

Recurrent Neural Networks (RNNs) are naturally suited to environment friendly inference, requiring far much less reminiscence and compute than attention-based architectures, however the sequential nature of their computation has traditionally made it impractical to scale up RNNs to billions of parameters. A brand new development from Apple researchers makes RNN coaching dramatically extra environment friendly — enabling large-scale coaching for the primary time and widening the set of structure decisions out there to practitioners in designing LLMs, significantly for resource-constrained deployment.
In ParaRNN: Unlocking Parallel Coaching of Nonlinear RNNs for Giant Language Fashions, a brand new paper accepted to ICLR 2026 as an Oral, Apple researchers share a brand new framework for parallelized RNN coaching that achieves a 665× speedup over the standard sequential strategy (see Determine 1). This effectivity achieve permits the coaching of the primary 7-billion-parameter classical RNNs that may obtain language modeling efficiency aggressive with transformers (see Determine 2).
To speed up analysis in environment friendly sequence modeling and allow researchers and practitioners to discover new nonlinear RNN fashions at scale, the ParaRNN codebase has been launched as an open-source framework for computerized training-parallelization of nonlinear RNNs.
Speedup from Parallel RNN Coaching
Efficiency of Giant-Scale Traditional RNNs
The computational value of the eye mechanism in a transformer grows quadratically with sequence size, whereas the computation required for a single ahead cross via an RNN is identical no matter how a lot context got here earlier than. This permits constant-time token technology throughout inference, making them significantly enticing for environment friendly deployment.
However there’s a catch: this effectivity benefit solely applies at inference time. Not like transformers, RNN coaching can’t be parallelized alongside the sequence size.
The very property that makes RNN environment friendly at inference — their sequential, recurrent construction — turns into a basic bottleneck throughout coaching. Not like the eye mechanism, which may course of all tokens in a sequence concurrently, an RNN software should be unrolled step-by-step, as illustrated in Determine 3.
Elementary trade-off between RNNs and Consideration
Fashionable recurrent architectures have leveraged a intelligent workaround to allow sequence parallelization: simplifying the recurrence relationship to be purely linear within the hidden state. Selective state area fashions (SSMs) like Mamba use a recurrence within the kind:
whereas classical RNNs embrace nonlinearities:
Linearity permits parallelization as a result of linear operations are associative, that means the order by which you mix them doesn’t have an effect on the ultimate end result, identical to . This mathematical property permits us to make use of parallel discount algorithms (also referred to as parallel scan) to compute your entire sequence of hidden states concurrently. The instinct is identical behind the parallel computation of a cumulative sum: relatively than sequentially including new phrases (beginning with , add , then …), one can compute partial leads to parallel (add , and , similtaneously and and and , …) and mix them in a tree-like construction, as illustrated in Determine 4. This strategy transforms the SSM software from sequential steps to parallel steps, which makes for a dramatic speedup for lengthy sequences: doubling the sequence size solely requires one further step, as an alternative of double the quantity.
A Compromise for Parallelizability: Linearity
Linearity, nevertheless, comes with its personal set of limitations: the sorts of hidden state evolutions that may be modeled by a linear system is diminished in its selection, which has a direct impression on the general expressivity of the RNN mannequin. The query then turns into: should we sacrifice expressivity for velocity, or can we’ve each?
The important thing perception is that we can have one of the best of each worlds, by adapting Newton’s technique — a traditional numerical approach for fixing nonlinear equations. Moderately than tackling the complicated system straight, Newton’s technique works by iteratively constructing and fixing an approximation (within the type of a extra tractable linear system) which is used to progressively refine the answer to the goal nonlinear one.
In Determine 5 we illustrate how we will apply this to our state of affairs. As an alternative of considering of the RNN as a sequence of sequential steps, we reframe your entire sequence as a single system of equations, the place the hidden states throughout all steps are unknowns to resolve for concurrently. Newton’s technique solves this method iteratively, approximating the nonlinearities with a linearization given by their native derivatives (i.e., their Jacobians). That is the place the magic occurs: the linearized RNN system has precisely the identical kind as a linear SSM, with the Jacobians taking part in the function of the state matrices . We’re successfully turning the answer of a nonlinear RNN into the iterative resolution of linear SSMs, every of which will be effectively solved in parallel.
Whereas this strategy introduces some overhead with respect to computing the RNN software sequentially, if the Newton iterations converge shortly sufficient (which we empirically noticed for well-designed RNN fashions), we will successfully get well the total nonlinear RNN habits in a fraction of the time, due to parallelization.
Newton’s Methodology Utilized
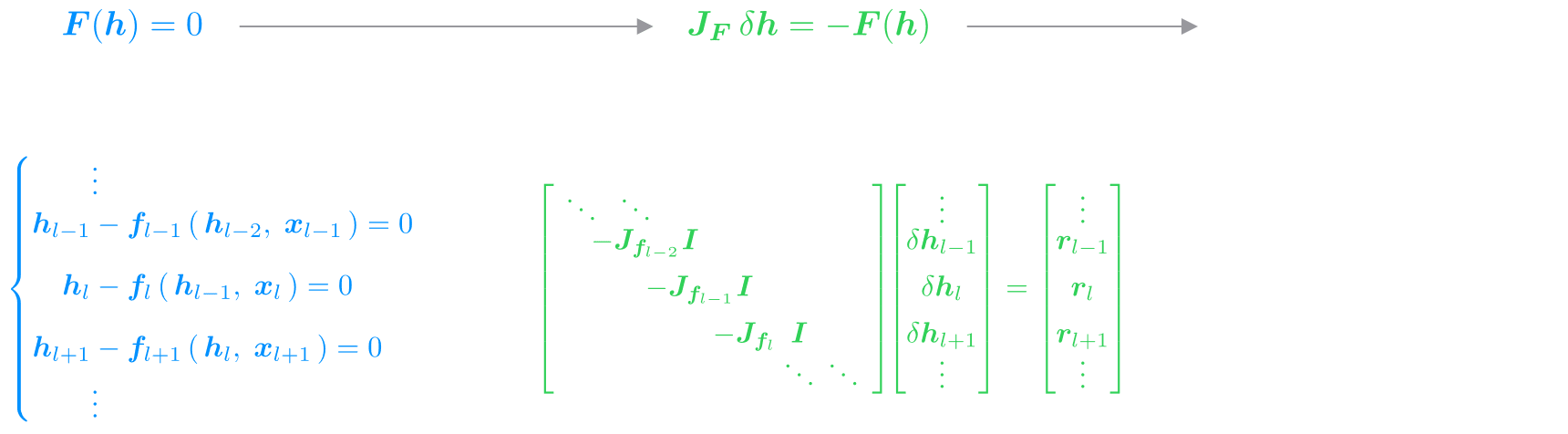
In our experiments, we apply this system to diversifications of two classical RNNs: the GRU and LSTM cells, and obtain convergence constantly with simply three iterations. In different phrases, with three fastidiously designed, parallel SSM purposes, we will get well the identical hidden state evolution as with the sequential software of a nonlinear RNN — dramatically decreasing wall-clock time at coaching.
Whereas the ParaRNN framework can in precept be utilized to any RNN, some cautious engineering remains to be required to make it sensible for large-scale coaching. The parallel discount algorithm on the coronary heart of the tactic must effectively assemble, retailer, and multiply collectively the Jacobian matrices arising from the linearization. For generic RNNs, these Jacobians are dense, which makes their storage develop quadratically and their multiplication cubically with hidden state measurement — a price intractable for large-scale fashions.
We tackle this following the design rules from fashionable SSMs like Mamba, and introduce the ParaGRU and ParaLSTM cells: diversifications of the classical GRU and LSTM cells that yield structured Jacobians. Specifically, we simplify the matrices within the cells’ definition to solely have nonzero parts of their primary diagonal. This ensures that their Jacobians are additionally diagonal (for ParaGRU) and block-diagonal (for ParaLSTM), as outlined in Determine 6.

{kind=link}
To get one of the best speedups, we then implement customized CUDA kernels to carry out environment friendly parallel discount of Jacobians presenting these constructions. Within the design of our kernels, we make certain to carefully comply with the GPU reminiscence hierarchy to maintain the information as native as potential. Because of this, our fully-fused implementation handles Newton iterations, system meeting, and parallel discount in a single kernel, reaching outstanding speedups over Mamba, In Determine 7 we offer timing outcomes for the three implementations we offer to use our ParaRNN cells in parallel: in pure PyTorch, in PyTorch with CUDA-accelerated discount, and fully-fused in CUDA.
Ahead Move via ParaGRU and ParaLSTM Cells
To validate the effectiveness of the ParaRNN framework in enabling sensible coaching of nonlinear RNNs at scale, we skilled fashions starting from 400M to 7B parameters on language modelling duties. Our objective is to check how classical RNNs can carry out as LLMs, as soon as large-scale coaching turns into possible by way of parallelization.
The outcomes present that even classical RNNs make for aggressive LLMs when skilled on the 7B scale. Each by way of sheer perplexity and downstream job efficiency (see Desk 1), ParaGRU and ParaLSTM obtain scores similar to transformers and state-of-the-art SSMs.
| Mannequin | #params | ↓ PPL |
↑ Arc-C |
↑ HSwag |
↑ OBQA |
↑ WinoG |
↑ PiQA |
↑ MMLU |
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mamba2 | 6.96B | 8.62 | 40.02 | 39.59 | 69.78 | 69.68 | 42.20 | 42.20 | 65.19 | 63.77 | 76.66 | 26.61 | ||
| ParaLSTM | 6.76B | 9.16 | 37.46 | 36.52 | 62.47 | 62.85 | 42.20 | 38.80 | 57.70 | 59.12 | 75.19 | 25.31 | ||
| ParaGRU | 6.76B | 9.19 | 39.68 | 36.77 | 65.85 | 65.75 | 42.20 | 40.40 | 61.40 | 59.83 | 76.66 | 25.29 | ||
| Transformer | 6.89B | 9.55 | 34.30 | 33.36 | 62.98 | 62.20 | 40.00 | 37.20 | 61.48 | 60.85 | 74.97 | 23.12 | ||
Desk 1: Fashions accuracy on downstream duties from the lm-eval-harness analysis suite (variety of photographs in brackets). Total, the RNN fashions attain efficiency similar to Mamba and transformer throughout the board.
The actual benefit of recurrent fashions shines at inference time, as proven in Determine 8. The constant-time token technology of RNNs means sustaining excessive throughput no matter context size, making them an interesting selection for purposes the place reaching quick technology is paramount.
Furthermore, the flexibility to incorporate nonlinearities within the recurrence step definition dramatically boosts efficiency on artificial duties requiring state monitoring and retrieval capabilities. These are helpful to check the mannequin’s potential to keep up and replace significant info in its inside state, and to retailer and get well related info when wanted. The improved efficiency outlined in Desk 2 signifies that nonlinear RNNs present superior expressivity over linear ones, and are value contemplating to design extra highly effective fashions.
| Mannequin | MQAR | 𝑘-hop | Parity | ||
|---|---|---|---|---|---|
| Transformer | 100% | 78% | 53% | ||
| Mamba2 | 100% | 98% | 51% | ||
| ParaGRU | 100% | 100% | 100% | ||
| ParaLSTM | 100% | 100% | 100% |
Desk 2: Together with nonlinearities into the recursion definition permits to realize
superior efficiency on state monitoring and recall duties over purely linear RNNs like Mamba.
Finally, our experiments present that scalability was the lacking piece within the RNN puzzle all alongside. At billion scale, they carry out in addition to fashionable language fashions, and boast superior expressivity and sooner throughput as well. These outcomes open the door to reconsidering nonlinear recurrence in fashionable sequence modelling: the nonlinearity vs coaching effectivity trade-off isn’t basic — it was only a consequence of computational limitations, which we will now overcome.
To speed up progress and allow additional exploration nonlinear RNN fashions at scale, the ParaRNN codebase has been launched as an open-source framework. Researchers and practitioners can simply concentrate on designing the RNN cell — the framework takes care of every part else.
To outline a customized cell in ParaRNN, simply implement its recurrence step:
class MyRNNCell( BaseRNNCell ):
def recurrence_step( self, h, x, system_parameters ):
h_new = ...
return h_new
The framework robotically handles Newton’s technique software, Jacobian meeting, parallel discount routines, and optimizations for structured Jacobians.
- Pure PyTorch: For prototyping. Makes use of computerized differentiation and works for any RNN, however is just not optimized for scale
- CUDA-Accelerated: For generic cells with (block-)diagonal Jacobians. Makes use of customized kernels for parallel discount
- Absolutely-Fused: Single-kernel implementation fusing the entire Newton routine. Requires CUDA implementation of recurrence step
The modular design makes it simple to experiment with customized cells, Jacobian constructions, and solver configurations—it suffices to inherit from the out there base lessons and implement the precise discount operations.
RNN software is just not inherently sequential anymore. For the primary time, classical RNNs will be skilled on the scale of billions of parameters with coaching instances and efficiency matching fashionable architectures — unlocking the inference effectivity and expressivity benefits that made recurrence interesting within the first place.
ParaRNN opens the door to exploring nonlinear recurrence at scale: experimenting with novel architectures and pushing the boundaries of what’s potential with recurrent fashions is now simpler than ever. Nonlinear RNNs are again and able to scale.