

{kind=link}
Within the final 15-20 years multilevel modeling has developed from a specialty space of statistical analysis into a normal analytical software utilized by many utilized researchers.
Stata has a whole lot of multilevel modeling capababilities.
I wish to present you the way simple it’s to suit multilevel fashions in Stata. Alongside the way in which, we’ll unavoidably introduce among the jargon of multilevel modeling.
I’m going to give attention to ideas and ignore most of the particulars that may be a part of a proper knowledge evaluation. I’ll offer you some strategies for studying extra on the finish of the put up.
Stata has a pleasant dialog field that may help you in constructing multilevel fashions. If you want a short introduction utilizing the GUI, you’ll be able to watch an illustration on Stata’s YouTube Channel:
Introduction to multilevel linear fashions in Stata, half 1: The xtmixed command
Multilevel knowledge are characterised by a hierarchical construction. A basic instance is youngsters nested inside lecture rooms and lecture rooms nested inside colleges. The take a look at scores of scholars inside the similar classroom could also be correlated because of publicity to the identical instructor or textbook. Likewise, the common take a look at scores of courses could be correlated inside a faculty because of the related socioeconomic degree of the scholars.
You could have run throughout datasets with these sorts of buildings in your individual work. For our instance, I want to use a dataset that has each longitudinal and classical hierarchical options. You possibly can entry this dataset from inside Stata by typing the next command:
use http://www.stata-press.com/knowledge/r12/productiveness.dta
We’re going to construct a mannequin of gross state product for 48 states within the USA measured yearly from 1970 to 1986. The states have been grouped into 9 areas based mostly on their financial similarity. For distributional causes, we can be modeling the logarithm of annual Gross State Product (GSP) however within the curiosity of readability, I’ll merely check with the dependent variable as GSP.
. describe gsp 12 months state area
storage show worth
variable title sort format label variable label
-----------------------------------------------------------------------------
gsp float %9.0g log(gross state product)
12 months int %9.0g years 1970-1986
state byte %9.0g states 1-48
area byte %9.0g areas 1-9
Let’s take a look at a graph of those knowledge to see what we’re working with.
twoway (line gsp 12 months, join(ascending)), ///
by(area, title("log(Gross State Product) by Area", measurement(medsmall)))
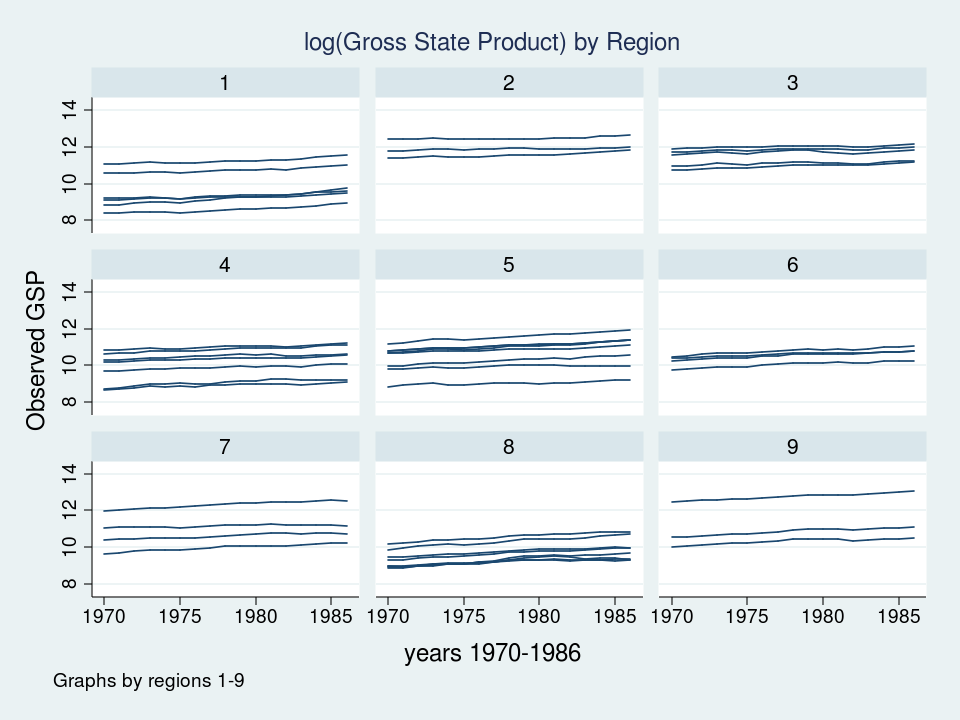{kind=link}
Every line represents the trajectory of a state’s (log) GSP over time 1970 to 1986. The very first thing I discover is that the teams of strains are totally different in every of the 9 areas. Some teams of strains appear greater and a few teams appear decrease. The second factor that I discover is that the slopes of the strains will not be the identical. I’d like to include these attributes of the information into my mannequin.
Let’s sort out the vertical variations within the teams of strains first. If we take into consideration the hierarchical construction of those knowledge, I’ve repeated observations nested inside states that are in flip nested inside areas. I used shade to maintain monitor of the information hierarchy.
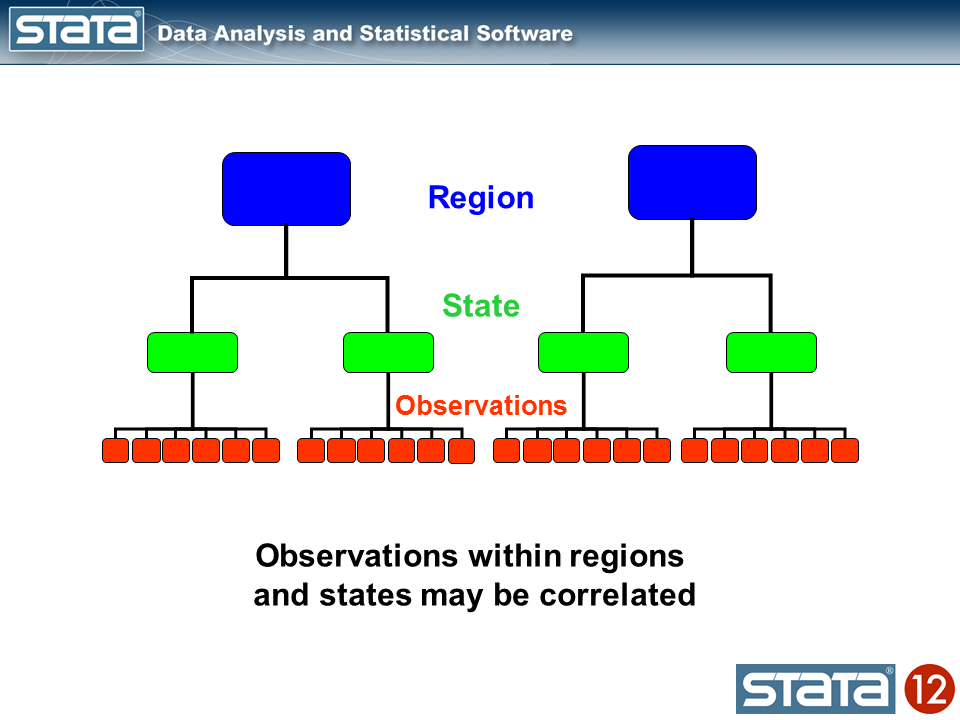
We may compute the imply GSP inside every state and word that the observations inside in every state range about their state imply.

Likewise, we may compute the imply GSP inside every area and word that the state means range about their regional imply.

We may additionally compute a grand imply and word that the regional means range in regards to the grand imply.
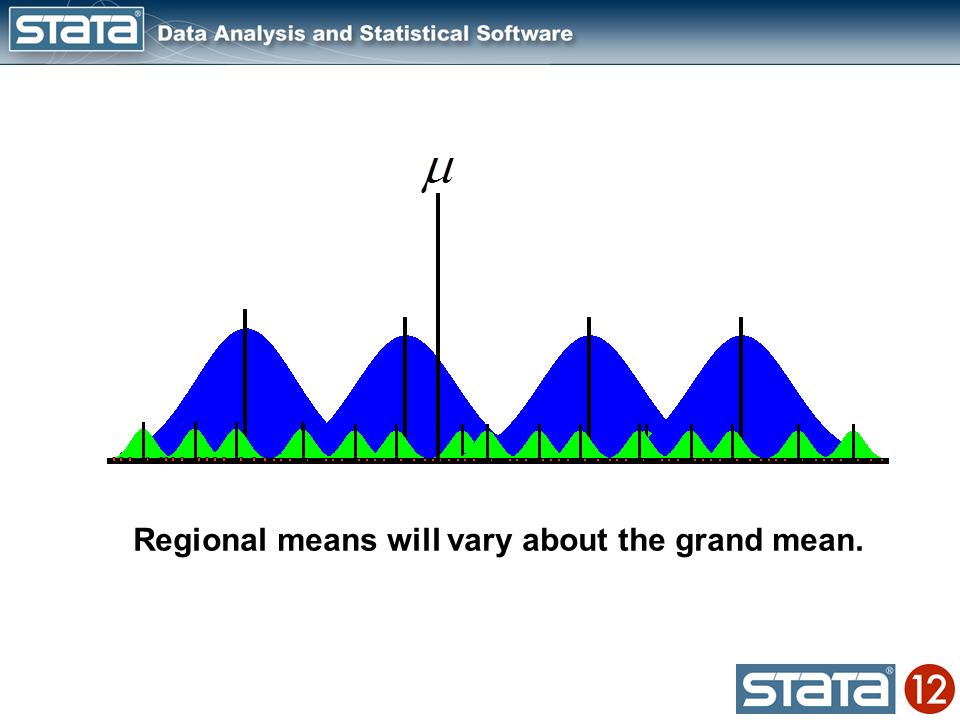
Subsequent, let’s introduce some notation to assist us hold monitor of our mutlilevel construction. Within the jargon of multilevel modelling, the repeated measurements of GSP are described as “degree 1”, the states are known as “degree 2” and the areas are “degree 3”. I can add a three-part subscript to every statement to maintain monitor of its place within the hierarchy.

Now let’s take into consideration our mannequin. The best regression mannequin is the intercept-only mannequin which is equal to the pattern imply. The pattern imply is the “mounted” a part of the mannequin and the distinction between the statement and the imply is the residual or “random” a part of the mannequin. Econometricians typically desire the time period “disturbance”. I’m going to make use of the image μ to indicate the mounted a part of the mannequin. μ may characterize one thing so simple as the pattern imply or it may characterize a group of unbiased variables and their parameters.

Every statement can then be described when it comes to its deviation from the mounted a part of the mannequin.
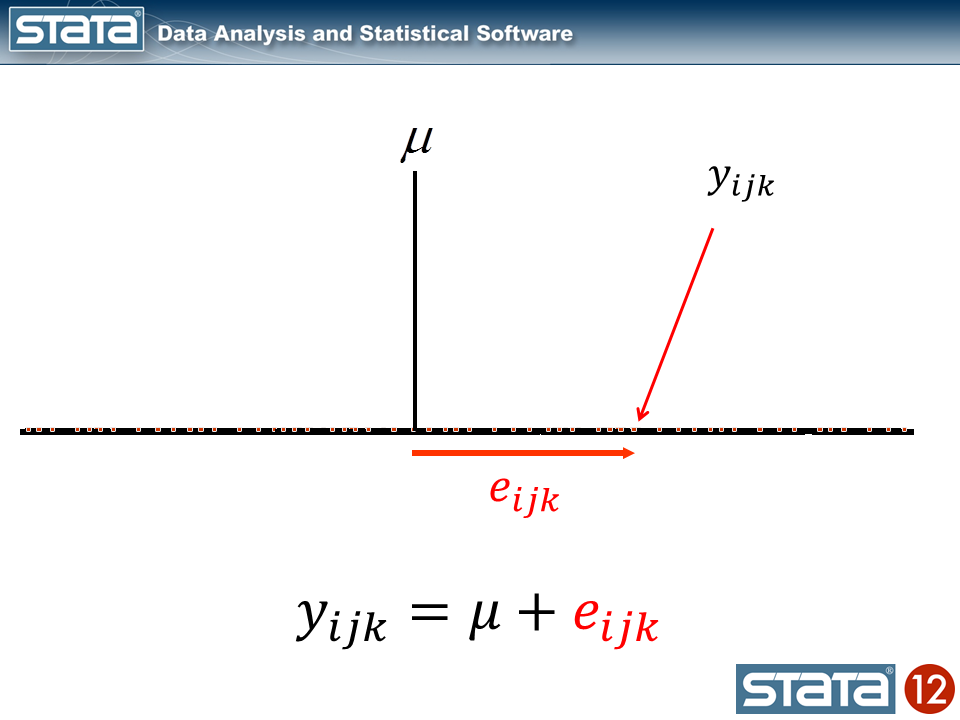
If we computed this deviation of every statement, we may estimate the variability of these deviations. Let’s strive that for our knowledge utilizing Stata’s xtmixed command to suit the mannequin:
. xtmixed gsp
Blended-effects ML regression Variety of obs = 816
Wald chi2(0) = .
Log probability = -1174.4175 Prob > chi2 = .
------------------------------------------------------------------------------
gsp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
_cons | 10.50885 .0357249 294.16 0.000 10.43883 10.57887
------------------------------------------------------------------------------
------------------------------------------------------------------------------
Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
-----------------------------+------------------------------------------------
sd(Residual) | 1.020506 .0252613 .9721766 1.071238
------------------------------------------------------------------------------
The highest desk within the output reveals the mounted a part of the mannequin which seems like another regression output from Stata, and the underside desk shows the random a part of the mannequin. Let’s take a look at a graph of our mannequin together with the uncooked knowledge and interpret our outcomes.
predict GrandMean, xb
label var GrandMean "GrandMean"
twoway (line GrandMean 12 months, lcolor(black) lwidth(thick)) ///
(scatter gsp 12 months, mcolor(purple) msize(tiny)), ///
ytitle(log(Gross State Product), margin(medsmall)) ///
legend(cols(4) measurement(small)) ///
title("GSP for 1970-1986 by Area", measurement(medsmall))
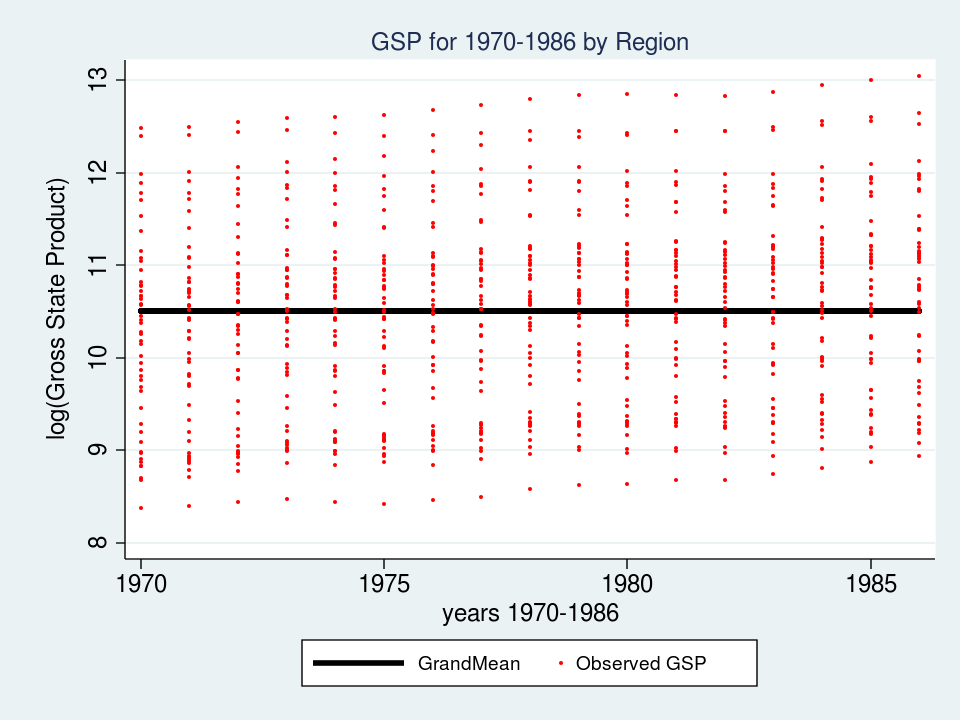
The thick black line within the middle of the graph is the estimate of _cons, which is an estimate of the mounted a part of mannequin for GSP. On this easy mannequin, _cons is the pattern imply which is the same as 10.51. In “Random-effects Parameters” part of the output, sd(Residual) is the common vertical distance between every statement (the purple dots) and glued a part of the mannequin (the black line). On this mannequin, sd(Residual) is the estimate of the pattern commonplace deviation which equals 1.02.
At this level it’s possible you’ll be considering to your self – “That’s not very fascinating – I may have completed that with Stata’s summarize command”. And you’d be right.
. summ gsp
Variable | Obs Imply Std. Dev. Min Max
-------------+--------------------------------------------------------
gsp | 816 10.50885 1.021132 8.37885 13.04882
However right here’s the place it does change into fascinating. Let’s make the random a part of the mannequin extra complicated to account for the hierarchical construction of the information. Take into account a single statement, yijk and take one other take a look at its residual.
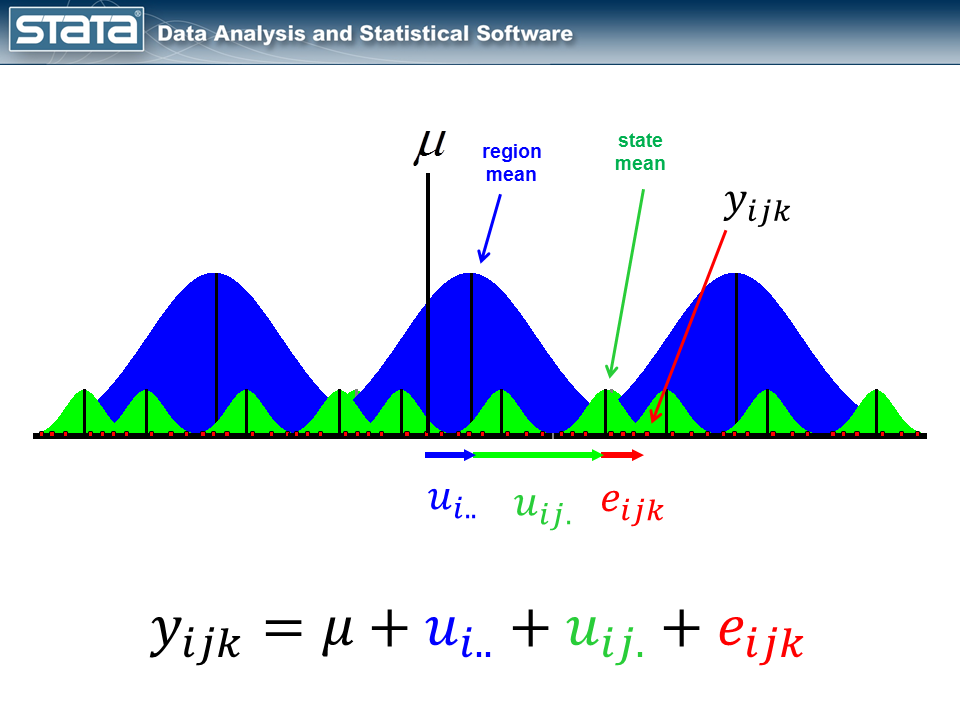
The statement deviates from its state imply by an quantity that we are going to denote eijk. The statement’s state imply deviates from the the regionals imply uij. and the statement’s regional imply deviates from the mounted a part of the mannequin, μ, by an quantity that we are going to denote ui... We have now partitioned the statement’s residual into three components, aka “elements”, that describe its magnitude relative to the state, area and grand means. If we calculated this set of residuals for every statement, wecould estimate the variability of these residuals and make distributional assumptions about them.

These sorts of fashions are sometimes referred to as “variance part” fashions as a result of they estimate the variability accounted for by every degree of the hierarchy. We will estimate a variance part mannequin for GSP utilizing Stata’s xtmixed command:
xtmixed gsp, || area: || state:
------------------------------------------------------------------------------
gsp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
_cons | 10.65961 .2503806 42.57 0.000 10.16887 11.15035
------------------------------------------------------------------------------
------------------------------------------------------------------------------
Random-effects Parameters | Estimate Std. Err. [95% Conf. Interval]
-----------------------------+------------------------------------------------
area: Identification |
sd(_cons) | .6615227 .2038944 .361566 1.210325
-----------------------------+------------------------------------------------
state: Identification |
sd(_cons) | .7797837 .0886614 .6240114 .9744415
-----------------------------+------------------------------------------------
sd(Residual) | .1570457 .0040071 .149385 .1650992
------------------------------------------------------------------------------
The mounted a part of the mannequin, _cons, continues to be the pattern imply. However now there are three parameters estimates within the backside desk labeled “Random-effects Parameters”. Every quantifies the common deviation at every degree of the hierarchy.
Let’s graph the predictions from our mannequin and see how effectively they match the information.
predict GrandMean, xb
label var GrandMean "GrandMean"
predict RegionEffect, reffects degree(area)
predict StateEffect, reffects degree(state)
gen RegionMean = GrandMean + RegionEffect
gen StateMean = GrandMean + RegionEffect + StateEffect
twoway (line GrandMean 12 months, lcolor(black) lwidth(thick)) ///
(line RegionMean 12 months, lcolor(blue) lwidth(medthick)) ///
(line StateMean 12 months, lcolor(inexperienced) join(ascending)) ///
(scatter gsp 12 months, mcolor(purple) msize(tiny)), ///
ytitle(log(Gross State Product), margin(medsmall)) ///
legend(cols(4) measurement(small)) ///
by(area, title("Multilevel Mannequin of GSP by Area", measurement(medsmall)))
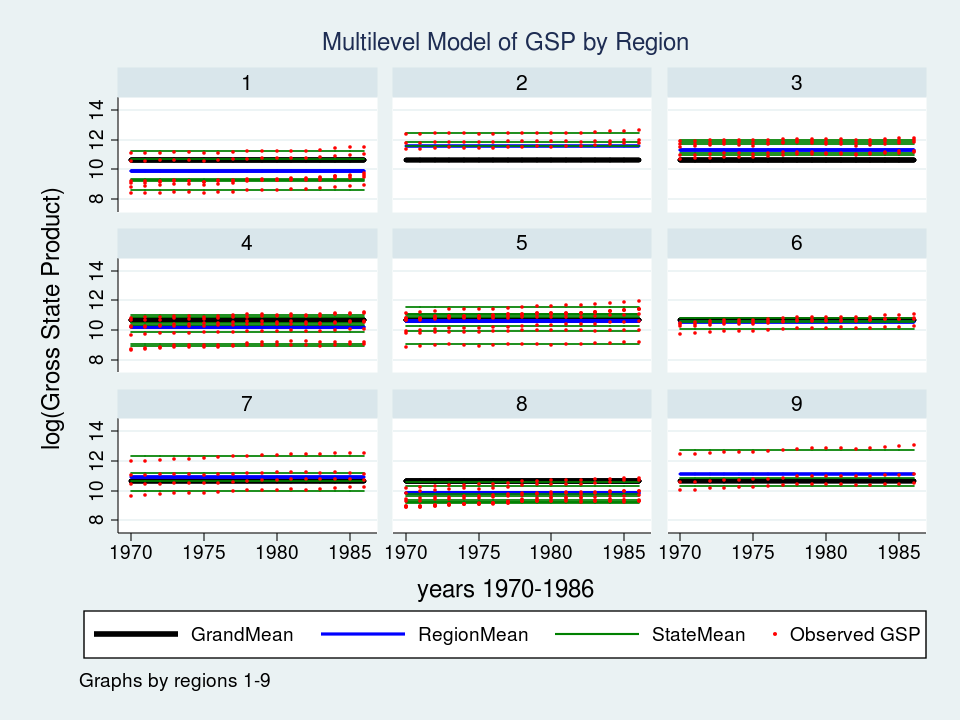
Wow – that’s a pleasant graph if I do say so myself. It could be spectacular for a report or publication, nevertheless it’s slightly powerful to learn with all 9 areas displayed directly. Let’s take a better take a look at Area 7 as a substitute.
twoway (line GrandMean 12 months, lcolor(black) lwidth(thick)) ///
(line RegionMean 12 months, lcolor(blue) lwidth(medthick)) ///
(line StateMean 12 months, lcolor(inexperienced) join(ascending)) ///
(scatter gsp 12 months, mcolor(purple) msize(medsmall)) ///
if area ==7, ///
ytitle(log(Gross State Product), margin(medsmall)) ///
legend(cols(4) measurement(small)) ///
title("Multilevel Mannequin of GSP for Area 7", measurement(medsmall))

The purple dots are the observations of GSP for every state inside Area 7. The inexperienced strains are the estimated imply GSP inside every State and the blue line is the estimated imply GSP inside Area 7. The thick black line within the middle is the general grand imply for all 9 areas. The mannequin seems to suit the information pretty effectively however I can’t assist noticing that the purple dots appear to have an upward slant to them. Our mannequin predicts that GSP is fixed inside every state and area from 1970 to 1986 when clearly the information present an upward pattern.
So we’ve tackled the primary characteristic of our knowledge. We’ve succesfully integrated the essential hierarchical construction into our mannequin by becoming a variance componentis utilizing Stata’s xtmixed command. However our graph tells us that we aren’t completed but.
Subsequent time we’ll sort out the second characteristic of our knowledge — the longitudinal nature of the observations.
If you happen to’d prefer to study extra about modelling multilevel and longitudinal knowledge, try
Multilevel and Longitudinal Modeling Utilizing Stata, Third Version
Quantity I: Steady Responses
Quantity II: Categorical Responses, Counts, and Survival
by Sophia Rabe-Hesketh and Anders Skrondal
or join our in style public coaching course “Multilevel/Blended Fashions Utilizing Stata“.
There’s a course arising in Washington, DC on February 7-8, 2013.