

{kind=link}
Textual content-to-SQL era stays a persistent problem in enterprise AI functions, significantly when working with customized SQL dialects or domain-specific database schemas. Whereas basis fashions (FMs) display sturdy efficiency on commonplace SQL, reaching production-grade accuracy for specialised dialects requires fine-tuning. Nevertheless, fine-tuning introduces an operational trade-off: internet hosting customized fashions on persistent infrastructure incurs steady prices, even in periods of zero utilization.
The on-demand inference of Amazon Bedrock with fine-tuned Amazon Nova Micro fashions provides an alternate. By combining the effectivity of LoRA (Low-Rank Adaptation) fine-tuning with serverless and pay-per-token inference, organizations can obtain customized text-to-SQL capabilities with out the overhead value incurred by persistent mannequin internet hosting. Regardless of the extra inference time overhead of making use of LoRA adapters, testing demonstrated latency appropriate for interactive text-to-SQL functions, with prices scaling by utilization quite than provisioned capability.
On this submit, we display two approaches to fine-tune Amazon Nova Micro for customized SQL dialect era to ship each value effectivity and manufacturing prepared efficiency. Our instance workload maintained a value of $0.80 month-to-month with a pattern site visitors of twenty-two,000 queries per 30 days, which resulted in prices financial savings in comparison with a persistently hosted mannequin infrastructure.
Conditions
To deploy these options, you have to the next:
- An AWS account with billing enabled
- Commonplace IAM permissions and position configured to entry:
- Quota for ml.g5.48xl occasion for Amazon SageMaker AI coaching.
Answer overview
The answer consists of the next high-level steps:
- Put together your customized SQL coaching dataset with I/O pairs particular to your group’s SQL dialect and enterprise necessities.
- Begin the fine-tuning course of on Amazon Nova Micro mannequin utilizing your ready dataset and chosen fine-tuning strategy.
- Amazon Bedrock mannequin customization for streamlined deployment
- Amazon SageMaker AI for fine-grained coaching customization and management
- Deploy the customized mannequin on Amazon Bedrock to make use of on-demand inference, eradicating infrastructure administration whereas paying just for token utilization.
- Validate mannequin efficiency with take a look at queries particular to your customized SQL dialect and enterprise use circumstances.
To display this strategy in follow, we offer two full implementation paths that tackle totally different organizational wants. The primary makes use of the managed mannequin customization of Amazon Bedrock for groups prioritizing simplicity and speedy deployment. The second makes use of Amazon SageMaker AI coaching jobs for organizations requiring extra granular management over hyperparameters and coaching infrastructure. Each implementations share the identical information preparation pipeline and deploy to Amazon Bedrock for on-demand inference. The next are hyperlinks to every GitHub code pattern:
The next structure diagram illustrates the end-to-end workflow, which encompasses information preparation, each fine-tuning approaches, and the Bedrock deployment path that permits serverless inference.
1. Dataset preparation
Our demonstration makes use of the sql-create-context dataset. This dataset is a curated mixture of WikiSQL and Spider datasets containing over 78,000 examples of pure language questions paired with SQL queries throughout various database schemas. This dataset supplies a super basis for text-to-SQL fine-tuning as a consequence of its selection in question complexity, from easy SELECT statements to advanced multi-table joins with aggregations.
Information formatting and construction
The Coaching information is structured as outlined within the documentation. This entails creating JSONL information that include system immediate directions paired with person queries and corresponding SQL responses of various complexity. The formatted coaching dataset is then cut up into coaching and validation units, saved as JSONL information, and uploaded to Amazon Easy Storage Service (Amazon S3) for the fine-tuning course of.
Pattern Transformed File
{
"schemaVersion": "bedrock-conversation-2024",
"system": [
{
"text": "You are a powerful text-to-SQL model. Your job is to answer questions about a database. You can use the following table schema for context: CREATE TABLE head (age INTEGER)"
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": "Return the SQL query that answers the following question: How many heads of the departments are older than 56 ?"
}
]
},
{
"position": "assistant",
"content material": [
{
"text": "SELECT COUNT(*) FROM head WHERE age > 56"
}
]
}
]
}Amazon Bedrock fine-tuning strategy
The mannequin customization of Amazon Bedrock supplies a streamlined, totally managed strategy to fine-tuning Amazon Nova fashions with out the necessity to provision or handle coaching infrastructure. This methodology is good for groups searching for speedy iteration and minimal operational overhead whereas reaching customized mannequin efficiency tailor-made to their text-to-SQL use case.
Utilizing the customization capabilities of Amazon Bedrock, coaching information is uploaded to Amazon S3, and fine-tuning jobs are configured by way of the AWS console or API. AWS then handles the underlying coaching infrastructure. The ensuing customized mannequin could be deployed utilizing on-demand inference, sustaining the identical token-based pricing as the bottom Nova Micro mannequin with no extra markup making it a cheap resolution for variable workloads.This strategy is well-suited when it’s good to rapidly customise a mannequin for customized SQL dialects with out managing ML infrastructure, wish to minimal operational complexity, or want serverless inference with computerized scaling.
2a. Making a Tremendous-tuning Job Utilizing Amazon Bedrock
Amazon Bedrock helps fine-tuning utilizing each the AWS Console and AWS SDK for Python (Boto3). The AWS documentation comprises normal steering on easy methods to submit a coaching job with each approaches. In our implementation, we used the AWS SDK for Python (Boto3). Consult with the pattern pocket book in our GitHub samples repository to view our step-by-step implementation.
Configure hyperparameters
After choosing the mannequin to fine-tune, we then configure our hyperparameters for our use case. For Amazon Nova Micro fine-tuning on Amazon Bedrock, the next hyperparameters could be custom-made to optimize our text-to-SQL mannequin:
| Parameter | Vary/Constraints | Objective | What we used |
| Epochs | 1–5 | Variety of full passes by way of the coaching dataset | 5 epochs |
| Batch Dimension | Fastened at 1 | Variety of samples processed earlier than updating mannequin weights | 1 (mounted for Nova Micro) |
| Studying Charge | 0.000001–0.0001 | Step measurement for gradient descent optimization | 0.00001 for secure convergence |
| Studying Charge Warmup Steps | 0–100 | Variety of steps to step by step enhance studying fee | 10 |
Be aware: These hyperparameters have been optimized for our particular dataset and use case. Optimum values might fluctuate primarily based on dataset measurement and complexity. Within the pattern dataset, this configuration supplied improved stability between mannequin accuracy and coaching time, finishing in roughly 2-3 hours.
Analyzing coaching metrics
Amazon Bedrock mechanically generates coaching and validation metrics, that are saved in your specified S3 output location. These metrics embody:
- Coaching loss: Measures how nicely the mannequin suits the coaching information
- Validation loss: Signifies generalization efficiency on unseen information
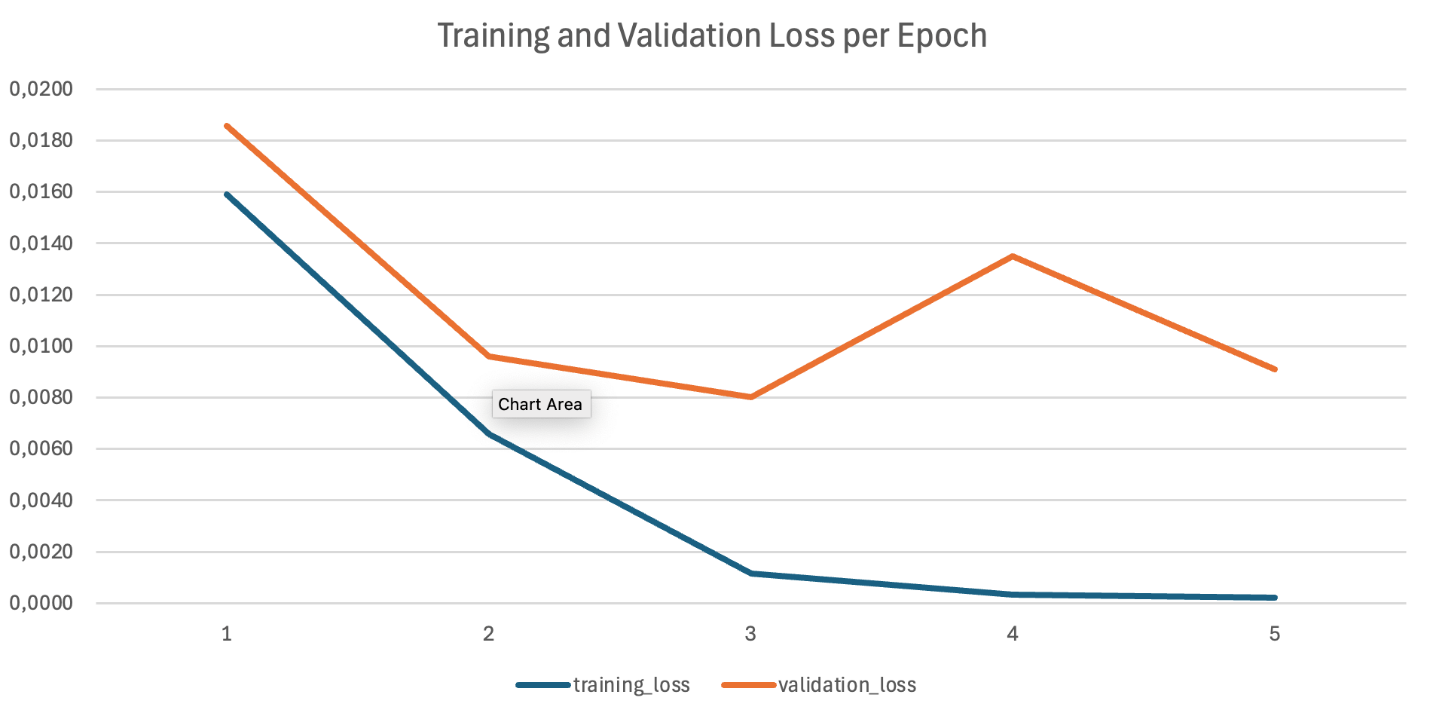
The coaching and validation loss curves present profitable coaching: each lower constantly, observe related patterns, and converge to comparable ultimate values.
3a. Deploy with on-demand inference
After your fine-tuning job completes efficiently, you possibly can deploy your customized Nova Micro mannequin utilizing on-demand inference. This deployment possibility supplies computerized scaling and pay-per-token pricing, making it superb for variable workloads with out the necessity to provision devoted compute assets.
Invoking the customized Nova Micro mannequin
After deployment, you possibly can invoke your customized text-to-SQL mannequin by utilizing the deployment ARN because the mannequin ID within the Amazon Bedrock Converse API.
# Use the deployment ARN because the mannequin ID
deployment_arn = "arn:aws:bedrock:us-east-1::deployment/"
# Put together the inference request
response = bedrock_runtime.converse(
modelId=deployment_arn,
messages=[
{
"role": "user",
"content": [
{
"text": """Database schema:
CREATE TABLE sales (
id INT,
product_name VARCHAR(100),
category VARCHAR(50),
revenue DECIMAL(10,2),
sale_date DATE
);
Question: What are the top 5 products by revenue in the Electronics category?"""
}
]
}
],
inferenceConfig={
"maxTokens": 512,
"temperature": 0.1, # Low temperature for deterministic SQL era
"topP": 0.9
}
)
# Extract the generated SQL question
sql_query = response['output']['message']['content']['text']
print(f"Generated SQL:
{sql_query}") Amazon SageMaker AI fine-tuning strategy
Whereas the Amazon Bedrock strategy streamlines mannequin customization by way of a managed coaching expertise, organizations searching for deeper optimization management would possibly profit from the SageMaker AI strategy. SageMaker AI supplies in depth management over coaching parameters that may considerably influence effectivity and mannequin efficiency. You’ll be able to alter batch measurement for pace and reminiscence optimzation, fine-tune dropout settings throughout layers to forestall overfitting, and configure studying fee schedules for coaching stability. For LoRA fine-tuning particularly, You should use SageMaker AI to customise scaling components and regularization parameters with totally different settings optimized for multimodal versus text-only datasets. Moreover, you possibly can alter the context window measurement and optimizer settings to match your particular use case necessities. See the next pocket book for the entire code pattern.
1b. Information preparation and add
The info preparation and add course of for the SageMaker AI fine-tuning strategy is similar to the Amazon Bedrock implementation. Each approaches convert the SQL dataset to the bedrock-conversation-2024 schema format, cut up the info into coaching and take a look at units, and add the JSONL information on to S3.
# S3 prefix for coaching information
training_input_path = f's3://{sess.default_bucket()}/datasets/nova-sql-context'
# Add datasets to S3
train_s3_path = sess.upload_data(
path="information/train_dataset.jsonl",
bucket=bucket_name,
key_prefix=training_input_path
)
test_s3_path = sess.upload_data(
path="information/test_dataset.jsonl",
bucket=bucket_name,
key_prefix=training_input_path
)
print(f'Coaching information uploaded to: {train_s3_path}')
print(f'Take a look at information uploaded to: {test_s3_path}')2b. Making a fine-tuning job utilizing Amazon SageMaker AI
Choose the mannequin ID, recipe, and picture URI:
# Nova configuration
model_id = "nova-micro/prod"
recipe = "https://uncooked.githubusercontent.com/aws/sagemaker-hyperpod-recipes/refs/heads/important/recipes_collection/recipes/fine-tuning/nova/nova_1_0/nova_micro/SFT/nova_micro_1_0_g5_g6_48x_gpu_lora_sft.yaml"
instance_type = "ml.g5.48xlarge"
instance_count = 1
# Nova-specific picture URI
image_uri = f"708977205387.dkr.ecr.{sess.boto_region_name}.amazonaws.com/nova-fine-tune-repo:SM-TJ-SFT-latest"
print(f'Mannequin ID: {model_id}')
print(f'Recipe: {recipe}')
print(f'Occasion sort: {instance_type}')
print(f'Occasion rely: {instance_count}')
print(f'Picture URI: {image_uri}')Configuring customized coaching recipes
A key differentiator when utilizing Amazon SageMaker AI for Nova mannequin fine-tuning is the flexibility to customise a coaching recipe. Recipes are pre-configured coaching stacks supplied by AWS that will help you rapidly begin coaching and fine-tuning. Whereas sustaining compatibility with the usual hyperparameter set (epochs, batch measurement, studying fee, and warmup steps) of Amazon Bedrock, the recipes lengthen hyperparameter choices by way of:
- Regularization parameters: hidden_dropout, attention_dropout, and ffn_dropout to forestall overfitting.
- Optimizer settings: Customizable beta coefficients and weight decay settings.
- Structure controls: Adapter rank and scaling components for LoRA coaching.
- Superior scheduling: Customized studying fee schedules and warmup methods.
The really helpful strategy is to start out with the default settings to create a baseline, then optimize primarily based in your particular wants. Right here’s an inventory of among the extra parameters that you would be able to optimize for.
| Parameter | Vary/Constraints | Objective |
max_length |
1024–8192 | Management the utmost context window measurement for enter sequences |
global_batch_size |
16,32,64 | Variety of samples processed earlier than updating mannequin weights |
hidden_dropout |
0.0–1.0 | Regularization for hidden layer states to forestall overfitting |
attention_dropout |
0.0–1.0 | Regularization for consideration mechanism weights |
ffn_dropout |
0.0–1.0 | Regularization for feed ahead community layers |
weight_decay |
0.0–1.0 | L2 Regularization power for mannequin weights |
Adapter_dropout |
0.0–1.0 | Regularization for LoRA adapter parameters |
The whole recipe that we used could be discovered right here.
Creating and executing a SageMaker AI coaching job
After configuring your mannequin and recipe, initialize the ModelTrainer object and start coaching:
from sagemaker.prepare import ModelTrainer
coach = ModelTrainer.from_recipe(
training_recipe=recipe,
recipe_overrides=recipe_overrides,
compute=compute_config,
stopping_condition=stopping_condition,
output_data_config=output_config,
position=position,
base_job_name=job_name,
sagemaker_session=sess,
training_image=image_uri
)
# Configure information channels
from sagemaker.prepare.configs import InputData, S3DataSource
train_input = InputData(
channel_name="prepare",
data_source=S3DataSource(
s3_uri=train_s3_path,
s3_data_type="Converse",
s3_data_distribution_type="FullyReplicated"
)
)
val_input = InputData(
channel_name="val",
data_source=S3DataSource(
s3_uri=test_s3_path,
s3_data_type="Converse",
s3_data_distribution_type="FullyReplicated"
)
)
# Start coaching
training_job = coach.prepare(
input_data_config=[train_input,val_input],
wait=False
)After coaching, we register the mannequin with Amazon Bedrock by way of the create_custom_model_deployment Amazon Bedrock API, enabling on-demand inference by way of the converse API utilizing the deployed mannequin ARN, system prompts, and person messages.
In our SageMaker AI coaching job, we used default recipe parameters, together with an epoch of two and batch measurement of 64, our information contained 20,000 strains thus the entire coaching job lasted for 4 hours. With our ml.g5.48xlarge occasion, the full value for fine-tuning our Nova Micro mannequin was $65.
4. Testing and analysis
For evaluating our mannequin, we carried out each operational and accuracy testing. To guage accuracy, we applied an LLM-as-a-Choose strategy the place we collected questions and SQL responses from our fine-tuned mannequin and used a decide mannequin to attain them in opposition to the bottom fact responses.
def get_score(system, person, assistant, generated):
formatted_prompt = (
"You're a information science trainer that's introducing college students to SQL. "
f"Think about the next query and schema:"
f"{person} "
f"{system} "
"Right here is the proper reply:"
f"{assistant} "
f"Right here is the scholar's reply:"
f"{generated} "
"Please present a numeric rating from 0 to 100 on how nicely the scholar's "
"reply matches the proper reply. Put the rating in XML tags."
)
_, outcome = ask_claude(formatted_prompt)
sample = r'(.*?) '
match = re.search(sample, outcome)
return match.group(1) if match else "0"
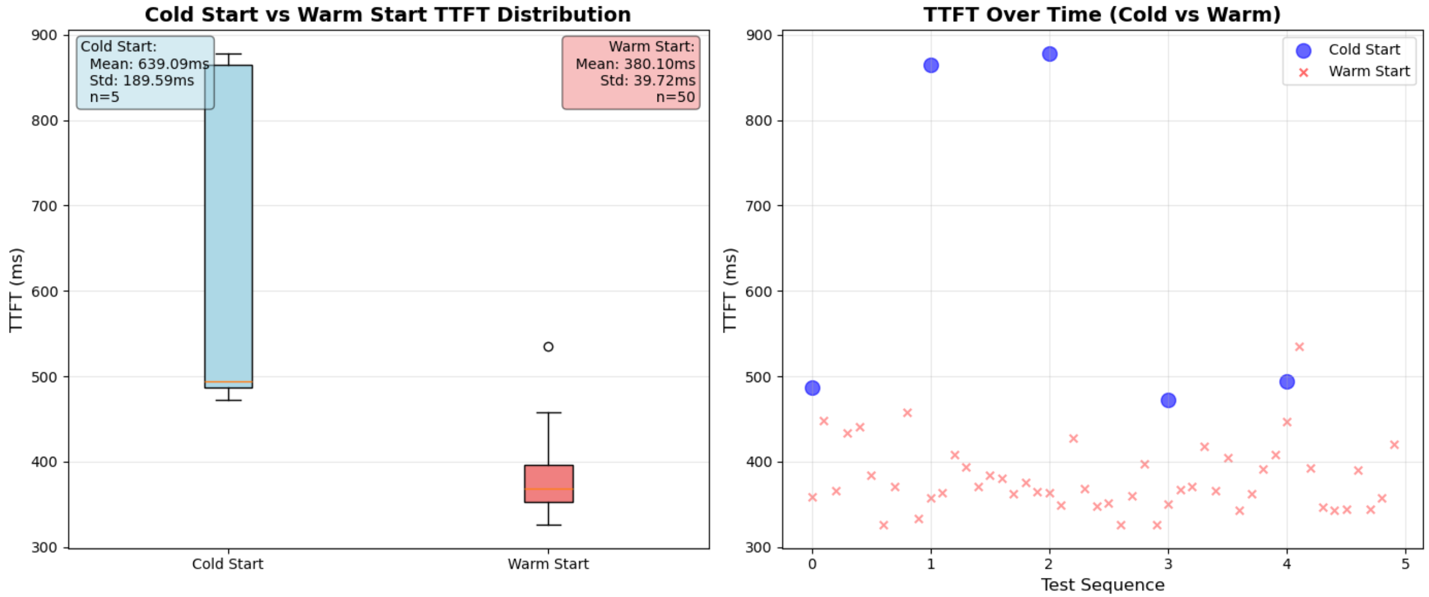
For operational testing, we gathered metrics together with TTFT (Time to First Token) and OTPS (Output Tokens Per Second). In comparison with the bottom Nova Micro mannequin, we skilled chilly begin time to first token averaging 639 ms throughout 5 runs (34% enhance). This latency enhance stems from making use of LoRA adapters at inference time quite than baking them into mannequin weights. Nevertheless, this architectural alternative delivers substantial value advantages, because the fine-tuned Nova Micro mannequin prices the identical as the bottom mannequin, enabling on-demand pricing with pay-per-use flexibility and no minimal commitments. Throughout regular operation, our time to first token averages 380 ms throughout 50 calls (7% enhance). Finish-to-end latency totals roughly 477 ms for full response era. Token era maintains a fee of roughly 183 tokens per second, representing solely a 27% lower from the bottom mannequin whereas remaining extremely appropriate for interactive functions.
Value abstract
One-time prices:
- Amazon Bedrock mannequin coaching value: $0.001 per 1,000 tokens × variety of epochs
- For two,000 examples, 5 epochs and roughly 800 tokens every = $8.00
- SageMaker AI mannequin coaching value: We used the ml.g5.48xlarge occasion, which prices $16.288/hour
- Coaching lasted 4 hours with a 20,000-line dataset = $65.15
- Ongoing prices
- Storage: $1.95 per 30 days per customized mannequin
- On-demand inference: Similar per-token pricing as base Nova Micro
- Enter tokens: $0.000035 per 1,000 tokens (Amazon Nova Micro)
- Output tokens: $0.00014 per 1,000 tokens (Amazon Nova Micro)
Instance calculation for manufacturing workload:
For 22,000 queries per 30 days (100 customers × 10 queries/day × 22 enterprise days):
- Common 800 enter tokens + 60 output tokens per question
- Enter value: (22,000 × 800 / 1,000) × 0.000035 = 0.616
- Output value: (22,000 × 60 / 1,000) × 0.00014 = 0.184
- Whole month-to-month inference value: 0.80 USD
This evaluation validates that for customized dialect text-to-SQL use circumstances, fine-tuning a Nova mannequin utilizing PEFT LoRA on Amazon Bedrock is considerably more cost effective than self-hosting customized fashions on persistent infrastructure. Self-hosted approaches would possibly suite use circumstances requiring most management over infrastructure, safety configurations, or integration necessities, however the Amazon Bedrock on-demand value mannequin provides important value financial savings for many manufacturing text-to-SQL workloads.
Conclusion
These implementation choices display how Amazon Nova fine-tuning could be tailor-made to organizational wants and technical necessities. We explored two distinct approaches that serve totally different audiences and use circumstances. Whether or not you select the managed simplicity of Amazon Bedrock or extra management by way of SageMaker AI coaching, the serverless deployment mannequin and on-demand pricing signifies that you solely pay for what you employ, whereas eradicating infrastructure administration.
The Amazon Bedrock mannequin customization strategy supplies a streamlined, managed resolution that eliminates infrastructure complexity. Information scientists can concentrate on information preparation and mannequin analysis with out managing coaching infrastructure, making it superb for fast experimentation and improvement.
The SageMaker AI coaching strategy provides elevated management over each side of the fine-tuning course of. Machine studying (ML) engineers acquire granular management over coaching parameters, infrastructure choice, and integration with current MLOps workflows, which allows optimization for required efficiency, value, and operational necessities. For instance, you possibly can alter batch sizes and occasion sorts to optimize coaching pace, or modify studying charges and LoRA parameters to stability mannequin high quality with coaching time primarily based in your particular operational wants
Select Amazon Bedrock mannequin customization when: You want speedy iteration, have restricted ML infrastructure experience, or wish to decrease operational overhead whereas nonetheless reaching customized mannequin efficiency.
Select SageMaker AI coaching when: You require fine-grained parameter management, have particular infrastructure or compliance necessities, want integration with current MLOps pipelines, or wish to optimize each side of the coaching course of.
Get began
Able to construct your personal cost-effective text-to-SQL resolution? Entry our full implementations:
Each approaches use the identical cost-efficient deployment mannequin, so you possibly can select primarily based in your crew’s experience and necessities quite than value constraints.
Concerning the authors