

{kind=link}
A 12 months or two in the past, utilizing superior AI fashions felt costly sufficient that you just needed to suppose twice earlier than asking something. Immediately, utilizing those self same fashions feels low-cost sufficient that you just don’t even discover the associated fee.
This isn’t simply because “know-how improved” in a imprecise sense. There are particular causes behind it, and it comes right down to how AI methods spend computation. That’s what individuals imply after they speak about token economics.
Tokens: The Elementary Unit
AI doesn’t learn phrases the way in which we do. It chops textual content into smaller constructing blocks referred to as tokens.
A token isn’t all the time a full phrase. It may be a complete phrase (like apple), a part of a phrase (like un and plausible), and even only a comma.
Every token generated requires a specific amount of computation. So should you zoom out, the price of utilizing AI comes right down to a easy relationship:
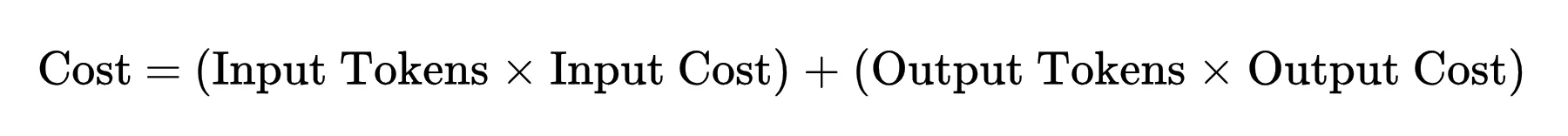
Since AI token prices are per million tokens, the equation evaluates to:
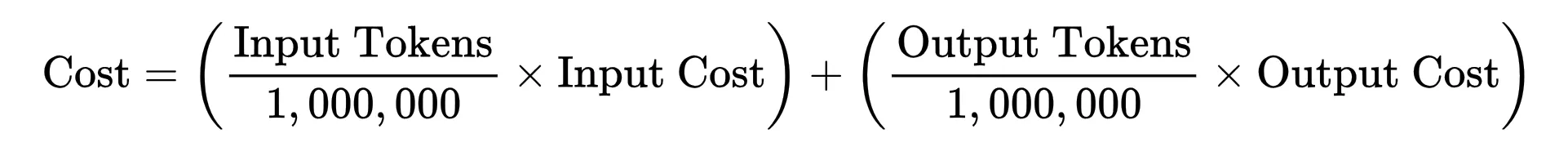
Click on right here to see how the associated fee is calculated for a mannequin
We’d be doing the maths on Gemini 3.1 Professional Preview.
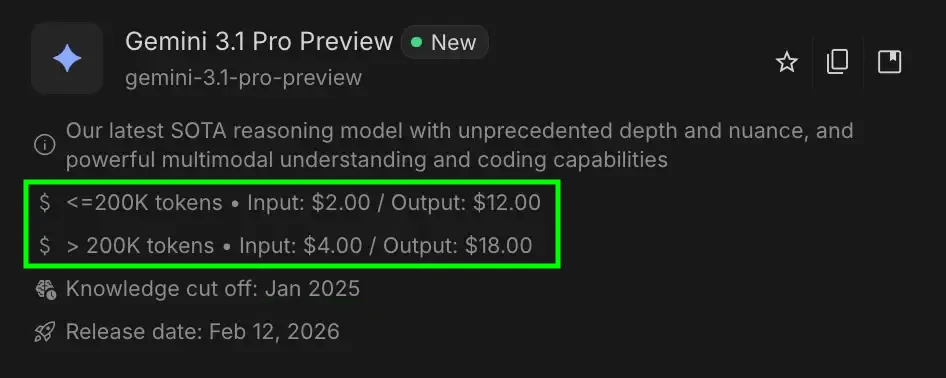
Let’s say you ship a immediate that’s 50,000 tokens (Enter Tokens) and the AI writes again 2,000 tokens (Output Tokens).
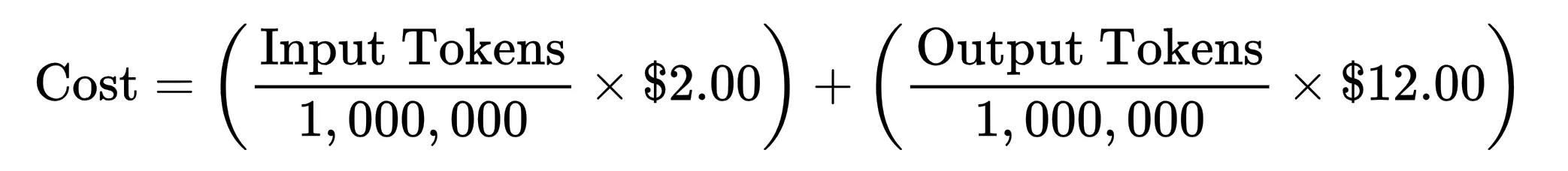
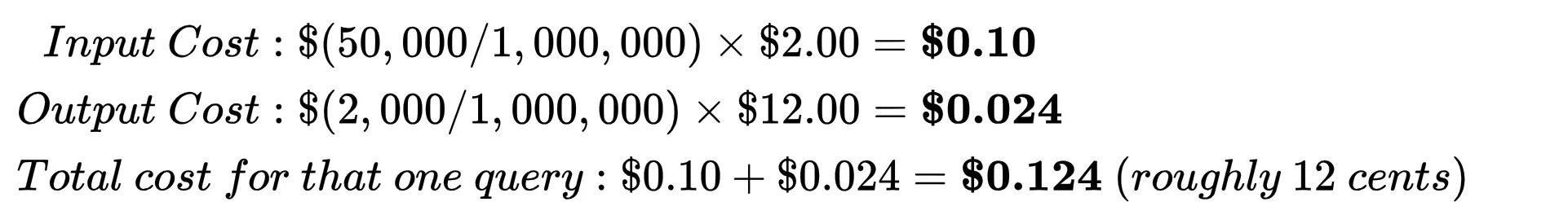
Since tokens are the foreign money of AI. In case you management tokens, you management prices.
If AI is getting cheaper, it means we’re doing considered one of two issues:
- Decreasing how a lot compute every token wants (Enter/Output tokens)
- Making that compute cheaper (Token value)
In actuality, we did each!
Utilizing much less compute per token
The primary wave of enhancements got here from a easy realization:
We have been utilizing extra computation than crucial.
Early fashions handled each request the identical method. Small or massive question, textual content or picture inputs, run the complete mannequin at full precision each time. That works, nevertheless it’s wasteful.
So the query grew to become: the place can we lower compute with out hurting output high quality?
Quantization: Making every operation lighter
Probably the most direct enchancment got here from quantization. Fashions initially used high-precision numbers for calculations. Nevertheless it seems you possibly can cut back that precision considerably with out degrading efficiency usually.
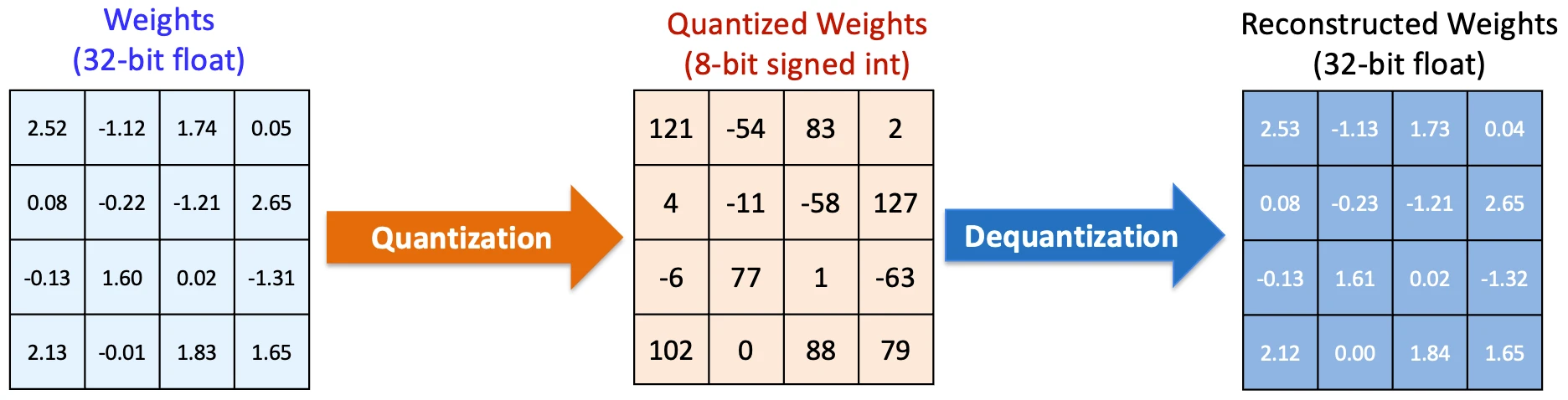
This impact compounds shortly. Each token passes by 1000’s of such operations, so even a small discount per operation results in a significant drop in price per token.
Notice: Full-precision quantization constants (a scale and a zero level) should be saved for each block. This storage is crucial so the AI can later de-quantize the info.
MoE Structure: Not utilizing the entire mannequin each time
The following realization was much more impactful:
Perhaps we don’t want the whole mannequin to work for each response.
This led to architectures like Combination of Specialists (MoE).
As a substitute of 1 massive community dealing with every part, the mannequin is break up into smaller “consultants,” and only some of them are activated for a given enter. A routing mechanism decides which of them matter.
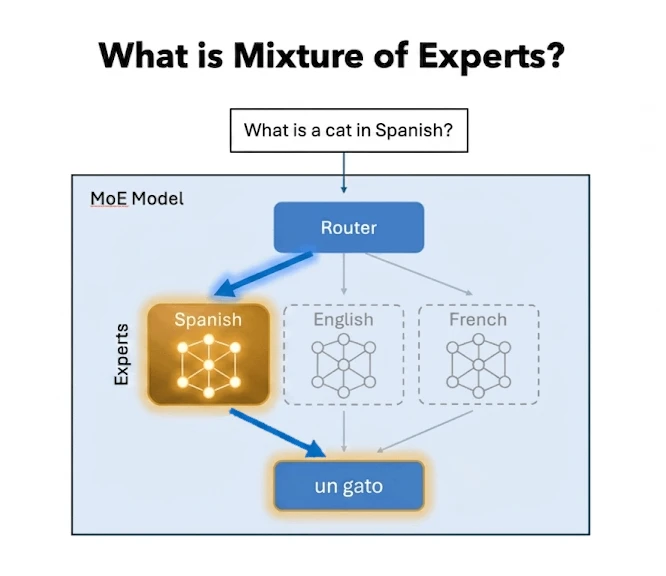
So the mannequin can nonetheless be massive and succesful general, however for any question, solely a fraction of it’s truly doing work.
That instantly reduces compute per token with out shrinking the mannequin’s general intelligence.
SLM: Choosing the proper mannequin measurement
Then got here a extra sensible remark.
Most real-world duties aren’t that complicated. A variety of what we ask AI to do is repetitive or easy: summarizing textual content, formatting output, answering easy questions.
That’s the place Small Language Fashions (SLMs) are available. These are lighter fashions designed to deal with easier duties effectively. In trendy methods, they usually deal with the majority of the workload, whereas bigger fashions are reserved for tougher issues.

So as a substitute of optimizing one mannequin endlessly, use a a lot smaller mannequin that matches your objective.
Distillation: Compressing massive fashions into smaller ones
Distillation is when a big mannequin is used to coach a smaller one, transferring its conduct in a compressed kind. The smaller mannequin received’t match the unique in each situation, however for a lot of duties, it will get surprisingly shut.
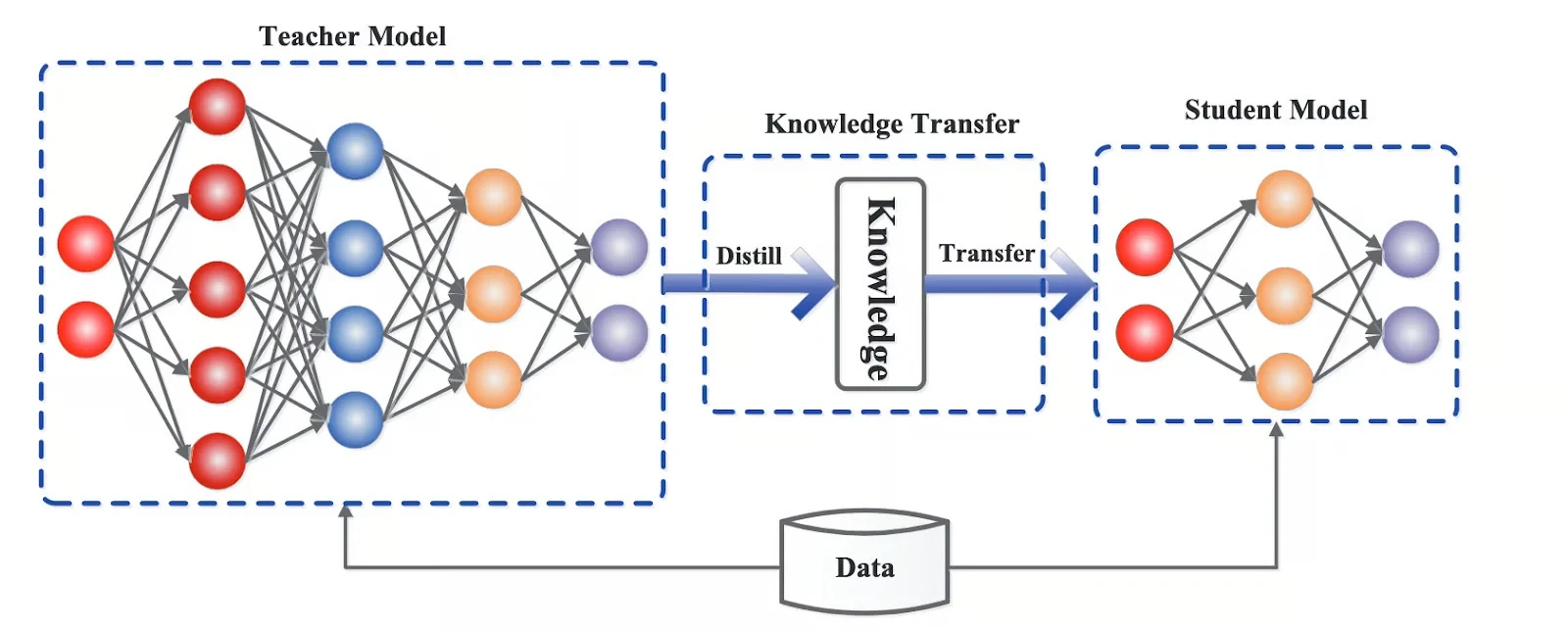
This implies you possibly can serve a less expensive mannequin whereas preserving a lot of the helpful conduct.
Once more, the theme is identical: cut back how a lot computation is required per token.
KV Caching: Avoiding repeated work
Lastly, there’s the conclusion that not each computation must be carried out from scratch.
In actual methods, inputs overlap. Conversations repeat patterns. Prompts share construction.
Fashionable implementations reap the benefits of this by caching which is reusing intermediate states from earlier computations. As a substitute of recalculating every part, the mannequin picks up from the place it left off.
This doesn’t change the mannequin in any respect. It simply removes redundant work.
Notice: There are trendy caching strategies like TurboQuant which presents excessive compression in KV caching method. Resulting in even larger financial savings.
Making compute itself cheaper
As soon as the quantity of compute per token was diminished, the subsequent step was apparent:
Make the remaining compute cheaper to run.
Executing the identical mannequin extra effectively
A variety of progress right here comes from optimizing inference itself.
Even with the identical mannequin, the way you execute it issues. Enhancements in batching, reminiscence entry, and parallelization imply that the identical computation can now be carried out sooner and with fewer sources.
You’ll be able to see this in observe with fashions like GPT-4 Turbo or Claude 4 Haiku. These are solely new intelligence layers that are engineered to be sooner and cheaper to run in comparison with earlier variations.
That is what usually exhibits up as “optimized” or “turbo” variants. The intelligence hasn’t modified: the execution has merely grow to be tighter and extra environment friendly.
{Hardware} that amplifies all of this
All these enhancements profit from {hardware} that’s designed for this sort of workload.
Corporations like NVIDIA and Google have constructed chips particularly optimized for the sorts of operations AI fashions depend on, particularly large-scale matrix multiplications.

These chips are higher at:
- dealing with lower-precision computations (vital for quantization)
- shifting knowledge effectively
- processing many operations in parallel
{Hardware} doesn’t cut back prices by itself. Nevertheless it makes each different optimization more practical.
Placing all of it collectively
Early AI methods have been wasteful. Each token used the complete mannequin, full precision, each time.
Then issues shifted. We began chopping pointless work:
- lighter operations
- partial mannequin utilization
- smaller fashions for easier duties
- avoiding recomputation
As soon as the workload shrank, the subsequent step was making it cheaper to run:
- higher execution
- smarter batching
- {hardware} constructed for these precise operations.
That’s why prices dropped sooner than anticipated.
There isn’t only a single issue main this modification. As a substitute it’s a regular shift towards utilizing solely the compute that’s truly wanted.
Often Requested Questions
A. Tokens are chunks of textual content AI processes. Extra tokens imply extra computation, instantly impacting price and efficiency.
A. AI is cheaper as a result of methods cut back compute per token and make computation extra environment friendly by optimization strategies and higher {hardware}.
A. AI price is predicated on enter and output tokens, priced per million tokens, combining utilization and per-token charges.
I focus on reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, knowledge evaluation, and knowledge retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and revel in expert-curated content material.