

{kind=link}
Seismic information evaluation is an integral part of vitality exploration, however configuring complicated processing workflows has historically been a time-consuming and error-prone problem. Halliburton’s Seismic Engine, a cloud-native utility for seismic information processing, is a robust software that beforehand required handbook configuration of roughly 100 specialised instruments to create workflows. This course of was not solely time-consuming but in addition required deep experience, doubtlessly limiting the accessibility and effectivity of the software program.
To deal with this problem, Halliburton partnered with the AWS Generative AI Innovation Middle to develop an AI-powered assistant for Seismic Engine. The answer makes use of Amazon Bedrock, Amazon Bedrock Information Bases, Amazon Nova, and Amazon DynamoDB to remodel complicated workflow creation into conversations. Geoscientists and information scientists can configure processing instruments by way of pure language interplay as an alternative of handbook configuration.
On this put up, we’ll discover how we constructed a proof-of-concept that converts pure language queries into executable seismic workflows whereas offering a question-answering functionality for Seismic Engine instruments and documentation. We’ll cowl the technical particulars of the answer, share analysis outcomes exhibiting workflow acceleration of as much as 95%, and talk about key learnings that may assist different organizations improve their complicated technical workflows with generative AI.
Our collaboration with AWS has been instrumental in accelerating subsurface interpretation workflows. By integrating Amazon Bedrock providers with Halliburton Landmark’s DS365 Seismic Engine, we have been in a position to cut back historically time‑consuming workflow‑constructing duties by an order of magnitude. This generative AI–powered workflow assistant not solely improves effectivity and accuracy but in addition makes our superior geophysical instruments extra accessible to a broader vary of customers. The scalable cloud‑native structure on AWS has enabled us to ship a seamless, conversational expertise that essentially improves productiveness throughout subsurface workflows.
— Phillip Norlund, Supervisor of Subsurface Applied sciences, Halliburton Landmark
— Slim Bouchrara, Senior Product Proprietor of Subsurface R&D, Halliburton Landmark
Resolution overview
Our venture aimed to handle two key targets: remodeling pure language queries into executable seismic workflows, and offering an clever query and reply (Q&A) system for Seismic Engine documentation. To attain this, we developed an answer utilizing Amazon Bedrock that allows geoscientists to work together with complicated seismic instruments by way of pure dialog.The spine of our system is a FastAPI utility deployed on AWS App Runner, which handles consumer queries by way of a streaming interface. When a consumer submits a question, an intent router powered by Amazon Nova Lite analyzes the request to find out whether or not it’s in search of workflow era or technical data. For Q&A requests, the system makes use of Amazon Bedrock Information Bases with Amazon OpenSearch Serverless to offer related solutions from listed documentation. For workflow requests, a era agent utilizing Anthropic’s Claude on Amazon Bedrock creates YAML workflows by deciding on from 82 out there Seismic Engine instruments.
To keep up context and allow multi-turn conversations, we built-in Amazon DynamoDB for chat historical past and interplay logging. The system helps streaming responses for each Q&A and workflow era, offering fast suggestions to customers because the system processes their requests. This structure permits complicated technical workflows to be created and modified by way of pure dialog, whereas sustaining the exact management required for seismic information processing. The next diagram illustrates the answer structure.
Question routing and intent classification
After the consumer’s question is supplied to the system, the Intent Router classifies the intent label of the given question by calling Amazon Nova Lite by way of the Amazon Bedrock API. The big language mannequin (LLM) is given a immediate to provide one among three intent labels: “Workflow_Generation”, “QnA”, and “General_Question”.The “Workflow_Generation” label is used to route queries associated to workflow era, together with studying/loading datasets, information processing operations, and numerous requests involving manipulating particular datasets. The “QnA” intent label is used for questions associated to particular instruments, requests for pattern workflows, or questions on Seismic Engine documentation. The “General_Question” label is reserved for queries unrelated to Seismic Engine operations or workflows.In our implementation, Amazon Nova Lite carried out the routing process effectively, providing an excellent steadiness between accuracy and latency.
Query answering implementation
The Q&A element handles Seismic Engine-related queries by utilizing Amazon Bedrock Information Bases, a totally managed service for end-to-end Retrieval Augmented Technology (RAG) workflow. We selected Bedrock Information Bases as a result of it alleviates the operational overhead of managing vector databases, chunking methods, and embedding pipelines. As a totally managed service, it handles infrastructure scaling, safety, and upkeep routinely, in order that our group might deal with answer growth relatively than RAG infrastructure operations. The service gives native assist for a number of chunking methods together with hierarchical chunking, which maintains parent-child relationships to steadiness granular retrieval with broader doc context.The information sources embrace software documentation markdown recordsdata and Seismic Engine manuals saved in S3. We saved software documentation recordsdata unchunked since they’re comparatively quick, preserving full context for particular person instruments. For longer paperwork like Seismic Engine manuals, we used hierarchical chunking with default settings. We use Amazon Titan Textual content Embeddings V2 for embedding era and OpenSearch Serverless because the vector database. The system additionally shops metadata comparable to file names, URLs, and doc varieties for every listed merchandise for downstream use.For each retrieval and response era, we use Amazon Bedrock Information Bases’ retrieve_and_generate API with Claude 3.5 Haiku because the mannequin. The system helps multi-turn conversations by sustaining session context, and responses are formatted with inline citations for enhanced traceability.
Be aware: This answer was developed and evaluated utilizing Claude 3.5 Sonnet V2 and Claude 3.5 Haiku. Since then, these fashions have been succeeded by Claude Sonnet 4.5 and most not too long ago Claude Sonnet 4.6, in addition to Claude Haiku 4.5, all out there by way of Amazon Bedrock. The answer structure helps mannequin upgrades with out code modifications, so as to use the newest mannequin capabilities.
This method permits our system to offer context-aware, related solutions to consumer queries about Seismic Engine instruments and workflows.
Workflow era
For queries categorised as “Workflow_Generation”, our answer makes use of LLM brokers to transform pure language into executable YAML workflows. The agent is certain with 82 instruments out there on Seismic Engine. Based mostly on the consumer’s question and power specs that outline inputs, parameters, and outputs, the agent selects applicable instruments, determines their appropriate execution order, and generates a YAML workflow that addresses the consumer’s necessities. The next determine illustrates the workflow era course of.
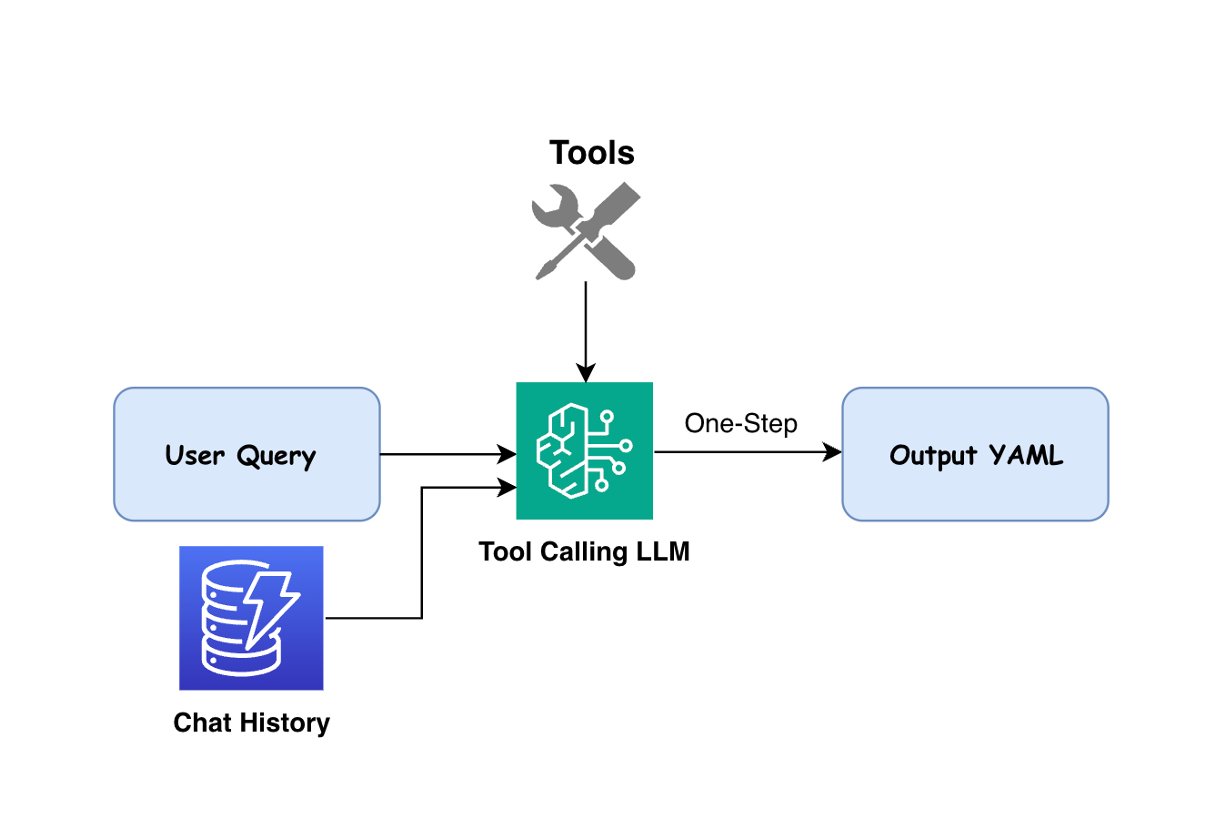
We used each Claude 3.5 Sonnet V2 and Claude 3.5 Haiku in our implementation, orchestrated by way of the LangChain framework for agent administration and power binding. The fashions are supplied with detailed software descriptions and specs, in order that they will perceive every software’s capabilities and necessities. When producing workflows, the system considers not solely the express necessities within the consumer’s question but in addition contains obligatory default parameters when particular values aren’t supplied.The workflow era course of helps multi-turn conversations, in order that customers can modify beforehand generated workflows by way of pure language requests. Through the use of dialog historical past saved in Amazon DynamoDB, the LLM can both generate new workflows or modify current ones in line with the consumer’s present question.
Analysis
To judge our answer’s effectiveness, we created a complete take a look at dataset of query-workflow pairs, consisting of each low and medium complexity workflows. These have been derived from actual historic workflows and validated by material specialists to confirm they precisely signify typical consumer requests.
Workflow era outcomes
| Mannequin | Complexity | Success Price | Imply Technology Time (s) | Median Technology Time (s) |
| Claude Haiku 3.5 | easy | 84% | 8.3 | 5.9 |
| medium | 90% | 12.4 | 9.1 | |
| Claude Sonnet 3.5 V2 | easy | 86% | 11.2 | 11.5 |
| medium | 97% | 15.8 | 16.6 |
Each fashions demonstrated robust efficiency, with Claude Sonnet 3.5 V2 exhibiting superior success charges, notably for medium complexity workflows. The system delivers responses by way of streaming, offering customers with fast suggestions because the workflow is generated, with full workflows delivered inside 5.9-16.6 seconds. Claude Haiku 3.5 provides quicker era instances, offering a trade-off possibility between pace and accuracy.
Comparability to baseline efficiency
| Consumer Sort | % Success | % Failure | Time to Construct Easy Stream (min) | Time to Construct Complicated Stream (min) |
| New Consumer | 70% | 20% | 4 | 20 |
| Skilled Consumer | 85% | 10% | 2 | 5 |
| Our Resolution | 84-97% | 3-16% | 0.13-0.26 | 0.21-0.28 |
Our generative AI answer demonstrates the next enhancements:
- Success charges of 84-97% surpass each new and skilled customers.
- Workflow creation time is diminished from minutes to seconds, representing over a 95% time discount.
These outcomes reveal that customers throughout expertise ranges can improve productiveness by over 95%, whereas sustaining or exceeding the accuracy of handbook workflow creation.
Conclusion
On this put up, we confirmed how we used Amazon Bedrock to remodel complicated technical processes into pure conversations. By implementing an AI-powered assistant with built-in Q&A capabilities, we achieved workflow era success charges of 84-97% whereas lowering creation time by over 95% in comparison with handbook processes. The system’s skill to deal with each low and medium complexity workflows, mixed with its contextual understanding of Seismic Engine instruments, demonstrates how generative AI can enhance industrial software program usability with out compromising accuracy.
This method additionally generalizes nicely to different domains with complicated, multi-step agentic workflows requiring specialised software information and configuration. As subsequent steps, take into account exploring multi-agent architectures utilizing frameworks like Strands Brokers SDK with Amazon Bedrock AgentCore for improved accuracy by way of specialised sub-agents.
In regards to the authors