

{kind=link}
This submit is cowritten with Altay Sansal and Alejandro Valenciano from TGS.
TGS, a geoscience knowledge supplier for the power sector, helps corporations’ exploration and manufacturing workflows with superior seismic basis fashions (SFMs). These fashions analyze advanced 3D seismic knowledge to determine geological constructions very important for power exploration. To assist improve their next-generation fashions as a part of their AWS infrastructure modernization, TGS partnered with the AWS Generative AI Innovation Heart (GenAIIC) to optimize their SFM coaching infrastructure.
This submit describes how TGS achieved near-linear scaling for distributed coaching and expanded context home windows for his or her Imaginative and prescient Transformer-based SFM utilizing Amazon SageMaker HyperPod. This joint answer minimize coaching time from 6 months to simply 5 days whereas enabling evaluation of seismic volumes bigger than beforehand doable.
Addressing seismic basis mannequin coaching challenges
TGS’s SFM makes use of a Imaginative and prescient Transformer (ViT) structure with Masked AutoEncoder (MAE) coaching designed by the TGS staff to investigate 3D seismic knowledge. Scaling such fashions presents a number of challenges:
- Information scale and complexity – TGS works with massive volumes of proprietary 3D seismic knowledge saved in domain-specific codecs. The sheer quantity and construction of this knowledge required environment friendly streaming methods to keep up excessive throughput and assist stop GPU idle time throughout coaching.
- Coaching effectivity – Coaching massive FMs on 3D volumetric knowledge is computationally intensive. Accelerating coaching cycles would allow TGS to include new knowledge extra regularly and iterate on mannequin enhancements quicker, delivering extra worth to their shoppers.
- Expanded analytical capabilities – The geological context a mannequin can analyze is determined by how a lot 3D quantity it might course of directly. Increasing this functionality would enable the fashions to seize each native particulars and broader geological patterns concurrently.
Understanding these challenges highlights the necessity for a complete method to distributed coaching and infrastructure optimization. The AWS GenAIIC partnered with TGS to develop a complete answer addressing these challenges.
Answer overview
The collaboration between TGS and the AWS GenAIIC targeted on three key areas: establishing an environment friendly knowledge pipeline, optimizing distributed coaching throughout a number of nodes, and increasing the mannequin’s context window to investigate bigger geological volumes. The next diagram illustrates the answer structure.
The answer makes use of SageMaker HyperPod to assist present a resilient, scalable coaching infrastructure with computerized well being monitoring and checkpoint administration. The SageMaker HyperPod cluster is configured with AWS Id and Entry Administration (IAM) execution roles scoped to the minimal permissions required for coaching operations, deployed inside a digital personal cloud (VPC) with community isolation and safety teams limiting communication to approved coaching nodes. Terabytes of coaching knowledge streams straight from Amazon Easy Storage Service (Amazon S3), assuaging the necessity for intermediate storage layers whereas sustaining excessive throughput. AWS CloudTrail logs API calls to Amazon S3 and SageMaker providers, and Amazon S3 entry logging is enabled on coaching knowledge buckets to supply an in depth audit path of knowledge entry requests. The distributed coaching framework makes use of superior parallelization methods to effectively scale throughout a number of nodes, and context parallelism strategies allow the mannequin to course of considerably bigger 3D volumes than beforehand doable.
The ultimate cluster configuration consisted of 16 Amazon Elastic Compute Cloud (Amazon EC2) P5 cases for the employee nodes built-in by way of the SageMaker AI versatile coaching plans, every containing:
- 8 NVIDIA H200 GPUs with 141GB HBM3e reminiscence per GPU
- 192 vCPUs
- 2048 GB system RAM
- 3200 Gbps EFAv3 networking for ultra-low latency communication
Optimizing the coaching knowledge pipeline
TGS’s coaching dataset consists of 3D seismic volumes saved within the TGS-developed MDIO format—an open supply format constructed on Zarr arrays designed for large-scale scientific knowledge within the cloud. Such volumes can comprise billions of knowledge factors representing underground geological constructions.
Choosing the proper storage method
The staff evaluated two approaches for delivering knowledge to coaching GPUs:
- Amazon FSx for Lustre – Copy knowledge from Amazon S3 to a high-speed distributed file system that the nodes learn from. This method offers sub-millisecond latency however requires pre-loading and provisioned storage capability.
- Streaming straight from Amazon S3 – Stream knowledge straight from Amazon S3 utilizing MDIO’s native capabilities with multi-threaded libraries, opening a number of concurrent connections per node.
Selecting streaming straight from Amazon S3
The important thing architectural distinction lies in how throughput scales with the cluster. With streaming straight from Amazon S3, every coaching node creates impartial Amazon S3 connections, so combination throughput can scale linearly. With Amazon FSx for Lustre, the nodes share a single file system whose throughput is tied to provisioned storage capability. Utilizing Amazon FSx along with Amazon S3 requires solely a small Amazon FSx storage quantity, which limits all the cluster to that quantity’s throughput, making a bottleneck because the cluster grows.
Complete testing and value evaluation revealed streaming from Amazon S3 straight because the optimum alternative for this configuration:
- Efficiency – Achieved 4–5 GBps sustained throughput per node utilizing a number of knowledge loader processes with pre-fetching over HTTPS endpoints (TLS 1.2)—enough to totally make the most of the GPUs.
- Value effectivity – Streaming from Amazon S3 alleviated the necessity for Amazon FSx provisioning, decreasing storage infrastructure prices by over 90% whereas serving to ship 64-80 GBps cluster-wide throughput. The Amazon S3 pay-per-use mannequin was extra economical than provisioning high-throughput Amazon FSx capability.
- Higher scaling – Streaming from Amazon S3 straight scales naturally—every node brings its personal connection bandwidth, avoiding the necessity for advanced capability planning.
- Operational simplicity – No intermediate storage to provision, handle, or synchronize.
The staff optimized Amazon S3 connection pooling and carried out parallel knowledge loading to maintain excessive throughput throughout the 16 nodes.
Choosing the distributed coaching framework
When coaching massive fashions throughout a number of GPUs, the mannequin’s parameters, gradients, and optimizer states have to be distributed throughout units. The staff evaluated completely different distributed coaching approaches to search out the optimum steadiness between reminiscence effectivity and coaching throughput:
- ZeRO-2 (Zero Redundancy Optimizer Stage 2) – This method partitions gradients and optimizer states throughout GPUs whereas protecting a full copy of mannequin parameters on every GPU. This helps scale back reminiscence utilization whereas sustaining quick communication, as a result of every GPU can straight entry the parameters in the course of the ahead go with out ready for knowledge from different GPUs.
- ZeRO-3 – This method goes additional by additionally partitioning mannequin parameters throughout GPUs. Though this helps maximize reminiscence effectivity (enabling bigger fashions), it requires extra frequent communication between GPUs to assemble parameters throughout computation, which might scale back throughput.
- FSDP2 (Totally Sharded Information Parallel v2) – PyTorch’s native method equally shards parameters, gradients, and optimizer states. It gives tight integration with PyTorch however entails comparable communication trade-offs as ZeRO-3.
Complete testing revealed DeepSpeed ZeRO-2 because the optimum framework for this configuration, delivering robust efficiency whereas effectively managing reminiscence:
- ZeRO-2 – 1,974 samples per second (carried out)
- FSDP2 – 1,833 samples per second
- ZeRO-3 – 869 samples per second
This framework alternative supplied the inspiration for attaining near-linear scaling throughout a number of nodes. The mix of those three key optimizations helped ship the dramatic coaching acceleration:
- Environment friendly distributed coaching – DeepSpeed ZeRO-2 enabled near-linear scaling throughout 128 GPUs (16 nodes × 8 GPUs)
- Excessive-throughput knowledge pipeline – Streaming from Amazon S3 straight sustained 64–80 GBps combination throughput throughout the cluster
Collectively, these enhancements helped scale back coaching time from 6 months to five days—enabling TGS to iterate on mannequin enhancements weekly slightly than semi-annually.
Increasing analytical capabilities
One of the vital achievements was increasing the mannequin’s discipline of view—how a lot 3D geological quantity it might analyze concurrently. A bigger context window permits the mannequin to seize each nice particulars (small fractures) and broad patterns (basin-wide fault programs) in a single go, serving to present insights that have been beforehand undetectable throughout the constraints of smaller evaluation home windows for TGS’s shoppers. The implementation by the TGS and AWS groups concerned adapting the next superior methods to allow ViTs to course of considerably bigger 3D seismic volumes:
- Ring consideration implementation – Every GPU processes a portion of the enter sequence whereas circulating key-value pairs to neighboring GPUs, steadily accumulating consideration outcomes throughout the distributed system. PyTorch offers an API that makes this easy:
- Dynamic masks ratio adjustment – The MAE coaching method required ensuring unmasked patches plus classification tokens are evenly divisible throughout units, necessitating adaptive masking methods.
- Decoder sequence administration – The decoder reconstructs the total picture by processing each the unmasked patches from the encoder and the masked patches. This creates a special sequence size that additionally must be divisible by the variety of GPUs.
The previous implementation enabled processing of considerably bigger 3D seismic volumes as illustrated within the following desk.
| Metric | Earlier (Baseline) | With Context Parallelism |
| Most enter measurement | 640 × 640 × 1,024 voxels | 1,536 × 1,536 × 2,048 voxels |
| Context size | 102,400 tokens | 1,170,000 tokens |
| Quantity improve | 1× | 4.5× |
The next determine offers an instance of 2D mannequin context measurement.
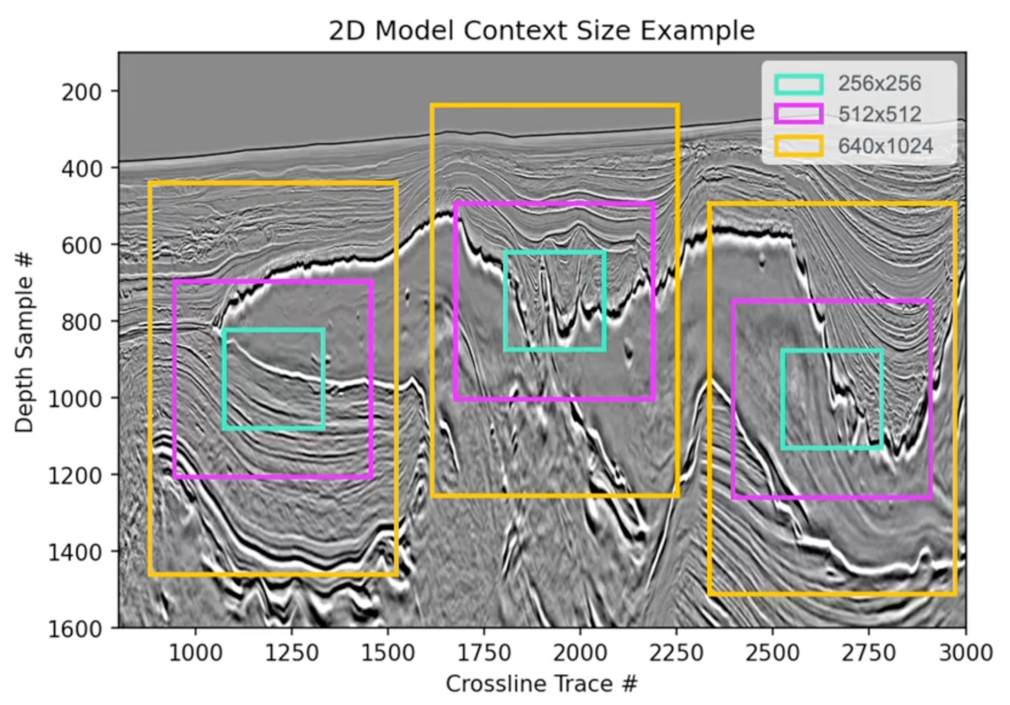
This growth permits TGS’s fashions to seize geological options throughout broader spatial contexts, serving to improve the analytical capabilities they’ll supply to shoppers.
Outcomes and impression
The collaboration between TGS and the AWS GenAIIC delivered substantial enhancements throughout a number of dimensions:
- Vital coaching acceleration – The optimized distributed coaching structure diminished coaching time from 6 months to five days—an approximate 36-fold speedup, enabling TGS to iterate quicker and incorporate new geological knowledge extra regularly into their fashions.
- Close to-linear scaling – The answer demonstrated robust scaling effectivity from single-node to 16-node configurations, attaining roughly 90–95% parallel effectivity with minimal efficiency degradation because the cluster measurement elevated.
- Expanded analytical capabilities – The context parallelism implementation allows coaching on bigger 3D volumes, permitting fashions to seize geological options throughout broader spatial contexts.
- Manufacturing-ready, cost-efficient infrastructure – The SageMaker HyperPod primarily based answer with streaming from Amazon S3 helps present an economical basis that scales effectively as coaching necessities develop, whereas serving to ship the resilience, flexibility, and operational effectivity wanted for manufacturing AI workflows.
These enhancements set up a robust basis for TGS’s AI-powered analytics system, delivering quicker mannequin iteration cycles and broader geological context per evaluation to shoppers whereas serving to defend TGS’s priceless knowledge belongings.
Classes realized and greatest practices
A number of key classes emerged from this collaboration that may profit different organizations working with large-scale 3D knowledge and distributed coaching:
- Systematic scaling method – Beginning with a single-node baseline institution earlier than progressively increasing to bigger clusters enabled systematic optimization at every stage whereas managing prices successfully.
- Information pipeline optimization is crucial – For data-intensive workloads, considerate knowledge pipeline design can present robust efficiency. Direct streaming from object storage with acceptable parallelization and prefetching delivered the throughput wanted with out advanced intermediate storage layers.
- Batch measurement tuning is nuanced – Growing batch measurement doesn’t all the time enhance throughput. The staff discovered excessively massive batch measurement can create bottlenecks in getting ready and transferring knowledge to GPUs. Via systematic testing at completely different scales, the staff recognized the purpose the place throughput plateaued, indicating the information loading pipeline had grow to be the limiting issue slightly than GPU computation. This optimum steadiness maximized coaching effectivity with out over-provisioning assets.
- Framework choice is determined by your particular necessities – Totally different distributed coaching frameworks contain trade-offs between reminiscence effectivity and communication overhead. The optimum alternative is determined by mannequin measurement, {hardware} traits, and scaling necessities.
- Incremental validation – Testing configurations at smaller scales earlier than increasing to full manufacturing clusters helped determine optimum settings whereas controlling prices in the course of the improvement part.
Conclusion
By partnering with the AWS GenAIIC, TGS has established an optimized, scalable infrastructure for coaching SFMs on AWS. The answer helps speed up coaching cycles whereas increasing the fashions’ analytical capabilities, serving to TGS ship enhanced subsurface analytics to shoppers within the power sector. The technical improvements developed throughout this collaboration—notably the variation of context parallelism to ViT architectures for 3D volumetric knowledge—reveal the potential for making use of superior AI methods to specialised scientific domains. As TGS continues to broaden its subsurface AI system and broader AI capabilities, this basis can help future enhancements similar to multi-modal integration and temporal evaluation.
To be taught extra about scaling your individual FM coaching workloads, discover SageMaker HyperPod for resilient distributed coaching infrastructure, or assessment the distributed coaching greatest practices within the SageMaker documentation. For organizations focused on comparable collaborations, the AWS Generative AI Innovation Heart companions with clients to assist speed up their AI initiatives.
Acknowledgement
Particular because of Andy Lapastora, Bingchen Liu, Prashanth Ramaswamy, Rohit Thekkanal, Jared Kramer, Arun Ramanathan and Roy Allela for his or her contribution.
In regards to the authors