

{kind=link}
That is a part of a long-running collection on Claude Code which started again in mid-December. Yow will discover all of them right here. My curiosity is persistently extra on the top of “utilizing Claude Code for sensible empirical analysis” outlined as the kind of quantitative (largely causality) analysis you see lately within the social sciences which focuses on datasets saved in spreadsheets, calculations utilizing scripting programming languages (R, Stata, python) and econometric estimators. However I additionally write “Claude Code fan fiction” type essays, after which generally identical to many marvel the place we’re going now with such radical issues as AI Brokers that look like shifting which cognitive actions and duties people have a comparative benefit in and which of them we don’t.
For many who are new to the substack, I’m the Ben H. Williams Professor of Economics at Baylor College, and presently on go away educating statistics lessons within the Authorities division at Harvard College. I dwell in Again Bay, and find it irresistible right here — I notably love the New England winters, the Patriots, the Celtics, the Crimson Sox, and New England as a area extra usually. I get pleasure from writing about econometrics, causal inference, AI and private stuff. I’m the creator of a guide known as Causal Inference: The Mixtape (Yale College Press, 2021) in addition to the creator of a brand new guide popping out this summer time that is kind of a sequel/revision to it known as Causal Inference: The Remix (additionally with Yale).
This substack is a labor of affection. When you aren’t a paying subscriber, please take into account changing into one! I believe you’ll get pleasure from digging into the previous archive. I even have a podcast known as The Mixtape with Scott which is in its fifth season. This season is co-hosted with Caitlin Myers and we’re doing a analysis challenge on the air utilizing Claude Code to proceed serving to ourselves and others be taught extra about what is feasible with AI brokers for “sensible empirical work”. Thanks once more for becoming a member of — now learn on to be taught miserable information about how six statistical packages for the similar econometric estimator with the similar specs yields six extraordinarily completely different solutions to the identical query and the identical dataset. Sigh. I’ve three lengthy movies belong. The primary one reveals me doing the experiment which I describe under, whereas the second and third one reveals me reviewing the findings. Get pleasure from! And don’t overlook to ponder changing into a paying subscriber which is barely $5/month! 🙂
Video 1: Organising the Claude Codit Audit (52 minutes)
Slides 1-20 of the “stunning deck” breakdown of CS evaluation (52 minutes)
Slides 21-47 continued (43 minutes)
I’ll inform this story in attribute melodrama. If I have been to attempt to clarify this to my youngsters, they’d assume I’m being a tad bit dramatic once I inform them the sky is falling due to the variation in estimates for a similar estimator, identical information, identical covariates that I had discovered. However I’d simply say sticks and stones could break your fathers bones, however nothing hurts worse than whenever you make enjoyable of me youngsters so please cease and care in regards to the issues I care about.
However this substack isn’t about that. This substack is in regards to the outcomes of an experiment I did utilizing Claude Code. Six packages, identical estimator, identical information, identical covariates, with ATT estimates with as a lot as 50% of variation coming from which language-specific bundle you employ, and coefficient estimates starting from 0.0 to 2.38 on an essential query (psychological well being hospital closures) and final result (homicides).
One bundle stated the remedy impact was roughly half a normal deviation. One other stated it was greater than double that.
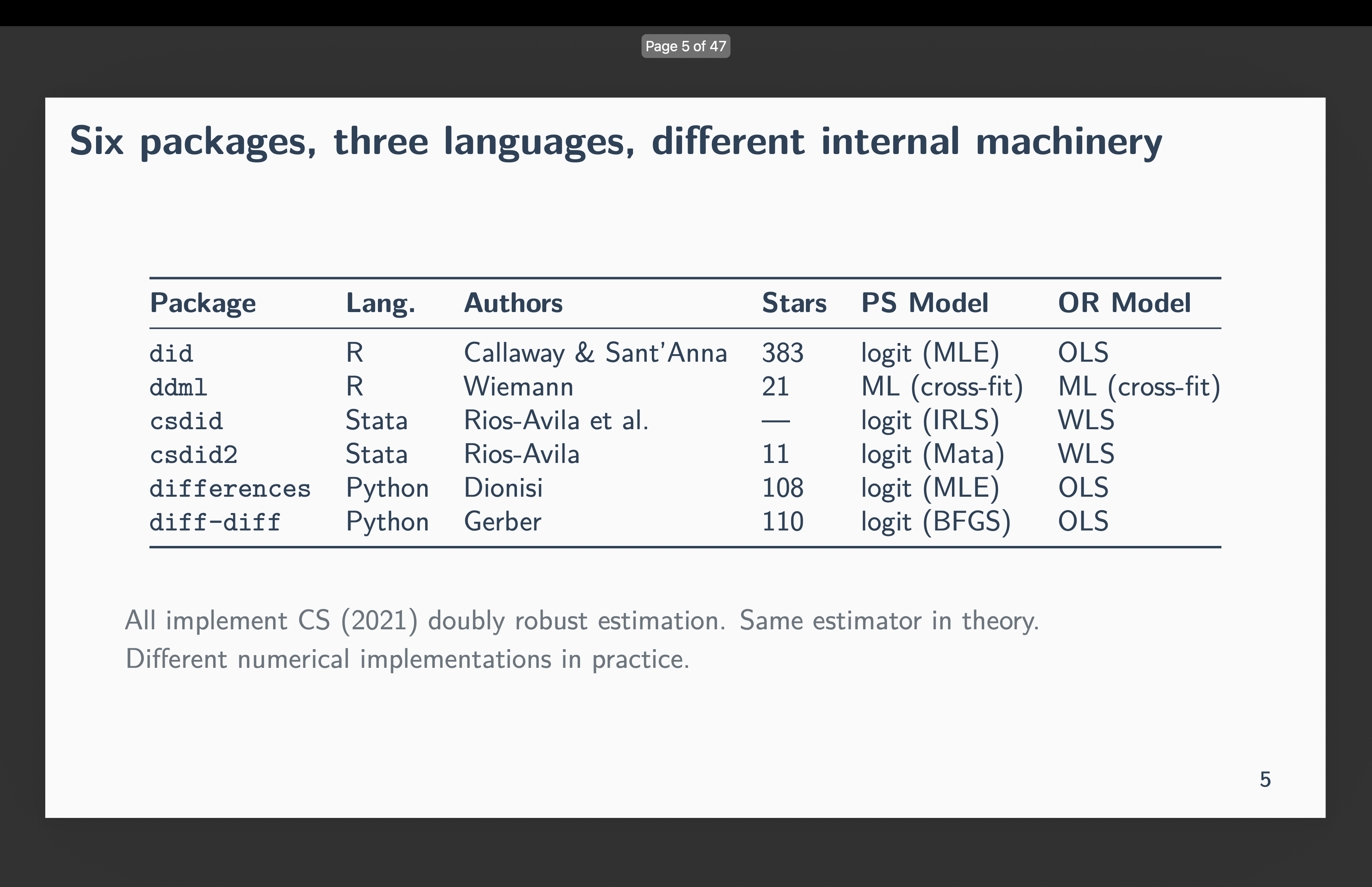
Callaway and Sant’Anna (2021) or CS has over 10,750 Google Scholar citations. Six impartial groups constructed software program to implement it:
-
did (R) — Callaway and Sant’Anna themselves
-
ddml (R) — Ahrens, Hansen, Schaffer, and Wiemann
-
csdid (Stata) — Rios-Avila, Sant’Anna, and Callaway
-
csdid2 (Stata) — Rios-Avila
-
variations (Python) — Dionisi
-
diff-diff (Python) — Gerber
My experiment was easy — have Claude Code wrote nearly 100 scripts (16 specs throughout all six packages in three programming languages concurrently) to find out the “between” or “across-package” variation in estimates, in addition to the inside. I selected the identical estimator (CS) with the precise 16 specs in order that I might determine exactly what was driving the variation if it existed, in addition to measure how giant it’s. However the thought is easy: CS is 4 averages and three subtractions with a propensity rating and final result regression.
None of that’s random excluding the bootstrapped commonplace errors (which I don’t examine) and thus the one factor that may clarify variation in estimated ATTs is bundle implementation of the propensity scores, the dealing with of close to separation in that propensity rating by the language-specific bundle, and any delicate points like rounding. As it isn’t even frequent for economics articles to report which bundle and model they used of an estimator, not to mention carry out the form of diagnostics I do right here (i.e., 96 specs throughout six languages to research the above points), I believe the findings are a bit worrisome.
However as I’ve written earlier than, I believe one of many actual contributions that Claude Code and AI brokers extra usually can deliver to the desk is the position of the subagents to carry out numerous varieties of, let’s name it, “code audit” on excessive worth, time intensive, excessive stakes issues. And that’s exactly what that is:
That is precisely the form of “excessive worth, time intensive, tough, excessive stakes” work that AI brokers ought to do. Writing similar specs throughout R, Stata, and Python would ordinarily imply both being competent in a number of programming languages, packages in a language, econometrics, and good empirical practices (e.g., steadiness tables, histogram distributions of propensity scores, falsifications). An individual with such expertise is both normally not one among us, and doubtless not our coauthors, and if we all know of somebody like that, they’re most likely individuals with very excessive alternative prices and aren’t going to mortgage us their experience for a month or two of labor that’s finally simply tedious coding work.
However Claude Code can, but in addition ought to, do that. And so a part of my conclusion on this train is a straightforward coverage advice for all empiricists: do that. Use Claude Code to carry out intensive code audits. Yow will discover my philosophy of it right here at my repo “MixtapeTools” and my referee2 persona particularly. Simply have Claude Code learn it and clarify the concept of referee2 which tries to easily replicate our whole pipelines in a number of languages to catch primary coding errors. However in right this moment’s train, it was additionally to doc that generally there is no such thing as a coding mistake and but the estimates from completely different packages could range extensively. However a code audit would’ve discovered that too.
So right here is the gist. The info come from a staggered rollout of psychological well being facilities throughout Brazilian municipalities, 2002-2016. I’ve 29 covariates masking demographics, economics, well being infrastructure, and inhabitants traits. Sixteen specs pattern the house from zero covariates up by means of all 29. All variation is coming from covariates, each inside a bundle (i.e., which covariates) however extra importantly throughout packages. And that’s the headline — even for similar specs, you will get variation in estimates and generally as a lot as anyplace from an ATT of zero to an ATT of two.38. Even in case you drop the zero, some specs yielded estimates starting from 0.45 extra homicides to 2.38 homicides (measured as a municipality inhabitants murder price).
A 5 fold distinction in estimated results of a psychological well being hospital altering within the murder price is just not trivial.
Zero covariates. I do know it’s the covariates as a result of with zero covariates, all 5 packages agreed to 4 decimal locations: ATT round 0.31. The info are similar, the estimator is similar, the baseline works. And so this turns into one among my suggestions: all the time take a look at the baseline with out covariates in your coding audit, not since you imagine it’s the right estimator, however as a result of it’s the best specification, and helps decide some primary information earlier than you go additional.
One covariate. Then I added one covariate — poptotaltrend, a inhabitants development variable — the estimates fanned out throughout estimators. For that single-covariate specification, the ATTs ranged from 0.45 (ddml) to 1.15 (csdid). Add just a few extra covariates and the R bundle did began silently returning zeros. Although you’d see the output that clearly signifies an issue, I believe the truth that it’s spitting out zeroes for the ATT (and NAs for the usual error) is extra simply missed going ahead if persons are utilizing AI brokers exterior of the R Studio surroundings. So I doc it anyway and word that for these 9 out of 16 specs, the ATT = 0.000, SE = NA.
However importantly — that doesn’t occur for the others. So you will have R’s did refusing to do the calculations (however which nonetheless had a zero ATT), however you will have the others going ahead. How is that doable precisely? Or possibly why is the higher query.
I requested Claude Code to calculate a two-way ANOVA decomposition of the variation in these estimates to attempt to unpack the story a bit extra. Forty p.c of the entire variation in ATT estimates comes from specification selection — which covariates you embody. Sixteen p.c comes from bundle selection — which software program you employ, holding the specification mounted. And 44 p.c is the interplay: packages breaking at completely different specs in several methods. That interplay time period is just not noise. It’s systematic disagreement.
The determine under reveals the specification curve — one line per bundle, x-axis is the 16 specs ordered by variety of covariates. And every dot above the notches on the x-axis symbolize the straightforward ATT. So when there are vertical gaps, it means they disagree, and when they’re on high of one another, all of them agree. Word that on the baseline they’re stacked on high of one another. However after we embody inhabitants development, estimates fan out. By the point you hit three or 4 covariates, the strains are unfold throughout a variety wider than the estimate itself. It’s at okay=4 additionally that R’s did started spitting out zeros.
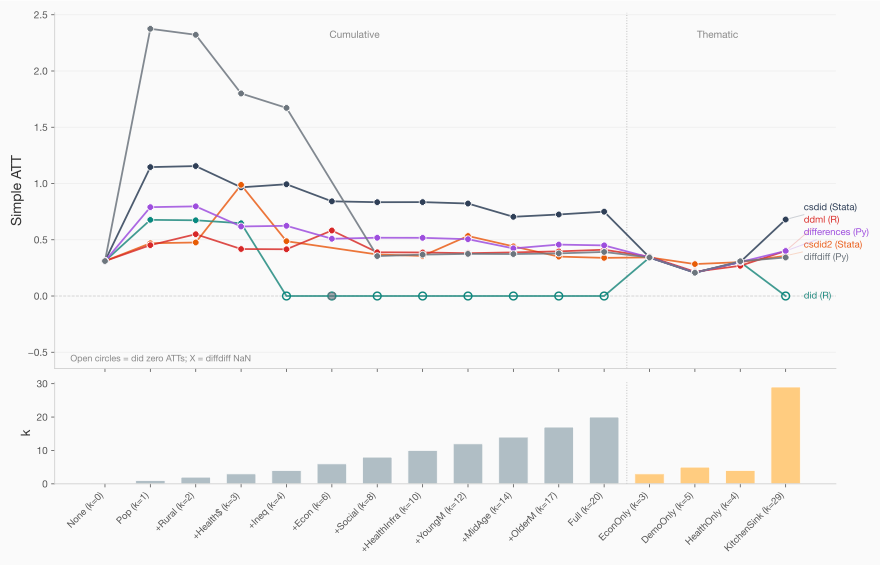
The grey strains specs all embody inhabitants development as a covariate. The final one labeled “Kitchen Sink” consists of all 29 covariates (together with inhabitants development). And those labeled “Econ solely (okay=3), DemoOnly (okay=5) and healthOnly (okay=4)” embody 3, 5 and 4 covariates from these descriptions (however not inhabitants development). Word that these three largely agree — the discrepancy are largest when inhabitants development was included.
The offender is poptotaltrend. Why is that? As a result of it is the same as the inhabitants of the municipality multiplied by the 12 months. That’s how the development is modeled. However some municipalities are gigantic. As an example Rio has nearly 7 million individuals. Whereas rural municipalities usually are not surprisingly a lot smaller. When multiplied by the 12 months, you find yourself with the worth being as much as 10 billion.
So what? A quantity is a quantity, isn’t it? What’s so onerous a couple of “huge quantity” anyway?
Here’s what Claude Code thinks is occurring. He thinks the issue is coming not from the econometric estimator however from how every bundle is storing giant numbers.
Computer systems retailer about 15-16 important digits in a 64-bit floating level quantity. When two columns of your covariate matrix differ by an element of 10 billion, the matrix inversion that sits inside each propensity rating and each final result regression can not distinguish the small column from rounding error. The situation variety of the design matrix — a measure of how a lot error will get amplified whenever you invert it — exceeds the brink the place computation turns into unreliable.
In order that’s the primary downside — it has to do merely with how a big quantity is getting saved and the implications of a giant quantity with matrix inversion. However that’s really fixable, too. You may simply divide a big quantity by one other giant quantity. And but that’s not the one downside although that could be a main a part of the issue within the image above.
The deeper situation is near-separation within the propensity rating. With 29 covariates and a few remedy cohorts as small as 47 municipalities towards 4,000 controls, sure covariate combos completely predict remedy project. The estimated propensity rating hits zero or one for these items. The inverse chance weight — which is the propensity rating divided by one minus the propensity rating — goes to infinity. Widespread help fails.
Once more, so what. Any clarification you give like that’s generic. It ought to be failing for all of the packages, proper? That is the place there’s some issues beneath the hood that most individuals by no means see. That is the hidden first stage that almost all utilized researchers by no means see.
As a fast apart, I believe one of many casualties of economics ignoring propensity scores for a number of a long time is that we don’t know the essential diagnostics with respect to propensity rating — like checking for frequent help with histograms or on this case checking for close to separation, and even what meaning. And also you’d be tremendous in case you by no means ran propensity rating evaluation in ideas — besides that propensity scores are beneath the hood in CS, and in marginal remedy results with instrumental variables. And people methodologies are fashionable, and since they’ve propensity scores inside them, we’re unknowingly venturing into waters the place we possibly have deep information about diff-in-diff, and even CS doubtlessly, however shallow to no information about propensity rating, and thus actually don’t understand what to verify, and even to verify. Significantly when these propensity scores usually are not being displayed throughout the bigger bundle output itself.
To not point out that many individuals write Callaway and Sant’Anna as a regression equation and transfer on. So even then there’s a good quantity of distance persons are having in observe with the propensity rating, even for a preferred estimator like CS. Which is why I believe it’s vital that we be taught it — even when you’ll simply use diff-in-diff. As a result of in case you use diff-in-diff, you may be utilizing propensity scores sooner or later, however you could not understand it. And if a paper writes down a regression equation and says they estimate it with CS, they nearly definitely don’t understand it in any other case there could be a propensity rating within the equation.
So beneath, each doubly strong estimate requires each a propensity rating mannequin and an final result regression. When you will have 29 covariates, you will have 536,870,911 doable covariate subsets — that’s 2 to the 29 minus 1. That is known as “the curse of dimensionality”. And you may hit that curse far, far sooner than the kitchen sink regression. And when you will have okay>n (i.e., extra dimensions than observations), you should have extra parameters than items, and so you can’t even estimate the mannequin.
Which is ok when all packages inform you this or do the identical factor, however they don’t all try this. And even in case you can see it from R Studio, if we’re shifting in direction of automated CLI pipelines, we could not see regardless of the packages are spitting out anyway.
Take away poptotaltrend from the covariate set and all 5 packages comply with inside 0.007. The between-package hole drops from over 0.57 to beneath 0.08. The left-hand aspect reveals the divergence with poptotaltrend; the right-hand aspect under reveals with out. Discover how dropping will get us intently to close similar ATT estimates.
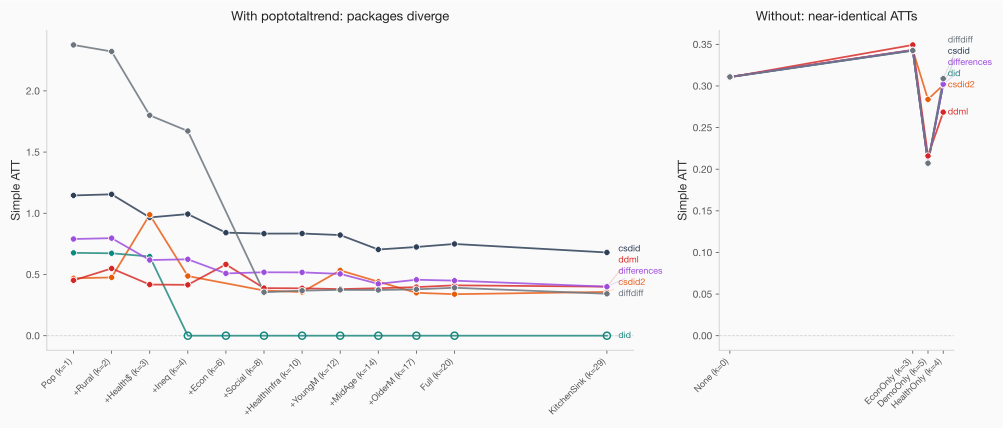
And right here’s the factor that retains me up: this isn’t actually about difference-in-differences. A easy logistic regression would have the identical near-separation downside with the identical covariates. This goes past Callaway and Sant’Anna. Any estimator that is determined by a propensity rating is uncovered and that’s as a result of the packages all differ with respect to the optimizer used (extra under on that).
If the “huge quantity” downside is as a result of it’s an enormous quantity, then let’s handle that by making all numbers in the identical scale. Let’s standardize our covariates and take a look at once more.
So, I re-ran all 96 scripts with z-score standardized covariates by means of demeaning and scaling by the usual deviation. This provides us a imply zero and commonplace deviation one. In different phrases, flip every covariate right into a z-score. Once I did this, the situation quantity dropped to roughly 1. Each zero recovered. All 96 cells produced actual ATT estimates. The numerical downside was gone. As an example, not does R’s did refuse to calculate something — not less than now we’re getting non-zero values for all 96 calculations.

And but, csdid nonetheless estimated ATTs roughly twice as giant as the opposite packages. The fan narrowed however didn’t shut. You may see these new outcomes right here.
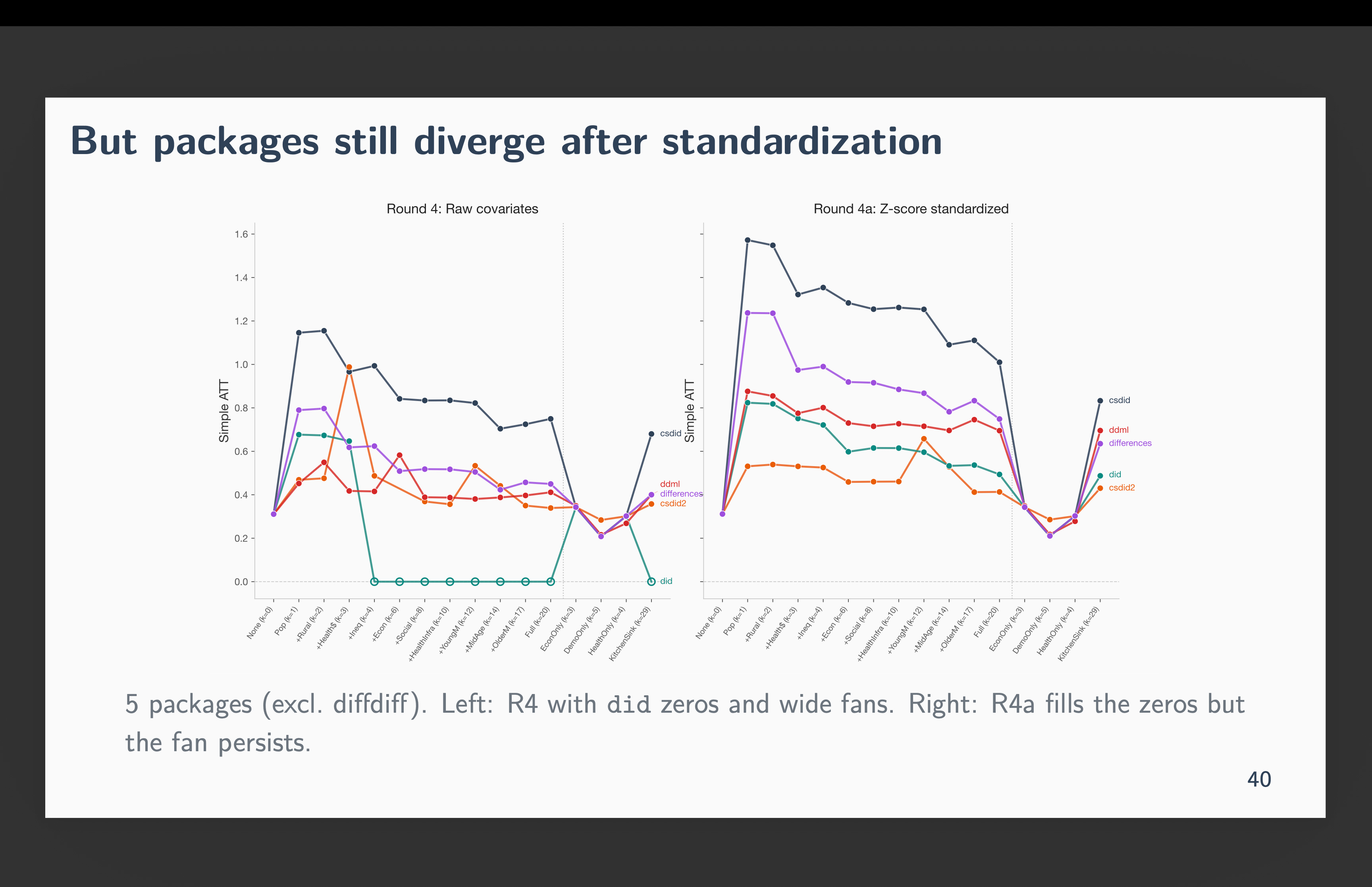
Why is that this taking place if we now not have “huge numbers”? Due to “near-separation” from the propensity rating stage creating outliers. Close to-separation is about outlier construction, not scale. Z-scoring preserves outliers — a municipality that’s 8 commonplace deviations from the imply continues to be 8 commonplace deviations from the imply. It’s simply not 10 billion in comparison with 0.4 because the imply of every covariate is zero and its commonplace deviation is 1.
The issue is that every bundle makes use of a special logit optimizer to estimate the propensity rating, and every optimizer handles near-separation in a different way. did makes use of MLE logit. csdid makes use of inverse chance tilting, which finds weights that precisely steadiness covariates between handled and controls — and when near-separation is current, it assigns excessive weights to attain that steadiness. Completely different propensity scores, completely different ATTs.
So, to summarize — standardization of covariates into z-scores mounted the pc’s downside, however not the statistical downside. The statistical downside stays even with z-scores as that has to do with outlier construction and excellent prediction of the propensity scores due to this fact in sufficient instances.
This isn’t about researcher discretion — each bundle acquired the identical specification. It additionally isn’t about parallel traits — we by no means received that far. Heck, it’s actually not even about CS. That is really about the way in which that every bundle brings within the propensity rating and the way it offers with numbers, and the way it handles failures. In a single case, failure brought on for example the estimator to only drop all the covariates regardless of being advised to make use of them and revert again to the “no covariate” case. And that’s decidedly not clear by any means.
That is implementation variation buried in supply code. Package deal selection is a substantive choice that determines whether or not your ATT is 0.00, 0.45, 1.15, or 2.38, and no journal requires you to report which bundle you used, and “robustness” is never if by no means going to contain checking a special language’s completely different bundle, and even completely different variations of the identical bundle.
I’ve been calling it “orthogonal language hallucination errors” — the concept in case you run the identical specification in three languages they usually don’t agree, one thing is incorrect, and the errors throughout languages are unlikely to be correlated. When Claude Code writes six pipelines and two of them disagree with the opposite 4, that’s informative. It’s a code audit that may have been prohibitively costly to do by hand.
Between-package variation is a beforehand undocumented supply of publication bias. Not the type the place researchers select specs to get significance — the type the place the software program silently produces completely different solutions and no one checks.
So I’d not be an excellent economist if I didn’t end a chat with “coverage suggestions”. Listed here are 4 coverage suggestions due to this fact.
-
First, report the bundle and model. Even after standardization, bundle selection produces roughly 2x completely different estimates.
-
Second, standardize your covariates earlier than estimation. It eliminates numerical singularity and reduces interplay variance by a 3rd.
-
Third, run a zero-covariate baseline.
-
Fourth, Affirm packages agree unconditionally earlier than you begin including covariates and watching the outcomes diverge — not since you assume the right specification is “no covariates” however as a result of it’s the best case and you may rule out methods the packages are dealing with covariate instances.
However then here’s a fifth level. The fifth level, and the broader level, is that this type of cross-package, cross-language audit is strictly what Claude Code must be used for. Why? As a result of this can be a process that’s time-intensive, high-value, and brutally straightforward to get incorrect. However only one mismatched diagnostic throughout languages invalidates the whole comparability, even one thing so simple as pattern measurement values differing throughout specs, would flag it. That is each straightforward and never straightforward — however it isn’t the work people must be doing by hand given how straightforward it will be to even get that a lot incorrect.
You may skip across the movies. The final two is me going over the “stunning deck” that Claude Code made for me, and that deck is posted on my web site.
When you discover this type of work helpful — utilizing Claude Code for sensible analysis, not influencer content material — I’d respect your contemplating a paid subscription. This can be a labor of affection, and there’s extra to dig into. Not simply Callaway and Sant’Anna. Each estimator that is determined by a propensity rating. Each bundle that inverts a matrix with out telling you the situation quantity.
The TL;DR although is that tthe packages didn’t agree. And none of them advised you. And generally psychological well being deinstitutionalization had no impact and generally it had 2.4 extra homicides per capita. And it’s not due to “robustness” stuff — they need to be similar they usually weren’t.