

{kind=link}
Desk of Contents
- Autoregressive Mannequin Limits and Multi-Token Prediction in DeepSeek-V3
- Why Subsequent-Token Prediction Limits DeepSeek-V3
- Multi-Token Prediction in DeepSeek-V3: Predicting A number of Tokens Forward
- DeepSeek-V3 Structure: Multi-Token Prediction Heads Defined
- Gradient Insights for Multi-Token Prediction in DeepSeek-V3
- DeepSeek-V3 Coaching vs. Inference: How MTP Adjustments Each
- Multi-Token Prediction Loss Weighting and Decay for DeepSeek-V3
- Step-by-Step Implementation of Multi-Token Prediction Heads in DeepSeek-V3
- Integrating Multi-Token Prediction with DeepSeek-V3’s Core Transformer
- Theoretical Foundations: MTP, Curriculum Studying, and Auxiliary Duties
- Multi-Token Prediction Advantages: Coherence, Planning, and Sooner Convergence
- Abstract
Autoregressive Mannequin Limits and Multi-Token Prediction in DeepSeek-V3
Within the first three elements of this collection, we constructed the muse of DeepSeek-V3 by implementing its configuration and Rotary Placeal Embeddings (RoPE), exploring the effectivity beneficial properties of Multi-Head Latent Consideration (MLA), and scaling capability by way of the Combination of Consultants (MoE). Every of those parts provides a vital piece to the puzzle, progressively shaping a mannequin that balances efficiency, scalability, and effectivity. With these constructing blocks in place, we at the moment are able to sort out one other defining innovation: Multi-Token Prediction (MTP).
In contrast to conventional autoregressive fashions that predict one token at a time, MTP permits DeepSeek-V3 to forecast a number of tokens concurrently, considerably accelerating coaching and inference. This method not solely reduces computational overhead but additionally improves the mannequin’s means to seize richer contextual patterns throughout sequences.
On this lesson, we’ll discover the idea behind MTP, study why it represents a leap ahead in language modeling, and implement it step-by-step. As with the sooner classes, this installment continues our broader mission to reconstruct DeepSeek-V3 from scratch, exhibiting how improvements together with RoPE, MLA, MoE, and now MTP match collectively right into a cohesive structure that may culminate within the meeting and coaching of the complete mannequin.
This lesson is the 4th in a 6-part collection on Constructing DeepSeek-V3 from Scratch:
- DeepSeek-V3 Mannequin: Concept, Config, and Rotary Positional Embeddings
- Construct DeepSeek-V3: Multi-Head Latent Consideration (MLA) Structure
- DeepSeek-V3 from Scratch: Combination of Consultants (MoE)
- Autoregressive Mannequin Limits and Multi-Token Prediction in DeepSeek-V3 (this tutorial)
- Lesson 5
- Lesson 6
To find out about DeepSeek-V3 and construct it from scratch, simply preserve studying.
Why Subsequent-Token Prediction Limits DeepSeek-V3
Conventional language fashions are skilled with a easy goal: given tokens  , predict the following token
, predict the following token  . Mathematically, we maximize:
. Mathematically, we maximize:
") .
.
This autoregressive factorization is elegant and has confirmed remarkably efficient. Nonetheless, it has a basic limitation: the mannequin solely receives a coaching sign for instant next-token prediction. It by no means explicitly learns to plan a number of steps forward.
Contemplate producing the sentence: “The cat sat on the mat as a result of it was snug.” When predicting “as a result of,” the mannequin ought to already be contemplating how the sentence will full — together with the subordinate clause, the pronoun reference, and the conclusion. However with next-token prediction alone, there’s no express gradient sign encouraging this ahead planning. The mannequin may study it implicitly by way of publicity to many examples, however we’re in a roundabout way optimizing for it.
This limitation turns into particularly obvious in duties requiring long-term coherence (e.g., story era, multi-paragraph reasoning, or code era), the place later statements have to be per earlier declarations. The mannequin can simply generate regionally fluent textual content that globally contradicts itself as a result of its coaching goal solely seems one token forward.
Multi-Token Prediction in DeepSeek-V3: Predicting A number of Tokens Forward
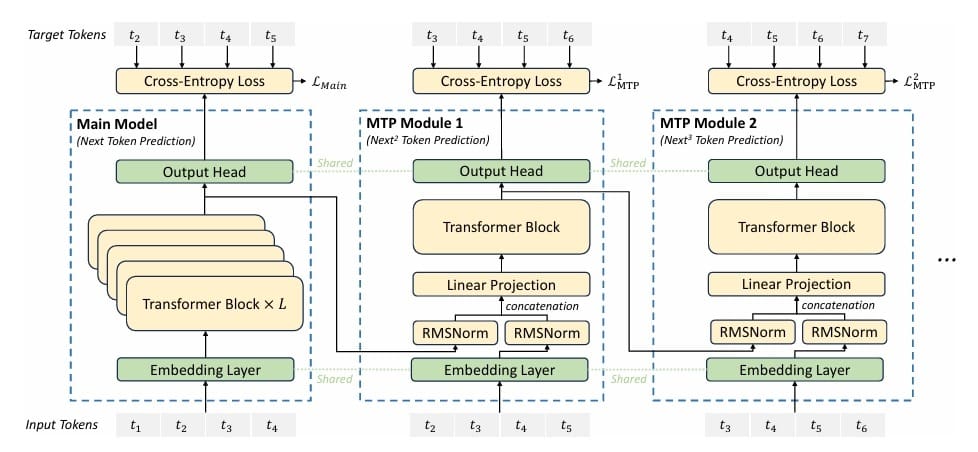
Multi-Token Prediction (Determine 1) addresses this by including auxiliary prediction heads that forecast a number of tokens into the longer term. Alongside the usual prediction ") , we additionally predict:
, we additionally predict:
")
")
and so forth for  tokens forward. Critically, these predictions are computed in parallel throughout coaching (not autoregressively) — we all know all floor fact tokens, so we are able to supervise all predictions concurrently.
tokens forward. Critically, these predictions are computed in parallel throughout coaching (not autoregressively) — we all know all floor fact tokens, so we are able to supervise all predictions concurrently.
The whole coaching goal turns into:
 + sumlimits_{d=1}^{n} lambda_d sumlimits_{t=1}^{T-d-1} log P(x_{t+d+1} mid x_{1:t}, x_{t+1:t+d})") ,
,
the place is the variety of future tokens we predict,  are weighting coefficients (usually lowering with distance:
are weighting coefficients (usually lowering with distance:  ), and we’ve explicitly proven that predictions at depth
), and we’ve explicitly proven that predictions at depth  situation on each the context as much as place
situation on each the context as much as place  and the intermediate tokens as much as
and the intermediate tokens as much as  .
.
DeepSeek-V3 Structure: Multi-Token Prediction Heads Defined
Implementing MTP requires architectural additions. We are able to’t simply reuse the principle language modeling head for future predictions — we have to situation on the intermediate tokens. DeepSeek-V3 implements this by way of a hierarchy of prediction heads, every specialised for a selected future depth.
Head Structure: For predicting tokens forward, we’ve got a head  that mixes:
that mixes:
- The hidden illustration from the Transformer at place :

- The embedding of the token at place
 :
: 
The mix follows:
} = text{Combine}(h_t, e_{t+d})")
This mixed illustration is then processed by way of a mini-Transformer (light-weight consideration and feedforward layers) earlier than projecting to the vocabulary:
} = h_t^{(d)} + text{Attention}(h_t^{(d)})")
} = h_t^{(d)} + text{MoE}(h_t^{(d)})")
} W_text{vocab}")
The instinct is highly effective: to foretell token  , we begin with the illustration at place (encoding all context), incorporate the embedding of token (telling us what phrase we’ve simply generated), course of by way of a small Transformer (permitting the mannequin to refine this mix), and undertaking to vocabulary (producing logits over the vocabulary). This structure naturally encourages ahead planning — the mannequin should study representations at place which might be helpful for predictions a number of steps forward.
, we begin with the illustration at place (encoding all context), incorporate the embedding of token (telling us what phrase we’ve simply generated), course of by way of a small Transformer (permitting the mannequin to refine this mix), and undertaking to vocabulary (producing logits over the vocabulary). This structure naturally encourages ahead planning — the mannequin should study representations at place which might be helpful for predictions a number of steps forward.
Gradient Insights for Multi-Token Prediction in DeepSeek-V3
From an optimization perspective, MTP supplies richer gradient alerts. In commonplace coaching, solely the hidden illustration receives gradients from predicting . With MTP, additionally receives gradients from predicting  . These extra gradients encourage to encode info related not only for the instant subsequent token, however for a number of future tokens.
. These extra gradients encourage to encode info related not only for the instant subsequent token, however for a number of future tokens.
Furthermore, the gradients from future predictions circulation by way of completely different pathways — by way of the MTP heads’ mini-Transformers. This creates a type of multi-task studying wherein completely different prediction depths impose distinct consistency constraints on the realized representations. A illustration that works properly for predicting 1 token forward won’t be good for predicting 5 tokens forward; MTP encourages studying representations that assist each.
We are able to consider this as including an implicit regularizer. The extra prediction targets constrain the realized representations to be extra structured, extra forward-looking, and extra globally coherent. It’s comparable in spirit to multi-task studying, the place auxiliary duties enhance illustration high quality even when we care primarily about one foremost process.
DeepSeek-V3 Coaching vs. Inference: How MTP Adjustments Each
Throughout Coaching: We compute all predictions in parallel. For a sequence of size  , we predict:
, we predict:
- Principal head: positions 1 by way of
 predict positions 2 by way of
predict positions 2 by way of - Depth-1 head: positions 1 by way of
 predict positions 3 by way of
predict positions 3 by way of - Depth-2 head: positions 1 by way of
 predict positions 4 by way of
predict positions 4 by way of
Every prediction makes use of the bottom fact intermediate tokens (accessible throughout coaching), so there’s no error accumulation. The losses are computed independently and summed with acceptable weights.
Throughout Inference: Apparently, MTP heads are usually not used throughout autoregressive era. As soon as coaching is full, we generate textual content utilizing solely the principle prediction head in the usual autoregressive method. The MTP heads have served their objective by bettering the realized representations; we don’t want their multi-step predictions at inference time.
That is computationally interesting: we get the advantages of MTP (higher representations, improved coherence) throughout coaching, however inference stays as environment friendly as a normal language mannequin. There’s no extra computational value at deployment.
Multi-Token Prediction Loss Weighting and Decay for DeepSeek-V3
The weighting coefficients are necessary hyperparameters. Intuitively, predictions additional sooner or later are tougher and fewer dependable, so we should always weight them much less closely. A standard scheme is exponential decay:

the place  . For instance, with
. For instance, with  :
:
- Depth 1 (predicting
 from ): weight 1.0
from ): weight 1.0 - Depth 2 (predicting
 from ): weight 0.5
from ): weight 0.5 - Depth 3 (predicting
 from ): weight 0.25
from ): weight 0.25
In our implementation, we use an easier method: uniform weighting of 0.3 for all MTP losses relative to the principle loss. That is much less subtle however simpler to tune and nonetheless supplies the core advantages.
Step-by-Step Implementation of Multi-Token Prediction Heads in DeepSeek-V3
Let’s implement the entire MTP system:
class MultiTokenPredictionHead(nn.Module):
"""
Multi-Token Prediction Head
Every head predicts a token at a particular future place.
Combines earlier hidden state with future token embedding.
"""
def __init__(self, config: DeepSeekConfig, depth: int):
tremendous().__init__()
self.depth = depth
self.n_embd = config.n_embd
# Mix earlier hidden state with future token embedding
self.combine_proj = nn.Linear(2 * config.n_embd, config.n_embd, bias=config.bias)
# Normalization
self.norm1 = RMSNorm(config.n_embd)
self.norm2 = RMSNorm(config.n_embd)
# Transformer parts (mini-transformer for every head)
self.attn = MultiheadLatentAttention(config)
self.mlp = MixtureOfExperts(config)
self.attn_norm = RMSNorm(config.n_embd)
self.mlp_norm = RMSNorm(config.n_embd)
Strains 1-24: Prediction Head Construction. Every MultiTokenPredictionHead is specialised for a selected depth — head 1 predicts 1 token forward, head 2 predicts 2 tokens forward, and so on. We retailer the depth for potential depth-conditional processing (although we don’t use it on this easy implementation).
The structure has 3 foremost parts: a mix projection that merges the hidden state and future token embeddings, normalization layers for stabilization, and a mini-Transformer consisting of an consideration module and an MoE. This mini-Transformer is full however light-weight — it has the identical structure as our foremost mannequin blocks however serves a specialised objective.
def ahead(self, prev_hidden, future_token_embed):
"""
Args:
prev_hidden: [B, T, D] - Hidden states from earlier layer
future_token_embed: [B, T, D] - Embeddings of future tokens
Returns:
hidden: [B, T, D] - Processed hidden states
"""
# Normalize inputs
prev_norm = self.norm1(prev_hidden)
future_norm = self.norm2(future_token_embed)
# Mix representations
mixed = torch.cat([prev_norm, future_norm], dim=-1)
hidden = self.combine_proj(mixed)
# Course of by way of mini-transformer
hidden = hidden + self.attn(self.attn_norm(hidden))
moe_out, _ = self.mlp(self.mlp_norm(hidden))
hidden = hidden + moe_out
return hidden
Strains 26-41: The Mixture Technique. The ahead methodology takes two inputs: prev_hidden (the hidden illustration at place , encoding all context as much as that time) and future_token_embed (the embedding of the token at place , offering details about what’s been generated). We normalize each inputs independently — this prevents scale mismatches between the hidden representations (which can have grown or shrunk by way of many Transformer layers) and the embeddings (which come contemporary from the embedding layer). We concatenate alongside the function dimension, doubling the dimensionality, then undertaking again to n_embd dimensions. This projection learns the right way to merge content material from these two completely different sources.
Strains 44-46: Mini-Transformer Processing. The mixed illustration flows by way of a light-weight Transformer. First, consideration with a residual connection: the mannequin can attend throughout the sequence, permitting place to collect info from different positions when predicting . That is essential as a result of the prediction may rely upon context earlier within the sequence. Then, MoE with a residual connection: the skilled networks can apply non-linear transformations, refining the mixed illustration. Using the identical MLA consideration and MoE that we’ve already carried out is elegant — we’re reusing well-tested parts. The pre-norm structure (normalizing earlier than consideration and MoE relatively than after) has turn into commonplace in fashionable Transformers for coaching stability.
Line 48: Returning Refined Hidden State. The output hidden state has the identical dimensionality because the enter ( ), so it may be projected by way of the vocabulary matrix to get logits for predicting
), so it may be projected by way of the vocabulary matrix to get logits for predicting  . This hidden state has been enriched with info from each the context (through
. This hidden state has been enriched with info from each the context (through prev_hidden) and the intermediate token (through future_token_embed), and has been refined by way of consideration and skilled processing. It represents the mannequin’s finest understanding of what ought to come next-next, not simply subsequent.
Integrating Multi-Token Prediction with DeepSeek-V3’s Core Transformer
The MTP heads combine into the principle mannequin throughout coaching. After computing the ultimate hidden states  from the principle Transformer, we apply the next operations:
from the principle Transformer, we apply the next operations:
- Principal prediction: Challenge to vocabulary to foretell , compute cross-entropy loss
- Depth-1 prediction: For every place , get embedding of (floor fact), mix with by way of head 1, undertaking to vocabulary to foretell
 , compute cross-entropy loss
, compute cross-entropy loss - Depth-2 prediction: For every place , get embedding of (floor fact), mix with head-1 output, undertaking to vocabulary to foretell
 , compute cross-entropy loss
, compute cross-entropy loss
The important thing perception is that we chain the heads: head 2’s enter consists of head 1’s output. This creates a hierarchical construction wherein every head builds on the earlier one, progressively wanting additional into the longer term.
Theoretical Foundations: MTP, Curriculum Studying, and Auxiliary Duties
MTP has attention-grabbing theoretical connections to different areas of machine studying:
Temporal Distinction Studying: In reinforcement studying, temporal distinction studying propagates worth info backward from future states. MTP does one thing analogous — it propagates gradient info backward from future predictions, encouraging present representations to encode future-relevant info.
Auxiliary Duties: MTP might be considered as an auxiliary process framework wherein the auxiliary duties are future token predictions. Analysis in multi-task studying reveals that auxiliary duties enhance illustration high quality when they’re associated however distinct from the principle process. Future token prediction is completely associated (it’s the identical process at completely different time steps) however distinct (it requires completely different info).
Curriculum Studying: The depth-weighted loss construction implements a type of curriculum — we emphasize near-future predictions (simpler, extra dependable) greater than far-future predictions (tougher, noisier). This step by step rising problem might assist coaching by first studying short-term dependencies earlier than tackling long-term construction.
Multi-Token Prediction Advantages: Coherence, Planning, and Sooner Convergence
Analysis on Multi-Token Prediction reveals a number of empirical advantages:
- Improved Coherence: Fashions skilled with MTP generate extra globally coherent textual content, with fewer contradictions or matter drift over lengthy generations
- Higher Planning: For duties like story writing or code era, the place early choices constrain later prospects, MTP helps the mannequin make forward-compatible decisions
- Sooner Convergence: The extra coaching alerts can speed up studying, reaching goal efficiency with fewer coaching steps
- Regularization: MTP acts as a regularizer, stopping overfitting by encouraging representations that assist a number of associated targets
Nonetheless, MTP additionally has prices. Coaching turns into extra advanced — we should handle a number of prediction heads and punctiliously weight their losses. Coaching is slower — computing a number of predictions per place will increase computation by an element of roughly  for future tokens (the issue is just not linear as a result of not all positions can predict tokens forward). Reminiscence utilization will increase because of the extra heads’ parameters.
for future tokens (the issue is just not linear as a result of not all positions can predict tokens forward). Reminiscence utilization will increase because of the extra heads’ parameters.
The tradeoff is usually favorable for bigger fashions and longer-form era duties. For small fashions or short-sequence duties, the overhead might outweigh the advantages. In our youngsters’s story era process, MTP ought to assist with sustaining narrative consistency throughout a narrative.
What’s subsequent? We advocate PyImageSearch College.
86+ complete lessons • 115+ hours hours of on-demand code walkthrough movies • Final up to date: March 2026
★★★★★ 4.84 (128 Rankings) • 16,000+ College students Enrolled
I strongly imagine that when you had the best trainer you can grasp pc imaginative and prescient and deep studying.
Do you suppose studying pc imaginative and prescient and deep studying must be time-consuming, overwhelming, and complex? Or has to contain advanced arithmetic and equations? Or requires a level in pc science?
That’s not the case.
All it is advisable to grasp pc imaginative and prescient and deep studying is for somebody to elucidate issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter schooling and the way advanced Synthetic Intelligence subjects are taught.
In case you’re severe about studying pc imaginative and prescient, your subsequent cease must be PyImageSearch College, probably the most complete pc imaginative and prescient, deep studying, and OpenCV course on-line immediately. Right here you’ll discover ways to efficiently and confidently apply pc imaginative and prescient to your work, analysis, and initiatives. Be part of me in pc imaginative and prescient mastery.
Inside PyImageSearch College you will discover:
- &verify; 86+ programs on important pc imaginative and prescient, deep studying, and OpenCV subjects
- &verify; 86 Certificates of Completion
- &verify; 115+ hours hours of on-demand video
- &verify; Model new programs launched commonly, guaranteeing you may sustain with state-of-the-art methods
- &verify; Pre-configured Jupyter Notebooks in Google Colab
- &verify; Run all code examples in your internet browser — works on Home windows, macOS, and Linux (no dev setting configuration required!)
- &verify; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
- &verify; Simple one-click downloads for code, datasets, pre-trained fashions, and so on.
- &verify; Entry on cellular, laptop computer, desktop, and so on.
Abstract
Within the first three classes of this collection, we progressively assembled the foundations of DeepSeek-V3: beginning with its configuration and Rotary Positional Embeddings (RoPE), then advancing to the effectivity of Multi-Head Latent Consideration (MLA), and scaling capability by way of the Combination of Consultants (MoE). Every of those improvements has added a vital piece to the structure, balancing effectivity, scalability, and representational energy. With these parts in place, we flip to a different breakthrough that redefines how language fashions study and generate textual content: Multi-Token Prediction (MTP).
Conventional autoregressive fashions depend on next-token prediction, a technique that, whereas efficient, might be shortsighted — focusing solely on instant context relatively than broader sequence-level patterns. MTP addresses this limitation by enabling the mannequin to foretell a number of tokens forward, accelerating coaching and inference whereas enriching contextual understanding. On this lesson, we discover the shortcomings of next-token prediction, introduce the structure of specialised prediction heads, and study why MTP works from a gradient perspective.
We then dive into sensible issues (e.g., weighted loss, decay methods, and implementation particulars), earlier than integrating MTP into the principle mannequin. By the tip, we see how this innovation not solely improves effectivity but additionally strengthens the theoretical and empirical foundations of DeepSeek-V3, bringing us nearer to assembling the entire structure.
Quotation Data
Mangla, P. “Autoregressive Mannequin Limits and Multi-Token Prediction in DeepSeek-V3,” PyImageSearch, S. Huot, A. Sharma, and P. Thakur, eds., 2026, https://pyimg.co/alrep
@incollection{Mangla_2026_autoregressive-model-limits-and-mTP-in-deepseek-v3,
writer = {Puneet Mangla},
title = {{Autoregressive Mannequin Limits and Multi-Token Prediction in DeepSeek-V3}},
booktitle = {PyImageSearch},
editor = {Susan Huot and Aditya Sharma and Piyush Thakur},
12 months = {2026},
url = {https://pyimg.co/alrep},
}
To obtain the supply code to this submit (and be notified when future tutorials are printed right here on PyImageSearch), merely enter your e-mail deal with within the kind under!

Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your e-mail deal with under to get a .zip of the code and a FREE 17-page Useful resource Information on Laptop Imaginative and prescient, OpenCV, and Deep Studying. Inside you will discover my hand-picked tutorials, books, programs, and libraries that can assist you grasp CV and DL!
The submit Autoregressive Mannequin Limits and Multi-Token Prediction in DeepSeek-V3 appeared first on PyImageSearch.