

{kind=link}
Retrieval-Augmented Technology (RAG) has change into a regular approach for grounding massive language fashions in exterior information — however the second you progress past plain textual content and begin mixing in photos and movies, the entire strategy begins to buckle. Visible information is token-heavy, semantically sparse relative to a particular question, and grows unwieldy quick throughout multi-step reasoning. Researchers at Tongyi Lab, Alibaba Group launched ‘VimRAG’, a framework constructed particularly to handle that breakdown.
The issue: linear historical past and compressed reminiscence each fail with visible information
Most RAG brokers right now observe a Thought-Motion-Commentary loop — generally referred to as ReAct — the place the agent appends its full interplay historical past right into a single rising context. Formally, at step t the historical past is Ht = [q, τ1, a1, o1, …, τt-1, at-1, ot-1]. For duties pulling in movies or visually wealthy paperwork, this shortly turns into untenable: the data density of essential observations |Ocrit|/|Ht| falls towards zero as reasoning steps enhance.
The pure response is memory-based compression, the place the agent iteratively summarizes previous observations right into a compact state mt. This retains density steady at |Ocrit|/|mt| ≈ C, however introduces Markovian blindness — the agent loses observe of what it has already queried, resulting in repetitive searches in multi-hop eventualities. In a pilot research evaluating ReAct, iterative summarization, and graph-based reminiscence utilizing Qwen3VL-30B-A3B-Instruct on a video corpus, summarization-based brokers suffered from state blindness simply as a lot as ReAct, whereas graph-based reminiscence considerably diminished redundant search actions.
A second pilot research examined 4 cross-modality reminiscence methods. Pre-captioning (textual content → textual content) makes use of solely 0.9k tokens however reaches simply 14.5% on picture duties and 17.2% on video duties. Storing uncooked visible tokens makes use of 15.8k tokens and achieves 45.6% and 30.4% — noise overwhelms sign. Context-aware captioning compresses to textual content and improves to 52.8% and 39.5%, however loses fine-grained element wanted for verification. Selectively retaining solely related imaginative and prescient tokens — Semantically-Associated Visible Reminiscence — makes use of 2.7k tokens and reaches 58.2% and 43.7%, the perfect trade-off. A 3rd pilot research on credit score project discovered that in constructive trajectories (reward = 1), roughly 80% of steps include noise that might incorrectly obtain constructive gradient sign below customary outcome-based RL, and that eradicating redundant steps from detrimental trajectories recovered efficiency totally. These three findings straight encourage VimRAG’s three core parts.
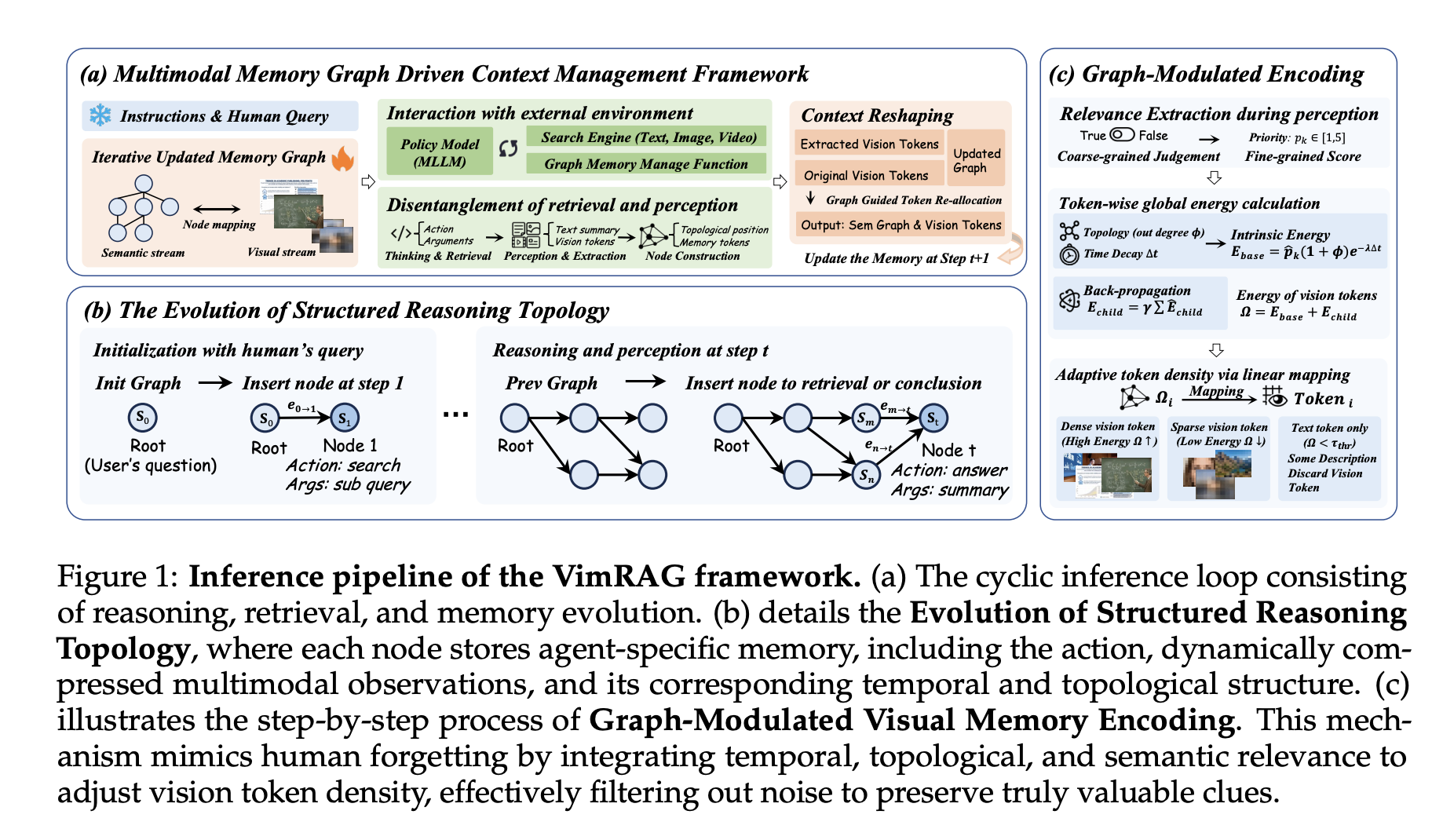
VimRAG’s three-part structure
- The first element is the Multimodal Reminiscence Graph. Fairly than a flat historical past or compressed abstract, the reasoning course of is modeled as a dynamic directed acyclic graph Gt(Vt, Et) Every node vi encodes a tuple (pi, qi, si, mi): mum or dad node indices encoding native dependency construction, a decomposed sub-query related to the search motion, a concise textual abstract, and a multimodal episodic reminiscence financial institution of visible tokens from retrieved paperwork or frames. At every step the coverage samples from three motion varieties: aret (exploratory retrieval, spawning a brand new node and executing a sub-query), amem (multimodal notion and reminiscence inhabitants, distilling uncooked observations right into a abstract st and visible tokens mt utilizing a coarse-to-fine binary saliency masks u ∈ {0,1} and a fine-grained semantic rating p ∈ [1,5]), and aans (terminal projection, executed when the graph accommodates adequate proof). For video observations, amem leverages the temporal grounding functionality of Qwen3-VL to extract keyframes aligned with timestamps earlier than populating the node.
- The second element is Graph-Modulated Visible Reminiscence Encoding, which treats token project as a constrained useful resource allocation drawback. For every visible merchandise mi,ok, intrinsic power is computed as Eint(mi,ok) = p̂i,ok · (1 + deg+G(vi)) · exp(−λ(T − ti)), combining semantic precedence, node out-degree for structural relevance, and temporal decay to low cost older proof. Last power provides recursive reinforcement from successor nodes: , preserving foundational early nodes that assist high-value downstream reasoning. Token budgets are allotted proportionally to power scores throughout a world top-Ok choice, with a complete useful resource finances of Scomplete = 5 × 256 × 32 × 32. Dynamic allocation is enabled solely throughout inference; coaching averages pixel values within the reminiscence financial institution.
- The third element is Graph-Guided Coverage Optimization (GGPO). For constructive samples (reward = 1), gradient masks are utilized to dead-end nodes not on the essential path from root to reply node, stopping constructive reinforcement of redundant retrieval. For detrimental samples (reward = 0), steps the place retrieval outcomes include related info are excluded from the detrimental coverage gradient replace. The binary pruning masks is outlined as . Ablation confirms this produces quicker convergence and extra steady reward curves than baseline GSPO with out pruning.
Outcomes and availability
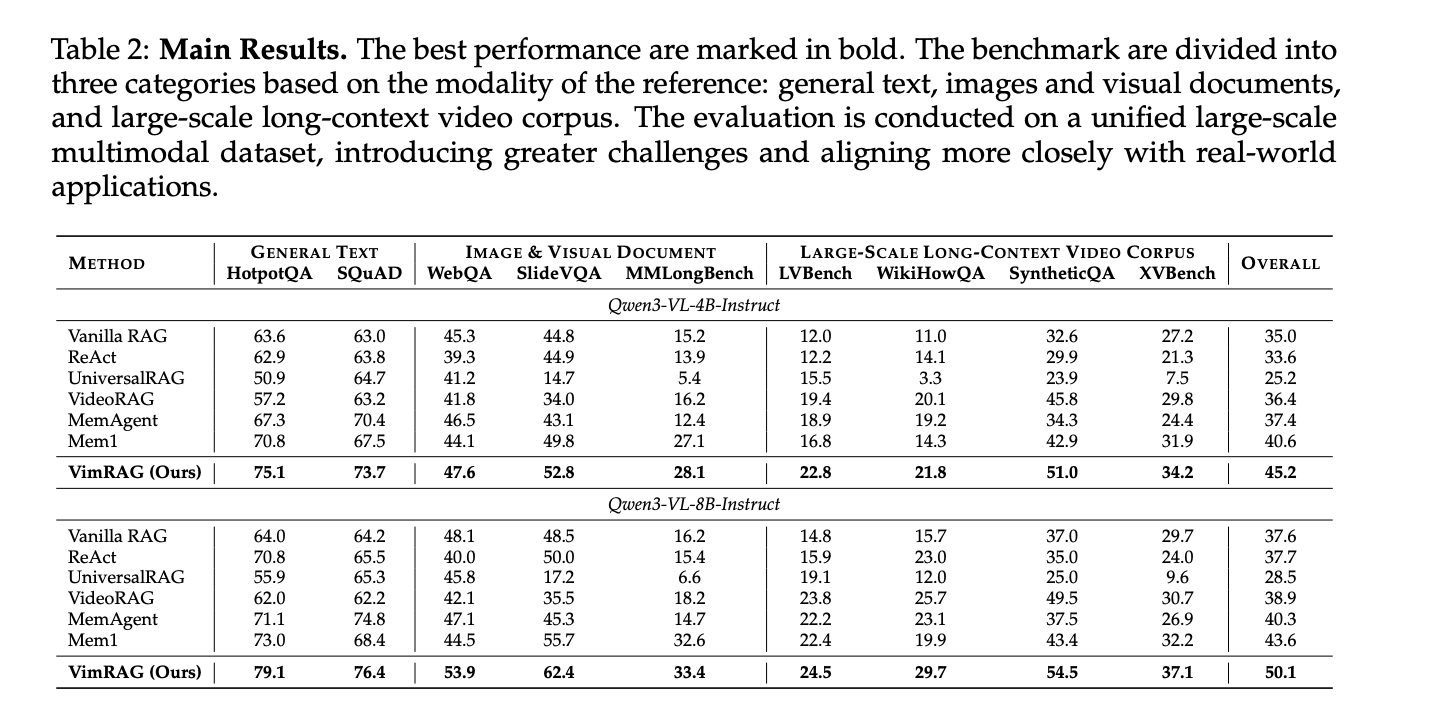
VimRAG was evaluated throughout 9 benchmarks — HotpotQA, SQuAD, WebQA, SlideVQA, MMLongBench, LVBench, WikiHowQA, SyntheticQA, and XVBench, a brand new cross-video benchmark the analysis workforce constructed from HowTo100M to handle the dearth of analysis requirements for cross-video understanding. All 9 datasets have been merged right into a single unified corpus of roughly 200k interleaved multimodal objects, making the analysis tougher and extra consultant of real-world circumstances. GVE-7B served because the embedding mannequin supporting text-to-text, picture, and video retrieval.
On Qwen3-VL-8B-Instruct, VimRAG achieves an total rating of fifty.1 versus 43.6 for Mem1, the prior greatest baseline. On Qwen3-VL-4B-Instruct, VimRAG scores 45.2 towards Mem1’s 40.6. On SlideVQA with the 8B spine, VimRAG reaches 62.4 versus 55.7; on SyntheticQA, 54.5 versus 43.4. Regardless of introducing a devoted notion step, VimRAG additionally reduces complete trajectory size in comparison with ReAct and Mem1, as a result of structured reminiscence prevents the repetitive re-reading and invalid searches that trigger linear strategies to build up a heavy tail of token utilization.
Key Takeaways
- VimRAG replaces linear interplay historical past with a dynamic directed acyclic graph (Multimodal Reminiscence Graph) that tracks the agent’s reasoning state throughout steps, stopping the repetitive queries and state blindness that plague customary ReAct and summarization-based RAG brokers when dealing with massive volumes of visible information.
- Graph-Modulated Visible Reminiscence Encoding solves the visible token finances drawback by dynamically allocating high-resolution tokens to a very powerful retrieved proof based mostly on semantic relevance, topological place within the graph, and temporal decay — moderately than treating all retrieved photos and video frames at uniform decision.
- Graph-Guided Coverage Optimization (GGPO) fixes a elementary flaw in how agentic RAG fashions are skilled — customary outcome-based rewards incorrectly penalize good retrieval steps in failed trajectories and incorrectly reward redundant steps in profitable ones. GGPO makes use of the graph construction to masks these deceptive gradients on the step stage.
- A pilot research utilizing 4 cross-modality reminiscence methods confirmed that selectively retaining related imaginative and prescient tokens (Semantically-Associated Visible Reminiscence) achieves the perfect accuracy-efficiency trade-off, reaching 58.2% on picture duties and 43.7% on video duties with solely 2.7k common tokens — outperforming each uncooked visible storage and text-only compression approaches.
- VimRAG outperforms all baselines throughout 9 benchmarks on a unified corpus of roughly 200k interleaved textual content, picture, and video objects, scoring 50.1 total on Qwen3-VL-8B-Instruct versus 43.6 for the prior greatest baseline Mem1, whereas additionally lowering complete inference trajectory size regardless of including a devoted multimodal notion step.
Try the Paper, Repo and Mannequin Weights. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 120k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be a part of us on telegram as nicely.
Have to associate with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so forth.? Join with us

Michal Sutter is a knowledge science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling complicated datasets into actionable insights.