

{kind=link}
The hole between proprietary frontier fashions and extremely clear open-source fashions is closing sooner than ever. NVIDIA has formally pulled the curtain again on Nemotron 3 Tremendous, a staggering 120 billion parameter reasoning mannequin engineered particularly for complicated multi-agent purposes.
Launched at this time, Nemotron 3 Tremendous sits completely between the light-weight 30 billion parameter Nemotron 3 Nano and the extremely anticipated 500 billion parameter Nemotron 3 Extremely coming later in 2026. Delivering as much as 7x greater throughput and double the accuracy of its earlier technology, this mannequin is an enormous leap ahead for builders who refuse to compromise between intelligence and inference effectivity.
The ‘5 Miracles’ of Nemotron 3 Tremendous
Nemotron 3 Tremendous’s unprecedented efficiency is pushed by 5 main technological breakthroughs:
- Hybrid MoE Structure: The mannequin intelligently combines memory-efficient Mamba layers with high-accuracy Transformer layers. By solely activating a fraction of parameters to generate every token, it achieves a 4x improve in KV and SSM cache utilization effectivity.
- Multi-Token Prediction (MTP): The mannequin can predict a number of future tokens concurrently, resulting in 3x sooner inference occasions on complicated reasoning duties.
- 1-Million Context Window: Boasting a context size 7x bigger than the earlier technology, builders can drop large technical studies or complete codebases immediately into the mannequin’s reminiscence, eliminating the necessity for re-reasoning in multi-step workflows.
- Latent MoE: This enables the mannequin to compress data and activate 4 consultants for a similar compute price as one. With out this innovation, the mannequin would have to be 35 occasions bigger to hit the identical accuracy ranges.
- NeMo RL Health club Integration: By interactive reinforcement studying pipelines, the mannequin learns from dynamic suggestions loops somewhat than simply static textual content, successfully doubling its intelligence index.
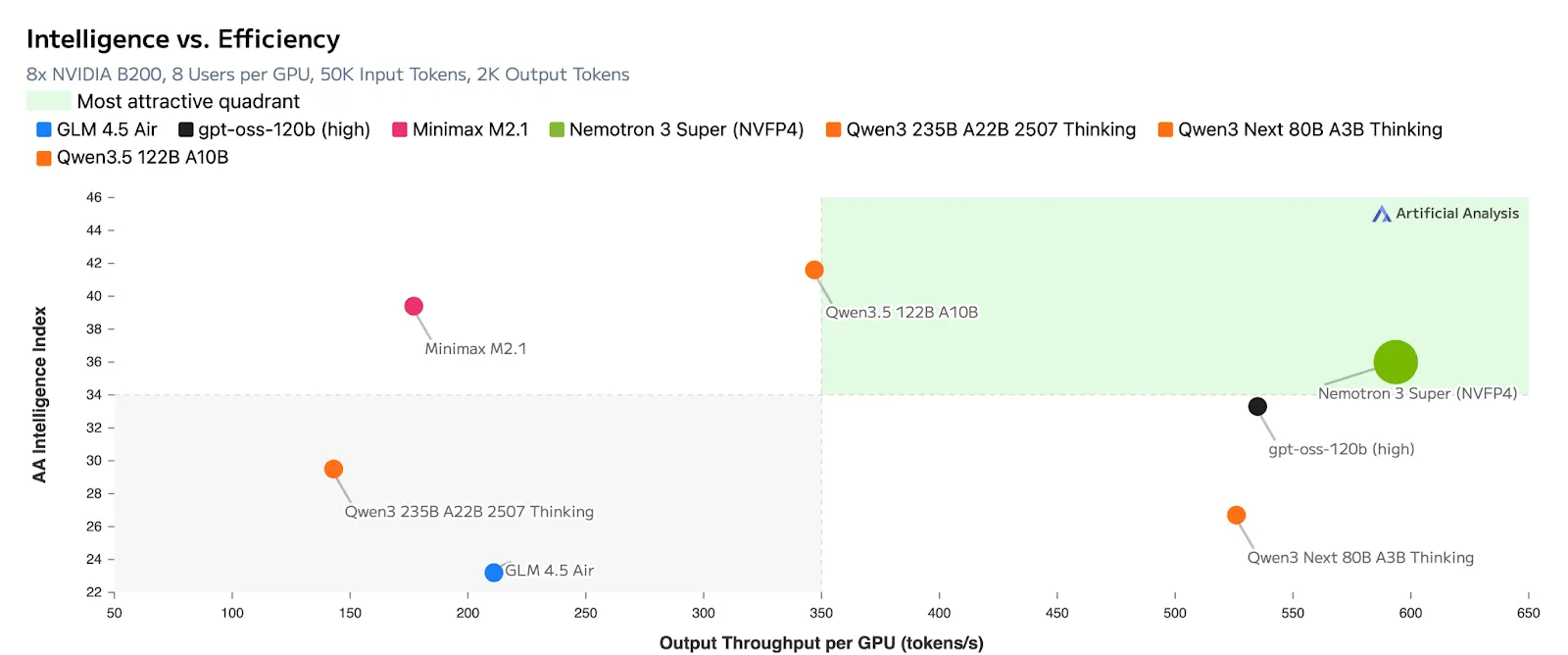
All these breakthroughs, result in unimaginable effectivity by way of output tokens per GPU
Why Nemotron 3 Tremendous is the Final Engine for Multi-Agent AI?
Nemotron 3 Tremendous isn’t simply a regular massive language mannequin; it’s particularly positioned as a reasoning engine designed to plan, confirm, and execute complicated duties inside a broader system of specialised fashions. Right here is strictly why its structure makes it a game-changer for multi-agent workflows:
- Excessive Throughput for Deeper Reasoning: The mannequin’s 7x greater throughput bodily expands its search area. As a result of it will probably course of and generate tokens sooner, it will probably discover considerably extra trajectories and consider higher responses. This enables builders to run deeper reasoning on the identical compute price range, which is crucial for constructing subtle, autonomous brokers.
- Zero “Re-Reasoning” in Lengthy Workflows: In multi-agent techniques, brokers continually move context forwards and backwards. The 1-million token context window permits the mannequin to retain large quantities of state, like complete codebases or lengthy, multi-step agent dialog histories, immediately in its reminiscence. This eliminates the latency and value of forcing the mannequin to re-process context at each single step.
- Agent-Particular Coaching Environments: As a substitute of relying solely on static textual content datasets, the mannequin’s pipeline was prolonged with over 15 interactive reinforcement studying environments. By coaching in dynamic simulation loops (reminiscent of devoted environments for software program engineering brokers and tool-augmented search), Nemotron 3 Tremendous discovered the optimum trajectories for autonomous activity completion.
- Superior Device Calling Capabilities: In real-world multi-agent purposes, fashions have to act, not simply textually reply. Out of the field, Nemotron 3 Tremendous has confirmed extremely proficient at instrument calling, efficiently navigating large swimming pools of obtainable features—reminiscent of dynamically choosing from over 100 completely different instruments in complicated cybersecurity workflows.
Open Sourced and Coaching Scale
NVIDIA isn’t simply releasing the weights; they’re utterly open-sourcing the mannequin’s complete stack, which incorporates the coaching datasets, libraries, and the reinforcement studying environments.
Due to this stage of transparency, Synthetic Evaluation locations Nemotron 3 Tremendous squarely within the ‘most tasty quadrant,’ noting that it achieves the very best openness rating whereas sustaining main accuracy alongside proprietary fashions. The inspiration of this intelligence comes from a very redesigned pipeline educated on 10 trillion curated tokens, supplemented by an additional 9 to 10 billion tokens strictly targeted on superior coding and reasoning duties.

Developer Management: Introducing ‘Reasoning Budgets‘
Whereas uncooked parameter counts and benchmark scores are spectacular, NVIDIA crew understands that real-world enterprise builders want exact management over latency, consumer expertise, and compute prices. To unravel the basic intelligence-versus-speed dilemma, Nemotron 3 Tremendous introduces extremely versatile Reasoning Modes immediately by way of its API, placing an unprecedented stage of granular management within the palms of the developer.
As a substitute of forcing a one-size-fits-all output, builders can dynamically modify precisely how exhausting the mannequin ‘thinks’ based mostly on the precise activity at hand:
- Full Reasoning (Default): The mannequin is unleashed to leverage its most capabilities, exploring deep search areas and multi-step trajectories to resolve probably the most complicated, agentic issues.
- The ‘Reasoning Finances’: This can be a complete game-changer for latency-sensitive purposes. Builders can explicitly cap the mannequin’s pondering time or compute allowance. By setting a strict reasoning price range, the mannequin intelligently optimizes its inside search area to ship the very best doable reply inside that actual constraint.
- ‘Low Effort Mode’: Not each immediate requires a deep, multi-agent evaluation. When a consumer simply wants a easy, concise reply (like customary summarization or fundamental Q&A) with out the overhead of deep reasoning, this toggle transforms Nemotron 3 Tremendous right into a lightning-fast responder, saving large quantities of compute and time.
The ‘Golden’ Configuration
Tuning reasoning fashions can usually be a irritating strategy of trial and error, however NVIDIA crew has utterly demystified it for this launch. To extract the very best efficiency throughout all of those dynamic modes, NVIDIA recommends a worldwide configuration of Temperature 1.0 and High P 0.95.
In keeping with NVIDIA crew, locking in these actual hyperparameter settings ensures the mannequin maintains the right mathematical stability of artistic exploration and logical precision, whether or not it’s operating on a constrained low-effort mode or an uncapped reasoning deep-dive.
Actual-World Functions and Availability
Nemotron 3 Tremendous is already proving its mettle throughout demanding enterprise purposes:
- Software program Growth: It handles junior-level pull requests and outperforms main proprietary fashions in concern localization, efficiently discovering the precise line of code inflicting a bug.
- Cybersecurity: The mannequin excels at navigating complicated safety ISV workflows with its superior tool-calling logic.
- Sovereign AI: Organizations globally in areas like India, Vietnam, South Korea, and Europe are utilizing the Nemotron structure to construct specialised, localized fashions tailor-made for particular areas and regulatory frameworks.
Nemotron 3 Tremendous is released in BF16, FP8, and NVFP4 quantizations, with NVFP4 required for operating the mannequin on a DGX Spark.
Take a look at the Fashions on Hugging Face. You could find particulars on Analysis Paper and Technical/Developer Weblog.
Due to the NVIDIA AI crew for the thought management/ Sources for this text. NVIDIA AI crew has supported and sponsored this content material/article.

Jean-marc is a profitable AI enterprise govt .He leads and accelerates development for AI powered options and began a pc imaginative and prescient firm in 2006. He’s a acknowledged speaker at AI conferences and has an MBA from Stanford.