

{kind=link}
Desk of Contents
- Semantic Caching for LLMs: TTLs, Confidence, and Cache Security
- Why Semantic Caching for LLMs Requires Manufacturing Hardening
- Cache TTL in Semantic Caching: Stopping Stale LLM Responses
- MLOps Venture Construction for Semantic Caching with FastAPI and Redis
- The right way to Implement Cache TTL Validation in Python and Redis
- Confidence Scoring in Semantic Caching: Past Similarity for LLMs
- Implementing Confidence Scoring for LLM Cache Optimization (Code Walkthrough)
- Question Normalization and Deduplication for Environment friendly Semantic Caching
- Stopping Cache Poisoning in Semantic Caching for LLM Programs
- Finish-to-Finish Semantic Cache Hardening: TTL, Confidence, and Security Demos
- Semantic Caching Limitations: Commerce-Offs in LLM Optimization Programs
- Abstract
Semantic Caching for LLMs: TTLs, Confidence, and Cache Security
On this lesson, you’ll learn to harden a semantic cache for LLMs, one of the crucial essential LLMOps patterns for decreasing redundant inference prices, and transfer from a working semantic caching prototype to a system that may survive real-world utilization with TTL validation, confidence scoring, deduplication, and cache poisoning prevention.
This lesson is the final in a 2-part collection on Semantic Caching for LLMs:
- Semantic Caching for LLMs: FastAPI, Redis, and Embeddings
- Semantic Caching for LLMs: TTLs, Confidence, and Cache Security (this tutorial)
To learn to harden a semantic cache for LLMs and make it secure, dependable, and production-ready, simply maintain studying.
Why Semantic Caching for LLMs Requires Manufacturing Hardening
In Lesson 1, we constructed a semantic cache that works end-to-end. It accurately avoids redundant LLM calls, reuses responses for an identical queries, and even handles paraphrased inputs by way of semantic similarity. For a lot of tutorials, that will be the top of the story.
In actual programs, nonetheless, working is simply the place to begin.
A semantic cache that works underneath ideally suited situations can nonetheless fail in delicate and harmful methods when uncovered to actual customers, long-running processes, and evolving data. These failures don’t often seem as crashes or specific errors. As a substitute, they present up as silent correctness points, degraded consumer belief, and unpredictable habits over time.
What Lesson 1 Solved — and What It Didn’t
Lesson 1 centered on the correctness of circulate:
- Requests transfer by way of precise match → semantic match → LLM fallback (technology)
- Cached responses are reused when acceptable
- The system is observable and debuggable
- Nothing is hidden behind abstractions
What it deliberately didn’t handle was long-term security.
We didn’t ask:
- How outdated is that this cached response, and may we nonetheless belief it?
- What occurs if the LLM returns an error or partial output?
- What if the cache slowly fills with duplicates?
- What if similarity is excessive however the reply is now not legitimate?
These questions solely matter as soon as the system runs for days or even weeks, not minutes.
Actual-World Failure Modes in Semantic Caching
Semantic caching introduces failure modes that not often exist in conventional exact-match caches.
For instance:
- A cached reply with very excessive similarity should be stale
- An error response could also be by accident cached and reused
- Slight variations of the identical question might create duplicate entries
- Outdated however related solutions might seem appropriate whereas being subtly improper
None of those points breaks the system outright. As a substitute, they quietly degrade correctness and consumer belief over time.
These are the toughest bugs to detect as a result of the system continues to reply rapidly and confidently.
Why “It Works” Does Not Imply “It’s Protected”
A semantic cache sits instantly within the resolution path of an LLM system. When it makes a mistake, that mistake is amplified by way of reuse.
If an unsafe response enters the cache:
- It may be served repeatedly
- It will probably outlive the situations that made it legitimate
- It may be returned with excessive confidence
That is why semantic caching requires extra self-discipline, not much less, than direct LLM calls.
On this lesson, we’ll take the working system from Lesson 1 and start hardening it. We are going to introduce specific safeguards for staleness, confidence, duplication, and security — with out altering the core structure.
The aim is to not make the system good, however to make its failures managed, seen, and predictable.
That’s the distinction between a demo and a system you possibly can belief.
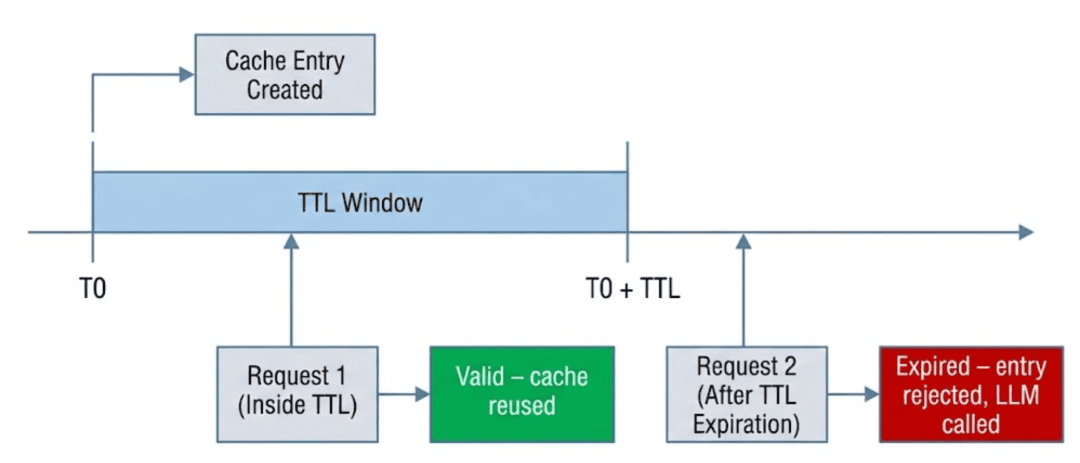
Cache TTL in Semantic Caching: Stopping Stale LLM Responses
As soon as a semantic cache is deployed and begins reusing LLM responses, a brand new query instantly arises:
How lengthy ought to a cached response be trusted?
Not like conventional caches that retailer deterministic outputs, semantic caches retailer model-generated solutions. These solutions are solely legitimate inside a sure window of time and context. With out specific controls, a semantic cache can proceed serving responses which are technically legitimate however virtually improper.
This part explains why cached LLM responses grow to be stale, how TTLs assist, and what it means for a cache entry to be unsafe.
Why Cached LLM Responses Develop into Stale
LLM responses are usually not timeless.
They’re influenced by:
- evolving APIs and libraries
- altering enterprise logic or documentation
- up to date prompts or system habits
- newly launched edge circumstances
A cached reply that was appropriate an hour in the past might now not replicate the present state of the world.
Semantic caching amplifies this danger as a result of:
- responses are reused aggressively
- excessive similarity can masks outdated content material
- cached solutions are returned with confidence
With out staleness controls, the cache slowly turns into a museum of outdated truths.
TTL as a Security Mechanism
A time-to-live (TTL) specifies how lengthy a cache entry stays legitimate.
As soon as the TTL expires:
- the entry is handled as unsafe
- it ought to now not be reused
- a recent LLM response have to be generated
TTL doesn’t assure correctness, however it limits the blast radius of staleness.
In semantic caching, TTL just isn’t an optimization. It’s a correctness safeguard.
Software-Stage TTL vs Redis: EXPIRE
There are 2 frequent methods to implement TTLs when utilizing Redis:
Redis EXPIRE
- Redis routinely deletes keys after a set period
- Expired entries are eliminated totally
- The appliance has no visibility into expired knowledge
Software-Stage TTL (Used Right here)
- Entries stay saved in Redis
- Expiration is checked at learn time by the appliance
- The appliance decides whether or not an entry is secure to reuse
On this system, TTL is enforced on the utility layer relatively than utilizing Redis TTL by way of the native EXPIRE command, a deliberate selection that prioritizes observability over automation.
This selection permits us to:
- examine expired entries throughout debugging
- apply customized expiration logic
- mix TTL with different security alerts (similar to confidence)
We commerce computerized deletion for management and observability.
When a Cache Entry Turns into Unsafe
On this system, a cache entry is taken into account unsafe when any of the next are true:
- its TTL has expired
- its content material is malformed or inaccurate
- its confidence rating falls beneath an appropriate threshold
TTL is the primary and most elementary of those checks.
If an entry fails the TTL test, semantic similarity is irrelevant.
Reusing it could prioritize velocity over correctness.
Designing TTLs for LLM Workloads
There is no such thing as a common “appropriate” TTL for LLM responses.
As a substitute, TTLs needs to be chosen primarily based on:
- how briskly the underlying data modifications
- how expensive incorrect solutions are
- how continuously related queries seem
Quick TTLs:
- cut back staleness danger
- improve LLM calls
Lengthy TTLs:
- enhance cache hit price
- improve danger of outdated responses
In Lesson 1, we used a conservative default TTL to maintain habits predictable. On this lesson, we’ll give attention to how TTLs are enforced relatively than on tuning them for a selected area.
TTL design is a coverage resolution. TTL enforcement is a correctness requirement.
Would you want fast entry to three,457 photographs curated and labeled with hand gestures to coach, discover, and experiment with … totally free? Head over to Roboflow and get a free account to seize these hand gesture photographs.
Want Assist Configuring Your Improvement Surroundings?

All that mentioned, are you:
- Quick on time?
- Studying in your employer’s administratively locked system?
- Eager to skip the effort of preventing with the command line, package deal managers, and digital environments?
- Able to run the code instantly in your Home windows, macOS, or Linux system?
Then be a part of PyImageSearch College immediately!
Achieve entry to Jupyter Notebooks for this tutorial and different PyImageSearch guides pre-configured to run on Google Colab’s ecosystem proper in your internet browser! No set up required.
And better of all, these Jupyter Notebooks will run on Home windows, macOS, and Linux!
MLOps Venture Construction for Semantic Caching with FastAPI and Redis
Earlier than diving into particular person parts, let’s take a second to know how the challenge is organized.
A transparent listing construction is particularly essential in LLM-backed programs, the place obligations span API orchestration, caching, embeddings, mannequin calls, and observability. On this challenge, every concern is remoted into its personal module so the request circulate stays simple to hint and cause about.
After downloading the supply code from the “Downloads” part, your listing construction ought to appear to be this:
. ├── app │ ├── api │ │ ├── __init__.py │ │ └── ask.py │ ├── cache │ │ ├── __init__.py │ │ ├── poisoning.py │ │ ├── schemas.py │ │ ├── semantic_cache.py │ │ └── ttl.py │ ├── config │ │ ├── __init__.py │ │ └── settings.py │ ├── embeddings │ │ ├── __init__.py │ │ └── embedder.py │ ├── llm │ │ ├── __init__.py │ │ └── ollama_client.py │ ├── major.py │ └── observability │ └── metrics.py ├── complete-codebase.txt ├── docker-compose.yml ├── Dockerfile ├── README.md └── necessities.txt
Let’s break this down at a excessive degree.
The app/ Bundle
The app/ listing comprises all runtime utility code. Nothing outdoors this folder is imported at runtime.
This retains the service self-contained and makes it simple to cause about deployment and dependencies.
app/major.py: Software Entry Level
This file defines the FastAPI utility and registers all routers.
It comprises no enterprise logic — solely service wiring. Each request to the system enters by way of this file.
app/api/: API Layer
The api/ package deal defines HTTP-facing endpoints.
ask.py: Implements the/askendpoint and acts because the orchestration layer for the complete semantic caching pipeline.
The API layer is answerable for:
- validating enter
- implementing cache ordering
- coordinating cache, embeddings, and LLM calls
- returning structured debug data
It doesn’t implement caching or similarity logic instantly.
app/cache/: Caching Logic
This package deal comprises all cache-related performance.
semantic_cache.py: Core semantic cache implementation (precise match, semantic match, Redis storage, similarity search).schemas.py: Defines the cache entry schema used for Redis storage.ttl.py: Software-level TTL configuration and expiration checks.poisoning.py: Security checks to forestall invalid or error responses from being reused.
By isolating caching logic right here, the API layer stays clear and reusable.
app/embeddings/: Embedding Era
embedder.py: Handles embedding technology by way of Ollama’s embedding endpoint.
This module has a single duty: changing textual content into semantic vectors.
It doesn’t cache, rank, or validate embeddings.
app/llm/: LLM Consumer
ollama_client.py: Wraps calls to the Ollama text-generation endpoint.
Isolating LLM interplay permits the remainder of the system to stay model-agnostic.
app/observability/: Metrics
metrics.py: Implements easy in-memory counters for cache hits, misses, and LLM calls.
These metrics are deliberately light-weight and meant for studying and debugging, not manufacturing monitoring.
Configuration and Infrastructure
Outdoors the app/ listing:
config/settings.py: Centralizes environment-based configuration (Redis host, TTLs, mannequin names).Dockerfileanddocker-compose.yml: Outline a reproducible runtime surroundings for the API and Redis.necessities.txt: Lists all Python dependencies required to run the service.
The right way to Implement Cache TTL Validation in Python and Redis
Within the earlier part, we mentioned why cached LLM responses grow to be stale and why TTLs are essential. On this part, we transfer from idea to code and have a look at how TTL validation is enforced in apply.
The important thing thought is straightforward however essential:
Cache entries are usually not deleted routinely. They’re validated at learn time.
This design selection retains cache habits specific, observable, and secure.
The Default TTL Configuration
TTL configuration is centralized in a single helper operate:
File: app/cache/ttl.py
def default_ttl():
return settings.CACHE_TTL_SECONDS
Reasonably than hardcoding a price, the TTL is loaded from configuration. This permits totally different environments to make use of totally different TTLs with out altering the code.
At this stage, the particular TTL worth just isn’t essential. What issues is that:
- each cache entry receives a TTL at creation time
- TTL is handled as metadata, not as a Redis function
Checking Whether or not an Entry Has Expired
TTL enforcement occurs by way of a devoted validation operate:
def is_expired(entry):
attempt:
created_at = int(entry["created_at"])
ttl = int(entry["ttl"])
now = int(time.time())
return now > (created_at + ttl)
besides (KeyError, ValueError, TypeError):
return True
This operate solutions 1 query:
Is that this cache entry nonetheless secure to reuse?
If the present time exceeds created_at + ttl, the entry is taken into account expired and should not be reused.
Fail-Protected Expiration Conduct
Discover the exception dealing with on the finish of is_expired().
If the entry:
- is lacking required fields
- comprises malformed values
- can’t be parsed safely
…it’s handled as expired by default.
This can be a deliberate fail-safe design.
When coping with cached LLM responses, silently trusting malformed knowledge is extra harmful than recomputing a response. If the system is uncertain, it expires the entry and falls again to the LLM.
Correctness all the time wins over reuse.
Finest-Effort Cleanup Throughout Cache Reads
TTL validation does greater than reject expired entries — it additionally performs opportunistic cleanup throughout cache searches.
Contained in the semantic cache search logic:
- expired entries are detected
- expired keys are faraway from Redis
- the cache continues scanning remaining entries
This cleanup occurs:
- with out background staff
- with out scheduled jobs
- with out blocking the request
This isn’t a full rubbish collector. It’s a best-effort hygiene mechanism that retains the cache from accumulating junk over time.
Why We Validate on Learn, Not Delete on Write
At this level, a pure query arises:
Why not simply use Redis EXPIRE and let Redis delete entries routinely?
There are 3 causes this technique validates TTLs on learn as an alternative:
- Visibility: Expired entries stay inspectable throughout debugging.
- Management: The appliance decides what “expired” means, not Redis.
- Composability: TTL checks could be mixed with confidence scoring, poisoning detection, and different security alerts.
By validating at learn time, TTL turns into a part of the decision-making pipeline relatively than an invisible background mechanism.
Confidence Scoring in Semantic Caching: Past Similarity for LLMs
Up thus far, semantic caching choices have relied closely on semantic similarity. If a cached response is analogous sufficient to a brand new question, it feels affordable to reuse it.
In apply, this assumption breaks down.
Excessive similarity solutions an essential query — “Is that this response about the identical factor?” — however it does not reply an equally essential one:
“Is that this response nonetheless secure to reuse proper now?”
Confidence scoring exists to bridge that hole.
Why Excessive Similarity Can Nonetheless Be Fallacious
Semantic similarity measures closeness in which means, not correctness over time.
Think about a cached response that:
- has very excessive embedding similarity to the present question
- was generated hours or days in the past
- refers to data that has since modified
From a vector perspective, the response nonetheless seems “appropriate.”
From a system perspective, it could now not be reliable.
This downside is delicate as a result of:
- similarity scores stay excessive
- responses look fluent and assured
- failures are silent relatively than catastrophic
With out an extra sign, the cache has no approach to distinguish related however stale from related and secure.
Combining Semantic Similarity with Freshness
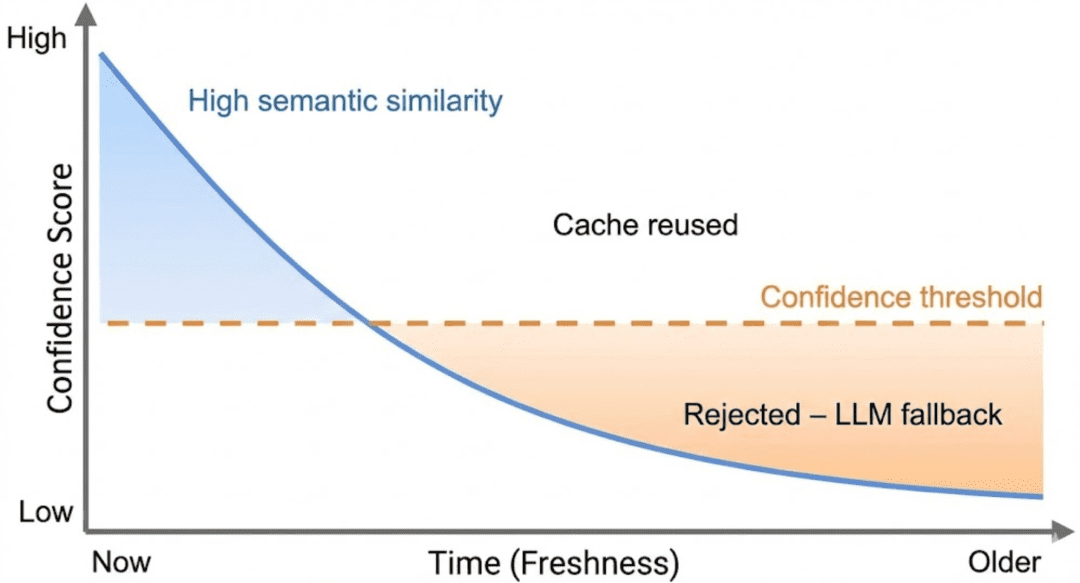
Confidence scoring introduces a second dimension: freshness.
Reasonably than deciding reuse primarily based on similarity alone, the cache evaluates a mixed sign that displays:
- how semantically shut the response is
- how just lately the response was generated
At a excessive degree, confidence solutions the query:
“How snug are we reusing this response proper now?”
Contemporary responses with excessive similarity rating excessive confidence.
Outdated responses, even with excessive similarity, step by step lose confidence as they age.
This ensures that point acts as a pure decay mechanism.
Understanding the Confidence Rating (Excessive-Stage)
On this system, confidence is a weighted mixture of:
- semantic similarity
- freshness relative to TTL
You do not want to consider precise formulation at this stage. What issues is the habits:
- Confidence begins excessive when an entry is created
- Confidence decreases because the entry ages
- Confidence is capped by semantic similarity
- Expired entries all the time fail confidence checks
Confidence just isn’t a chance. It’s a reuse heuristic designed to favor correctness over velocity.
How Confidence Impacts Cache Reuse Selections
Confidence scoring acts as a gatekeeper within the cache pipeline.
Even when:
- the entry just isn’t expired
- the semantic similarity is above threshold
…the cache will reject reuse if confidence falls beneath an appropriate degree.
When this occurs:
- the cache treats the entry as unsafe
- the request falls again to the LLM
- a recent response is generated and saved
This habits ensures that the cache degrades gracefully.
As uncertainty will increase, the system routinely shifts work again to the LLM relatively than returning questionable outcomes.
Why Confidence Belongs within the Cache (Not the LLM)
It’s tempting to push this logic downstream and let the LLM “repair” stale responses.
That method fails for 2 causes:
- the LLM has no context about cache age
- the LLM can not distinguish reused content material from recent inference
Confidence have to be enforced earlier than reuse, not after technology.
By embedding confidence checks instantly into the cache, we be certain that reuse choices are specific, explainable, and controllable.
Implementing Confidence Scoring for LLM Cache Optimization (Code Walkthrough)
Within the earlier part, we launched confidence scoring as a conceptual safeguard: a approach to stop semantically related however stale responses from being reused.
On this part, we make that concept concrete by implementing it.
We are going to stroll by way of the place confidence is computed, the place it’s enforced, and what occurs when a cached entry is rejected.
The place Confidence Is Computed
Confidence is computed contained in the semantic cache, alongside similarity scoring.
def compute_confidence(similarity: float, created_at: int, ttl: int) -> float:
age = time.time() - created_at
if ttl <= 0:
freshness = 1.0
else:
freshness = max(0.0, 1.0 - (age / ttl))
confidence = (0.7 * similarity) + (0.3 * freshness)
return spherical(confidence, 3)
This operate combines 2 alerts:
- Semantic similarity: how shut the meanings are
- Freshness: how latest the response is relative to its TTL
The precise weights are usually not essential right here. What issues is the habits:
- Contemporary, related responses rating excessive confidence
- Outdated responses lose confidence over time
- Expired entries collapse to low confidence
Confidence is due to this fact bounded, decaying, and explicitly outlined.
Why Confidence Is Computed within the Cache
Discover that confidence is computed contained in the cache layer, not within the API.
This ensures:
- all reuse choices are centralized
- confidence logic is utilized persistently
- the API stays an orchestration layer, not a coverage engine
The API doesn’t want to know how confidence is computed — solely whether or not it’s acceptable.
The place Confidence Is Enforced
Confidence enforcement occurs within the request pipeline in ask.py.
elif cached.get("confidence", 0.0) < 0.7:
miss_reason = "low_confidence"
This test happens after:
- precise or semantic matching
- TTL validation
- poisoning checks
And earlier than a cached response is returned.
If confidence is beneath the brink:
- the cache entry is rejected
- the request is handled as a cache miss
- the pipeline falls again to the LLM
This ensures that reuse occurs solely when confidence meets an appropriate threshold.
Why Rejection Is Safer Than Reuse
When confidence is low, the system has 2 selections:
- reuse a response it doesn’t absolutely belief
- generate a recent response
This implementation all the time chooses the second possibility.
The price of an additional LLM name is predictable.
The price of serving an incorrect response just isn’t.
By rejecting low-confidence entries, the cache degrades gracefully as an alternative of failing silently.
What Occurs After Rejection
As soon as a cached entry is rejected:
- the request proceeds to the LLM
- a brand new response is generated
- the brand new response is saved with a recent timestamp and TTL
Over time, this naturally refreshes the cache with out requiring specific invalidation logic.
Making Rejections Observable
Confidence-based rejections are usually not hidden.
They’re surfaced by way of:
miss_reason = "low_confidence"- debug metadata returned to the shopper
- cache miss metrics
This makes it attainable to know why the cache didn’t reuse a response — a important property when tuning thresholds later.
Question Normalization and Deduplication for Environment friendly Semantic Caching
At this level, our semantic cache is secure towards stale and low-confidence responses. Nevertheless, there may be one other failure mode that seems as soon as the system runs for longer durations of time:
The cache slowly fills with duplicate entries characterizeing the identical question.
This downside doesn’t break correctness, however it might probably silently degrade cache high quality and effectivity.
Why Duplicate Cache Entries Are a Downside
In pure language programs, customers not often sort queries the identical manner twice.
Think about the next inputs:
- What’s semantic caching?
- What’s semantic caching
- What is semantic caching?
From a human perspective, these queries are an identical.
From a naïve cache’s perspective, they’re fully totally different strings.
If we retailer every variation individually:
- cache dimension grows unnecessarily
- similarity scans grow to be slower
- cache hit price decreases
- an identical LLM work is repeated
This isn’t a semantic downside — it’s a normalization downside.
Normalizing Queries Earlier than Caching
To stop this, the cache normalizes queries earlier than storing them.
def _hash_query(question: str) -> str:
normalized = " ".be a part of(question.decrease().cut up())
return hashlib.sha256(normalized.encode()).hexdigest()
This operate performs 3 essential steps:
- Lowercasing: Ensures case-insensitive matching
- Whitespace normalization: Collapses further areas and removes main/trailing whitespace
- Hashing: Produces a fixed-length identifier for quick comparability
The result’s a steady illustration of the question’s construction, not its formatting.
Deduplication at Retailer Time
Deduplication occurs when a brand new cache entry is about to be written.
query_hash = self._hash_query(question)
for key in self.r.smembers(f"{self.namespace}:keys"):
knowledge = self.r.hgetall(key)
if knowledge and knowledge.get("query_hash") == query_hash:
return
Earlier than storing a brand new entry, the cache checks whether or not an entry with the identical normalized hash already exists within the cache.
If it does:
- the brand new entry is not saved
- the cache avoids creating a replica
- cupboard space and future scans are preserved
This method ensures that an identical queries map to a single cache entry, no matter how they had been formatted.
Why Deduplication Occurs within the Cache Layer
Deduplication is enforced contained in the cache relatively than within the API layer.
This design ensures:
- all cache writes are normalized persistently
- deduplication logic lives subsequent to storage logic
- API code stays easy and declarative
The API doesn’t have to care how deduplication works — solely that the cache stays clear.
Why Hash-Primarily based Deduplication Works Effectively Right here
Utilizing a hash as an alternative of uncooked strings gives a number of benefits:
- fixed-length comparisons
- environment friendly storage
- no dependency on question size
- sensible collision resistance
For this technique, SHA-256 is greater than adequate. The aim is stability and ease, not cryptographic safety.
What Deduplication Does Not Resolve
It’s essential to know the bounds of this method.
Hash-based deduplication:
- prevents precise duplicates after normalization
- does not merge semantically related queries
- does not exchange semantic caching
In different phrases:
- deduplication retains the cache clear
- semantic similarity retains the cache helpful
They resolve totally different issues and complement one another.
Stopping Cache Poisoning in Semantic Caching for LLM Programs
To this point, we’ve protected the semantic cache towards staleness, low confidence, and duplicate entries. There may be yet another failure mode that may silently undermine the complete system if left unchecked:
Cache poisoning — storing responses that ought to by no means be reused.
Cache poisoning doesn’t often crash the system. As a substitute, it causes the cache to confidently serve unhealthy solutions repeatedly, amplifying a single failure into many incorrect responses.
What Cache Poisoning Seems to be Like in LLM Programs
Within the context of LLM-backed programs, cache poisoning sometimes occurs when:
- the LLM returns an error message
- the response is empty or incomplete
- the output is malformed resulting from a timeout or partial technology
If these responses are cached, each future “hit” returns the identical failure immediately — quick, however incorrect.
That is particularly harmful as a result of:
- the cache seems to be working
- responses are returned rapidly
- the system seems wholesome from the skin
Poisoning Prevention Technique
Reasonably than making an attempt to detect each attainable unhealthy response, this technique makes use of a easy, conservative heuristic:
If a response seems unsafe, don’t cache it.
This retains the logic simple to cause about and avoids false positives.
Detecting Poisoned Entries
Poisoning detection is applied in a devoted helper operate.
def is_poisoned(entry):
resp = entry.get("response", "")
if not resp or resp.startswith("[LLM Error]"):
return True
return False
This operate flags an entry as poisoned if:
- the response is empty, or
- the response is an specific LLM error
These situations are deliberately strict. When doubtful, the entry is handled as unsafe.
The place Poisoning Is Enforced
Poisoning checks are utilized earlier than any cached response is reused in ask.py.
elif is_poisoned(cached):
miss_reason = "poisoned"
If a cached entry is poisoned:
- it’s rejected instantly
- the request is handled as a cache miss
- the pipeline falls again to the LLM
This ensures that invalid responses are by no means reused, even when they’ve excessive similarity or seem recent.
Why Poisoned Entries Are Rejected, Not Repaired
The cache doesn’t try and “repair” poisoned entries.
Attempting to restore cached LLM output introduces:
- ambiguity
- hidden transformations
- unpredictable habits
As a substitute, the system takes the most secure attainable motion:
- reject the entry
- generate a recent response
- overwrite with a clear consequence
This retains the cache habits specific and predictable.
Making Poisoning Seen
Identical to low-confidence rejections, poisoning just isn’t silent.
The reason being surfaced by way of:
miss_reason = "poisoned"- debug metadata returned to the shopper
- cache miss metrics
This makes it attainable to differentiate between:
- semantic misses
- security rejections
- pressured fallbacks
Visibility is a important a part of security.
What This Method Does Not Cowl
This poisoning technique is deliberately easy.
It doesn’t try and:
- analyze response high quality
- validate structured output
- detect hallucinations
- rating semantic correctness
These checks are domain-specific and belong outdoors the cache.
The cache’s duty is slim:
Don’t reuse responses which are clearly unsafe.
Finish-to-Finish Semantic Cache Hardening: TTL, Confidence, and Security Demos
In Lesson 1, we verified that semantic caching works.
On this lesson, we harden that system by watching every security mechanism activate in apply.
The aim of those demos just isn’t efficiency testing.
The aim is behavioral verification.
Every demo isolates one hardening function and makes its impact seen by way of the response payload.
Demo Case 1: TTL Expiration Forces a Cache Miss
Begin by sending a question and populating the cache:
curl -X POST http://localhost:8000/ask
-H "Content material-Sort: utility/json"
-d '{"question": "Clarify semantic caching for LLMs"}'
This primary request falls again to the LLM and shops a brand new cache entry.
After ready longer than the configured TTL, ship the identical request once more:
sleep 61
curl -X POST http://localhost:8000/ask
-H "Content material-Sort: utility/json"
-d '{"question": "Clarify semantic caching for LLMs"}'
Anticipated Conduct
- Actual-match lookup finds an entry
- TTL validation fails
- Entry is rejected
- LLM known as once more
Instance response
{
"from_cache": false,
"debug": {
"hit": false,
"miss_reason": "no_match"
}
}
This confirms that stale responses are usually not reused.
Demo Case 2: Semantic Reuse When Confidence Stays Excessive
Now think about a cached response that’s nonetheless inside TTL and retains adequate confidence.
Ship a semantically related question:
curl -X POST http://localhost:8000/ask
-H "Content material-Sort: utility/json"
-d '{"question": "How does semantic caching cut back LLM calls?"}'
Anticipated Conduct
- Semantic similarity match discovered
- Confidence computed
- Confidence above threshold
- Cached response reused
Instance response
{
"from_cache": true,
"debug": {
"hit": true,
"cache_path": "semantic_match",
"confidence": 0.81
}
}
This demonstrates that semantic reuse is allowed when each relevance and freshness stay acceptable.
Demo Case 3: Failed LLM Responses Are By no means Cached
A secure semantic cache should be certain that failed LLM responses are by no means reused. This demo demonstrates write-time cache poisoning prevention.
This method enforces that rule at write time.
if not response.startswith("[LLM Error]"):
cache.retailer(...)
Solely legitimate responses are ever written to Redis.
How We Display This
We don’t shut down Ollama or the embedding service.
Community failures abort the request earlier than caching logic runs and are usually not appropriate demos.
As a substitute, we simulate an LLM failure.
Step 1: Briefly Simulate an LLM Error
In generate_llm_response():
if "simulate_error" in immediate.decrease():
return "[LLM Error] Simulated failure"
Step 2: Ship a Question
curl -X POST http://localhost:8000/ask
-H "Content material-Sort: utility/json"
-d '{"question": "Simulate error in semantic caching"}'
Anticipated Conduct
from_cache = false- Cache miss
- Error response returned
Step 3: Ship the Identical Question Once more
Anticipated Outcome
- Cache miss once more
- LLM known as once more
- No cached response reused
Why the Miss Cause Is no_match
- Failed responses are by no means saved
- No cache entry exists to reject or consider
- Cache poisoning checks apply solely to present entries
That is intentional and proper.
Demo Case 4: Deduplication Underneath Question Variations
Ship a question with uncommon spacing:
curl -X POST http://localhost:8000/ask
-H "Content material-Sort: utility/json"
-d '{"question": " What is semantic caching? "}'
Then ship the normalized model:
curl -X POST http://localhost:8000/ask
-H "Content material-Sort: utility/json"
-d '{"question": "What's semantic caching?"}'
Anticipated Conduct
- Each queries map to the identical normalized hash
- Just one cache entry exists
- Actual-match reuse happens
Instance response
{
"from_cache": true,
"debug": {
"hit": true,
"cache_path": "exact_match"
}
}
This confirms deduplication is working accurately.
Demo Case 5: Observing Metrics After Hardening
After working a number of demos, examine the metrics endpoint:
curl http://localhost:8000/inside/metrics
Instance response
{
"hits": 3,
"misses": 4,
"llm_calls": 4,
"_note": "In-memory metrics. Reset on restart. Not production-ready."
}
Metrics make it easier to confirm that:
- security rejections improve misses
- LLM calls rise when reuse is unsafe
- the system degrades gracefully
What These Demos Show
Throughout these situations, we verified that:
- Stale entries are rejected
- Low-confidence reuse is prevented
- Poisoned responses are by no means cached
- Duplicate entries are prevented
- Cache habits is observable and explainable
The cache now not optimizes for velocity alone.
It optimizes for secure reuse.
Semantic Caching Limitations: Commerce-Offs in LLM Optimization Programs
By this level, we’ve constructed a semantic cache that’s not solely useful, but additionally hardened towards frequent failure modes: staleness, low confidence, poisoning, duplication, and silent reuse.
Nevertheless, no system design is full with out clearly stating what it doesn’t try to unravel.
This part makes these boundaries specific.
Why This Cache Nonetheless Makes use of O(N) Scans
All semantic lookups on this implementation carry out a linear scan over cached entries.
Which means:
- each semantic search compares the question embedding towards all saved embeddings
- time complexity grows linearly with cache dimension
This isn’t an oversight.
It’s a deliberate design selection made for:
- instructing readability
- transparency
- small-to-medium cache sizes
By avoiding ANN indexes or vector databases, each resolution stays seen and debuggable. You’ll be able to hint precisely why a match was chosen or rejected.
For instructional programs and low-volume providers, this trade-off is appropriate — and sometimes fascinating.
What We Deliberately Did Not Implement
To maintain the system centered and comprehensible, a number of manufacturing options had been deliberately disregarded:
- Approximate nearest neighbor (ANN) indexing
- Redis Vector Search or RediSearch
- Background rubbish assortment staff
- Distributed locks for thundering herd prevention
- Request coalescing or single-flight patterns
- Multi-process or persistent metrics
- Cache warming methods
Every of those provides complexity that will obscure the core concepts being taught.
This cache is designed to clarify semantic caching, to not compete with specialised retrieval infrastructure.
When This Design Is “Good Sufficient”
This structure works effectively when:
- cache dimension is modest (a whole bunch to low 1000’s of entries)
- site visitors is low to reasonable
- correctness and explainability matter greater than uncooked throughput
- you might be experimenting with semantic reuse habits
- you wish to perceive cache dynamics earlier than scaling
Typical examples embrace:
- inside instruments
- developer-facing APIs
- analysis prototypes
- instructional programs
- early-stage LLM purposes
In these contexts, the simplicity of the design is a energy, not a weak point.
When You Want a Vector Database or ANN Index
As utilization grows, linear scans finally grow to be the bottleneck.
You need to think about a devoted vector search resolution when:
- cache dimension grows into tens or a whole bunch of 1000’s of entries
- latency necessities grow to be strict
- a number of staff or providers share the identical cache
- semantic search dominates request time
At that time, applied sciences similar to the next:
- FAISS (Fb AI Similarity Search)
- Milvus
- Pinecone
- Redis Vector Search
grow to be acceptable.
Importantly, the hardening ideas from this lesson nonetheless apply. TTLs, confidence scoring, poisoning prevention, and observability stay related even when the storage backend modifications.
The Core Commerce-Off, Revisited
This lesson intentionally favors:
- readability over cleverness
- specific choices over hidden automation
- security over aggressive reuse
That makes it a great basis, not a ultimate vacation spot.
What’s subsequent? We advocate PyImageSearch College.
86+ whole lessons • 115+ hours hours of on-demand code walkthrough movies • Final up to date: Could 2026
★★★★★ 4.84 (128 Rankings) • 16,000+ College students Enrolled
I strongly imagine that in case you had the precise trainer you can grasp laptop imaginative and prescient and deep studying.
Do you assume studying laptop imaginative and prescient and deep studying must be time-consuming, overwhelming, and sophisticated? Or has to contain complicated arithmetic and equations? Or requires a level in laptop science?
That’s not the case.
All that you must grasp laptop imaginative and prescient and deep studying is for somebody to elucidate issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter training and the way complicated Synthetic Intelligence subjects are taught.
When you’re critical about studying laptop imaginative and prescient, your subsequent cease needs to be PyImageSearch College, essentially the most complete laptop imaginative and prescient, deep studying, and OpenCV course on-line immediately. Right here you’ll learn to efficiently and confidently apply laptop imaginative and prescient to your work, analysis, and initiatives. Be part of me in laptop imaginative and prescient mastery.
Inside PyImageSearch College you will discover:
- &test; 86+ programs on important laptop imaginative and prescient, deep studying, and OpenCV subjects
- &test; 86 Certificates of Completion
- &test; 115+ hours hours of on-demand video
- &test; Model new programs launched frequently, making certain you possibly can sustain with state-of-the-art strategies
- &test; Pre-configured Jupyter Notebooks in Google Colab
- &test; Run all code examples in your internet browser — works on Home windows, macOS, and Linux (no dev surroundings configuration required!)
- &test; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
- &test; Simple one-click downloads for code, datasets, pre-trained fashions, and so on.
- &test; Entry on cellular, laptop computer, desktop, and so on.
Abstract
On this lesson, we took a working semantic cache and made it secure, bounded, and explainable.
Reasonably than specializing in enhancing cache hit charges in any respect prices, we launched guardrails to make sure cached LLM responses are reused solely when they’re reliable.
We added application-level TTL validation to forestall stale responses from persisting indefinitely, mixed semantic similarity with freshness by way of confidence scoring, and enforced specific rejection paths for low-confidence and expired entries.
We additionally addressed delicate however harmful failure modes that seem in actual programs over time. Question normalization and deduplication stop silent cache bloat, and poisoning checks be certain that error responses are by no means reused.
Observability alerts make each cache resolution inspectable relatively than implicit. Collectively, these modifications rework the cache from a efficiency optimization right into a reliability element.
Lastly, we made the system’s limitations specific. This design favors readability, correctness, and debuggability over uncooked scalability. It intentionally avoids ANN indexes, vector databases, and distributed coordination, making it appropriate for small-to-medium programs and academic use circumstances.
As workloads develop, the identical hardening ideas apply even when the underlying storage or retrieval technique modifications.
With this lesson, semantic caching is now not simply quick. It’s defensive, explainable, and production-aware.
Quotation Data
Singh, V. “Semantic Caching for LLMs: TTLs, Confidence, and Cache Security,” PyImageSearch, S. Huot, A. Sharma, and P. Thakur, eds., 2026, https://pyimg.co/ahr3p
@incollection{Singh_2026_semantic-caching-llms-ttls-confidence-cache-safety,
writer = {Vikram Singh},
title = {{Semantic Caching for LLMs: TTLs, Confidence, and Cache Security}},
booktitle = {PyImageSearch},
editor = {Susan Huot and Aditya Sharma and Piyush Thakur},
12 months = {2026},
url = {https://pyimg.co/ahr3p},
}
To obtain the supply code to this put up (and be notified when future tutorials are revealed right here on PyImageSearch), merely enter your electronic mail handle within the kind beneath!

Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your electronic mail handle beneath to get a .zip of the code and a FREE 17-page Useful resource Information on Pc Imaginative and prescient, OpenCV, and Deep Studying. Inside you will discover my hand-picked tutorials, books, programs, and libraries that will help you grasp CV and DL!
The put up Semantic Caching for LLMs: TTLs, Confidence, and Cache Security appeared first on PyImageSearch.