

{kind=link}
I stay desirous about attempting to grasp how the way by which you extract the inputs wanted to calculate t-statistics from printed work can provide false positives when checking for p-hacking. This substack is about me strolling you thru this once more, however utilizing a stroll by video, a shiny app, in addition to a transcript of my change with Claude Code the place I figured this out myself. Right here is the transcript for individuals who need to see how I have a tendency to make use of Claude Code, much less as an automator and extra as a “considering companion”.
Thanks once more for studying! I hope you take pleasure in this submit. This can be a reader supported substack and as earlier than, all Claude Code posts will probably be out there free to everybody till they mechanically go behind a paywall (all posts ultimately go behind a paywall, however solely the non-Claude Code ones are randomly paywalled instantly).
Right here is the earlier submit from March twenty ninth the place I posted that I’d found out the extraction technique I had used to recreate t-statistics from the APE venture’s AI generated papers was giving false positives for p-hacking.
Let me simply overview a number of issues, although, in order that this submit stands sufficient alone that it may be learn.
Once we run a regression, we get a coefficient and we get a typical error. These are the 2 inputs used for our speculation assessments apart from a vital worth and a call rule. The choice rule will probably be a model of “if the t-statistic exceeds some vital worth, then reject at alpha equal to some fraction I’ve picked”. We use the vital worth of 1.96 due to the central restrict theorem. Underneath the legislation of enormous numbers, the imply of the calculations from the implied counterfactual samples related to an estimator’s sampling distribution is at all times centered on the true inhabitants estimand. And underneath the central restrict theorem, that sampling distribution is regular as n goes to infinity. The massive of enormous numbers tells us in regards to the imply, and the central restrict theorem tells in regards to the form, and we use the form, primarily, for calculating p-values. And we decide 1.96 as a result of for the traditional distribution, 95% of all chance is mass is inside 1.96 commonplace deviations from the imply (in both route).
So in case you run a regression, your package deal used will provide you with a number of the outcomes of speculation assessments. For one you’ll get a t-statistic, which is the “true ratio of the true coefficient and the true commonplace error”. You’ll get a p-value related to that t-statistic (what share of the remaining elements of the tail have t-statistics bigger than your t-statistic?). And also you’ll most likely get a 95% confidence interval. They comprise a lot of the identical info, with slight twists, and all of them are simply misunderstood by folks with no depth of statistical literacy.
However my level is that you’ll be making all of these speculation testing calculations off the “actual coefficients” and “actual commonplace errors” and never the rounded ones.
None of that is truly an issue, although. You around the coefficients and commonplace errors as a result of they the rounded numbers are solely executed for the aim of speaking outcomes. The rounded numbers will not be themselves used for any subsequent speculation testing calculations. The one purpose it issues on this case is that in case you are extracting the inputs from tables to assemble your individual t-statistics for a take a look at of p-hacking, then you’ll have measurement error that’s instantly pointing to a t-statistic of two, paradoxically. Put one other means, rounded coefficients and rounded commonplace errors at all times create heaping. It’s not simply that you just introduce measurement error — it’s that if you find yourself rounding these final two digits, you might be principally collapsing the ratio (for ratios that had been in both route) into a selected set of discrete numbers. The t-statistic will not be steady any extra.
So if rounding is at all times creating comparatively extra heaps after rounding than earlier than, the one factor that can make such issues visibly stand out is that if there are a variety of such situations proper round there within the first place.
There are literally a variety of methods to take a ratio of two single digit integers and get precisely 2. It’s truly the second commonest ratio you will get, the opposite being to get a ratio of 1. Let me present you all of the methods you get take two single digit integers and get a ratio of precisely 2:1.
-
2 / 1 = 2
-
4 / 2 = 2
-
6 / 3 = 2
-
8 / 2 = 2
What a couple of ratio of precisely 3:1 although? That one is more durable. There’s solely to was to take single digit integers, take a ratio, and get 3. They’re:
-
3 / 1 = 3
-
9 / 3 = 3
The one one that’s bigger than 2 is a ratio equalling 1. And there are 9 methods to take a ratio of single digit integers to get a price of 1. They’re:
-
1 / 1 = 1
-
2 / 2 = 1
-
3 / 3 = 1
And so forth.
So the difficulty is that when you’ve gotten numbers with main zeroes earlier than and after the decimal level (e.g., beta hat = 0.00313 vs beta hat = 3.313), the rounding you do is definitely creating de facto “single digit integers” for the aim of this instance. Have a look at the instance beneath that Claude Code gave me in our dialog to see what I imply. Now these will not be simply the only digit examples; you’ve received included issues like 18/9 and 12/6. However that’s simply one other means of explaining all of the spikes within the rounded to the thousandth case.

There are a number of shifting elements to this synthetic proof for p-hacking related to easy counting of t-statistic values. The opposite that isn’t as apparent I feel is the standard relationship between a regression coefficient’s personal worth and the dimensions of the end result itself.
Right here is an instance from the shiny app. The one on the left is when the dimensions is ‘giant’, and the one on the fitting is when the dimensions is ‘small’. And also you get the heaping on integers (and notably at 2) on the fitting however not the left. The correct being the small scaled end result and the left being its authentic scale. Why is that this occurring?
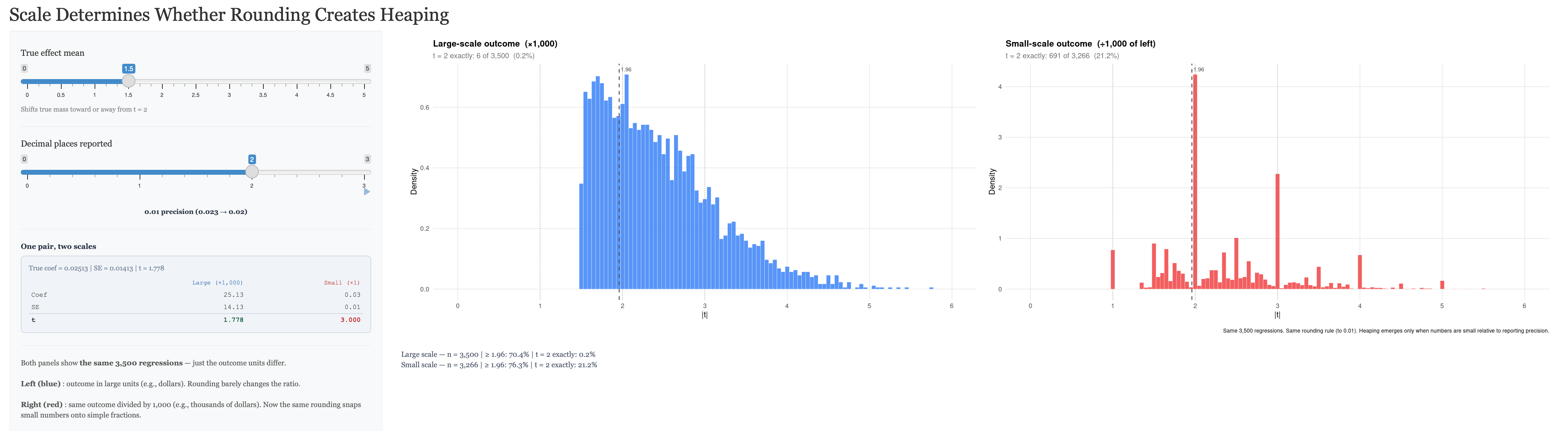
While you regress a quantity like annual earnings onto a dummy variable for faculty, the coefficient on faculty can have many numbers forward of the 0. So as an example, it is likely to be beta = $25,123.45 with a typical error of $5,456.78 giving a t-statistic of 4.6040796954. In the event you rounded these numbers, perhaps you’d spherical to the entire quantity: beta = $25,123 and a typical error of $5,457 and a t-statistic of 4.6038116181.
However when in case you had at all times for no matter purpose divided your earnings information by 10,000 first after which ran the regression. Nicely, in case you did that, your beta coefficient can also be scaled by 10,000 and your commonplace error too, however not your t-statistic. Your t-statistic is “scale invariant”. No matter you probably did to the information does rescale the coefficients and commonplace errors, nevertheless it does so proportionally, and thus the t-statistic being a ratio stays precisely the identical.
So in case you spherical coefficients and commonplace errors for tables, executed purely for rhetorical functions not scientific ones, you truly received’t change the t-statistic on your speculation assessments as a result of the t-statistic executed on your speculation assessments relies on non-rounded ones. However, in case you are a 3rd social gathering extracting the coefficients and commonplace errors from tables, which had been rounded for rhetorical functions, to assemble t-statistics, they are going to at all times be heaped regardless that the precise p-values within the papers themselves can have been executed off the true t-statistic, and never the one the third social gathering simply pulled.
The one means subsequently that you just’d falsely reject the null was if two issues had been true. First, the distribution of t-statistics should have giant mass round 2 within the first place. You’ve gotten easy features with focus round 2 and nonetheless not have the sort of bunching that density assessments are designed to choose up, thoughts you. In order that’s the very first thing — you’d must have a variety of true t-statistics in that neighborhood of two to ensure that there to be heaps at 2 after you collapse. And you’ll frankly want the dimensions of the end result to most likely be small.
The second shouldn’t be actually a principled assertion, however I’m saying in follow, with causal research, the place so typically the therapy variable is binary, then you definately’re going to be extra prone to decide up “small coefficients and small commonplace errors” (which means numbers with a number of zeroes after the decimal level first) when the end result was already small in scale. I feel it’s intuitive when you concentrate on it too.
Return to that instance the place you might be regressing whole annual earnings onto a dummy. Your coefficient on the dummy is prone to be giant too. You received’t get a t-statistic of precisely 2, moreover, even in case you spherical as a result of in such situations “rounding” is at all times about placement close to the decimal level. So you probably have a quantity like 1,527.345, rounding means to indicate 1,527. It doesn’t imply exhibiting 15, and it for positive doesn’t imply exhibiting 2. Rounding is in different phrases about coping with fractions for show functions. And so because of this, many of the ratio worth will probably be unchanged by rounding as a result of 1527 and 1527.345 within the numerator are kind of going to be the identical factor.
But when the dimensions had been small to start with, then perhaps your coefficient and commonplace error would’ve been extra like 0.01527 and 0.00456. So then the rounding does find yourself pushing you in direction of these explicit pairs I mentioned as you chop off increasingly more of the final digits.

I wished to now share a shiny app I made with Claude Code’s assist for example this. I even have a video stroll by. Let me share them each now. The video stroll by takes you thru the shiny app, as I’m nonetheless undecided I absolutely made a really intuitive shiny app within the first place. So I wished to simply assist you see easy methods to interpret this stuff as there are a number of shifting elements. Bear in mind the shifting elements are:
-
Rounding coefficients and commonplace errors for desk functions
-
Extracting rounded coefficients and rounded commonplace errors by a 3rd social gathering for the needs of reconstructing a t-statistic
-
The arithmetic implied by why rounded numbers can attain the quantity 2 so simply than 1.5 or 3 or most different numbers
-
The precise circumstances underneath which rounding coefficients and commonplace errors will give inflated t-stats at t=2 and result in false positives that there’s p-hacking when there isn’t
-
The position that the dimensions of the left-hand-side variable performs in all of this.
And the video simply walks you thru it. The precise shiny app is right here although. And sure that’s round 10,000 open tabs. Tune in Saturday morning when I’ll submit all of them.
Watch the video, have Claude Code learn this substack, learn it your self, however I feel between all of it you possibly can most likely work out the purpose I’m making.
So what I’m going to do subsequent is I’m going to do an explainer on the historical past of the Brodeur p-hacking papers, however much less so on the findings, and moreso in relation to those rounding issues. And the reason being as a result of Brodeur, et al., like me, had extracted their t-statistics from 50,000 regressions utilizing tables, which had been rounded, and apparently sufficient, the consequence of rounding was correlated with which analysis design the researchers used.
What I didn’t know is that within the evolution of these papers, the “repair” for this rounding problem that Brodeur et al had executed initially didn’t actually repair it. A staff wrote a remark within the AER pointing it out. Brodeur, et al. responded graciously, acknowledging the issue, and when an accurate repair was employed to beat it, the proof for p-hacking in difference-in-differences went away. The p-hacking for diff-in-diff was actually an artifact of the extraction technique. Instrumental variables nonetheless confirmed indicators of p-hacking, however diff-in-diff didn’t. Not on the 1.96 vital worth anyway (they are saying there’s nonetheless one thing on the 10% stage once they do the repair).
For the reason that AI generated papers on the Social Catalyst’s Lab APE Venture are overwhelmingly utilizing DiD, this extraction technique I used was notably delicate to it. And I simply thought I ought to actually attempt to make this stuff as clear as I can. I additionally really feel like this substack can attempt to educate others in regards to the mindset to be having for when David and them launch their very own evaluation of the AI papers. The problem they’ll have is that they must get the “true t-statistic” from the uncooked regression information, however because the AI brokers weren’t producing t-statistics, however slightly normally simply reporting asterisks (I discovered that additionally which I can present one other time) for tiers of p-values (e.g., ** if p<0.05), then the “true t-statistic” shouldn’t be within the papers, neither is it actually even being saved anyplace. In order that they’d must go subsequently write a brand new script to return and recollect all of it. However in contrast to any third social gathering doing meta-analysis on different folks’s work, that is truly doable. Often, it’s not.