

{kind=link}
Picture by Creator
# Introduction
Most information scientists study pandas by studying tutorials and copying patterns that work.
That’s high-quality for getting began, nevertheless it usually ends in newcomers growing unhealthy habits. Using iterrows() loops, intermediate variable assignments, and repetitive merge() calls are some examples of code that’s technically correct however slower than obligatory and harder to learn than it must be.
The patterns under should not edge circumstances. They cowl the most typical each day operations in information science, resembling filtering, reworking, becoming a member of, grouping, and computing conditional columns.
In every of them, there’s a widespread strategy and a greater strategy, and the excellence is usually one in all consciousness moderately than complexity.
These six have the best affect: methodology chaining, the pipe() sample, environment friendly joins and merges, groupby optimizations, vectorized conditional logic, and efficiency pitfalls.
# Methodology Chaining
Intermediate variables could make code really feel extra organized, however usually simply add noise. Methodology chaining permits you to write a sequence of transformations as a single expression, which reads naturally and avoids naming objects that don’t want distinctive identifiers.
As a substitute of this:
df1 = df[df['status'] == 'lively']
df2 = df1.dropna(subset=['revenue'])
df3 = df2.assign(revenue_k=df2['revenue'] / 1000)
consequence = df3.sort_values('revenue_k', ascending=False)
You write this:
consequence = (
df
.question("standing == 'lively'")
.dropna(subset=['revenue'])
.assign(revenue_k=lambda x: x['revenue'] / 1000)
.sort_values('revenue_k', ascending=False)
)
The lambda in assign() is essential right here.
When chaining, the present state of the DataFrame can’t be accessed by identify; it’s a must to use a lambda to consult with it. Essentially the most frequent explanation for chains breaking is forgetting this, which usually ends in a NameError or a stale reference to a variable that was outlined earlier within the script.
One different mistake value figuring out is using inplace=True inside a series. Strategies with inplace=True return None, which breaks the chain instantly. In-place operations must be averted when writing chained code, as they provide no reminiscence benefit and make the code more durable to comply with.
# The Pipe() Sample
When one in all your transformations is sufficiently complicated to deserve its personal separate perform, utilizing pipe() means that you can keep it contained in the chain.
pipe() passes the DataFrame as the primary argument to any callable:
def normalize_columns(df, cols):
df[cols] = (df[cols] - df[cols].imply()) / df[cols].std()
return df
consequence = (
df
.question("standing == 'lively'")
.pipe(normalize_columns, cols=['revenue', 'sessions'])
.sort_values('income', ascending=False)
)
This retains complicated transformation logic inside a named, testable perform whereas preserving the chain. Every piped perform may be individually examined, which is one thing that turns into difficult when the logic is hidden inline inside an intensive chain.
The sensible worth of pipe() extends past look. Dividing a processing pipeline into labeled capabilities and linking them with pipe() permits the code to self-document. Anybody studying the sequence can perceive every step from the perform identify without having to parse the implementation.
It additionally makes it straightforward to swap out or skip steps throughout debugging: should you remark out one pipe() name, the remainder of the chain will nonetheless run easily.
# Environment friendly Joins And Merges
One of the vital generally misused capabilities in pandas is merge(). The 2 errors we see most frequently are many-to-many joins and silent row inflation.
If each dataframes have duplicate values within the be a part of key, merge() performs a cartesian product of these rows. For instance, if the be a part of key will not be distinctive on not less than one facet, a 500-row “customers” desk becoming a member of to an “occasions” desk may end up in tens of millions of rows.
This doesn’t increase an error; it simply produces a DataFrame that seems appropriate however is bigger than anticipated till you look at its form.
The repair is the validate parameter:
df.merge(different, on='user_id', validate="many_to_one")
This raises a MergeError instantly if the many-to-one assumption is violated. Use “one_to_one”, “one_to_many”, or “many_to_one” relying on what you count on from the be a part of.
The indicator=True parameter is equally helpful for debugging:
consequence = df.merge(different, on='user_id', how='left', indicator=True)
consequence['_merge'].value_counts()
This parameter provides a _merge column exhibiting whether or not every row got here from “left_only”, “right_only”, or “each”. It’s the quickest technique to catch rows that failed to hitch whenever you anticipated them to match.
In circumstances the place each dataframes share an index, be a part of() is faster than merge() since it really works immediately on the index as a substitute of looking by a specified column.
# Groupby Optimizations
When utilizing a GroupBy, one underused methodology is remodel(). The distinction between agg() and remodel() comes right down to what form you need again.
The agg() methodology returns one row per group. Then again, remodel() returns the identical form as the unique DataFrame, with every row crammed with its group’s aggregated worth. This makes it best for including group-level statistics as new columns with out requiring a subsequent merge. Additionally it is sooner than the handbook mixture and merge strategy as a result of pandas doesn’t must align two dataframes after the very fact:
df['avg_revenue_by_segment'] = df.groupby('phase')['revenue'].remodel('imply')
This immediately provides the common income for every phase to every row. The identical consequence with agg() would require computing the imply after which merging again on the phase key, utilizing two steps as a substitute of 1.
For categorical groupby columns, at all times use noticed=True:
df.groupby('phase', noticed=True)['revenue'].sum()
With out this argument, pandas computes outcomes for each class outlined within the column’s dtype, together with combos that don’t seem within the precise information. On giant dataframes with many classes, this ends in empty teams and pointless computation.
# Vectorized Conditional Logic
Utilizing apply() with a lambda perform for every row is the least environment friendly technique to calculate conditional values. It avoids the C-level operations that pace up pandas by operating a Python perform on every row independently.
For binary circumstances, NumPy‘s np.the place() is the direct alternative:
df['label'] = np.the place(df['revenue'] > 1000, 'excessive', 'low')
For a number of circumstances, np.choose() handles them cleanly:
circumstances = [
df['revenue'] > 10000,
df['revenue'] > 1000,
df['revenue'] > 100,
]
decisions = ['enterprise', 'mid-market', 'small']
df['segment'] = np.choose(circumstances, decisions, default="micro")
The np.choose() perform maps on to an if/elif/else construction at vectorized pace by evaluating circumstances so as and assigning the primary matching choice. That is normally 50 to 100 occasions sooner than an equal apply() on a DataFrame with one million rows.
For numeric binning, conditional task is totally changed by pd.minimize() (equal-width bins) and pd.qcut() (quantile-based bins), which mechanically return a categorical column with out the necessity for NumPy. Pandas takes care of every thing, together with labeling and dealing with edge values, whenever you cross it the variety of bins or the bin edges.
# Efficiency Pitfalls
Some widespread patterns decelerate pandas code greater than anything.
For instance, iterrows() iterates over DataFrame rows as (index, Collection) pairs. It’s an intuitive however sluggish strategy. For a DataFrame with 100,000 rows, this perform name may be 100 occasions slower than a vectorized equal.
The shortage of effectivity comes from constructing an entire Collection object for each row and executing Python code on it separately. Each time you end up writing for _, row in df.iterrows(), cease and think about whether or not np.the place(), np.choose(), or a groupby operation can exchange it. More often than not, one in all them can.
Utilizing apply(axis=1) is quicker than iterrows() however shares the identical drawback: executing on the Python stage for every row. For each operation that may be represented utilizing NumPy or pandas built-in capabilities, the built-in methodology is at all times sooner.
Object dtype columns are additionally an easy-to-miss supply of slowness. When pandas shops strings as object dtype, operations on these columns run in Python moderately than C. For columns with low cardinality, resembling standing codes, area names, or classes, changing them to a categorical dtype can meaningfully pace up groupby and value_counts().
df['status'] = df['status'].astype('class')
Lastly, keep away from chained task. Utilizing df[df['revenue'] > 0]['label'] = 'constructive' might alter the preliminary DataFrame, relying on whether or not pandas generated a duplicate behind the scenes. The habits is undefined. Make the most of .loc alongside a boolean masks as a substitute:
df.loc[df['revenue'] > 0, 'label'] = 'constructive'
That is unambiguous and raises no SettingWithCopyWarning.
# Conclusion
These patterns distinguish code that works from code that works effectively: environment friendly sufficient to run on actual information, readable sufficient to take care of, and structured in a manner that makes testing straightforward.
Methodology chaining and pipe() deal with readability, whereas the be a part of and groupby patterns deal with correctness and efficiency. Vectorized logic and the pitfall part deal with pace.
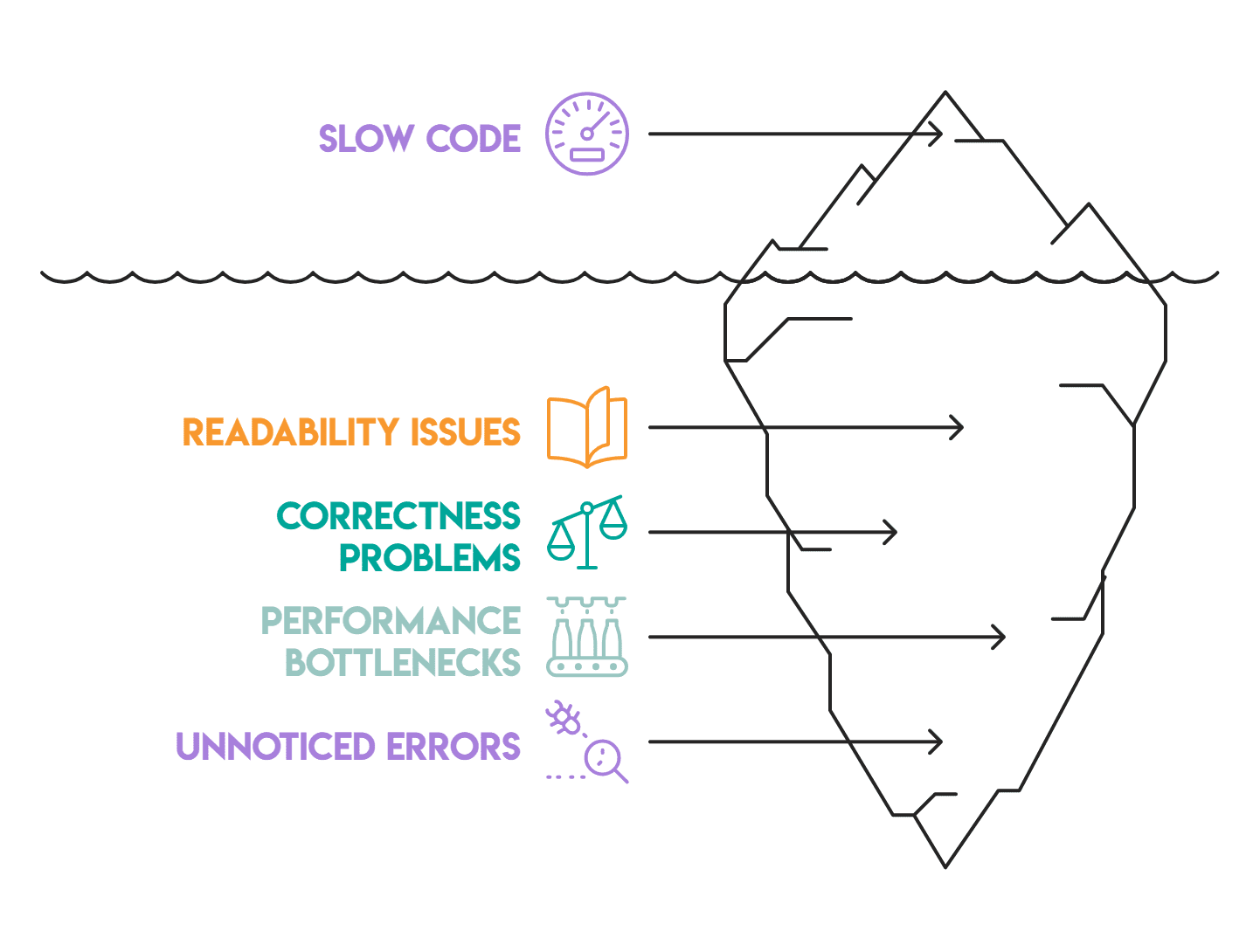
Most pandas code we evaluate has not less than two or three of those points. They accumulate quietly — a sluggish loop right here, an unvalidated merge there, or an object dtype column no one seen. None of them causes apparent failures, which is why they persist. Fixing them separately is an inexpensive place to begin.
Nate Rosidi is a knowledge scientist and in product technique. He is additionally an adjunct professor educating analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from high firms. Nate writes on the most recent tendencies within the profession market, offers interview recommendation, shares information science tasks, and covers every thing SQL.