannequin: doing the human components effectively will get more durable in case you performed no function within the AI-handled components. Understanding what your agent did is itselfcostly time.
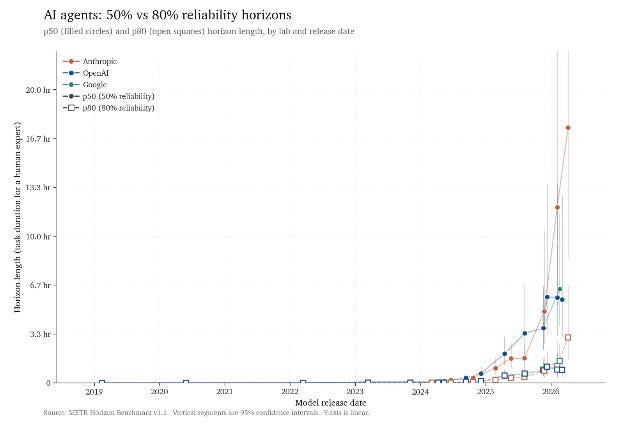
The forecasting query, then, is how reliably AI handles every enter. The usual METR benchmark makes use of 50% reliability — probably a poor enter to an O-ring chain. The 80%-reliability sequence can also be rising (plotted with the 80% reliability measure above), however from a a lot decrease base and with comparable uncertainty. Whether or not reliable-enough duties increase rapidly is the important thing query for analysis manufacturing.
I’m skeptical of Scott’s paper-farm state of affairs. Reputational norms stop any researcher from credibly flooding their CV with lots of of papers, and even in fields the place paper counts dwarf ours, there may be nonetheless an expectation that researchers perceive their very own work. The deeper dialog — what’s publication for, what will we worth in analysis — predates LLMs. Agentic AI has lowered the price of producing the floor artifact so quick that the query is now unavoidable, and dealing by it is going to be wholesome.
I’ll finish with a concrete instance, from work with Alex Zentefis on radiologists. We learn scan studies to determine diagnoses and distinguish continual from acute PE. This is able to have been prohibitively expensive 5 years in the past. As we speak it’s trivial on the native LLMs the hospital system has on its analysis servers. The set of possible questions has expanded.
So: beware nihilism. Returning to RFK, these are occasions of hazard but additionally of bizarre inventive risk. The fascinating query is which issues we select to deploy these instruments towards.
[I develop the O-ring framework and the stage-by-stage view of the research pipeline more fully in a longer post here.]